
 développement back-end
Tutoriel Python
Introduction détaillée aux points de connaissance de la structure des données Python3
développement back-end
Tutoriel Python
Introduction détaillée aux points de connaissance de la structure des données Python3
Introduction détaillée aux points de connaissance de la structure des données Python3

Cet article vous apporte des connaissances pertinentes sur python Il présente principalement des problèmes liés aux structures de données, notamment les nombres, les chaînes, les listes, les tuples, les dictionnaires, etc.

Apprentissage recommandé : Tutoriel vidéo Python
Nombre Numéro
Type entier (int) - généralement appelé entier ou entier, est un entier positif ou négatif sans point décimal. Les entiers Python3 n'ont pas de limite de taille et peuvent être utilisés comme types Long. Booléen est un sous-type d’entier.
Type à virgule flottante (float) - Le type à virgule flottante se compose d'une partie entière et d'une partie décimale. Le type à virgule flottante peut également être exprimé en utilisant la notation scientifique (2,5e2 = 2,5 x 102 = 250)
Nombre pluriel ( ( (). complexe )) - Un nombre complexe se compose d'une partie réelle et d'une partie imaginaire, qui peuvent être représentées par a + bj, ou complexe(a,b). La partie réelle a et la partie imaginaire b du nombre complexe sont toutes deux flottantes. types de points.
Conversion de type numérique
int(x) Convertit x en un entier.
float(x) Convertit x en un nombre à virgule flottante.
complexe(x) Convertit x en un nombre complexe, la partie réelle étant x et la partie imaginaire étant 0.
complex(x, y) Convertit x et y en un nombre complexe, la partie réelle étant x et la partie imaginaire étant y. x et y sont des expressions numériques.
Opération numérique
# + - * / %(取余) **(幂运算) # 整数除法中,除法 / 总是返回一个浮点数, # 如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 // print(8 / 5) # 1.6 print(8 // 5) # 1 # 注意:// 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系 print(8 // 5.0) # 1.0 # 使用 ** 操作来进行幂运算 print(5 ** 2) # 5的平方 25
String str
Requête de chaîne
index() : Trouvez la première occurrence de la sous-chaîne substr Si la sous-chaîne recherchée n'existe pas, lancez une exception ValueErrorrindex ()
rindex. () : Recherchez la dernière occurrence de la sous-chaîne substr. Si la sous-chaîne recherchée n'existe pas, une exception ValueError() est levée
find() : Recherchez la position de la sous-chaîne substr. une fois. Si la sous-chaîne recherchée n'existe pas, alors -1 est renvoyée.
-
rfind() : Recherchez la position où la sous-chaîne recherchée n'existe pas, alors -1 est renvoyée.
s = 'hello, hello' print(s.index('lo')) # 3 print(s.find('lo')) # 3 print(s.find('k')) # -1 print(s.rindex('lo')) # 10 print(s.rfind('lo')) # 10Copier après la connexionConversion de casse de chaîne
