
 base de données
Redis
Explication détaillée des connaissances sur la structure des données Redis avec images et textes
base de données
Redis
Explication détaillée des connaissances sur la structure des données Redis avec images et textes
Explication détaillée des connaissances sur la structure des données Redis avec images et textes

Cet article vous apporte des connaissances pertinentes sur Redis Il présente principalement des problèmes liés aux structures de données, notamment les chaînes, les listes, les hachages, les ensembles ordonnés, etc. J'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel d'apprentissage Redis
Structure de données redis : String (string), List (list), hash (hash), Set (set), Shorted Set (ensemble ordonné)
Structure de données sous-jacente : chaîne dynamique simple, liste doublement chaînée, liste compressée, table de hachage, liste de sauts, tableau d'entiers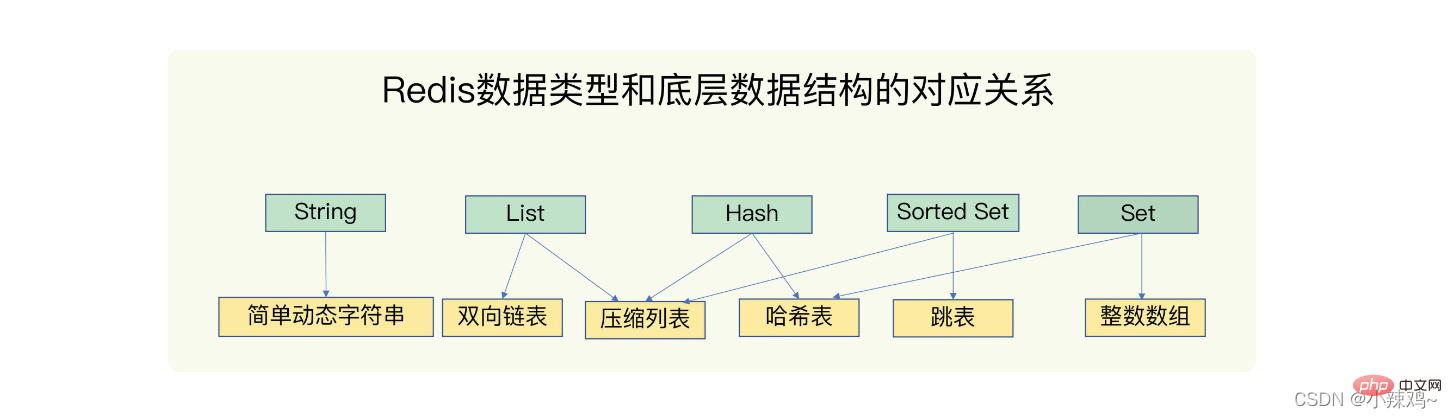
