
 base de données
tutoriel mysql
Collection de questions et réponses d'interview MySQL (partage de résumé)
base de données
tutoriel mysql
Collection de questions et réponses d'interview MySQL (partage de résumé)
Collection de questions et réponses d'interview MySQL (partage de résumé)

Cet article vous apporte des connaissances pertinentes sur mysql Il compile principalement certaines questions fréquemment posées lors des entretiens, notamment l'architecture des bases de données, l'indexation et l'optimisation SQL, etc. J'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel mysql
1. Architecture de la base de données
1.1. Parlez du schéma d'infrastructure de MySQL
Parlez à l'intervieweur de l'architecture logique de MySQL Si vous avez un tableau blanc, vous pouvez dessiner. l'image suivante. Les images proviennent d'Internet.
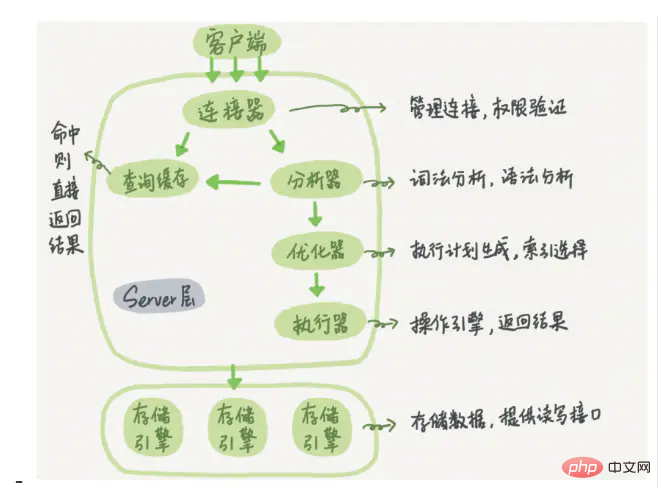
Le diagramme d'architecture logique MySQL est principalement divisé en trois couches :
(1) La première couche est responsable du traitement de la connexion, de l'authentification des autorisations, de la sécurité, etc.
(2) La deuxième couche est responsable de la compilation et optimisation de SQL
(3) La troisième couche est le moteur de stockage.
1.2. Comment une instruction de requête SQL est-elle exécutée dans MySQL ?
Vérifiez d'abord si l'instruction
a l'autorisationS'il n'y a pas d'autorisation, un message d'erreur sera renvoyé directement. S'il y a une autorisation, le cache sera d'abord interrogé (avant la version MySQL8.0). ).是否有权限,如果没有权限,直接返回错误信息,如果有权限会先查询缓存(MySQL8.0 版本以前)。如果没有缓存,分析器进行
词法分析,提取 sql 语句中 select 等关键元素,然后判断 sql 语句是否有语法错误,比如关键词是否正确等等。最后优化器确定执行方案进行权限校验,如果没有权限就直接返回错误信息,如果有权限就会
调用数据库引擎接口
analyse lexicale, extrait les éléments clés tels que select dans l'instruction sql, puis détermine si l'instruction sql contient des erreurs grammaticales, par exemple si les mots-clés sont corrects, etc.
Enfin, l'optimiseur détermine le plan d'exécution et effectue une vérification des autorisations. S'il n'y a pas d'autorisation, il renverra directement un message d'erreur. S'il y a une autorisation, il appellera l'interface du moteur de base de données. et renvoie le résultat de l'exécution.
2. Optimisation SQL
2.1. Comment optimiser SQL dans le travail quotidien ? Vous pouvez répondre à cette question à partir de ces dimensions : 2.1.1,Optimiser la structure du tableau
(1) Essayez d'utiliser des champs numériquesSi les champs qui contiennent uniquement des informations numériques, essayez de ne pas les concevoir comme des types de caractères. Cela réduit les performances des requêtes et des jointures et augmente la surcharge de stockage. En effet, le moteur comparera chaque caractère de la chaîne un par un lors du traitement des requêtes et des connexions, et une seule comparaison suffit pour les types numériques. (2) Utilisez autant que possible varchar au lieu de charLes champs de longueur variable ont un petit espace de stockage et peuvent économiser de l'espace de stockage.
