- Fichier journal
- Journal des erreurs
- Activé par défaut, afficher les variables telles que '%log_error%';
- Journal des requêtes générales (Journal des requêtes générales)
- Enregistrer les instructions de requête générales, afficher les variables telles que '% general%' ;
- Journal binaire (journal binaire)
- enregistre les opérations de modification effectuées sur la base de données MySQL et enregistre l'heure d'occurrence et l'heure d'exécution de l'instruction, cependant, il n'enregistre pas la sélection, l'affichage, etc. SQL qui le fait ; ne modifiez pas la base de données. Principalement utilisé pour la récupération de bases de données et la réplication maître-esclave.
- afficher les variables comme '%log_bin%' ; //S'il faut activer
- afficher les variables comme '%binlog%' ; //Vue des paramètres
- afficher les journaux binaires ; //Afficher les fichiers journaux
- Journal des requêtes lentes ( Journal des requêtes lent)
- Enregistrez toutes les requêtes SQL dont le délai d'exécution expire, la valeur par défaut est de 10 secondes.
- afficher les variables comme '%slow_query%'; //S'il faut activer
- afficher les variables comme '%long_query_time%'; //Durée
- Le fichier de configuration
- est utilisé pour stocker tous les fichiers d'informations de configuration MySQL, tels que mon.cnf, mon.ini, etc.
- Fichier de données
- fichier db.opt : enregistre le jeu de caractères par défaut et les règles de vérification utilisées par cette bibliothèque.
- fichier frm : stocke les informations de métadonnées (méta) liées à la table, y compris les informations de définition de la structure de la table, etc. Chaque table aura un fichier frm.
- Fichier MYD : Il est dédié au moteur de stockage MyISAM et stocke les données de la table MyISAM Chaque table aura un fichier .MYD.
- Fichier MYI : dédié au moteur de stockage MyISAM, qui stocke les informations liées à l'index de la table MyISAM. Chaque table MyISAM correspond à un fichier .MYI.
- fichier ibd et fichier IBDATA : stockez les fichiers de données InnoDB (y compris les index). Le moteur de stockage InnoDB dispose de deux modes d'espace table : espace table exclusif et espace table partagé. Les espaces table exclusifs utilisent des fichiers .ibd pour stocker les données, et chaque table InnoDB correspond à un fichier .ibd. Les espaces table partagés utilisent des fichiers .ibdata et toutes les tables utilisent un (ou plusieurs fichiers .ibdata auto-configurés).
- fichier ibdata1 : fichier de données de l'espace table système, qui stocke les métadonnées de la table, les journaux d'annulation, etc.
- Fichiers ib_logfile0, ib_logfile1 : refaire les fichiers journaux.
- fichier pid
- Le fichier pid est un fichier de processus de l'application mysqld dans l'environnement Unix/Linux, comme beaucoup d'autres programmes serveur Unix/Linux, il stocke son propre identifiant de processus.
- fichier socket
- le fichier socket est également disponible dans l'environnement Unix/Linux. Les utilisateurs peuvent directement utiliser Unix Socket pour se connecter à MySQL lorsque la connexion client est établie dans un environnement Unix/Linux sans passer par le réseau TCP/IP.
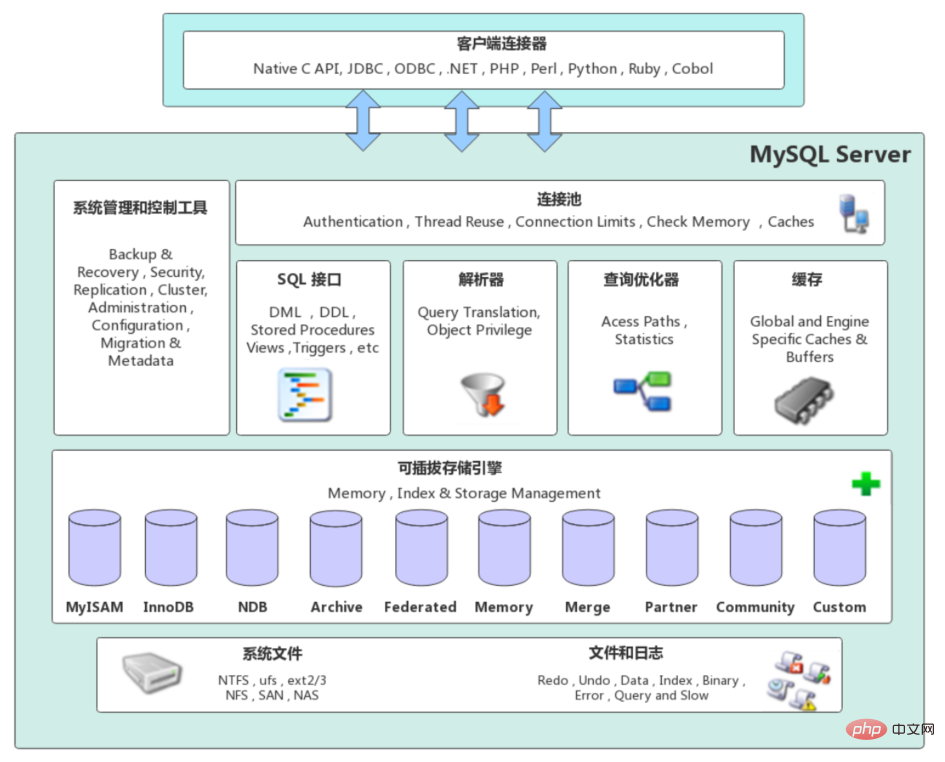
2. Mécanisme d'exploitation MySQL

- Établissez une connexion (Connecteurs et pool de connexions) et établissez une connexion avec MySQL via le protocole de communication client/serveur. La méthode de communication entre le client MySQL et le serveur est « semi-duplex ». Pour chaque connexion MySQL, il existe à tout moment un statut de thread pour identifier ce que fait la connexion.
- Mécanisme de communication :
- Duplex intégral : peut envoyer et recevoir des données en même temps, comme passer des appels téléphoniques.
- Half-duplex : fait référence à un certain moment, soit en envoyant des données, soit en recevant des données, pas en même temps. Par exemple, les premiers talkies-walkies
- simplex : ne peuvent envoyer que des données ou ne peuvent recevoir que des données. Par exemple, rue à sens unique ;
- Statut du fil : afficher la liste des processus ; //Afficher les informations sur le fil que l'utilisateur exécute, l'utilisateur root peut voir tous les fils, les autres utilisateurs ne peuvent voir que le leur
- id ; ID du fil, vous pouvez utiliser kill xx ;
- user : L'utilisateur qui a démarré ce fil
- Host : L'IP et le numéro de port du client qui a envoyé la requête
- db : Dans quelle bibliothèque la commande actuelle est exécutée
- Command : La commande d'opération en cours d'exécution par ce fil
- Create DB : création actuelle d'une opération de bibliothèque
- Drop DB : suppression d'une opération de bibliothèque
- Execute : exécution d'une instruction PreparedStatement
- Close Stmt : fermeture d'une instruction PreparedStatement
- Query : exécution d'une instruction
- Sleep : En attente que le client envoie une déclaration
- Quit : Quitter
- Shutdown : Arrêt du serveur
- Time : Indique l'heure à laquelle le thread est dans l'état actuel, en secondes
- State : Statut du thread
- Mise à jour : recherche des enregistrements correspondants et réalisation de modifications
- En veille : actuellement en attente que le client envoie une nouvelle demande
- Démarrage : le traitement de la demande est en cours
- Tableau de vérification : la table de données est en cours de vérification
- Tableau de clôture : les données dans la table est actualisée sur le disque
- Verrouillé : l'enregistrement est verrouillé par d'autres requêtes
- Envoi de données : traitement de la requête Select et envoi des résultats au client en même temps
- Info : enregistre généralement les déclarations exécuté par le thread et affiche les 100 premiers caractères par défaut. Vous voulez voir l'utilisation complète de show full processlist ;
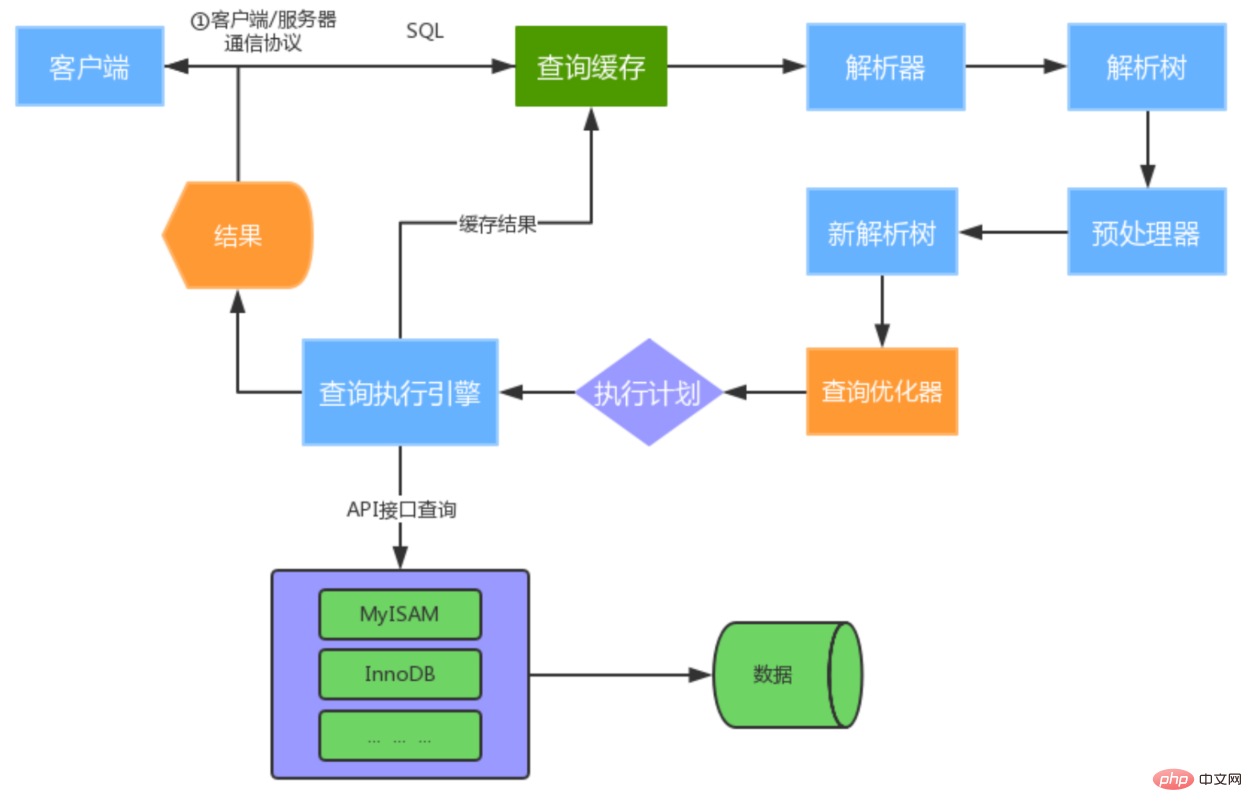
- Query Cache (Cache&Buffer), qui est un endroit dans MySQL qui peut optimiser les requêtes si le cache de requêtes est activé et que la même instruction SQL est interrogée pendant. le processus de cache de requêtes, les résultats de la requête seront renvoyés directement au client ; si le cache de requêtes n'est pas activé ou si exactement la même instruction SQL n'est pas interrogée, l'analyseur effectuera une analyse syntaxique et sémantique et générera un « arbre d'analyse ».
- Mettez en cache les résultats de la requête Select et des instructions SQL ;