- upper() : Convertit tous les caractères de la chaîne en lettres majuscules
- lower() : Convertit tous les caractères de la chaîne en lettres minuscules
- capitalize() : convertissez le premier caractère en majuscules et convertissez les caractères restants en minuscules
- title() : convertissez le premier caractère de chaque mot en majuscule et convertir les caractères restants de chaque mot en minuscules
-
s = 'hello, Python' print(s.upper()) # HELLO, PYTHON print(s.lower()) # hello, python print(s.swapcase()) # HELLO, pYTHON print(s.capitalize()) # Hello, python print(s.title()) # Hello, Python
Copier après la connexionAlignement des chaînes
- center() : alignement central, le premier paramètre spécifie la largeur et le deuxième paramètre spécifie le remplissage. La valeur par défaut est un espace. Si la largeur définie est inférieure à la largeur réelle, la chaîne d'origine sera renvoyée
- ljust() : aligné à gauche, le premier paramètre spécifie la largeur, le deuxième paramètre Paramètres spécifie le remplissage. , la valeur par défaut est un espace, si la largeur définie est plus petite que la largeur réelle, la chaîne d'origine sera renvoyée
- rjust() : aligné à droite, le premier paramètre spécifie la largeur, le deuxième paramètre spécifie le remplissage, la valeur par défaut est un espace, si la largeur définie est inférieure à la largeur réelle, la chaîne d'origine sera renvoyée
- zfill() : alignée à droite, complétée par 0 à gauche. qui est utilisé pour spécifier la largeur de la chaîne. Si la largeur spécifiée est inférieure ou égale aux caractères. La longueur de la chaîne, renvoie la chaîne elle-même () : Séparer à partir du côté gauche de la chaîne
rsplit() : Séparer à partir du côté gauche de la chaîne Commencez à diviser par la droite
Le caractère de fractionnement par défaut est un espace et la valeur de retour est une liste
Spécifiez le caractère de fractionnement pour diviser la chaîne via le paramètre sep
Spécifiez le nombre maximum de divisions lors de la division de la chaîne de caractères via le paramètre maxsplit , après le nombre maximum de divisions, les sous-chaînes restantes seront utilisées séparément comme partie
s = 'hello,Python'
'''居中对齐'''
print(s.center(20, '*')) # ****hello,Python****
'''左对齐 '''
print(s.ljust(20, '*')) # hello,Python********
print(s.ljust(5, '*')) # hello,Python
'''右对齐'''
print(s.rjust(20, '*')) # ********hello,Python
'''右对齐,使用0进行填充'''
print(s.zfill(20)) # 00000000hello,Python
print('-1005'.zfill(8)) # -0001005s = 'hello word Python'
print(s.split()) # ['hello', 'word', 'Python']
s1 = 'hello|word|Python'
print(s1.split(sep='|')) # ['hello', 'word', 'Python']
print(s1.split('|', 1)) # ['hello', 'word|Python'] # 左侧开始
