
 base de données
tutoriel mysql
Quelle est la méthode d'implémentation de la séparation en lecture et en écriture MySQL ?
base de données
tutoriel mysql
Quelle est la méthode d'implémentation de la séparation en lecture et en écriture MySQL ?
Quelle est la méthode d'implémentation de la séparation en lecture et en écriture MySQL ?

Dans MySQL, vous pouvez utiliser « mysql-proxy » pour réaliser la séparation en lecture-écriture ; « mysql-proxy » est un logiciel officiellement fourni par MySQL pour réaliser la séparation en lecture-écriture, également appelée middleware, qui permet à la base de données principale de gérer opérations d'écriture. Lors du traitement des requêtes de la base de données, la cohérence de la base de données est obtenue grâce à la réplication maître-esclave.

L'environnement d'exploitation de ce tutoriel : système windows10, version mysql8.0.22, ordinateur Dell G3.
Quelle est la méthode d'implémentation de la séparation en lecture et en écriture de MySQL ?
Les plug-ins dans Mysql qui peuvent réaliser la séparation en lecture et en écriture incluent mysql-proxy / Mycat / Amoeba est un plug-in fourni avec le. système. Cette expérience est principalement utilisée pour y parvenir. Read/Write Splitting
mysql-proxy est un logiciel qui implémente le "Read/Write Splitting" (officiellement fourni par MySQL, également appelé middleware). la base de données gère les opérations d'écriture (insertion, mise à jour, suppression), tout en traitant l'opération de requête (sélection) à partir de la base de données. La cohérence de la base de données est obtenue grâce à la réplication maître-esclave
Le proxy MySQL peut réaliser la distinction entre les instructions de lecture et d'écriture en s'appuyant principalement sur un script Lua interne (qui peut réaliser le jugement des instructions de lecture et d'écriture)
Si c'est le cas uniquement sur le serveur principal (écriture L'opération d'écriture des données est terminée sur le serveur). À ce stade, l'opération d'écriture n'est pas effectuée sur le serveur esclave et il n'y a pas de données à ce moment-là, une autre technologie doit être utilisée pour. assurer la cohérence des données entre les serveurs maître et esclave. Cette technologie est appelée technologie de réplication maître-esclave. Par conséquent, la réplication maître-esclave est la base de la séparation lecture-écriture (MySQL-Proxy) signifie que le maître. gère l'opération d'écriture et l'esclave gère l'opération de lecture. Il est très approprié pour les scénarios où le nombre d'opérations de lecture est relativement important et peut réduire la charge de travail du maître
