

Cet article vous amènera à en savoir plus sur Redis, à analyser la persistance en détail, à présenter son principe de fonctionnement, son processus de persistance, etc. J'espère qu'il vous sera utile !
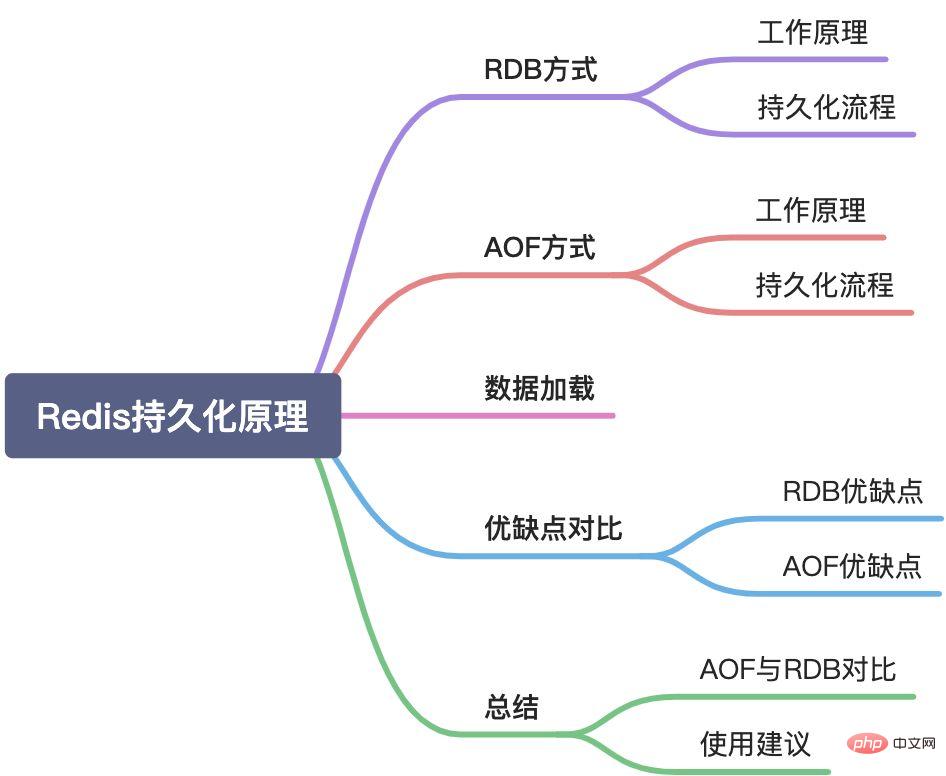
Cet article présentera le mécanisme de persistance de Redis sous les aspects suivants :
 ## Écrit avant
## Écrit avant
Cet article présente les deux méthodes de persistance de Redis en détail dans leur ensemble, y compris les principes de fonctionnement, les processus de persistance et les stratégies de pratiques , et quelques connaissances théoriques derrière eux. L'article précédent n'a présenté que la persistance RDB, mais la persistance Redis est un tout et ne peut pas être introduite séparément, elle a donc été réorganisée. [Recommandations associées : Tutoriel vidéo Redis]
Redis est une base de données en mémoire et toutes les données seront stockées en mémoire par rapport aux bases de données relationnelles traditionnelles telles que MySQL, Oracle et SqlServer, qui enregistrent les données directement sur le disque. disk, Redis L'efficacité de lecture et d'écriture est très élevée. Cependant, il existe également un gros défaut dans la sauvegarde en mémoire. Une fois l'alimentation coupée ou l'ordinateur en panne, tout le contenu de la base de données mémoire sera perdu. Afin de combler cette lacune, Redis fournit la fonction de persistance des données de mémoire dans les fichiers du disque dur et de restauration des données via des fichiers de sauvegarde, ce qui constitue le mécanisme de persistance de Redis.