1. Table de hachage : une table de hachage est en fait un tableau, et chaque élément du tableau est appelé un seau de hachage. 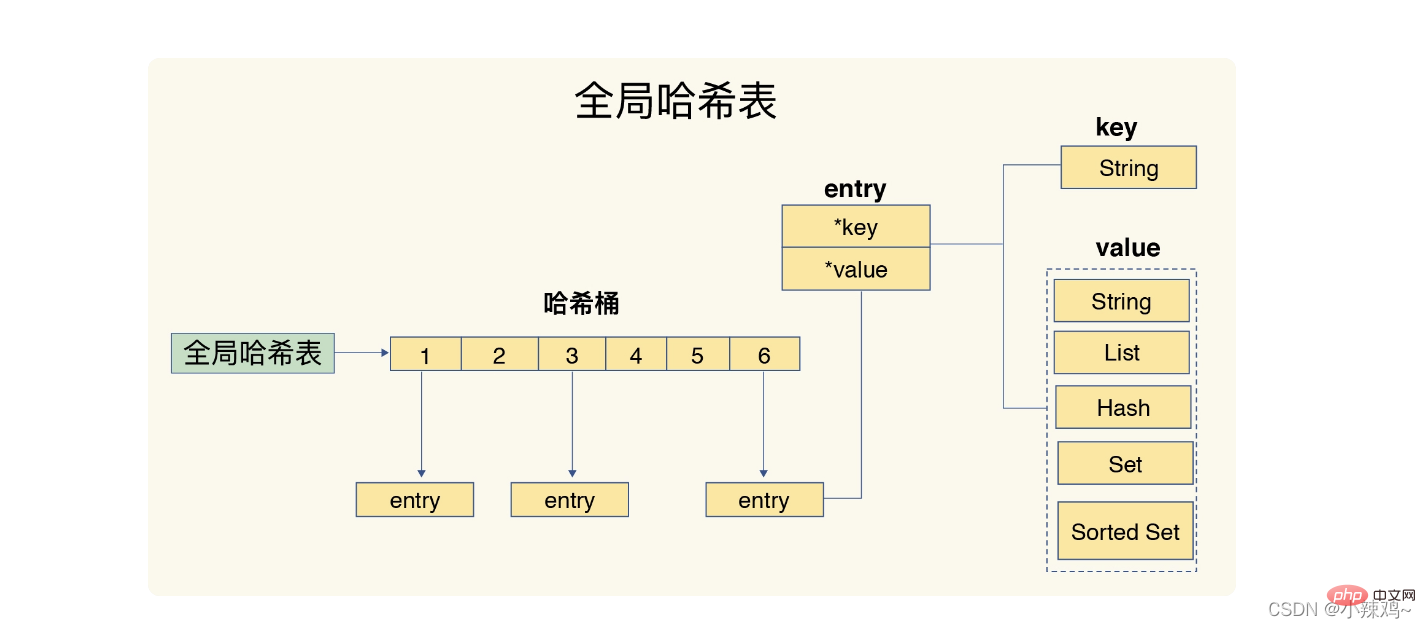
Les conflits de hachage et les répétitions peuvent provoquer un blocage des opérations.
La méthode de Redis pour résoudre les conflits de hachage est le hachage en chaîne, tandis que le rehachage consiste à augmenter le nombre de compartiments de hachage existants. 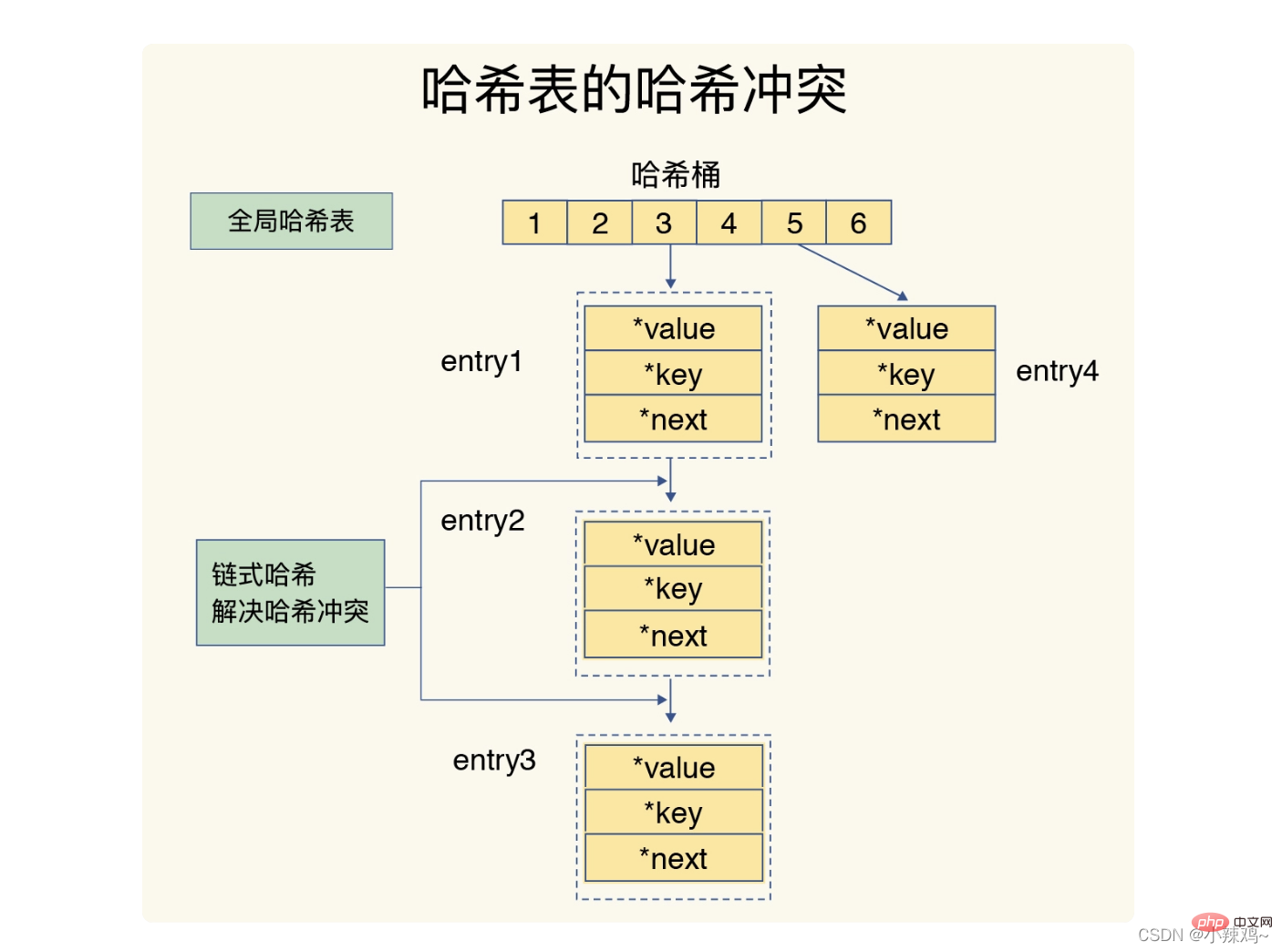
Étapes de fonctionnement du rehachage : 1. Allouez un espace plus grand à la table de hachage, par exemple, deux fois la taille de la table de hachage actuelle
2. Remappez et copiez les données de la table de hachage 1 vers la table de hachage 2
3. Libérez le espace de la table de hachage 1
La deuxième étape implique un grand nombre d'opérations de copie de données. Si toutes les données de la table de hachage 1 sont migrées en même temps, le thread sera bloqué et les autres requêtes ne seront pas servies. Afin d'éviter ce problème, Redis utilise un rehash progressif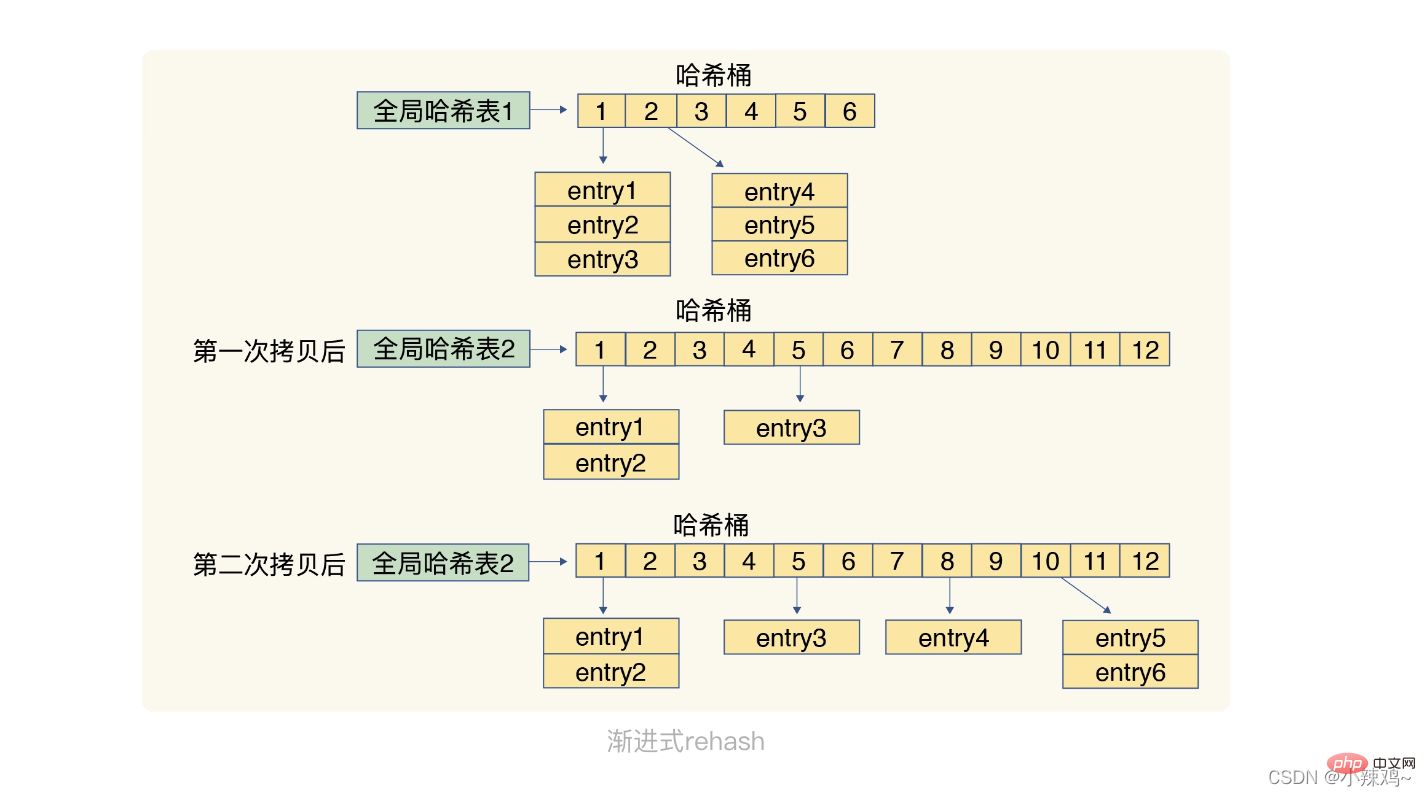
