

Cet article vous apporte des connaissances pertinentes sur python, qui présente principalement les problèmes liés au développement de robots multithread et aux algorithmes de recherche courants. Examinons-le ensemble, j'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Python
Après avoir maîtrisé les requêtes et les expressions régulières, vous pouvez commencer à explorer réellement certaines URL simples.
Cependant, le robot d'exploration n'a actuellement qu'un seul processus et un seul thread, c'est pourquoi on l'appelle un robot d'exploration à un seul thread . Les robots d'exploration monothread ne visitent qu'une page à la fois et ne peuvent pas utiliser pleinement la bande passante réseau de l'ordinateur. Une page ne fait que quelques centaines de Ko au maximum. Ainsi, lorsqu'un robot explore une page, la vitesse supplémentaire du réseau et le temps entre le lancement de la requête et l'obtention du code source sont gaspillés. Si le robot d'exploration peut accéder à 10 pages en même temps, cela équivaut à augmenter la vitesse d'exploration de 10 fois. Pour atteindre cet objectif, vous devez utiliser la technologie multi-thread.
Le langage Python dispose d'un Global Interpreter Lock (GIL). Cela fait que le multi-threading de Python est un pseudo-multi-threading, c'est-à-dire qu'il s'agit essentiellement d'un thread, mais ce thread ne fait chaque chose que pendant quelques millisecondes. Après quelques millisecondes, il enregistre la scène et fait d'autres choses, et. puis fait autre chose après quelques millisecondes. Après un tour, revenez à la première chose, reprenez la scène, travaillez pendant quelques millisecondes et continuez à changer... Un seul thread à l'échelle micro, c'est comme faire plusieurs choses à la fois. en même temps à une échelle macro. Ce mécanisme a peu d'impact sur les opérations gourmandes en E/S (Entrée/Sortie, entrée/sortie), mais sur les opérations gourmandes en calculs CPU, puisqu'un seul cœur du CPU peut être utilisé, il aura un impact significatif sur les performances. impact. Par conséquent, si vous êtes impliqué dans des programmes gourmands en calcul, vous devez utiliser plusieurs processus. Les multi-processus de Python ne sont pas affectés par le GIL. Les robots d'exploration sont des programmes gourmands en E/S, donc l'utilisation du multithreading peut considérablement améliorer l'efficacité de l'exploration.
multiprocessing lui-même est la bibliothèque multiprocessus de Python, utilisée pour gérer les opérations liées aux multiprocessus. Cependant, étant donné que les ressources de mémoire et de pile ne peuvent pas être partagées directement entre les processus et que le coût de démarrage d'un nouveau processus est bien supérieur à celui des threads, l'utilisation de plusieurs threads pour l'analyse présente plus d'avantages que l'utilisation de plusieurs processus.
Il existe un module factice sous multitraitement, qui permet aux threads Python d'utiliser diverses méthodes de multitraitement.
Il existe une classe Pool sous factice, qui est utilisée pour implémenter le pool de threads.
Ce pool de threads possède une méthode map(), qui permet à tous les threads du pool de threads d'exécuter une fonction "simultanément".
Par exemple :
Après avoir appris la boucle for
for i in range(10): print(i*i)
Cette façon d'écrire peut certes donner des résultats, mais le code est calculé un par un, ce qui n'est pas très efficace. Si vous utilisez la technologie multi-threading pour permettre au code de calculer les carrés de plusieurs nombres en même temps, vous devez utiliser multiprocessing.dummy pour y parvenir :
Exemple d'utilisation du multi-threading :
from multiprocessing.dummy import Pooldef cal_pow(num):
return num*num
pool=Pool(3)num=[x for x in range(10)]result=pool.map(cal_pow,num)print('{}'.format(result))Dans le code ci-dessus , définit d'abord une fonction utilisée pour calculer des carrés, puis initialise un pool de threads avec 3 threads. Ces trois fils sont chargés de calculer le carré de 10 nombres. Celui qui finit de calculer le nombre disponible en premier prendra le nombre suivant et continuera à calculer jusqu'à ce que tous les nombres soient calculés.
Dans cet exemple, La méthode map() du pool de threads reçoit deux paramètres Le premier paramètre est le nom de la fonction et le deuxième paramètre est une liste. Remarque : Le premier paramètre est uniquement le nom de la fonction et ne peut pas contenir de parenthèses. Le deuxième paramètre est un objet itérable. Chaque élément de cet objet itérable sera reçu en paramètre par la fonction clac_power2(). En plus des listes, des tuples, des ensembles ou des dictionnaires peuvent être utilisés comme deuxième paramètre de map().