Redis prend en charge deux méthodes de persistance : l'instantané RDB et l'AOF.
Instantané RDB En termes officiels : la solution de persistance RDB est un instantané point à temps généré à partir de votre ensemble de données à un intervalle de temps spécifié. Il enregistre l'instantané de mémoire de tous les objets de données de la base de données Redis à un certain moment dans un fichier binaire compressé, qui peut être utilisé pour la sauvegarde, le transfert et la récupération des données Redis. Jusqu’à présent, il s’agit toujours de la solution officielle de support par défaut.
Étant donné que RDB est un instantané ponctuel de l'ensemble de données dans Redis, comprenons d'abord brièvement comment les objets de données dans Redis sont stockés et organisés en mémoire.
Par défaut, il y a 16 bases de données dans Redis, numérotées de 0 à 15, chaque base de données Redis en utilise une redisDb对象来表示,redisDbUtilisez une table de hachage pour stocker les objets K-V. Pour faciliter la compréhension, j'ai pris l'une des bases de données comme exemple pour dessiner un diagramme schématique de la structure de stockage des données internes de Redis.

Un instantané dans le temps est l'état de chaque objet de données dans chaque base de données dans Redis à un certain moment En supposant d'abord que tous les objets de données ne changeront pas à ce moment, nous pouvons suivre le chiffre. ci-dessus Selon la relation de structure des données, ces objets de données sont lus et écrits dans des fichiers afin d'obtenir la persistance Redis. Ensuite, lorsque Redis redémarre, le contenu de ce fichier est lu selon les règles, puis écrit dans la mémoire Redis pour revenir à l'état de persistance.
Bien sûr, cette prémisse est vraie lorsque notre hypothèse ci-dessus est vraie, sinon nous n'aurions aucun moyen de démarrer face à un ensemble de données qui change tout le temps. Nous savons que le traitement des commandes client dans Redis est un modèle monothread. Si la persistance est traitée comme une commande, l'ensemble de données sera définitivement dans un état statique. De plus, le processus enfant créé par la fonction fork() fournie par le système d'exploitation peut obtenir les mêmes données mémoire que le processus parent, ce qui équivaut à obtenir une copie des données mémoire une fois le fork terminé, que devrait faire le processus enfant ; le processus parent le fait, et le travail de persistance de l'état est confié au processus enfant.
Évidemment, la première situation n'est pas recommandée. Une sauvegarde persistante entraînera l'indisponibilité du service Redis dans un court laps de temps, ce qui est intolérable pour un système à haute haute disponibilité. Par conséquent, la deuxième méthode est la principale méthode pratique de persistance RDB. Étant donné que les données du processus parent continuent de changer après la duplication du processus enfant et que le processus enfant n'est pas synchronisé avec le processus parent, la persistance RDB ne peut pas garantir les performances en temps réel ; la perte de certaines données ; la fréquence de sauvegarde détermine la quantité de données perdues. L'augmentation de la fréquence de sauvegarde signifie que le processus de fork consomme plus de ressources CPU et entraînera également des E/S disque plus importantes.
