
 base de données
Redis
Compréhension approfondie des solutions de cluster Redis (mode maître-esclave, mode sentinelle, mode Redis Cluster)
base de données
Redis
Compréhension approfondie des solutions de cluster Redis (mode maître-esclave, mode sentinelle, mode Redis Cluster)
Compréhension approfondie des solutions de cluster Redis (mode maître-esclave, mode sentinelle, mode Redis Cluster)

Cet article vous apporte des connaissances pertinentes sur Redis, qui présente principalement les problèmes liés au mode maître-esclave, au mode sentinelle et au mode Redis Cluster. J'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel Redis
Introduction à la solution cluster Redis (mode maître-esclave, mode sentinelle, mode Cluster Redis)
1. Mode maître-esclave
L'existence principale du stockage complet des données dans. un seul redis Deux problèmes :
Sauvegarde des données et dégradation des performances causées par un volume de données important.
Le mode maître-esclave de Redis apporte une meilleure solution à ces deux problèmes. Le mode maître-esclave fait référence à l'utilisation d'une instance Redis comme hôte et des instances restantes comme machines de sauvegarde.
Les données de l'hôte et de l'esclave sont totalement cohérentes. L'hôte prend en charge diverses opérations telles que l'écriture et la lecture des données, tandis que l'esclave ne prend en charge que la synchronisation et la lecture des données avec l'hôte. En d'autres termes, le client peut écrire des données sur l'hôte. , et l'hôte synchronise automatiquement l'opération d'écriture des données avec l'esclave.
Le mode maître-esclave résout très bien le problème de sauvegarde des données, et comme les données du service maître-esclave sont presque cohérentes, les commandes d'écriture de données peuvent être envoyées à l'hôte pour exécution, tandis que les commandes de lecture de données peuvent être envoyées à différents esclaves. pour l'exécution, atteignant ainsi l'objectif de séparation de la lecture et de l'écriture.
Comment fonctionne la réplication maître-esclave :
Une fois que le service de nœud esclave esclave démarre et se connecte au maître, il enverra activement une commande SYNC. Après avoir reçu la commande de synchronisation, le nœud maître du service maître démarrera le processus de sauvegarde en arrière-plan et collectera toutes les commandes reçues pour modifier l'ensemble de données. Une fois le processus en arrière-plan terminé, le maître transférera l'intégralité du fichier de base de données à l'esclave pour terminer une opération complète. synchronisation. Le service de nœud esclave esclave enregistre et charge les données du fichier de base de données en mémoire après les avoir reçues. Après cela, le nœud maître continue de transmettre toutes les commandes de modification collectées et les nouvelles commandes de modification aux esclaves en séquence. Les esclaves exécuteront cette fois ces commandes de modification de données pour réaliser la synchronisation finale des données.
Si le lien entre le maître et l'esclave est déconnecté, l'esclave peut se reconnecter automatiquement au maître. Une fois la connexion réussie, une synchronisation complète sera automatiquement effectuée. 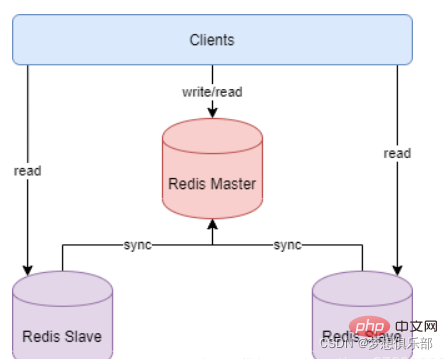
Déploiement :
version redis :6.0.9
1 Copiez 4 copies des fichiers de configuration Redis
nommez-les master.conf slave1.conf slave2.conf slave3.conf
2. les fichiers de configuration Configuration simple
Le fichier de configuration du nœud maître ne nécessite généralement pas de paramètres particuliers. Le port par défaut est 6379
Paramètre de port du nœud Slave1 6380, puis configurez une ligne de réplique de 127.0.0.1 6379
Paramètre de port du nœud Slave2 6381, et puis configurez une ligne de réplique de 127.0.0.1 6379