print(s1.rsplit('|', 1)) # ['hello|word', 'Python'] # 右侧开始isdecimal( ) : Détermine si la chaîne spécifiée est entièrement composée de nombres décimauxisnumeric() : Détermine si la chaîne spécifiée est entièrement composée de nombres
isalnum() : Détermine si la chaîne spécifiée est entièrement composée de lettres et de chiffres
- caractères Chaîne autres opérations
- Remplacement de chaîne
- replace()
s = 'hello,world' print(s[:5]) # hello 从索引0开始,到4结束 print(s[6:]) # world 从索引6开始,到最后一个元素 print(s[1:5:1]) # ello 从索引1开始,到4结束,步长为1 print(s[::2]) # hlowrd 从开始到结束,步长为2 print(s[::-1]) # dlrow,olleh 步长为负数,从最后一个元素(索引-1)开始,到第一个元素结束 print(s[-6::1]) # ,world 从索引-6开始,到最后一个结束
join( )
s = 'hello,Python,Python,Python'
print(s.replace('Python', 'Java')) # 默认全部替换 hello,Java,Java,Java
print(s.replace('Python', 'Java', 2)) # 设置替换个数 hello,Java,Java,Python- % espace réservé : avant la sortie Ajouter %, utiliser des parenthèses et des virgules pour plusieurs paramètres
%s chaîne%i ou %d entier
- -%f nombre à virgule flottante
{} espace réservé : appelez la méthode format()
- f -string : Écrivez la variable dans {}
-
lst = ['hello', 'java', 'Python'] print(','.join(lst)) # hello,java,Python print('|'.join(lst)) # hello|java|PythonCopier après la connexion - Définissez la largeur et la précision du nombre
name = '张三'
age = 20
print('我叫%s, 今年%d岁' % (name, age))
print('我叫{0}, 今年{1}岁,小名也叫{0}'.format(name, age))
print(f'我叫{name}, 今年{age}岁')
# 我叫张三, 今年20岁
# 我叫张三, 今年20岁,小名也叫张三
# 我叫张三, 今年20岁# 设置数字的宽度和精度
'''%占位'''
print('%10d' % 99) # 10表示宽度
print('%.3f' % 3.1415926) # .3f表示小数点后3位
print('%10.3f' % 3.1415926) # 同时设置宽度和精度
'''{}占位 需要使用:开始'''
print('{:.3}'.format(3.1415926)) # .3表示3位有效数字
print('{:.3f}'.format(3.1415926)) # .3f表示小数点后3位
print('{:10.3f}'.format(3.1415926)) # .3f表示小数点后3位
# 99
#3.142
# 3.142
#3.14
#3.142
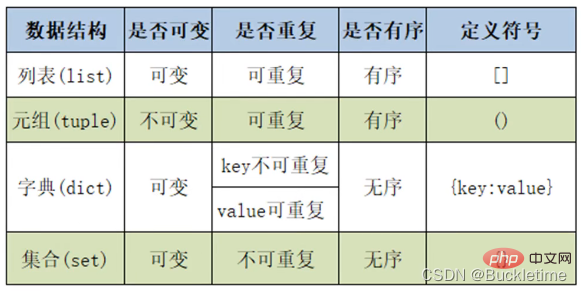
# 3.142可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存
列表的创建
- []:使用中括号
- list():使用内置函数list()
- 列表生成式
语法格式:[i*i for i in range(i, 10)]
-
解释:i表示自定义变量,i*i表示列表元素的表达式,range(i, 10)表示可迭代对象
print([i * i for i in range(1, 10)])# [1, 4, 9, 16, 25, 36, 49, 64, 81]
Copier après la connexion
列表元素的查询
- 判断指定元素在列表中是否存在
in / not in
- 列表元素的遍历
for item in list: print(item)
- 查询元素索引
list.index(item)
- 获取元素
list = [1, 4, 9, 16, 25, 36, 49, 64, 81]print(list[3]) # 16print(list[3:6]) # [16, 25, 36]
列表元素的增加
append():在列表的末尾添加一个元素
extend():在列表的末尾至少添加一个元素
insert0:在列表的指定位置添加一个元素
切片:在列表的指定位置添加至少一个元素
列表元素的删除
rerove():一次删除一个元素,
重复元素只删除第一个,
元素不存在抛出ValceError异常pop():删除一个指定索引位置上的元素,
指定索引不存在抛出IndexError异常,
不指定索引,删除列表中最后一个元素切片:一次至少删除一个元素
clear0:清空列表
del:删除列表
列表元素的排序
- sort(),列表中的所有元素默认按照从小到大的顺序进行排序,可以指定reverse= True,进行降序排序,是对原列表的操作。
list.sort()
- sorted(),可以指定reverse—True,进行降序排序,原列表不发生改变,产生新的列表。
sorted(list)
知识点总结
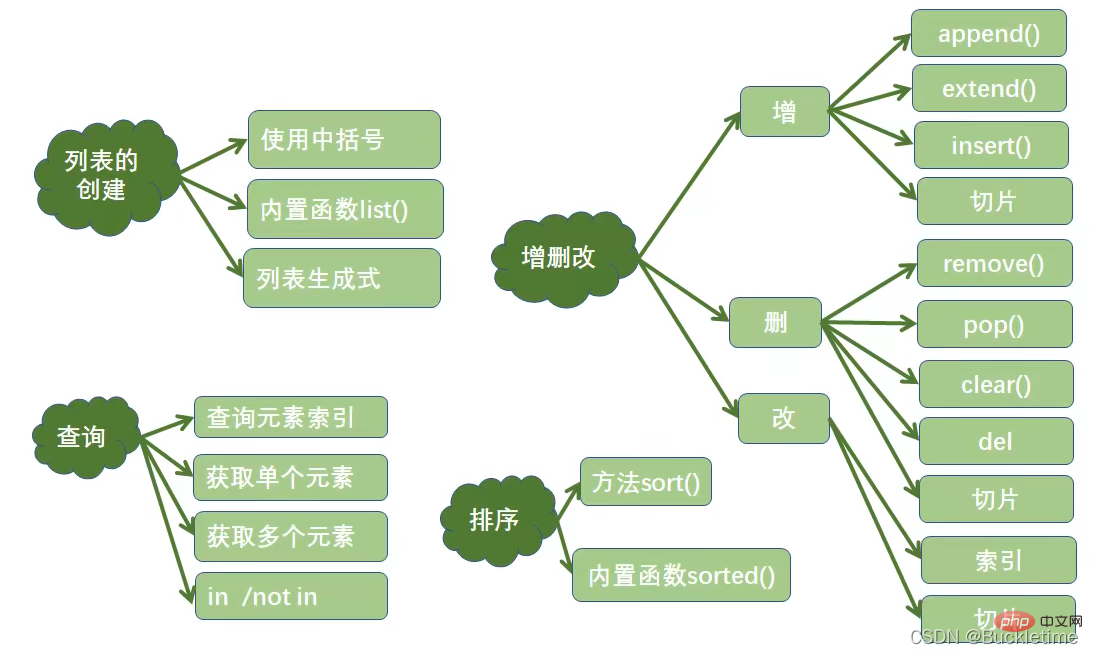
元组 tuple
元组的特点
