
 base de données
Redis
Comprendre brièvement l'implémentation de l'algorithme d'élimination du cache LRU de Redis
base de données
Redis
Comprendre brièvement l'implémentation de l'algorithme d'élimination du cache LRU de Redis
Comprendre brièvement l'implémentation de l'algorithme d'élimination du cache LRU de Redis

Cet article vous apporte des connaissances pertinentes sur le Tutoriel Redis, qui présente principalement les problèmes liés à la mise en œuvre de l'algorithme d'élimination du cache LRU de Redis. LRU utilisera une liste chaînée pour maintenir l'état d'accès de chaque donnée dans le cache, et en fonction de cela. Accès en temps réel aux données et ajustement de la position des données dans la liste chaînée. J'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel d'apprentissage Redis
1 Le principe de mise en œuvre du standard LRU
LRU, Least Récemment utilisé (Least Récemment utilisé, LRU), algorithme de cache classique.
LRU utilisera une liste chaînée pour maintenir l'état d'accès de chaque donnée dans le cache, et ajustera la position des données dans la liste chaînée en fonction de l'accès en temps réel aux données, puis utilisera la position des données dans la liste chaînée pour indiquer si les données ont été récemment consultées ou non.
LRU placera respectivement la tête et la queue de la chaîne à l'extrémité MRU et à l'extrémité LRU :
- MRU, l'abréviation de Most Récemment Utilisé, indiquant que les données ici viennent d'être consultées
- Fin LRU, les données ici est la donnée la moins récemment consultée
LRU peut être divisé dans les cas suivants :
- case1 : Lorsque de nouvelles données sont insérées, LRU insère les données dans la tête de la chaîne et en même temps, se déplace les données en tête de la liste chaînée d'origine et les données qui suivent vers la queue Bit
- case2 : Lorsque les données viennent d'être consultées une seule fois, LRU déplacera les données de leur position actuelle dans la liste chaînée vers la tête. de la chaîne. Déplacez toutes les autres données de la tête de la liste chaînée vers sa position actuelle d'un bit vers la queue
- case3 : lorsque la longueur de la liste chaînée ne peut plus accueillir plus de données et que de nouvelles données sont insérées, LRU supprime les données à la queue de la liste chaînée. Cela équivaut également à éliminer les données du cache
Illustration du cas 2 : La longueur de la liste chaînée est de 5, et les données enregistrées de la tête à la queue de la liste chaînée sont 5, 33, 9, 10 et 8 respectivement. Supposons que les données 9 soient consultées une fois, puis 9 seront déplacées vers la tête de la liste chaînée, et en même temps, les données 5 et 33 seront toutes deux déplacées d'une position vers la fin de la liste chaînée.
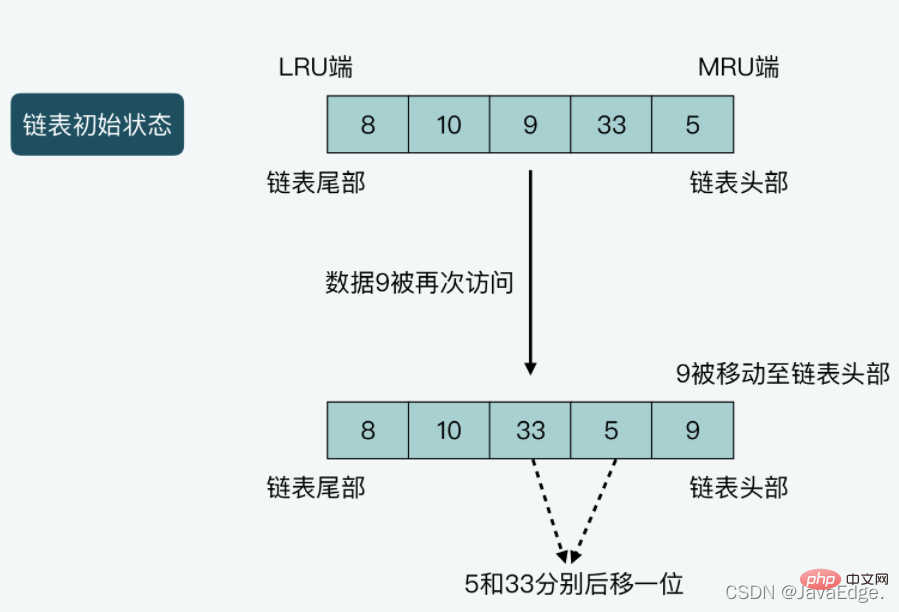
Donc, s'il est implémenté strictement selon LRU, en supposant que Redis enregistre beaucoup de données, il doit être implémenté dans le code :
-
Lorsque Redis utilise le maximum de mémoire, maintenez une liste chaînée pour tous les données qui peuvent être hébergées
Espace mémoire supplémentaire pour enregistrer la liste chaînée
-
Chaque fois que de nouvelles données sont insérées ou que des données existantes sont à nouveau accessibles, plusieurs opérations de liste chaînée doivent être effectuées
Dans le processus d'accès aux données, Redis est affecté par la surcharge liée au mouvement des données et aux opérations de liste chaînée
Conduisant en fin de compte à une réduction des performances d'accès Redis.
Ainsi, qu'il s'agisse d'économiser de la mémoire ou de maintenir les hautes performances de Redis, Redis n'est pas implémenté strictement selon les principes de base de LRU, mais fournit une implémentation approximative de l'algorithme LRU.
