
 développement back-end
Tutoriel Python
Détection et traitement des données aberrantes Python (exemples détaillés)
développement back-end
Tutoriel Python
Détection et traitement des données aberrantes Python (exemples détaillés)
Détection et traitement des données aberrantes Python (exemples détaillés)

Cet article vous apporte des connaissances pertinentes sur python, qui présente principalement les problèmes liés aux valeurs aberrantes dans l'analyse des données. Généralement, les méthodes de détection des valeurs aberrantes incluent des méthodes statistiques, des méthodes basées sur le clustering et certaines méthodes spéciales de détection des valeurs aberrantes, etc. Ces méthodes sont présentées ci-dessous. J'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel d'apprentissage du python
1 Qu'est-ce qu'une valeur aberrante ?
Dans l'apprentissage automatique, la détection et traitement des anomalies est une branche relativement petite, ou en d'autres termes, un sous-produit de l'apprentissage automatique, car dans les problèmes de prédiction généraux, le modèle est généralement une analyse de la structure globale des données de l'échantillon. Cette expression capture généralement les propriétés générales de l'échantillon global, et les points qui sont complètement incohérents avec l'échantillon global en termes de ces propriétés sont appelés valeurs aberrantes. Les valeurs aberrantes ne sont généralement pas utilisées dans les problèmes de prédiction, car la prédiction. les problèmes se concentrent généralement sur les propriétés de l'échantillon global et le mécanisme de génération des valeurs aberrantes est complètement incompatible avec l'échantillon global. Si l'algorithme est sensible aux valeurs aberrantes, alors le modèle généré ne peut pas prédire l'échantillon global et il existe donc une meilleure expression. la prédiction sera inexacte. D'un autre côté, les points anormaux sont d'un grand intérêt pour les analystes dans certains scénarios, comme la prédiction de maladies. Habituellement, les indicateurs physiques des personnes en bonne santé sont similaires dans certaines dimensions. Si les indicateurs physiques d'une personne apparaissent. S'il y a une anomalie, alors. sa condition physique doit avoir changé sous certains aspects. Bien entendu, ce changement n'est pas nécessairement causé par la maladie (souvent appelé point de bruit), mais l'apparition et la détection d'anomalies sont un point de départ important pour la prédiction de la maladie. Des scénarios similaires peuvent également être appliqués à la fraude au crédit, aux cyberattaques, etc.
2 Méthodes de détection des valeurs aberrantes
Les méthodes générales de détection des valeurs aberrantes incluent les méthodes statistiques, les méthodes basées sur le clustering et certaines méthodes spécialisées dans la détection des valeurs aberrantes. Ces méthodes sont présentées ci-dessous.
1. Statistiques simples
Si vous utilisez pandas, nous pouvons directement utiliser describe() pour observer la description statistique des données (observer approximativement quelques statistiques), Cependant, les statistiques sont continues, comme suit : pandas,我们可以直接使用describe()来观察数据的统计性描述(只是粗略的观察一些统计量),不过统计数据为连续型的,如下:
df.describe()

或者简单使用散点图也能很清晰的观察到异常值的存在。如下所示:

2. 3∂原则
这个原则有个条件:数据需要服从正态分布。在3∂原则下,异常值如超过3倍标准差,那么可以将其视为异常值。正负3∂的概率是99.7%,那么距离平均值3∂之外的值出现的概率为P(|x-u| > 3∂) <= 0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。

红色箭头所指就是异常值。
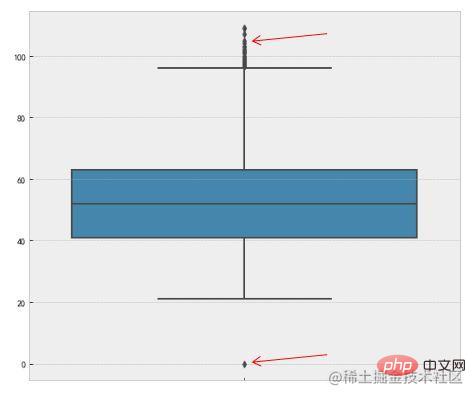
3. 箱型图
这种方法是利用箱型图的四分位距(IQR)对异常值进行检测,也叫Tukey‘s test。箱型图的定义如下:

四分位距(IQR)就是上四分位与下四分位的差值。而我们通过IQR的1.5倍为标准,规定:超过上四分位+1.5倍IQR距离,或者下四分位-1.5倍IQR距离的点为异常值。下面是Python中的代码实现,主要使用了numpy的percentile方法。
Percentile = np.percentile(df['length'],[0,25,50,75,100]) IQR = Percentile[3] - Percentile[1] UpLimit = Percentile[3]+ageIQR*1.5 DownLimit = Percentile[1]-ageIQR*1.5
也可以使用seaborn的可视化方法boxplot
f,ax=plt.subplots(figsize=(10,8)) sns.boxplot(y='length',data=df,ax=ax) plt.show()
 Ou utilisez simplement un nuage de points pour observer clairement l'existence de valeurs aberrantes. Comme indiqué ci-dessous :
Ou utilisez simplement un nuage de points pour observer clairement l'existence de valeurs aberrantes. Comme indiqué ci-dessous :
2.