Étant donné que les robots d'exploration sont des opérations gourmandes en E/S, en particulier lors de la demande de code source de page Web, si vous utilisez un seul thread pour développer, vous perdrez beaucoup de temps à attendre le retour de la page Web. , donc multi-threading L'application de la technologie aux robots d'exploration peut grandement améliorer l'efficacité opérationnelle des robots d'exploration. Donnez un exemple. Il faut 50 minutes pour laver les vêtements dans la machine à laver, 15 minutes pour faire bouillir de l'eau dans la bouilloire et 1 heure pour mémoriser du vocabulaire. Si vous attendez que la machine à laver lave d'abord les vêtements, puis faites bouillir l'eau une fois les vêtements lavés, puis récitez le vocabulaire une fois l'eau bouillie, cela prendra un total de 125 minutes.
Mais si vous le dites autrement, en regardant les choses dans leur ensemble, 3 choses peuvent fonctionner en même temps. Supposons que vous ayez soudainement deux autres personnes qui sont chargées de mettre les vêtements dans la machine à laver et d'attendre. la machine à laver pour finir, et l'autre personne Vous êtes responsable de faire bouillir l'eau et d'attendre qu'elle bout, et il vous suffit de mémoriser les mots. Lorsque l’eau bout, le clone responsable de l’ébullition de l’eau disparaît en premier. Lorsque la machine à laver a fini de laver les vêtements, le clone responsable du lavage des vêtements disparaît. Enfin, vous mémorisez vous-même les mots. Cela ne prend que 60 minutes pour réaliser 3 choses en même temps.
Bien sûr, vous constaterez certainement que l’exemple ci-dessus n’est pas la situation réelle de la vie. En réalité, personne n’est séparé. Ce qui se passe dans la vraie vie, c'est que lorsque les gens mémorisent des mots, ils se concentrent sur leur mémorisation ; lorsque l'eau bout, la bouilloire émet un son pour vous rappeler que lorsque les vêtements sont lavés, la machine à laver émet un son « didi » ; . Il suffit donc de prendre les mesures correspondantes lorsque le rappel arrive. Il n'est pas nécessaire de vérifier toutes les minutes. Les deux différences ci-dessus sont en fait les différences entre les modèles asynchrones multithread et pilotés par événements. Cette section parle des opérations multithread, et nous parlerons plus tard du framework de robot utilisant des opérations asynchrones. Il vous suffit maintenant de vous rappeler que lorsque le nombre d'actions à effectuer n'est pas important, il n'y a pas de différence dans les performances des deux méthodes, mais une fois que le nombre d'actions augmente de manière significative, l'amélioration de l'efficacité du multithread sera diminuer, encore pire que le single-threading. Et à ce moment-là, seules les opérations asynchrones constituent la solution au problème.