Il existe deux méthodes pour compléter la persistance RDB dans Redis : rdbSave et rdbSaveBackground (dans le fichier de code source rdb.c). Parlons brièvement de la différence entre les deux :
.Le déclenchement de la persistance RDB doit être indissociable des deux méthodes ci-dessus, et les méthodes de déclenchement sont divisées en manuel et automatique. Le déclenchement manuel est facile à comprendre.Cela signifie que nous lançons manuellement des instructions de sauvegarde persistantes sur le serveur Redis via le client Redis, puis que le serveur Redis commence à exécuter le processus de persistance. Les instructions ici incluent save et bgsave. Le déclenchement automatique est un processus de persistance que Redis déclenche automatiquement lorsque les conditions prédéfinies sont remplies en fonction de ses propres exigences de fonctionnement. Les scénarios déclenchés automatiquement sont les suivants (extraits de cet article) :
save m nin serverCron >. Les règles de configuration sont automatiquement déclenchées ; save m n配置规则自动触发;debug reload命令重新加载redis时;结合源码及参考文章,我整理了RDB持久化流程来帮助大家有个整体的了解,然后再从一些细节进行说明。
从上图可以知道:
rdbSave方法完成的。自动触发流程是一个完整的链路,涵盖了rdbSaveBackground、rdbSave等,接下来我以serverCron为例分析一下整个流程。
serverCron是Redis内的一个周期性函数,每隔100毫秒执行一次,它的其中一项工作就是:根据配置文件中save规则来判断当前需要进行自动持久化流程,如果满足条件则尝试开始持久化。了解一下这部分的实现。
在redisServer中有几个与RDB持久化有关的字段,我从代码中摘出来,中英文对照着看下:
struct redisServer {
/* 省略其他字段 */
/* RDB persistence */
long long dirty; /* Changes to DB from the last save
* 上次持久化后修改key的次数 */
struct saveparam *saveparams; /* Save points array for RDB,
* 对应配置文件多个save参数 */
int saveparamslen; /* Number of saving points,
* save参数的数量 */
time_t lastsave; /* Unix time of last successful save
* 上次持久化时间*/
/* 省略其他字段 */
}
/* 对应redis.conf中的save参数 */
struct saveparam {
time_t seconds; /* 统计时间范围 */
int changes; /* 数据修改次数 */
};saveparams对应redis.conf下的save规则,save参数是Redis触发自动备份的触发策略,seconds为统计时间(单位:秒), changes为在统计时间内发生写入的次数。save m n的意思是:m秒内有n条写入就触发一次快照,即备份一次。save参数可以配置多组,满足在不同条件的备份要求。如果需要关闭RDB的自动备份策略,可以使用save ""。以下为几种配置的说明:
# 表示900秒(15分钟)内至少有1个key的值发生变化,则执行 save 900 1 # 表示300秒(5分钟)内至少有1个key的值发生变化,则执行 save 300 10 # 表示60秒(1分钟)内至少有10000个key的值发生变化,则执行 save 60 10000 # 该配置将会关闭RDB方式的持久化 save ""
serverCron
En combinant le code source et les articles de référence, j'ai organisé le processus de persistance RDB ; pour aider tout le monde à avoir une compréhension globale, puis à partir de quelques détails. 
Comme vous pouvez le constater sur l'image ci-dessus :
rdbSave la méthode est terminée.
Le processus de déclenchement automatique est un lien complet, couvrant rdbSaveBackground, rdbSave, etc. Ensuite, j'utiliserai serverCron comme exemple pour analyser l'ensemble du processus.
règles de sauvegarde et contrôles
🎜serverCron est une fonction périodique de Redis, exécutée toutes les 100 millisecondes. L'une de ses tâches consiste à déterminer le besoin actuel de persistance automatique en fonction des règles de sauvegarde dans le fichier de configuration. , une tentative sera faite pour démarrer la persistance. Découvrez la mise en œuvre de cette partie. 🎜🎜Il y a plusieurs champs liés à la persistance RDB dansredisServer Je les ai extraits du code et les ai regardés en chinois et en anglais : 🎜int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他逻辑 */
/* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写,
* 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 后台无 saving/rewrite 子进程才会进行,逐个检查每个save规则*/
for (j = 0; j = sp->changes
&& server.unixtime-server.lastsave > sp->seconds
&&(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
/* 执行bgsave过程 */
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
/* 省略:Trigger an AOF rewrite if needed. */
}
/* 省略其他逻辑 */
}saveparams correspond à redis.conf, le paramètre de sauvegarde est la stratégie de déclenchement pour que Redis déclenche la sauvegarde automatique, secondes est le temps statistique (unité : secondes), changes C'est le nombre d'écritures survenues pendant la période statistique. <code>save m n signifie : s'il y a n écritures dans un délai de m secondes, un instantané sera déclenché, c'est-à-dire une sauvegarde. Plusieurs groupes de paramètres de sauvegarde peuvent être configurés pour répondre aux exigences de sauvegarde dans différentes conditions. Si vous devez désactiver la politique de sauvegarde automatique de RDB, vous pouvez utiliser save "". Voici les descriptions de plusieurs configurations : 🎜int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
if (hasActiveChildProcess()) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
// fork子进程
if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) {
int retval;
/* Child 子进程:修改进程标题 */
redisSetProcTitle("redis-rdb-bgsave");
redisSetCpuAffinity(server.bgsave_cpulist);
// 执行rdb持久化
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
sendChildCOWInfo(CHILD_TYPE_RDB, 1, "RDB");
}
// 持久化完成后,退出子进程
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent 父进程:记录fork子进程的时间等信息*/
if (childpid == -1) {
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %ld",(long) childpid);
// 记录子进程开始的时间、类型等。
server.rdb_save_time_start = time(NULL);
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
return C_OK;
}
return C_OK; /* unreached */
}serverCron Le code de détection des règles de sauvegarde RDB est le suivant : 🎜# no-关闭,yes-开启,默认no appendonly yes appendfilename appendonly.aof
set number 0 incr number incr number incr number incr number incr number
Redis的rdbSave函数是真正进行RDB持久化的函数,流程、细节贼多,整体流程可以总结为:创建并打开临时文件、Redis内存数据写入临时文件、临时文件写入磁盘、临时文件重命名为正式RDB文件、更新持久化状态信息(dirty、lastsave)。其中“Redis内存数据写入临时文件”最为核心和复杂,写入过程直接体现了RDB文件的文件格式,本着一图胜千言的理念,我按照源码流程绘制了下图。
补充说明一下,上图右下角“遍历当前数据库的键值对并写入”这个环节会根据不同类型的Redis数据类型及底层数据结构采用不同的格式写入到RDB文件中,不再展开了。我觉得大家对整个过程有个直观的理解就好,这对于我们理解Redis内部的运作机制大有裨益。
上一节我们知道RDB是一种时间点(point-to-time)快照,适合数据备份及灾难恢复,由于工作原理的“先天性缺陷”无法保证实时性持久化,这对于缓存丢失零容忍的系统来说是个硬伤,于是就有了AOF。
AOF是Append Only File的缩写,它是Redis的完全持久化策略,从1.1版本开始支持;这里的file存储的是引起Redis数据修改的命令集合(比如:set/hset/del等),这些集合按照Redis Server的处理顺序追加到文件中。当重启Redis时,Redis就可以从头读取AOF中的指令并重放,进而恢复关闭前的数据状态。
AOF持久化默认是关闭的,修改redis.conf以下信息并重启,即可开启AOF持久化功能。
# no-关闭,yes-开启,默认no appendonly yes appendfilename appendonly.aof
AOF本质是为了持久化,持久化对象是Redis内每一个key的状态,持久化的目的是为了在Reids发生故障重启后能够恢复至重启前或故障前的状态。相比于RDB,AOF采取的策略是按照执行顺序持久化每一条能够引起Redis中对象状态变更的命令,命令是有序的、有选择的。把aof文件转移至任何一台Redis Server,从头到尾按序重放这些命令即可恢复如初。举个例子:
首先执行指令set number 0,然后随机调用incr number、get number 各5次,最后再执行一次get number ,我们得到的结果肯定是5。
