

Cet article vous apporte des connaissances pertinentes sur mysql, qui introduit principalement des questions liées à la structure de l'index. Alors, quelle est la structure de l'index ? Pourquoi l’indexation peut-elle être si rapide ? Jetons un coup d'œil ci-dessous, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel mysql
Tout d'abord, nous devons savoir que pour obtenir la persistance, l'index ne peut être stocké que sur le disque dur lors d'une interrogation via l'index. , un disque dur sera généré des opérations d'E/S, par conséquent, lors de la conception de l'index, il est nécessaire de réduire autant que possible le nombre de recherches pour réduire le temps d'E/S.
De plus, vous devez connaître un principe très important : l'unité de base de l'espace de stockage de gestion de base de données est la page (Page), et plusieurs enregistrements de ligne (Row) sont stockés sur une seule page. 页(Page),一个页中存储多条行记录(Row)。
计算机系统对磁盘 I/O 会做预读优化,当一次I/O时,除了当前磁盘地址的数据以外,还会把相邻的数据也读取到内存缓冲池中,每一次 I/O 读取的数据成为一页,InnoDB 默认的页大小是 16KB。
连续的 64 个页组成一个区(Extent),一个或多个区组成一个段(Segment),一个或多个段组成表空间(Tablespace)。InnoDB 有两种表空间类型,共享表空间表示多张表共享一个表空间,独立表空间表示每张表的数据和索引全部存在独立的表空间中。
数据页结构如下(图源:极客时间《MySQL 必知必会》):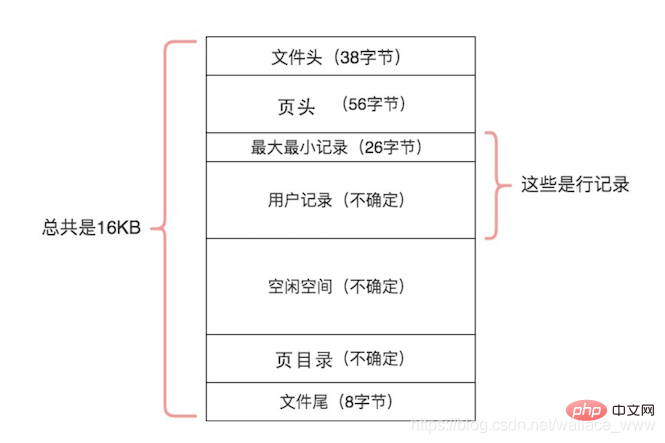
数据页的 7 个结构内容可以大致分为以下三类:
详情可参考淘宝的数据库内核月报
很自然的,我们会想到查找算法中涉及到的一些常用数据结构,比如二叉查找树,二叉平衡树等等,实际上,Innodb 的索引是用 B+ 树
lecture anticipée pour les E/S du disque Lorsqu'une E/S est effectuée, en plus des données à l'adresse actuelle du disque, les données adjacentes seront également lues dans le disque. mémoire tampon. Dans le pool, les données lues par chaque E/S deviennent une page et la taille de page par défaut d'InnoDB est de 16 Ko. Étendue, une ou plusieurs étendues forment un Segment et un ou plusieurs segments forment un Tablespace. InnoDB a deux types d'espace table partagé, ce qui signifie que plusieurs tables partagent un espace table indépendant, ce qui signifie que les données et les index de chaque table sont tous stockés dans des espaces table indépendants. La structure de la page de données est la suivante (Source : Geek Time "Must Know MySQL") : 
 Les 7 contenus structurels de la page de données peuvent être grossièrement divisés en trois catégories suivantes :
Les 7 contenus structurels de la page de données peuvent être grossièrement divisés en trois catégories suivantes :
Naturellement, nous réfléchirons de certaines structures de données courantes impliquées dans les algorithmes de recherche, telles que les arbres de recherche binaires, les arbres binaires équilibrés, etc. En fait, l'index d'Innodb utilise B+ tree pour y parvenir, voyons pourquoi cette structure d'index a été choisi.
