

Parlons du verrouillage global MySQL

Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement des problèmes liés aux verrous globaux. Les verrous globaux verrouillent l'intégralité de la base de données. Après avoir ajouté un verrou en lecture à la base de données, aucune autre requête ne peut ajouter un verrou en écriture à la base de données. Examinons-le ensemble, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo MySQL
L'intention initiale de la conception d'une base de données est de traiter les problèmes de concurrence. En tant que ressource partagée par plusieurs utilisateurs, lorsqu'un accès simultané se produit, la base de données doit contrôler raisonnablement les règles d'accès. de la ressource. Le verrou est une structure de données importante utilisée pour mettre en œuvre cette règle d'accès.
Publions d'abord un schéma de la classification générale des verrous
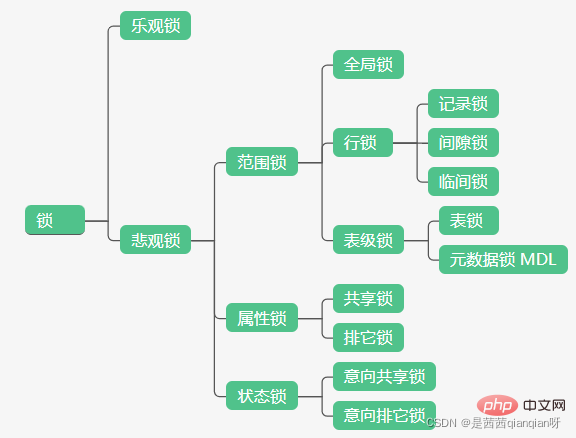
Selon la portée du verrouillage, les verrous dans MySQL peuvent être grossièrement divisés en verrous globaux, verrous de table et verrous de ligne. Nous apprendrons principalement ces types de verrous en premier. Dans cet article, nous découvrirons les verrous globaux.
Verrouillage global
Le verrouillage global consiste à verrouiller l'intégralité de la base de données. Après avoir ajouté un verrou en lecture à la base de données, aucune autre requête ne peut ajouter de verrous en écriture à la base de données. Lorsque nous ajoutons un verrou en écriture à la base de données, aucune autre requête ultérieure ne peut ajouter de verrous en lecture ou en écriture à la base de données.
FTWRL
MySQL fournit une méthode pour ajouter un verrou de lecture global, Flush tables avec verrou de lecture (FTWRL). Lorsque nous devons mettre la bibliothèque entière en lecture seule, nous pouvons utiliser cette commande. Ensuite, les instructions suivantes des autres threads seront bloquées : les instructions de mise à jour des données (ajouter, supprimer, modifier), les instructions de définition des données (y compris la création de tables). , modification des structures de table, etc.) et update Une instruction de validation pour une transaction de classe.
Scénarios d'utilisation des verrous globaux
Scénarios d'utilisation des verrous globaux : Effectuez une sauvegarde logique de l'ensemble de la base de données. La sauvegarde logique consiste à sélectionner chaque table de la base de données entière et à l'enregistrer sous forme de texte. C'est-à-dire que le verrouillage global n'est utilisé que lors de la sauvegarde de données maître-esclave ou de l'importation et de l'exportation de données.
Alors pourquoi avez-vous besoin d'un verrouillage global ?
Parce que lorsque nous effectuons une sauvegarde de données ou que nous importons et exportons des données, si des données peuvent être ajoutées, supprimées et modifiées en même temps pendant cette période, une incohérence des données se produira.
Dans le passé, il existait un moyen d'utiliser le FTWRL mentionné ci-dessus pour garantir qu'aucun autre thread ne mettrait à jour la base de données pendant la sauvegarde. Remarque : pendant le processus de sauvegarde, l'intégralité de la bibliothèque est entièrement en lecture seule.
Étant donné que le verrouillage global est orienté vers cette base de données, l'ajout d'un verrouillage global semble très dangereux :
- Si nous sauvegardons sur la base de données principale, les mises à jour ne peuvent pas être effectuées pendant la période de sauvegarde, ce qui signifie que pratiquement toutes les activités sont suspendues.
- Si nous sauvegardons sur la base de données esclave, le binlog synchronisé à partir de la base de données maître pendant la période de sauvegarde ne peut pas être exécuté, ce qui entraînera un retard maître-esclave et une incohérence des données.
Comment éviter le verrouillage
Étant donné que l'ajout d'un verrouillage global a un impact si important, pouvons-nous éviter le verrouillage ?
