
 développement back-end
Tutoriel Python
En savoir plus sur les pools de processus Python et les verrous de processus
développement back-end
Tutoriel Python
En savoir plus sur les pools de processus Python et les verrous de processus
En savoir plus sur les pools de processus Python et les verrous de processus

Cet article vous apporte des connaissances pertinentes sur python, qui présente principalement les problèmes liés aux pools de processus et aux verrous de processus, y compris les modules de création de pool de processus, les fonctions de pool de processus, etc. Examinons-les ensemble, j'espère que cela aidera tout le monde.

Apprentissage recommandé : Tutoriel vidéo Python
Pool de processus
Qu'est-ce qu'un pool de processus
Nous avons mentionné dans le chapitre précédent sur les processus que lorsque trop de processus sont créés, les ressources seront consommées trop grandes. Afin d'éviter cette situation, nous devons fixer le nombre de processus et, à ce stade, nous avons besoin de l'aide du pool de processus.
On peut penser le pool de processus comme un pool dans lequel un certain nombre de processus sont créés à l'avance. Voir l'image ci-dessous :

Par exemple, ce tableau rectangulaire rouge représente un pool de processus, et il y a 6 processus dans ce pool. Ces 6 processus seront créés avec le pool de processus. De plus, nous avons dit un jour lors de l'apprentissage du cycle de vie orienté objet que chaque objet instancié sera recyclé par le gestionnaire de mémoire après utilisation.
Notre processus sera également recyclé par le gestionnaire de mémoire avec le processus de création et d'arrêt. C'est le cas pour chaque processus. Le processus créé lors de la fermeture du processus consommera également une certaine quantité de performances. Les processus du pool de processus ne seront pas fermés après leur création et pourront être réutilisés à tout moment, évitant ainsi la consommation de ressources de création et de fermeture, et évitant les opérations répétées de création et de fermeture, ce qui améliore l'efficacité.
Bien sûr, lorsque nous aurons fini d'exécuter le programme et que le pool de processus sera fermé, le processus sera également fermé.