Port du nœud Slave3 Définissez 6382 et configurez une ligne de réplique de 127.0.0.1 6379
3 Ouvrez respectivement le nœud maître et 3 nœuds esclaves
redis-server master.conf
redis-. server slave1.conf
redis-server slave2.conf
redis-server slave3 .conf
4 Vérifiez l'état maître-esclave du cluster
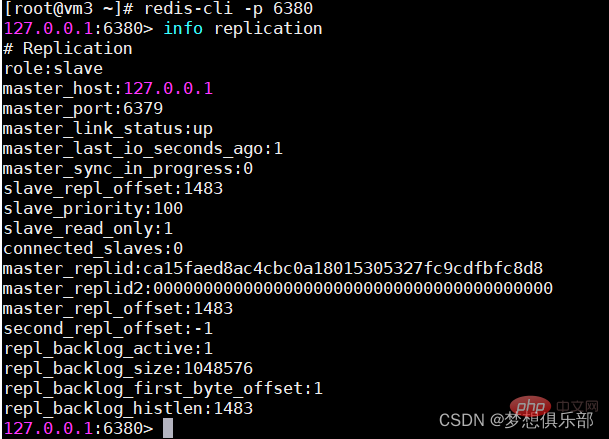
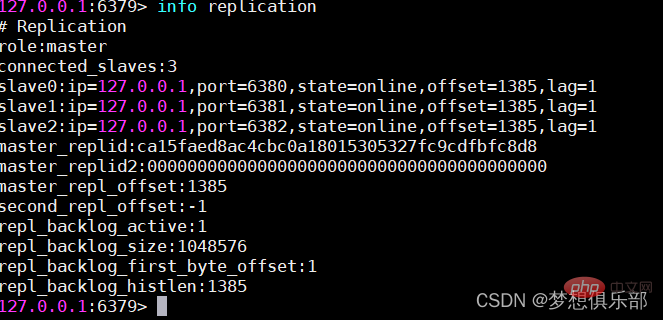
Avantages et inconvénients du mode maître-esclave :
1. Avantages :
Le même maître peut synchroniser plusieurs esclaves.
Le maître peut synchroniser automatiquement les données avec l'esclave, et peut séparer la lecture et l'écriture pour partager la pression de lecture du maître.
La synchronisation entre le maître et l'esclave s'effectue de manière non bloquante. le client peut toujours soumettre des requêtes ou des demandes de mise à jour.
2. Inconvénients :
n'a pas de fonctions automatiques de tolérance aux pannes et de récupération. Le temps d'arrêt du maître ou de l'esclave peut entraîner l'échec de la demande du client. ou changez manuellement l'IP du client pour récupérer
Le maître est en panne avant. Si les données ne sont pas synchronisées, il y aura des problèmes d'incohérence des données après le changement d'IP. Il est difficile de prendre en charge l'expansion en ligne. par configuration sur une seule machine. En fait, le mode maître-esclave de redis est très simple et est rarement utilisé dans les environnements de production réels. Il est recommandé d'utiliser le mode maître-esclave dans les environnements de production réels pour assurer une haute disponibilité du système. La raison pour laquelle il n'est pas recommandé est due à ses inconvénients. Dans les situations où la quantité de données est très importante ou où la haute disponibilité du système est requise. Dans ce cas, le mode maître-esclave est également instable. Bien que ce modèle soit très simple, ce modèle constitue la base d'autres modèles, donc comprendre ce modèle sera très utile pour apprendre d'autres modèles.
2. Mode Sentinel (Sentinel)
Sentinel, comme son nom l'indique, est là pour monter la garde du cluster Redis une fois qu'un problème est découvert, il peut réagir en conséquence. Ses fonctions incluent
Contrôler si le maître et l'esclave fonctionnent normalement Lorsque le maître tombe en panne, il peut automatiquement convertir un esclave en maître (si le frère aîné meurt, choisissez un frère plus jeune pour prendre le relais)
Plusieurs sentinelles peuvent surveiller la même chose Redis, et les sentinelles peuvent également surveiller automatiquement
Après avoir découvert automatiquement l'esclave et les autres nœuds sentinelles, la sentinelle peut régulièrement surveiller si ces bases de données et nœuds ont arrêté les services en envoyant régulièrement des commandes PING.
Si la base de données PING ou le nœud expire (configuré via sentinel down-after-milliseconds master-name millisecondes) et ne répond pas, Sentinel le considère comme étant subjectivement hors ligne (sdown, s signifie subjectivement - subjectivement). Si le maître est hors ligne, la sentinelle enverra une commande aux autres sentinelles pour leur demander si elles pensent également que le maître est subjectivement hors ligne. Si un certain nombre (c'est-à-dire le quorum dans le fichier de configuration) de votes est atteint, le maître est hors ligne. sentinel considérera que le maître a été objectivement hors ligne (odown , o est Objectivement - objectivement) et élit le nœud sentinelle principal pour lancer la reprise après panne du système maître-esclave. S'il n'y a pas suffisamment de processus sentinelles pour accepter l'état hors ligne du maître, l'état hors ligne objectif du maître sera supprimé. Si le maître renvoie une réponse valide à la commande PING envoyée à nouveau au processus sentinelle, l'état hors ligne subjectif du maître sera supprimé. .