2 Implémentation de l'algorithme LRU approximatif dans Redis
Comment le mécanisme d'élimination de mémoire de Redis active-t-il l'algorithme LRU approximatif ? Les paramètres de configuration suivants dans redis.conf :
maxmemory, définissez la capacité de mémoire maximale que le serveur Redis peut utiliser. Une fois que la mémoire réelle utilisée par le serveur dépasse le seuil, le serveur effectuera une élimination de mémoire selon le. Politique de configuration maxmemory-policy. Utilisez
maxmemory-policy pour définir la stratégie d'élimination de la mémoire du serveur Redis, y compris LRU, LFU approximatifs, l'élimination par valeur TTL et l'élimination aléatoire, etc. une fois l'option maxmemory définie et lorsque maxmemory-policy est configuré comme allkeys-lru ou volatile-lru, une LRU approximative est activée. allkeys-lru et volatile-lru utilisent tous deux un LRU approximatif pour éliminer les données. La différence est la suivante :
 volatile-lru filtre dans les paires KV avec TTL défini Les données qui sera éliminé
volatile-lru filtre dans les paires KV avec TTL défini Les données qui sera éliminé
- Calcul de la valeur de l'horloge LRU globale
-
Initialisation de la valeur clé et mise à jour de la valeur de l'horloge LRU
Quoi Dans la fonction, la valeur d'horloge LRU correspondant à chaque paire clé-valeur est initialisée et mise à jour -
L'exécution réelle de l'algorithme LRU approximatif
Comment exécuter l'algorithme LRU approximatif, c'est-à-dire lorsque l'élimination des données est déclenchée, et le mécanisme d'élimination réel Pour mettre en œuvre -
2.1 Calcul de la valeur globale de l'horloge LRU
L'algorithme LRU approximatif doit encore distinguer la rapidité d'accès des différentes données, c'est-à-dire que Redis a besoin de connaître la dernière heure d'accès aux données. D’où l’horloge LRU : enregistrer l’horodatage de chaque accès aux données. Redis utilisera une structure redisObject pour enregistrer le pointeur vers V pour V dans chaque paire KV. En plus du pointeur qui enregistre la valeur, redisObject utilise également 24 bits pour enregistrer les informations d'horloge LRU, qui correspondent à la variable membre lru. De cette manière, chaque paire KV enregistrera l'horodatage de son dernier accès dans la variable lru.
Comment la valeur d'horloge LRU de chaque paire KV est-elle calculée ? Redis Server utilise une horloge LRU globale au niveau de l'instance, et l'heure LRU de chaque paire KV est définie en fonction de l'horloge LRU globale.
Cette horloge LRU globale est stockée dans la variable membre du serveur de variables globales Redislruclock

Lorsque le serveur Redis est démarré et que initServerConfig est appelé pour initialiser divers paramètres, getLRUClock sera appelé pour définir la valeur de lruclock :

Il faut donc noter que si l'intervalle de temps entre deux accès à une donnée est
La fonction getLRUClock divise l'horodatage UNIX obtenu par LRU_CLOCK_RESOLUTION pour obtenir l'horodatage UNIX calculé avec la précision de l'horloge LRU, qui est la valeur actuelle de l'horloge LRU.
getLRUClock effectuera une opération AND entre la valeur de l'horloge LRU et la définition de la macro LRU_CLOCK_MAX (la valeur maximale que l'horloge LRU peut représenter).

Ainsi, par défaut, la valeur globale de l'horloge LRU est un horodatage UNIX calculé avec une précision de 1s, et est initialisé dans initServerConfig.
Comment la valeur de l'horloge LRU globale est-elle mise à jour lorsque Redis Server est en cours d'exécution ? Il est lié au serverCron correspondant à l'événement s'exécutant régulièrement de Redis Server dans le cadre piloté par les événements.
serverCron, en tant que fonction de rappel pour les événements temporels, sera exécutée périodiquement. Sa valeur de fréquence est déterminée par l'élément de configuration hz dans redis.conf. La valeur par défaut est 10, c'est-à-dire que la fonction serverCron s'exécutera toutes les 100 ms. (1s/10 = 100ms). Dans serverCron, la valeur de l'horloge globale LRU sera mise à jour régulièrement en fonction de la fréquence d'exécution de cette fonction en appelant getLRUClock :

De cette façon, chaque paire KV peut obtenir le dernier horodatage d'accès de l'horloge globale LRU.
Pour chaque paire KV, dans quelles fonctions son redisObject.lru correspondant est-il initialisé et mis à jour ?
2.2 Initialisation et mise à jour de la valeur d'horloge LRU de la paire clé-valeur
Pour une paire KV, la valeur d'horloge LRU est initialement définie lors de la création de la paire KV. Cette opération d'initialisation est appelée dans la fonction createObject, cette fonction. est appelé lorsque Redis souhaite créer une paire KV.
En plus d'allouer de l'espace mémoire à redisObject, createObject initialisera également redisObject.lru selon la configuration maxmemory_policy.
- Si maxmemory_policy=LFU, la valeur de la variable lru sera initialisée et définie sur la valeur calculée de l'algorithme LFU
- maxmemory_policy≠LFU, puis createObject appelle LRU_CLOCK pour définir la valeur lru, qui est la valeur de l'horloge LRU correspondant au Paire KV.