Lorsque nous avons une tâche qui doit être exécutée, nous déterminerons s'il existe des processus inactifs dans le pool de processus actuel (les processus dits inactifs sont en fait des processus dans le pool de processus qui n'exécutent pas de tâches). Lorsqu'un processus est inactif, la tâche trouvera le processus pour effectuer la tâche. Si tous les processus du pool de processus actuel sont dans un état non inactif, la tâche entrera dans l'état d'attente et n'entrera ni ne sortira du pool de processus tant qu'un processus du pool de processus ne sera pas inactif pour exécuter la tâche.
C'est le rôle du pool de processus.
Module de création de pool de processus - multitraitement
Créer une fonction de pool de processus - Pool
| Nom de la fonction | Introduction | Paramètres | Valeur de retour |
|---|---|---|---|
| Pool | pool de processus Créer | Processcount | Objet pool de processus |
Pool功能介绍:通过调用 "multiprocessing" 模块的 "Pool" 函数来帮助我们创建 "进程池对象" ,它有一个参数 "Processcount" (一个整数),代表我们这个进程池中创建几个进程。
Méthodes communes du pool de processus
Après avoir créé un objet pool de processus, nous devons faire fonctionner son processus. Méthode (fonction).
| Nom de la fonction | Introduction | Paramètres | Valeur de retour |
|---|---|---|---|
| apply_async | Tâche ajoutée au pool de processus (asynchrone) | func, args | Aucun |
| fermer | Fermer le pool de processus | Aucun | Aucun |
| join | En attente de la fin de la tâche du pool de processus | Aucun | Aucun |
- Fonction apply_async : Sa fonction est d'ajouter des tâches au pool de processus, et elle est implémentée de manière asynchrone.
AsynchroneNous n'avons pas encore appris cette connaissance, nous n'avons donc pas encore à nous soucier de ce que cela signifie. Il a deux paramètres :func et agrs, func est une fonction ajoutée au pool de processus ; args est un tuple, représentant les paramètres d'une fonction, ce qui est le même que lorsque nous créons et utilisons un processus. . Tout à fait cohérent.异步这个知识我们还没有学习,先不用关心它到底是什么意思。它有两个参数:func 与 agrs, func 是加入进程池中工作的函数;args 是一个元组,代表着签一个函数的参数,这和我们创建并使用一个进程是完全一致的。- close 函数:当我们使用完进程池之后,通过调用 close 函数可以关闭进程池。它没有任何的参数,也没有任何的返回值。
- join 函数:它和我们上一章节学习的 创建进程的 join 函数中方法是一致的。只有进程池中的任务全部执行完毕之后,才会执行后续的任务。不过一般它会伴随着进程池的关闭(