La sentinelle estime qu'une fois que le maître est objectivement hors ligne, l'opération de récupération des pannes doit être effectuée par la sentinelle leader élue.
Une fois le leader sélectionné, le leader commence à effectuer une récupération des pannes sur le système et en sélectionne une dans la base de données. du maître défaillant. Pour élire un nouveau maître,
Après avoir sélectionné l'esclave qui doit être remplacé, la sentinelle principale envoie une commande à la base de données pour la mettre à niveau en maître, puis envoie des commandes aux autres esclaves pour accepter le nouveau maître, et enfin met à jour les données. Mettez à jour l'ancien maître arrêté vers la base de données d'esclaves du nouveau maître, afin qu'il puisse continuer à fonctionner en tant qu'esclave après la restauration du service. 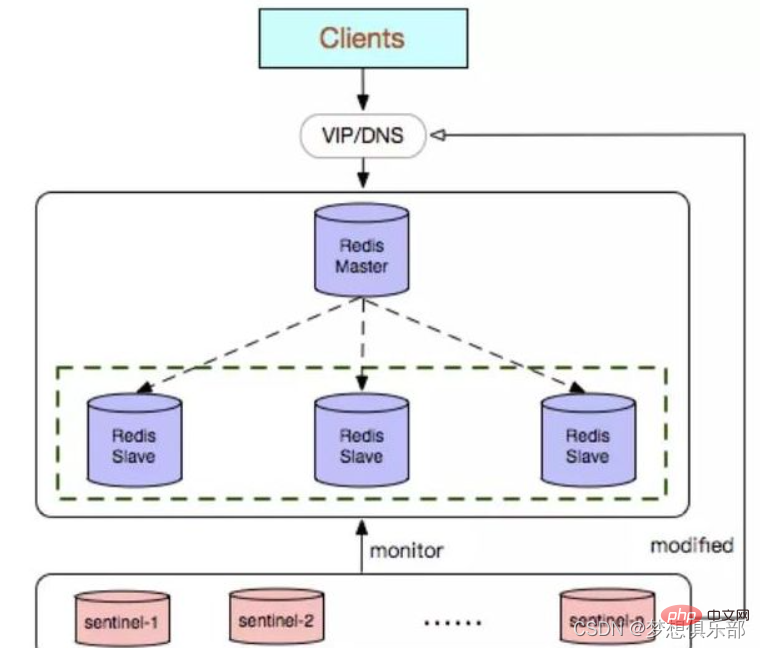
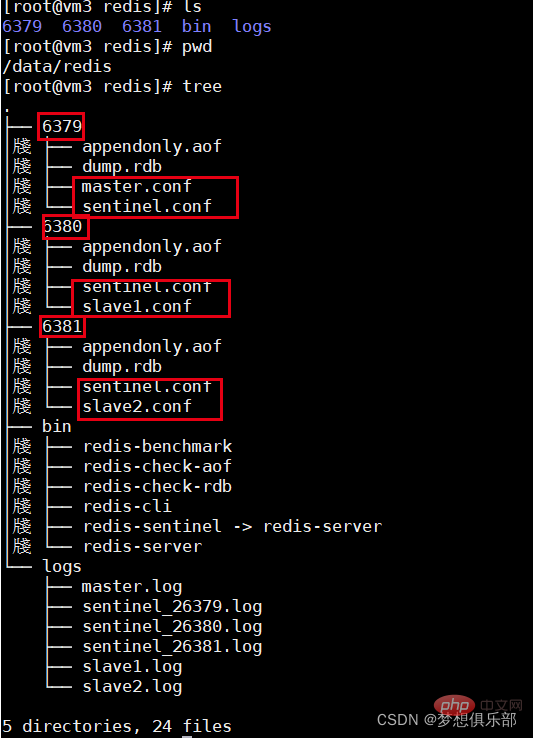
Le mode Sentinelle est basé sur le mode de réplication maître-esclave précédent. Le fichier de configuration de sentinel est sentinel.conf Ajoutez la configuration suivante dans le répertoire correspondant Attention à ne pas entrer en conflit de ports :
port 26379 protected-mode no daemonize yes pidfile "/var/run/redis-sentinel-26379.pid" logfile "/data/redis/logs/sentinel_26379.log" dir "/data/redis/6379" sentinel monitor mymaster 127.0.0.1 6379 2 ##指定主机IP地址和端口,并且指定当有2台哨兵认为主机挂了,则对主机进行容灾切换 #sentinel auth-pass mymaster pwdtest@2019 ##当在Redis实例中开启了requirepass,这里就需要提供密码 sentinel down-after-milliseconds mymaster 3000 ##这里设置了主机多少秒无响应,则认为挂了 sentinel failover-timeout mymaster 180000 ##故障转移的超时时间,这里设置为三分钟
Le format est le suivant :
Afficher l'état de sentinel : 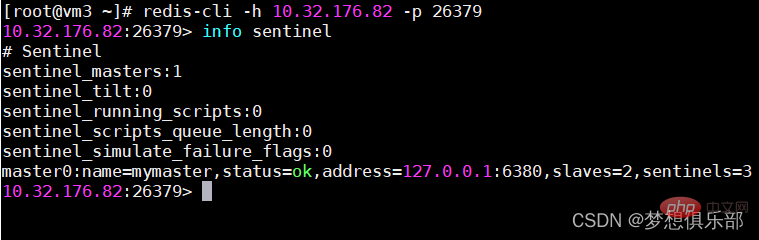
. 3. mode cluster redis (Cluster)
Le cluster adopte une structure sans centre, et ses fonctionnalités sont les suivantes :
Le client est directement connecté au nœud redis Le client n'a pas besoin de se connecter à tous les nœuds du cluster. , connectez-vous simplement à n'importe quel nœud disponible dans le cluster
Le mécanisme de fonctionnement spécifique du mode Cluster :
Sur chaque nœud de Redis, il y a un slot avec une plage de valeurs de 0 à 16383, soit un total de 16384 slots
