

Cet article vous apporte des connaissances pertinentes sur python Il présente principalement des problèmes liés aux tuples, notamment la création, l'accès, la modification, la suppression et les méthodes intégrées des tuples.

Apprentissage recommandé : Tutoriel Python
Introduction - En Python, les informations importantes sur les données du projet sont enregistrées via des structures de données. Le langage Python possède une variété de structures de données intégrées, telles que des listes, des tuples, des dictionnaires et des ensembles, etc. Dans ce cours, nous parlerons de l'une des structures de données les plus importantes en Python : les tuples.
En Python, nous pouvons considérer les tuples comme un type particulier de liste. La seule différence entre celui-ci et une liste est que les éléments de données du tuple ne peuvent pas être modifiés [cela reste inchangé - non seulement les éléments de données ne peuvent pas être modifiés, mais les éléments de données ne peuvent pas non plus être ajoutés ou supprimés ! 】. Lorsque nous devons créer un ensemble de données immuables, nous mettons généralement les données dans des tuples~
en Python, la forme de base de création d'un tuple est. pour mettre les éléments de données entre parenthèses "()", et séparer chaque élément par une virgule ",".
Comme suit :
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
tuple2 = (1, 2, 3, 4, 5)
# 而且——是可以创建空元组哦!
tuple3 = ()
# 小注意——如果你创建的元组只包含一个元素时,也不要忘记在元素后面加上逗号。让其识别为一个元组:
tuple4 = (22, )Les tuples sont similaires aux chaînes et aux listes. Les index commencent à 0 et des opérations telles que l'interception et la combinaison peuvent être effectuées.
Comme suit :
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
tuple2 = (1, 2, 3, 4, 5)
# 显示元组中索引为1的元素的值
print("tuple1[1]:", tuple1[0])
# 显示元组中索引从1到3的元素的值
print("tuple2[1:3]:", tuple2[1:3])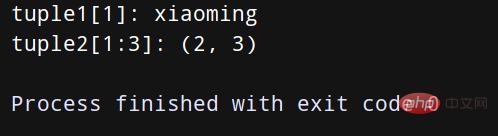
Bien qu'il soit dit au début que les tuples sont immuables, il a toujours une fonctionnalité prise en charge Opération - connexion et combinaison entre tuples :
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
tuple2 = (1, 2, 3, 4, 5)
tuple_new = tuple1 + tuple2
print(tuple_new)
Bien que le tuple soit immuable, le tuple entier peut être supprimé via l'instruction del.
Comme suit :
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
print(tuple1) # 正常打印tuple1
del tuple1
print(tuple1) # 因为上面删除了tuple1,所以再打印会报错哦!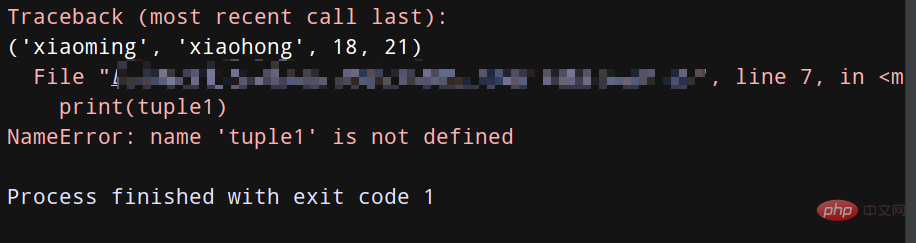
Les tuples sont immuables, mais nous pouvons manipuler les tuples en utilisant des méthodes intégrées. Les méthodes intégrées couramment utilisées sont les suivantes :
4. Décomposer une séquence en variables distinctes
Comme suit :
tuple1 = (18, 22) x, y = tuple1 print(x) print(y) tuple2 = ['xiaoming', 33, 19.8, (2012, 1, 11)] name, age, level, date = tuple2 print(name) print(date)Copier après la connexion

En Python, l'expression astérisque est très utile lors d'une itération sur une séquence de tuples de longueur variable. Ce qui suit montre le processus de décomposition d'une séquence de tuples à marquer.
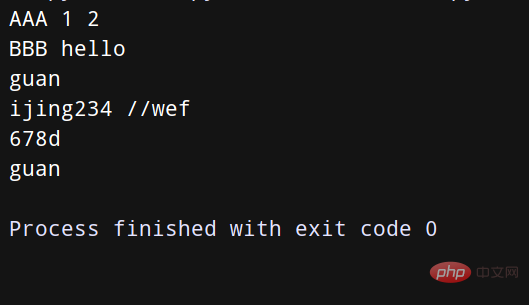
records = [ ('AAA', 1, 2), ('BBB', 'hello'), ('CCC', 5, 3) ] def do_foo(x, y): print('AAA', x, y) def do_bar(s): print('BBB', s) for tag, *args in records: if tag == 'AAA': do_foo(*args) elif tag == 'BBB': do_bar(*args) line = 'guan:ijing234://wef:678d:guan' uname, *fields, homedir, sh = line.split(':') print(uname) print(*fields) print(homedir) print(sh)Copier après la connexion
 (2)
(2)
Utilisation de l'implémentation deque intégrée :
from _collections import deque q = deque(maxlen=3) q.append(1) q.append(2) q.append(3) print(q) q.append(4) print(q)