La complexité des tableaux entiers et des listes doublement chaînées est O(N)
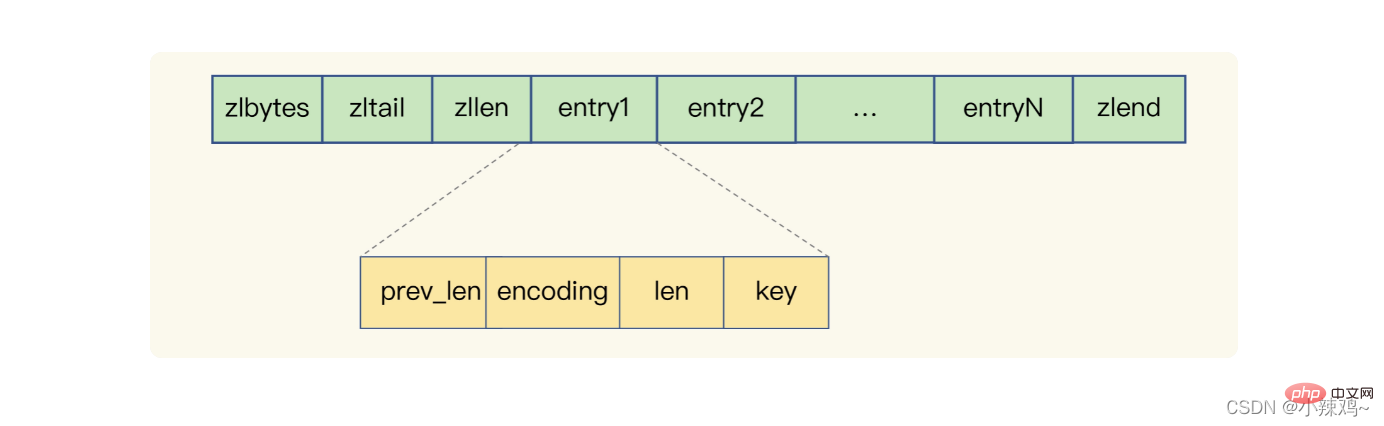
La liste compressée a trois données dans l'en-tête, qui sont la longueur de la liste, le décalage de la queue de la liste, et la liste Le nombre d'entrées au milieu
La liste compressée a également un élément zlend à la fin du tableau pour représenter la fin de la liste 
Sauter la liste : Une liste chaînée ordonnée ne peut trouver que éléments un par un, tandis qu'une liste de sauts ajoute un index multi-niveaux sur la base de la liste chaînée. Grâce à la position de l'index Plusieurs sauts pour obtenir un positionnement rapide des données 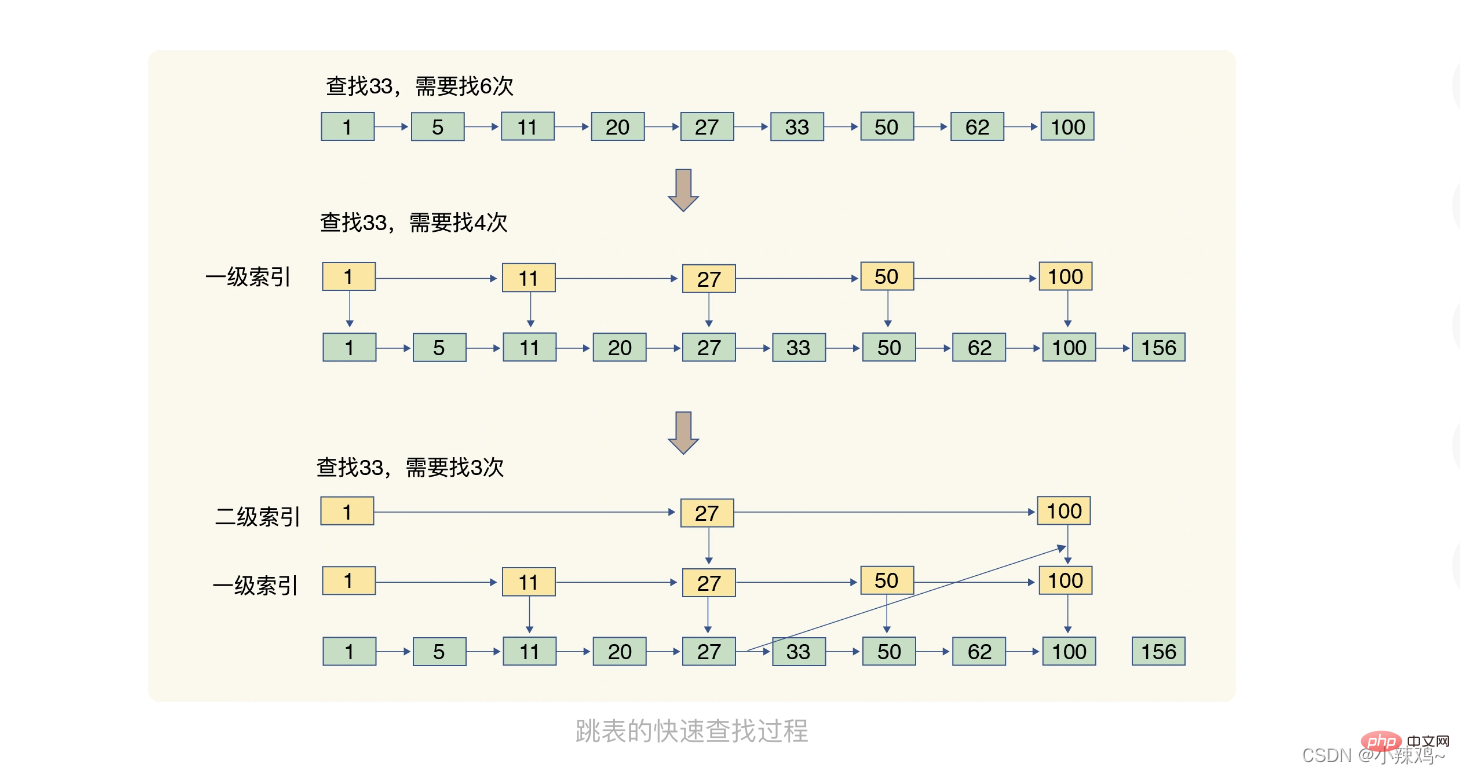
La complexité temporelle des cinq structures suivantes 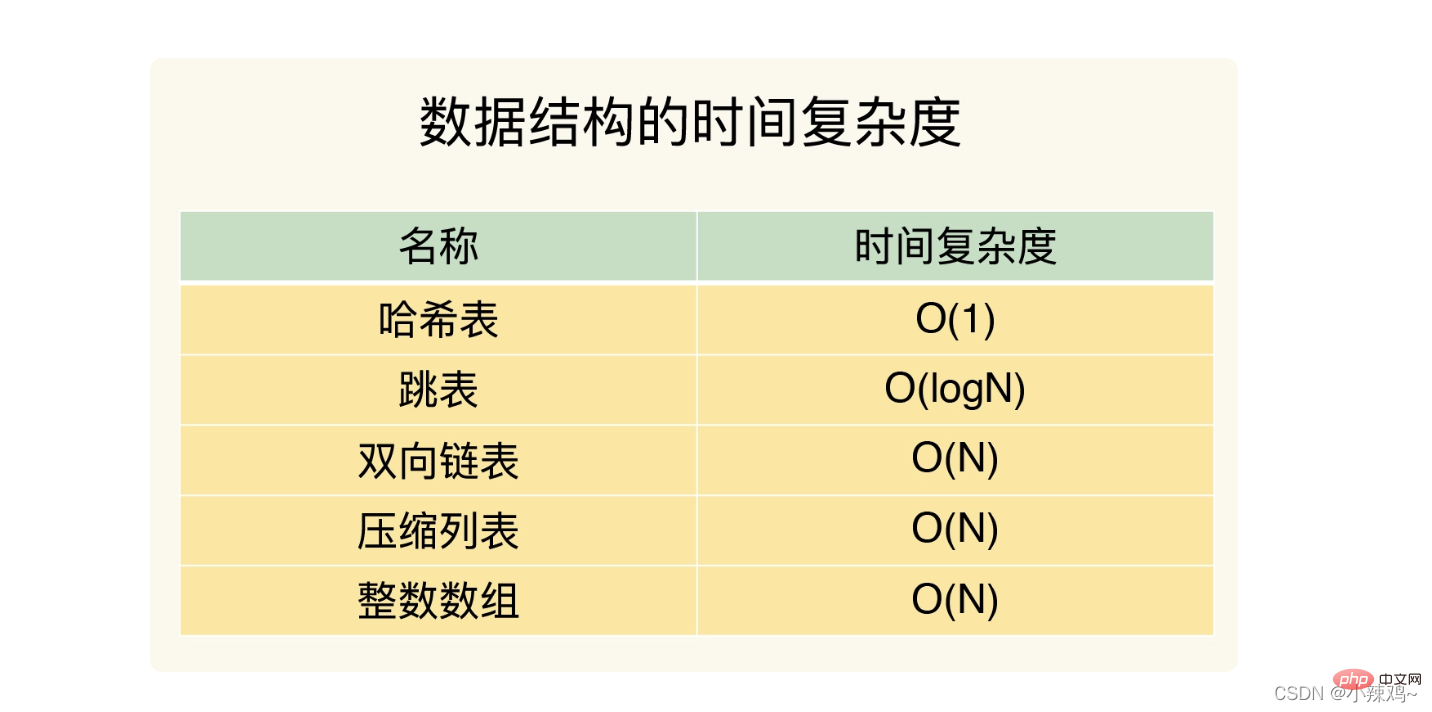
Chaîne type
Le type String ne convient pas à tous les scénarios. Il présente un inconvénient évident lors de la sauvegarde des données. Il consomme plus d'espace mémoire. Étant donné que le type String nécessite