

Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement les connaissances pertinentes sur les verrous au niveau des lignes dans InnoDB. Les verrous de ligne, également appelés verrous d'enregistrement, comme leur nom l'indique, sont des verrous ajoutés aux enregistrements. ensemble, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
Le verrouillage de ligne, également appelé verrouillage d'enregistrement, comme son nom l'indique, est un verrou ajouté à l'enregistrement. Mais veuillez noter que cet enregistrement fait référence au verrouillage de l'entrée d'index sur l'index. Cette fonctionnalité d'implémentation du verrouillage de ligne d'InnoDB signifie qu'InnoDB utilise des verrous au niveau de la ligne uniquement lorsque les données sont récupérées via des conditions d'index. Sinon, InnoDB utilisera des verrous de table.
Que vous utilisiez un index de clé primaire, un index unique ou un index normal, InnoDB utilisera des verrous de ligne pour verrouiller les données.
Les verrous de ligne ne peuvent être utilisés que si le plan d'exécution utilise réellement l'index : même si le champ d'index est utilisé dans la condition, l'utilisation ou non de l'index pour récupérer des données est déterminée par MySQL en jugeant le coût des différents plans d'exécution If. MySQL considère que l'analyse de la table entière est plus efficace. Par exemple, pour certaines très petites tables, il n'utilisera pas d'index. Dans ce cas, InnoDB utilisera des verrous de table au lieu de verrous de ligne.
Dans le même temps, lorsque nous utilisons des conditions de plage au lieu de conditions d'égalité pour récupérer des données et demander un verrouillage, InnoDB verrouillera les éléments d'index des enregistrements de données existants qui remplissent les conditions.
Mais même les verrous de ligne sont divisés en différents types dans InnoDB. En d'autres termes, même si un verrou de ligne est ajouté au même enregistrement, si le type est différent, l'effet sera différent.
Ici, nous utilisons toujours la table des enseignants précédente, ajoutons un index et insérons quelques enregistrements.
mysql> desc teacher; +--------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+--------------+------+-----+---------+-------+ | number | int(11) | NO | PRI | NULL | | | name | varchar(100) | YES | MUL | NULL | | | domain | varchar(100) | YES | | NULL | | +--------+--------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) mysql> select * from teacher; +--------+------+--------+ | number | name | domain | +--------+------+--------+ | 1 | T | Java | | 3 | M | Redis | | 9 | X | MQ | | 15 | O | Python | | 21 | A | Golang | +--------+------+--------+ 5 rows in set (0.00 sec)
Jetons un coup d'œil aux types courants de verrous de rangée.
Également appelés verrous d'enregistrement, ils ne verrouillent qu'un seul enregistrement. Le nom officiel du type est : LOCK_REC_NOT_GAP. Par exemple, le diagramme schématique de l'ajout d'un verrou d'enregistrement à l'enregistrement avec une valeur numérique de 9 est le suivant :
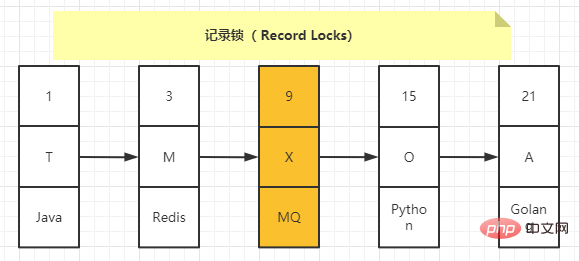
Les verrous d'enregistrement sont divisés en verrous S et verrous X Lorsqu'une transaction acquiert un verrou d'enregistrement de type S. pour un enregistrement Après cela, d'autres transactions peuvent continuer à acquérir le verrouillage d'enregistrement de type S de l'enregistrement, mais elles ne peuvent pas continuer à acquérir le verrouillage d'enregistrement de type X lorsqu'une transaction acquiert le verrouillage d'enregistrement de type X d'un autre enregistrement ; les transactions ne peuvent pas non plus continuer à acquérir le verrou d'enregistrement de type X des verrous d'enregistrement de type S, et les verrous d'enregistrement de type X ne peuvent plus être obtenus.