Grâce à l'introduction ci-dessus, nous savons que le verrouillage vise à résoudre le problème de l'incohérence des données. Ainsi, tant que nous pouvons résoudre le problème de l'incohérence des données, nous n'avons pas besoin d'ajouter un verrou global. Il existe une telle idée : si nous enregistrons un journal des opérations lorsque nous démarrons la sauvegarde des données, l'ajout, la suppression, la modification et l'interrogation de la base de données seront autorisés sans verrouillage pendant le processus de sauvegarde, et pendant le processus de sauvegarde, les enregistrements d'opérations d'ajouts , les suppressions, les modifications et les requêtes seront enregistrées dans un seul fichier journal, une fois notre sauvegarde terminée, nous exécuterons toutes les opérations dans le fichier journal pendant cette période. Cela garantit la cohérence des données avant et après la sauvegarde.
En résumé, sans verrouillage, les données de sauvegarde et les données principales ne sont pas à un instant logique, et cette vue est logiquement incohérente. Si nous nous assurons que les points de temps logiques sont cohérents, c'est-à-dire que les vues logiques sont cohérentes, nous pouvons garantir la cohérence des données. À partir de là, nous pensons au niveau d'isolement des transactions que nous avons appris auparavant. L'ouverture d'une transaction sous le niveau d'isolement répétable est une bonne chose. vue cohérente.
Il existe un mécanisme dans InnoDB, le moteur par défaut de MySQL, pour assurer la cohérence des données. Le moteur InnoDB dispose d'une fonction de version d'instantané de données. Cette fonction est appelée MVCC car MVCC conserve des instantanés des versions historiques. Chaque instantané correspond à un numéro de version de transaction. Lorsque nous sauvegardons les données, nous demanderons un numéro de version de transaction lors de la lecture. Pour récupérer des données, il vous suffit de lire les données avec un numéro de version de transaction plus petit que le vôtre.
–verrouillage de commande à transaction unique
L'outil de sauvegarde logique officiel est mysqldump. Lorsque mysqldump utilise le paramètre –single-transaction, une transaction sera démarrée avant l'importation des données pour garantir l'obtention d'une vue cohérente. Grâce à la prise en charge de MVCC, les données peuvent être mises à jour normalement pendant ce processus.
Le rôle du paramètre --single-transaction est de définir le niveau d'isolement de la transaction sur lecture répétable, c'est-à-dire REPEATABLE READ. Cela garantit que toutes les mêmes requêtes dans une transaction lisent les mêmes données, ce qui garantit à peu près cela pendant. pendant la période de vidage, si d'autres threads du moteur InnoDB modifient les données de la table et les soumettent, cela n'aura aucun impact sur les données du thread de vidage.
Et définissez AVEC INSTANTANÉ COHÉRENT au niveau instantané. Imaginez que s'il ne s'agit que d'une lecture répétable, alors avant que les données ne soient vidées au début de la transaction, d'autres threads modifient et soumettent les données, alors le résultat de la première requête à ce moment est le résultat soumis par d'autres threads, et AVEC CONSISTENT SNAPSHOT peut garantir que lorsqu'une transaction est démarrée, le résultat de la première requête est les données A au début de la transaction. Même si d'autres threads modifient ses données en B à ce moment, le résultat de la requête est toujours A.
La méthode de transaction unique s'applique uniquement aux bibliothèques qui utilisent des moteurs de transaction pour toutes les tables. Dans le processus mysqldump, l'ajout de --single-transaction peut garantir que les données InnoDB sont complètement cohérentes. Pour les moteurs comme MyISAM qui ne prennent pas en charge les transactions, s'il y a des mises à jour pendant le processus de sauvegarde, seules les données les plus récentes peuvent toujours être obtenues. Cela détruit la cohérence de la sauvegarde. À l’heure actuelle, un verrou global est toujours nécessaire, nous devons donc toujours utiliser la commande FTWRL.
Paramètre en lecture seule
Nous pouvons également nous poser cette question, puisque toute la bibliothèque doit être en lecture seule, pourquoi n'utilisons-nous pas set global readonly = true ?
Il est vrai que la méthode readonly peut également mettre la bibliothèque entière en lecture seule, mais il est quand même recommandé d'utiliser la méthode FTWRL, principalement pour deux raisons :
- Dans certains systèmes, la valeur en lecture seule sera utilisé pour d'autres logiques, telles que Déterminer si une base de données est la base de données principale ou de secours. Par conséquent, la modification des variables globales a un impact plus important.
- Il existe des différences dans les mécanismes de gestion des exceptions. Si le client se déconnecte anormalement après l'exécution de la commande FTWRL, MySQL libérera automatiquement le verrou global et la bibliothèque entière reviendra à un état dans lequel elle pourra être mise à jour normalement.
Après avoir défini l'ensemble de la bibliothèque en lecture seule, si une exception se produit sur le client, la base de données restera en lecture seule, ce qui rendra l'ensemble de la bibliothèque dans un état non inscriptible pendant une longue période, avec un risque élevé.
Apprentissage recommandé : Tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
