

Résumer l'utilisation avancée des fonctions Python

Cet article vous apporte des connaissances pertinentes sur python Il présente principalement comment utiliser les fonctions avancées, y compris la dénomination et la portée des fonctions, l'imbrication des fonctions et la chaîne de portée, et le nom de la fonction, j'espère. cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Python
1. Espace de noms et portée de la fonction
1. Espace de noms de la fonction
Qu'est-ce qu'un espace de noms ?
S'il y a une chaîne de code, observez sa sortie :
def f(): a = 1 return a print(a) 输出结果: Traceback (most recent call last): File "E:/python代码/11/文件一.py", line 4, in <module> print(a) NameError: name 'a' is not definedCopier après la connexionUne erreur est signalée ! L'erreur est "le nom 'a' n'est pas défini". La variable a n'est pas définie. . . Pourquoi? J'ai clairement défini a=1 !
Ensuite, nous devons comprendre ce que fait le code Python lorsqu'il rencontre une fonction lors de son exécution :
Tout d'abord, après avoir démarré l'exécution à partir de l'interpréteur Python, un espace est ouvert dans la mémoire. Chaque fois qu'une variable est rencontrée, enregistrez simplement la. correspondance entre les noms et les valeurs des variables. Mais lorsqu'il rencontre une définition de fonction, l'interpréteur ne lit que symboliquement le nom de la fonction dans la mémoire, indiquant qu'il connaît l'existence de cette fonction. Quant aux variables et à la logique à l'intérieur de la fonction, l'interprète ne s'en soucie pas du tout. Lorsque l'appel de fonction est exécuté, l'interpréteur python allouera une autre mémoire pour stocker le contenu de la fonction. À ce moment, il fera attention aux variables de la fonction, et les variables de la fonction seront stockées dans la nouvelle ouverte. mémoire. Les variables de la fonction ne peuvent être utilisées qu'à l'intérieur de la fonction, et à mesure que la fonction termine son exécution, tout le contenu de cette mémoire sera effacé.
Nous avons donné un nom à cet espace qui "stocke la relation entre les noms et les valeurs" - cela s'appelle espace de noms
L'espace que le code a créé au début pour stocker "la relation entre les noms de variables et les valeurs" est appelé global espace de noms , l'espace temporaire ouvert lors du fonctionnement interne de la fonction est appelé espace de noms local
Trois catégories d'espaces de noms de fonction
Les espaces de noms de fonction sont divisés en trois catégories au total
1、内置命名空间 —— python解释器 # 就是python解释器一启动就可以使用的名字存储在内置命名空间中 # 内置的名字在启动解释器的时候被加载进内存里 2、全局命名空间 —— 我们写的代码但不是函数中的代码 # 是在程序从上到下被执行的过程中依次加载进内存的 # 放置了我们设置的所有变量名和函数名 3、局部命名空间 —— 函数 # 就是函数内部定义的名字 # 当调用函数的时候 才会产生这个名称空间 随着函数执行的结束 这个命名空间就又消失了 #在局部:可以使用全局、内置命名空间中的名字 #在全局:可以使用内置命名空间中的名字,但是不能用局部中使用 #在内置:不能使用局部和全局的名字的Copier après la connexionEspace de dénomination intégré : l'espace de noms intégré stocke pour nous les noms (fonctions) fournis par l'interpréteur Python. Nous n'avons pas besoin de les définir. Ce sont tous des noms familiers que nous pouvons utiliser directement en ouvrant l'interpréteur, comme. : input, print, str, set...
L'ordre de chargement et de valeur entre les trois espaces de noms
2. La portée d'une fonctionOrdre de chargement : espace de noms intégré (chargé avant l'exécution du programme> Espace de noms global ( pendant l'exécution du programme : chargé de haut en bas)> Espace de noms local (lorsque le programme est en cours d'exécution : chargé uniquement lorsqu'il est appelé)
Lors d'un appel local : Espace de noms global > globalement : Espace de noms global > Espace de noms intégré
Exemple :
a = 10 def f(): a = 1 print(a) f() print(a) 输出结果: 1 10Copier après la connexion
Selon la portée effective, elle peut être divisée en portée globale et portée locale.
