

MySQL résume le principe MVCC d'InnoDB

Cet article vous apporte des connaissances pertinentes sur mysql, qui introduit principalement les problèmes liés au principe MVCC d'InnoDB MVCC est un contrôle de concurrence multi-version, principalement pour améliorer les performances de concurrence de la base de données. j'espère que cela aide tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
MVCC signifie Multi-Version Concurrency Control, qui est un contrôle de concurrence multi-version, principalement destiné à améliorer les performances de concurrence de la base de données. Lorsqu'une demande de lecture ou d'écriture se produit pour la même ligne de données, elle sera verrouillée et bloquée. Mais MVCC utilise une meilleure façon de gérer les requêtes de lecture-écriture, de sorte qu'aucun verrouillage ne se produise lorsqu'un conflit de requêtes de lecture-écriture se produit. Cette lecture fait référence à la lecture de l'instantané, et non à la lecture actuelle. La lecture actuelle est une opération de verrouillage et est un verrou pessimiste. Alors, comment parvient-il à lire et à écrire sans verrouillage ? Que signifient la lecture d'instantané et la lecture actuelle ? Nous l’apprendrons tous plus tard.
MySQL peut largement éviter les problèmes de lecture fantôme sous le niveau d'isolement REPEATABLE READ. Comment MySQL fait-il cela ?
Chaîne de versions
Nous savons que pour les tables utilisant le moteur de stockage InnoDB, ses enregistrements d'index cluster contiennent deux colonnes cachées nécessaires (row_id n'est pas nécessaire, la table que nous avons créée a une clé primaire ou une clé UNIQUE non NULL le fera n'inclut pas la colonne row_id) :
trx_id : chaque fois qu'une transaction modifie un enregistrement d'index clusterisé, l'identifiant de la transaction sera attribué à la colonne cachée trx_id.
roll_pointer : chaque fois qu'un enregistrement d'index clusterisé est modifié, l'ancienne version sera écrite dans le journal d'annulation. Cette colonne cachée équivaut à un pointeur, qui peut être utilisé pour trouver l'enregistrement avant les informations de modification.
Pour illustrer ce problème, nous créons une table de démonstration :
CREATE TABLE `teacher` ( `number` int(11) NOT NULL, `name` varchar(100) DEFAULT NULL, `domain` varchar(100) DEFAULT NULL, PRIMARY KEY (`number`)) ENGINE=InnoDB DEFAULT CHARSET=utf8
Insérons ensuite une donnée dans cette table :
mysql> insert into teacher values(1, 'J', 'Java');Query OK, 1 row affected (0.01 sec)
Les données ressemblent maintenant à ceci :
mysql> select * from teacher; +--------+------+--------+ | number | name | domain | +--------+------+--------+ | 1 | J | Java | +--------+------+--------+ 1 row in set (0.00 sec)
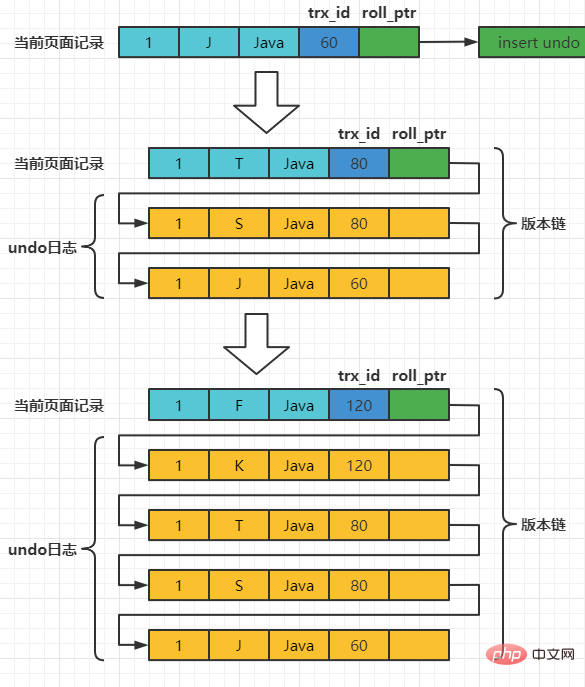
Supposons que l'ID de transaction d'insertion de l'enregistrement est 60 , alors le diagramme schématique de l'enregistrement à ce moment est le suivant :

