
 Opération et maintenance
exploitation et maintenance Linux
Quel est le caractère pipe sous Linux
Opération et maintenance
exploitation et maintenance Linux
Quel est le caractère pipe sous Linux
Quel est le caractère pipe sous Linux

Sous Linux, le caractère pipe est "|", qui est principalement utilisé pour connecter deux ou plusieurs commandes ensemble et utiliser la sortie d'une commande comme entrée de la commande suivante ; .. ]", la sortie de la commande à gauche du caractère "|" sera utilisée comme entrée de la commande à droite du caractère "|". Le caractère pipe peut être utilisé en continu. La sortie de la première commande sera utilisée comme entrée de la deuxième commande, et la sortie de la deuxième commande sera utilisée comme entrée de la troisième commande, et ainsi de suite.

L'environnement d'exploitation de ce tutoriel : système linux7.3, ordinateur Dell G3.
Shell a également une fonction, qui consiste à connecter deux ou plusieurs commandes (programmes ou processus) ensemble et à utiliser la sortie d'une commande comme entrée de la commande suivante. Deux ou plusieurs commandes connectées de cette manière Un tuyau est formé. .
Les tuyaux Linux utilisent des barres verticales | pour connecter plusieurs commandes, appelées caractères de tuyau.
command1 | command2 command1 | command2 [ | commandN... ]
Lorsqu'un tube est placé entre deux commandes, la sortie de la commande à gauche du symbole du tube | devient l'entrée de la commande à droite. Tant que la première commande écrit sur la sortie standard et que la deuxième commande lit à partir de l'entrée standard, les deux commandes peuvent former un canal. La plupart des commandes Linux peuvent être utilisées pour former des tubes.
Le caractère pipe peut être utilisé en continu. La sortie de la première commande sera utilisée comme entrée de la deuxième commande, et la sortie de la deuxième commande sera utilisée comme entrée de la troisième commande, et ainsi de suite.

Il convient de noter ici que command1 doit avoir une sortie correcte et que command2 doit être capable de traiter le résultat de sortie de command2 ; et command2 ne peut traiter que le résultat de sortie correct de command1, mais ne peut pas gérer le message d'erreur de commande1.
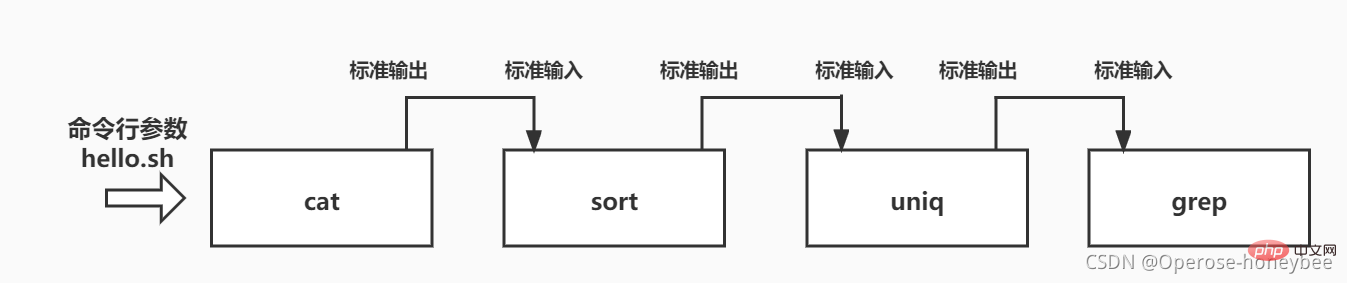
Par exemple : triez le fichier hello.sh et recherchez la ligne contenant "meilleur" après l'avoir trié et dédupliqué. La commande est : cat hello.sh sort | grep 'better'
Afficher le texte.
Trier- Supprimer la duplication
- Filtre
【1】La première étape - Afficher le texte Utilisez d'abord la commande cat pour afficher le texte, et le contenu imprimé à l'écran est la sortie de la commande cat
Utilisez d'abord la commande cat pour afficher le texte, et le contenu imprimé à l'écran est la sortie de la commande cat
[root@linuxforliuhj test]# cat hello.sh hello this is linux be better be better i am lhj hello this is linux i am lhj i am lhj be better i am lhj have a nice day have a nice day hello this is linux hello this is linux have a nice day zzzzzzzzzzzzzz dddddddd gggggggggggggggggggg [root@linuxforliuhj test]#
【2】Le deuxième processus - le tri
Les résultats générés par la commande cat précédente sont envoyés à la commande de tri via le pipeline, de sorte que la commande de tri trie le texte généré par la commande cat précédente
[root@linuxforliuhj test]# cat hello.sh | sort be better be better be better dddddddd gggggggggggggggggggg have a nice day have a nice day have a nice day hello this is linux hello this is linux hello this is linux hello this is linux i am lhj i am lhj i am lhj i am lhj zzzzzzzzzzzzzz [root@linuxforliuhj test]#
【3】 Le troisième processus Processus - Déduplication
Comme mentionné dans l'article précédent présentant uniq, le tri peut être efficacement dédupliqué lorsqu'il est utilisé en combinaison avec uniq, de sorte que le texte généré par le tri est envoyé à uniq pour être traité via le pipeline, de sorte qu'uniq traite le tri. text. , peut supprimer efficacement les doublons
[root@linuxforliuhj test]# cat hello.sh | sort | uniq be better dddddddd gggggggggggggggggggg have a nice day hello this is linux i am lhj zzzzzzzzzzzzzz [root@linuxforliuhj test]#
【4】Le quatrième processus - le filtrage
La dernière étape du filtrage consiste également à filtrer la sortie de texte après le traitement de la commande précédente, la commande uniq
[root@linuxforliuhj test]# cat hello.sh | sort | uniq | grep 'better' be better [root@linuxforliuhj test]#
Voici le point important !