因为在这个过程中,能够引起number状态变更的只有set/incr类型的指令,并且它们执行的先后顺序是已知的,无论执行多少次get都不会影响number的状态。所以,保留所有set/incr命令并持久化至aof文件即可。按照aof的设计原理,aof文件中的内容应该是这样的(这里是假设,实际为RESP协议):
set number 0 incr number incr number incr number incr number incr number
最本质的原理用“命令重放”四个字就可以概括。但是,考虑实际生产环境的复杂性及操作系统等方面的限制,Redis所要考虑的工作要比这个例子复杂的多:
set命令,存在很大的压缩空间。从流程上来看,AOF的工作原理可以概括为几个步骤:命令追加(append)、文件写入与同步(fsync)、文件重写(rewrite)、重启加载(load),接下来依次了解每个步骤的细节及背后的设计哲学。
Lorsque la fonction de persistance AOF est activée, après que Redis ait exécuté une commande d'écriture, elle ajoutera la commande d'écriture exécutée au format de protocole (c'est-à-dire RESP, le protocole de communication pour l'interaction entre le client Redis et le serveur) Ajouté à la fin du tampon AOF géré par le serveur Redis. Il n'y a qu'une seule opération d'ajout à thread pour les fichiers AOF, et il n'y a pas d'opérations complexes telles que la recherche. Il n'y a aucun risque d'endommagement des fichiers même en cas de panne de courant ou de temps d'arrêt. De plus, l'utilisation de protocoles texte présente de nombreux avantages :
sds conçue indépendamment par Redis qui utilisera différentes méthodes selon le type de commande (catAppendOnlyGenericCommand, catAppendOnlyExpireAtCommand<.> etc.) traite le contenu de la commande et enfin l'écrit dans le tampon. </.>
Il est à noter que si la réécriture AOF est en cours lorsque les commandes sont ajoutées, ces commandes seront également ajoutées au tampon de réécriture (aof_rewrite_buffer). sds,Redis会根据命令的类型采用不同的方法(catAppendOnlyGenericCommand、catAppendOnlyExpireAtCommand等)对命令内容进行处理,最后写入缓冲区。
需要注意的是:如果命令追加时正在进行AOF重写,这些命令还会追加到重写缓冲区(aof_rewrite_buffer)。
AOF文件的写入与同步离不开操作系统的支持,开始介绍之前,我们需要补充一下Linux I/O缓冲区相关知识。硬盘I/O性能较差,文件读写速度远远比不上CPU的处理速度,如果每次文件写入都等待数据写入硬盘,会整体拉低操作系统的性能。为了解决这个问题,操作系统提供了延迟写(delayed write)机制来提高硬盘的I/O性能。
传统的UNIX实现在内核中设有缓冲区高速缓存或页面高速缓存,大多数磁盘I/O都通过缓冲进行。 当将数据写入文件时,内核通常先将该数据复制到其中一个缓冲区中,如果该缓冲区尚未写满,则并不将其排入输出队列,而是等待其写满或者当内核需要重用该缓冲区以便存放其他磁盘块数据时, 再将该缓冲排入到输出队列,然后待其到达队首时,才进行实际的I/O操作。这种输出方式就被称为延迟写。
延迟写减少了磁盘读写次数,但是却降低了文件内容的更新速度,使得欲写到文件中的数据在一段时间内并没有写到磁盘上。当系统发生故障时,这种延迟可能造成文件更新内容的丢失。为了保证磁盘上实际文件系统与缓冲区高速缓存中内容的一致性,UNIX系统提供了sync、fsync和fdatasync三个函数为强制写入硬盘提供支持。
Redis每次事件轮训结束前(beforeSleep)都会调用函数flushAppendOnlyFile,flushAppendOnlyFile会把AOF缓冲区(aof_buf)中的数据写入内核缓冲区,并且根据appendfsync配置来决定采用何种策略把内核缓冲区中的数据写入磁盘,即调用fsync()。该配置有三个可选项always、no、everysec,具体说明如下:
fsync(),是安全性最高、性能最差的一种策略。fsync()。性能最好,安全性最差。fsync()。这是官方建议的同步策略,也是默认配置,做到兼顾性能和数据安全性,理论上只有在系统突然宕机的情况下丢失1秒的数据。注意:上面介绍的策略受配置项no-appendfsync-on-rewrite的影响,它的作用是告知Redis:AOF文件重写期间是否禁止调用fsync(),默认是no。
如果appendfsync设置为always或everysec,后台正在进行的BGSAVE或者BGREWRITEAOF消耗过多的磁盘I/O,在某些Linux系统配置下,Redis对fsync()的调用可能阻塞很长时间。然而这个问题还没有修复,因为即使是在不同的线程中执行fsync(),同步写入操作也会被阻塞。
为了缓解此问题,可以使用该选项,以防止在进行BGSAVE或BGREWRITEAOF
 🎜
