

Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement des problèmes liés à l'architecture de réplication, notamment l'architecture de réplication maître-esclave, l'architecture de réplication en cascade, l'architecture de réplication multi-maître-esclave, etc. J'espère que cela aidera tout le monde.

Apprentissage recommandé : Tutoriel vidéo MySQL
Dans les scénarios d'application réels, plus de 90 % de la réplication MySQL est un modèle architectural dans lequel un maître réplique vers un ou plusieurs esclaves .
Dans un scénario où la pression des requêtes de lecture de la bibliothèque principale est très élevée, vous pouvez configurer l'architecture de réplication à un maître et à plusieurs esclaves pour obtenir une séparation en lecture et en écriture et distribuer un grand nombre de requêtes de lecture qui n'ont pas des exigences en temps réel particulièrement élevées grâce à l'équilibrage de charge sur plusieurs bibliothèques esclaves (les requêtes de lecture avec des exigences en temps réel élevées peuvent être lues à partir de la bibliothèque maître) pour réduire la pression de lecture sur la bibliothèque maître, comme le montre la figure ci-dessous.
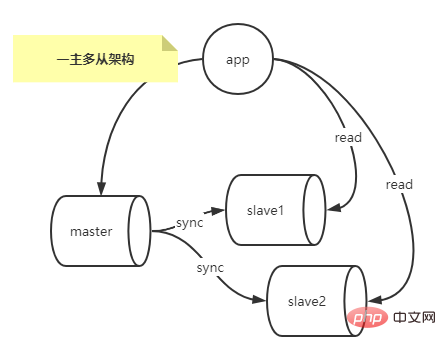
Inconvénients :
Puisque le maître doit être fermé pour une maintenance de routine, alors un esclave doit être converti en maître, sélectionnez Lequel pose problème ?
Lorsqu'un esclave devient maître, les données du maître actuel et du maître précédent sont incohérentes, et le maître précédent n'a pas enregistré le fichier binlog et la position POS du nœud maître actuel.
L'architecture de réplication multi-maître résout le problème de point de défaillance unique du maître dans l'architecture de réplication multi-esclave à maître unique.
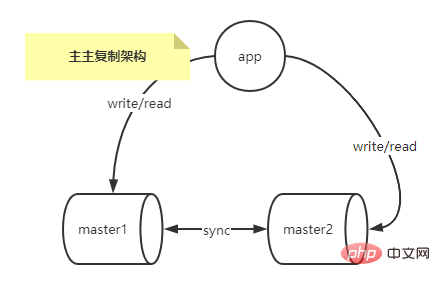
Vous pouvez utiliser un outil tiers, tel que keepalived, pour réaliser facilement une dérive IP, afin que les temps d'arrêt et la maintenance du maître n'affectent pas les opérations d'écriture.
Un maître et plusieurs esclaves. S'il y a trop d'esclaves, la pression d'E/S et la pression du réseau de la bibliothèque principale augmenteront avec l'augmentation des bibliothèques esclaves, car chaque bibliothèque esclave aura un BINLOG indépendant. Le thread de vidage est utilisé pour envoyer des événements, et l'architecture de réplication en cascade résout les E/S supplémentaires et la pression réseau sur la bibliothèque principale dans le scénario maître-multi-esclave.
Comme le montre l'image ci-dessous.
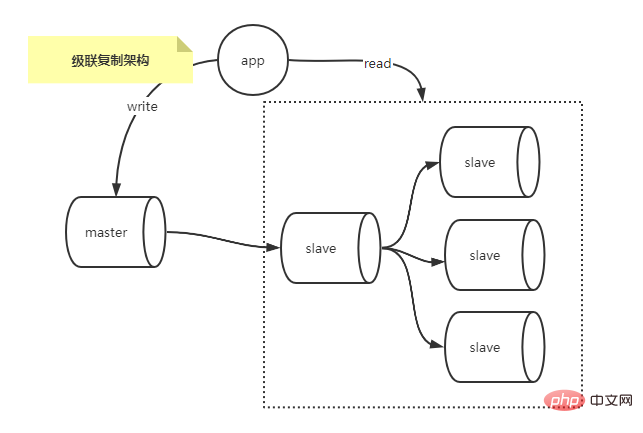
Par rapport à l'architecture un maître-multiple-esclave, la réplication en cascade copie uniquement les données de la base de données maître vers un petit nombre de bases de données esclaves, et d'autres bases de données esclaves copient ensuite les données de ce petit nombre de bases de données esclaves, ainsi alléger la charge de travail de la pression de la base de données maître.