un espace mémoire supplémentaire pour enregistrer la longueur des données, l'utilisation de l'espace et d'autres informations, ces informations sont également appelées métadonnées.
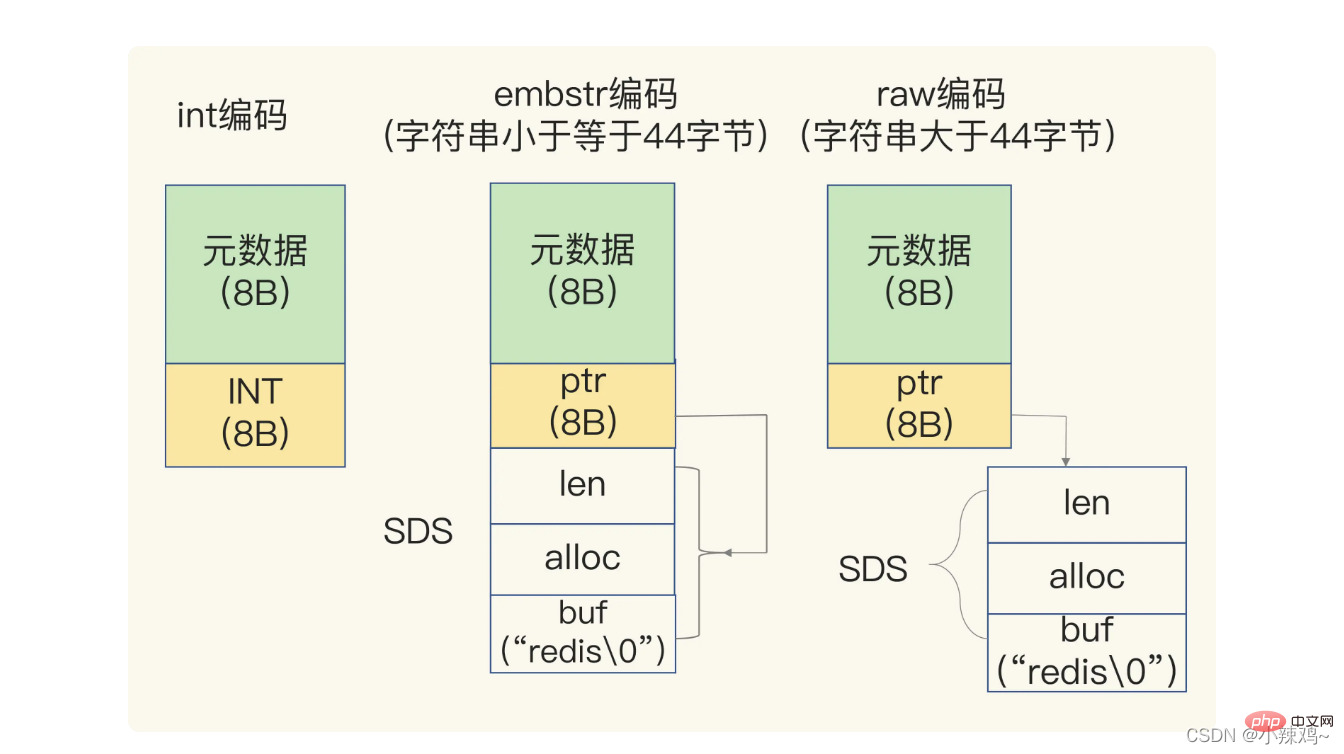
Lorsque les données enregistrées contiennent des caractères, la chaîne sera enregistrée à l'aide d'une simple structure SDS de chaîne dynamique 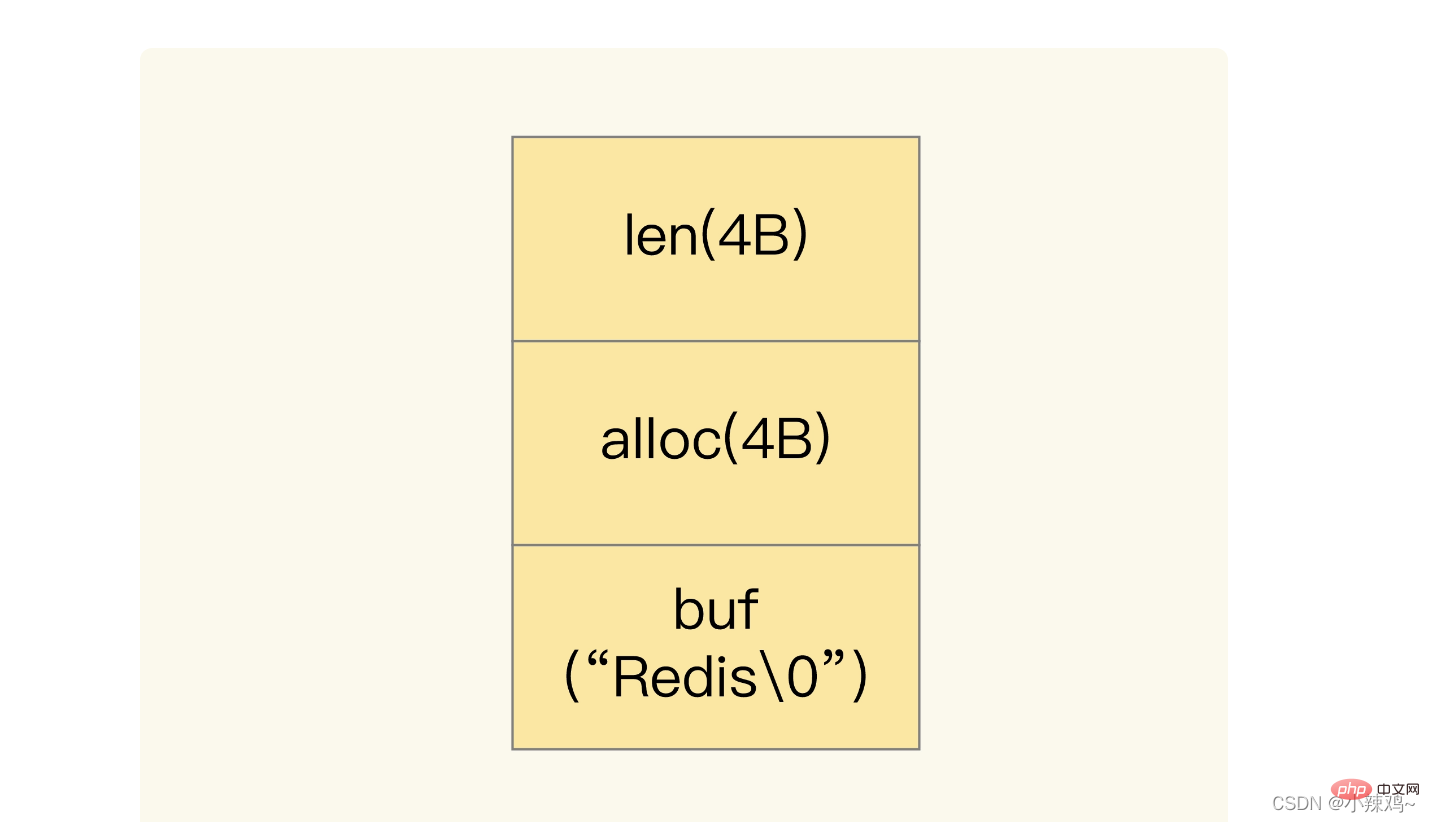
len est la longueur utilisée de buf et alloc est la longueur réelle allouée de buf
Parce qu'il existe de nombreux types de données Redis, différents types de données sont Les mêmes métadonnées doivent être enregistrées, donc redis utilisera une structure RedisObject pour enregistrer uniformément ces métadonnées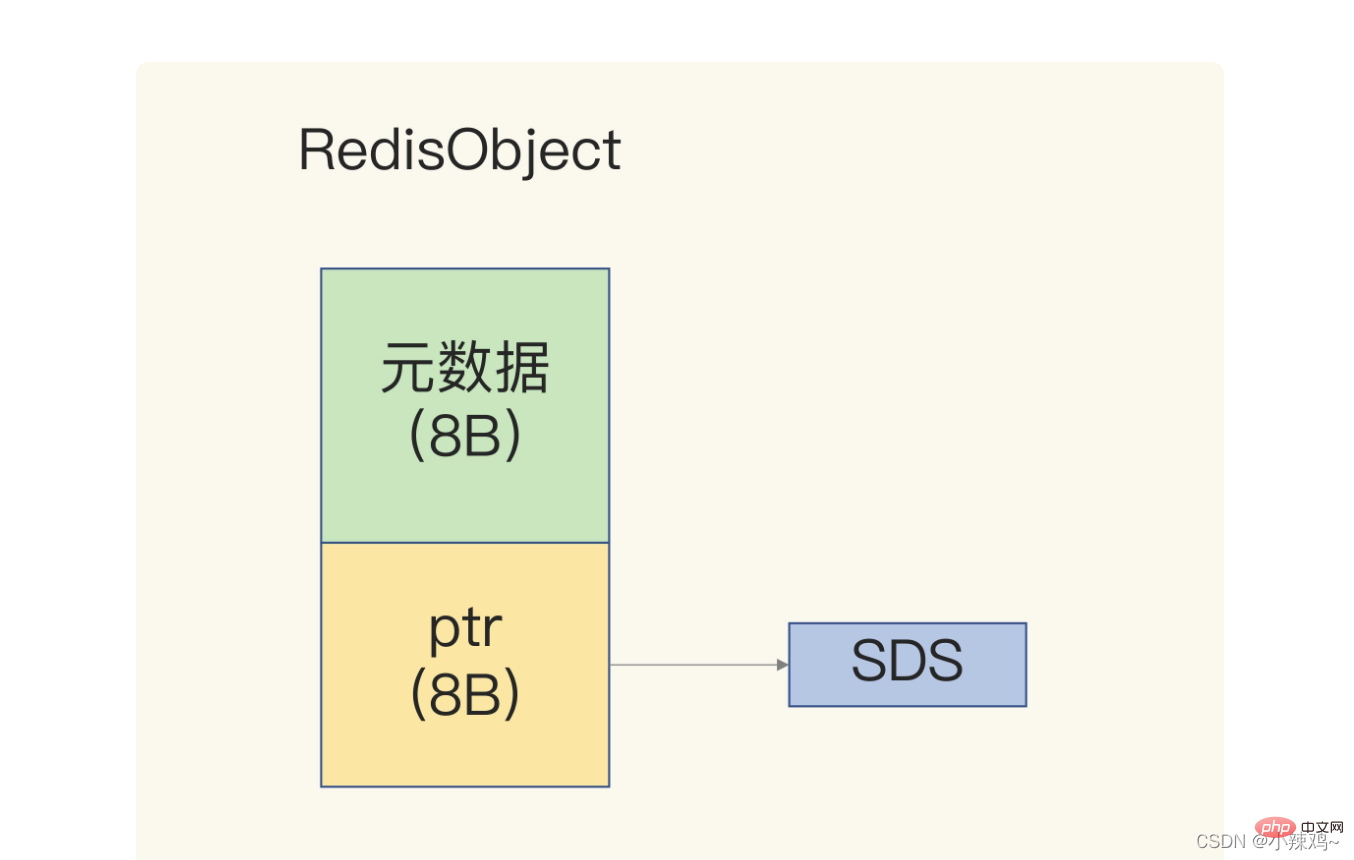
Lors de l'enregistrement du type Long, le pointeur RedisObject est directement affecté aux données entières, de sorte qu'aucun pointeur supplémentaire n'est nécessaire pour pointer vers it. Integer, économisant ainsi l'espace occupé par les pointeurs.