Ce principe a une condition :
Les données doivent obéir à la distribution normale. Selon le principe 3∂, si une valeur aberrante dépasse 3 fois l’écart type, elle peut être considérée comme une valeur aberrante. La probabilité d'un 3∂ positif ou négatif est de 99,7 %, donc la probabilité qu'une valeur autre que 3∂ par rapport à la valeur moyenne apparaisse est P(|x-u| > 3∂) <= 0,003, ce qui est très rare et petit. événement probable. Si les données ne suivent pas une distribution normale, elles peuvent également être décrites par le nombre de fois où l'écart type s'éloigne de la moyenne.
La flèche rouge pointe vers la valeur aberrante. 3. Box plot
🎜Cette méthode utilise l'🎜intervalle interquartile (IQR)🎜 du box plot pour détecter les valeurs aberrantes, également appelée 🎜Test de Tukey🎜. La définition du box plot est la suivante : 🎜🎜🎜🎜 quatre points L'IQR est la différence entre le quartile supérieur et le quartile inférieur. Nous utilisons 1,5 fois l'IQR comme norme et stipulons que les points dépassant le quartile supérieur + 1,5 fois la distance IQR, ou le quartile inférieur - 1,5 fois la distance IQR 🎜 sont des valeurs aberrantes. Ce qui suit est l'implémentation du code en Python, utilisant principalement la méthode percentile de numpy. 🎜rrreee🎜Vous pouvez également utiliser la méthode de visualisation boxplot de seaborn pour y parvenir : 🎜rrreee🎜🎜🎜🎜La flèche rouge pointe vers la valeur aberrante. 🎜🎜Ce qui précède est une méthode simple couramment utilisée pour déterminer les valeurs aberrantes. Introduisons quelques algorithmes de détection de valeurs aberrantes plus complexes. Comme cela implique beaucoup de contenu, seules les idées de base seront présentées. Les amis intéressés peuvent étudier en profondeur par eux-mêmes. 🎜🎜4. Basée sur la détection de modèle🎜🎜Cette méthode construit généralement un 🎜modèle de distribution de probabilité🎜, calcule la probabilité que l'objet soit conforme au modèle et traite les objets à faible probabilité comme des valeurs aberrantes. Si le modèle est un ensemble de clusters, les anomalies sont des objets qui n'appartiennent de manière significative à aucun cluster ; si le modèle est une régression, les anomalies sont des objets relativement éloignés de la valeur prédite. 🎜🎜Définition de probabilité d'une valeur aberrante : 🎜Une valeur aberrante est un objet qui a une faible probabilité 🎜 par rapport au modèle de distribution de probabilité des données. La condition préalable à cette situation est de savoir à quelle distribution obéit l'ensemble de données. Si l'estimation est erronée, cela entraînera une distribution à queue lourde. 🎜Par exemple, la méthode RobustScaler dans l'ingénierie des caractéristiques, lors de la mise à l'échelle des valeurs des caractéristiques des données, utilisera la distribution quantile des caractéristiques des données pour diviser les données en plusieurs segments en fonction du quantile, et ne prendra que le segment du milieu. . Pour effectuer une mise à l'échelle, par exemple, prenez uniquement les données du quantile de 25 % au quantile de 75 % pour la mise à l'échelle. Cela réduit l’impact des données anormales. RobustScaler方法,在做数据特征值缩放的时候,它会利用数据特征的分位数分布,将数据根据分位数划分为多段,只取中间段来做缩放,比如只取25%分位数到75%分位数的数据做缩放。这样减小了异常数据的影响。
优缺点:(1)有坚实的统计学理论基础,当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效;(2)对于多元数据,可用的选择少一些,并且对于高维数据,这些检测可能性很差。
5. 基于近邻度的离群点检测
统计方法是利用数据的分布来观察异常值,一些方法甚至需要一些分布条件,而在实际中数据的分布很难达到一些假设条件,在使用上有一定的局限性。
确定数据集的有意义的邻近性度量比确定它的统计分布更容易。这种方法比统计学方法更一般、更容易使用,因为一个对象的离群点得分由到它的k-最近邻(KNN)的距离给定。
需要注意的是:离群点得分对k的取值高度敏感。如果k太小,则少量的邻近离群点可能导致较低的离群点得分;如果K太大,则点数少于k的簇中所有的对象可能都成了离群点。为了使该方案对于k的选取更具有鲁棒性,可以使用k个最近邻的平均距离。
优缺点:(1)简单;(2)缺点:基于邻近度的方法需要O(m2)时间,大数据集不适用;(3)该方法对参数的选择也是敏感的;(4)不能处理具有不同密度区域的数据集,因为它使用全局阈值,不能考虑这种密度的变化。
5. 基于密度的离群点检测
从基于密度的观点来说,离群点是在低密度区域中的对象。基于密度的离群点检测与基于邻近度的离群点检测密切相关,因为密度通常用邻近度定义。一种常用的定义密度的方法是,定义密度为到k个最近邻的平均距离的倒数。如果该距离小,则密度高,反之亦然。另一种密度定义是使用DBSCAN聚类算法使用的密度定义,即一个对象周围的密度等于该对象指定距离d内对象的个数。
优缺点:(1)给出了对象是离群点的定量度量,并且即使数据具有不同的区域也能够很好的处理;(2)与基于距离的方法一样,这些方法必然具有O(m2)的时间复杂度。对于低维数据使用特定的数据结构可以达到O(mlogm);(3)参数选择是困难的。虽然LOF算法通过观察不同的k值,然后取得最大离群点得分来处理该问题,但是,仍然需要选择这些值的上下界。