LRU_CLOCK renvoie la valeur actuelle de l'horloge LRU globale. Parce qu'une fois qu'une paire KV est créée, elle équivaut à un accès, et sa valeur d'horloge LRU correspondante représente son horodatage d'accès :
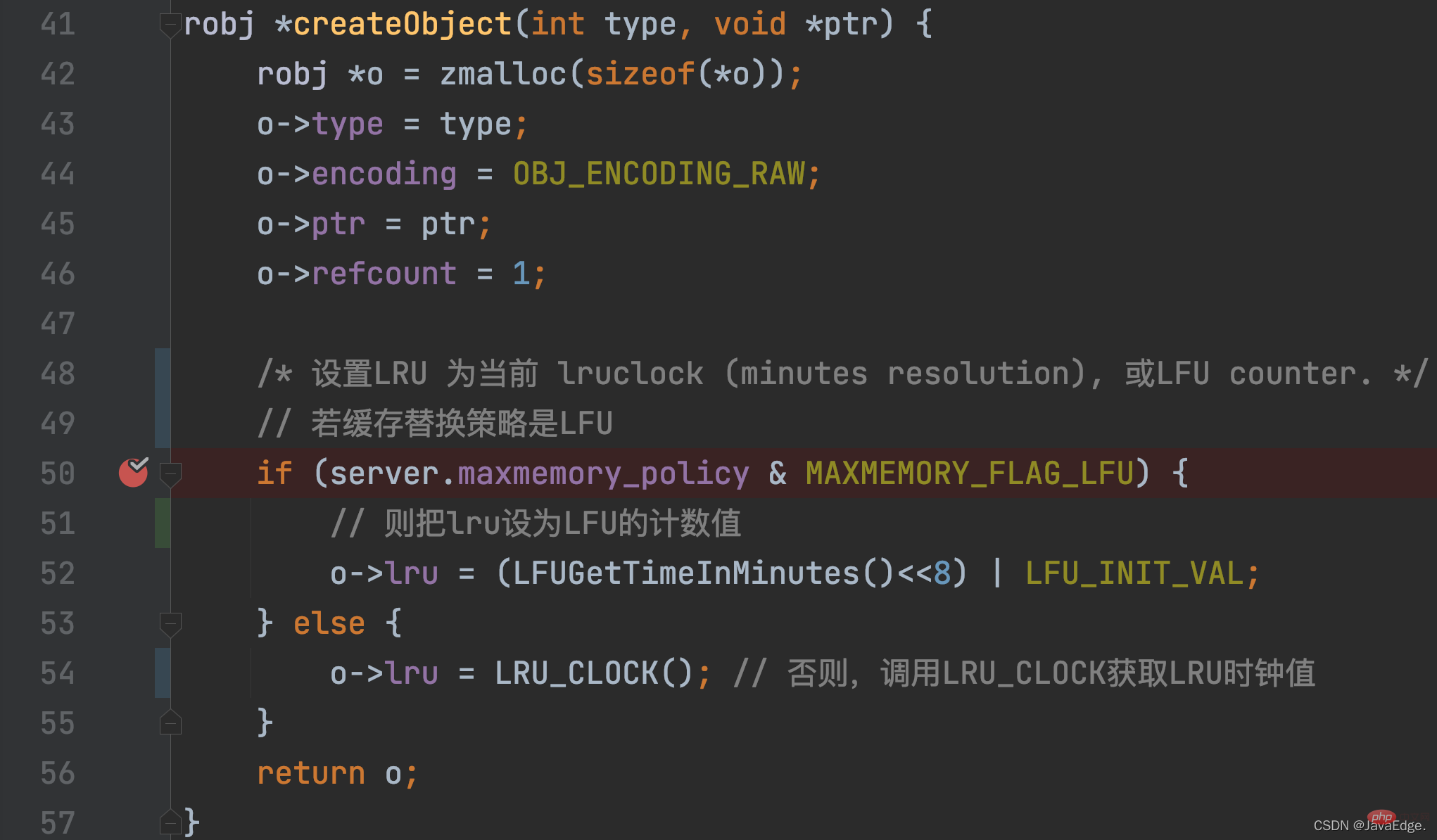
Quand la valeur d'horloge LRU de cette paire KV sera-t-elle à nouveau mise à jour ?
Tant qu'une paire KV est accédée, sa valeur d'horloge LRU sera mise à jour ! Lorsqu'une paire KV est accédée, l'opération d'accès finira par appeler lookupKey.
lookupKey recherchera la paire KV accessible à partir de la table de hachage globale. Si la paire KV existe, lookupKey mettra à jour la valeur d'horloge LRU de la paire clé-valeur, qui est son horodatage d'accès, en fonction de la valeur de configuration de maxmemory_policy.