| T1 | T2 |
|---|---|
| begin; | |
| sélectionnez * du professeur où numéro = 9 pour la mise à jour; | |
| sélectionnez * du professeur où number=9 pour la mise à jour ; # Blocage |
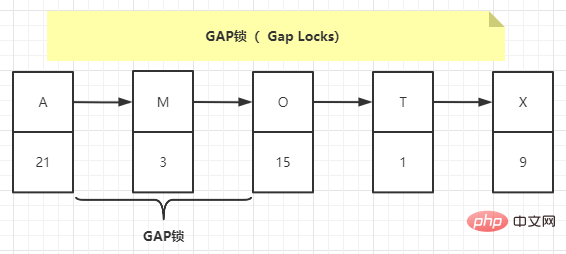
MySQL peut résoudre partiellement le problème de lecture fantôme sous le niveau d'isolement REPEATABLE READ. Vous pouvez utiliser la solution MVCC ou la solution de verrouillage. Cependant, il existe un problème lors de l'utilisation de la solution de verrouillage. Lorsque la transaction effectue l'opération de lecture pour la première fois, ces enregistrements fantômes n'existent pas encore et nous ne pouvons pas ajouter de verrous d'enregistrement à ces enregistrements fantômes. InnoDB propose un type de verrou appelé Gap Locks. Le nom officiel du type est : LOCK_GAP.
Gap Lock verrouille essentiellement l'espace avant et après l'index, mais ne verrouille pas l'index lui-même.
| T1 | T2 |
|---|---|
| begin; | |
| mettre à jour l'ensemble des enseignants domain='Redis' où name='M'; | |
| insérer dans la valeur de l'enseignant(23,'B','docker'); # Blocage | |
| insérer dans la valeur de l'enseignant(23,'B','docker'); 事务T1会对([A, 21], [M, 3])、([M, 3], [O, 15])之间进行上gap锁,如下图中所示:
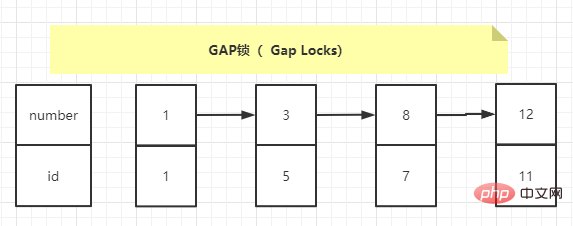
意味着不允许别的事务在这条记录前后间隙插入新记录,所以T2就不能插入。 但是当SQL语句变为: insert into teacher value(70,'P','docker'); Copier après la connexion 能插入吗?当然能,因为(70,‘P’)这条记录不在被锁的区间内。 思考题现在有表,表中有记录如下: <span style="font-family: " microsoft yahei sans gb helvetica neue tahoma arial sans-serif>list = ['su liang','hacker','ice']<br>list.insert(1,'kiko')<br>print(list)<br>#结果:['su liang', 'kiko', 'hacker', 'ice']</span><br> Copier après la connexion 开启一个事务: begin;SELECT * FROM test1 WHERE number = 3 FOR UPDATE; Copier après la connexion 开启另外一个事务: INSERT INTO test1 (id, number) VALUES (2, 1); # 阻塞 INSERT INTO test1 (id, number) VALUES (3, 2); # 阻塞 INSERT INTO test1 (id, number) VALUES (6, 8); # 阻塞 INSERT INTO test1 (id, number) VALUES (8, 8); # 正常执行 INSERT INTO test1 (id, number) VALUES (9, 9); # 正常执行 INSERT INTO test1 (id, number) VALUES (10, 12); # 正常执行 UPDATE test1 SET number = 5 WHERE id = 11 AND number = 12; # 阻塞 Copier après la connexion 为什么(6,8)不能执行,(8,8)可以执行?这个间隙锁的范围应该是[1,8],最后一个语句为什么不能执行?
