

Explication détaillée du mode maître-esclave du cluster Redis

Cet article vous apporte des connaissances pertinentes sur Redis, qui présente principalement les problèmes liés aux clusters, et parle en détail du contenu du mode maître-esclave, y compris le cluster maître-esclave de chacun, etc. ensemble, j'espère que cela aidera tout le monde.

Apprentissage recommandé : Tutoriel vidéo Redis
1. Pourquoi avez-vous besoin d'un cluster ?
Dans notre développement actuel, Il n'est pas possible d'utiliser un seul Redis dans les projets d'ingénierie, pour les raisons suivantes :
2. Mode maître-esclave Introduction(1) De la structure, un seul serveur Redis apparaîtra Point de défaillance unique, et un serveur doit gérer toutes les charges de requêtes, haute pression ;
(2) À partir de la capacité, la mémoire d'un seul serveur Redis la capacité est limitée, même un serveur Redis. la capacité de la mémoire est de 256 Go et toute la mémoire ne peut pas être utilisée comme mémoire de stockage Redis. De manière générale, la mémoire maximale utilisée par un seul Redis ne doit pas dépasser 20 Go.
(3) Les performances de lecture et d'écriture d'un seul serveur Redis sont limitées L'utilisation d'un cluster peut améliorer les capacités de lecture et d'écriture.
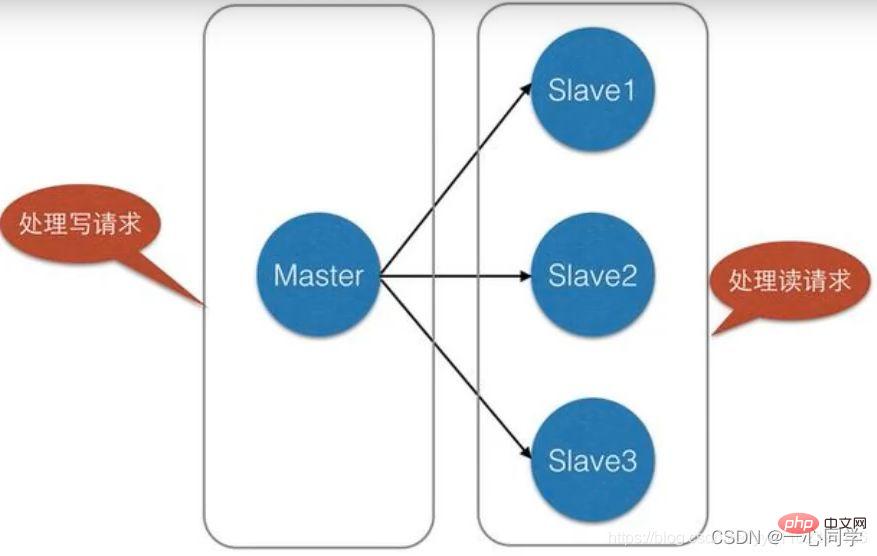
Actuellement, Redis dispose de trois modes cluster, à savoir : Mode maître-esclave, mode Sentinelle, mode Cluster le mode maître-esclave est le plus simple des ; trois modes. , dans Réplication maître-esclave, cela fait référence à la copie de données d'un serveur Redis vers d'autres serveurs Redis. Le premier est appelé nœud maître (maître/leader) et le second est appelé nœud esclave (esclave/suiveur).
Remarque :
(1)La réplication des données est unidirectionnelle, uniquement du nœud maître vers le nœud esclave. Master est principalement destiné à l'écriture et Slave est principalement destiné à la lecture. (2)
Par défaut, chaque serveur Redis est un nœud maître ; (3)
Un nœud maître peut avoir plusieurs nœuds esclaves (ou aucun nœud esclave), mais un nœud esclave ne peut avoir un nœud maître .