(3) Lorsque la colonne d'index contient une grande quantité de données en double, l'index peut être supprimé. Par exemple, s'il existe une colonne pour le sexe, presque uniquement masculin, féminin et inconnu, un tel index n'est pas valide.- 2.1.2,
Optimiser les requêtes
- Vous devriez essayer d'éviter d'utiliser les opérateurs != ou dans les clauses Where
- Vous devriez essayer d'éviter d'utiliser les clauses or in Where pour connecter les conditions
- N'utilisez pas select * dans aucune requête. Évitez de porter des jugements de valeur nulle sur les champs de la clause Where. Indexation des champs
Évitez de créer trop d'index et d'utiliser des index combinés
- 2.2. (expliquer) et comment comprendre la signification de chaque champ ? Ajoutez le mot-clé expliquer avant l'instruction select pour renvoyer les informations du plan d'exécution.
- (1) colonne id : c'est le numéro de série de l'instruction select. MySQL divise les requêtes select en requêtes simples et requêtes complexes.
(2) colonne select_type : Indique si la ligne correspondante est une requête simple ou complexe.
(3) colonne de table : indique à quelle table une ligne d'explication accède.
(4) colonne de type : une des colonnes les plus importantes. Représente le type d'association ou le type d'accès que MySQL détermine pour rechercher des lignes dans la table. Du meilleur au pire : system > eq_ref > fulltext > index_merge > index_subquery > index > la requête pourrait utiliser pour trouver. 
2.3. Vous êtes-vous déjà soucié du SQL chronophage dans le système d'entreprise ? Les statistiques de requête sont-elles trop lentes ? Comment avez-vous optimisé les requêtes lentes ?
Lorsque nous écrivons habituellement SQL, nous devons développer l'habitude d'utiliser l'analyse expliquée. Les statistiques de requêtes lentes, d'exploitation et de maintenance nous donneront régulièrement des statistiques
Optimisation des idées de requêtes lentes :
Analyser les instructions, si des champs/données inutiles sont chargés
-
Analyser les phrases d'exécution SQL, si elles atteignent l'index, etc. .
Si le SQL est très complexe, optimisez la structure SQL
Si la quantité de données de table est trop importante, envisagez des sous-tables
3. Index
3.1. et index non clusterisé
Vous pouvez appuyer sur les quatre réponses suivantes à partir de plusieurs dimensions :
(1) Une table ne peut avoir qu'un seul index clusterisé, tandis qu'une table peut avoir plusieurs index non clusterisés.
(2) Index clusterisé, l'ordre logique des valeurs clés dans l'index détermine l'ordre physique des lignes correspondantes dans le tableau, l'ordre logique de l'index dans l'index est différent du ordre de stockage physique des lignes sur le disque.
(3) L'index est décrit à travers la structure de données d'un arbre binaire Nous pouvons comprendre l'index clusterisé de cette façon : les nœuds feuilles de l'index sont les nœuds de données. Les nœuds feuilles des index non clusterisés sont toujours des nœuds d'index, mais ont un pointeur pointant vers le bloc de données correspondant.
(4) Index clusterisé : le stockage physique est trié selon l'index ; index non clusterisé : le stockage physique n'est pas trié selon l'index ;
3.2.Pourquoi utiliser l'arbre B+ et pourquoi pas l'arbre binaire ordinaire ?
Vous pouvez examiner ce problème sous plusieurs dimensions, si la requête est suffisamment rapide, si l'efficacité est stable, combien de données sont stockées et le nombre de recherches sur le disque. Pourquoi n'est-ce pas un arbre binaire ordinaire, pourquoi l'est-il. pas un arbre binaire équilibré, pourquoi n'est-ce pas un arbre B, mais un arbre B+ ?