🎜L'implémentation UNIX traditionnelle a un cache de tampon ou un cache de pages dans le noyau. La plupart des disques I/ O est effectué via la mise en mémoire tampon. Lors de l'écriture de données dans un fichier, le noyau copie généralement d'abord les données dans l'un des tampons. Si le tampon n'est pas encore plein, il ne le met pas en file d'attente dans la file d'attente de sortie, mais attend qu'il se remplisse ou lorsque le noyau en a besoin. Lorsque le tampon est réutilisé pour stocker d'autres données de bloc de disque, le tampon est mis en file d'attente dans la file d'attente de sortie, puis l'opération d'E/S réelle n'est effectuée que lorsqu'elle atteint la tête de la file d'attente. Cette méthode de sortie est appelée écriture différée.🎜L'écriture différée réduit le nombre de lectures et d'écritures sur le disque, mais elle réduit également la vitesse de mise à jour du contenu du fichier, de sorte que les données à écrire dans le fichier ne soient pas écrites sur le disque pendant un certain temps. Lorsqu'une panne du système se produit, ce délai peut entraîner la perte des mises à jour des fichiers. Afin de garantir la cohérence du système de fichiers réel sur le disque et du contenu du cache tampon, le système UNIX fournit trois fonctions : sync, fsync et fdatasync pour prendre en charge l'écriture forcée sur le disque dur. 🎜🎜Redis appellera la fonction
flushAppendOnlyFile avant la fin de chaque rotation d'événement (beforeSleep), et flushAppendOnlyFile appellera le tampon AOF (aof_buf ) est écrit dans le tampon du noyau et la stratégie utilisée pour écrire les données du tampon du noyau sur le disque est déterminée en fonction de la configuration <code>appendfsync, c'est-à-dire en appelant fsync( ). Cette configuration comporte trois options : <code>always, no et everysec. Les détails sont les suivants : 🎜🎜🎜always : appelez fsync. à chaque fois (), est la stratégie avec la sécurité la plus élevée et les pires performances. 🎜🎜non : fsync() ne sera pas appelé. Meilleures performances, pire sécurité. 🎜🎜everysec : Appelez fsync() uniquement lorsque les conditions de synchronisation sont remplies. Il s'agit de la stratégie de synchronisation officiellement recommandée et c'est également la configuration par défaut. Elle prend en compte à la fois les performances et la sécurité des données. En théorie, seulement 1 seconde de données sera perdue en cas d'arrêt soudain du système. 🎜🎜🎜Remarque : La stratégie présentée ci-dessus est affectée par l'élément de configuration no-appendfsync-on-rewrite. Sa fonction est d'informer Redis s'il doit interdire l'appel de fsync() lors de la réécriture du fichier AOF. , la valeur par défaut est non. 🎜🎜Si appendfsync est défini sur always ou everysec, BGSAVE ou est en cours traité en arrière-plan >BGREWRITEAOF consomme trop d'E/S disque Sous certaines configurations système Linux, l'appel de Redis à fsync() peut se bloquer pendant une longue période. Cependant, ce problème n'a pas encore été résolu, car l'opération d'écriture synchrone sera bloquée même si fsync() est exécuté dans un thread différent. 🎜🎜Pour atténuer ce problème, cette option peut être utilisée pour empêcher fsync() d'être appelé dans le processus principal lors de l'exécution de BGSAVE ou BGREWRITEAOF. 🎜yes意味着,如果子进程正在进行BGSAVE或BGREWRITEAOF,AOF的持久化能力就与appendfsync设置为no有着相同的效果。最糟糕的情况下,这可能会导致30秒的缓存数据丢失。yes,否则保持为no。如前面提到的,Redis长时间运行,命令不断写入AOF,文件会越来越大,不加控制可能影响宿主机的安全。
为了解决AOF文件体积问题,Redis引入了AOF文件重写功能,它会根据Redis内数据对象的最新状态生成新的AOF文件,新旧文件对应的数据状态一致,但是新文件会具有较小的体积。重写既减少了AOF文件对磁盘空间的占用,又可以提高Redis重启时数据恢复的速度。还是下面这个例子,旧文件中的6条命令等同于新文件中的1条命令,压缩效果显而易见。
我们说,AOF文件太大时会触发AOF文件重写,那到底是多大呢?有哪些情况会触发重写操作呢?