1.Par exemple, vous pouvez trouver sur notre site de commerce électronique queRedondance des données : La réplication maître-esclave implémente la sauvegarde à chaud des données, qui est une méthode de redondance des données en plus de la persistance. 2.
Récupération après panne : Lorsqu'un problème survient sur le nœud maître, le nœud esclave peut fournir des services pour obtenir une récupération rapide après panne. Il s'agit en fait d'une sorte de redondance de service ; 3.
Pierre angulaire de la haute disponibilité (cluster) : La réplication maître-esclave est également la base de la mise en œuvre des Sentinels et des clusters. Par conséquent, la réplication maître-esclave est la base de la haute disponibilité de Redis. 4.
Équilibrage de charge : basé sur la réplication maître-esclave, combinée à une séparation lecture-écriture, le nœud maître peut fournir des services d'écriture et les nœuds esclaves peuvent fournir des services de lecture (c'est-à-dire que lors de l'écriture de données Redis, l'application se connecte au nœud maître et lit Redis. Lorsque les données sont générées, l'application connecte les nœuds esclaves) pour partager la charge du serveur, en particulier dans les scénarios où il y a moins d'écriture et plus de lecture, le partage de la charge de lecture via plusieurs nœuds esclaves peut considérablement augmenter la concurrence ; du serveur Redis.
un produit ne doit être téléchargé qu'une seule fois, mais il peut être consulté plusieurs fois par les utilisateurs, c'est-à-dire "Écrivez moins et lisez plus ", nous Vous pouvez utiliser la réplication maître-esclave pour la séparation lecture-écriture, pour réduire la pression sur le serveur :
3. Construisez le cluster maître-esclave
3.1. Préparation
1. Copiez les trois fichiers de configuration (nom d'origine : redis.conf) et renommez-les en : redis79.conf. , redis80.conf, redis81.conf.

2. Modifier le fichier de configuration
(1) Modifier redis79.conf
Modifier le numéro de port
port 6379
Configuré pour fonctionner en arrière-plan
daemonize:yes
Définissez le nom du fichier journal
logfile “6379.log"
Définissez le nom du fichier db
dbfilename dump6379.rdb
(2) Modifier redis80.conf
Modifier le numéro de port
port 6380
Définir pour s'exécuter en arrière-plan
daemonize:yes
Définir le nom du fichier d'identification du processus d'enregistrement
pidfile /var/run/redis_6380.pid
Définir le nom du fichier journal
logfile “6380.log"
Définissez le nom du fichier db
dbfilename dump6380.rdb
(3) Modifier redis81.conf
Modifier le numéro de port
port 6381
Définir pour s'exécuter en arrière-plan
daemonize:yes
Définir le nom du fichier d'identification du processus d'enregistrement
pidfile /var/run/redis_6381.pid
Configurer les fichiers journaux Le nom
logfile “6381.log"
Définir le nom du fichier db
dbfilename dump6381.rdb
Les fonctions de ces attributs sont les suivantes :
pid (ID de port) : L'ID du processus est enregistré et le fichier est verrouillé. Empêche le programme d'être démarré plusieurs fois.
logfile : Effacez l'emplacement du fichier journal
dbfilename : dumpxxx.file #Persistent file location
port : Le numéro de port occupé par le processus
Construisez un maître et deux esclaves
. Démarrez le serveur Redis
Remarque : Par défaut, chaque serveur Reids est le nœud maître, et si nous voulons construire un serveur maître-esclave, il nous suffit de le construire sur la machine esclave.
Démarrez maintenant les serveurs redis79, redis80, redis81 respectivement.
redis-server redis79.conf redis-server redis80.conf redis-server redis81.conf
Utilisez la commande suivante pour vérifier si le démarrage a réussi :
ps -ef|grep redis

Ouvrez trois fenêtres client et faites fonctionner respectivement trois serveurs Redis.
Entrez la commande :
Notez que vous devez spécifier le port pour savoir quel Redis nous voulons ouvrir.