3.2.1. Pourquoi pas un arbre binaire ordinaire ?
Si l'arbre binaire est spécialisé dans une liste chaînée, cela équivaut à une analyse de table complète. Par rapport aux arbres de recherche binaires, les arbres binaires équilibrés ont une efficacité de recherche plus stable et une vitesse de recherche globale plus rapide.
3.2.2. Pourquoi pas un arbre binaire équilibré ?
Nous savons que l'interrogation des données en mémoire est beaucoup plus rapide que sur le disque. Si une structure de données telle qu'un arbre est utilisée comme index, alors chaque fois que nous recherchons des données, nous devons lire un nœud sur le disque, ce que nous appelons un bloc de disque, mais un arbre binaire équilibré ne stocke qu'une seule valeur clé. et des données par nœud. S'il s'agit d'un arbre B, plus de données de nœud peuvent être stockées et la hauteur de l'arborescence sera également réduite, donc le nombre de lectures sur le disque sera réduit et l'efficacité des requêtes sera plus rapide.
3.2.3. Pourquoi n'est-ce pas un arbre B mais un arbre B+ ?
L'arbre B+ ne stocke pas de données sur des nœuds non-feuilles, uniquement des valeurs clés, tandis que les nœuds B-tree stockent non seulement des valeurs clés, mais stockent également des données. La taille par défaut d'une page dans innodb est de 16 Ko. Si aucune donnée n'est stockée, davantage de valeurs clés seront stockées, l'ordre de l'arborescence correspondante (l'arborescence des nœuds enfants du nœud) sera plus grande et l'arborescence sera plus grande. plus court et plus gros, de cette façon, le nombre d'E/S disque dont nous avons besoin pour rechercher des données sera à nouveau réduit et l'efficacité de la requête de données sera plus rapide.
B+ Toutes les données de l'index de l'arborescence sont stockées dans des nœuds feuilles, et les données sont organisées dans l'ordre et liées à la liste chaînée. Ensuite, l'arborescence B+ rend la recherche par plage, la recherche par tri, la recherche de groupe et la recherche de déduplication extrêmement simples.
3.3. Quelle est la différence entre l'index Hash et l'index arborescent B+ ? Comment avez-vous choisi de concevoir l’indice ?
L'arbre B+ peut effectuer une requête de plage, l'index de hachage ne le peut pas.
L'arbre B+ prend en charge le principe le plus à gauche de l'index conjoint, l'index de hachage ne le prend pas en charge.
L'arbre B+ prend en charge l'ordre par tri, mais l'index de hachage ne le prend pas en charge.
L'index Hash est plus efficace que l'arbre B+ sur des requêtes équivalentes.
Arbre B+ Lors de l'utilisation de like pour une requête floue, les mots après like (comme commencer par %) peuvent jouer un rôle d'optimisation et l'index de hachage ne peut pas du tout effectuer de requête floue.
3.4. Quel est le principe du préfixe le plus à gauche ? Quel est le principe de correspondance le plus à gauche ?
Le principe du préfixe le plus à gauche signifie la priorité la plus à gauche. Lors de la création d'un index multi-colonnes, en fonction des besoins de l'entreprise, la colonne la plus fréquemment utilisée dans la clause Where doit être placée à l'extrême gauche.
Lorsque nous créons un index combiné, tel que (a1, a2, a3), cela équivaut à créer trois index (a1), (a1, a2) et (a1, a2, a3), qui correspond à la correspondance la plus à gauche dans principe.