- Lors de l'exécution de la requête Select, interrogez d'abord le cache pour déterminer s'il existe un jeu d'enregistrements disponible et si les exigences sont exactement les mêmes (y compris les valeurs des paramètres), de sorte que les données mises en cache correspondront ;
- Même si le cache de requêtes est activé, le code SQL suivant ne peut pas être mis en cache :
- L'instruction de requête utilise SQL_NO_CACHE
- Le résultat de la requête est supérieur au paramètre query_cache_limit
- Il y a des incertitudes paramètres dans la requête, tels que now()
- afficher les variables comme '%query_cache %' ; //Vérifier si le cache de requête est activé, la taille de l'espace, les restrictions, etc.
- afficher l'état comme 'Qcache%' ; //Affichez les paramètres de cache plus détaillés, l'espace de cache disponible, les blocs de cache, la taille du cache, etc.
- Analyse L'analyseur analyse le SQL envoyé par le client et génère un "arbre d'analyse". Le préprocesseur vérifie en outre si « l'arbre d'analyse » est légal sur la base de certaines règles MySQL. Par exemple, il vérifiera si la table de données et la colonne de données existent, et analysera également les noms et les alias pour voir s'ils sont ambigus, et enfin générera un. nouvel "arbre d'analyse".
- L'optimiseur de requêtes (Optimizer) génère le plan d'exécution optimal basé sur « l'arbre d'analyse ». MySQL utilise de nombreuses stratégies d'optimisation pour générer des plans d'exécution optimaux, qui peuvent être divisés en deux catégories : l'optimisation statique (optimisation au moment de la compilation) et l'optimisation dynamique (optimisation au moment de l'exécution).
- Stratégie de transformation équivalente
- 5=5 et a>5 est remplacé par a> 5
- a
-
Optimiser le nombre, le min, le maximum et d'autres fonctions
- La fonction min du moteur InnoDB n'a besoin que de trouver l'index le plus à gauche
- La fonction max du moteur InnoDB n'a besoin que de trouver l'index le plus à droite
- Le nombre de moteurs MyISAM (*), aucun calcul n'est requis, retournez directement
-
Terminez la requête plus tôt
- Utilisez la requête de limite pour obtenir les données requises par la limite sans continuer à parcourir les données suivantes Optimisation de dans
- MySQL va d'abord trier la requête entrante, puis utiliser la méthode de fractionnement binaire pour trouver des données. Par exemple, où id in (2,1,3) devient in (1,2,3)
Le moteur d'exécution de requête est responsable de l'exécution de l'instruction SQL. À ce stade, le moteur d'exécution de requête le fera. en fonction du stockage de la table dans l'instruction SQL. Le type de moteur et l'interface API correspondante interagissent avec le cache du moteur de stockage sous-jacent ou les fichiers physiques pour obtenir les résultats de la requête et les renvoyer au client. Si le cache de requêtes est activé, l'instruction SQL et les résultats seront entièrement enregistrés dans le cache de requêtes (Cache&Buffffer). Si la même instruction SQL est exécutée ultérieurement, les résultats seront renvoyés directement.
- Si la mise en cache des requêtes est activée, mettez d'abord en cache les résultats de la requête
- Il y a trop de résultats renvoyés, utilisez le mode incrémentiel pour revenir
- Lors du démarrage de l'exécution, vous devez d'abord déterminer si vous avez l'autorisation d'exécuter des requêtes sur cette table T. Si non, une erreur d'absence d'autorisation sera renvoyée. (Si le cache de requêtes est atteint, la vérification des autorisations sera effectuée lorsque le cache de requêtes renvoie les résultats. La requête appellera également precheck pour vérifier les autorisations avant l'optimiseur).
- Si vous avez la permission, ouvrez la table et poursuivez l'exécution. Lorsqu'une table est ouverte, l'exécuteur utilisera l'interface fournie par le moteur en fonction de la définition du moteur de la table. Le flux d'exécution de l'exécuteur est le suivant :
- sélectionnez * from test which age > 10 ;
- Appelez l'interface du moteur InnoDB pour obtenir la première ligne de ce tableau et déterminez si la valeur d'âge est 10. Sinon, ignorez stockez ensuite cette ligne dans l'ensemble de résultats ;
- Appelez l'interface du moteur pour obtenir la "ligne suivante" et répétez la même logique de jugement jusqu'à ce que la dernière ligne de ce tableau soit récupérée.
- L'exécuteur renvoie au client un ensemble d'enregistrements composé de toutes les lignes qui remplissent les conditions lors du processus de parcours ci-dessus en tant qu'ensemble de résultats.
-
3. Moteur de stockage Mysql
Le moteur de stockage est situé au niveau de la troisième couche de l'architecture MySQL. Il est responsable du stockage et de l'extraction des données dans MySQL. .Il est basé surMySQL Un mécanisme d'accès aux fichiers personnalisé par l'interface abstraite de la couche d'accès aux fichiers fournie. Ce mécanisme est appelé moteur de stockage. Utilisez la commande
show moteurs pour afficher les informations sur le moteur prises en charge par la base de données actuelle.
Le moteur de stockage MyISAM était utilisé par défaut avant la version 5.5, et le moteur de stockage InnoDB était utilisé à partir de la version 5.5.
- InnoDB : prend en charge les transactions, possède des capacités de validation, de restauration et de récupération après incident, sécurité des transactions ;
- MyISAM : ne prend pas en charge les transactions et les clés étrangères, la vitesse d'accès est rapide
- Mémoire : utilise la mémoire pour créer des tables, la vitesse d'accès est très rapide ; rapide, car Les données sont en mémoire et l'index de hachage est utilisé par défaut, mais une fois fermé, les données seront perdues
- Archive : moteur de type archive, ne prend en charge que les instructions d'insertion et de sélection ; dans les fichiers CSV, en raison des limitations des fichiers, toutes les colonnes doivent obligatoirement être spécifiées non nulles. De plus, le moteur CSV ne prend pas en charge les index et les partitions, il convient donc aux tables intermédiaires pour l'échange de données. seulement en entrant mais pas en sortant, disparaissant lors de la saisie, et toutes les données insérées ne seront pas enregistrées
- Fédéré : peut accéder aux tables des bases de données MySQL distantes ; Une table locale ne sauvegarde pas les données et accède au contenu d'une table distante.