Fenêtre un :
redis-cli -p 6379
Fenêtre deux :
redis-cli -p 6380
Fenêtre trois :
redis-cli -p 6381
Définir la relation maître-esclave
Nous définirons redis79 comme nœud maître, et redis80 et redis81 est défini comme nœud esclave .
Configurer l'adresse IP et le numéro de port de l'hébergeur équivaut à vouloir le reconnaître comme votre patron.
redis80:
#SLAVEOF IP地址 端口 127.0.0.1:6380> slaveof 127.0.0.1 6379 OK
redis81:
#SLAVEOF IP地址 端口 127.0.0.1:6381> slaveof 127.0.0.1 6379 OK
这个时候,我们在从机使用INFO命令就可以查看主从关系了:
info replication
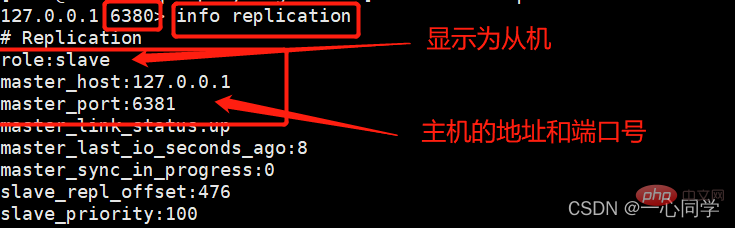
而此时我们去主机redis79中使用同样的命令进行查看:
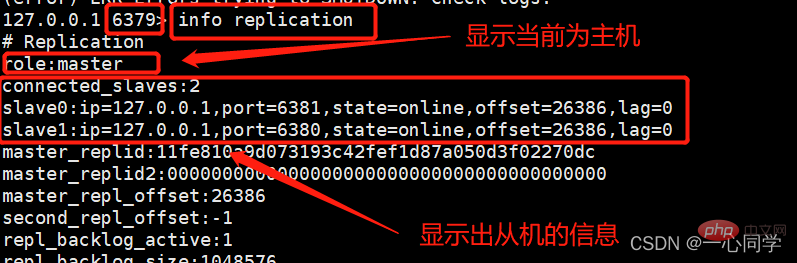
现在我们的一主二从的关系就成功搭建好了!
提示:如果要将从机变成主机,我们只需要在从机执行以下命令,即可让自己变为主机。
SLAVEOF no one
四、知识讲解
知识一
主机可以进行读写操作,而从机只能读操作。
注意:主机中的所有信息和数据,都会自动被从机保存。
主机:
127.0.0.1:6379> set key1 v1 OK 127.0.0.1:6379> get key1 "v1"
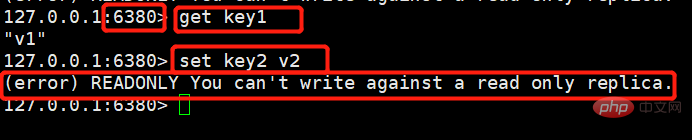
从机:
127.0.0.1:6380> get key1 "v1" 127.0.0.1:6380> set key2 v2 #进行写操作就会报错,提示从机只能进行读操作 (error) READONLY You can't write against a read only replica.