Bien sûr, il y a des inconvénients : la réplication traditionnelle de MySQL est asynchrone. Dans le scénario de réplication en cascade, les données de la base de données maître doivent être répliquées deux fois avant d'atteindre les autres bases de données esclaves. Le délai pendant cette période est comparé à celui d'une base de données maître. scénario de réplication multi-esclave où les données ne sont expérimentées qu'une seule fois. La copie est encore plus volumineuse.
Vous pouvez réduire la latence de la réplication en cascade en sélectionnant le moteur de table comme BLACKHOLE sur l'esclave secondaire. Comme son nom l'indique, le moteur BLACKHOLE est un moteur de « trou noir ». Les données écrites dans la table BLACKHOLE ne seront pas écrites sur le disque. La table BLACKHOLE est toujours une table vide. Les opérations INSERT, UPDATE et DELETE enregistrent uniquement les événements. dans le BINLOG.
Ce qui suit démontre le moteur BLACKHOLE :
mysql> CREATE TABLE `user` (
-> `id` int NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> `name` varchar(255) NOT NULL DEFAULT '',
-> `age` tinyint unsigned NOT NULL DEFAULT 0
-> )ENGINE=BLACKHOLE charset=utf8mb4;Query OK, 0 rows affected (0.00 sec)mysql> INSERT INTO `user` (`name`,`age`) values("itbsl", "26");Query OK, 1 row affected (0.00 sec)mysql> select * from user;Empty set (0.00 sec)Vous pouvez voir qu'il n'y a aucune donnée dans la table utilisateur avec le moteur de stockage de BLACKHOLE.
Combine l'architecture de réplication multi-maître et en cascade, qui résout le problème du maître monopoint et résout le problème du délai de cascade esclave.
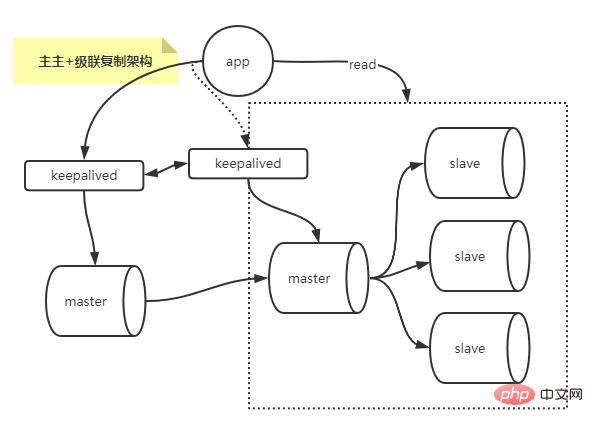
Planification de l'hôte :
Fichier de configuration my.cnf :
$ cat /home/mysql/docker-data/3315/conf/my.cnf [mysqld] character_set_server=utf8 init_connect='SET NAMES utf8' symbolic-links=0 lower_case_table_names=1 server-id=1403314 log-bin=mysql-bin binlog-format=ROW auto_increment_increment=2 # 几个主库,这里就配几 auto_increment_offset=1 # 每个主库的偏移量需要不一致 gtid_mode=ON enforce-gtid-consistency=true binlog-do-db=order # 要同步的数据库
Démarrer docker :
$ docker run --name mysql3314 -p 3314:3306 --privileged=true -ti -e MYSQL_ROOT_PASSWORD=root -e MYSQL_DATABASE=order -e MYSQL_USER=user -e MYSQL_PASSWORD=pass -v /home/mysql/docker-data/3314/conf:/etc/mysql/conf.d -v /home/mysql/docker-data/3314/data/:/var/lib/mysql -v /home/mysql/docker-data/3314/logs/:/var/log/mysql -d mysql:5.7
Ajouter un utilisateur pour la réplication et autoriser :
mysql> GRANT REPLICATION SLAVE,FILE,REPLICATION CLIENT ON *.* TO 'repluser'@'%' IDENTIFIED BY '123456'; Query OK, 0 rows affected, 1 warning (0.01 sec) mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.01 sec)
Démarrer la synchronisation de master1 (l'utilisateur ici vient de master2) :
mysql> change master to master_host='172.23.252.98',master_port=3315,master_user='repluser',master_password='123456',master_auto_position=1; Query OK, 0 rows affected, 2 warnings (0.03 sec) mysql> start slave; Query OK, 0 rows affected (0.00 sec)
La configuration de master2 est similaire à master1.