close 函数)才会使用。
apply_async 函数演示案例
接下里我们在 Pycharm 中创建一个脚本,练习一下关于进程池的使用方法。
- 定义一个函数,打印输出该函数 每次被执行的次数 与 该次数的进程号
- 定义进程池的数量,每一次的执行进程数量最多为该进程池设定的进程数
示例代码如下:
# coding:utf-8import osimport timeimport multiprocessingdef work(count):
# 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
# print('********')if __name__ == '__main__':
pool = multiprocessing.Pool(3)
# 定义进程池的进程数量,同一时间每次执行最多3个进程
for i in range(21):
pool.apply_async(func=work, args=(i,))
# 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
time.sleep(15)
# 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。运行结果如下:
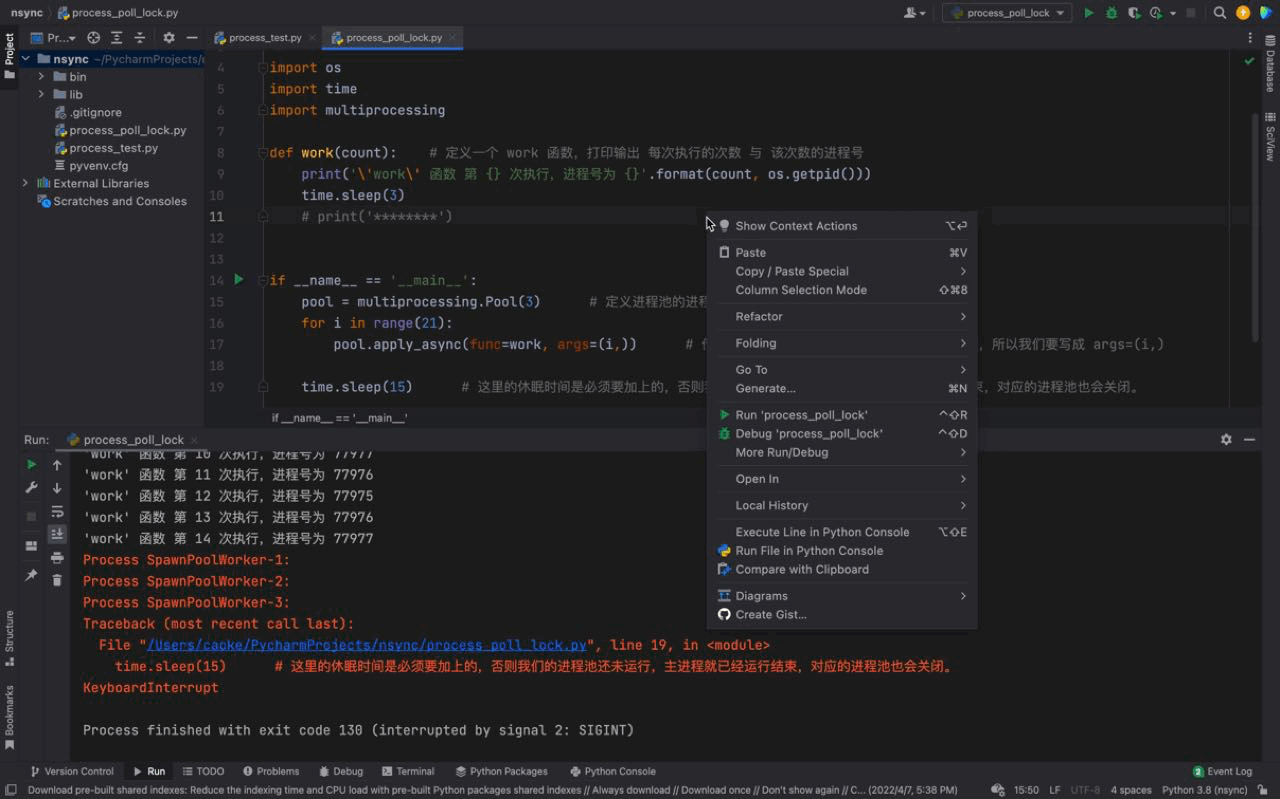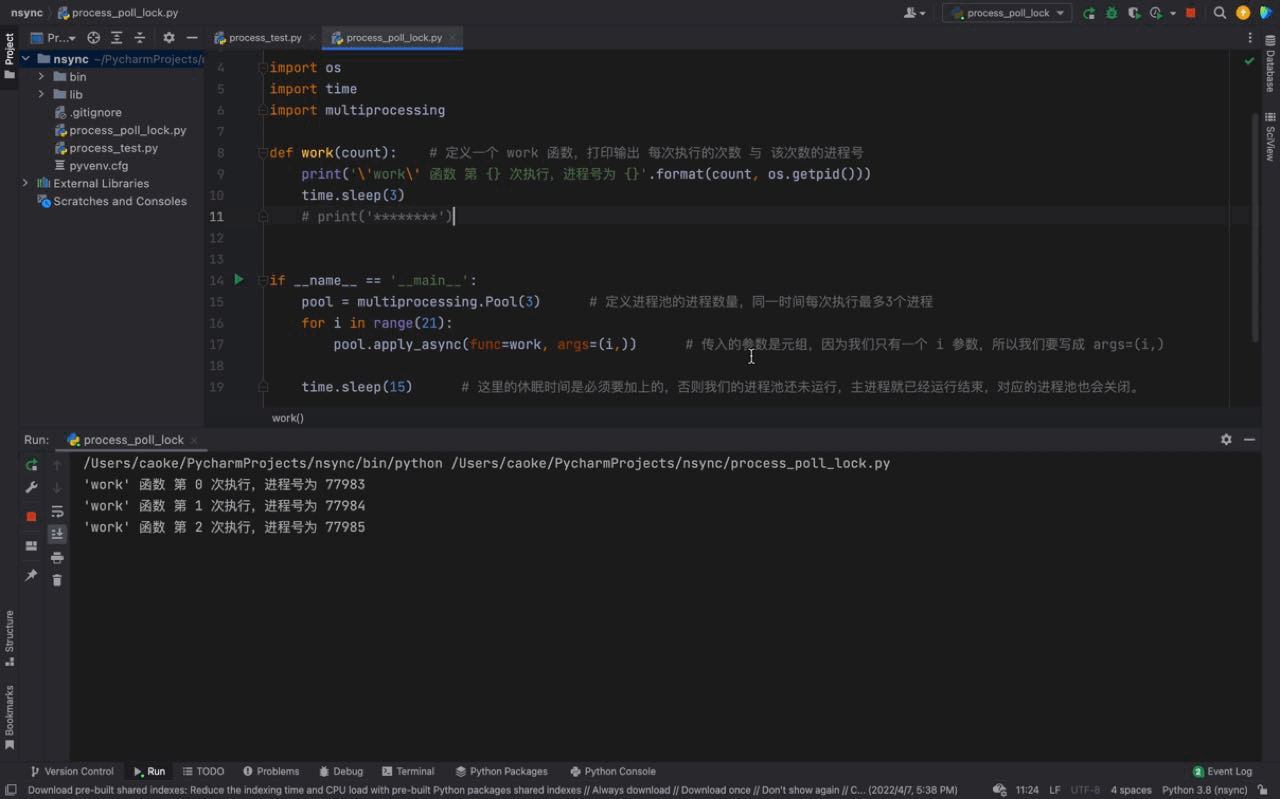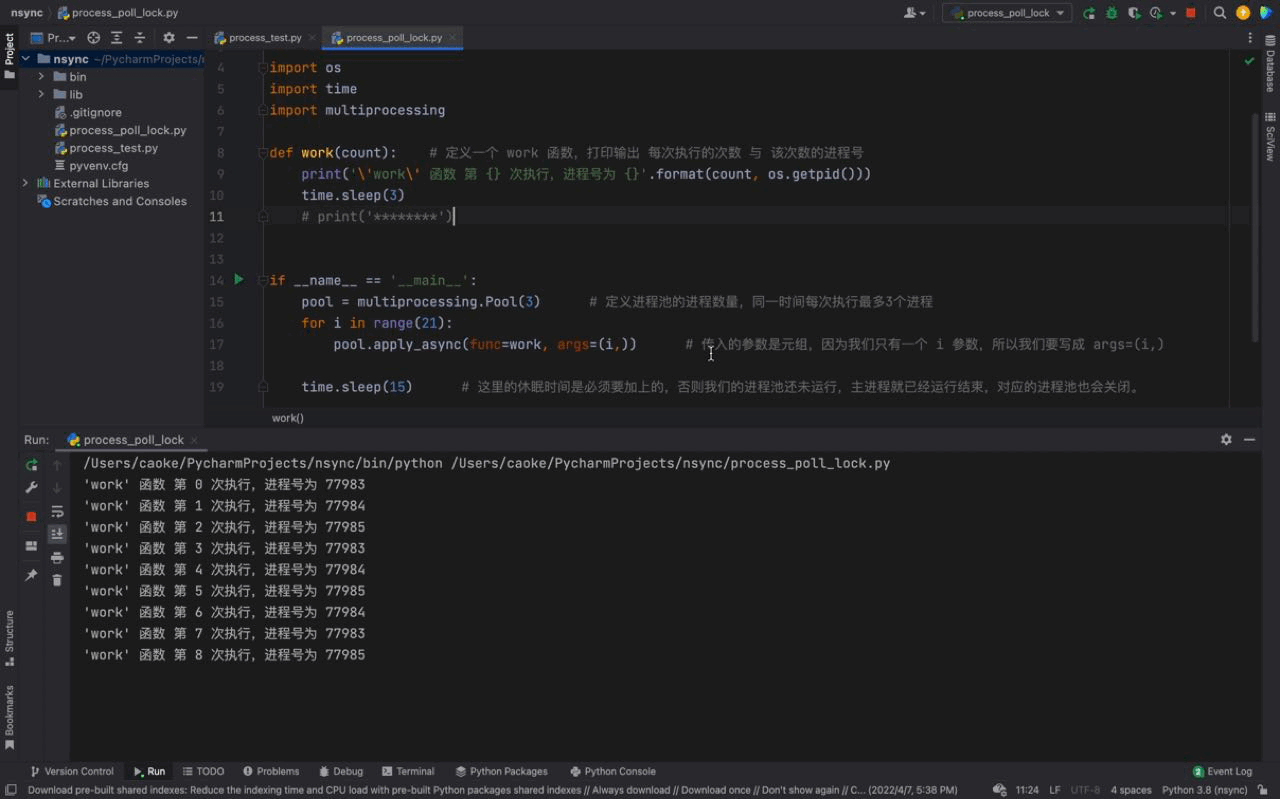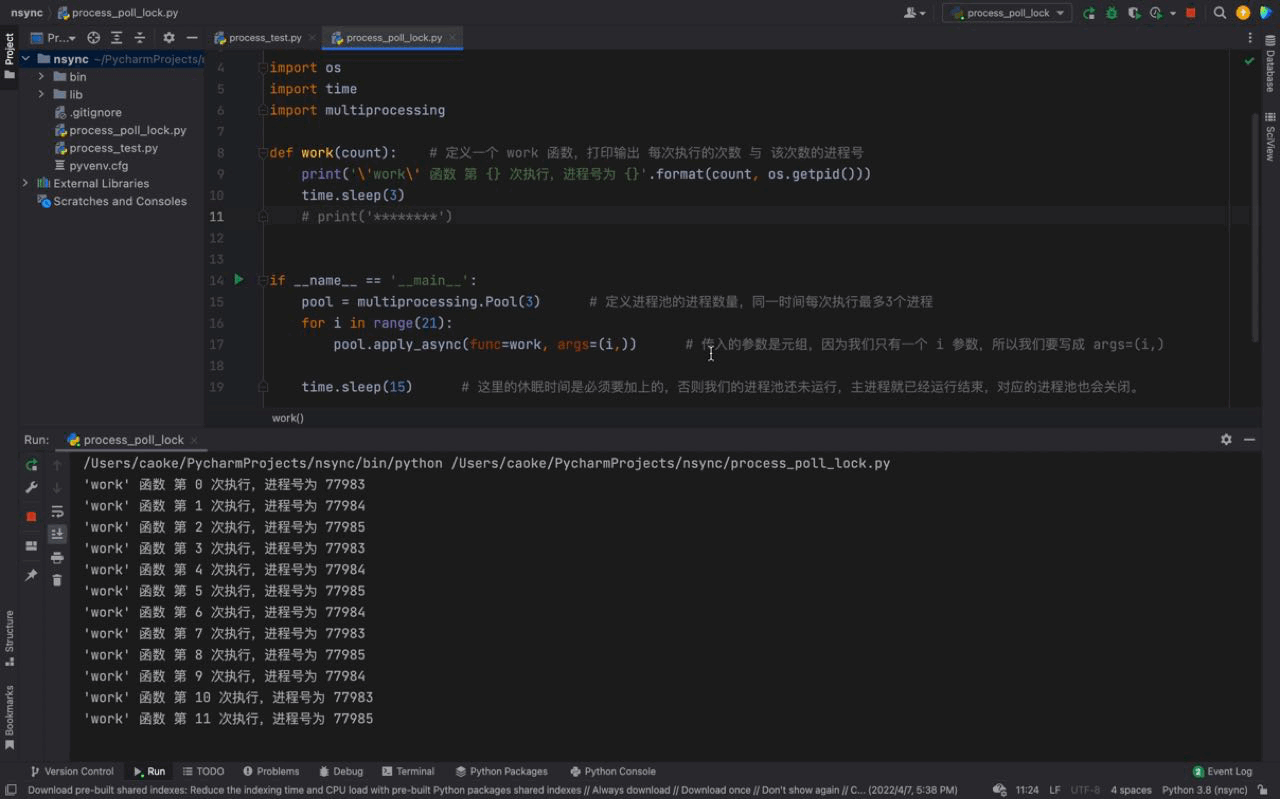
从上图中我们可以看到每一次都是一次性运行三个进程,每一个进程的进程号是不一样的,但仔细看会发现存在相同的进程号,这说明进程池的进程号在被重复利用。这证明我们上文介绍的内容,进程池中的进程不会被关闭,可以反复使用。
而且我们还可以看到每隔3秒都会执行3个进程,原因是我们的进程池中只有3个进程;虽然我们的 for 循环 中有 21 个任务,work 函数会被执行21次,但是由于我们的进程池中只有3个进程。所以当执行了3个任务之后(休眠3秒),后面的任务等待进程池中的进程处于空闲状态之后才会继续执行。
同样的,进程号在顺序上回出现一定的区别,原因是因为我们使用的是一种 异步 的方法(异步即非同步)。这就导致 work 函数 一起执行的三个任务会被打乱顺序,这也是为什么我们的进程号出现顺序不一致的原因。(更多的异步知识我们会在异步的章节进行详细介绍)
进程池的原理: 上述脚本的案例证实了我们进程池关于进程的限制,只有当我们进程池中的进程处于空闲状态的时候才会将进程池外等待的任务扔到进程池中工作。
close 函数与 join 函数 演示
在上文的脚本中, 我们使用 time.sleep(15) 帮助我们将主进程阻塞15秒钟再次退出,所以给了我们进程池足够的时间完成我们的 work() 函数的循环任务。
如果没有 time.sleep(15) 这句话又怎么办呢,其实这里就可以使用进程的 join 函数了。不过上文我们也提到过,进程的 join() 函数一般都会伴随进程池的关闭(close 函数)来使用。接下来,我们就将上文脚本中的 time.sleep(15) 替换成 join() 函数试一下。
示例代码如下:
# coding:utf-8import osimport timeimport multiprocessingdef work(count):
# 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
# print('********')if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
for i in range(21):
pool.apply_async(func=work, args=(i,))
# 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
# time.sleep(15)
pool.close()
pool.join()运行结果如下:
从上面的动图我们可以看出,work() 函数的任务与进程池中的进程与使用 time.sleep(15)的运行结果一致。
PS:如果我们的主进程会一直执行,不会退出。那么我们并不需要添加 close() 与 join() 函数 ,可以让进程池一直启动着,直到有任务进来就会执行。
在后面学习 WEB 开发之后,不退出主进程进行工作是家常便饭。还有一些需要长期执行的任务也不会关闭,但要是只有一次性执行的脚本,就需要添加 close() 与 join() 函数 来保证进程池的任务全部完成之后主进程再退出。当然,如果主进程关闭了,就不会再接受新的任务了,也就代表了进程池的终结。
接下来再看一个例子,在
work 函数中加入一个 return。这里大家可能会有一个疑问,在上一章节针对进程的知识点明明说的是