- MRG_MyISAM : Une combinaison d'un groupe de tables MyISAM. Ces tables MyISAM doivent avoir la même structure. La table Merge elle-même n'a pas de données. L'opération Merge peut opérer sur un groupe de tables MyISAM ;
- Transactions et clés étrangères
- InnoDB prend en charge les transactions et les clés étrangères, avec sécurité et intégrité, adaptées à un grand nombre d'opérations d'insertion ou de mise à jour
MyISAM ne prend pas en charge les transactions et les clés étrangères, il fournit un stockage et une récupération à grande vitesse , adapté à un grand nombre d'opérations de requête sélectionnées
mécanisme de verrouillage- InnoDB prend en charge le verrouillage au niveau des lignes, en verrouillant les enregistrements spécifiés. Le verrouillage est implémenté en fonction de l'index.
- MyISAM prend en charge le verrouillage au niveau de la table, verrouillant ainsi la table entière.
Structure de l'index- InnoDB utilise un index clusterisé (index clusterisé). L'index et les enregistrements sont stockés ensemble, mettant en cache à la fois l'index et les enregistrements.
- MyISAM utilise un index non clusterisé (index non clusterisé), l'index et l'enregistrement sont séparés.
Capacité de traitement simultané- MyISAM utilise des verrous de table, ce qui entraînera un faible taux de simultanéité des opérations d'écriture, aucun blocage entre les lectures et le blocage des lectures et des écritures.
- Le blocage de lecture et d'écriture d'InnoDB peut être lié au niveau d'isolement, et le contrôle de concurrence multi-versions (MVCC) peut être utilisé pour prendre en charge une concurrence élevée
-
Fichiers de stockage - La table InnoDB correspond à deux fichiers, un .frm fichier de structure de table et un fichier de données .ibd. La table InnoDB prend en charge jusqu'à 64 To ;
- La table MyISAM correspond à trois fichiers, un fichier de structure de table .frm, un fichier de données de table MYD et un fichier d'index .MYI. À partir de
MySQL5.0, la limite par défaut est de 256 To.
- Scénarios applicables
- MyISAM
Aucune prise en charge des transactions requise (non prise en charge)
La modification des données est relativement faible, principalement la lectureLes exigences de cohérence des données ne sont pas élevées -
- InnoDB
- Nécessite une prise en charge des transactions (a de meilleures caractéristiques de transaction)
- Le verrouillage au niveau des lignes a une bonne adaptabilité à une concurrence élevée
Exigences de cohérence des données plus élevées- Si le périphérique matériel dispose d'une grande mémoire , vous pouvez utiliser les meilleures capacités de mise en cache d'InnoDB pour améliorer l'utilisation de la mémoire et réduire les E/S disque
-
-
- Résumé
- Comment choisir entre les deux moteurs ?
poursuit-il des requêtes rapides et peu de modifications de données ? Oui, MyISAMDans la plupart des cas, il est recommandé d'utiliser InnoDB-
-
-
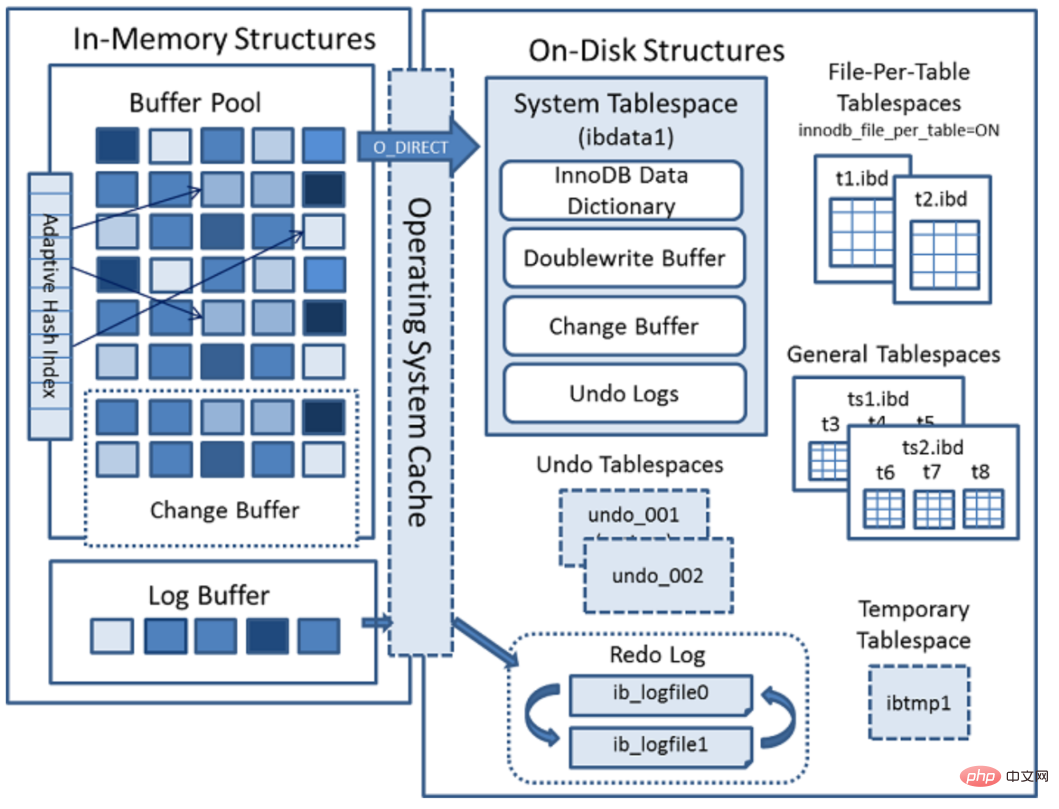
- Structure de stockage InnoDB
Structure de mémoire InnoDB
La structure de mémoire comprend principalement quatre composants : Buffer Pool, Change Buffer, Adaptive Hash Index et Log Buffer.
- Buffer Pool : pool tampon, appelé BP. BP est basé sur la page, avec une taille par défaut de 16 Ko. La couche inférieure de BP utilise une structure de données de liste chaînée pour gérer les pages. Lorsque InnoDB accède aux enregistrements et aux index de table, ils seront mis en cache dans la page Page. Une utilisation ultérieure peut réduire les opérations d'E/S sur le disque et améliorer l'efficacité.
- Mécanisme de gestion des pages
- La page peut être divisée en trois types selon le statut :
- page libre : page inactive, non utilisée
- page propre : page utilisée, les données n'ont pas été modifiées
- page sale : page sale, la la page est utilisée, les données ont été modifiées et les données de la page et les données sur le disque sont incohérentes
- Pour les trois types de pages ci-dessus, InnoDB les maintient et les gère via trois structures de listes chaînées :
- gratuit. list : représente le tampon libre, gère la page libre
- flush list : indique le tampon qui doit être vidé sur le disque, gère les pages sales et les pages internes sont triées par heure de modification. Des pages sales existent à la fois dans la liste chaînée de vidage et dans la liste chaînée LRU, mais elles ne s'affectent pas les unes les autres. La liste chaînée LRU est responsable de la gestion de la disponibilité et du stockage des pages, tandis que la liste chaînée vidage est responsable de la gestion de l'opération de vidage. de pages sales.
- liste lru : indique le tampon utilisé, gère la page propre et la page sale, le tampon est basé sur le point médian, la liste liée avant est appelée la nouvelle zone de liste, qui stocke les données fréquemment consultées, représentant 63 % de ces dernières liées ; la liste est appelée ancienne. La zone de liste stocke les données les moins utilisées, représentant 37 %.
-
Maintenance améliorée de l'algorithme LRU
- LRU ordinaire : méthode d'élimination de fin, les nouvelles données sont ajoutées depuis la tête de la liste chaînée et sont éliminées depuis la fin lorsque l'espace est libéré.
- LRU modifié : la liste chaînée est divisée en deux parties, la nouvelle et l'ancienne. en ajoutant des éléments, ils ne sont pas insérés à partir de la tête de la liste, mais à partir de la position médiane. Si les données sont accessibles rapidement, la page se déplacera vers la tête de la nouvelle liste. n'a pas été consulté, il se déplacera progressivement à la fin de l'ancienne liste et attendra son élimination.