La principale différence est qu'il y a un attribut dans my.cnf qui doit être incohérent :
auto_increment_offset=2 # 每个主库的偏移量需要不一致
Test :
Créez une table dans master2 et ajoutez des données :
mysql> create table t_order(id int primary key auto_increment, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t_order(name) values("A");
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_order(name) values("B");
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
+----+------+
2 rows in set (0.00 sec)Vous pouvez constater que la taille du pas d'id dans master2 vaut 2, et il commence à partir de 2 augmentations.
Ensuite, interrogez les données dans master1 et ajoutez :
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
+----+------+
2 rows in set (0.00 sec)
mysql> insert into t_order(name) values("E");
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
| 5 | E |
+----+------+
3 rows in set (0.00 sec)Vous pouvez constater que la taille du pas de l'identifiant dans master1 est de 2, et elle commence à augmenter à partir de 1. Ensuite, interrogez les données dans master2 et vous pouvez trouver les données avec id 5, indiquant la configuration de réplication maître-maître. Pas de problème.
Pourquoi les décalages de l'auto-incrémentation de l'identifiant dans les deux maîtres sont-ils différents ? Lorsque les deux maîtres reçoivent la demande d'insertion en même temps, cela peut garantir que l'ID n'est pas en conflit. En fait, cela ne peut garantir que les données insérées n'entrent pas en conflit, mais ne peut pas garantir l'incohérence des données causée par la suppression et la modification.
Ainsi, dans les scénarios d'application réels, un seul maître peut être exposé au client pour garantir la cohérence des données.
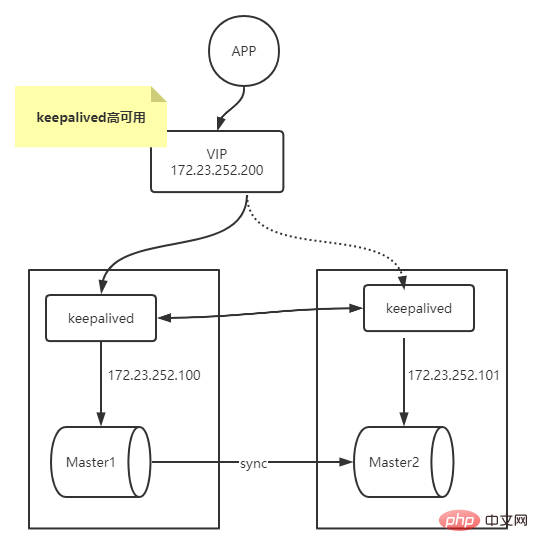
这里借助keepalived来对上面的多主复制架构改造来实现MySQL的高可用。
keepalived的安装:
$ sudo apt-get install -y keepalived
keepalived.conf
$ cat /etc/keepalived/keepalived3314.conf! Configuration File for keepalived#简单的头部,这里主要可以做邮件通知报警等的设置,此处就暂不配置了;global_defs {
#notificationd LVS_DEVEL}#预先定义一个脚本,方便后面调用,也可以定义多个,方便选择;vrrp_script chk_haproxy {
script "/etc/keepalived/chkmysql.sh" #具体脚本路径
interval 2 #脚本循环运行间隔}#VRRP虚拟路由冗余协议配置vrrp_instance VI_1 { #VI_1 是自定义的名称;
state BACKUP #MASTER表示是一台主设备,BACKUP表示为备用设备【我们这里因为设置为开启不抢占,所以都设置为备用】
nopreempt #开启不抢占
interface eth0 #指定VIP需要绑定的物理网卡
virtual_router_id 11 #VRID虚拟路由标识,也叫做分组名称,该组内的设备需要相同
priority 130 #定义这台设备的优先级 1-254;开启了不抢占,所以此处优先级必须高于另一台
advert_int 1 #生存检测时的组播信息发送间隔,组内一致
authentication { #设置验证信息,组内一致
auth_type PASS #有PASS 和 AH 两种,常用 PASS
auth_pass asd #密码
}
virtual_ipaddress {
172.23.252.200 #指定VIP地址,组内一致,可以设置多个IP
}
track_script { #使用在这个域中使用预先定义的脚本,上面定义的
chk_haproxy }
#notify_backup "/etc/init.d/haproxy restart" #表示当切换到backup状态时,要执行的脚本
#notify_fault "/etc/init.d/haproxy stop" #故障时执行的脚本}/etc/keepalived/chkmysql.sh
$ cat /etc/keepalived/chkmysql.s.sh#!/bin/bashmysql -uroot -proot -P 3314 -e "show status;" > /dev/null 2>&1if [ $? == 0 ];then echo "$host mysql login successfully" exit 0else echo "$host login failed" killall keepalived exit 2fi
推荐学习:mysql视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