fonction join : elle est cohérente avec la fonction join que nous avons apprise dans le chapitre précédent pour créer un processus. Ce n'est qu'une fois que toutes les tâches du pool de processus sont exécutées que les tâches suivantes seront exécutées. Cependant, elle est généralement utilisée lorsque le pool de processus est fermé (进程无法获取返回值,那么这里的work()函数增加的returnfonction close : une fois que nous avons fini d'utiliser le pool de processus, nous pouvons fermer le pool de processus en appelant la fonction close. Il n'a aucun paramètre ni aucune valeur de retour.fonction close).
Cas de démonstration de la fonction apply_async
Ensuite, nous créons un script dans Pycharm pour nous entraîner à utiliser le pool de processus. 🎜🎜🎜🎜Définissez une fonction et imprimez le nombre de fois que la fonction est exécutée à chaque fois et le numéro de processus de ce numéro🎜Définissez le nombre de pools de processus. Le nombre de processus en cours d'exécution à chaque fois est maximum. le nombre de processus définis pour le pool de processus. Numéro
L'exemple de code est le suivant : 🎜
# coding:utf-8import osimport timeimport multiprocessingdef work(count): # 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
return '\'work\' 函数 result 返回值为:{}, 进程ID为:{}'.format(count, os.getpid())if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
results = []
for i in range(21):
result = pool.apply_async(func=work, args=(i,)) # 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
results.append(result)
for result in results:
print(result.get()) # 可以通过这个方式返回 apply_async 的返回值,
# 通过这种方式也不再需要 使用 close()、join() 函数就可以正常执行。
# time.sleep(15) # 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。
# pool.close()
# pool.join()Le résultat d'exécution est le suivant : 🎜
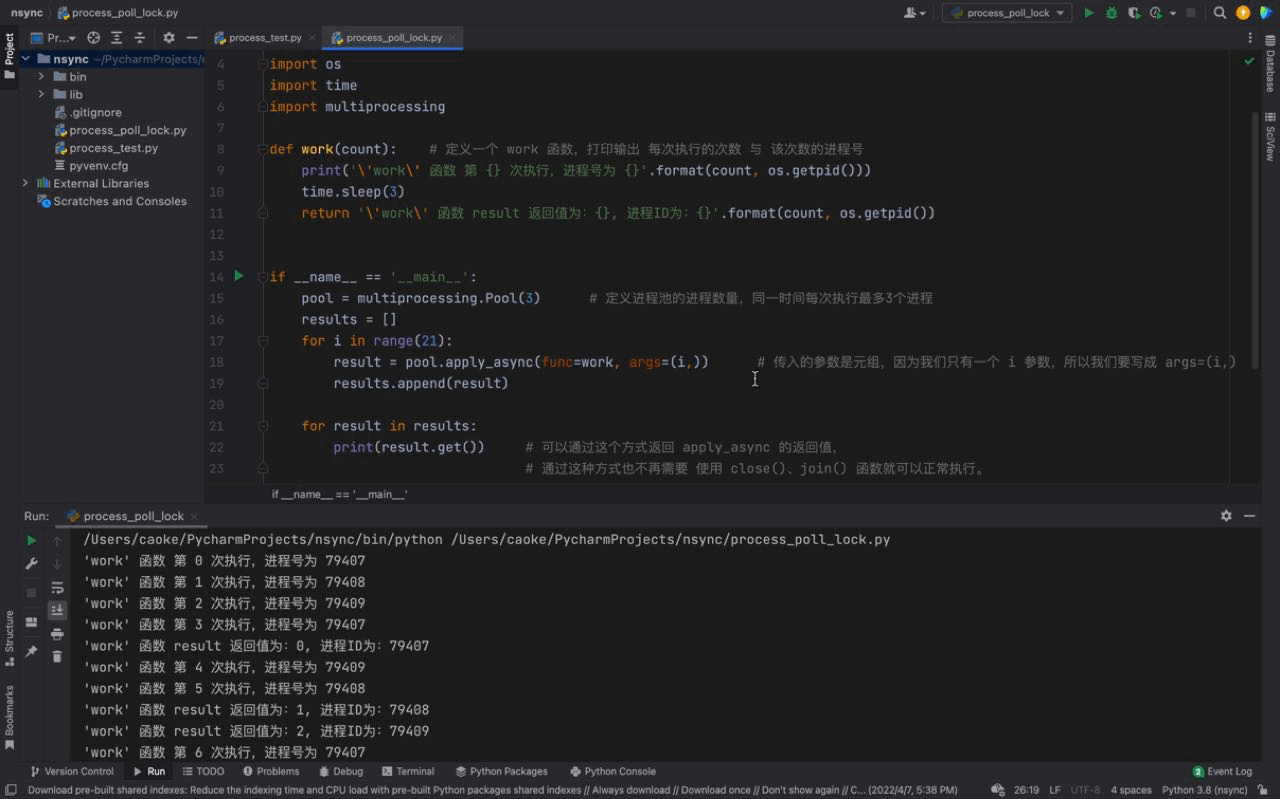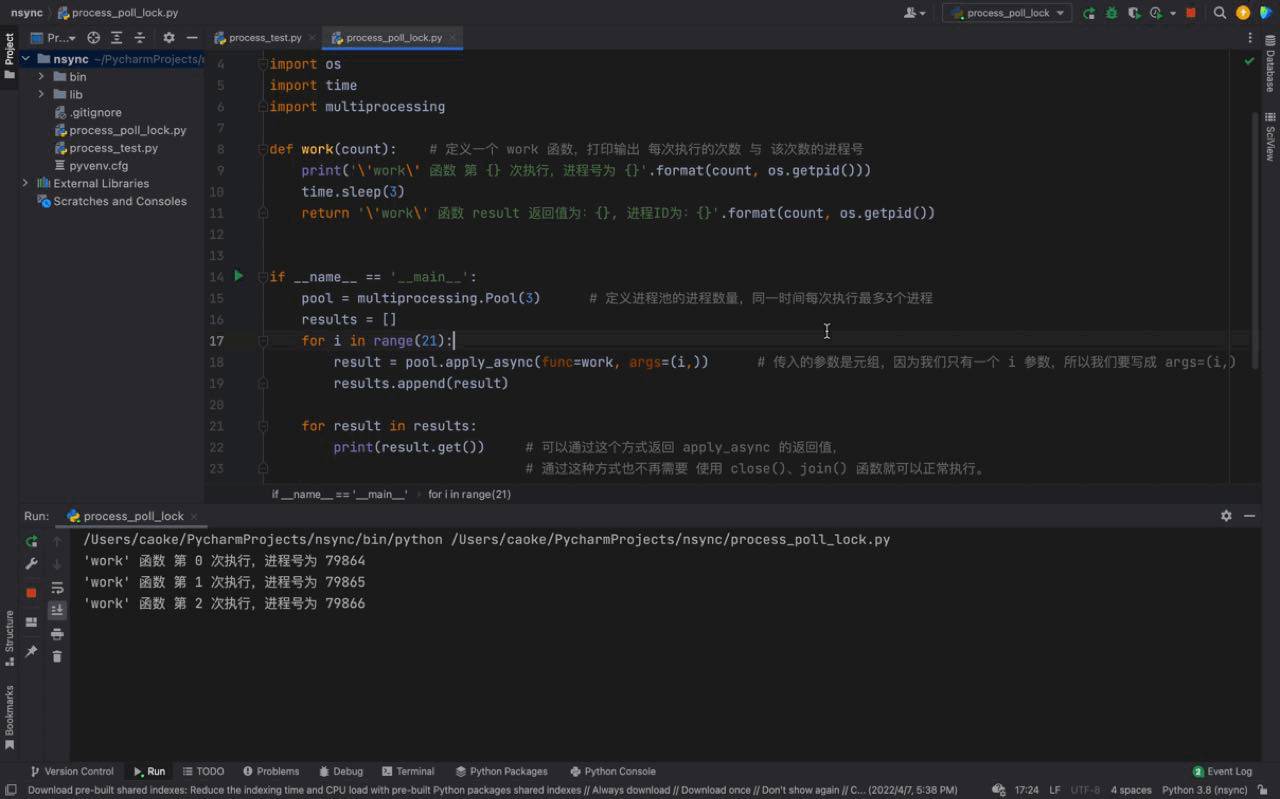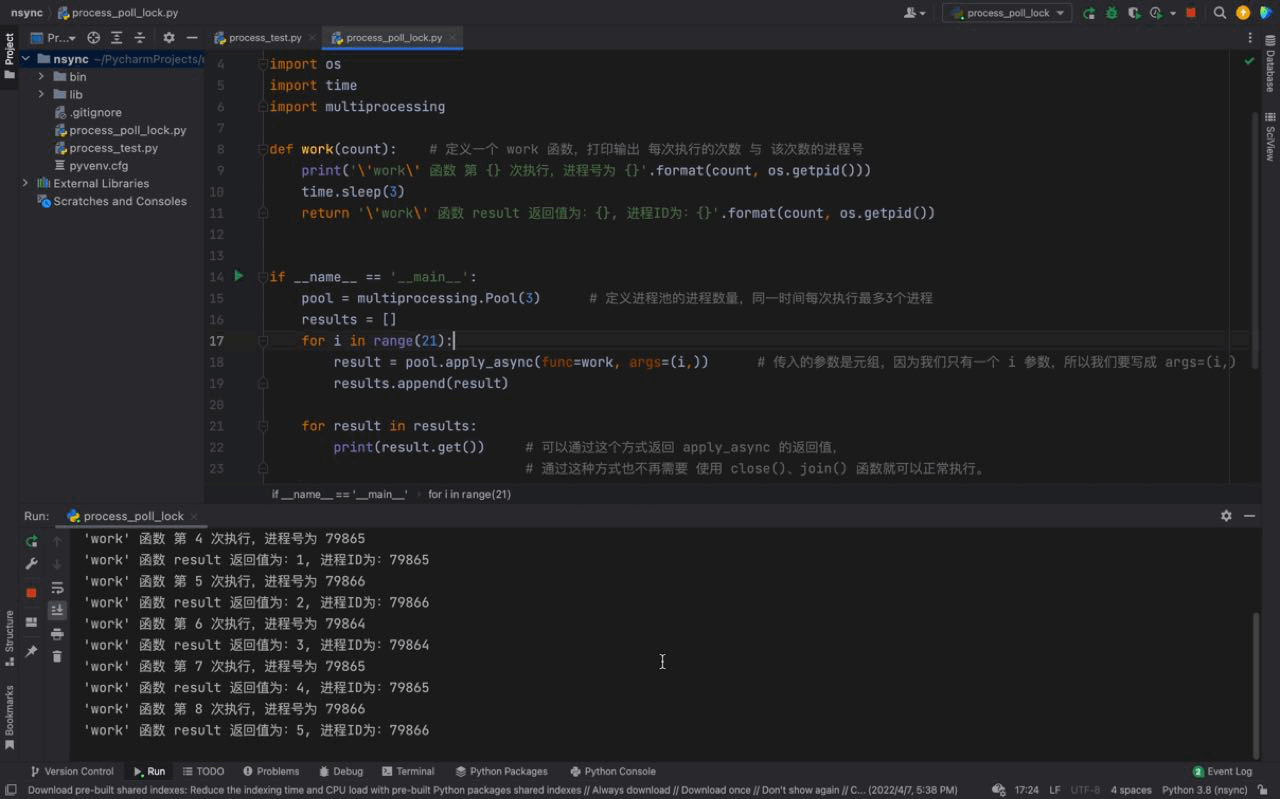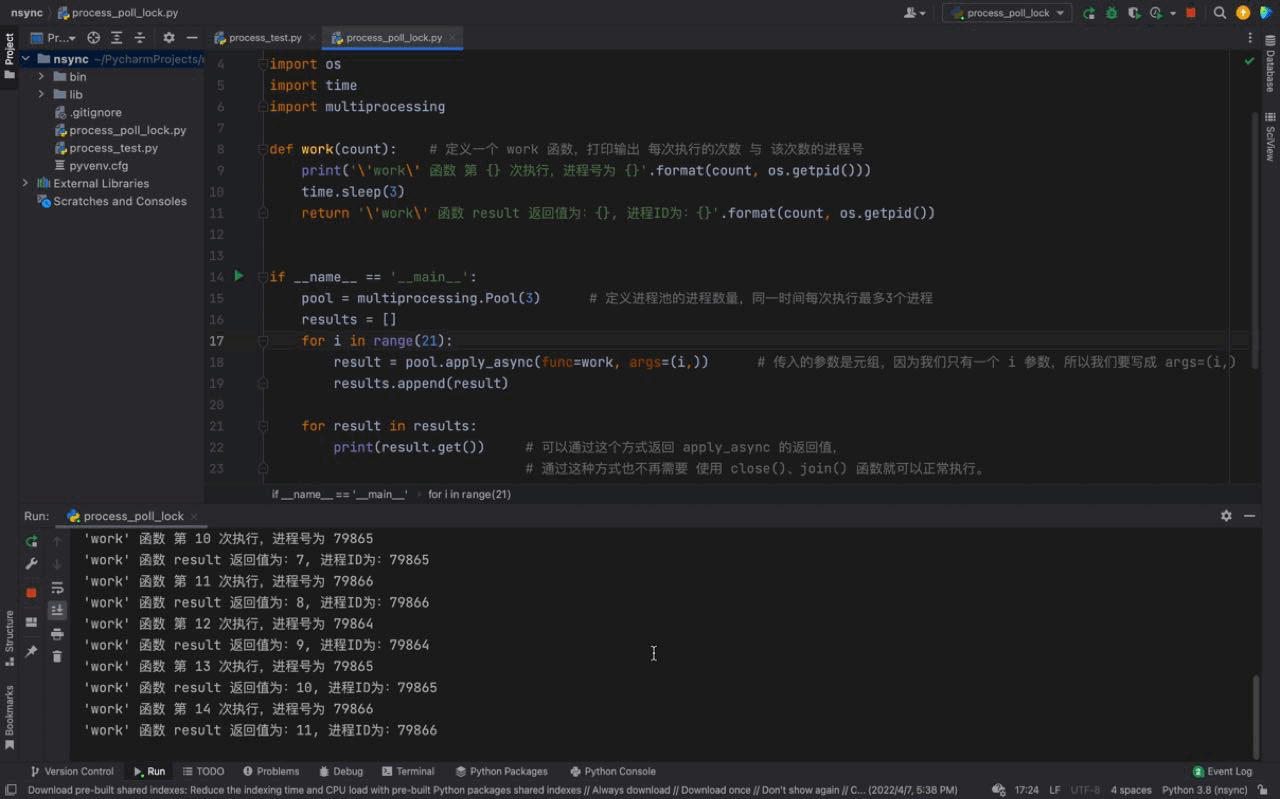 🎜
🎜
D'après l'image ci-dessus, nous pouvons voir qu'à chaque fois, trois processus sont exécutés en même temps. Le numéro de processus de chaque processus est différent, mais si vous regardez attentivement, vous constaterez que le même numéro de processus existe, ce qui est le cas. indique que le numéro de processus du pool de processus est en cours de réutilisation. Cela prouve ce que nous avons introduit ci-dessus, les processus du pool de processus ne seront pas fermés et pourront être utilisés à plusieurs reprises. 🎜