- Chaque fois que de nouvelles données de page sont lues dans le pool de tampons, le moteur InnoDb déterminera s'il y a des pages libres et si elles sont suffisantes, si c'est le cas, la page gratuite sera supprimée de la liste libre et placée dans la liste LRU. S'il n'y a pas de pages libres, la page par défaut de la liste chaînée LRU sera éliminée selon l'algorithme LRU, et l'espace mémoire sera libéré et alloué à de nouvelles pages.
- Paramètres de configuration du pool de tampons
- afficher les variables comme '%innodb_page_size%' ; //Afficher la taille de la page
- afficher les variables comme '%innodb_old%' ; //Afficher les anciens paramètres de liste dans la liste lru
- afficher les variables comme '%innodb_buffer%'; //Vérifiez les paramètres du pool de mémoire tampon
- Recommandation : définissez innodb_buffer_pool_size sur 60 % à 80 % de la taille totale de la mémoire, et innodb_buffer_pool_instances peut être défini sur plusieurs pour éviter les conflits de cache.
- Change Buffer : Tampon d'écriture, appelé CB. Lors de l'exécution d'une opération DML, si BP n'a pas ses données de page correspondantes, la page du disque ne sera pas immédiatement chargée dans le pool de tampons. Au lieu de cela, les modifications du tampon seront enregistrées dans CB, et lorsque les données futures seront lues, les données. sera fusionné et restauré au milieu BP.
- ChangeBuffer occupe l'espace BufferPool. La valeur par défaut est de 25 % et le maximum autorisé est de 50 %. Il peut être ajusté en fonction du volume d'activité de lecture et d'écriture. Paramètre innodb_change_buffer_max_size;
- Lorsqu'un enregistrement est mis à jour, l'enregistrement existe dans le BufferPool et est modifié directement dans le BufferPool, une opération mémoire. Si l'enregistrement n'existe pas dans le BufferPool (pas de hit), une opération mémoire sera effectuée directement dans le ChangeBuffer sans avoir à interroger le disque pour les données et éviter une E/S disque. Lorsque l'enregistrement sera interrogé la prochaine fois, il sera d'abord lu à partir du disque, puis les informations seront lues à partir du ChangeBuffer et fusionnées, et enfin chargées dans le BufferPool.
- Tampon d'écriture, applicable uniquement aux pages d'index ordinaires non uniques
- Si l'unicité est définie dans l'index, InnoDB doit effectuer une vérification de l'unicité lors des modifications, le disque doit donc être interrogé et une opération IO doit être effectuée. L'enregistrement sera directement interrogé dans le BufferPool puis modifié dans le pool de tampons. Il ne sera pas exploité dans ChangeBuffer.
- Indice de hachage adaptatif : index de hachage adaptatif, utilisé pour optimiser les requêtes pour les données BP. Le moteur de stockage InnoDB surveillera la recherche d'index de table. S'il est observé que la construction d'un index de hachage peut améliorer la vitesse, il construira un index de hachage, il est donc appelé adaptatif. Le moteur de stockage InnoDB crée automatiquement des index de hachage pour certaines pages en fonction de la fréquence et du modèle d'accès.
- Log Buffer : Le tampon de journal est utilisé pour enregistrer les données à écrire dans le fichier journal (Redo/Undo) sur le disque. Le contenu du tampon de journal est régulièrement actualisé dans le fichier journal du disque. Lorsque le tampon de journal est plein, il sera automatiquement vidé sur le disque. Lors d'opérations de transaction volumineuses telles que des BLOB ou des mises à jour multi-lignes, l'augmentation du tampon de journal peut économiser les E/S du disque.
- LogBuffer est principalement utilisé pour enregistrer les journaux du moteur InnoDB. Les journaux de rétablissement et d'annulation seront générés lors des opérations DML.
- Lorsque l'espace LogBuffer est plein, il sera automatiquement écrit sur le disque.Vous pouvez réduire la fréquence d'E/S du disque en augmentant le paramètre innodb_log_buffer_size ; le paramètre
- innodb_flush_log_at_trx_commit contrôle le comportement d'actualisation du journal, la valeur par défaut est 1
- 0 : écriture des fichiers journaux et vidage des opérations sur le disque toutes les 1 seconde (écriture du fichier journal LogBuffer --> Cache du système d'exploitation, vider le cache du système d'exploitation -> fichier disque), les données seront perdues pendant 1 seconde maximum
- 1 : Soumission de la transaction, écriture du fichier journal et vidage du disque immédiatement, les données ne seront pas perdues, mais des opérations d'E/S fréquentes se produiront
- 2 : Soumission de la transaction, écrivez immédiatement les fichiers journaux et effectuez des opérations de vidage du disque toutes les 1 seconde
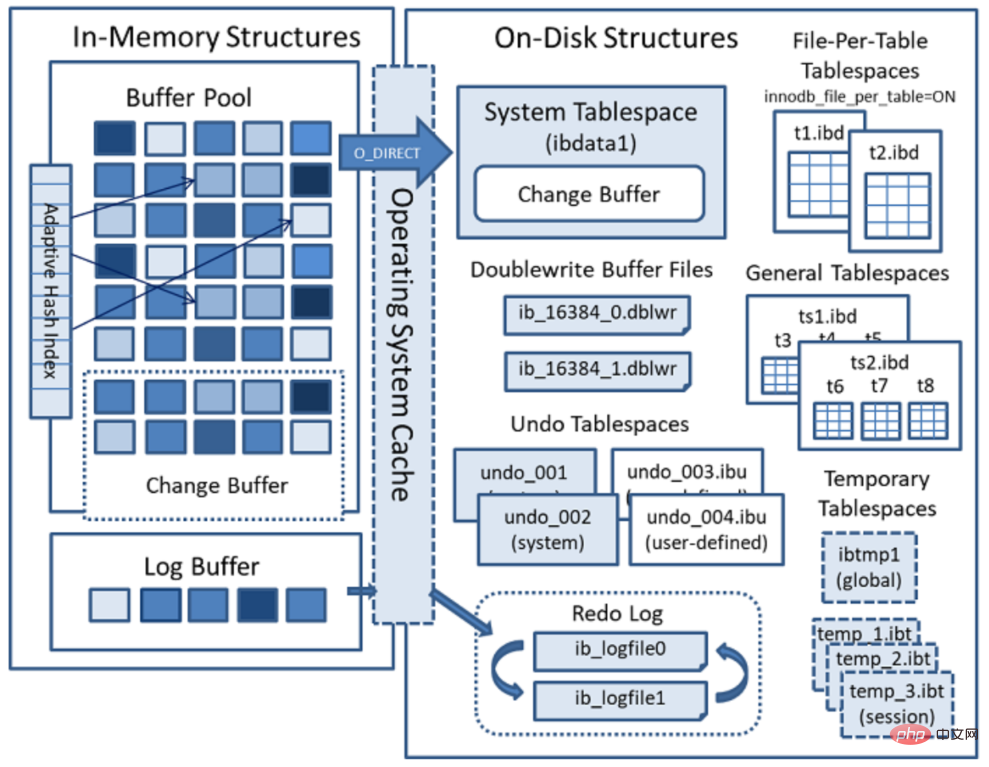
Structure du disque InnoDB
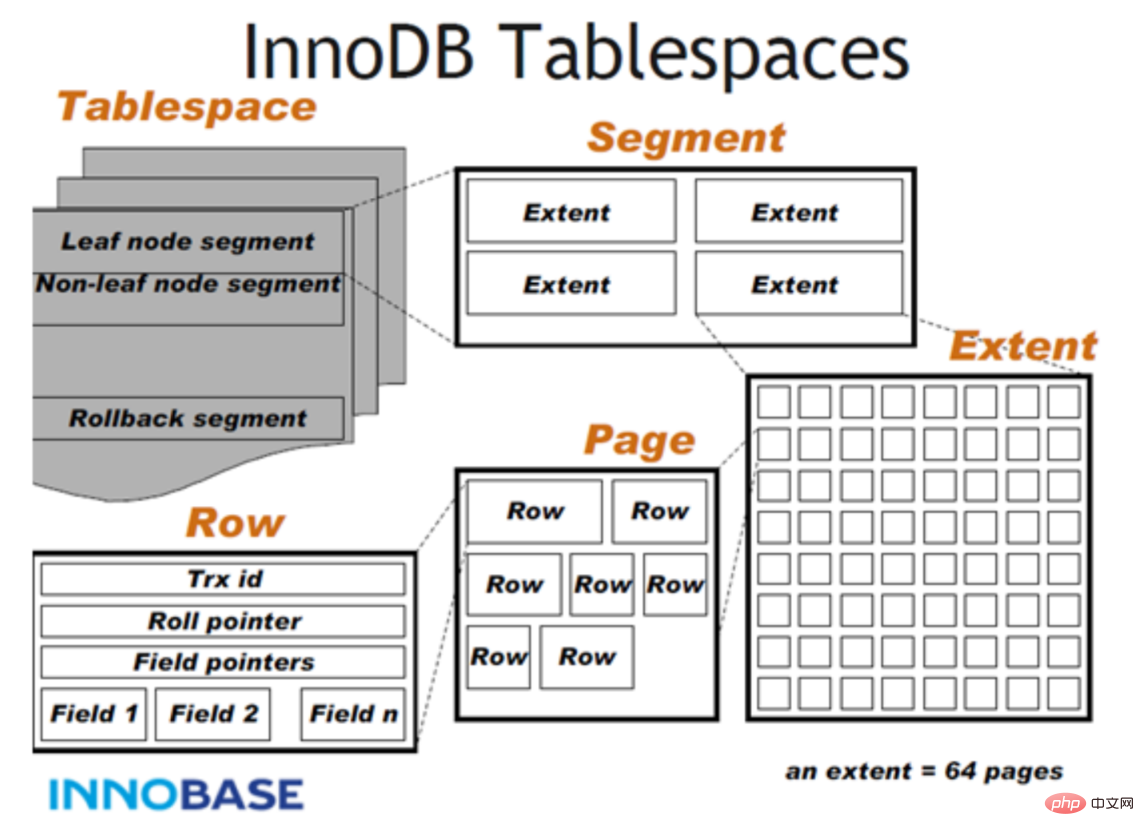
Le disque InnoDB comprend principalement des espaces de table, un dictionnaire de données InnoDB, un tampon de double écriture, un journal de rétablissement et des journaux d'annulation.