Lorsque maxmemory_policy n'est pas configuré en tant que politique LFU, la fonction lookupKey appellera la fonction LRU_CLOCK pour obtenir la valeur d'horloge globale LRU actuelle et l'attribuera à la variable lru dans la structure redisObject de la paire clé-valeur
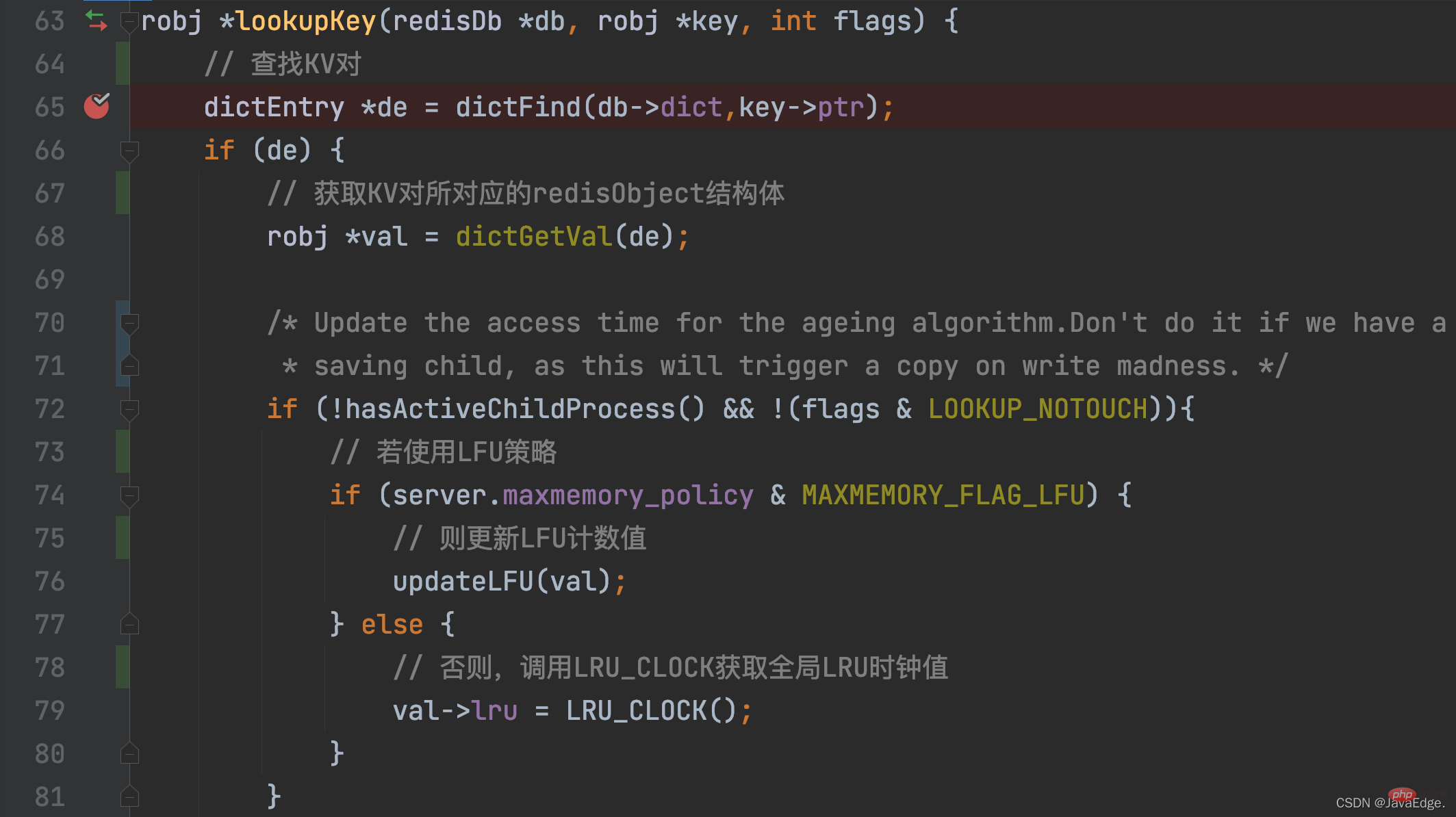
De cette façon, une fois l'accès à chaque paire KV effectué, elle peut obtenir le dernier horodatage d'accès. Mais vous pourriez être curieux : comment ces horodatages d'accès sont-ils finalement utilisés pour se rapprocher de l'algorithme LRU pour l'élimination des données ?
2.3 Exécution réelle de l'algorithme LRU approximatif
La raison pour laquelle Redis implémente le LRU approximatif est de réduire la surcharge des ressources mémoire et du temps de fonctionnement.
2.3.1 Quand l'exécution de l'algorithme est-elle déclenchée ?
La logique principale du LRU approximatif réside dans la réalisation d'expulsions.
performEvictions est appelée par evictionTimeProc et la fonction evictionTimeProc est appelée par processCommand.
processCommand, Redis appellera lors du traitement de chaque commande :
 Ensuite, isSafeToPerformEvictions jugera à nouveau s'il faut continuer à exécuter performEvictions en fonction des conditions suivantes :
Ensuite, isSafeToPerformEvictions jugera à nouveau s'il faut continuer à exécuter performEvictions en fonction des conditions suivantes :


Une fois performEvictions appelé et maxmemory-policy défini sur allkeys-lru ou volatile-lru, l'exécution approximative de LRU est déclenchée.
2.3.2 Processus d'exécution approximatif spécifique à LRU
L'exécution peut être divisée en les étapes suivantes :
2.3.2.1 Déterminer l'utilisation actuelle de la mémoire
Appelez getMaxmemoryState pour évaluer l'utilisation actuelle de la mémoire et déterminer si la capacité actuelle de la mémoire du serveur Redis dépasse la valeur de configuration maxmemory.
S'il ne dépasse pas maxmemory, C_OK sera renvoyé et performEvictions reviendra également directement.

Lorsque getMaxmemoryState évalue l'utilisation actuelle de la mémoire, s'il constate que la mémoire utilisée dépasse la mémoire maximale, il calculera la quantité de mémoire qui doit être libérée. La taille de cette mémoire libérée = la quantité de mémoire utilisée - maxmemory.