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号
元组的创建
- 直接使用小括号(), 小括号可以省略
t = ('Python', 'hello', 90)- 使用内置函数tuple(), 若有多个元素必须加小括号
tuple(('Python', 'hello', 90))- 只包含一个元素的元组,需要使用小括号和逗号
t = (10,)
知识点总结
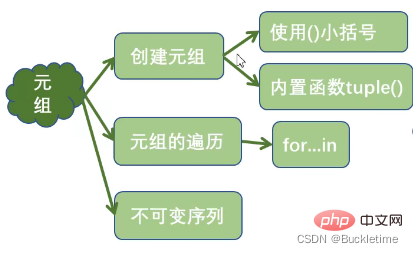
字典 dict
字典的特点
- 以键值对的方式存储,key唯一
- key必须是不可变对象
- 字典是可变序列
- 字典是无序序列 (注意:自Python3.7本后,dict 对象的插入顺序保留性质已被声明为 Python 语言规范的正式部分。即,Python3.7之后,字典是有序序列,顺序为字典的插入顺序)
字典的创建
- {}:使用花括号
- 使用内置函数dict()
- zip():字典生成式
items = ['fruits', 'Books', 'Others']
prices = [12, 36, 44]
d = {item.upper(): price for item, price in zip(items, prices)}
print(d) # {'FRUITS': 12, 'BOOKS': 36, 'OTHERS': 44}字典元素的获取
- []:[]取值
scores[‘张三’],若key不存在,抛出keyError异常 - get():get()方法取值,若key不存在,返回None,还可以设置默认返回值
字典元素的新增
user = {"id": 1, "name": "zhangsan"}
user["age"] = 25
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 25}字典元素的修改
user = {"id": 1, "name": "zhangsan", "age": 25}
user["age"] = 18
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 18}字典元素的删除
- del :删除指定的键值对或者删除字典
user = {"id": 1, "name": "zhangsan"}del user["id"]print(user) # {'name': 'zhangsan'}del user- claer():清空字典中的元素
user = {"id": 1, "name": "zhangsan"}user.clear()print(user) # {}获取字典视图
- keys():获取字典中所有key
- values():获取字典中所有value
- items():获取字典中所有key,value键值对
字典元素的遍历
- 遍历key,再通过key获取value
scores = {'张三': 100, '李四': 95, '王五': 88}for name in scores:
print(name, scores[name])- 通过items()方法,同时遍历key,value
scores = {'张三': 100, '李四': 95, '王五': 88}for name, score in scores.items():
print(name, score)知识点总结

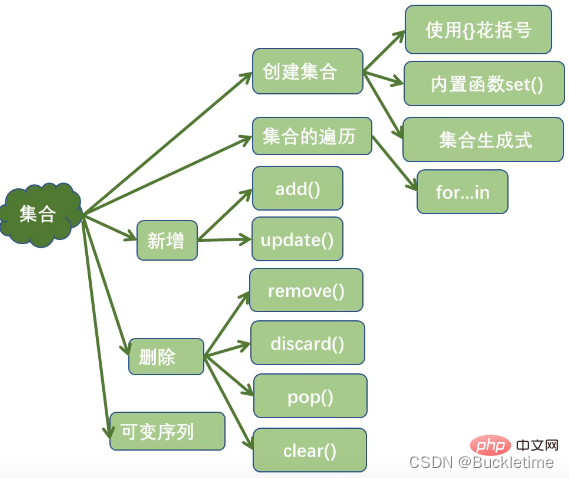
集合 set
集合的特点
- 集合是可变序列
- 集合是没有value的字典
- 集合中元素不重复
- 集合中元素是无序的
集合的创建
- {}
s = {'Python', 'hello', 90}- 内置函数set()
print(set("Python"))print(set(range(1,6)))print(set([3, 4, 7]))print(set((3, 2, 0)))print(set({"a", "b", "c"}))# 定义空集合:set()print(set())- 集合生成式
print({i * i for i in range(1, 10)})# {64, 1, 4, 36, 9, 16, 49, 81, 25}集合的操作
- 集合元素的判断操作
- in / not in
- 集合元素的新增操作
- add():一次添中一个元素
- update(:)添加多个元素
- 集合元素的删除操作
- remove():删除一个指定元素,如果指定的元素不存在抛出KeyError
- discard(:)删除一个指定元素,如果指定的元素不存在不抛异常
- pop():随机删除一个元素
- clear():清空集合
集合间的关系
两个集合是否相等:可以使用运算符 == 或 != 进行判断,只要元素相同就相等
一个集合是否是另一个集合的子集:issubset()
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {10, 70}print(s2.issubset(s1))
# Trueprint(s3.issubset(s1)) # False- 一个集合是否是另一个集合的超集:issuperset()
print(s1.issuperset(s2)) # Trueprint(s1.issuperset(s3)) # False
- 两个集合是否无交集:isdisjoint()
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {20, 70}print(s1.isdisjoint(s2))
# False 有交集print(s3.isdisjoint(s2)) # True 无交集集合的数学操作
- 交集: intersection() 与 &等价,两个集合的交集
s1 = {10, 20, 30, 40}s2 = {20, 30, 40, 50, 60}print(s1.intersection(s2)) # {40, 20, 30}print(s1 & s2) # {40, 20, 30}- 并集: union() 与 | 等价,两个集合的并集
print(s1.union(s2)) # {40, 10, 50, 20, 60, 30}print(s1 | s2) # {40, 10, 50, 20, 60, 30}- 差集: difference() 与 - 等价