-
Tablespaces : utilisés pour stocker les structures et les données des tables. Les espaces table sont divisés en espace table système, espace table indépendant, espace table général, espace table temporaire, espace table d'annulation et autres types
-
L'espace table système (l'espace table système)
- comprend le dictionnaire de données InnoDB, le stockage Doublewrite ; zone pour les journaux de tampon, de tampon de modification et d'annulation. L'espace table système contient également des données de table et des données d'index créées par défaut par n'importe quel utilisateur dans l'espace table système. Le tablespace système est un tablespace partagé car il est partagé par plusieurs tables. Le fichier de données de cet espace est contrôlé par le paramètre innodb_data_file_path. La valeur par défaut est ibdata1:12M:autoextend (le nom du fichier est ibdata1, 12 Mo, automatiquement étendu).
CREATE TABLESPACE ts1 ADD DATAFILE ts1.ibd Engine=InnoDB; //创建表空 间ts1 CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1; //将表添加到ts1 表空间
Copier après la connexion
-
Espace de table indépendant (espaces de table fichier par table)
- est activé par défaut. Un espace de table indépendant est un espace de table à table unique. La table est créée dans son propre fichier de données, pas dans le système. l'espace table. Lorsque l'option innodb_file_per_table est activée, des tables seront créées dans le tablespace. Sinon, innodb sera créé dans l'espace table système. Chaque tablespace de fichier table est représenté par un fichier de données .ibd, créé par défaut dans le répertoire de la base de données. Les fichiers de table d'espace table prennent en charge les formats de ligne dynamiques (dynamiques) et compressés (compressés).
-
Tablespaces généraux
- Les tablespaces généraux sont des tablespaces partagés créés via la syntaxe create tablespace. L'espace table général peut être créé dans d'autres espaces table en dehors du répertoire de données mysql. Il peut accueillir plusieurs tables et prend en charge tous les formats de lignes.
-
Tablespaces d'annulation
- Le tablespace d'annulation se compose d'un ou plusieurs fichiers contenant des fichiers journaux d'annulation. Avant MySQL 5.7, l'annulation occupait la zone partagée de l'espace table système. À partir de la version 5.7, l'annulation était séparée de l'espace table système.
- Le tablespace d'annulation utilisé par InnoDB est contrôlé par l'option de configuration innodb_undo_tablespaces, qui est par défaut 0. Une valeur de paramètre de 0 signifie que vous utilisez l'espace table système ibdata1 ; une valeur de paramètre supérieure à 0 signifie que vous utilisez les espaces table d'annulation undo_001, undo_002, etc.
-
Les tablespaces temporaires
- sont divisés en deux types : les tablespaces temporaires de session et les tablespaces temporaires globaux :
- les tablespaces temporaires de session stockent les tables temporaires créées par les utilisateurs et les tables temporaires à l'intérieur du disque.
- l'espace de table temporaire global stocke les segments d'annulation des tables temporaires des utilisateurs (segments d'annulation). Lorsque le serveur MySQL est arrêté normalement ou se termine anormalement, l'espace table temporaire sera supprimé et recréé à chaque démarrage.
-
Dictionnaire de données (Dictionnaire de données InnoDB)
- Le dictionnaire de données InnoDB se compose de tables système internes qui contiennent des métadonnées pour des objets tels que des tables de recherche, des index et des champs de table. Les métadonnées sont physiquement situées dans l'espace de table du système InnoDB. Pour des raisons historiques, les métadonnées du dictionnaire de données chevauchent dans une certaine mesure les informations stockées dans les fichiers de métadonnées des tables InnoDB (fichiers .frm).
-
Doublewrite Buffer
- est situé dans l'espace table système et est une zone de stockage. Avant que la page BufferPage ne soit vidée vers l'emplacement réel sur le disque, les données seront stockées dans le tampon Doublewrite. Si le système d'exploitation, le sous-système de stockage ou le processus mysqld plante pendant l'écriture de la page, InnoDB peut trouver une bonne sauvegarde de la page à partir du tampon Doublewrite lors de la récupération après crash. Dans la plupart des cas, le tampon doublewrite est activé par défaut. Pour désactiver le tampon Doublewrite, vous pouvez définir innodb_doublewrite sur 0. Il est recommandé de définir innodb_flush_method sur O_DIRECT lors de l'utilisation du tampon Doublewrite.
- Le paramètre innodb_flush_method de MySQL contrôle les modes d'ouverture et de vidage des fichiers de données innodb et des journaux de rétablissement. Il existe trois valeurs : fdatasync (par défaut), O_DSYNC, O_DIRECT. Le réglage de O_DIRECT signifie que l'opération d'écriture du fichier de données informera le système d'exploitation de ne pas mettre les données en cache, de ne pas utiliser la pré-lecture et d'écrire directement depuis InnodbBuffer vers le fichier disque.
- Le fdatasync par défaut signifie d'abord écrire dans le cache du système d'exploitation, puis appeler la fonction fsync() pour vider de manière asynchrone les informations de cache du fichier de données et refaire le journal.
-
Refaire le journal
- Le journal redo est une structure de données basée sur disque utilisée pour corriger les données écrites par des transactions incomplètes lors d'une récupération après incident. MySQL écrit les fichiers de journalisation de manière circulaire et enregistre toutes les modifications apportées au pool de tampons dans InnoDB. Lorsqu'une panne d'instance se produit (telle qu'une panne de courant) et que les données ne parviennent pas à être mises à jour dans le fichier de données, la base de données doit être refaite au redémarrage de la base de données pour mettre à jour à nouveau les données dans le fichier de données. Lors de l'exécution des transactions de lecture et d'écriture, des journaux redo continueront à être générés. Par défaut, le journal redo est physiquement représenté sur le disque par deux fichiers nommés ib_logfile0 et ib_logfile1.
-
Journaux d'annulation
- Les journaux d'annulation sont des sauvegardes de données modifiées enregistrées avant le début d'une transaction, utilisées pour annuler des transactions dans des circonstances exceptionnelles. Le journal d'annulation est un journal logique et est enregistré ligne par ligne. Les journaux d'annulation existent dans les tablespaces système, les tablespaces d'annulation et les tablespaces temporaires.
Évolution de la structure de la nouvelle version
- La version MySQL 5.7
- sépare l'espace table du journal d'annulation du fichier ibdata de l'espace table partagé, et l'utilisateur peut spécifier la taille et la quantité du fichier lors de l'installation de MySQL.
- Ajout d'un espace table temporaire, qui stocke les données des tables temporaires ou des ensembles de résultats de requêtes temporaires.
- La taille du pool de tampons peut être modifiée dynamiquement sans redémarrer l'instance de base de données.
- La version MySQL 8.0
- sépare complètement le dictionnaire de données et l'annulation de la table InnoDB de l'espace table partagé ibdata. Dans le passé, le dictionnaire de données dans ibdata devait être cohérent avec le dictionnaire de données dans l'espace table indépendant ibd. fichier. Version 8.0 Ce n'est pas nécessaire.
- l'espace table temporaire peut également être configuré avec plusieurs fichiers physiques, et ce sont tous des moteurs de stockage InnoDB et peuvent créer des index, ce qui accélère le traitement.