Mais la quantité de mémoire utilisée n'inclut pas la taille du tampon de copie utilisée pour la réplication maître-esclave, qui est calculée par getMaxmemoryState en appelant freeMemoryGetNotCountedMemory.
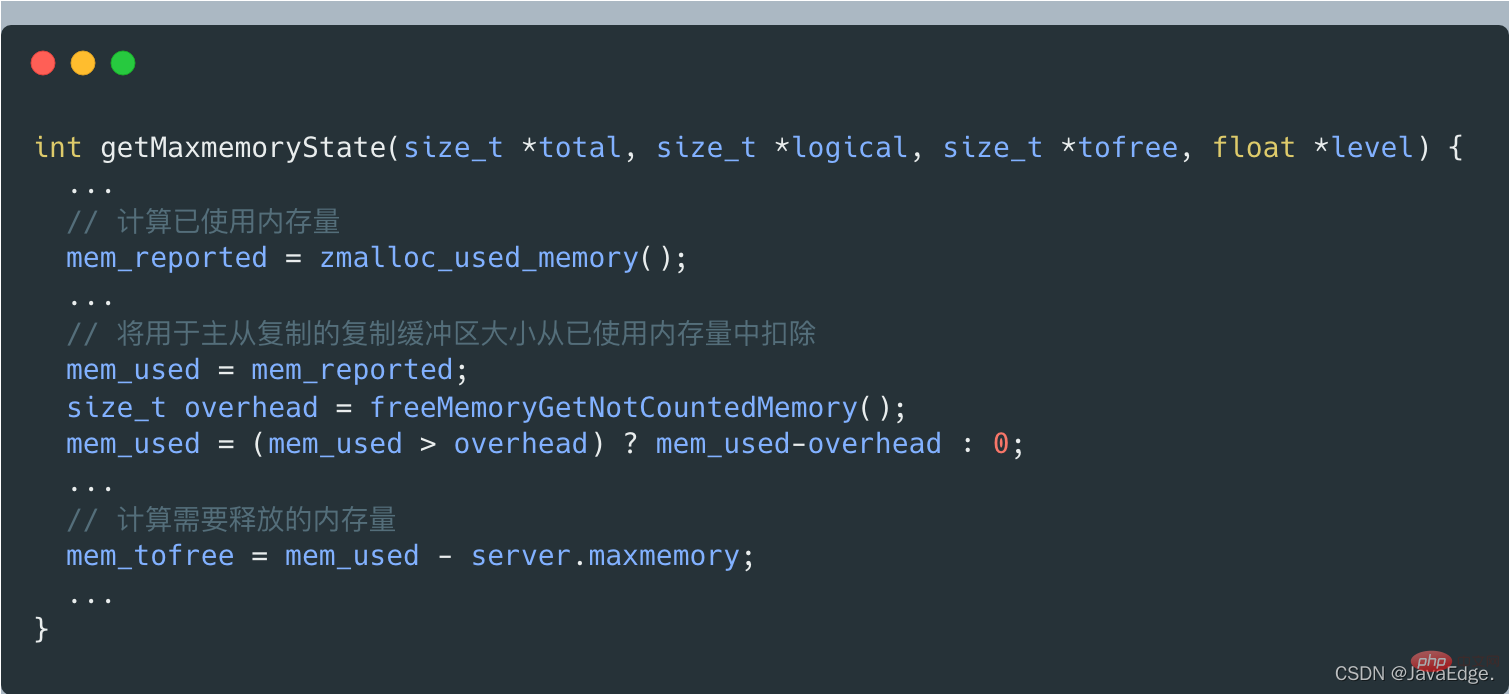
Si la quantité de mémoire actuellement utilisée par le serveur dépasse la limite supérieure de maxmemory, performEvictions exécutera une boucle while pour éliminer les données et libérer de la mémoire.
Pour les données d'élimination, Redis définit le tableau EvictionPoolLRU pour enregistrer les paires KV candidates à éliminer :


De cette façon, lorsque Redis Server exécute initSever pour l'initialisation, il appellera evictionPoolAlloc pour allouer de l'espace mémoire au tableau EvictionPoolLRU. La taille du tableau est déterminée par EVPOOL_SIZE. Par défaut, il peut enregistrer 16 candidats. Paires KV à éliminer.
PerformEvictions mettra à jour l'ensemble des paires KV candidates à éliminer, qui est le tableau EvictionPoolLRU, pendant le processus cyclique d'élimination des données.
2.3.2.2 Mettre à jour l'ensemble des paires KV candidates à éliminer
performEvictions appelle evictionPoolPopulate, qui appellera d'abord dictGetSomeKeys pour obtenir aléatoirement un certain nombre K de la table de hachage à échantillonner :
- dictGetSomeKeys table de hachage échantillonnée, configurée par maxmemory_policy Décision :
- Si maxmemory_policy=allkeys_lru, la table de hachage à échantillonner est la table de hachage globale du serveur Redis, c'est-à-dire qu'elle est échantillonnée dans toutes les paires KV
- Sinon, la table de hachage à échantillonner enregistre K avec TTL définir la table de hachage.