6. 基于聚类的方法来做异常点检测
基于聚类的离群点:一个对象是基于聚类的离群点,如果该对象不强属于任何簇,那么该对象属于离群点。
离群点对初始聚类的影响:如果通过聚类检测离群点,则由于离群点影响聚类,存在一个问题:结构是否有效。这也是k-means算法的缺点,对离群点敏感。为了处理该问题,可以使用如下方法:对象聚类,删除离群点,对象再次聚类(这个不能保证产生最优结果)。
优缺点:(1)基于线性和接近线性复杂度(k均值)的聚类技术来发现离群点可能是高度有效的;(2)簇的定义通常是离群点的补,因此可能同时发现簇和离群点;(3)产生的离群点集和它们的得分可能非常依赖所用的簇的个数和数据中离群点的存在性;(4)聚类算法产生的簇的质量对该算法产生的离群点的质量影响非常大。
7. 专门的离群点检测
其实以上说到聚类方法的本意是是无监督分类,并不是为了寻找离群点的,只是恰好它的功能可以实现离群点的检测,算是一个衍生的功能。
除了以上提及的方法,还有两个专门用于检测异常点的方法比较常用:One Class SVM和Isolation Forest
5. Détection des valeurs aberrantes basée sur la proximité
Les méthodes statistiques utilisent la distribution des données pour observer les valeurs aberrantes. Certaines méthodes nécessitent même certaines conditions de distribution. En pratique, la distribution des données est difficile à réaliser. il existe certaines limitations d'utilisation. Il est plus facile de déterminer une mesure significative de proximité d'un ensemble de données que de déterminer sa distribution statistique. Cette méthode est plus générale et plus facile à utiliser que les méthodes statistiques car le score aberrant d'un objet est donné par la distance à ses k voisins les plus proches (KNN). 🎜🎜Il est à noter que le score aberrant est très sensible à la valeur de k. Si k est trop petit, un petit nombre de valeurs aberrantes proches peuvent entraîner un faible score de valeurs aberrantes ; si K est trop grand, tous les objets des clusters comportant moins de k points peuvent devenir des valeurs aberrantes. Afin de rendre ce schéma plus robuste à la sélection de k, la distance moyenne des k voisins les plus proches peut être utilisée. 🎜🎜Avantages et inconvénients : (1) Simple ; (2) Inconvénients : La méthode basée sur la proximité nécessite un temps O(m2) et ne convient pas aux grands ensembles de données ; Cette méthode convient au choix des paramètres est également sensible (4) ; elle ne peut pas gérer des ensembles de données avec des régions de densités différentes car elle utilise un seuil global et ne peut pas prendre en compte de tels changements de densité. 🎜
5. Détection des valeurs aberrantes basée sur la densité
🎜D'un point de vue basé sur la densité, les valeurs aberrantes sont des objets situés dans des zones à faible densité. La détection des valeurs aberrantes basée sur la densité est étroitement liée à la détection des valeurs aberrantes basée sur la proximité, puisque la densité est souvent définie en termes de proximité. Une façon courante de définir la densité consiste à définir la densité comme l'inverse de la distance moyenne aux k voisins les plus proches. Si cette distance est faible, la densité est élevée et vice versa. Une autre définition de la densité est la définition de densité utilisée par l'algorithme de clustering DBSCAN, c'est-à-dire que la densité autour d'un objet est égale au nombre d'objets situés à une distance d spécifiée de l'objet. 🎜🎜Avantages et inconvénients : (1) Il donne une mesure quantitative indiquant que l'objet est une valeur aberrante et peut être bien traité même si les données ont des zones différentes (2) Par rapport à ; la méthode de distance est la même et ces méthodes doivent avoir une complexité temporelle de O(m2). Pour les données de faible dimension, l'utilisation de structures de données spécifiques peut obtenirO(mlogm) (3) La sélection des paramètres est difficile. Bien que l'algorithme LOF résolve ce problème en observant différentes valeurs k puis en obtenant le score aberrant maximum, il doit toujours choisir des limites supérieure et inférieure pour ces valeurs. 🎜6. Méthode basée sur le clustering pour la détection des valeurs aberrantes