- Les utilisateurs peuvent configurer certains espaces table comme la base de données Oracle. Chaque espace table correspond à plusieurs fichiers physiques. Chaque espace table peut être utilisé par plusieurs tables, mais une table ne peut être stockée que dans un seul espace table.
- Le tampon Doublewrite est également séparé de l'espace table partagé ibdata.
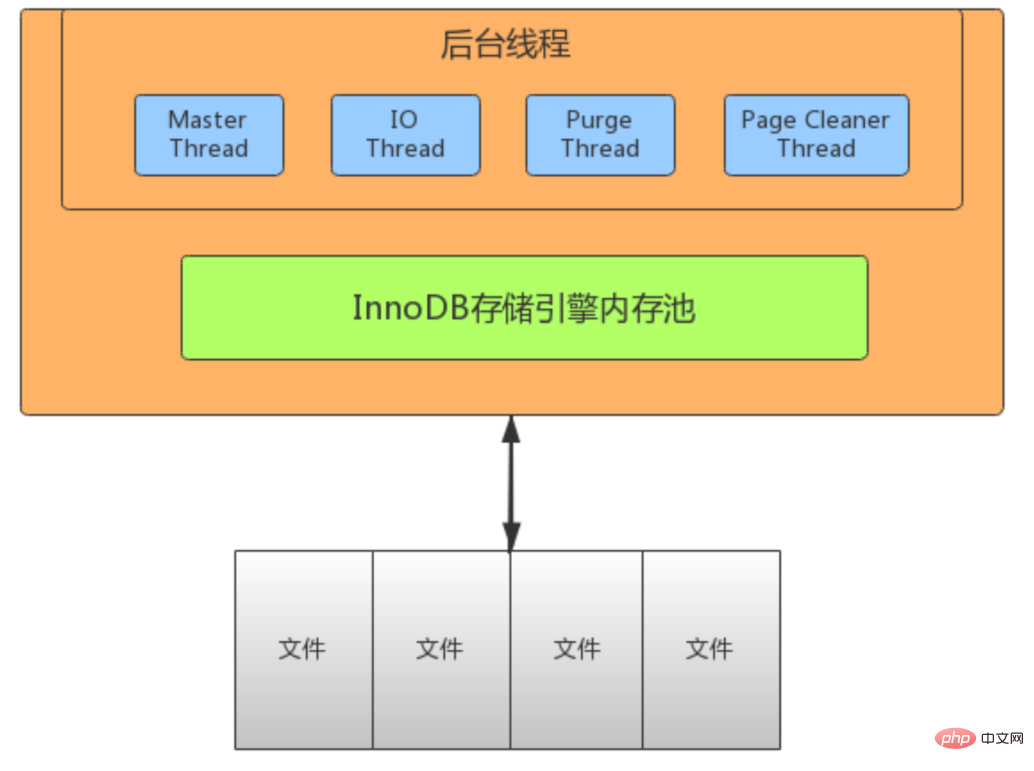
Modèle de thread InnoDB
- IO Thread
- utilise une grande quantité d'AIO (Async IO) dans InnoDB pour le traitement de lecture et d'écriture, ce qui peut considérablement améliorer les performances de la base de données. Il y a 10 threads IO dans InnoDB, dont 4 écritures, 4 lectures, 1 tampon d'insertion et 1 thread de journal.
fil de lecture : responsable des opérations de lecture et du chargement des données du disque vers la page de cache. 4 - threads d'écriture : responsables des opérations d'écriture et du vidage des pages sales mises en cache sur le disque. 4
- fils de journal : responsables du vidage du contenu du tampon de journal sur le disque. 1
- insérer le thread du tampon : responsable du vidage du contenu du tampon d'écriture sur le disque. Une fois qu'une transaction
-
Purge Thread est validée, le journal d'annulation utilisé par celle-ci ne sera plus nécessaire, donc Purge Thread doit recycler les pages d'annulation allouées. - afficher des variables comme '%innodb_purge_threads%';
-
La fonction consiste à vider les données sales sur le disque. Une fois les données sales vidées, le journal de rétablissement correspondant peut être écrasé, ce qui signifie que. les données peuvent être synchronisées et le - Atteindre l'objectif de recyclage des journaux redo. Le traitement du thread du thread d'écriture sera appelé.
afficher des variables comme '%innodb_page_cleaners%';-
-
Le thread principal est le thread principal d'InnoDB, responsable de la planification des autres threads, avec la priorité la plus élevée. Sa fonction est d'actualiser de manière asynchrone les données du pool de mémoire tampon sur le disque pour garantir la cohérence des données. Y compris : actualisation des pages sales (fil de nettoyage de page), annulation du recyclage de pages (fil de purge), actualisation du journal de rétablissement (fil de journal), tampon d'écriture fusionné, etc. Il y a deux processus principaux à l’intérieur, un toutes les secondes et un toutes les 10 secondes. - Opérations toutes les secondes :
Actualisez le tampon du journal et videz-le sur le disque - Fusionnez les données du tampon d'écriture, décidez si vous souhaitez opérer en fonction de la pression de lecture et d'écriture des E/S
- Actualisez les données des pages sales sur le disque, en fonction du taux de pages sales atteignant 75 % Seule opération (innodb_max_dirty_pages_pct,
- innodb_io_capacity)
-
Actualiser les données des pages sales sur le disque- Fusionner les données du tampon d'écriture