Si la chaîne enregistrée fait moins de 44 octets, le SDS et les métadonnées seront alloués à une zone de mémoire continue, appelée encodage embstr
Si la chaîne enregistrée est supérieure à 44 octets, le SDS et les métadonnées seront stockés séparément et appelés encodage brut
De plus, redis utilisera une table de hachage globale pour enregistrer toutes les paires clé-valeur. Chaque élément de la table de hachage est une structure dictEntry, qui est utilisée pour pointer vers une paire clé-valeur. value+next utilisera 24 octets, mais occupe en réalité 32 octets, car lorsque jemalloc alloue de la mémoire, il trouvera une puissance de 2 supérieure à N mais la plus proche de N comme espace alloué en fonction du nombre d'octets que nous appliquons. pour N, donc Peut réduire le nombre d'allocations fréquentes. 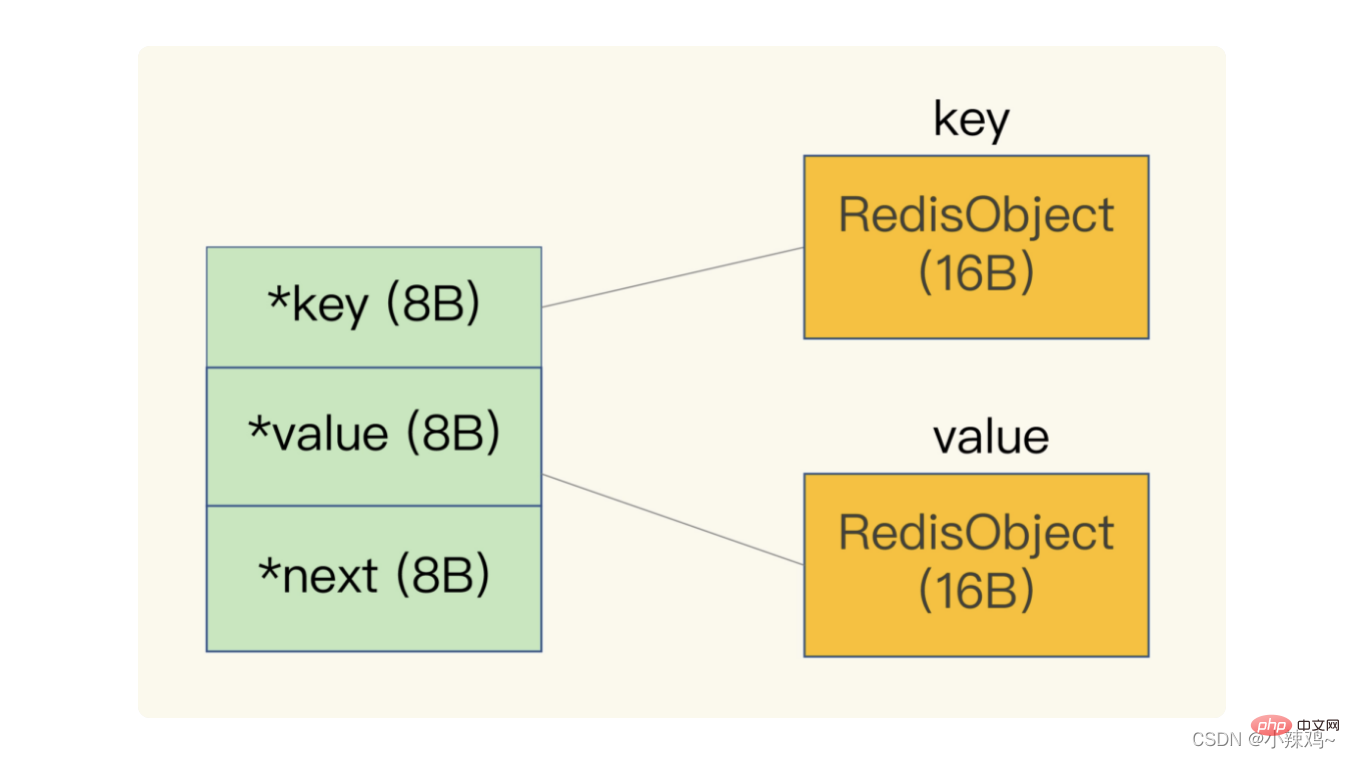
Quelle structure de données peut être utilisée pour économiser de la mémoire ?
Liste compressée : zlbytes représente la longueur de la liste, zltail représente le décalage de queue de la liste, zllen représente le nombre d'entrées dans la liste, zlend représente la fin de la liste, perv_len représente la longueur de l'entrée précédente, encodage représente la méthode d'encodage, len représente sa propre longueur, la clé est les données réellement stockées. Redis implémente la liste, le hachage et l'ensemble trié basés sur une liste compressée
Comment enregistrer des paires clé-valeur à valeur unique à l'aide de types d'ensemble ?
Lors de l'enregistrement de paires clé-valeur à valeur unique, vous pouvez utiliser le codage secondaire de Hash, qui consiste à diviser la valeur à valeur unique en deux parties. La première partie est utilisée comme clé du hachage et la dernière partie est utilisée. comme valeur du Hash
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。127.0.0.1:6379> info memory# Memoryused_memory:1039120127.0.0.1:6379> hset 1101000 060 3302000080(integer) 1127.0.0.1:6379> info memory# Memoryused_memory:1039136
Hash Le type a deux structures d'implémentation sous-jacentes : 1. Liste compressée 2. Table de hachage
Il y a deux seuils dans la liste de hachage Une fois ces deux seuils dépassés, elle sera convertie à partir de la liste compressée. list dans une table de hachage
Représenté par hash-max-ziplist-entries Le nombre maximum d'éléments dans la liste de hachage défini lors de l'enregistrement avec une liste compressée
hash-max-ziplist-value indique la longueur maximale d'un seul élément du hachage défini lors de l'enregistrement avec une liste compressée
Définir le mode statistiques
1. Statistiques d'agrégation
2 . Statistiques de tri
3. Statistiques d'état binaire
4. Statistiques de cardinalité
Trois types de données étendus de redis
1.Bitmap :
2.HyperLogLog
3.GEO :
Type de données GEO pour les applications LBS
La structure sous-jacente de GEO est implémentée sur la base de l'ensemble trié. L'ensemble trié peut être trié en fonction du poids des éléments et prend en charge les requêtes de plage. Sorted Set est un nombre à virgule flottante (type flottant), et la longitude et la latitude sont deux nombres, donc GeoHash est requis 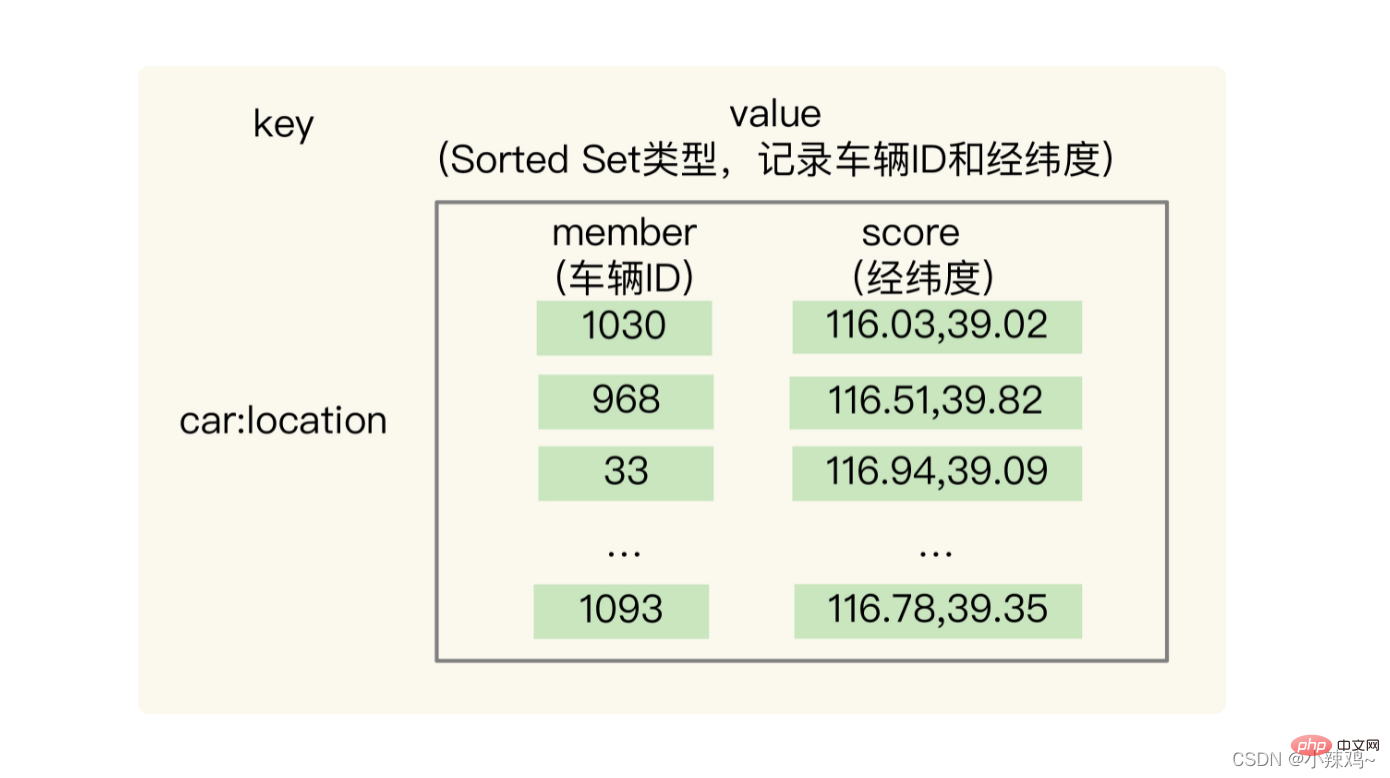 L'encodage GeoHash est effectué via "intervalle binaire, encodage par intervalle".
L'encodage GeoHash est effectué via "intervalle binaire, encodage par intervalle".