Voici le point important !
Les commandes cat, sort, uniq, grep et autres ci-dessus prennent toutes en charge le caractère pipe car ces commandes peuvent lire le texte pour être traité à partir de l'entrée standard (c'est-à-dire la lecture des paramètres à partir de l'entrée standard) ; pour certaines commandes, telles que rm, kill et d'autres commandes, elles ne prennent pas en charge la lecture des paramètres à partir de l'entrée standard, mais prennent uniquement en charge la lecture des paramètres à partir de la ligne de commande. (c'est-à-dire que delete doit être spécifié après le fichier ou le répertoire de commande rm, le numéro de processus à tuer doit être spécifié après la commande kill, etc.)
Alors, quel type de commandes prennent en charge les tubes et quel type de commandes ne supporte pas les tuyaux ?
Généralement, les commandes qui traitent du texte, telles que sort, uniq, grep, awk, sed, etc., prennent toutes en charge les tubes ; les commandes qui ne traitent pas de texte, telles que rm et ls, ne prennent pas en charge les tubes
Qu'est-ce qui est prioritaire entre les paramètres d'entrée standard et les paramètres de ligne de commande ?[root@linuxforliuhj test]# cat hello.sh | sort be better be better be better dddddddd gggggggggggggggggggg have a nice day have a nice day have a nice day hello this is linux hello this is linux hello this is linux hello this is linux i am lhj i am lhj i am lhj i am lhj zzzzzzzzzzzzzz [root@linuxforliuhj test]#Copier après la connexionCopier après la connexion. n'y a pas de paramètres après le tri, la sortie de la commande précédente lancée par le caractère barre verticale est traitée (c'est-à-dire que la sortie standard de la commande précédente est utilisée comme entrée standard de cette commande)
Lorsque le fichier à être delete n'est pas spécifié après rm, une erreur sera signalée. Les paramètres sont perdus, donc les commandes telles que rm ne prennent pas en charge la lecture des paramètres à partir de l'entrée standard. Elles prennent uniquement en charge la spécification de paramètres sur la ligne de commande, c'est-à-dire la spécification des fichiers à supprimer.[root@linuxforliuhj test]# ls beifen.txt hello.sh mk read.ln read.sh read.txt sub.sh [root@linuxforliuhj test]# ls | grep read.sh read.sh [root@linuxforliuhj test]# ls | grep read.sh | rm rm: missing operand Try 'rm --help' for more information. [root@linuxforliuhj test]#Copier après la connexion
Il y a les deux fichiers suivants[root@linuxforliuhj test]# cat a.txt
aaaa
dddd
cccc
bbbb
[root@linuxforliuhj test]# cat b.txt
1111
3333
4444
2222
[root@linuxforliuhj test]#
Copier après la connexionExécutez la commande : cat a.txt | sort
[root@linuxforliuhj test]# cat a.txt aaaa dddd cccc bbbb [root@linuxforliuhj test]# cat b.txt 1111 3333 4444 2222 [root@linuxforliuhj test]#
[root@linuxforliuhj test]# cat a.txt | sort aaaa bbbb cccc dddd [root@linuxforliuhj test]#
Lorsque le paramètre de ligne de commande de sort est vide, la sortie de la commande précédente sera utilisée comme entrée de cette commande par défaut
Commande d'exécution : cat a.txt | sort b.txt
[root@linuxforliuhj test]# cat a.txt | sort b.txt 1111 2222 3333 4444 [root@linuxforliuhj test]#
Vous pouvez voir que lorsque le paramètre de ligne de commande du tri (ici b.txt) n'est pas vide, le tri ne lira pas les paramètres dans l'entrée standard , et quand Lire les paramètres de la ligne de commande
Exécuter la commande : cat a.txt | sort b.txt -
[root@linuxforliuhj test]# cat a.txt | sort b.txt - 1111 2222 3333 4444 aaaa bbbb cccc dddd [root@linuxforliuhj test]#
" - "Indique l'entrée standard, c'est-à-dire la sortie de la commande cat a.txt, qui est équivalent au fichier b.txt et à l'entrée standard ensemble Le tri équivaut à trier a.txt b.txt
[root@linuxforliuhj test]# sort a.txt b.txt 1111 2222 3333 4444 aaaa bbbb cccc dddd [root@linuxforliuhj test]#
思考:对于rm、kill等命令,我们写脚本时常常会遇到需要查询某个进程的进程号然后杀掉该进程,查找某个文件然后删除它这样的需求,该怎么办呢?那就用xargs吧!