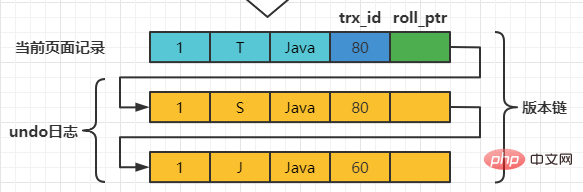
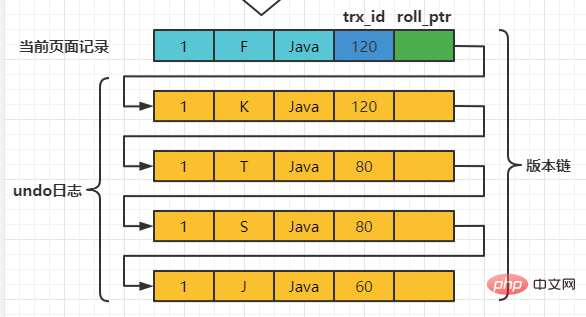
Supposons que deux transactions avec les ID de transaction 80 et 120 effectuent des opérations de MISE À JOUR sur cet enregistrement. Le processus d'opération est le suivant :
| Trx80 | Trx120 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| begin | ||||||||||
| begin | ||||||||||
| mettre à jour le nom de l'enseignant = 'S' où numéro = 1; | ||||||||||
| mettre à jour le professeur définir le nom = 'T' où numéro = 1; ; | ||||||||||
| commit |
| T1 | T2 |
|---|---|
| begin; | |
| sélectionner * de l'enseignant où nombre=30 ; | |
|
insérer dans les valeurs de l'enseignant (30, 'X', 'Java') ; enseignant où nombre = 30 ; a des données |
|
|
Eh bien, que se passe-t-il ? La transaction T1 présente évidemment un phénomène de lecture fantôme. Sous le niveau d'isolement REPEATABLE READ, T1 génère un ReadView lors de la première exécution d'une instruction SELECT normale, puis T2 insère un nouvel enregistrement dans la table professeur et le soumet. ReadView ne peut pas empêcher T1 d'exécuter l'instruction UPDATE ou DELETE pour modifier l'enregistrement nouvellement inséré (puisque T2 a déjà soumis, la modification de l'enregistrement ne provoquera pas de blocage), mais de cette façon, la valeur de la colonne cachée trx_id de ce nouvel enregistrement sera be Cela devient l'identifiant de transaction de T1. Après cela, T1 peut voir cet enregistrement lorsqu'il utilise une instruction SELECT ordinaire pour interroger cet enregistrement et peut renvoyer cet enregistrement au client. Du fait de l'existence de ce phénomène particulier, on peut aussi penser que MVCC ne peut pas interdire complètement la lecture fantôme. Résumé MVCCNous pouvons voir dans la description ci-dessus que ce que l'on appelle MVCC (Multi-Version ConcurrencyControl, contrôle de concurrence multi-version) fait référence à l'utilisation des deux niveaux d'isolement de READ COMMITTD et REPEATABLE READ pour exécuter des transactions ordinaires. L'opération SELECT est le processus d'accès à la chaîne de versions enregistrées. Cela permet aux opérations de lecture-écriture et d'écriture-lecture de différentes transactions d'être exécutées simultanément, améliorant ainsi les performances du système. Une grande différence entre les deux niveaux d'isolement de READ COMMITTD et REPEATABLE READ est que le moment de génération de ReadView est différent. READ COMMITTD générera un ReadView avant chaque opération SELECT ordinaire, tandis que REPEATABLE READ ne générera un ReadView que pour la première fois. . Générez simplement un ReadView avant l'opération SELECT et réutilisez ce ReadView pour les opérations de requête ultérieures, évitant ainsi fondamentalement le phénomène de lecture fantôme. Nous avons dit auparavant que l'exécution d'une instruction DELETE ou d'une instruction UPDATE qui met à jour la clé primaire ne supprimera pas immédiatement l'enregistrement correspondant de la page, mais effectuera ce qu'on appelle l'opération de suppression de marque, ce qui équivaut à simplement définir un. supprimer l'indicateur sur l'enregistrement. Ceci est principalement pour MVCC. De plus, ce qu'on appelle MVCC ne prend effet que lorsque nous effectuons des requêtes SEELCT ordinaires. Toutes les instructions SELECT que nous avons vues jusqu'à présent sont des requêtes ordinaires. Quant à ce qu'est une requête extraordinaire, nous en reparlerons plus tard. Apprentissage recommandé : Tutoriel vidéo mysql |
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