**
与RDB方式一样,AOF文件重写既可以手动触发,也会自动触发。手动触发直接调用bgrewriteaof命令,如果当时无子进程执行会立刻执行,否则安排在子进程结束后执行。自动触发由Redis的周期性方法serverCron检查在满足一定条件时触发。先了解两个配置项:
BGREWRITEAOF时AOF文件占用空间最小值,默认为64MB;Redis启动时把aof_base_size初始化为当时aof文件的大小,Redis运行过程中,当AOF文件重写操作完成时,会对其进行更新;aof_current_size为serverCron执行时AOF文件的实时大小。当满足以下两个条件时,AOF文件重写就会触发:
增长比例:(aof_current_size - aof_base_size) / aof_base_size > auto-aof-rewrite-percentage 文件大小:aof_current_size > auto-aof-rewrite-min-size
手动触发与自动触发的代码如下,同样在周期性方法serverCron中:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他逻辑 */
/* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写,
* 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */
if (!hasActiveChildProcess() &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 省略rdb持久化条件检查 */
/* AOF重写条件检查:aof开启、无子进程运行、增长百分比已设置、当前文件大小超过阈值 */
if (server.aof_state == AOF_ON &&
!hasActiveChildProcess() &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
/* 计算增长百分比 */
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
/**/
}AOF文件重写的流程是什么?听说Redis支持混合持久化,对AOF文件重写有什么影响?
从4.0版本开始,Redis在AOF模式中引入了混合持久化方案,即:纯AOF方式、RDB+AOF方式,这一策略由配置参数aof-use-rdb-preamble(使用RDB作为AOF文件的前半段)控制,默认关闭(no),设置为yes可开启。所以,在AOF重写过程中文件的写入会有两种不同的方式。当aof-use-rdb-preamble的值是:
结合源码(6.0版本,源码太多这里不贴出,可参考aof.c)及参考资料,绘制AOF重写(BGREWRITEAOF)流程图:
结合上图,总结一下AOF文件重写的流程:
父进程:
子进程:
aof-use-rdb-preamble, écrivez la première moitié en RDB ou Mode AOF et synchronisation avec le disque dur ; aof-use-rdb-preamble配置,以RDB或AOF方式写入前半部分,并同步至硬盘;Redis启动后通过loadDataFromDisk函数执行数据加载工作。这里需要注意,虽然持久化方式可以选择AOF、RDB或者两者兼用,但是数据加载时必须做出选择,两种方式各自加载一遍就乱套了。
理论上,AOF持久化比RDB具有更好的实时性,当开启了AOF持久化方式,Redis在数据加载时优先考虑AOF方式。而且,Redis 4.0版本后AOF支持了混合持久化,加载AOF文件需要考虑版本兼容性。Redis数据加载流程如下图所示:
在AOF方式下,开启混合持久化机制生成的文件是“RDB头+AOF尾”,未开启时生成的文件全部为AOF格式。考虑两种文件格式的兼容性,如果Redis发现AOF文件为RDB头,会使用RDB数据加载的方法读取并恢复前半部分;然后再使用AOF方式读取并恢复后半部分。由于AOF格式存储的数据为RESP协议命令,Redis采用伪客户端执行命令的方式来恢复数据。
如果在AOF命令追加过程中发生宕机,由于延迟写的技术特点,AOF的RESP命令可能不完整(被截断)。遇到这种情况时,Redis会按照配置项aof-load-truncated
Après le démarrage de Redis, le travail de chargement des données est effectué via la fonction loadDataFromDisk. Il convient de noter ici que même si la méthode de persistance peut être AOF, RDB ou les deux, un choix doit être fait lors du chargement des données. Le chargement des deux méthodes séparément provoquera le chaos.