相关推荐:《Linux视频教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 À quoi sert Linux?
Apr 12, 2025 am 12:20 AM
À quoi sert Linux?
Apr 12, 2025 am 12:20 AM
Linux convient aux serveurs, aux environnements de développement et aux systèmes intégrés. 1. En tant que système d'exploitation de serveurs, Linux est stable et efficace, et est souvent utilisé pour déployer des applications à haute monnaie. 2. En tant qu'environnement de développement, Linux fournit des outils de ligne de commande efficaces et des systèmes de gestion des packages pour améliorer l'efficacité du développement. 3. Dans les systèmes intégrés, Linux est léger et personnalisable, adapté aux environnements avec des ressources limitées.
 Comment afficher le nom d'instance d'Oracle
Apr 11, 2025 pm 08:18 PM
Comment afficher le nom d'instance d'Oracle
Apr 11, 2025 pm 08:18 PM
Il existe trois façons d'afficher les noms d'instance dans Oracle: utilisez le "SQLPlus" et "SELECT INSTRESS_NAME FROM V $ INSTERNE;" Commandes sur la ligne de commande. Utilisez "Show instance_name;" Commande dans SQL * Plus. Vérifiez les variables d'environnement (Oracle_sid sur Linux) via le gestionnaire de tâches du système d'exploitation, Oracle Enterprise Manager ou via le système d'exploitation.
 Utilisation de Docker avec Linux: un guide complet
Apr 12, 2025 am 12:07 AM
Utilisation de Docker avec Linux: un guide complet
Apr 12, 2025 am 12:07 AM
L'utilisation de Docker sur Linux peut améliorer l'efficacité du développement et du déploiement. 1. Installez Docker: utilisez des scripts pour installer Docker sur Ubuntu. 2. Vérifiez l'installation: exécutez Sudodockerrunhello-world. 3. Utilisation de base: Créez un conteneur Nginx Dockerrunrun-namemy-nginx-p8080: 80-dnginx. 4. Utilisation avancée: créez une image personnalisée, construisez et exécutez à l'aide de dockerfile. 5. Optimisation et meilleures pratiques: suivez les meilleures pratiques pour écrire des dockerfiles à l'aide de builds en plusieurs étapes et de dockercosive.
 Comment utiliser Oracle après l'installation
Apr 11, 2025 pm 07:51 PM
Comment utiliser Oracle après l'installation
Apr 11, 2025 pm 07:51 PM
Une fois Oracle installé, vous pouvez utiliser les étapes suivantes: créer une instance de base de données. Connectez-vous à la base de données. Créer un utilisateur. Créer une table. Insérer des données. Données de requête. Données d'exportation. Importer des données.
 Que faire si le port Apache80 est occupé
Apr 13, 2025 pm 01:24 PM
Que faire si le port Apache80 est occupé
Apr 13, 2025 pm 01:24 PM
Lorsque le port Apache 80 est occupé, la solution est la suivante: découvrez le processus qui occupe le port et fermez-le. Vérifiez les paramètres du pare-feu pour vous assurer qu'Apache n'est pas bloqué. Si la méthode ci-dessus ne fonctionne pas, veuillez reconfigurer Apache pour utiliser un port différent. Redémarrez le service Apache.
 Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Les étapes pour démarrer Apache sont les suivantes: Installez Apache (Commande: Sudo apt-get install Apache2 ou téléchargez-le à partir du site officiel) Start Apache (Linux: Sudo SystemCTL Démarrer Apache2; Windows: Cliquez avec le bouton droit sur le service "APACHE2.4" et SELECT ") Vérifiez si elle a été lancée (Linux: SUDO SYSTEMCTL STATURE APACHE2; (Facultatif, Linux: Sudo SystemCTL
 Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Cet article décrit comment surveiller efficacement les performances SSL des serveurs Nginx sur les systèmes Debian. Nous utiliserons NginxExporter pour exporter des données d'état NGINX à Prometheus, puis l'afficher visuellement via Grafana. Étape 1: Configuration de Nginx Tout d'abord, nous devons activer le module Stub_Status dans le fichier de configuration NGINX pour obtenir les informations d'état de Nginx. Ajoutez l'extrait suivant dans votre fichier de configuration Nginx (généralement situé dans /etc/nginx/nginx.conf ou son fichier incluant): emplacement / nginx_status {Stub_status
 Comment exécuter SQL à l'aide de la fenêtre de commande dans Oracle
Apr 11, 2025 pm 06:36 PM
Comment exécuter SQL à l'aide de la fenêtre de commande dans Oracle
Apr 11, 2025 pm 06:36 PM
Pour exécuter SQL dans la fenêtre de commande Oracle: ouvrez la fenêtre de commande. Connectez-vous à la base de données: connectez le nom d'utilisateur / le mot de passe. Entrez l'instruction SQL et appuyez sur Entrée pour exécuter. Afficher les résultats. Entrez Exit pour quitter la fenêtre de commande.