Lorsque nous accédons au clé, Redis obtiendra un résultat basé sur l'algorithme CRC16, puis calculera le reste du résultat à 16384, de sorte que chaque clé correspondra à un emplacement de hachage numéroté entre 0 et 16383. Grâce à cette valeur, trouvez le nœud correspondant au. emplacement correspondant, puis passez automatiquement à cet emplacement. Les opérations d'accès sont effectuées sur le nœud correspondant.
Afin de garantir une haute disponibilité, le mode Cluster introduit également le mode de réplication maître-esclave. Un nœud maître correspond à un ou plusieurs nœuds esclaves. Lorsque le nœud maître tombe en panne, les nœuds esclaves seront activés.
Lorsque d'autres nœuds maîtres envoient une requête ping à un nœud maître A, si plus de la moitié des nœuds maîtres communiquent avec A expirent, alors le nœud maître A est considéré comme étant en panne. Si le nœud maître A et ses nœuds esclaves sont en panne, le cluster ne peut plus fournir de services.
Le cluster Redis doit s'assurer que les nœuds correspondant aux 16384 emplacements fonctionnent normalement. Si un nœud tombe en panne, les emplacements dont il est responsable deviendront également invalides et l'ensemble du cluster ne fonctionnera pas.
Afin d'augmenter l'accessibilité du cluster, la solution officiellement recommandée est de configurer le nœud dans une structure maître-esclave, c'est-à-dire un nœud maître et n nœuds esclaves. À ce stade, si le nœud maître échoue, Redis Cluster sélectionnera l'un des nœuds esclaves à promouvoir au rang de nœud maître en fonction de l'algorithme d'élection. L'ensemble du cluster continuera à fournir des services au monde extérieur. tolérance aux pannes.
La configuration minimale des nœuds de cluster en mode Cluster est de 6 nœuds (selon le mécanisme d'élection du cluster et la mise en œuvre de la sauvegarde maître-esclave, redis nécessite au moins trois maîtres et trois esclaves au total pour former un cluster redis, car au moins la moitié parmi eux sont nécessaires pour déterminer si un nœud est en panne et nécessite une sauvegarde maître-esclave), le nœud maître fournit des opérations de lecture et d'écriture, et le nœud esclave sert de nœud de sauvegarde, ne fournit pas de requêtes et n'est utilisé que pour le basculement. .