Les deux morceaux de code suivants sont utilisés pour comparer les différences de performances entre les robots d'exploration monothread et les robots multithread pour explorer la page d'accueil de bd : 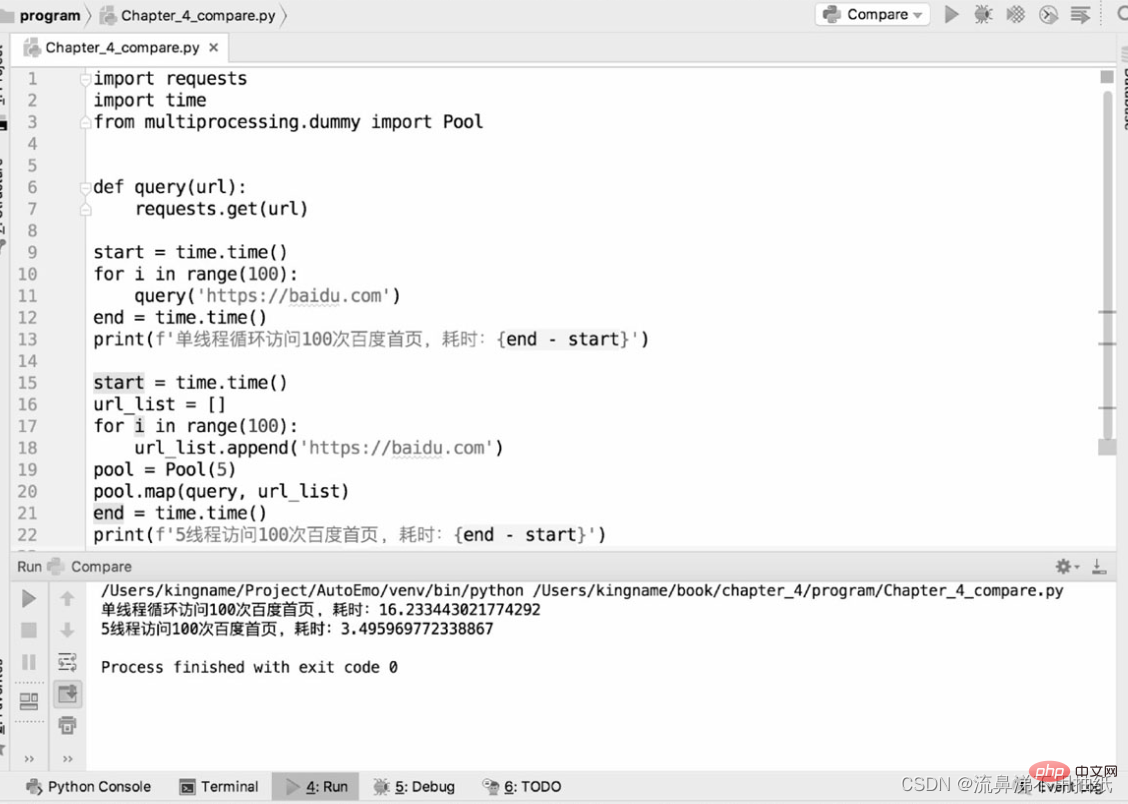
D'après les résultats d'exécution, nous pouvons voir qu'un thread prend environ 16,2 secondes, et 5 threads prennent environ 3,5 secondes. Le temps est environ un cinquième de celui d'un seul thread. Vous pouvez également voir l'effet de 5 threads "exécutés simultanément" du point de vue temporel. Mais cela ne signifie pas que plus le pool de threads est grand, mieux c'est. Les résultats ci-dessus montrent également que le temps d'exécution de cinq threads est en réalité un peu plus d'un cinquième du temps d'exécution d'un thread. Le point supplémentaire est en fait le moment du changement de thread. Cela reflète également le fait que le multithreading de Python est toujours en série au niveau micro. Par conséquent, si le pool de threads est trop grand, la surcharge provoquée par le changement de thread peut compenser l'amélioration des performances apportée par le multithreading. La taille du pool de threads doit être déterminée en fonction de la situation réelle et il n'existe pas de données exactes. Les lecteurs peuvent définir différentes tailles à des fins de test et de comparaison dans des scénarios d'application spécifiques afin de trouver les données les plus appropriées.
La classification des cours d'un site Web d'éducation en ligne nécessite d'explorer les informations de cours ci-dessus. Dès la page d'accueil, les cours sont répartis en plusieurs grandes catégories, comme Python, Node.js et Golang selon la langue. Il existe de nombreux cours dans chaque grande catégorie, comme les robots d'exploration, Django et l'apprentissage automatique sous Python. Chaque cours est divisé en plusieurs heures de cours.
Dans le cas d'une recherche en profondeur d'abord, l'itinéraire d'exploration est comme indiqué sur la figure (numéro de série de petit à grand) 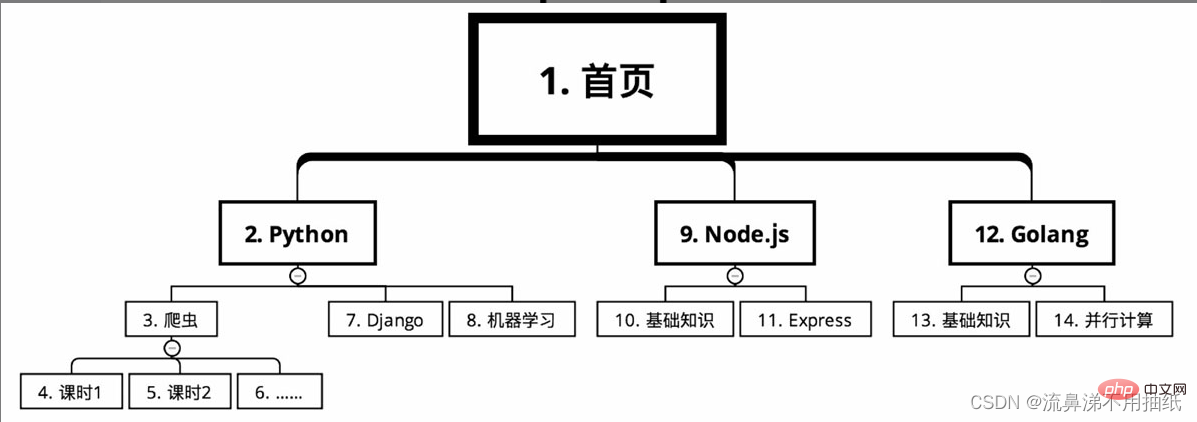
La séquence est la suivante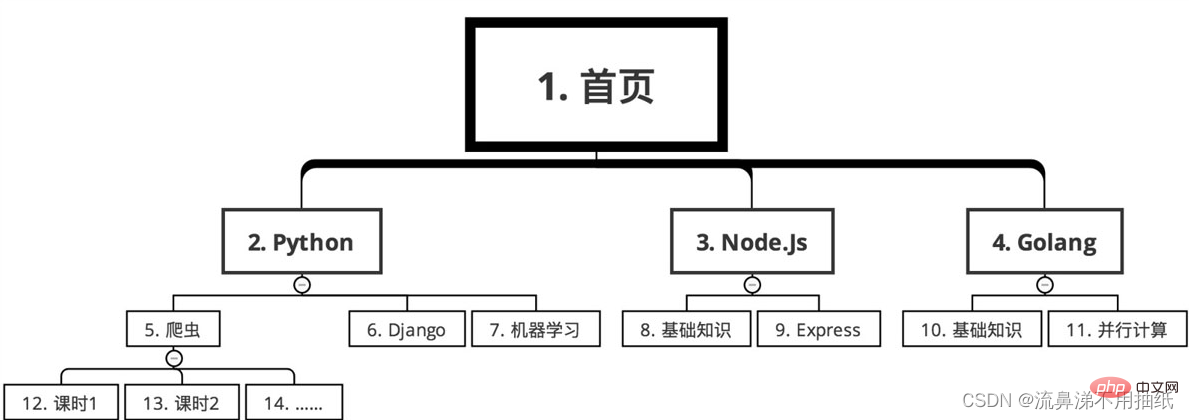
Par exemple, si vous souhaitez explorer un site Web à l'échelle nationale. Toutes les informations sur les restaurants et les informations de commande pour chaque restaurant. En supposant que l'algorithme de profondeur d'abord soit utilisé, explorez d'abord le restaurant A à partir d'un certain lien, puis explorez immédiatement les informations de commande du restaurant A. Comme il existe des centaines de milliers de restaurants à travers le pays, cela peut