Utilisez mysql-proxy pour réaliser la lecture-écriture. séparation de mysql. mysql-proxy agit en fait comme un proxy pour le serveur maître-esclave mysql back-end. Il accepte directement la demande du client, analyse l'instruction SQL et détermine s'il s'agit d'une opération de lecture ou d'une opération d'écriture. est ensuite distribué au serveur mysql correspondant
Parce que l'opération d'écriture de la base de données prend plus de temps que l'opération de lecture, la séparation de la lecture et de l'écriture de la base de données résout le problème de l'écriture dans la base de données, ce qui affecte l'efficacité de la requête
Dans le serveur1, configurez d'abord la réplication maître-esclave gtid avec le serveur2
la réplication maître-esclave gtid a été expliquée dans le blog précédent, donc je n'entrerai pas dans les détails ici, je montrerai seulement l'effet final
Vous pouvez voir que une base de données westos est établie sur le serveur1, et le serveur2 correspondant sera synchronisé  Configurer le proxy serveur3 (mysql-proxy)
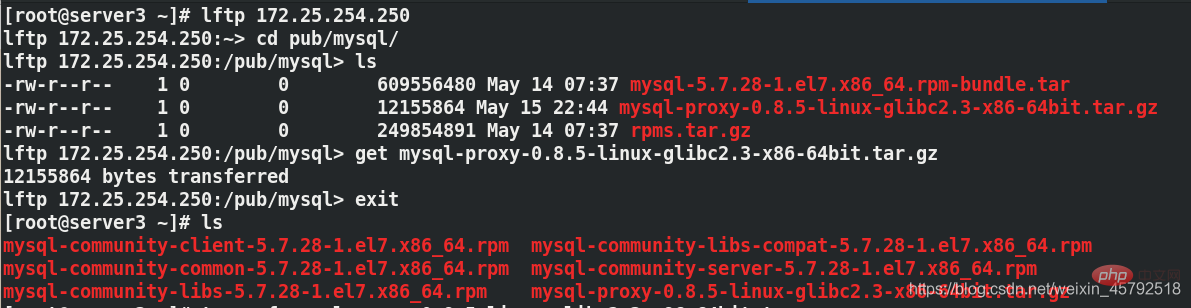
Configurer le proxy serveur3 (mysql-proxy)  Construire le serveur proxy mysql-proxy sur le serveur3 (pour permettre au client d'écrire sur le serveur1 et de lire données sur le serveur2)