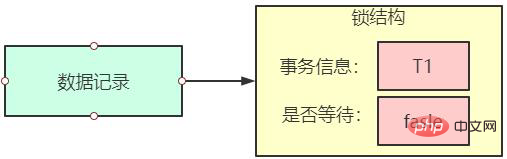
Next-Key Locks有时候我们既想锁住某条记录,又想阻止其他事务在该记录前边的间隙插入新记录,所以InnoDB就提出了一种称之为Next-Key Locks的锁,官方的类型名称为:LOCK_ORDINARY,我们也可以简称为next-key锁。next-key锁的本质就是 默认情况下,InnoDB以REPEATABLE READ隔离级别运行。在这种情况下,InnoDB使用Next-Key Locks锁进行搜索和索引扫描,这可以防止幻读的发生。 Insert Intention Locks我们说一个事务在插入一条记录时需要判断一下插入位置是不是被别的事务加了所谓的gap锁(next-key锁也包含gap 锁,后边就不强调了),如果有的话,插入操作需要等待,直到拥有gap锁的那个事务提交。 但是InnoDB规定事务在等待的时候也需要在内存中生成一个锁结构,表明有事务想在某个间隙中插入新记录,但是现在处于等待状态。这种类型的锁命名为Insert Intention Locks,官方的类型名称为:LOCK_INSERT_INTENTION,我们也可以称为插入意向锁。 可以理解为插入意向锁是一种锁的的等待队列,让等锁的事务在内存中进行排队等待,当持有锁的事务完成后,处于等待状态的事务就可以获得锁继续事务了。 隐式锁锁的的维护是需要成本的,为了节约资源,MySQL在设计提出了了一个隐式锁的概念。一般情况下INSERT操作是不加锁的,当然真的有并发冲突的情况下下,还是会导致问题的。 所以MySQL中,一个事务对新插入的记录可以不显式的加锁,但是别的事务在对这条记录加S锁或者X锁时,会去检查索引记录中的trx_id隐藏列,然后进行各种判断,会先帮助当前事务生成一个锁结构,然后自己再生成一个锁结构后进入等待状态。但是由于事务id的存在,相当于加了一个隐式锁。 这样的话,隐式锁就起到了延迟生成锁的用处。这个过程,我们无法干预,是由引擎自动处理的,对我们是完全透明的,我们知道下就行了。 锁的内存结构所谓的锁其实是一个内存中的结构,在事务执行前本来是没有锁的,也就是说一开始是没有锁结构和记录进行关联的,当一个事务想对这条记录做改动时,首先会看看内存中有没有与这条记录关联的锁结构,当没有的时候就会在内存中生成一个锁结构与之关联。比方说事务T1要对记录做改动,就需要生成一个锁结构与之关联。 锁结构里至少要有两个比较重要的属性:
当事务T1改动了条记录后,就生成了一个锁结构与该记录关联,因为之前没有别的事务为这条记录加锁,所以is_waiting 属性就是false,我们把这个场景就称之为获取锁成功,或者加锁成功,然后就可以继续执行操作了。 在事务T1提交之前,另一个事务T2也想对该记录做改动,那么先去看看有没有锁结构与这条记录关联,发现有一个锁结构与之关联后,然后也生成了一个锁结构与这条记录关联,不过锁结构的is_waiting属性值为true,表示当前事务需要等待,我们把这个场景就称之为获取锁失败,或者加锁失败,或者没有成功的获取到锁。 在事务T1提交之后,就会把该事务生成的锁结构释放掉,然后看看还有没有别的事务在等待获取锁,发现了事务T2还在等待获取锁,所以把事务T2对应的锁结构的is_waiting属性设置为false,然后把该事务对应的线程唤醒,让它继续执行,此时事务T2就算获取到锁了。这种实现方式非常像并发编程里AQS的等待队列。 对一条记录加锁的本质就是在内存中创建一个锁结构与之关联。那么,一个事务对多条记录加锁时,是不是就要创建多个锁结构呢?比如: SELECT * FROM teacher LOCK IN SHARE MODE; Copier après la connexion 很显然,这条语句需要为teacher表中的所有记录进行加锁。那么,是不是需要为每条记录都生成一个锁结构呢?其实理论上创建多个锁结构没有问题,反而更容易理解。但是如果一个事务要获取10,000条记录的锁,要生成10,000个这样的结构,不管是执行效率还是空间效率来说都是很不划算的,所以实际上,并不是一个记录一个锁结构。 当然锁结构实际是很复杂的,我们大概了解下里面包含哪些元素。
基本上来说,同一个事务里,同一个数据页面,同一个加锁类型的锁会保存在一起。 推荐学习:mysql视频教程 |
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