prendre 12 heures pour tous les gravir. Le problème qui en résulte est que le volume des commandes du restaurant A peut atteindre 8 heures du matin, tandis que le volume des commandes du restaurant B peut atteindre 8 heures du soir. Leur volume de commande diffère de 12 heures. Pour les restaurants populaires, 12 heures peuvent entraîner un écart de revenus de plusieurs millions. De cette façon, lors de l’analyse des données, le décalage horaire de 12 heures rendra difficile la comparaison des performances commerciales des restaurants A et B. Par rapport au volume des commandes, les changements de volume dans les restaurants sont beaucoup plus faibles. Par conséquent, si vous utilisez la recherche large, explorez d'abord tous les restaurants de 0h00 au milieu de la nuit à 12h00 le lendemain, puis concentrez-vous sur l'analyse du volume de commandes de chaque restaurant de 14h00 à 20h00. :00 le lendemain. De cette façon, il n'a fallu que 6 heures pour terminer la tâche d'exploration des commandes, réduisant ainsi la différence de volume de commandes causée par le décalage horaire. Dans le même temps, étant donné que l'exploration de la boutique tous les quelques jours a peu d'impact, le nombre de requêtes a également été réduit, ce qui rend plus difficile la découverte du robot par le site Web.
Autre exemple, pour analyser l'opinion publique en temps réel, vous devez explorer Baidu Tieba. Un forum populaire peut contenir des dizaines de milliers de pages de messages, en supposant que les premiers messages remontent à 2010. Si une recherche en largeur est utilisée, obtenez d'abord les titres et les URL de tous les articles de ce Tieba, puis saisissez chaque article en fonction de ces URL pour obtenir des informations sur chaque étage. Cependant, comme il s'agit de l'opinion publique en temps réel, les publications d'il y a 7 ans ont peu d'importance pour l'analyse actuelle. Ce qui est plus important, ce sont les nouvelles publications, donc les nouveaux contenus doivent être capturés en premier. Par rapport au contenu passé, le contenu en temps réel est le plus important. Par conséquent, pour explorer le contenu Tieba, une recherche approfondie doit d’abord être utilisée. Lorsque vous voyez une publication, entrez rapidement et explorez les informations de chaque étage. Après avoir exploré une publication, vous pouvez accéder à la publication suivante. Bien entendu, ces deux algorithmes de recherche ne sont pas l’un ou l’autre. Ils doivent être choisis de manière flexible en fonction de la situation réelle. Dans de nombreux cas, ils peuvent être utilisés simultanément.
Apprentissage recommandé : Tutoriel vidéo Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