3.5. Quels scénarios ne conviennent pas à l'indexation ?
Les objets contenant de petites quantités de données ne conviennent pas à l'indexation
-
Les champs avec des mises à jour fréquentes ne conviennent pas à l'indexation = Les champs avec une faible différenciation ne conviennent pas à l'indexation. (comme le genre)
3.6. Quels sont les avantages et les inconvénients des index ?
(1) Avantages :
Un index unique peut garantir le caractère unique de chaque ligne de données dans la table de base de données
L'index peut accélérer l'interrogation des données et réduire le temps d'interrogation
(2) Inconvénient :
Créer et maintenir des index prend du temps
Les index doivent occuper de l'espace physique en plus de l'espace de données occupé par la table de données, chaque index occupe également une certaine quantité d'espace physique
Incréments basés sur le. données dans le tableau Lors de la suppression ou de la modification, l'index doit également être maintenu dynamiquement.
4. Locks
4.1. Avez-vous déjà rencontré un problème de blocage dans MySQL ? Comment l'avez-vous résolu ?
Je l'ai rencontré. Mes étapes générales pour résoudre les blocages sont les suivantes :
(1) Vérifiez le journal des blocages et affichez l'état innodb du moteur ;
(2) Découvrez le blocage Sql
(3) Analysez la situation du verrouillage SQL
(4) Simulez le cas de blocage
(5) Analysez le blocage. Journal de verrouillage
(6) Analyse des résultats de blocage
4.2. Que sont les verrous optimistes et pessimistes dans la base de données et leurs différences ?
(1) Verrouillage pessimiste :
Le verrouillage pessimiste est déterminé et peu sûr. Son cœur n'appartient qu'à la transaction en cours, et elle craint toujours que ses données bien-aimées puissent être modifiées par d'autres transactions, donc une transaction Après avoir possédé ( obtenant) un verrou pessimiste, aucune autre transaction ne peut modifier les données et ne peut qu'attendre que le verrou soit libéré avant de l'exécuter.
(2) Verrouillage optimiste :
L'"optimisme" du verrouillage optimiste se reflète dans le fait qu'il estime que les données ne changeront pas trop fréquemment. Par conséquent, il permet à plusieurs transactions d’apporter des modifications aux données simultanément.
Méthode d'implémentation : le verrouillage optimiste est généralement implémenté à l'aide du mécanisme de numéro de version ou de l'algorithme CAS.
4.3. Connaissez-vous MVCC et connaissez-vous ses principes sous-jacents ?
MVCC (Multiversion Concurrency Control), c'est-à-dire une technologie de contrôle de concurrence multi-version.
L'implémentation de MVCC dans MySQL InnoDB vise principalement à améliorer les performances de concurrence des bases de données et à utiliser une meilleure façon de gérer les conflits de lecture-écriture, de sorte que même en cas de conflits de lecture-écriture, aucune lecture simultanée verrouillable et non bloquante ne puisse être obtenue. .
5. Transactions
5.1. Les quatre principales caractéristiques et principes de mise en œuvre des transactions MySQL
Atomicité : La transaction est exécutée dans son ensemble, et toutes les opérations sur la base de données qu'elle contient sont soit exécutées, soit aucune.
Cohérence : signifie que les données ne seront pas détruites avant le début de la transaction et après la fin de la transaction. Si le compte A transfère 10 yuans vers le compte B, le montant total de A et B restera inchangé quel que soit le succès ou l'échec.
Isolement : lorsque plusieurs transactions accèdent simultanément, les transactions sont isolées les unes des autres, c'est-à-dire qu'une transaction n'affecte pas les effets en cours des autres transactions. Bref, cela signifie qu’il n’y a pas de conflit entre les affaires.
Persistance : Indique qu'une fois la transaction terminée, les modifications opérationnelles apportées par la transaction à la base de données seront définitivement enregistrées dans la base de données.
5.2. Quels sont les niveaux d'isolement des transactions ? Quel est le niveau d'isolement par défaut de MySQL ?
Lecture non validée
Lecture validée
Lecture répétable
Sérialisable
Le niveau d'isolement des transactions est en lecture répétable
5.3. lectures, lectures sales et non -des lectures répétables ?
Les transactions A et B sont exécutées alternativement. La transaction A est interférée par la transaction B car la transaction A lit les données non validées de la transaction B. Il s'agit d'une lecture sale.