Portée globale : y compris
espace de noms intégré et portée globale, peut être référencé n'importe où dans l'ensemble du fichier, est valable globalement Portée locale : espace de noms local, ne peut être efficace que dans la portée locale
.
globals() :
- La fonction renverra toutes les variables globales
à l'emplacement actuel dans le type de dictionnaire
Résultat de sortie :def func(): a = 1 print(locals()) print(globals()) print('========================分割线==========================') func() print(locals()) print(globals())Copier après la connexion
.
global关键字
1、global是Python中的全局变量关键字。
2、变量分为局部变量与全局变量,局部变量又可称之为内部变量。
3、由某对象或某个函数所创建的变量通常都是局部变量,只能被内部引用,而无法被其它对象或函数引用。
4、全局变量既可以是某对象函数创建,也可以是在本程序任何地方创建。全局变量是可以被本程序所有对象或函数引用。
5、global关键字的作用是可以使得一个局部变量为全局变量例子:
在my函数中,在 x 前面加 global,my函数将 x 赋为8,此时全局变量中的 x 值改变。需要注意的是 global 需要在函数内部声明,若在函数外声明,则函数依然无法操作 x 。
x = 4 def my(): global x x = 8 print("x = ", x) print("x = ", x) my() print("x = ", x) 输出结果是: x = 4 x = 8 x = 8Copier après la connexion
二、函数的嵌套和作用域链
函数的嵌套调用
def max2(x,y): m = x if x>y else y return m def max4(a,b,c,d): res1 = max2(a,b) res2 = max2(res1,c) res3 = max2(res2,d) return res3 ret = max4(1,2,4,3) print(ret) 输出结果: 4
函数的嵌套定义
def f1():
print("in f1")
def f2():
print("in f2")
f2()
f1()
输出结果:
in f1
in f2
def f1():
def f2():
def f3():
print("in f3")
print("in f2")
f3()
print("in f1")
f2()
f1()
输出结果:
in f1
in f2
in f3函数的作用域链
a = 1
def outer():
a = 5
def inner():
a = 2
def inner2():
nonlocal a
a += 1
print('inner2',a)
inner2()
print('##a##:',a)
inner()
print('**a**:',a)
outer()
print('全局:',a)
输出结果:
inner2 3
##a##: 3
**a**: 5
全局: 1nonlocal关键字
#nonlocal 只能用于局部变量,找上层中离当前函数最近一层的局部变量且外部必须有这个变量 #声明了nonlocal的内部函数的变量修改会影响到离当前函数最近一层的局部变量 #对全局无效,在内部函数声明nonlocal变量之前不能再出现同名变量 #对局部也只是对最近一层有影响Copier après la connexiondef f1(): a = 1 def f2(): nonlocal a a = 2 f2() print('a in f1 : ',a) f1() 输出结果: a in f1 : 2Copier après la connexion
global关键字
# 对于不可变数据类型 在局部可是查看全局作用域中的变量 # 但是不能直接修改 # 如果想要修改,需要在程序的一开始添加global声明 # 如果在一个局部(函数)内声明了一个global变量,那么这个变量在局部的所有操作将对全局的变量有效Copier après la connexion
三、函数名的本质
函数名就是内存地址
函数名可以被赋值
函数名可以作为容器类型的元素
函数名可以作为函数的返回值
函数名可以作为函数的参数
def func(): print(123) func() print(func) # 函数名就是内存地址 # 函数名可以被赋值 func2 = func func2() #函数名可以作为容器类型的元素 l = [func,func2] for i in l: i() def func(): print(123) def wahaha(f): f() return f #函数名可以作为函数的返回值 qqxing = wahaha(func) #函数名可以作为函数的参数 qqxing() 输出结果: 123 <function func at 0x000001ADF9946280> 123 123 123 123 123Copier après la connexion
思考
如果我自己定义了一个input函数(作用:调用该函数就打印'在下周周ovo'),会不会与内置的input函数有冲突呢?
def input(a): print('在下周周ovo')Copier après la connexion那么接下来的代码怎么运行呢?
def input(a): print('在下周周ovo') def func(): input('请输入') print(input) func()Copier après la connexion答案:
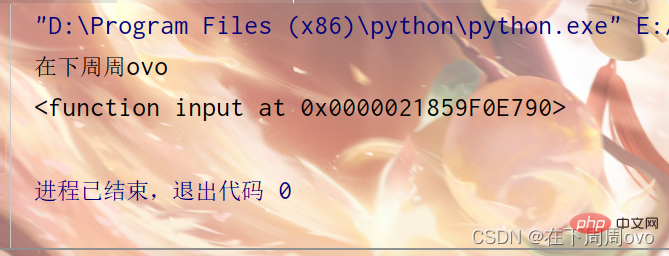
四、闭包
闭包函数的概念
内部函数包含对外部作用域而非全剧作用域名字的引用,该内部函数称为闭包函数
#函数内部定义的函数称为内部函数由于有了作用域的关系,我们就不能拿到函数内部的变量和函数了。如果我们就是想拿怎么办呢?返回呀!