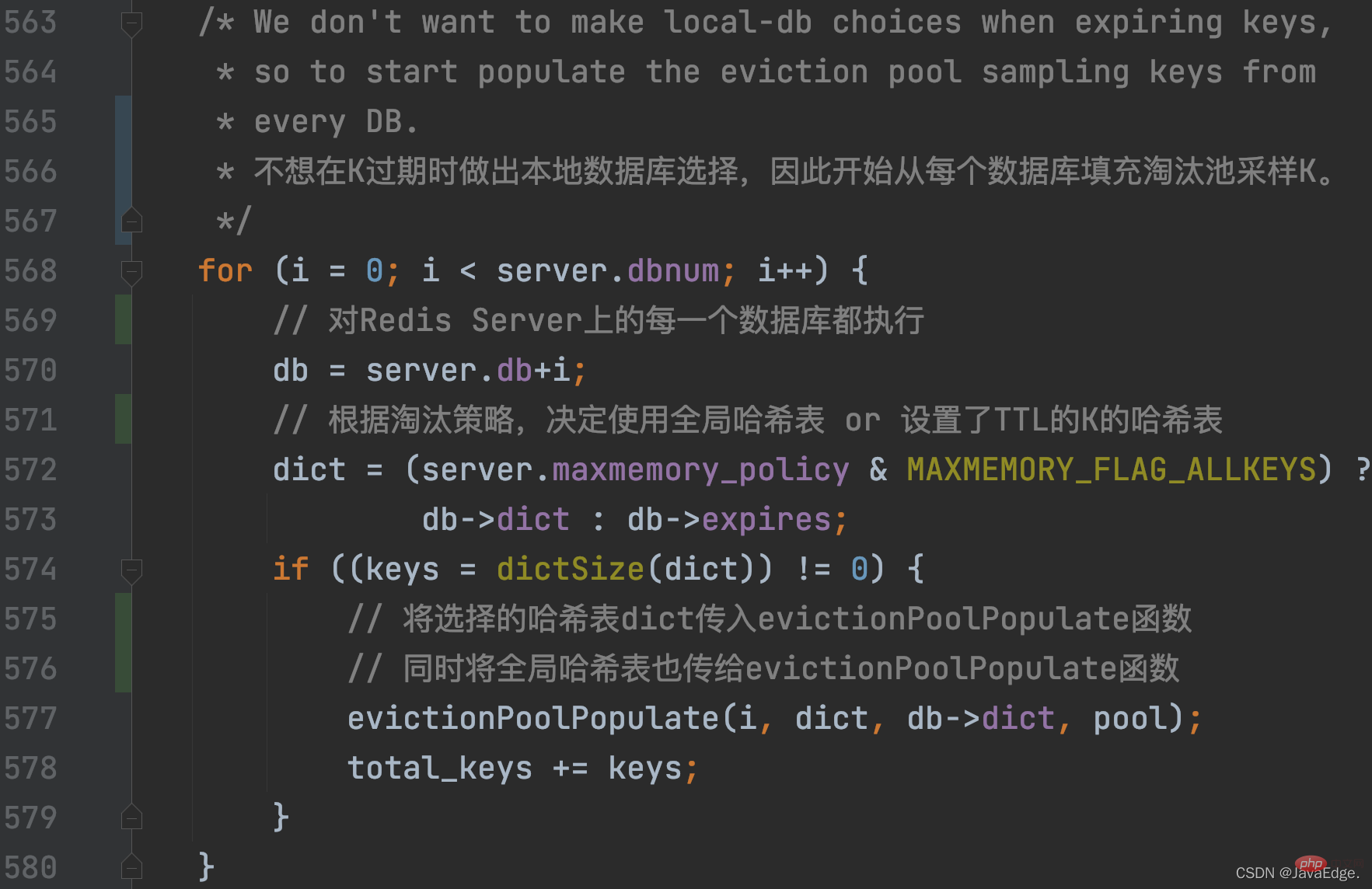
- Le nombre de K échantillonnés par dictGetSomeKeys est déterminé par l'élément de configuration maxmemory-samples, la valeur par défaut est 5 :

Donc, dictGetSomeKeys renvoie l'ensemble de paires KV échantillonnées. evictionPoolPopulate exécute une boucle basée sur le nombre réel de paires KV échantillonnées : appelezestimateObjectIdleTime pour calculer le temps d'inactivité de chaque paire KV dans l'ensemble d'échantillonnage :
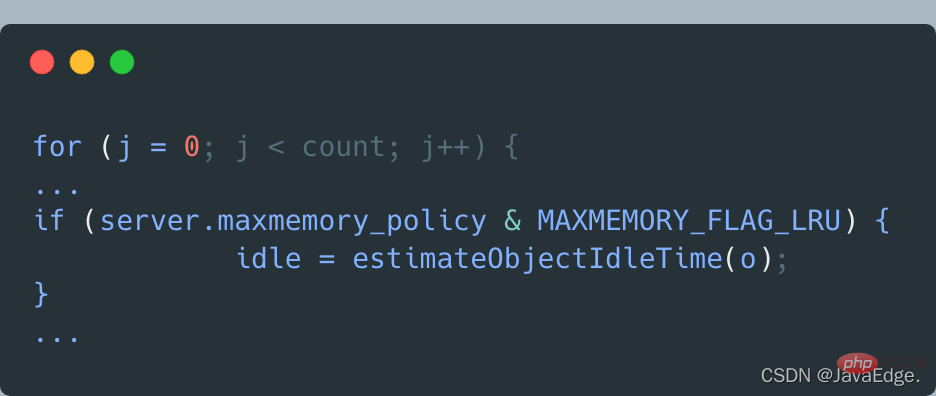
Ensuite, evictionPoolPopulate parcourt l'ensemble des paires KV candidates à éliminer, c'est-à-dire le tableau EvictionPoolLRU, essayez d'insérer chaque paire KV échantillonnée dans le tableau EvictionPoolLRU, en fonction de l'une des conditions suivantes :
- peut trouver un emplacement vide dans le tableau qui n'a pas encore inséré de paire KV
- peut trouver une paire KV dans le tableau avec un temps d'inactivité
Une fois le K éliminé sélectionné, performEvictions effectuera une suppression synchrone ou une suppression asynchrone selon la configuration de suppression paresseuse du serveur Redis : 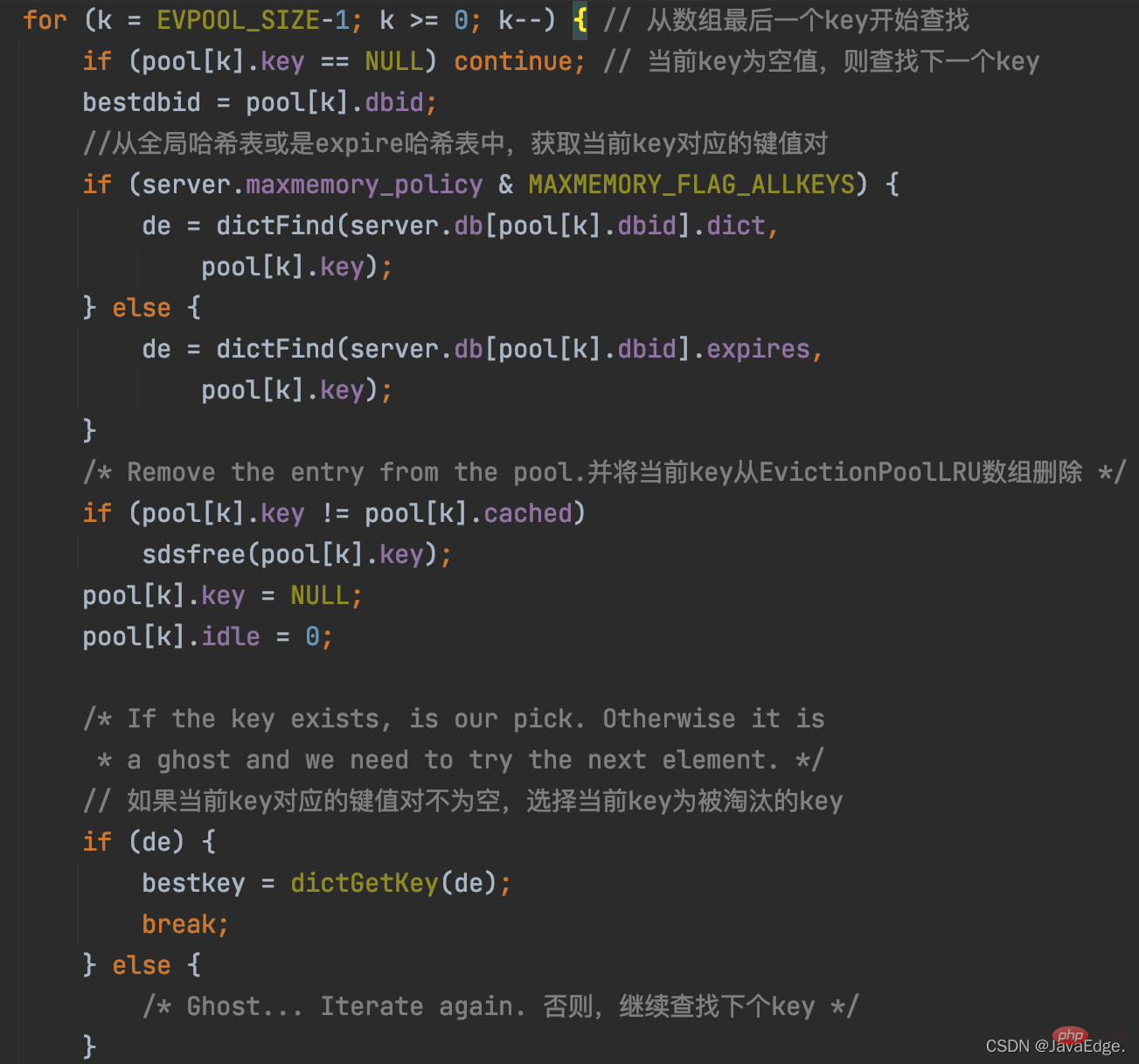