- Actualiser le tampon du journal
- Supprimer les pages d'annulation inutiles
-
Fichier de données InnoDBStructure de stockage de fichiers InnoDB
-
InnoDB文件存储格式
-
File文件格式(File-Format)
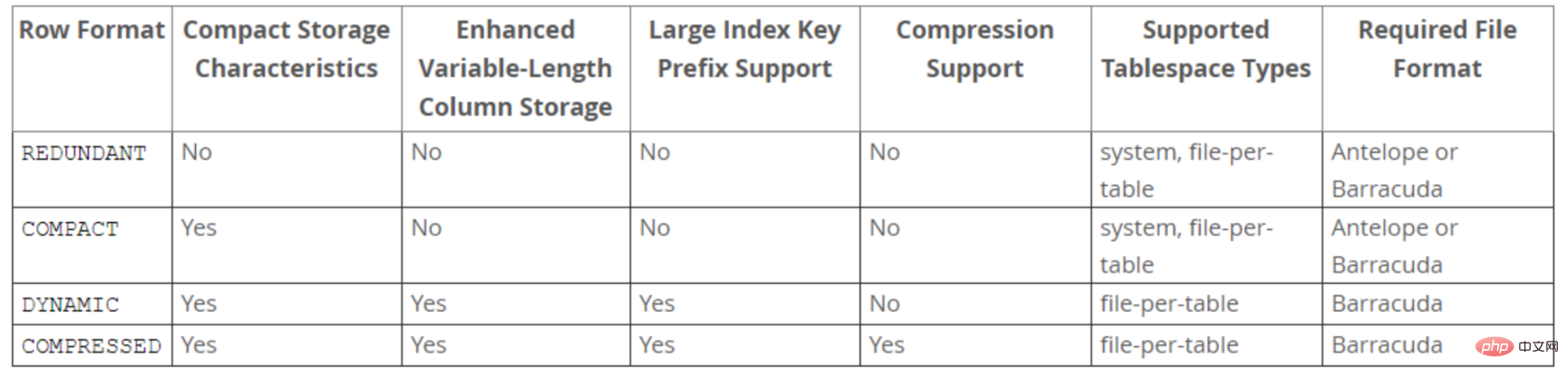
- 在早期的InnoDB版本中,文件格式只有一种,随着InnoDB引擎的发展,出现了新文件格式,用于支持新的功能。目前InnoDB只支持两种文件格式:Antelope 和 Barracuda。
- Antelope: 先前未命名的,最原始的InnoDB文件格式,它支持两种行格式:COMPACT和REDUNDANT,MySQL 5.6及其以前版本默认格式为Antelope。
- Barracuda: 新的文件格式。它支持InnoDB的所有行格式,包括新的行格式:COMPRESSED和 DYNAMIC。
- 通过innodb_file_format 配置参数可以设置InnoDB文件格式,之前默认值为Antelope,5.7版本开始改为Barracuda。
Row行格式(Row_format)
-
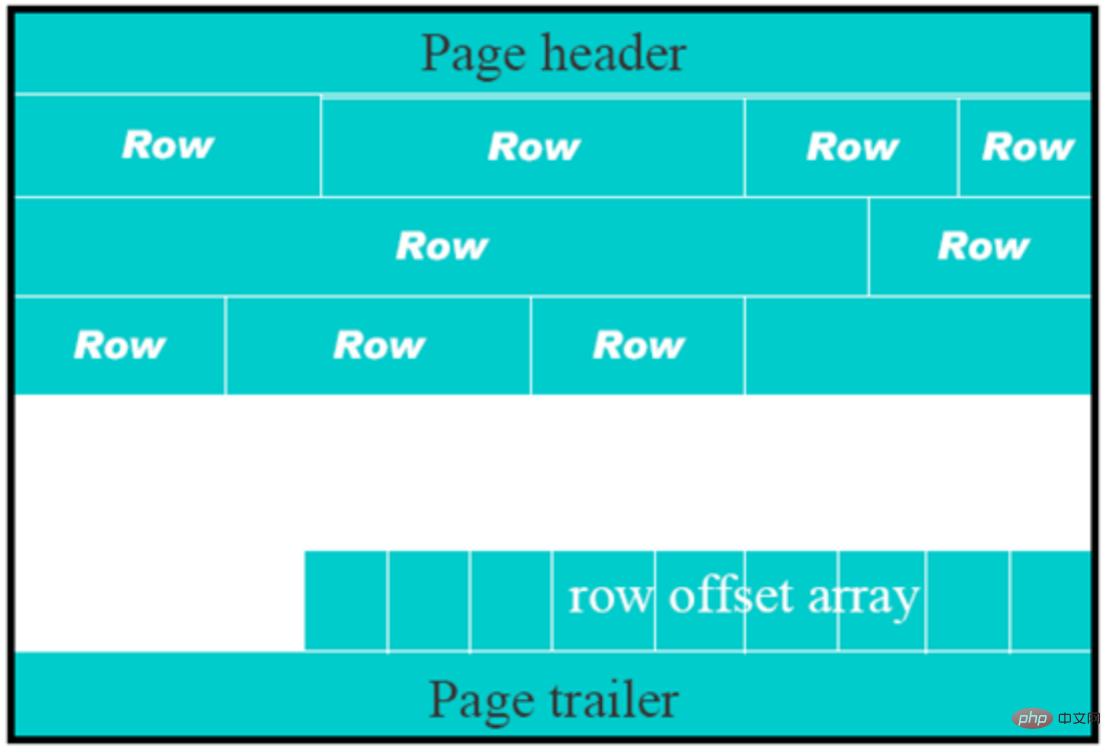
表的行格式决定了它的行是如何物理存储的,这反过来又会影响查询和DML操作的性能。如果在单个page页中容纳更多行,查询和索引查找可以更快地工作,缓冲池中所需的内存更少,写入更新时所需的I/O更少。
InnoDB存储引擎支持四种行格式:REDUNDANT、COMPACT、DYNAMIC和COMPRESSED。
DYNAMIC和COMPRESSED新格式引入的功能有:数据压缩、增强型长列数据的页外存储和大索引前缀。
每个表的数据分成若干页来存储,每个页中采用B树结构存储;
-
如果某些字段信息过长,无法存储在B树节点中,这时候会被单独分配空间,此时被称为溢出页,该字段被称为页外列。
- REDUNDANT 行格式
- 使用REDUNDANT行格式,表会将变长列值的前768字节存储在B树节点的索引记录中,其余
的存储在溢出页上。对于大于等于786字节的固定长度字段InnoDB会转换为变长字段,以便
能够在页外存储。
- COMPACT 行格式
- 与REDUNDANT行格式相比,COMPACT行格式减少了约20%的行存储空间,但代价是增加了
某些操作的CPU使用量。如果系统负载是受缓存命中率和磁盘速度限制,那么COMPACT格式
可能更快。如果系统负载受到CPU速度的限制,那么COMPACT格式可能会慢一些。
- DYNAMIC 行格式
- 使用DYNAMIC行格式,InnoDB会将表中长可变长度的列值完全存储在页外,而索引记录只包含指向溢出页的20字节指针。大于或等于768字节的固定长度字段编码为可变长度字段。DYNAMIC行格式支持大索引前缀,最多可以为3072字节,可通过innodb_large_prefix参数控制。
- COMPRESSED 行格式
- COMPRESSED行格式提供与DYNAMIC行格式相同的存储特性和功能,但增加了对表和索引
数据压缩的支持。
-
在创建表和索引时,文件格式都被用于每个InnoDB表数据文件(其名称与*.ibd匹配)。修改文件格式的方法是重新创建表及其索引,最简单方法是对要修改的每个表使用以下命令:
ALTER TABLE 表名 ROW_FORMAT=格式类型;
Copier après la connexion
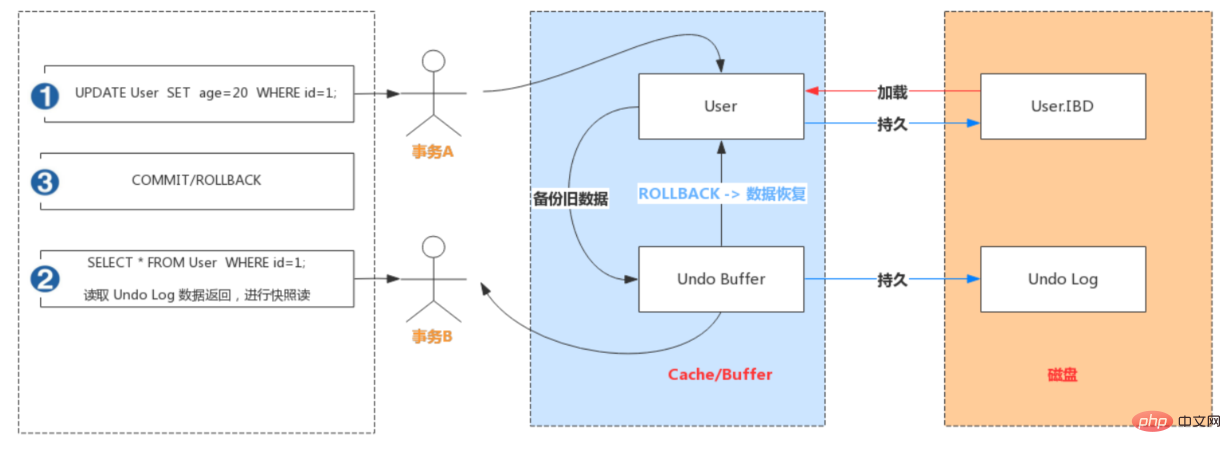
Undo Log
Undo Log介绍
Undo:意为撤销或取消,以撤销操作为目的,返回指定某个状态的操作。
Undo Log:数据库事务开始之前,会将要修改的记录存放到 Undo 日志里,当事务回滚时或者数据库崩溃时,可以利用 Undo 日志,撤销未提交事务对数据库产生的影响。
Undo Log产生和销毁:Undo Log在事务开始前产生;事务在提交时,并不会立刻删除undo log,innodb会将该事务对应的undo log放入到删除列表中,后面会通过后台线程purge thread进行回收处理。Undo Log属于逻辑日志,记录一个变化过程。例如执行一个delete,undolog会记录一个insert;执行一个update,undolog会记录一个相反的update。
Undo Log存储:undo log采用段的方式管理和记录。在innodb数据文件中包含一种rollback segment回滚段,内部包含1024个undo log segment。可以通过下面一组参数来控制Undo log存储。
#相关参数命令
show variables like '%innodb_undo%';
Copier après la connexion
Undo Log作用
- 实现事务的原子性
- Undo Log 是为了实现事务的原子性而出现的产物。事务处理过程中,如果出现了错误或者用户执行了 ROLLBACK 语句,MySQL 可以利用 Undo Log 中的备份将数据恢复到事务开始之前的状态。
-
实现多版本并发控制(MVCC)
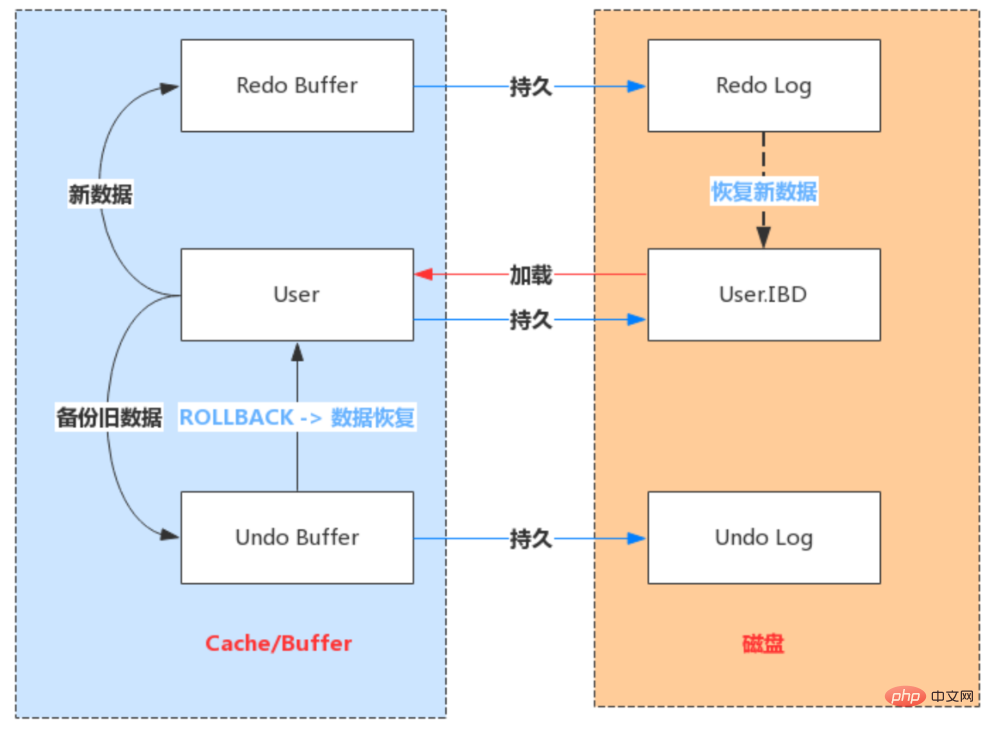
Redo Log 日志
-
Redo Log 介绍
- Redo:顾名思义就是重做。以恢复操作为目的,在数据库发生意外时重现操作。
- Redo Log:指事务中修改的任何数据,将最新的数据备份存储的位置(Redo Log),被称为重做日志。
- Redo Log 的生成和释放:随着事务操作的执行,就会生成Redo Log,在事务提交时会将产生Redo Log写入Log Buffer,并不是随着事务的提交就立刻写入磁盘文件。等事务操作的脏页写入到磁盘之后,Redo Log 的使命也就完成了,Redo Log占用的空间就可以重用(被覆盖写入)。
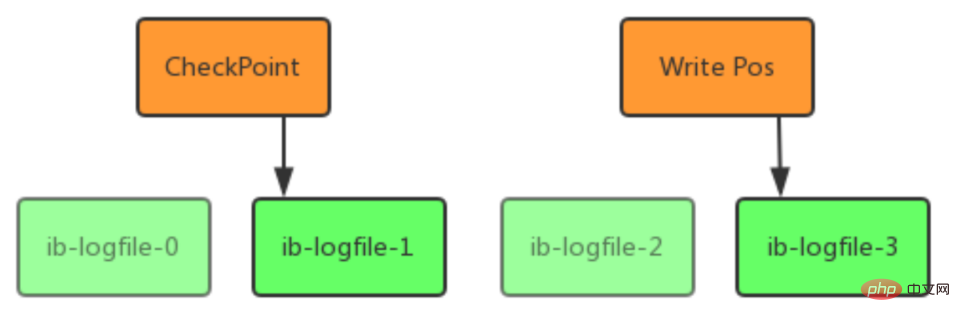
Redo Log工作原理
- Redo Log 是为了实现事务的持久性而出现的产物。防止在发生故障的时间点,尚有脏页未写入表
的 IBD 文件中,在重启 MySQL 服务的时候,根据 Redo Log 进行重做,从而达到事务的未入磁盘
数据进行持久化这一特性。
- write pos 是当前记录的位置,一边写一边后移,写到最后一个文件末尾后就回到 0 号文件开头;
- checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件;