知识二
主机如果宕机了,从机依旧可以读取到主机宕机前的数据,但仍然没有写操作,如果主机恢复过来了,从机依旧可以获取到主机写的数据。
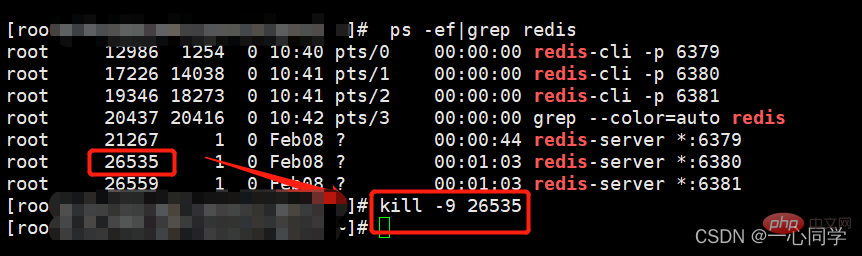
(1)停止主机进程(演示主机宕机了)
停止进程的命令:
kill -9 pid #pid为redis进程号
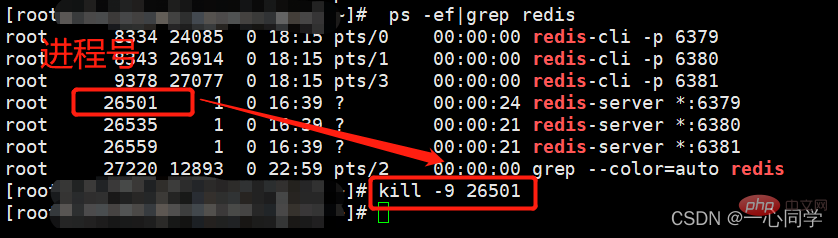
(2)从机获取宕机前主机写入的数据
可以发现,能够顺利拿到,但仍然是无法进行写操作的。
(3)恢复主机
redis-server redis79.conf
(4)主机重新写入数据,从机获取最新数据。
主机写入数据:
127.0.0.1:6379> set k2 yixin OK
从机读取最新数据:
127.0.0.1:6380> get k2 "yixin"
知识三
两种配置方式下的从机断开情况
a、命令行设置主从关系
从机断开了,其重新连接后变为主机,能拿到断开之前的数据,但拿不到主机新写入的值,如果重新设置主从关系,就可以拿到主机全部的数据了。
(1)停止从机进程。
(2)主机写入新数据。
127.0.0.1:6379> set k3 new OK
(3)重新启动从机服务器。
redis-server redis80.conf
(4)尝试获取从机宕机前主机写入的数据,发现可以拿到。
127.0.0.1:6380> get k1 "v1"
(5)尝试获取从机宕机期间主机写入的数据,发现无法拿到了。
127.0.0.1:6380> get k3 (nil)
此次我们可以进行查看主从关系,由于是命令行配置的,所以重启之后又变回主机了。
127.0.0.1:6380> info replication # Replication role:master connected_slaves:0
(6)如果要拿到主机的所有数据,只要执行以下命令重新配置主从关系就可以了。
slaveof 127.0.0.1 6379
b、配置文件设置的主从关系
从机断开后,重新连接,也是可以拿到主机的全部数据的。
(1)修改配置文件redis80.conf,添加主从关系。
#指定主机的ip与port slaveof 127.0.0.1 6379
(2)主机添加新数据
127.0.0.1:6379> set k5 hello OK
(3)重新启动redis80服务器。
redis-server redis80.conf
(4)获取从机宕机期间主机新写入的数据,发现现在可以顺利拿到了。
127.0.0.1:6380> get k5 "hello"
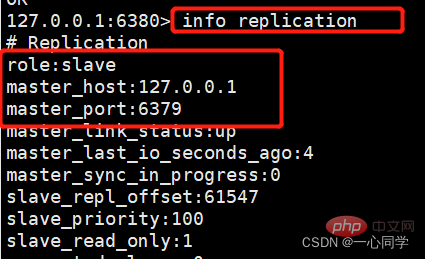
我们来查看6380的主从关系,可以发现在重启的时候就已经设置好主从关系了。
五、复制原理
(1)Slave 启动成功连接到 Master 后会发送一个sync同步命令
(2)Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
(3)全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
(4)增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步。
注意:只要是重新连接master,一次完全同步(全量复制)将被自动执行! 我们的数据一定可以在从机中看到。
六、主从模式的优缺点
优点
(1)同一个Master可以同步多个Slaves。
(2)Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。因此我们可以将Redis的Replication架构视为图结构。
(3)Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
(4)Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据。
(5)为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成。即便如此,系统的伸缩性还是得到了很大的提高。
(6)Master可以将数据保存操作交给Slaves完成,从而避免了在Master中要有独立的进程来完成此操作。
(7)支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
(1) Redis 主从模式不具备自动容错和恢复功能,如果主节点宕机,Redis 集群将无法工作,此时需要人为干预,将从节点提升为主节点。
(2) 如果主机宕机前有一部分数据未能及时同步到从机,即使切换主机后也会造成数据不一致的问题,从而降低了系统的可用性。
(3) 因为只有一个主节点,所以其写入能力和存储能力都受到一定程度地限制。
(4) 在进行数据全量同步时,若同步的数据量较大可能会造卡顿的现象。
推荐学习:Redis视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1358
1358
 52
52

 Solution à l'erreur 0x80242008 lors de l'installation de Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
Solution à l'erreur 0x80242008 lors de l'installation de Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