如果函数内的变量我们要想在函数外部用,可以直接返回这个变量,那么如果我们想在函数外部调用函数内部的函数呢?那就直接将函数名字作为返回值就好
def outer(): a = 1 def inner(): print(a) #内部函数调用了外部变量a return inner inn = outer() inn() 输出结果: 1Copier après la connexion
闭包函数的判断方法
判断闭包函数的方法__closure__
当运行后,如果有cell的话,就表示是闭包函数。如果没有就不是。
#输出的__closure__有cell元素 :是闭包函数 def func(): name = 'eva' def inner(): print(name) print(inner.__closure__) return inner f = func() f() #输出的__closure__为None :不是闭包函数 name = 'egon' def func2(): def inner(): print(name) print(inner.__closure__) return inner f2 = func2() f2() 输出结果: (<cell at 0x000001E935CB0FA0: str object at 0x000001E935CC2CB0>,) eva None egonCopier après la connexion
闭包嵌套
顾名思义是两个或以上的闭包函数嵌套在一起
def wrapper(): money = 10 def func(): name = 'zhou' def inner(): print(name,money) #引用了func()函数中name变量引用了wrapper()函数中money变量 return inner return func f = wrapper() i = f() i() 输出结果: zhuo 10Copier après la connexion
小结
#func(一个函数名) --->>对应函数的内存地址 #函数名()---函数调用 #函数的内存地址----()函数的调用 # 作用域两种 # 全局作用域 —— 作用在全局 —— 内置和全局名字空间中的名字都属于全局作用域 ——globals() # 局部作用域 —— 作用在局部 —— 函数(局部名字空间中的名字属于局部作用域) ——#locals()globals() : 永远打印全局的名字 #locals() : 输出什么 根据locals所在位置 #在代码中要尽量少定义全局变量,多使用返回值和接收返回值 #函数的嵌套: 嵌套调用 嵌套定义:定义在内部的函数无法直接在全局被调用 #函数名的本质: 就是一个变量,保存了函数所在的内存地址 #闭包: 内部函数包含对外部作用域而非全剧作用域名字的引用,该内部函数称为闭包函数Copier après la connexion
推荐学习:python视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Vous pouvez apprendre les concepts de programmation de base et les compétences de Python dans les 2 heures. 1. Apprenez les variables et les types de données, 2. Flux de contrôle maître (instructions et boucles conditionnelles), 3. Comprenez la définition et l'utilisation des fonctions, 4. Démarrez rapidement avec la programmation Python via des exemples simples et des extraits de code.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python est largement utilisé dans les domaines du développement Web, de la science des données, de l'apprentissage automatique, de l'automatisation et des scripts. 1) Dans le développement Web, les cadres Django et Flask simplifient le processus de développement. 2) Dans les domaines de la science des données et de l'apprentissage automatique, les bibliothèques Numpy, Pandas, Scikit-Learn et Tensorflow fournissent un fort soutien. 3) En termes d'automatisation et de script, Python convient aux tâches telles que les tests automatisés et la gestion du système.
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
 Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Les étapes pour démarrer un serveur Redis incluent: Installez Redis en fonction du système d'exploitation. Démarrez le service Redis via Redis-Server (Linux / MacOS) ou Redis-Server.exe (Windows). Utilisez la commande redis-Cli Ping (Linux / MacOS) ou redis-Cli.exe Ping (Windows) pour vérifier l'état du service. Utilisez un client redis, tel que redis-cli, python ou node.js pour accéder au serveur.
 MySQL peut-il se connecter au serveur SQL
Apr 08, 2025 pm 05:54 PM
MySQL peut-il se connecter au serveur SQL
Apr 08, 2025 pm 05:54 PM
Non, MySQL ne peut pas se connecter directement à SQL Server. Mais vous pouvez utiliser les méthodes suivantes pour implémenter l'interaction des données: utilisez Middleware: Exporter les données de MySQL au format intermédiaire, puis importez-les sur SQL Server via Middleware. Utilisation de Database Linker: Business Tools fournit une interface plus conviviale et des fonctionnalités avancées, essentiellement encore implémentées via Middleware.