Et nous pouvons également voir que 3 processus sont exécutés toutes les 3 secondes, car il n'y a que 3 processus dans notre pool de processus bien qu'il y ait 21 tâches dans notre for boucle, la fonction de travail le fera ; être exécuté 21 fois, mais comme il n'y a que 3 processus dans notre pool de processus. Ainsi, après avoir exécuté 3 tâches (en veille pendant 3 secondes), les tâches suivantes attendront que le processus du pool de processus soit inactif avant de continuer à s'exécuter. 🎜
De même, il existe une certaine différence dans l'ordre des numéros de processus. La raison est que nous utilisons une méthode asynchrone (asynchrone signifie asynchrone). Cela provoque le désordre des trois tâches exécutées ensemble par la fonction de travail, c'est pourquoi nos numéros de processus apparaissent dans un ordre incohérent. (Nous présenterons plus de connaissances asynchrones en détail dans le chapitre asynchrone) 🎜
Le principe du pool de processus : le cas de script ci-dessus confirme les limites de notre pool de processus sur les processus uniquement lorsque. les processus de notre pool de processus sont inactifs, les tâches en attente en dehors du pool de processus seront lancées dans le pool de processus pour y travailler. 🎜
Fermer la fonction et rejoindre la démonstration de la fonction
Dans le script ci-dessus, nous utilisons time.sleep(15) code> nous aide à bloquer le processus principal pendant 15 secondes avant de quitter à nouveau, donnant ainsi à notre pool de processus suffisamment de temps pour terminer la tâche de boucle de notre fonction work(). 🎜<p>Et s'il n'y a pas de phrase <code>time.sleep(15) ? En fait, la fonction join du processus peut être utilisée ici. Cependant, nous avons également mentionné plus haut que la fonction join() d'un processus est généralement utilisée lorsque le pool de processus est fermé (close function). Ensuite, essayons de remplacer time.sleep(15) par la fonction join() dans le script ci-dessus. 🎜