1. Démarrez le menu [Démarrer], entrez [cmd], cliquez avec le bouton droit sur [Invite de commandes] et sélectionnez Exécuter en tant qu'[Administrateur]. 2. Entrez les commandes suivantes dans l'ordre (copiez et collez soigneusement) : SCconfigwuauservstart=auto, appuyez sur Entrée SCconfigbitsstart=auto, appuyez sur Entrée SCconfigcryptsvcstart=auto, appuyez sur Entrée SCconfigtrustedinstallerstart=auto, appuyez sur Entrée SCconfigwuauservtype=share, appuyez sur Entrée netstopwuauserv , appuyez sur Entrée netstopcryptS.
 Stratégie de mise en cache et optimisation de l'API Golang
May 07, 2024 pm 02:12 PM
Stratégie de mise en cache et optimisation de l'API Golang
May 07, 2024 pm 02:12 PM
La stratégie de mise en cache dans GolangAPI peut améliorer les performances et réduire la charge du serveur. Les stratégies couramment utilisées sont : LRU, LFU, FIFO et TTL. Les techniques d'optimisation incluent la sélection du stockage de cache approprié, la mise en cache hiérarchique, la gestion des invalidations, ainsi que la surveillance et le réglage. Dans le cas pratique, le cache LRU est utilisé pour optimiser l'API pour obtenir des informations utilisateur à partir de la base de données. Les données peuvent être rapidement récupérées du cache. Sinon, le cache peut être mis à jour après l'avoir obtenu à partir de la base de données.
 Mécanisme de mise en cache et pratique d'application dans le développement PHP
May 09, 2024 pm 01:30 PM
Mécanisme de mise en cache et pratique d'application dans le développement PHP
May 09, 2024 pm 01:30 PM
Dans le développement PHP, le mécanisme de mise en cache améliore les performances en stockant temporairement les données fréquemment consultées en mémoire ou sur disque, réduisant ainsi le nombre d'accès à la base de données. Les types de cache incluent principalement le cache de mémoire, de fichiers et de bases de données. En PHP, vous pouvez utiliser des fonctions intégrées ou des bibliothèques tierces pour implémenter la mise en cache, telles que cache_get() et Memcache. Les applications pratiques courantes incluent la mise en cache des résultats des requêtes de base de données pour optimiser les performances des requêtes et la mise en cache de la sortie des pages pour accélérer le rendu. Le mécanisme de mise en cache améliore efficacement la vitesse de réponse du site Web, améliore l'expérience utilisateur et réduit la charge du serveur.