Dans le cadre d'une transaction, deux requêtes identiques lisent le même enregistrement mais renvoient des données différentes. Il s'agit d'une lecture non répétable.
La transaction A interroge l'ensemble de résultats d'une plage, et une autre transaction simultanée B insère/supprime des données dans cette plage et les valide silencieusement. Ensuite, la transaction A interroge à nouveau la même plage, et les ensembles de résultats obtenus par les deux lectures sont différents. Pareil, c'est une lecture fantôme.
6. Combat pratique
6.1. Si le processeur de la base de données MySQL augmente, comment y faire face ?
Processus de dépannage :
(1) Utilisez la commande top pour observer et déterminer si cela est causé par mysqld ou d'autres raisons.
(2) Si cela est causé par mysqld, affichez la liste des processus, vérifiez l'état de la session et déterminez si du SQL consommateur de ressources est en cours d'exécution.
(3) Découvrez le SQL à forte consommation et voyez si le plan d'exécution est précis, si l'index est manquant et si la quantité de données est trop importante.
Traitement :
(1) Tuez ces threads (et observez si l'utilisation du processeur diminue)
(2) Effectuez les ajustements correspondants (tels que l'ajout d'index, la modification de SQL, la modification des paramètres de mémoire)
(3) Redémarrez, exécutez-les SQL.
Autres situations :
Il est également possible que chaque instruction SQL ne consomme pas beaucoup de ressources, mais du coup, un grand nombre de connexions de session arrivent, provoquant une surtension du CPU. Dans ce cas, vous devez analyser avec l'application. pourquoi le nombre de connexions augmente. Ensuite, effectuez les ajustements correspondants, comme limiter le nombre de connexions, etc.
6.2 Comment résoudre le délai maître-esclave de MYSQL ?
La réplication maître-esclave s'effectue en cinq étapes : (images d'Internet)
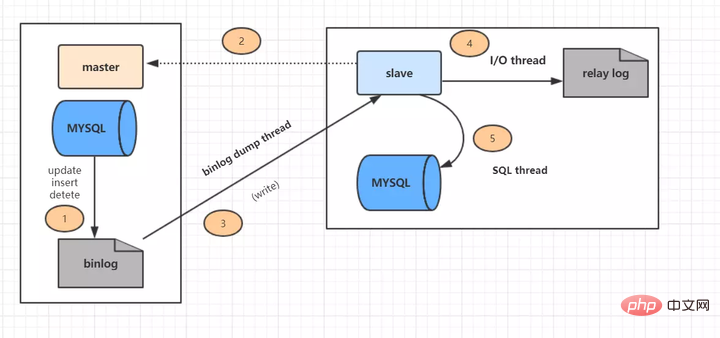
Étape 1 : Les événements de mise à jour (mise à jour, insertion, suppression) de la bibliothèque principale sont écrits dans le binlog
Étape 2 : Initiez une connexion de la bibliothèque esclave à la bibliothèque principale.
Étape 3 : À ce stade, la bibliothèque principale crée un thread de vidage du journal binaire et envoie le contenu du journal binaire à la bibliothèque esclave.
Étape 4 : Après avoir démarré à partir de la bibliothèque, créez un thread d'E/S, lisez le contenu du binlog transmis depuis la bibliothèque principale et écrivez-le dans le journal du relais
Étape 5 : Créez un thread SQL à partir du relais Lire le contenu dans le journal, exécutez l'événement de mise à jour de lecture à partir de la position Exec_Master_Log_Pos et écrivez le contenu mis à jour dans la base de données esclave
La raison du retard de synchronisation maître-esclave
Un serveur ouvre N liens pour que les clients se connectent, il y aura donc de grandes opérations de mise à jour simultanées, mais il n'y a qu'un seul thread pour lire le binlog du serveur Lorsqu'un certain SQL est exécuté sur le serveur esclave, cela prend un peu plus de temps. Cela peut prendre du temps ou parce qu'un certain SQL doit verrouiller la table, ce qui entraîne un retard important de SQL sur le serveur maître et une non-synchronisation avec le serveur esclave. Cela conduit à une incohérence maître-esclave, c'est-à-dire un retard maître-esclave.