Déploiement du cluster de cluster
Selon le mécanisme d'élection du cluster et la mise en œuvre de la sauvegarde maître-esclave, redis nécessite au moins trois maîtres et trois esclaves au total pour former un cluster redis. L'environnement de test peut démarrer 6 nœuds redis sur une machine physique. , mais en production L'environnement doit préparer au moins 2 à 3 machines physiques. (Trois machines virtuelles sont utilisées ici)
Le mode Cluster est basé sur le mode Sentinel. Lorsqu'il y a tellement de données qui nécessitent une expansion dynamique, les deux premières ne fonctionneront pas selon certaines règles. à plusieurs machines. 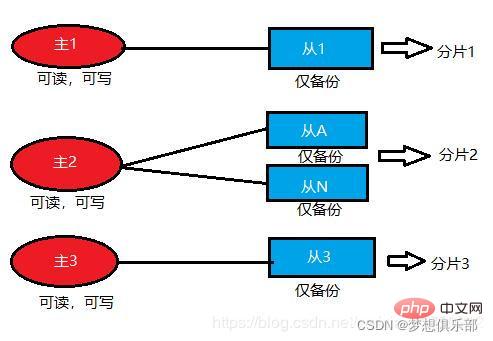
该模式就支持动态扩容,可以在线增加或删除节点,而且客户端可以连接任何一个主节点进行读写,不过此时的从节点仅仅只是备份的作用。至于为何能做到动态扩容,主要是因为Redis集群没有使用一致性hash,而是使用的哈希槽。Redis集群会有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,而集群的每个节点负责一部分hash槽。
那么这样就很容易添加或者删除节点, 比如如果我想新添加个新节点, 我只需要从已有的节点中的部分槽到过来;如果我想移除某个节点,就只需要将该节点的槽移到其它节点上,然后将没有任何槽的A节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
需要注意的是,该模式下不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上,并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为。
搭建集群
这里就直接搭建较为复杂的Cluster模式集群,也是企业级开发过程中使用最多的。
1.建redis各节点目录
最终目录结构如下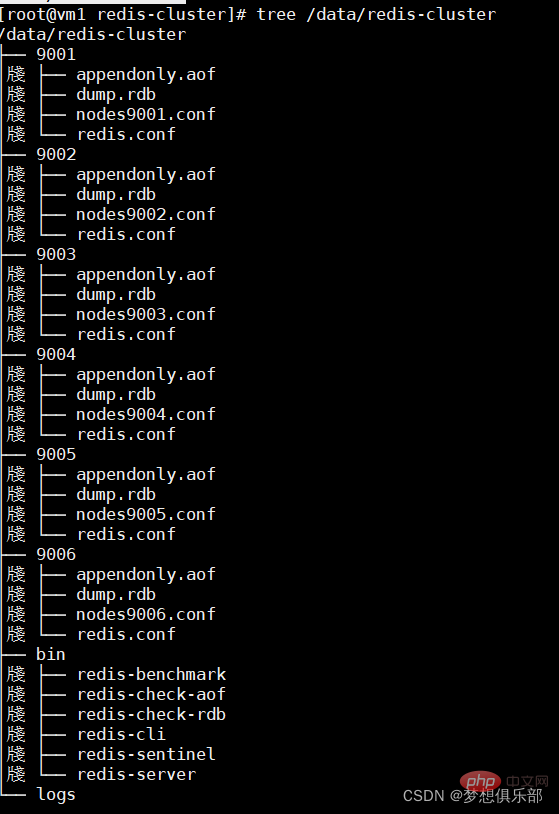
2.逐个修改redis配置
以 9001 的为例子,其余五个类似。
编辑 /data/redis-cluster/9001/redis.conf
redis.conf修改如下:
port 9001(每个节点的端口号) daemonize yes appendonly yes //开启aof bind 0.0.0.0(绑定当前机器 IP) dir "/data/redis-cluster/9001"(数据文件存放位置,,自己加到最后一行 快捷键 shift+g) pidfile /var/run/redis_9001.pid(pid 9001和port要对应) logfile "/data/redis-cluster/logs/9001.log" cluster-enabled yes(启动集群模式) cluster-config-file nodes9001.conf(9001和port要对应) cluster-node-timeout 15000
3.逐个启动redis节点
/data/redis-cluster/bin/redis-server /data/redis-cluster/9001/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9002/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9003/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9004/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9005/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9006/redis.conf
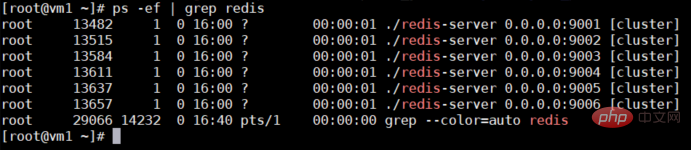
现在检查一下是否成功开启,如下图所示,都开启成功。
ps -el | grep redis
4.集群配置
此时的节点虽然都启动成功了,但他们还不在一个集群里面,不能互相发现,测试会报错:(error) CLUSTERDOWN Hash slot not served。
如下图所示

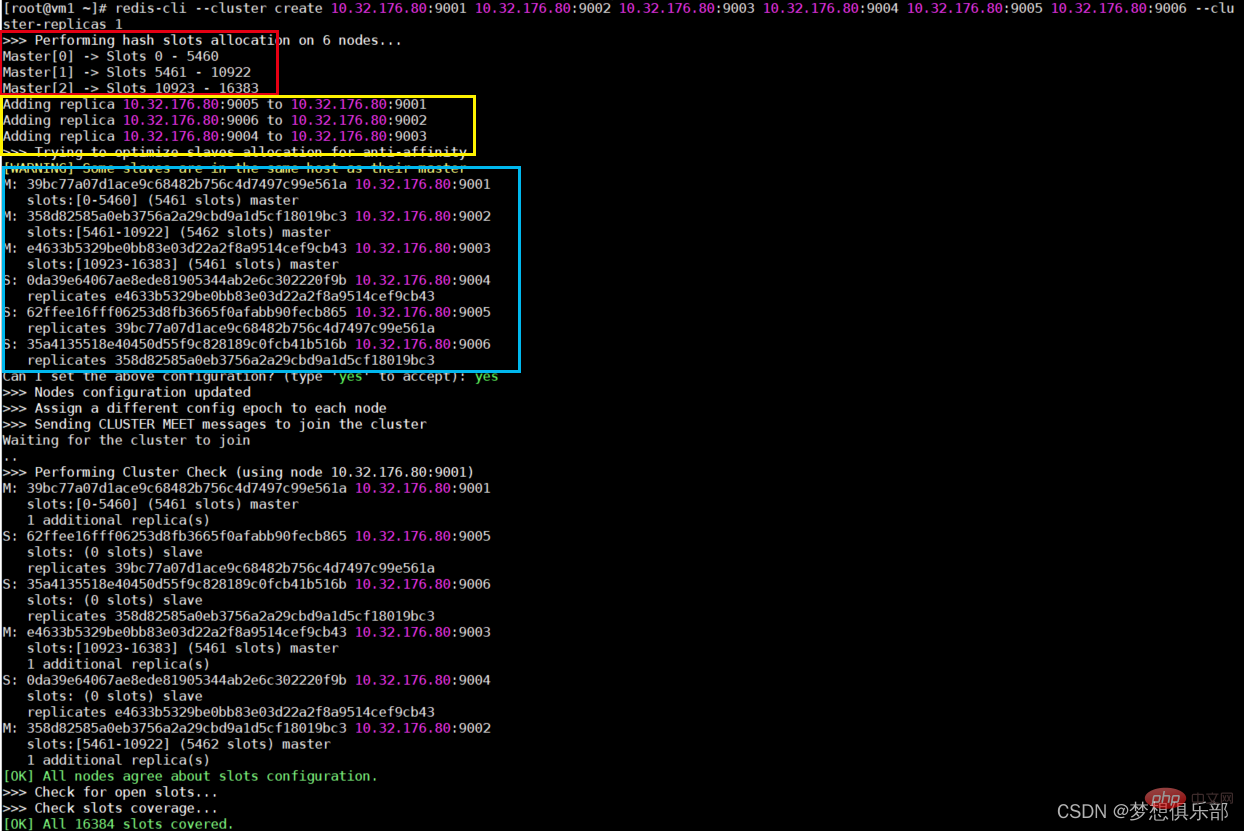
redis-cli --cluster create 10.32.176.80:9001 10.32.176.80:9002 10.32.176.80:9003 10.32.176.80:9004 10.32.176.80:9005 10.32.176.80:9006 --cluster-replicas 1
–cluster-replicas 1 这个指的是从机的数量,表示我们希望为集群中的每个主节点创建一个从节点。
红色选框是给三个主节点分配的共16384个槽点。
黄色选框是主从节点的分配情况。
蓝色选框是各个节点的详情。
5.测试
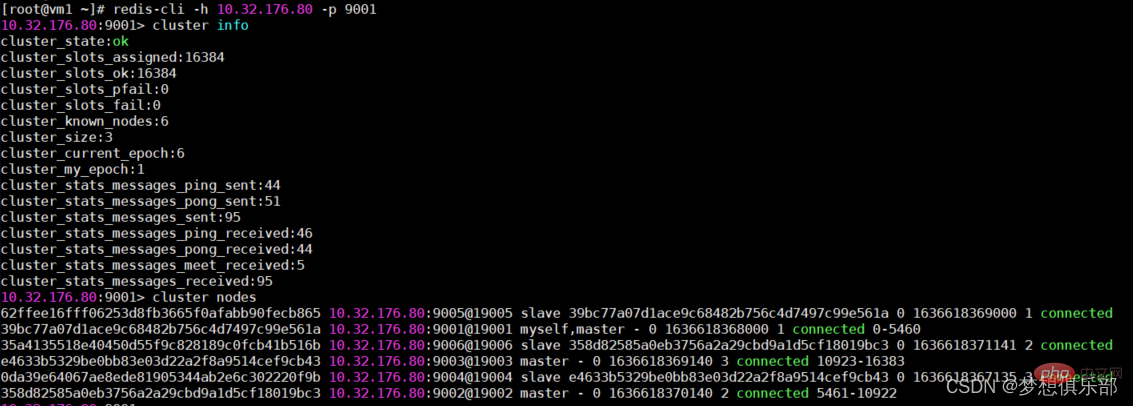
现在通过客户端命令连接上,通过集群命令看一下状态和节点信息等
/data/redis-cluster/bin/redis-cli -c -h 10.32.176.80 -p 9001 cluster info cluster nodes
效果图如下,集群搭建成功。
现在往9001这个主节点写入一条信息,我们可以在9002这个主节点取到信息,集群间各个节点可以通信。
6.故障转移
故障转移机制详解
集群中的节点会向其它节点发送PING消息(该PING消息会带着当前集群和节点的信息),如果在规定时间内,没有收到对应的PONG消息,就把此节点标记为疑似下线。当被分配了slot槽位的主节点中有超过一半的节点都认为此节点疑似下线(就是其它节点以更高的频次,更频繁的与该节点PING-PONG),那么该节点就真的下线。其它节点收到某节点已经下线的广播后,把自己内部的集群维护信息也修改为该节点已事实下线。