 Comment mettre à niveau Win11 anglais 21996 vers le chinois simplifié 22000_Comment mettre à niveau Win11 anglais 21996 vers le chinois simplifié 22000
May 08, 2024 pm 05:10 PM
Comment mettre à niveau Win11 anglais 21996 vers le chinois simplifié 22000_Comment mettre à niveau Win11 anglais 21996 vers le chinois simplifié 22000
May 08, 2024 pm 05:10 PM
Vous devez d’abord définir la langue du système sur l’affichage chinois simplifié et redémarrer. Bien sûr, si vous avez déjà modifié la langue d'affichage en chinois simplifié, vous pouvez simplement ignorer cette étape. Ensuite, commencez à utiliser le registre, regedit.exe, accédez directement à HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage dans la barre de navigation de gauche ou dans la barre d'adresse supérieure, puis modifiez la valeur de la clé InstallLanguage et la valeur de la clé par défaut sur 0804 (si vous souhaitez la changer en anglais en- nous, vous devez d'abord définir la langue d'affichage du système sur en-us, redémarrer le système, puis tout changer en 0409). Vous devez redémarrer le système à ce stade.
 Comment utiliser le cache Redis dans la pagination des tableaux PHP ?
May 01, 2024 am 10:48 AM
Comment utiliser le cache Redis dans la pagination des tableaux PHP ?
May 01, 2024 am 10:48 AM
L'utilisation du cache Redis peut considérablement optimiser les performances de la pagination du tableau PHP. Cela peut être réalisé en suivant les étapes suivantes : Installez le client Redis. Connectez-vous au serveur Redis. Créez des données de cache et stockez chaque page de données dans un hachage Redis avec la clé « page : {page_number} ». Récupérez les données du cache et évitez les opérations coûteuses sur les grandes baies.
 Comment trouver le fichier de mise à jour téléchargé par Win11_Partager l'emplacement du fichier de mise à jour téléchargé par Win11
May 08, 2024 am 10:34 AM
Comment trouver le fichier de mise à jour téléchargé par Win11_Partager l'emplacement du fichier de mise à jour téléchargé par Win11
May 08, 2024 am 10:34 AM
1. Tout d'abord, double-cliquez sur l'icône [Ce PC] sur le bureau pour l'ouvrir. 2. Double-cliquez ensuite sur le bouton gauche de la souris pour accéder à [Lecteur C]. Les fichiers système seront généralement automatiquement stockés dans le lecteur C. 3. Recherchez ensuite le dossier [windows] dans le lecteur C et double-cliquez pour entrer. 4. Après avoir accédé au dossier [windows], recherchez le dossier [SoftwareDistribution]. 5. Après avoir entré, recherchez le dossier [télécharger], qui contient tous les fichiers de téléchargement et de mise à jour Win11. 6. Si nous souhaitons supprimer ces fichiers, supprimez-les simplement directement dans ce dossier.
 Applications de mise en cache PHP Redis et bonnes pratiques
May 04, 2024 am 08:33 AM
Applications de mise en cache PHP Redis et bonnes pratiques
May 04, 2024 am 08:33 AM
Redis est un cache clé-valeur hautes performances. L'extension PHPRedis fournit une API pour interagir avec le serveur Redis. Suivez les étapes suivantes pour vous connecter à Redis, stocker et récupérer des données : Connecter : utilisez les classes Redis pour vous connecter au serveur. Stockage : utilisez la méthode set pour définir des paires clé-valeur. Récupération : utilisez la méthode get pour obtenir la valeur de la clé.
 Comment optimiser les performances des fonctions pour les différentes versions de PHP ?
Apr 25, 2024 pm 03:03 PM
Comment optimiser les performances des fonctions pour les différentes versions de PHP ?
Apr 25, 2024 pm 03:03 PM
Les méthodes permettant d'optimiser les performances des fonctions pour différentes versions de PHP incluent : l'utilisation d'outils d'analyse pour identifier les goulots d'étranglement des fonctions ; l'activation de la mise en cache des opcodes ou l'utilisation d'un système de mise en cache externe ; l'ajout d'annotations de type pour améliorer les performances et la sélection d'algorithmes de concaténation et de tri de chaînes appropriés en fonction de la version de PHP.