Construire le serveur proxy mysql-proxy sur le serveur3 (pour permettre au client d'écrire sur le serveur1 et de lire données sur le serveur2)
(2) Configurez sur le serveur3
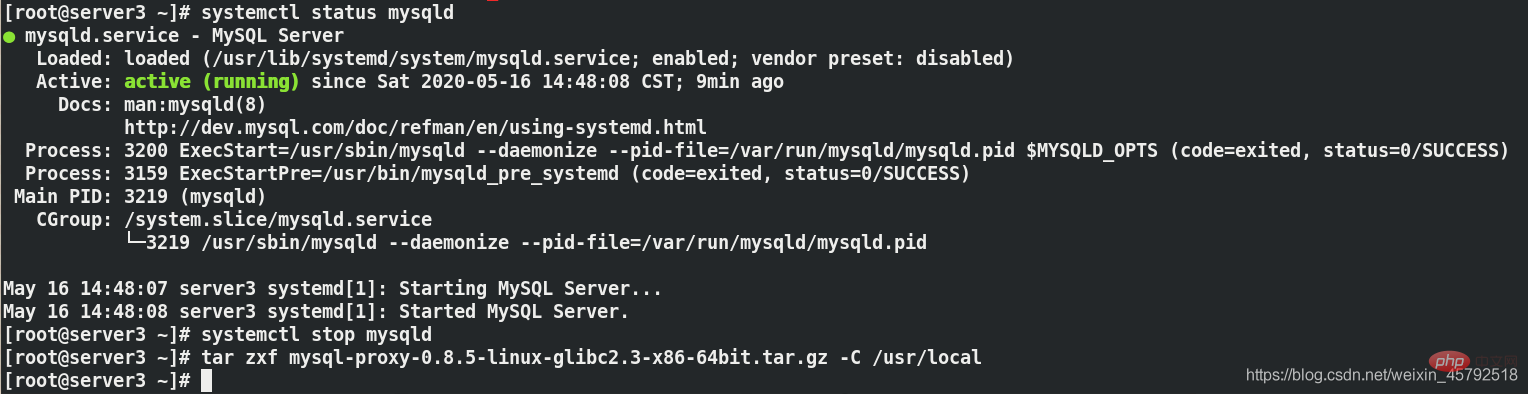
[root@server3 ~]# systemctl status mysqld ##查看mysqld服务状态 [root@server3 ~]# systemctl stop mysqld ##关闭mysqld服务,因为代理服务器要用3306端口 [root@server3 ~]# tar zxf mysql-proxy-0.8.5-linux-glibc2-x86-64bit.tar.gz -C /usr/local/ ##解压到/usr/local/目录下
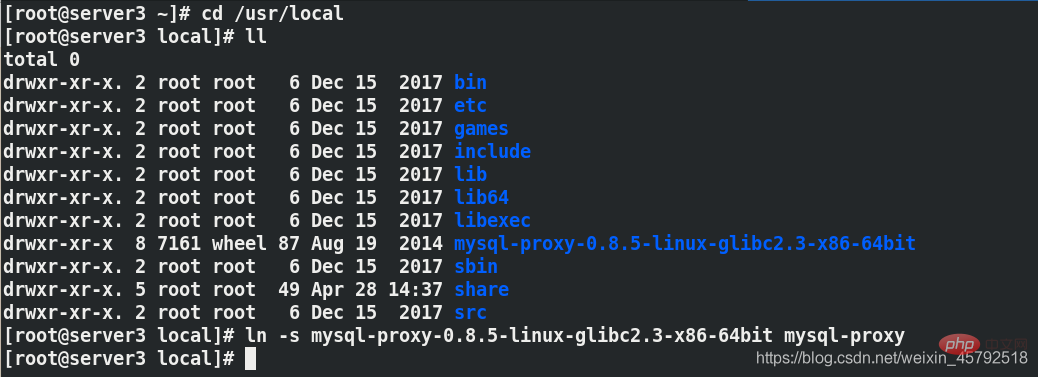
Établissez une connexion logicielle pour la gestion
ln -s mysql-proxy-0.8.5-linux-glibc2-x86-64bit mysql-proxy
Utilisez les deux commandes suivantes pour vérifier les paramètres écrits dans le fichier de configuration
[root@server3 bin]# ./mysql-proxy --help [root@server3 bin]# ./mysql-proxy --help-proxy
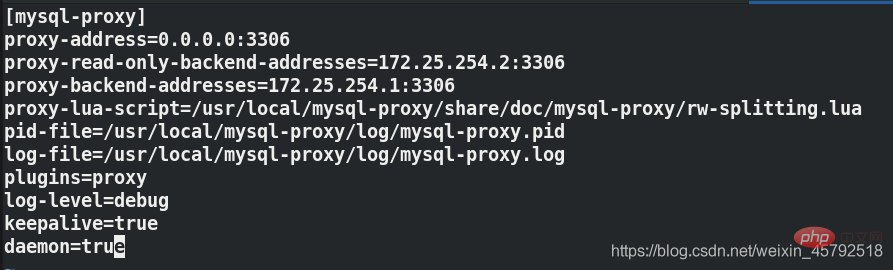
[mysql-proxy] ##指定语句块 proxy-address=0.0.0.0:3306 ##指定proxy访问的主机和端口,3306是一个对外的通用端口 proxy-read-only-backend-addresses=172.25.254.2:3306 ##读主机的ip和端口 proxy-backend-addresses=172.25.254.1:3306 ##执行写主机的ip和端口 proxy-lua-script=/usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua ##指定读写分离操作使用的lua文件路径 pid-file=/usr/local/mysql-proxy/log/mysql-proxy.pid ##pid存放路径 log-file=/usr/local/mysql-proxy/log/mysql-proxy.log ##日志存放路径 plugins=proxy ##指定使用的插件 log-level=debug ##日志的等级 keepalive=true ##开启守护进程 daemon=true ##使用后台方式运行