节点资格审查:然后对从节点进行资格审查,每个从节点检查最后与主节点的断线时间,如果该值超过配置文件的设置,那么取消该从节点的资格。准备选举时间:这里使用了延迟触发机制,主要是给那些延迟低的更高的优先级,延迟低的让它提前参与被选举,延迟高的让它靠后参与被选举。(延迟的高低是依据之前与主节点的最后断线时间确定的)
Vote d'élection : lorsque le nœud esclave obtient la qualification électorale, il lancera une demande d'élection aux autres nœuds maîtres dotés d'emplacements, et ils voteront. Plus la priorité du nœud esclave est élevée, plus il est susceptible de devenir le nœud maître. le nœud esclave Lorsque le nombre de votes obtenus atteint une certaine valeur (par exemple, s'il y a N nœuds maîtres dans le cluster, alors tant qu'un nœud esclave obtient N/2+1 votes, il est considéré comme le gagnant), il sera remplacé en tant que nœud maître.
Remplacer le nœud maître : le nœud esclave élu exécutera slaveof no one pour changer son statut d'esclave à maître, puis exécutera l'opération clusterDelSlot pour annuler les emplacements responsables du nœud maître défaillant, et exécutera clusterAddSlot pour s'attribuer ces emplacements , puis diffusez son propre message pong au cluster pour informer tous les nœuds du cluster que le nœud esclave actuel est devenu le nœud maître.
Reprise des opérations associées : le nouveau nœud maître reprend les informations d'emplacement du nœud maître précédemment défaillant, reçoit et traite les demandes de commandes liées à son propre emplacement.
Test de basculement
Il s'agit de la situation de nœuds spécifiques dans le cluster précédent. Je l'ai simplifié comme suit. Vous pouvez revenir sur les informations du cluster dans l'image.