L'exemple de code est le suivant : 🎜
# coding:utf-8import osimport timeimport multiprocessingdef work(count, lock): # 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号,增加线程锁。
lock.acquire() # 上锁
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
lock.release() # 解锁
return '\'work\' 函数 result 返回值为:{}, 进程ID为:{}'.format(count, os.getpid())if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
manager = multiprocessing.Manager()
lock = manager.Lock()
results = []
for i in range(21):
result = pool.apply_async(func=work, args=(i, lock)) # 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
# results.append(result)
# time.sleep(15) # 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。
pool.close()
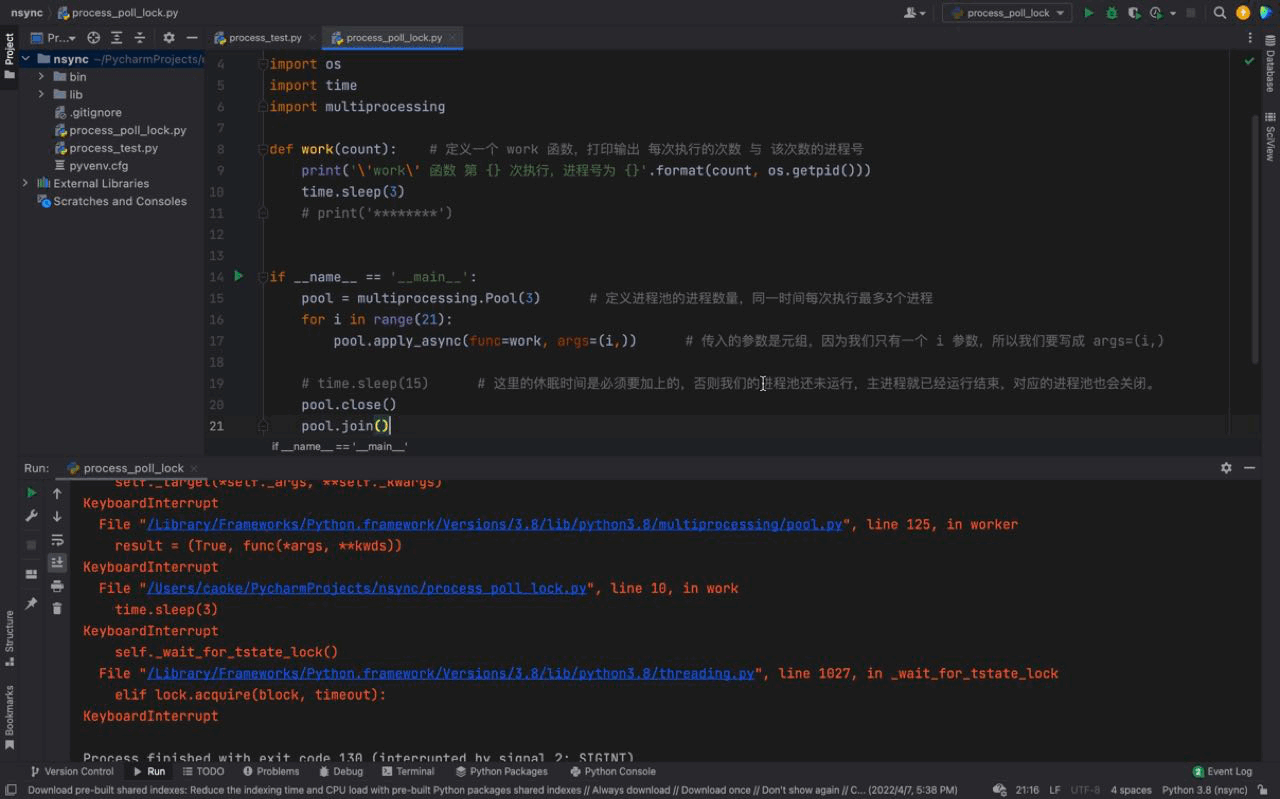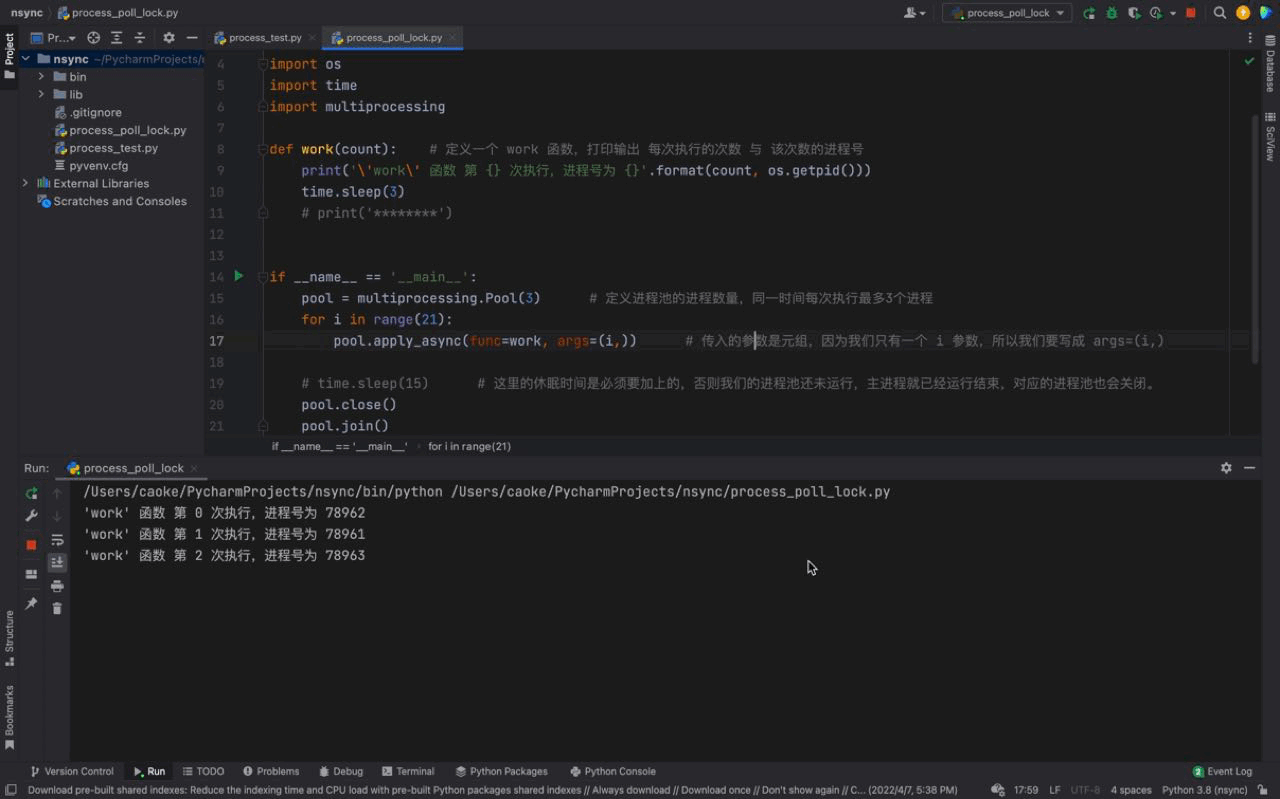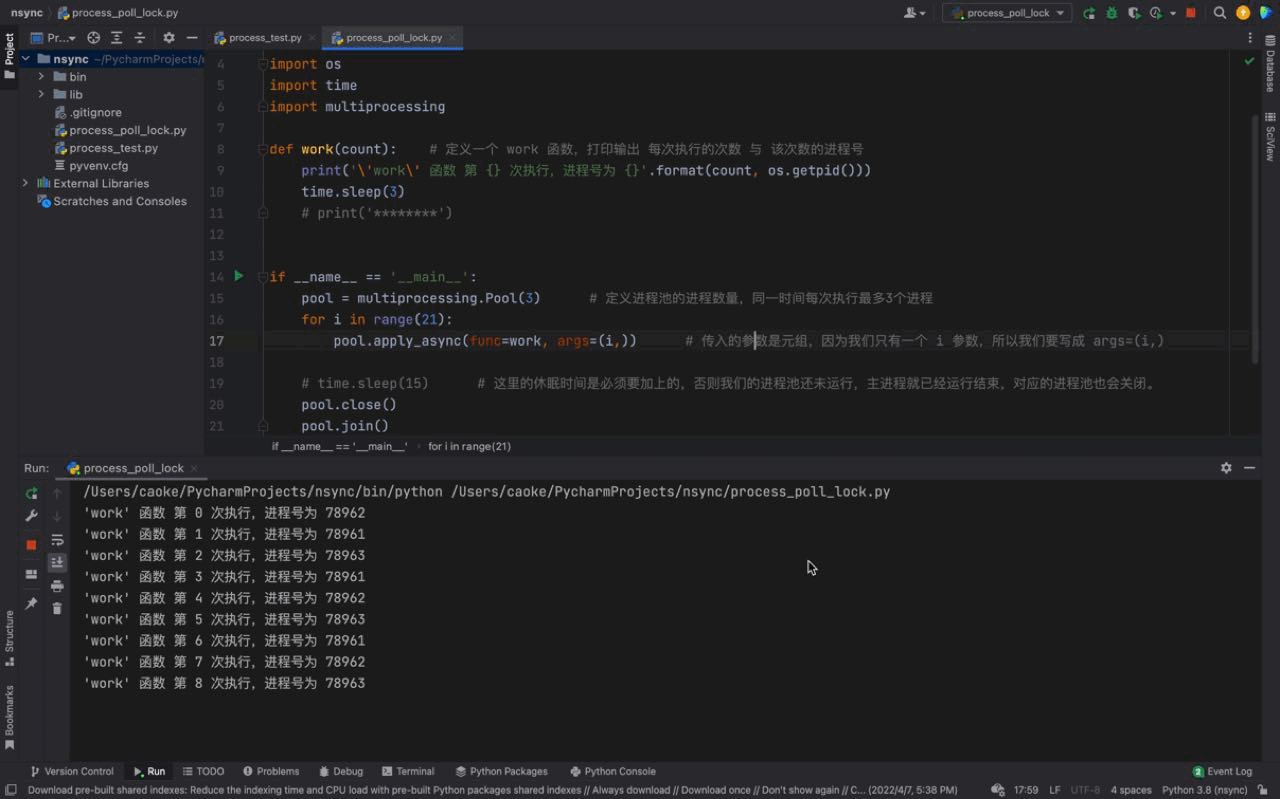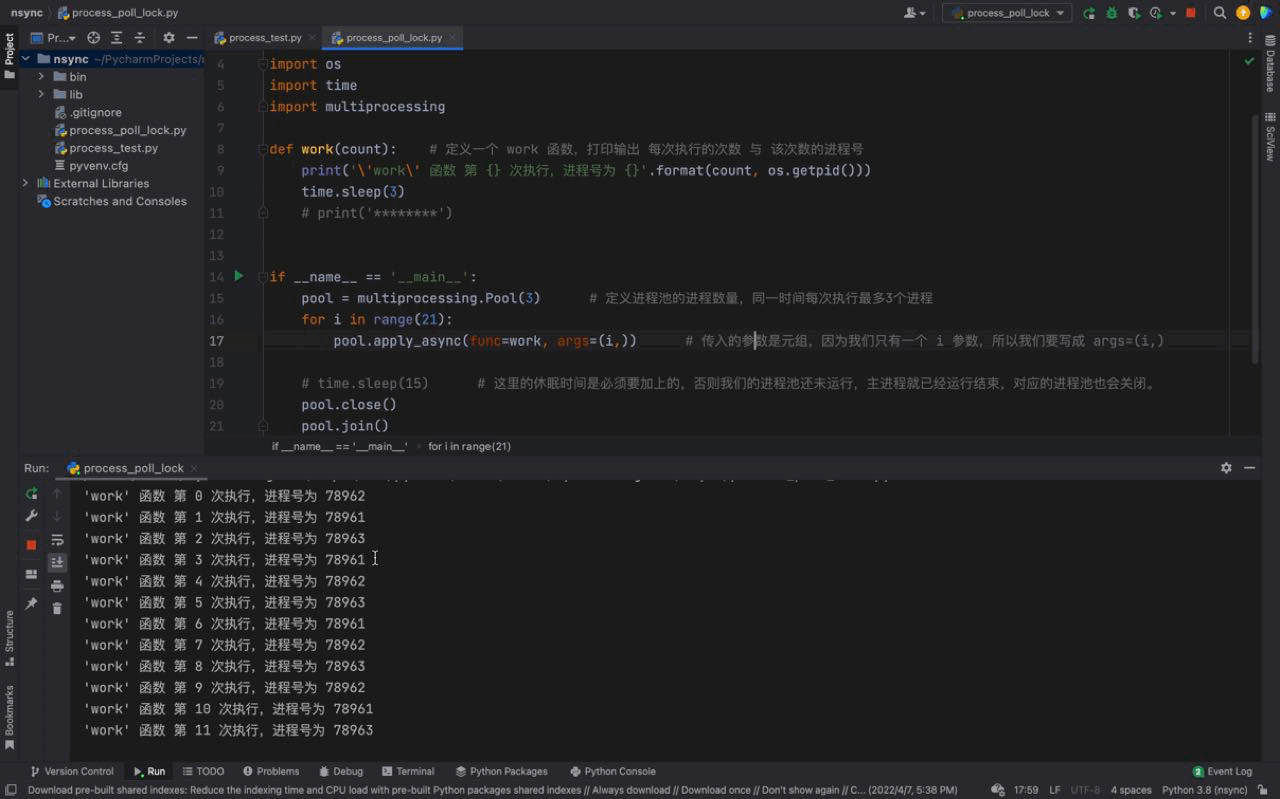
pool.join()Le résultat d'exécution est le suivant : 🎜
🎜
D'après l'animation ci-dessus, nous pouvons voir que les tâches du fonctionnent () fonction Les résultats de l'exécution du processus dans le pool de processus sont cohérents avec l'utilisation de time.sleep(15). 🎜
PS : Si notre processus principal s'exécute toujours, il ne se terminera pas. Ensuite, nous n'avons pas besoin d'ajouter les fonctions close() et join(), nous pouvons maintenir le pool de processus démarré jusqu'à ce qu'une tâche arrive et qu'elle soit exécutée. 🎜
Après avoir appris le développement WEB plus tard, il est courant de travailler sans quitter le processus principal. Certaines tâches doivent également être exécutées pendant une longue période et ne seront pas fermées. Cependant, s'il n'y a qu'un script d'exécution unique, vous devez ajouter les fonctions close() et join()<.> pour garantir que la tâche principale est terminée une fois que toutes les tâches du pool de processus sont terminées. Le processus se termine à nouveau. Bien entendu, si le processus principal est fermé, il n’acceptera plus de nouvelles tâches, ce qui signifie la fin du pool de processus. 🎜<hr>🎜<p>Regardons un autre exemple et ajoutons un retour à la <code>fonction de travail. 🎜