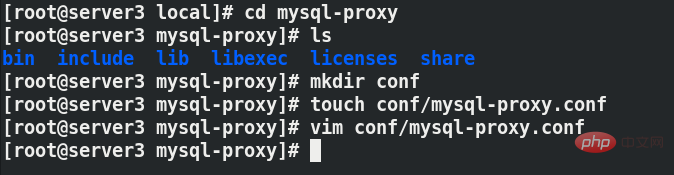
Après lors de l'enregistrement, vous devez modifier les autorisations du fichier de configuration à 660 et vous devez créer un répertoire de journaux
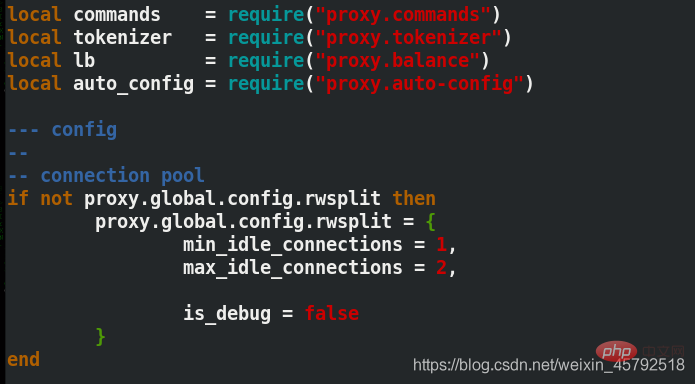
Modifier le nombre maximum et minimum de connexions lorsque la séparation lecture-écriture se produit dans la base de données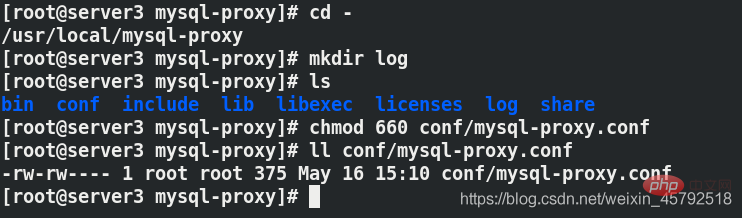
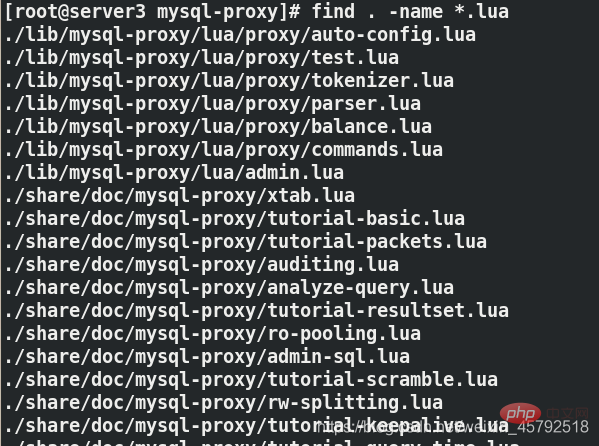
[root@server3 mysql-proxy]# find . -name *.lua ./share/doc/mysql-proxy/rw-splitting.lua [root@server3 mysql-proxy]# cd share/doc/mysql-proxy [root@server3 mysql-proxy]# ls [root@server3 mysql-proxy]# vim rw-splitting.lua ##将lua脚本里原本启动机制的最小4个最大8个连接,改为1和2 min_idle_connections = 1, 最小连接数 max_idle_connections = 2, 最大连接数
(3) Démarrez mysql-proxy
/usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/mysql-proxy.conf ##启动 cat /usr/local/mysql-proxy/log/mysql-proxy.log ##查看日志
Test de la séparation lecture-écriture
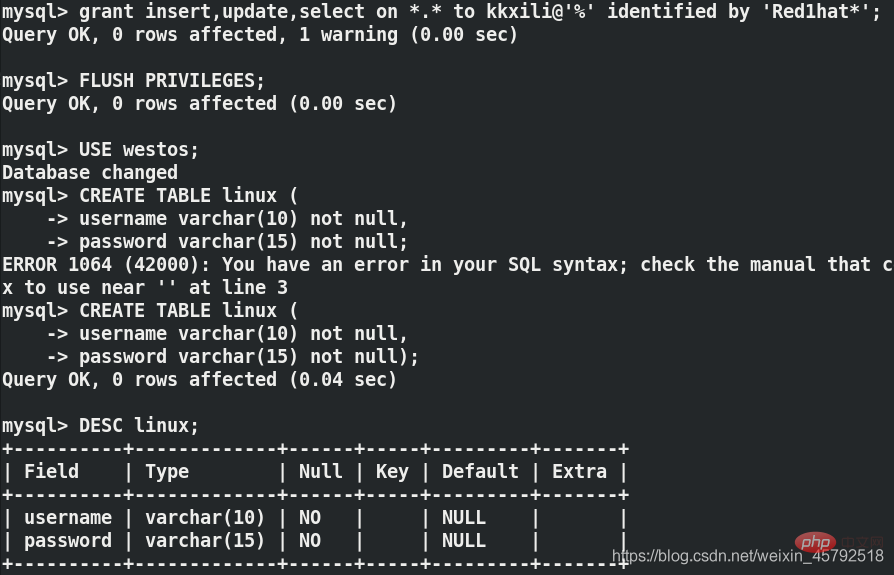
 (1) Créez un nouveau serveur sur le serveur 1 Utilisateur et autorisé
(1) Créez un nouveau serveur sur le serveur 1 Utilisateur et autorisé
mysql> grant insert,update,select on *.* to kkxili@'%' identified by 'Red1hat*'; mysql> FLUSH PRIVILEGES; ##刷新授权表 mysql> USE westos; Database changed mysql> CREATE TABLE linux ( -> username varchar(10) not null, -> password varchar(15) not null); mysql>DESC linux;