Convertissez d'abord la longitude et la latitude dans un format codé, puis effectuez le croisement
En fait, le but du croisement est le concept présenté dans la figure ci-dessous. Après le croisement, vous pouvez réellement localiser un carré dans les deux. -espace dimensionnel. Les valeurs de codage similaires que nous obtenons en utilisant la requête de plage d'ensembles triés sont également des carrés adjacents dans l'espace géographique réel. Par exemple, 1110011101 et 1111011101 sont adjacents dans l'emplacement spatial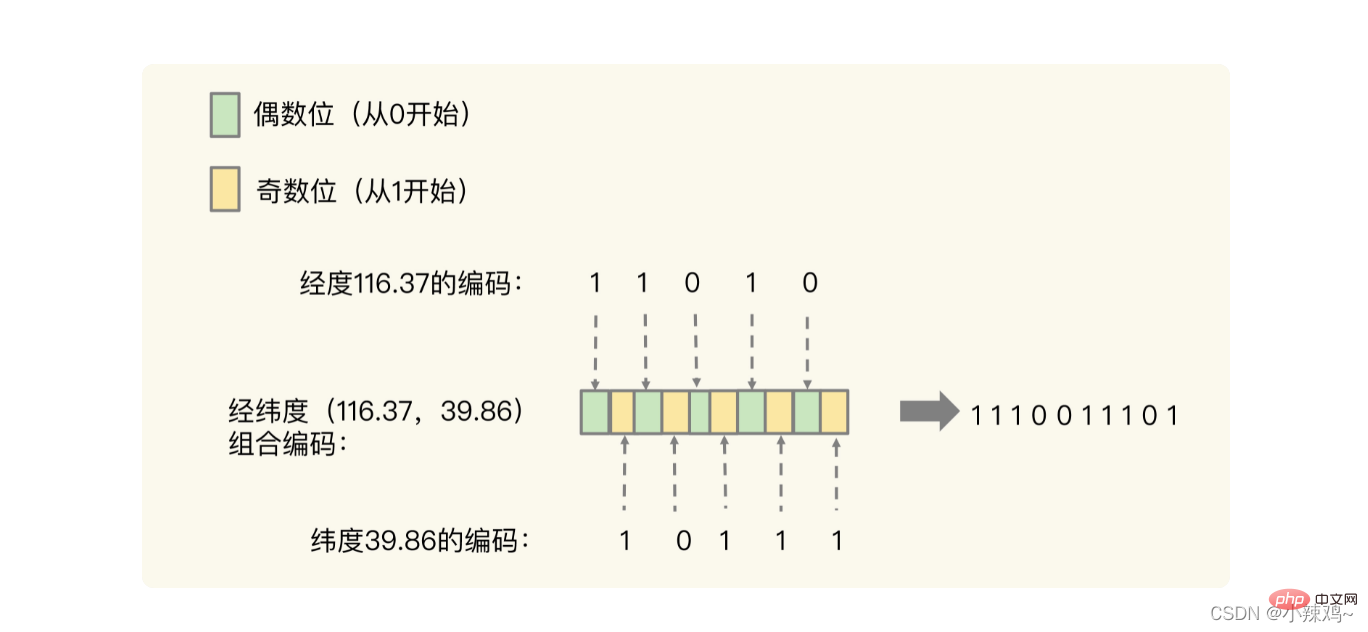
, mais il y aura un codage adjacent, mais les carrés réels sont des situations non adjacentes. Ainsi, afin d'éviter que cette situation ne se produise, on peut interroger 4 ou 8 carrés autour d'une longitude et d'une latitude données en même temps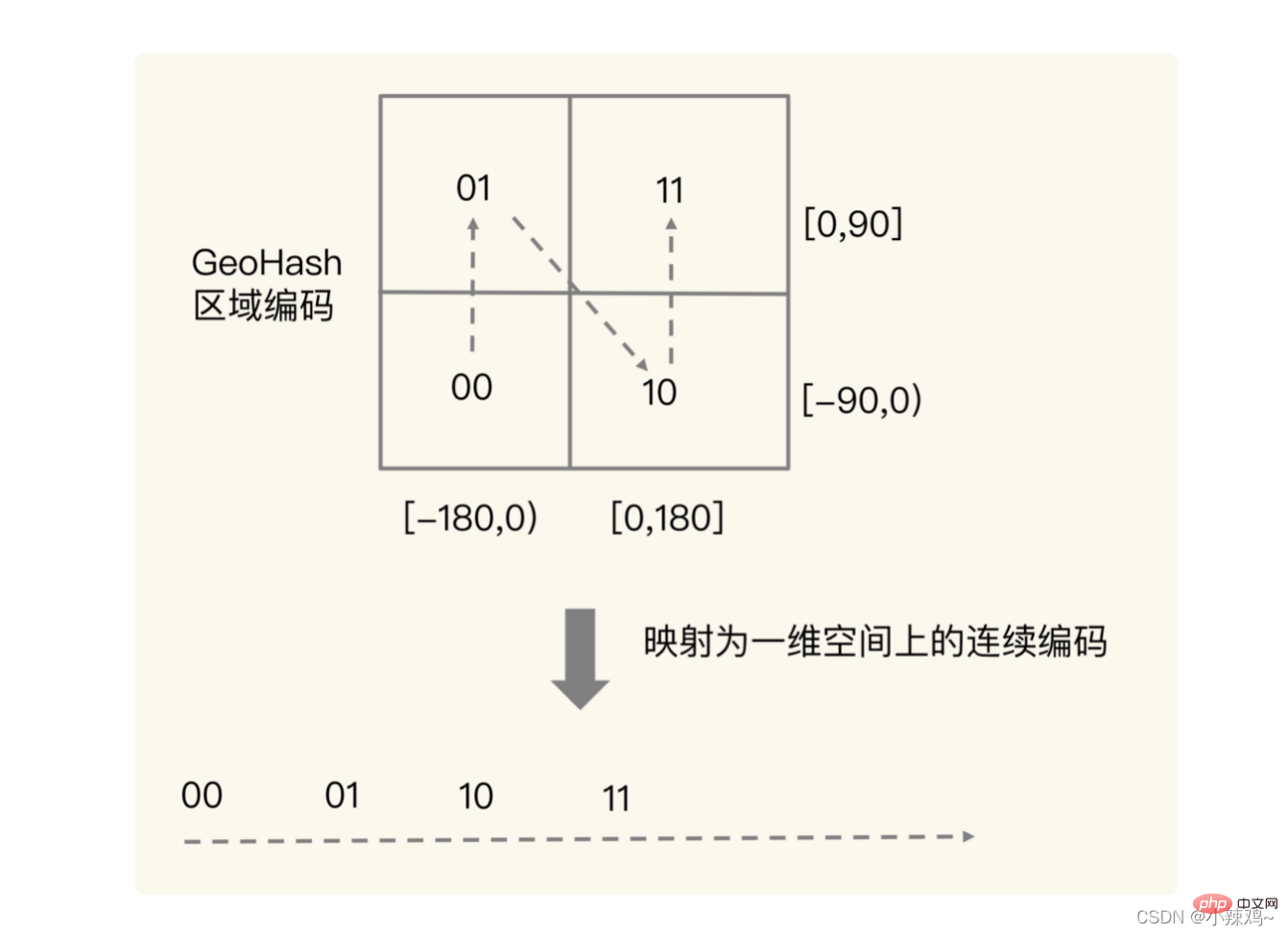
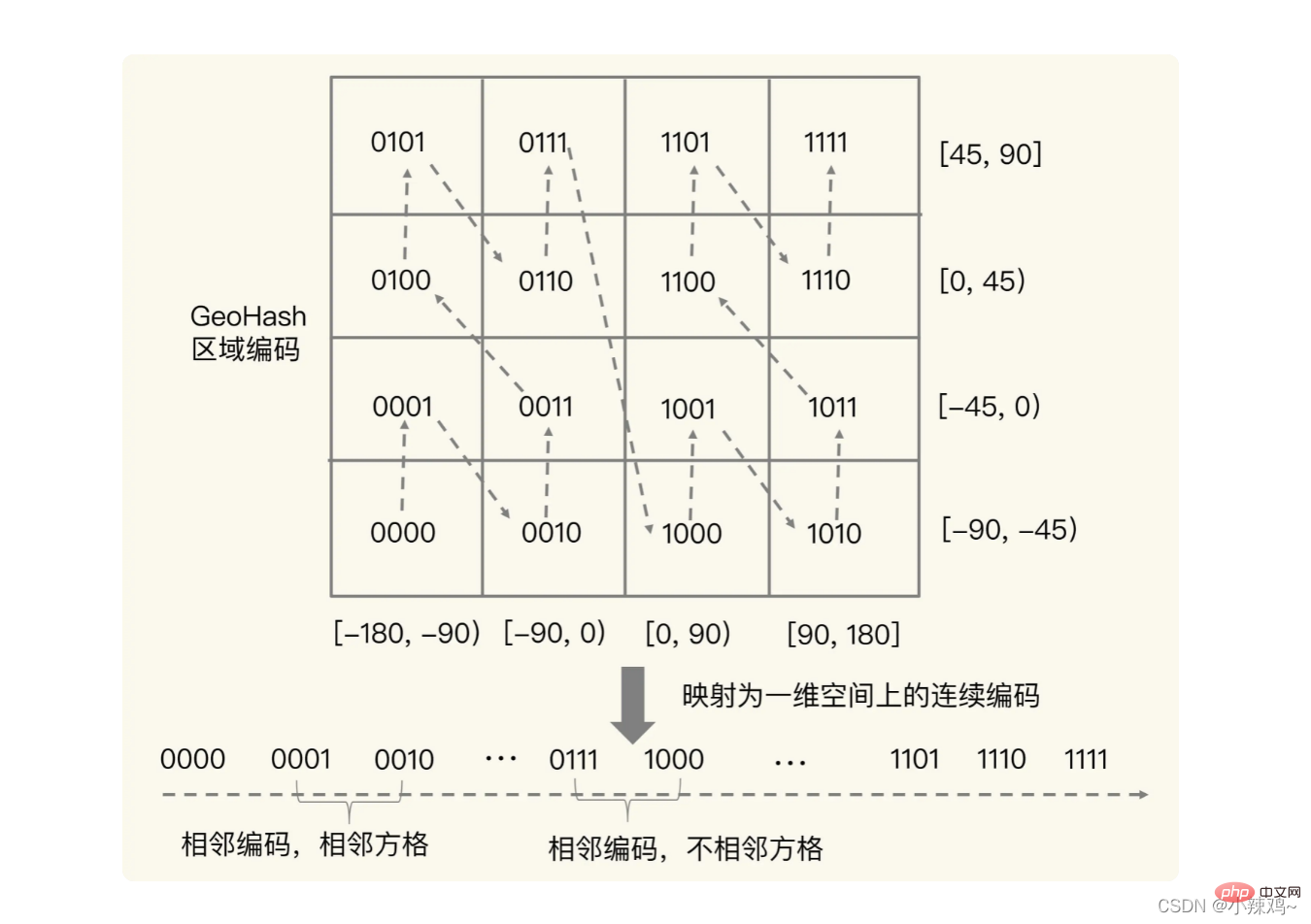 Comment faire fonctionner le type GEO ?