Vous avez peut-être une question ici. Le point de connaissance sur le processus dans le chapitre précédent indiquait clairement que le processus ne peut pas obtenir la valeur de retour, voici donc work() Quelle est la signification du <code>return ajouté à la fonction code> ? 🎜
其实不然,在我们的使用进程池的 apply_async 方法时,是通过异步的方式实现的,而异步是可以获取返回值的。针对上述脚本,我们在 for循环中针对每一个异步 apply_async 添加一个变量名,从而获取返回值。
示例代码如下:
# coding:utf-8import osimport timeimport multiprocessingdef work(count): # 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
return '\'work\' 函数 result 返回值为:{}, 进程ID为:{}'.format(count, os.getpid())if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
results = []
for i in range(21):
result = pool.apply_async(func=work, args=(i,)) # 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
results.append(result)
for result in results:
print(result.get()) # 可以通过这个方式返回 apply_async 的返回值,
# 通过这种方式也不再需要 使用 close()、join() 函数就可以正常执行。
# time.sleep(15) # 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。
# pool.close()
# pool.join()运行结果如下:
从运行结果可以看出,首先 work() 函数被线程池的线程执行了一遍,当第一组任务执行完毕紧接着执行第二次线程池任务的时候,打印输出了 apply_async 的返回值,证明返回值被成功的返回了。然后继续下一组的任务…
这些都是主要依赖于 异步 ,关于 异步 的更多知识会在 异步 的章节进行详细的介绍。
进程锁
进程锁的概念
锁:大家都知道,我们可以给一个大门上锁。
结合这个场景来举一个例子:比如现在有多个进程同时冲向一个 "大门" ,当前门内是没有 "人"的(其实就是进程),锁也没有锁上。当有一个进程进去之后并且把 “门” 锁上了,这时候门外的那些进程是进不来的。在门内的 “人” ,可以在 “门” 内做任何事情且不会被干扰。当它出来之后,会解开门锁。这时候又有一个 “人” 进去了门内,并且重复这样的操作,这就是 进程锁。它可以让锁后面的工作只能被一个任务来处理,只有它解锁之后下一个任务才会进入,这就是 “锁” 的概念。
而 进程锁 就是仅针对于 进程 有效的锁,当进程的任务开始之后,就会被上一把 “锁”;与之对应的是 线程锁 ,它们的原理几乎是一样的。
进程锁的加锁与解锁
进程锁的使用方法:
通过 multiprocessing 导入 Manager 类
from multiprocessing import Manager然后实例化 Manager
manager = Manager()再然后通过实例化后的 manager 调用 它的 Lock() 函数
lock = manager.Lock()接下来,就需要操作这个 lock 对象的函数
函数名 介绍 参数 返回值 acquire 上锁 无 无 release 解锁(开锁) 无 无
代码示例如下:
# coding:utf-8import osimport timeimport multiprocessingdef work(count, lock): # 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号,增加线程锁。
lock.acquire() # 上锁
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
lock.release() # 解锁
return '\'work\' 函数 result 返回值为:{}, 进程ID为:{}'.format(count, os.getpid())if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
manager = multiprocessing.Manager()
lock = manager.Lock()
results = []
for i in range(21):