print(s2.difference(s1)) # {50, 60}print(s2 - s1) # {50, 60}- 对称差集:symmetric_difference() 与 ^ 等价
print(s2.symmetric_difference(s1)) # {10, 50, 60}print(s2 ^ s1) # {10, 50, 60}知识点总结
列表、元组、字典、集合总结
推荐学习:python教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
En ce qui concerne le problème de la suppression de l'interpréteur Python qui est livré avec des systèmes Linux, de nombreuses distributions Linux préinstalleront l'interpréteur Python lors de l'installation, et il n'utilise pas le gestionnaire de packages ...
 Comment résoudre le problème de la détection de type pylance des décorateurs personnalisés dans Python?
Apr 02, 2025 am 06:42 AM
Comment résoudre le problème de la détection de type pylance des décorateurs personnalisés dans Python?
Apr 02, 2025 am 06:42 AM
Solution de problème de détection de type pylance Lorsque vous utilisez un décorateur personnalisé dans la programmation Python, le décorateur est un outil puissant qui peut être utilisé pour ajouter des lignes ...
 La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
À propos de Pythonasyncio ...
 Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Utilisation de Python dans Linux Terminal ...
 Python 3.6 Chargement du fichier de cornichon MODULENOTFOUNDERROR: Que dois-je faire si je charge le fichier de cornichon '__builtin__'?
Apr 02, 2025 am 06:27 AM
Python 3.6 Chargement du fichier de cornichon MODULENOTFOUNDERROR: Que dois-je faire si je charge le fichier de cornichon '__builtin__'?
Apr 02, 2025 am 06:27 AM
Chargement du fichier de cornichon dans Python 3.6 Erreur d'environnement: modulenotFounonError: NomoduLenamed ...
 FastAPI et AIOHTTP partagent-ils la même boucle d'événements mondiaux?
Apr 02, 2025 am 06:12 AM
FastAPI et AIOHTTP partagent-ils la même boucle d'événements mondiaux?
Apr 02, 2025 am 06:12 AM
Problèmes de compatibilité entre les bibliothèques asynchrones Python dans Python, la programmation asynchrone est devenue le processus de concurrence élevée et d'E / S ...
 Comment s'assurer que le processus de l'enfant se termine également après avoir tué le processus parent via le signal dans Python?
Apr 02, 2025 am 06:39 AM
Comment s'assurer que le processus de l'enfant se termine également après avoir tué le processus parent via le signal dans Python?
Apr 02, 2025 am 06:39 AM
Le problème et la solution du processus enfant continuent d'exécuter lors de l'utilisation de signaux pour tuer le processus parent. Dans la programmation Python, après avoir tué le processus parent à travers des signaux, le processus de l'enfant est toujours ...
 Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Chargement des fichiers de cornichons dans Python 3.6 Rapport de l'environnement Erreur: modulenotFoundError: NomoduLenamed ...