Comment faire fonctionner le type GEO ?
GEOADD : utilisé pour enregistrer un ensemble d'informations de longitude et de latitude et un identifiant correspondant dans une collection de type GEO.
Comment utiliser : supposons que l'ID du véhicule est 33 et que l'emplacement de latitude et de longitude est (116.034579, 39.030452). Nous pouvons utiliser une collection GEO pour enregistrer la latitude et la longitude de tous les véhicules. La clé de collection est cars:locations. Il vous suffit d'exécuter la commande suivante pour enregistrer la position actuelle de longitude et de latitude du véhicule portant le numéro d'identification 33 dans GEO.
GEOADD cars:locations 116.034579 39.030452 33
GEORADIUS : en fonction de l'emplacement de la longitude et de la latitude d'entrée, interrogez d'autres éléments dans une certaine plage centrée sur cette longitude et cette latitude
Comment personnaliser le type de données ?
La structure objet de base de Redis comprend le type, l'encodage, lru et refcount, *ptr
Développer une structure de données nommée NewTypeObject, qui comporte les quatre étapes suivantes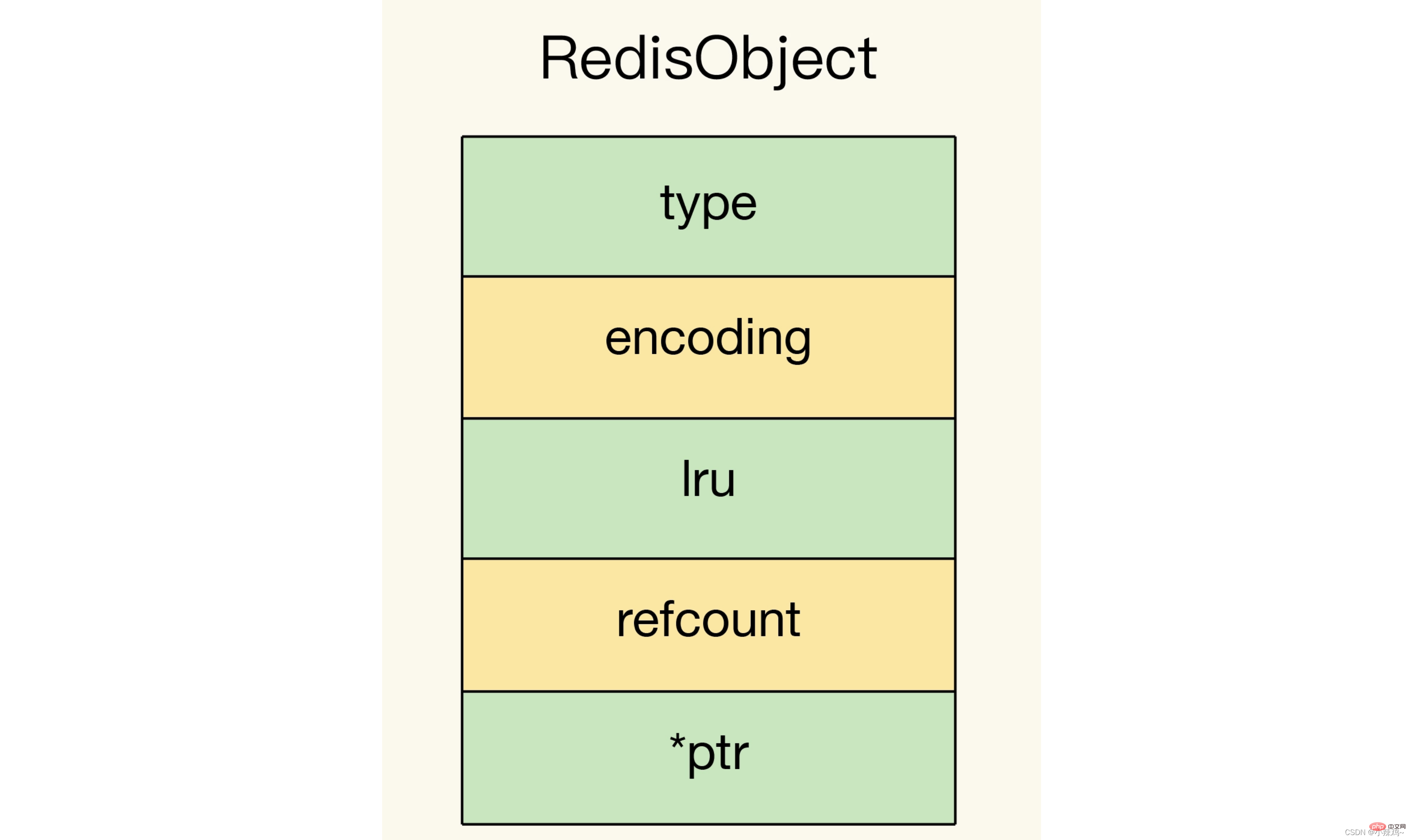
Comment enregistrer les données de séries chronologiques dans Redis ?
1. Sauvegarde basée sur le hachage et l'ensemble trié : pourquoi devrions-nous interroger sur la base de deux structures de données ?