🎜Valeurs aberrantes basées sur le clustering :Un objet est une valeur aberrante basée sur le clustering si l'objet n'appartient fortement à aucun cluster, alors l'objet appartient à une valeur aberrante. 🎜🎜L'impact des valeurs aberrantes sur le clustering initial : Si des valeurs aberrantes sont détectées via le clustering, une question se pose puisque les valeurs aberrantes affectent le clustering : si la structure est valide. C'est également une lacune de l'algorithmek-means, qui est sensible aux valeurs aberrantes. Afin de résoudre ce problème, vous pouvez utiliser les méthodes suivantes : regrouper les objets, supprimer les valeurs aberrantes et regrouper à nouveau les objets (cela ne garantit pas des résultats optimaux). 🎜🎜Avantages et inconvénients : (1) Les techniques de clustering basées sur une complexité linéaire et quasi-linéaire (k-means) peuvent être très efficaces pour découvrir des valeurs aberrantes ; (2) La définition des clusters est généralement une valeur aberrante ; . complément de points de cluster, il est donc possible de découvrir des clusters et des valeurs aberrantes en même temps ; (3) les ensembles de valeurs aberrantes résultants et leurs scores peuvent être très dépendants du nombre de clusters utilisés et de l'existence de valeurs aberrantes dans les données ( 4) La qualité des clusters produits par un algorithme de clustering a une grande influence sur la qualité des valeurs aberrantes produites par l'algorithme. 🎜7. Détection spécialisée des valeurs aberrantes
🎜En fait, l'intention initiale de la méthode de clustering mentionnée ci-dessus est une classification non supervisée, non pas pour trouver des valeurs aberrantes, mais simplement pour que sa fonction puisse réaliser des valeurs aberrantes. La détection de points est une fonction dérivée. 🎜🎜En plus des méthodes mentionnées ci-dessus, il existe deux méthodes plus couramment utilisées spécifiquement pour détecter les valeurs aberrantes :One Class SVM et Isolation Forest. Les détails ne seront pas abordés dans. Recherche en profondeur. 🎜🎜3 Comment gérer les valeurs aberrantes🎜🎜Des valeurs aberrantes ont été détectées et nous devons les gérer dans une certaine mesure. Les méthodes générales de traitement des valeurs aberrantes peuvent être grossièrement divisées dans les catégories suivantes : 🎜- Supprimer les enregistrements contenant des valeurs aberrantes : Supprimez directement les enregistrements contenant des valeurs aberrantes ;
- Traiter comme des valeurs manquantes : Traitez les valeurs aberrantes comme des valeurs manquantes et utilisez des méthodes de traitement des valeurs manquantes pour les traiter ; la valeur moyenne des deux valeurs observées avant et après peut être utilisée pour corriger la valeur aberrante
- Aucun traitement : effectuer directement une exploration de données sur l'ensemble de données avec des valeurs aberrantes ; situation réelle à considérer. Étant donné que certains modèles ne sont pas très sensibles aux valeurs aberrantes, même s'il y a des valeurs aberrantes, l'effet du modèle ne sera pas affecté. Cependant, certains modèles tels que la régression logistique LR sont très sensibles aux valeurs aberrantes. S'ils ne sont pas traités, des effets très faibles tels que le surajustement peuvent être obtenus. se produire.
- 4 Résumé des valeurs aberrantesCe qui précède est un résumé des méthodes de détection et de traitement des valeurs aberrantes.
Tutoriel Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
 Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python convient plus aux débutants, avec une courbe d'apprentissage en douceur et une syntaxe concise; JavaScript convient au développement frontal, avec une courbe d'apprentissage abrupte et une syntaxe flexible. 1. La syntaxe Python est intuitive et adaptée à la science des données et au développement back-end. 2. JavaScript est flexible et largement utilisé dans la programmation frontale et côté serveur.
 PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP est originaire en 1994 et a été développé par Rasmuslerdorf. Il a été utilisé à l'origine pour suivre les visiteurs du site Web et a progressivement évolué en un langage de script côté serveur et a été largement utilisé dans le développement Web. Python a été développé par Guidovan Rossum à la fin des années 1980 et a été publié pour la première fois en 1991. Il met l'accent sur la lisibilité et la simplicité du code, et convient à l'informatique scientifique, à l'analyse des données et à d'autres domaines.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