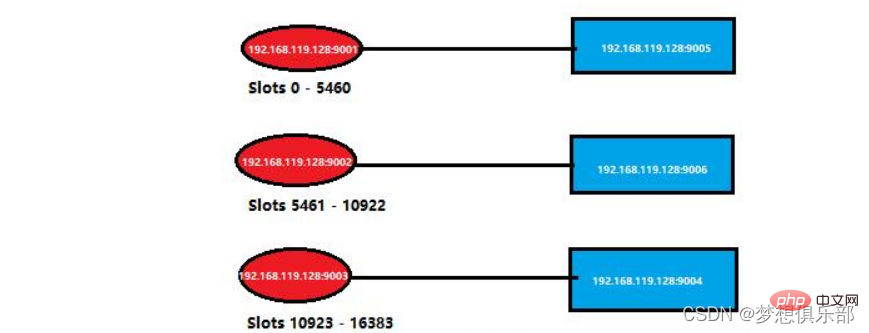
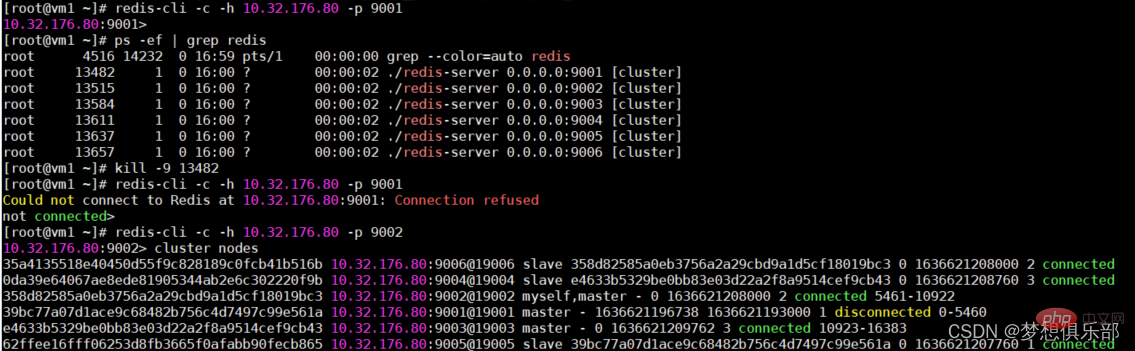
Fermez ici le processus du port 9001, qui consiste à simuler que le nœud maître raccroche.
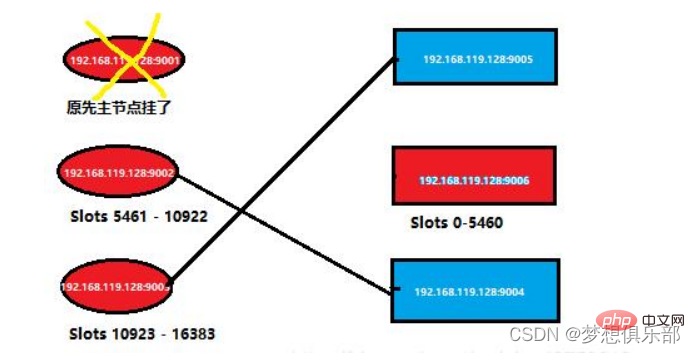
Si vous vous connectez au nœud Redis mort, le service vous sera refusé. Entrez via un nœud maître qui fonctionne toujours normalement, puis vérifiez à nouveau les informations dans le cluster
En bref, les informations du cluster précédent. devient Comme indiqué ci-dessous

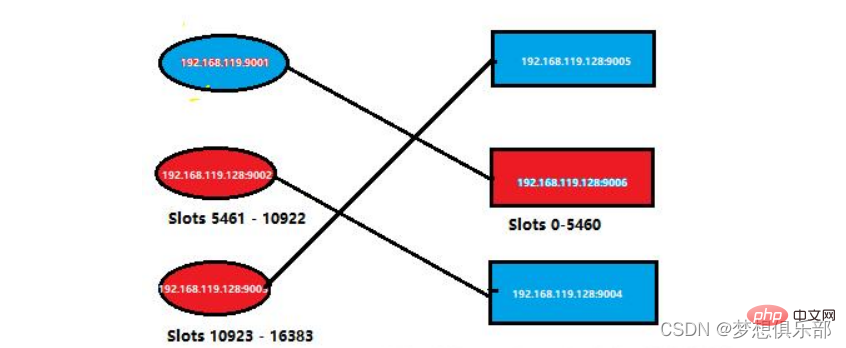
Maintenant, je redémarre le nœud maître qui vient de raccrocher et revérifie la situation du nœud à l'intérieur du cluster. La situation spécifique est celle indiquée dans la figure ci-dessous

En bref. , maintenant dans le cluster La situation des nœuds est la suivante
Apprentissage recommandé :Tutoriel Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Sur CentOS Systems, vous pouvez limiter le temps d'exécution des scripts LUA en modifiant les fichiers de configuration Redis ou en utilisant des commandes Redis pour empêcher les scripts malveillants de consommer trop de ressources. Méthode 1: Modifiez le fichier de configuration Redis et localisez le fichier de configuration Redis: le fichier de configuration redis est généralement situé dans /etc/redis/redis.conf. Edit Fichier de configuration: Ouvrez le fichier de configuration à l'aide d'un éditeur de texte (tel que VI ou NANO): Sudovi / etc / redis / redis.conf Définissez le délai d'exécution du script LUA: Ajouter ou modifier les lignes suivantes dans le fichier de configuration pour définir le temps d'exécution maximal du script LUA (unité: millisecondes)
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