Théoriquement, la persistance AOF a de meilleures performances en temps réel que RDB Lorsque la persistance AOF est activée, Redis donne la priorité à AOF lors du chargement des données. De plus, après la version Redis 4.0, AOF prend en charge la persistance hybride et la compatibilité des versions doit être prise en compte lors du chargement des fichiers AOF. Le processus de chargement des données Redis est illustré dans la figure ci-dessous :
En mode AOF, activez l'hybride mécanisme de persistance Le fichier généré est "En-tête RDB + queue AOF". Lorsqu'il n'est pas activé, tous les fichiers générés sont au format AOF. Compte tenu de la compatibilité des deux formats de fichier, si Redis constate que le fichier AOF est un en-tête RDB, il utilisera la méthode de chargement de données RDB pour lire et restaurer la première moitié, puis utilisera la méthode AOF pour lire et restaurer la seconde moitié ; . Étant donné que les données stockées au format AOF sont des commandes du protocole RESP, Redis utilise un pseudo client pour exécuter des commandes permettant de récupérer les données.
aof-load-truncated. Cette configuration indique à Redis de lire le fichier aof au démarrage, et que faire si le fichier s'avère tronqué (incomplet) : 🎜🎜🎜oui : Chargez autant de données que possible et avertissez l'utilisateur sous forme de log ; 🎜🎜non : Ensuite, il plante avec une erreur système et il est interdit de démarrer. L'utilisateur doit réparer le fichier puis redémarrer. 🎜🎜🎜Résumé🎜🎜Redis propose deux options de persistance : RDB prend en charge la génération d'instantanés ponctuels pour l'ensemble de données à des intervalles pratiques spécifiques ; AOF conserve chaque instruction d'écriture reçue par le serveur Redis dans le journal. redémarrer. Le format du journal est le protocole RESP et seule l'opération d'ajout est effectuée sur le fichier journal, il n'y a donc aucun risque de dommage. Et lorsque le fichier AOF est trop volumineux, le fichier compressé peut être automatiquement réécrit. 🎜🎜Bien sûr, vous pouvez également désactiver la fonction de persistance de Redis si vous n'avez pas besoin de conserver les données, mais ce n'est pas le cas dans la plupart des cas. En fait, on peut parfois utiliser RDB et AOF en même temps. Le plus important est de comprendre la différence entre les deux afin de les utiliser raisonnablement. 🎜redis-check-aof
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé
 Que sont les bases de données en mémoire ?
Que sont les bases de données en mémoire ?
 Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
 Comment utiliser Redis comme serveur de cache
Comment utiliser Redis comme serveur de cache
 Comment Redis résout la cohérence des données
Comment Redis résout la cohérence des données
 Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
 Quelles données le cache Redis stocke-t-il généralement ?
Quelles données le cache Redis stocke-t-il généralement ?
 Quels sont les 8 types de données de Redis
Quels sont les 8 types de données de Redis










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