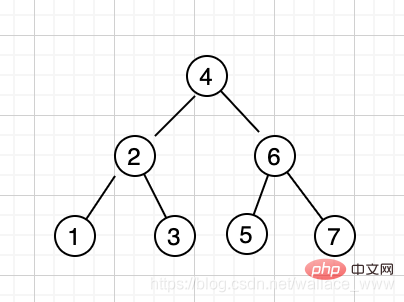
Tout d'abord, passons brièvement en revue la définition de l'arbre de recherche binaire. Dans un arbre de recherche binaire, si la clé à trouver est supérieure au nœud racine, recherchez dans le sous-arbre de droite si la clé est la suivante. est inférieur au nœud racine, recherchez dans le sous-arbre de gauche jusqu'à ce que la clé soit trouvée. La complexité temporelle est O(logn). Par exemple, la séquence [4,2,6,1,3,5,7] générera l'arbre de recherche binaire suivant :
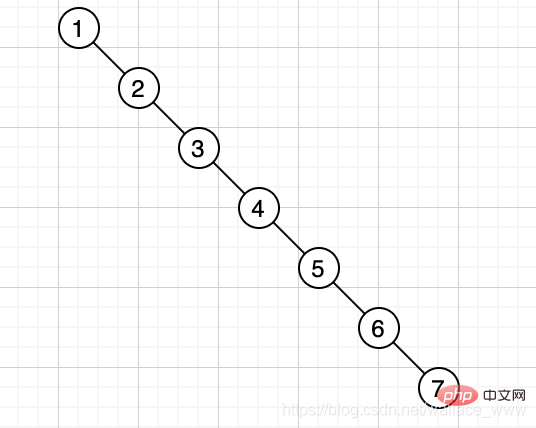
Cependant, dans certains cas particuliers, la profondeur de l'arbre binaire sera très grande, comme comme [1,2, 3,4,5,6,7], l'arbre suivant sera généré :
k - 1 个关键字 和 kdes pointeurs vers des nœuds enfants Comme mentionné ci-dessus, chaque E/S pré-lisera les données d'un bloc de disque, qui fait une page. Le contenu d'un bloc de disque est utilisé pour représenter une E/S. La structure du B-. L'arbre est le suivant (Source : Ji Vous devez connaître SQL en temps invité) : 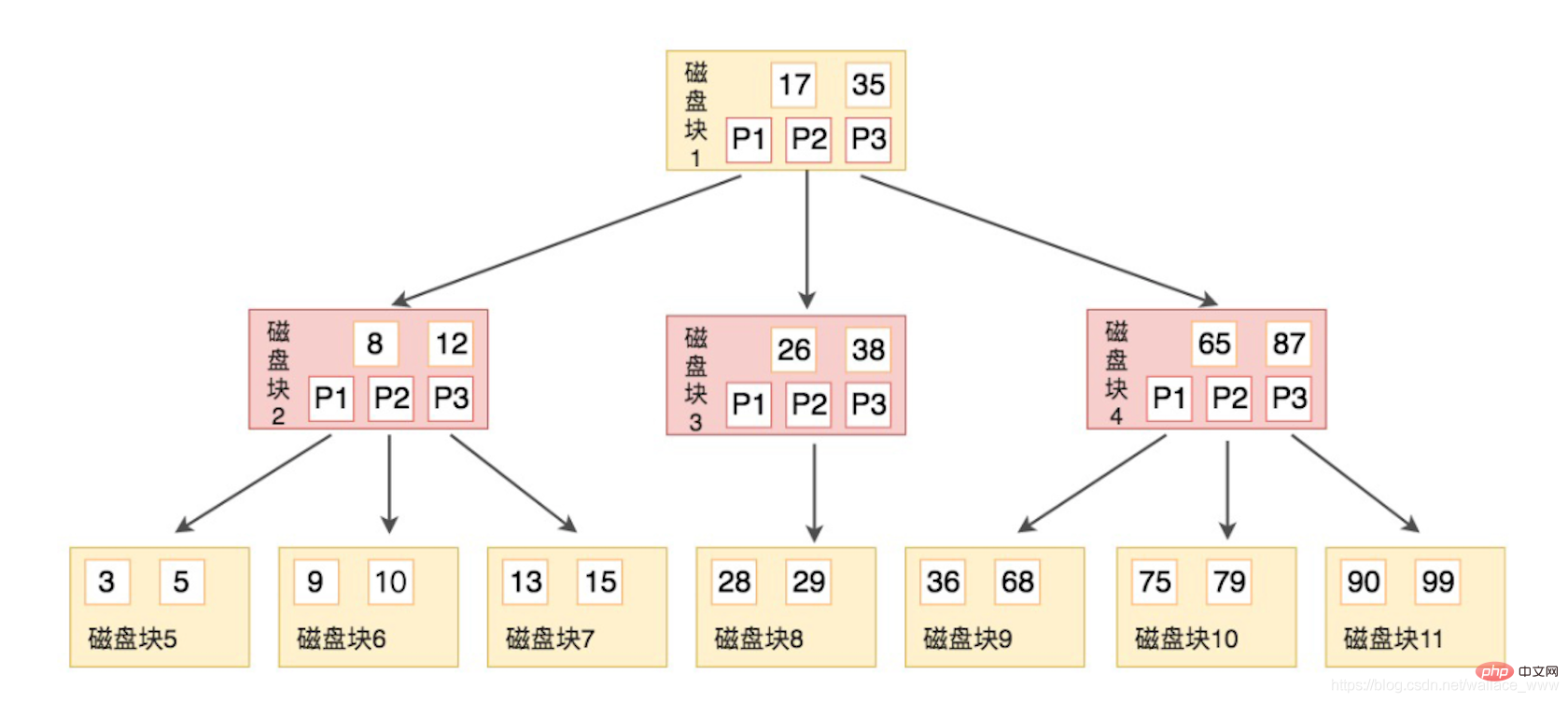
Le B-tree est également ordonné Puisque le pointeur du nœud enfant doit être 1 de plus que le mot-clé, le mot-clé peut être utilisé pour diviser les segments. du nœud enfant. Comme dans l'exemple de la figure, chaque nœud A a 2 mots-clés et 3 nœuds enfants, tels que le bloc de disque 2. Le mot-clé 3, 5 du premier point d'octet