(2)server3安装lsof

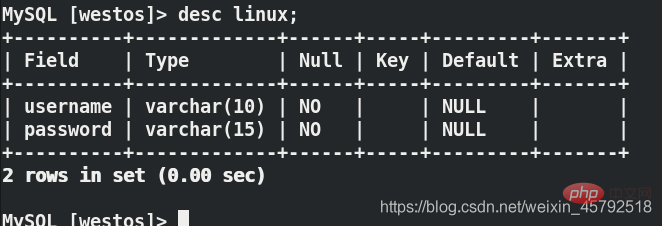
(3)在用户端虚拟机server4上第一次连接数据库代理server3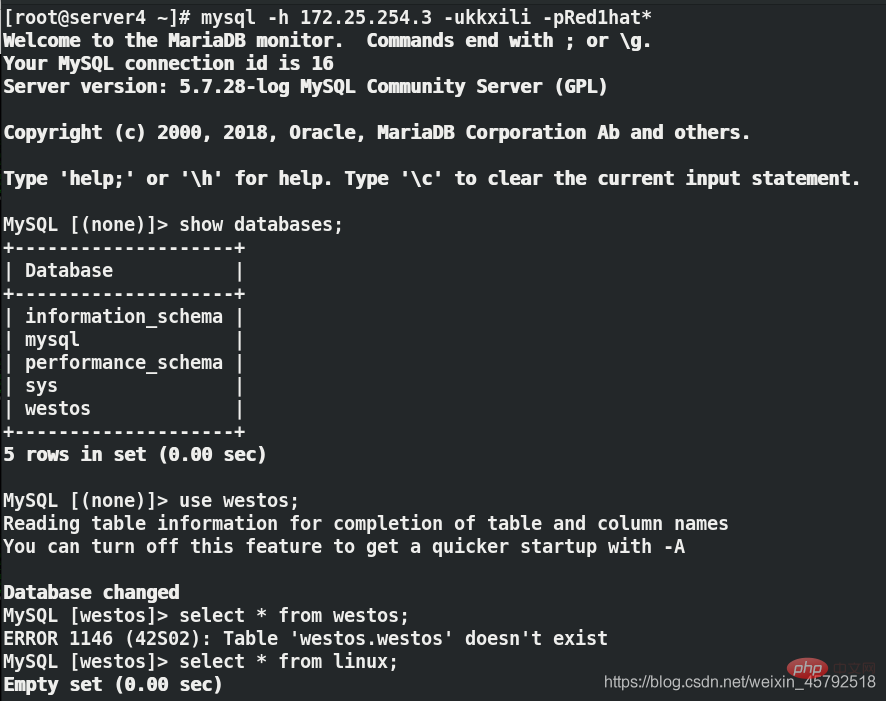
在server3上面:lsof -i:3306

(4)在用户端虚拟机server4上第二次连接数据库代理server3
在server3上面:lsof -i:3306

(5)在用户端虚拟机server4上第三次连接数据库代理server3
在server3上面:lsof -i:3306
开始读写分离
 上面是读写分离的读访问测试
上面是读写分离的读访问测试
写测试
在用户端插入数据
use westos;
insert into linux values('user1','123');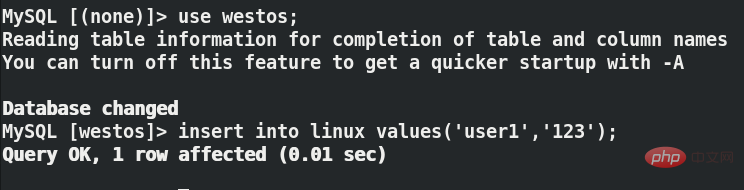
server1和server2都可以看到插入的数据
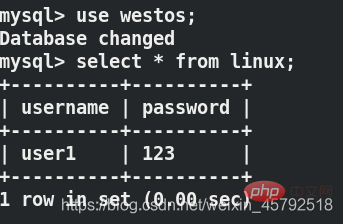
在server2中关闭主从复制
用户端再次写入数据,看不到刚刚写的数据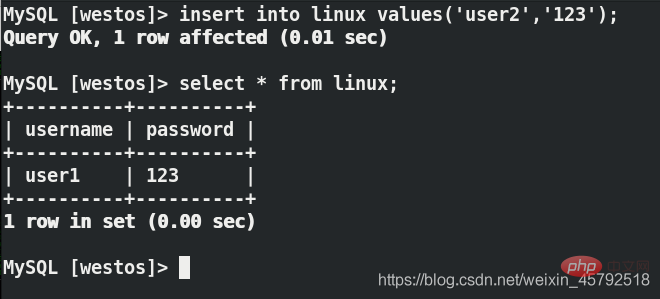
写在server1上,可以查看到数据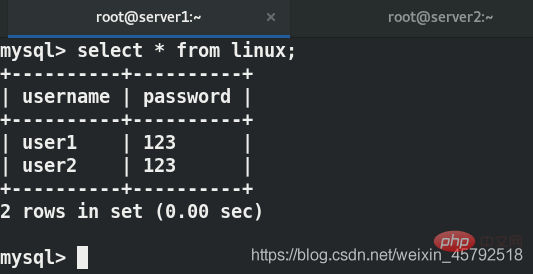
在server2上实现了读写分离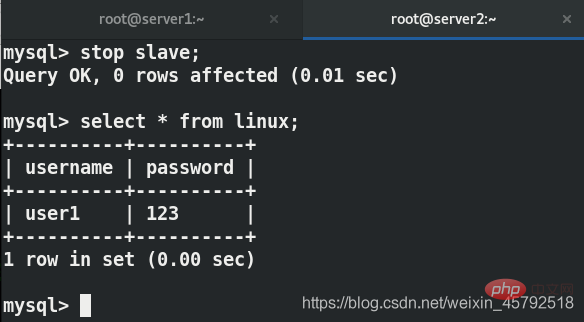
server2重新开启主从复制可以看到数据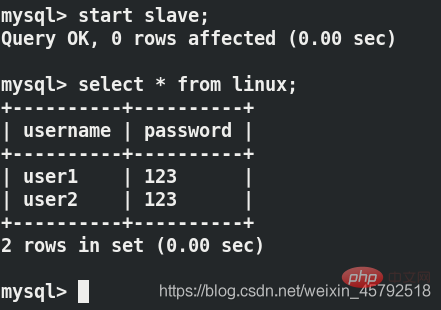
客户端读的是server2,server2只能读,不能写,因此看不到刚才写进去的东西,server1可以看到
实现了客户端(虚拟机)对server1的写,对server2的读
当访问数据库的用户数量很多时,数据库的代理就把后端的数据库实现读写分离
server1是写的数据库、server2是读的数据库
当server1和server2满足gtid的主从复制时,用户往数据库写入的数据其实是写入了server1,并没有写入server2,server2上面的数据是复制过去的,因此server1、server2、客户机上面都能查到刚刚写进去的数据,其实客户机查的是server2(读)
当关闭server1和server2的异步复制时,客户机往数据库写入的数据只写进了server1,没有写进去server2,server2也没有复制一份
因此server1可以查看到,server2和客户机上面都查不到刚刚写进去的数据,此时的客户机读的是server2
推荐学习:mysql视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