123.txt :from _collections import deque def search(lines, pattern, history=5): previous_lines = deque(maxlen=history) for line in lines: if pattern in line: yield line, previous_lines previous_lines.append(line) # Example use on a file if __name__ == '__main__': with open('123.txt') as f: for line, prevlines in search(f, 'python', 5): for pline in prevlines: # 包含python的行 print(pline) # print (pline, end='') # 打印最后检查过的N行文本 print(line) # print (pline, end='')Copier après la connexion
pythonpythonpythonpythonpythonpythonpython python python
在上述代码中,对一系列文本行实现了简单的文本匹配操作,当发现有合适的匹配时,就输出当前的匹配行以及最后检查过的N行文本。使用deque(maxlen=N)创建了一个固定长度的队列。当有新记录加入而使得队列变成已满状态时,会自动移除最老的那条记录。当编写搜索某项记录的代码时,通常会用到含有yield关键字的生成器函数,它能够将处理搜索过程的代码和使用搜索结果的代码成功解耦开来。
使用内置模块heapq可以实现一个简单的优先级队列。
如下——演示了实现一个简单的优先级队列的过程。
import heapq
class PriorityQueue:
def __init__(self):
self._queue = []
self._index = 0
def push(self, item, priority):
heapq.heappush(self._queue, (-priority, self._index, item))
self._index += 1
def pop(self):
return heapq.heappop(self._queue)[-1]
class Item:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'Item({!r})'.format(self.name)
q = PriorityQueue()
q.push(Item('AAA'), 1)
q.push(Item('BBB'), 4)
q.push(Item('CCC'), 5)
q.push(Item('DDD'), 1)
print(q.pop())
print(q.pop())
print(q.pop())在上述代码中,利用heapq模块实现了一个简单的优先级队列,第一次执行pop()操作时返回的元素具有最高的优先级。
拥有相同优先级的两个元素(foo和grok)返回的顺序,同插入到队列时的顺序相同。
函数heapq.heappush()和heapq.heappop()分别实现了列表_queue中元素的插入和移除操作,并且保证列表中的第一个元素的优先级最低。
函数heappop()总是返回“最小”的元素,并且因为push和pop操作的复杂度都是O(log2N),其中N代表堆中元素的数量,因此就算N的值很大,这些操作的效率也非常高。
上述代码中的队列以元组 (-priority, index, item)的形式组成,priority取负值是为了让队列能够按元素的优先级从高到底排列。这和正常的堆排列顺序相反,一般情况下,堆是按从小到大的顺序进行排序的。变量index的作用是将具有相同优先级的元素以适当的顺序排列,通过维护一个不断递增的索引,元素将以它们加入队列时的顺序排列。但是当index在对具有相同优先级的元素间进行比较操作,同样扮演一个重要的角色。
在Python中,如果以元组(priority, item)的形式存储元素,只要它们的优先级不同,它们就可以进行比较。但是如果两个元组的优先级相同,在进行比较操作时会失败。这时可以考虑引入一个额外的索引值,以(priority, index, item)的方式建立元组,因为没有哪两个元组会有相同的index值,所以这样就可以完全避免上述问题。一旦比较操作的结果可以确定,Python就不会再去比较剩下的元组元素了。
如下——演示了实现一个简单的优先级队列的过程:
import heapq
class PriorityQueue:
def __init__(self):
self._queue = []
self._index = 0
def push(self, item, priority):
heapq.heappush(self._queue, (-priority, self._index, item))
self._index += 1
def pop(self):
return heapq.heappop(self._queue)[-1]
class Item:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'Item({!r})'.format(self.name)
# ①
a = Item('AAA')
b = Item('BBB')
#a <p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/49d26f0b616718a47cdbeebb6cfbf35b-7.png" class="lazy" alt="Explication détaillée des tuples Python avec des exemples"></p><p>在上述代码中,因为在1-2中没有添加所以,所以当两个元组的优先级相同时会出错;而在3-4中添加了索引,这样就不会出错了!</p><p>推荐学习:<a href="https://www.php.cn/course/list/30.html" target="_blank">python学习教程</a></p>Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