result = pool.apply_async(func=work, args=(i, lock)) # 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
# results.append(result)
# time.sleep(15) # 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。
pool.close()
pool.join()执行结果如下:
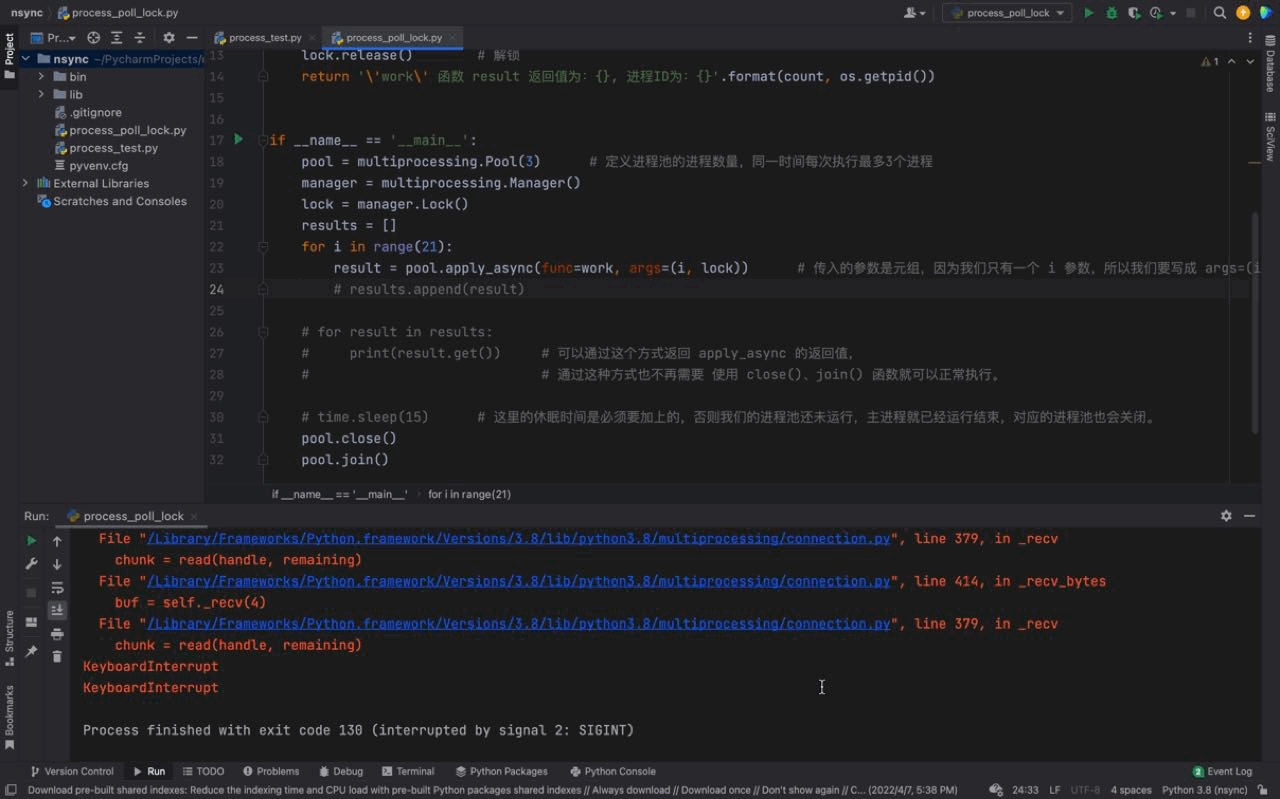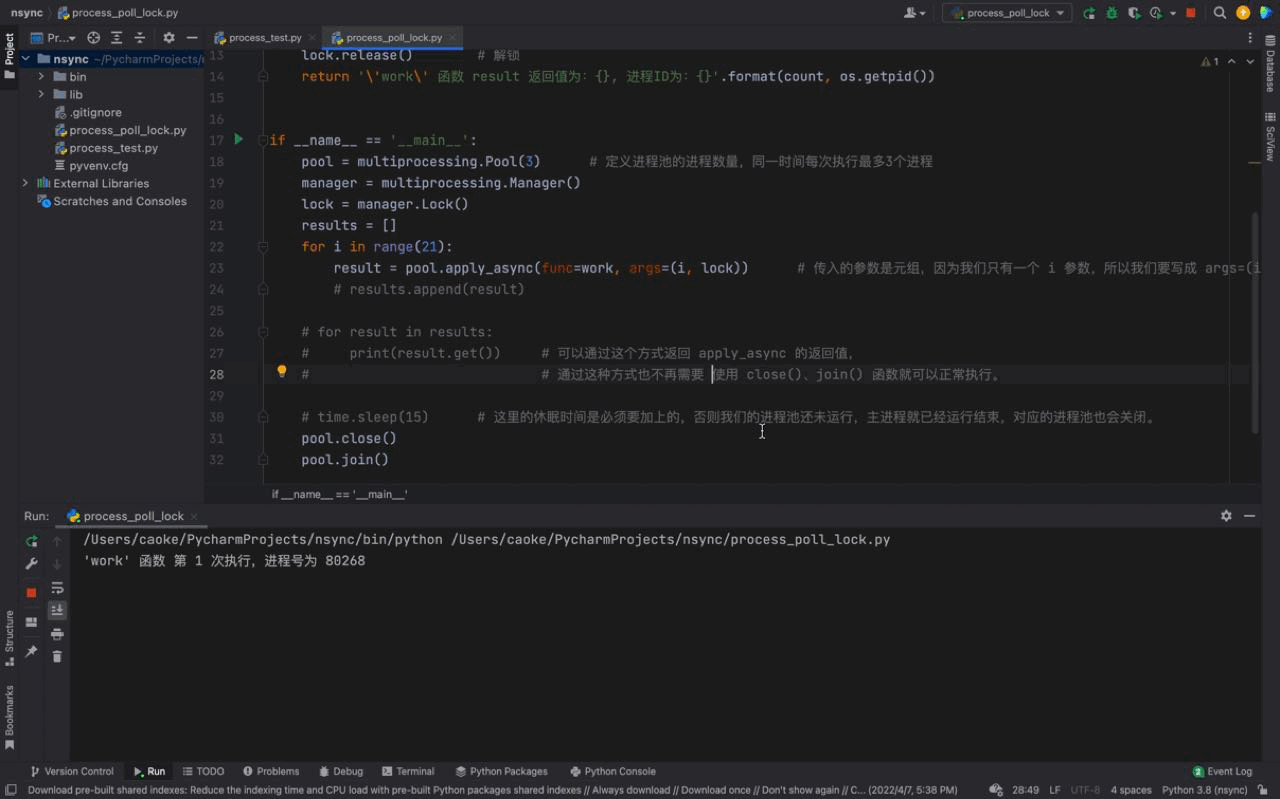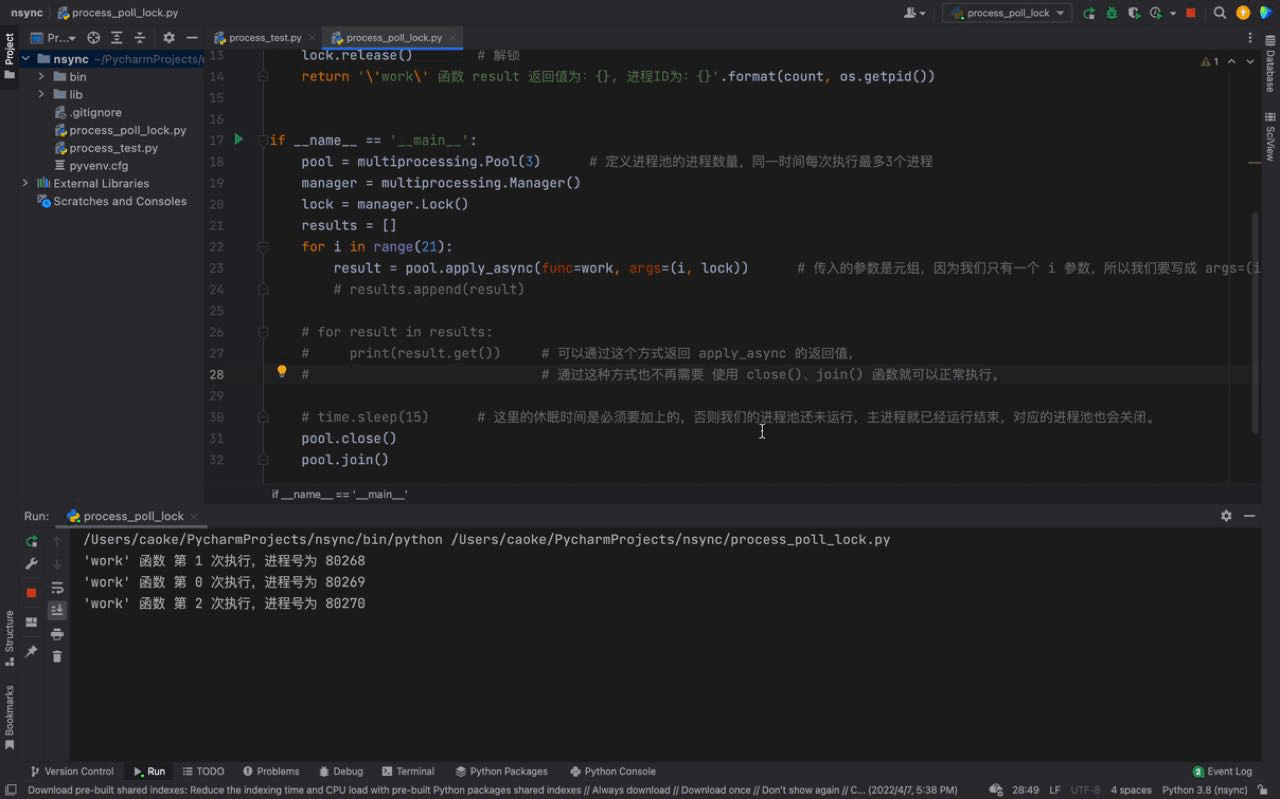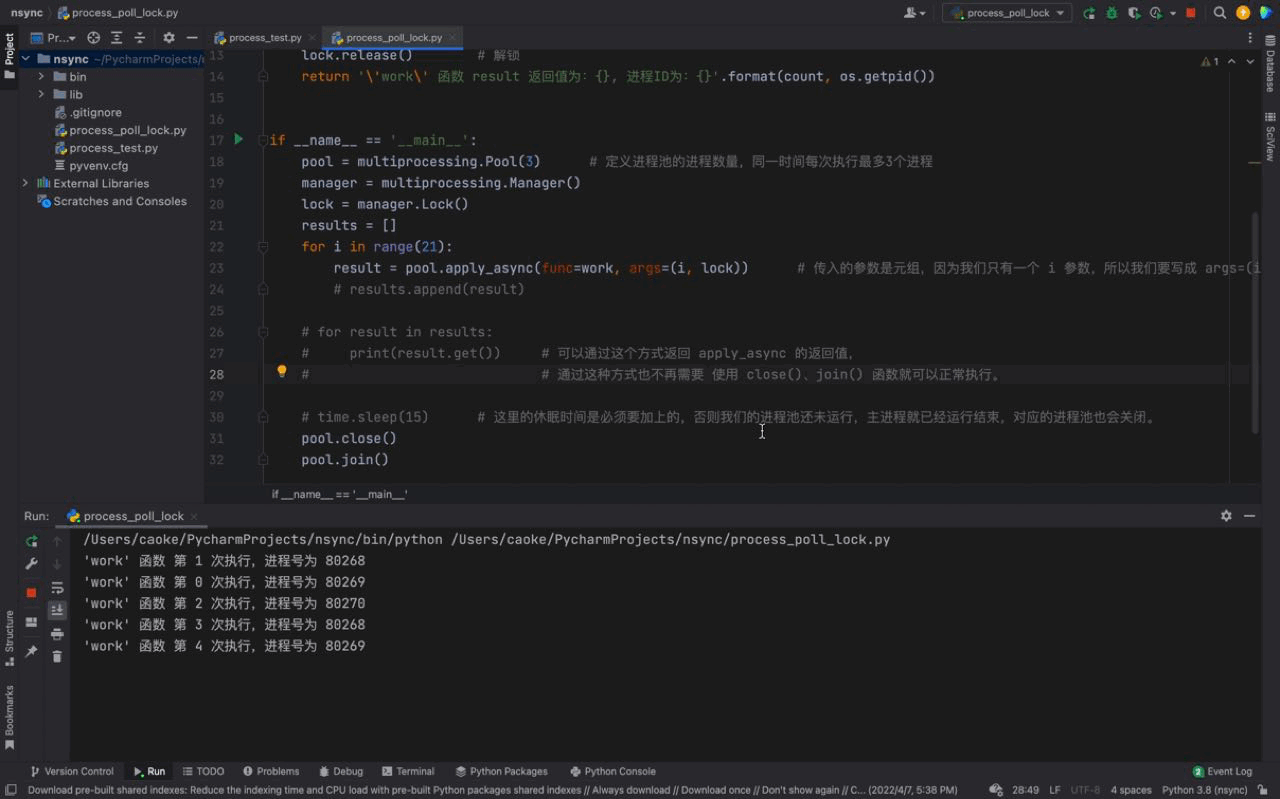
从上图中,可以看到每一次只有一个任务会被执行。由于每一个进程会被阻塞 3秒钟,所以我们的进程执行的非常慢。这是因为每一个进程进入到 work() 函数中,都会执行 上锁、阻塞3秒、解锁 的过程,这样就完成了一个进程的工作。下一个进程任务开始,重复这个过程… 这就是 进程锁的概念。
其实进程锁还有很多种方法,在 multiprocessing 中有一个直接使用的锁,就是 ``from multiprocessing import Lock。这个Lock的锁使用和我们刚刚介绍的Manager` 的锁的使用有所区别。(这里不做详细介绍,感兴趣的话可以自行拓展一下。)
锁 的使用可以让我们对某个任务 在同一时间只能对一个进程进行开发,但是 锁也不可以乱用 。因为如果某些原因造成 锁没有正常解开 ,就会造成死锁的现象,这样就无法再进行操作了。
因为 锁如果解不开 ,后面的任务也就没有办法继续执行任务,所以使用锁一定要谨慎。
推荐学习:python视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
La clé du contrôle des plumes est de comprendre sa nature progressive. Le PS lui-même ne fournit pas la possibilité de contrôler directement la courbe de gradient, mais vous pouvez ajuster de manière flexible le rayon et la douceur du gradient par plusieurs plumes, des masques correspondants et des sélections fines pour obtenir un effet de transition naturel.
 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
La plume PS est un effet flou du bord de l'image, qui est réalisé par la moyenne pondérée des pixels dans la zone de bord. Le réglage du rayon de la plume peut contrôler le degré de flou, et plus la valeur est grande, plus elle est floue. Le réglage flexible du rayon peut optimiser l'effet en fonction des images et des besoins. Par exemple, l'utilisation d'un rayon plus petit pour maintenir les détails lors du traitement des photos des caractères et l'utilisation d'un rayon plus grand pour créer une sensation brumeuse lorsque le traitement de l'art fonctionne. Cependant, il convient de noter que trop grand, le rayon peut facilement perdre des détails de bord, et trop petit, l'effet ne sera pas évident. L'effet de plumes est affecté par la résolution de l'image et doit être ajusté en fonction de la compréhension de l'image et de la saisie de l'effet.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