À ce stade, performEvictions a éliminé un K. Si l'espace mémoire libéré à ce moment n'est pas suffisant, c'est-à-dire que l'espace à libérer n'est pas atteint, performEvictions répétera également le processus de mise à jour de l'ensemble des paires KV candidates à éliminer et de sélection de la paire KV finale jusqu'à ce que le L'espace à libérer est satisfait aux exigences de taille. 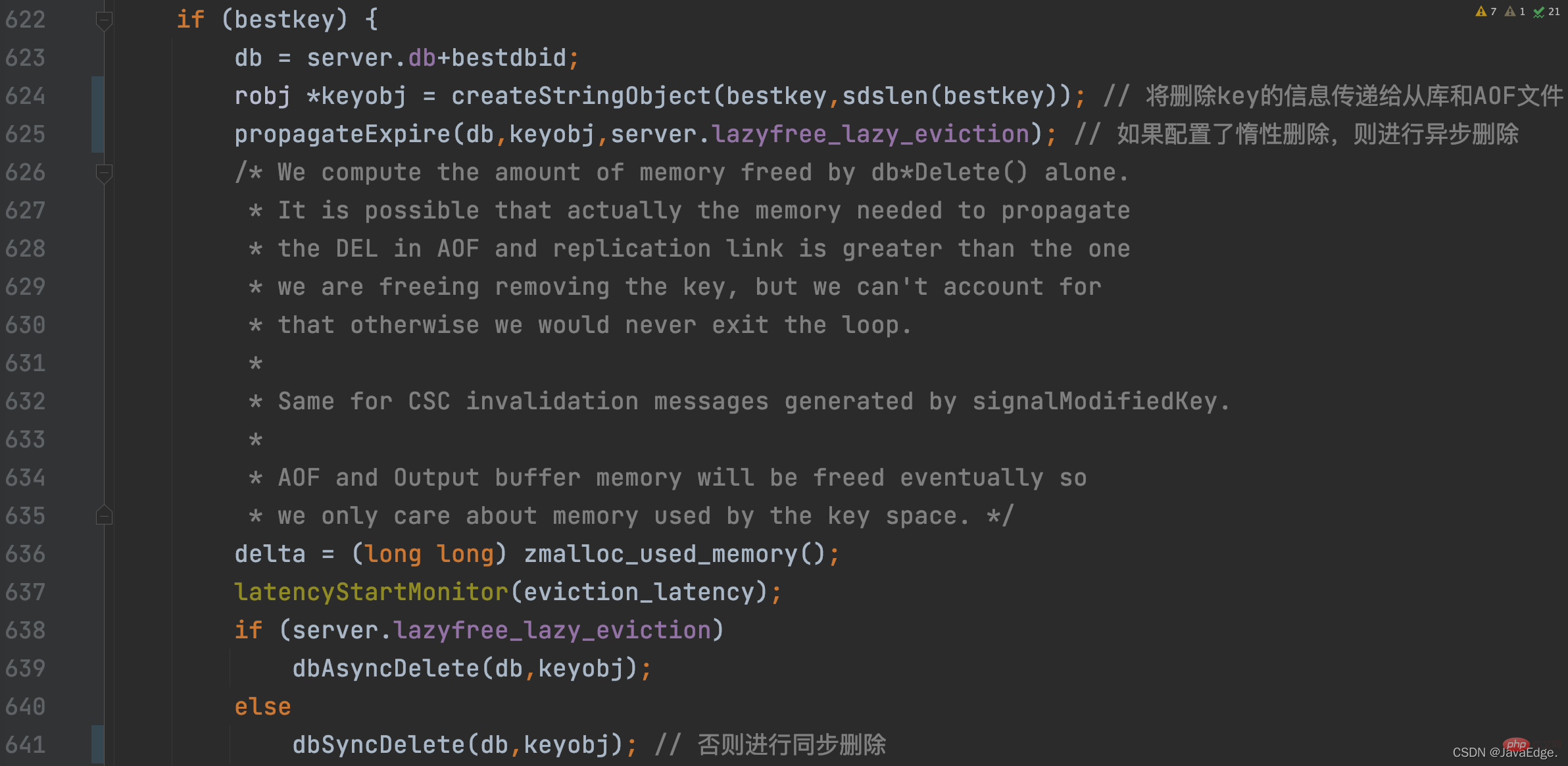
L'algorithme LRU approximatif n'utilise pas de liste chaînée qui prend du temps et de l'espace, mais utilise un ensemble de données de taille fixe à éliminer et sélectionne aléatoirement quelques K à ajouter à l'ensemble de données à éliminer à chaque fois. .
Enfin, en fonction de la durée d'inactivité des K dans l'ensemble à éliminer, supprimez les K avec le temps d'inactivité le plus long.
Résumé
Selon les principes de base de l'algorithme LRU, il s'avère que si l'algorithme LRU est implémenté strictement selon les principes de base, le système développé aura besoin d'espace mémoire supplémentaire pour enregistrer la liste chaînée LRU, et le système Le fonctionnement sera également affecté par la surcharge des opérations de liste chaînée LRU.
Les ressources mémoire et les performances de Redis sont toutes deux importantes, c'est pourquoi Redis implémente l'algorithme LRU approximatif :
- Tout d'abord, définissez l'horloge LRU globale et obtenez la valeur de l'horloge LRU globale comme horodatage d'accès lorsque la paire KV est créé et obtenez la valeur globale de l'horloge LRU à chaque accès et mettez à jour l'horodatage d'accès
- Ensuite, lorsque Redis traite une commande, performEvictions est appelé pour déterminer si la mémoire doit être libérée. Si la mémoire utilisée dépasse la mémoire maximale, sélectionnez au hasard quelques paires KV pour former un ensemble candidat à éliminer et sélectionnez les données les plus anciennes à éliminer en fonction de leurs horodatages d'accès
Le principe de base d'un algorithme et l'exécution réelle de l'algorithme sont dans le système Il y aura certains compromis pendant le développement, et les exigences en matière de ressources et de performances du système développé doivent être prises en compte de manière globale pour éviter la surcharge de ressources et de performances causée par une mise en œuvre stricte de l'algorithme.
Apprentissage recommandé : Tutoriel Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