- write pos 和 checkpoint 之间还空着的部分,可以用来记录新的操作。如果 write pos 追上checkpoint,表示写满,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint推进一下。
-
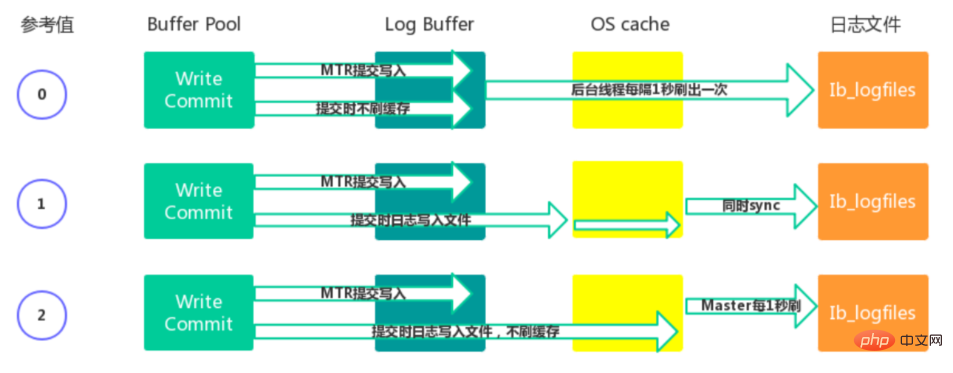
Redo Log相关配置参数
- 0:每秒提交 Redo buffer ->OS cache -> flush cache to disk,可能丢失一秒内的事务数据。由后台Master线程每隔 1秒执行一次操作。
- 1(默认值):每次事务提交执行 Redo Buffer -> OS cache -> flush cache to disk,最安全,性能最差的方式。
- 2:每次事务提交执行 Redo Buffer -> OS cache,然后由后台Master线程再每隔1秒执行OS cache -> flush cache to disk 的操作。
- 一般建议选择取值2,因为 MySQL 挂了数据没有损失,整个服务器挂了才会损失1秒的事务提交数
据。
Binlog日志
-
Binlog 记录模式
- Redo Log 是属于InnoDB引擎所特有的日志,而MySQL Server也有自己的日志,即 Binary log(二进制日志),简称Binlog。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
- 主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
- 数据恢复:通过mysqlbinlog工具来恢复数据。
- Binlog文件名默认为“主机名_binlog-序列号”格式,例如oak_binlog-000001,也可以在配置文件中指定名称。文件记录模式有STATEMENT、ROW和MIXED三种,具体含义如下。
- ROW(row-based replication, RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
- 优点:能清楚记录每一个行数据的修改细节,能完全实现主从数据同步和数据的恢复。
- 缺点:批量操作,会产生大量的日志,尤其是alter table会让日志暴涨。
- STATMENT(statement-based replication, SBR):每一条被修改数据的SQL都会记录到master的Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制。
- 优点:日志量小,减少磁盘IO,提升存储和恢复速度
- 缺点:在某些情况下会导致主从数据不一致,比如last_insert_id()、now()等函数。
- MIXED(mixed-based replication, MBR):以上两种模式的混合使用,一般会使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择写入模式。
-
Binlog 文件结构
-
Binlog写入机制
- 根据记录模式和操作触发event事件生成log event(事件触发执行机制)
- 将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区Log Event保存在一个binlog_cache_mngr数据结构中,在该结构中有两个缓冲区,一个是stmt_cache,用于存放不支持事务的信息;另一个是trx_cache,用于存放支持事务的信息。
- 事务在提交阶段会将产生的log event写入到外部binlog文件中。
- 不同事务以串行方式将log event写入binlog文件中,所以一个事务包含的log event信息在binlog文件中是连续的,中间不会插入其他事务的log event。
-
Binlog文件操作
- 根据记录模式和操作触发event事件生成log event(事件触发执行机制)
- 将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区
- Log Event保存在一个binlog_cache_mngr数据结构中,在该结构中有两个缓冲区,一个是stmt_cache,用于存放不支持事务的信息;另一个是trx_cache,用于存放支持事务的信息。
- 事务在提交阶段会将产生的log event写入到外部binlog文件中。
- 不同事务以串行方式将log event写入binlog文件中,所以一个事务包含的log event信息在
binlog文件中是连续的,中间不会插入其他事务的log event。
-
Binlog文件操作
-
Binlog状态查看
show variables like 'log_bin';
Copier après la connexion
-
开启Binlog功能
-
使用show binlog events命令
show binary logs; //等价于show master logs;
show master status;
show binlog events;
show binlog events in 'mysqlbinlog.000001';
Copier après la connexion
-
使用 mysqlbinlog 命令
mysqlbinlog "文件名"
mysqlbinlog "文件名" > "test.sql"
Copier après la connexion
-
使用 binlog 恢复数据
-
删除Binlog文件
-
Redo Log和 Binlog区别
- Redo Log是属于InnoDB引擎功能,Binlog是属于MySQL Server自带功能,并且是以二进制文件记录。
- Redo Log属于物理日志,记录该数据页更新状态内容,Binlog是逻辑日志,记录更新过程。
- Redo Log日志是循环写,日志空间大小是固定,Binlog是追加写入,写完一个写下一个,不会覆盖使用。
- Redo Log作为服务器异常宕机后事务数据自动恢复使用,Binlog可以作为主从复制和数据恢复使用。Binlog没有自动crash-safe能力。
推荐学习:mysql视频教程





 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié







![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