Le type Hash peut réaliser une requête rapide à clé unique, qui répond aux besoins des requêtes à clé unique de séries chronologiques. 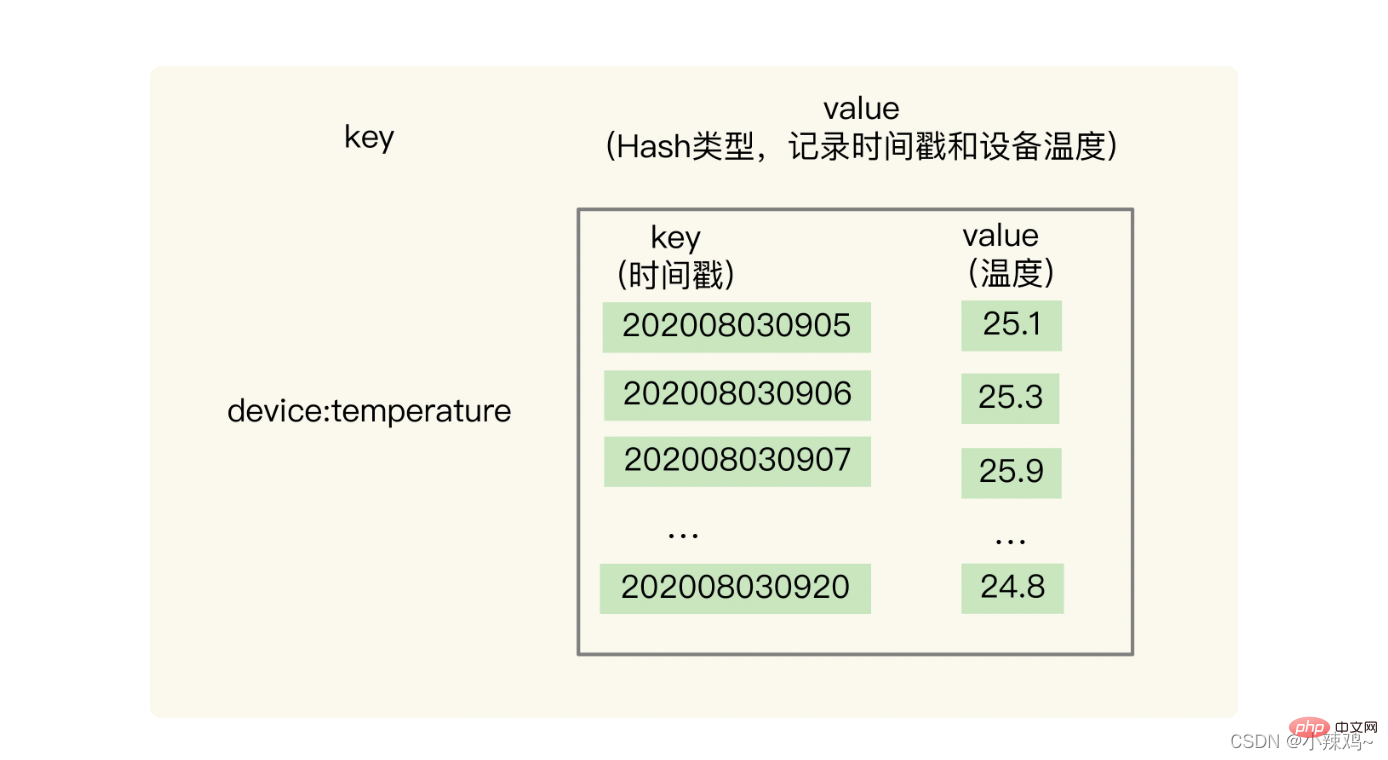
Cependant, le type de hachage présente un inconvénient : il ne prend pas en charge les requêtes de plage d'horodatage. nous devons utiliser Sorted Set car il est trié en fonction du score de poids des éléments, 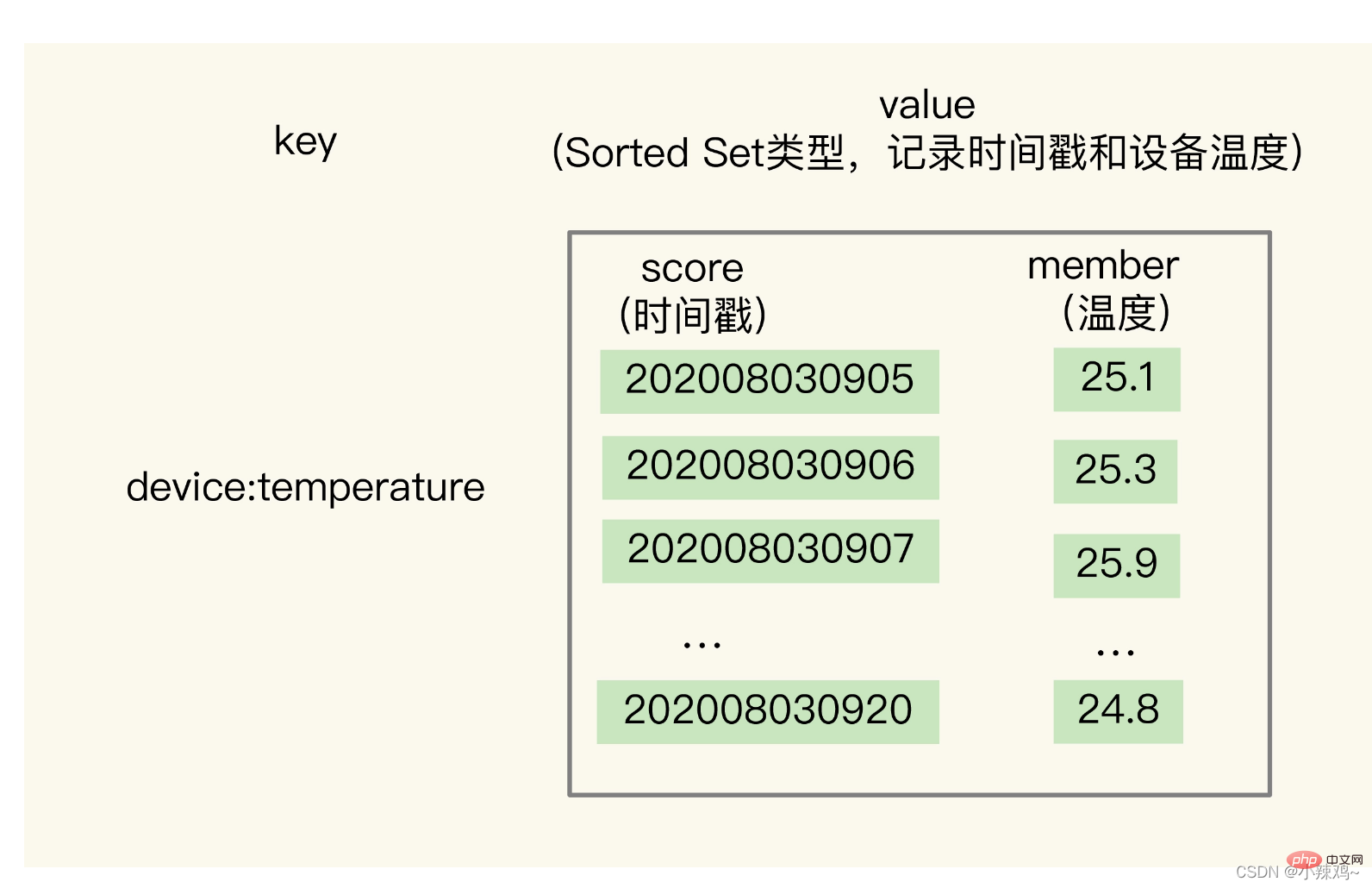
Alors comment assurer l'atomicité de ces deux opérations ?
Vous devez passer deux commandes : MULTI et EXEC :
MULTI signifie démarrer. Après avoir reçu cette commande, redis mettra la commande dans la file d'attente
EXEC signifie fin. Après avoir reçu cette commande, il commencera à exécuter les commandes dans la file d'attente 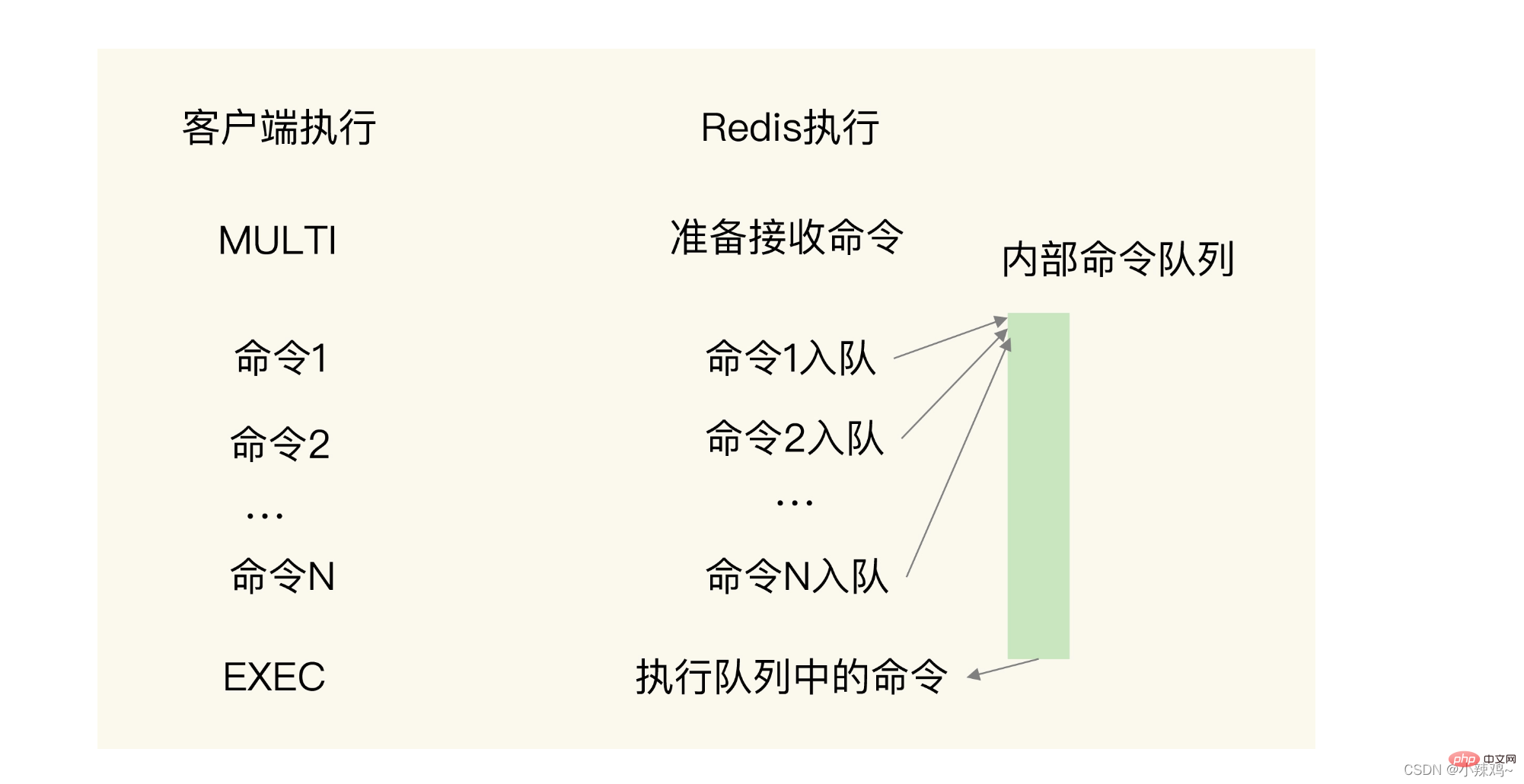 .
.
Mais si l'utilisation du hachage et de l'ensemble trié ne prend en charge que les requêtes de plage, mais pas les calculs agrégés. Si des calculs d'agrégation sont effectués sur le client, une grande quantité de transmission réseau se produira. Par conséquent, des calculs agrégés peuvent être effectués sur Redis via RedisTimeSeries.
Apprentissage recommandé : Tutoriel d'apprentissage Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