Solution au délai de synchronisation maître-esclave
Le serveur maître est responsable de l'opération de mise à jour et a des exigences de sécurité plus élevées que le serveur esclave, donc certains paramètres de configuration peuvent être modifiés, tels que sync_binlog=1, innodb_flush_log_at_trx_commit = 1 et ainsi de suite, paramètres, etc.
Choisissez un meilleur périphérique matériel en tant qu'esclave.
Utilisez un serveur esclave comme sauvegarde sans fournir de requêtes. La charge de ce côté est réduite et l'efficacité de l'exécution du SQL dans le journal du relais est naturellement plus élevée.
Le but de l'ajout de serveurs esclaves est de disperser la pression de lecture et ainsi de réduire la charge du serveur.
6.3. Si on vous demandait de concevoir des sous-bases de données et des sous-tableaux, dites-moi brièvement ce que vous feriez ?
Sous-base de données et schéma de table :
Sous-base de données horizontale : Divisez les données d'une base de données en plusieurs bases de données basées sur des champs et selon certaines stratégies (hachage, plage, etc.).
Répartition horizontale des tables : divisez les données d'une table en plusieurs tables en fonction des champs et selon certaines stratégies (hachage, plage, etc.).
Sous-base de données verticale : sur la base de tables, différentes tables sont divisées en différentes bases de données en fonction des différentes propriétés de l'entreprise.
Répartition verticale du tableau : En fonction des champs et selon l'activité des champs, les champs du tableau sont répartis en différentes tables (table principale et table étendue).
Middleware sharding-jdbc couramment utilisé :
sharding-jdbc
Mycat
Problèmes que vous pouvez rencontrer avec le sharding
-
Question de transaction : obligatoire Utiliser les transactions distribuées
Le problème de la jointure entre nœuds : pour résoudre ce problème, il peut être implémenté en deux requêtes
Le problème du nombre de nœuds croisés, de l'ordre par, du groupe par et de la fonction d'agrégation : obtenez respectivement sur chaque nœud Les résultats sont ensuite fusionnés côté application.
Migration des données, planification de la capacité, expansion et autres problèmes
-
Problème d'ID : une fois la base de données divisée, vous ne pouvez plus compter sur le mécanisme de génération de clé primaire de la base de données elle-même. Le moyen le plus simple de considérer l'UUID
. est un problème de pagination de tri à travers les fragments
Apprentissage recommandé : Tutoriel d'apprentissage MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat lui-même ne stocke pas le mot de passe de la base de données et ne peut récupérer que le mot de passe chiffré. Solution: 1. Vérifiez le gestionnaire de mots de passe; 2. Vérifiez la fonction "Remember Motway" de Navicat; 3. Réinitialisez le mot de passe de la base de données; 4. Contactez l'administrateur de la base de données.
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
NAVICAT pour MARIADB ne peut pas afficher directement le mot de passe de la base de données car le mot de passe est stocké sous forme cryptée. Pour garantir la sécurité de la base de données, il existe trois façons de réinitialiser votre mot de passe: réinitialisez votre mot de passe via Navicat et définissez un mot de passe complexe. Affichez le fichier de configuration (non recommandé, haut risque). Utilisez des outils de ligne de commande système (non recommandés, vous devez être compétent dans les outils de ligne de commande).
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Étapes pour effectuer SQL dans NAVICAT: Connectez-vous à la base de données. Créez une fenêtre d'éditeur SQL. Écrivez des requêtes ou des scripts SQL. Cliquez sur le bouton Exécuter pour exécuter une requête ou un script. Affichez les résultats (si la requête est exécutée).