est plus petit que son propre premier nœud enfant 8, et le 9, 10 du deuxième nœud enfant est compris entre 8 et 10. Entre 12 et 12, la valeur du troisième nœud enfant est 13 et 15, ce qui est supérieur à son deuxième nœud enfant 12.
Supposons que nous voulions trouver 9 maintenant, les étapes sont les suivantes :
est trouvé, bien que de nombreuses comparaisons aient été effectuées, mais en raison de la pré-lecture, la comparaison au sein du bloc disque est effectuée en mémoire, ce qui ne consomme pas d'E/S disque. L'opération ci-dessus ne nécessite que 3 E/S. Os à compléter, ce qui est une structure idéale.
L'arbre B+ est encore amélioré sur la base de l'arbre B. La différence entre l'arbre B+ et l'arbre B est la suivante :
L'exemple est le suivant. Dans cet exemple, les mots-clés du nœud parent sont tous les valeurs minimales parmi les nœuds enfants (Source : Geek Time SQL doit savoir) : 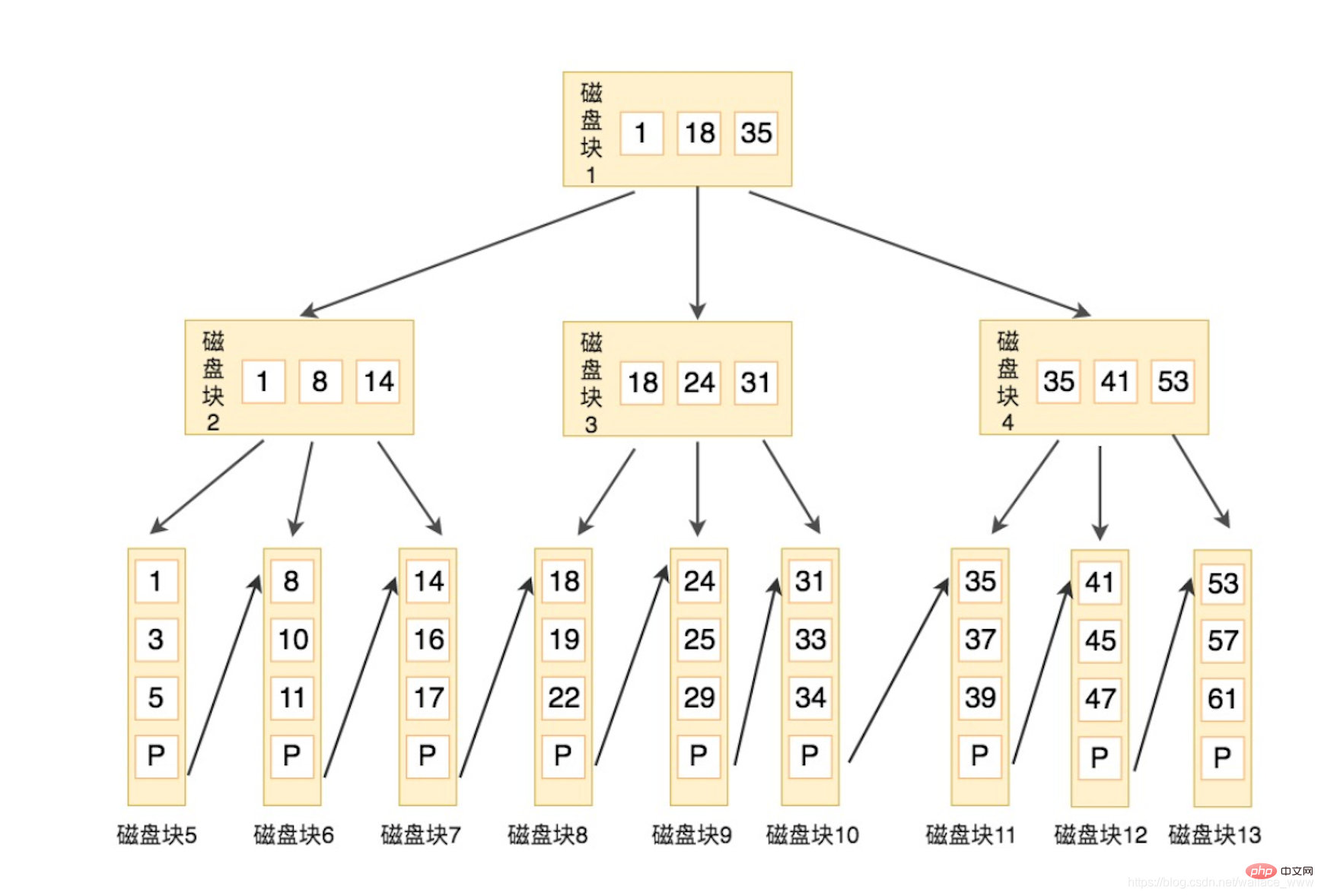
Supposons que vous souhaitiez trouver le mot-clé 16, les étapes de recherche sont les suivantes :
B+ avantages de l'arbre :
La structure d'index par défaut du moteur de stockage de mémoire de MySQL est l'index de hachage. une fonction, appelée fonction de hachage, qui utilise un algorithme spécifique (tel que MD5 , SHA1, SHA2, etc.) pour convertir une entrée de n'importe quelle longueur en sortie de longueur fixe. L'entrée et la sortie correspondent une à une. une introduction approfondie à la fonction de hachage. Pour plus de détails, veuillez vous référer à l'Encyclopédie Baidu.
L'efficacité de la recherche de hachage est O(1), ce qui est très efficace. Le dict de Python, la carte de Golang et la carte de hachage de Java sont tous implémentés sur la base de bases de données de valeurs clés telles que Redis sont également implémentées par Hash.
Pour une recherche précise, l'index Hash est plus efficace que l'index arborescent B+, mais l'index Hash a certaines limites, ce n'est donc pas la structure d'index la plus courante.
Pour les raisons ci-dessus, le moteur Mysql InnoDB ne prend pas en charge l'index de hachage, mais il existe une fonction d'index de hachage adaptative dans la structure de la mémoire. Lorsqu'une certaine valeur d'index est utilisée très fréquemment, elle sera basée sur l'arborescence B+. index Créez automatiquement un index de hachage pour améliorer les performances des requêtes.
L'index Hash adaptatif peut être compris comme un "index d'index". L'index Hash est utilisé pour stocker l'adresse de la page dans l'index de l'arborescence B+ et localiser rapidement le nœud feuille correspondant. Il peut être consulté via la variable innodb_adaptive_hash_index.
Apprentissage recommandé : Tutoriel mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié







![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



