
 développement back-end
Tutoriel Python
Exemple Python explication détaillée de pdfplombier lisant un PDF et écrivant dans Excel
développement back-end
Tutoriel Python
Exemple Python explication détaillée de pdfplombier lisant un PDF et écrivant dans Excel
Exemple Python explication détaillée de pdfplombier lisant un PDF et écrivant dans Excel

Cet article vous apporte des connaissances pertinentes sur python, qui présente principalement les problèmes liés à la lecture de PDF par pdfplumber et à l'écriture dans Excel, y compris l'installation du module pdfplumber, le chargement de PDF et quelques opérations pratiques, etc. , j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Python
1. Comparaison de 13 bibliothèques majeures pour exploiter le PDF en Python
PDF (Portable Document Format) est un format de document portable qui facilite la diffusion de documents sur les systèmes d'exploitation. Les documents PDF suivent un format standard, il existe donc de nombreux outils pouvant fonctionner sur des documents PDF, et Python ne fait pas exception.
Le tableau comparatif du module PDF opérationnel Python est le suivant :
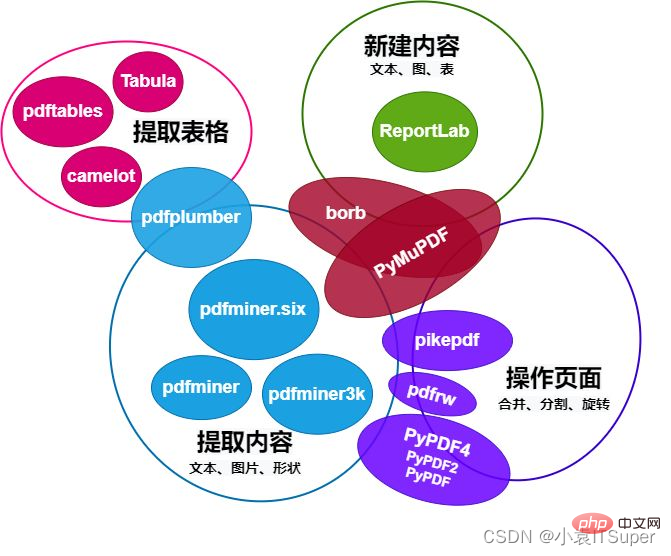
Cet article présente principalement pdfplumber en se concentrant sur l'extraction de contenu PDF, tel que le texte (position, police et couleur, etc.) et forme (rectangle, ligne droite, courbe), ainsi que la fonction des tables d'analyse. pdfplumber专注PDF内容提取,例如文本(位置、字体及颜色等)和形状(矩形、直线、曲线),还有解析表格的功能。
二、pdfplumber模块
其他几个 Python 库帮助用户从 PDF 中提取信息。作为一个广泛的概述,pdfplumber它通过结合以下功能将自己与其他 PDF 处理库区分开来:
- 轻松访问有关每个 PDF 对象的详细信息
- 用于提取文本和表格的更高级别、可自定义的方法
- 紧密集成的可视化调试
- 其他有用的实用功能,例如通过裁剪框过滤对象
1. 安装
cmd控制台输入:
pip install pdfplumber
导包:
import pdfplumber
案例PDF截图(两页未截全):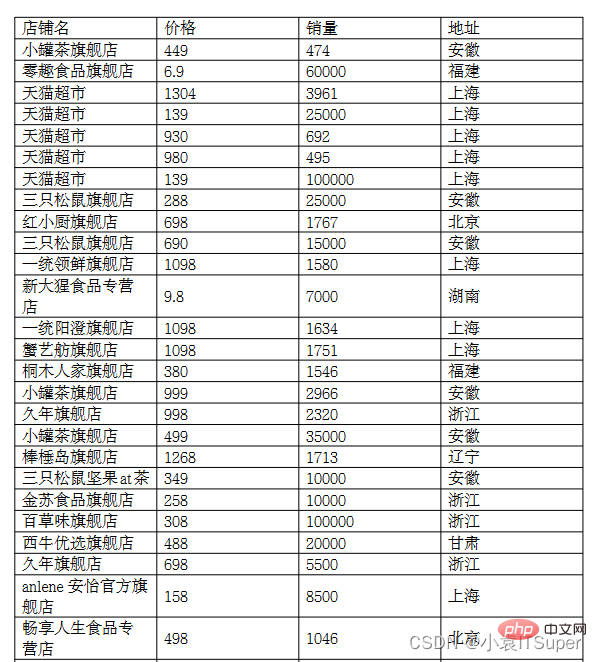
2. 加载PDF
读取PDF代码:pdfplumber.open("路径/文件名.pdf", password = "test", laparams = { "line_overlap": 0.7 })
参数解读:
-
password:要加载受密码保护的 PDF,请传递password关键字参数 -
laparams:要将布局分析参数设置为pdfminer.six的布局引擎,请传递laparams关键字参数
案例代码:
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf)
print(type(pdf))输出结果:
<pdfplumber.pdf.pdf><class></class></pdfplumber.pdf.pdf>
3. pdfplumber.PDF类
pdfplumber.PDF类表示单个 PDF,并具有两个主要属性:
| 属性 | 说明 |
|---|---|
.metadata |
从PDF的Info中获取元数据键 /值对字典。 通常包括“ CreationDate”,“ ModDate”,“ Producer”等。 |
.pages |
返回一个包含pdfplumber.Page实例的列表,每一个实例代表PDF每一页的信息 |
1. 读取PDF文档信息(.metadata):
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf.metadata)运行结果:
{'Author': 'wangwangyuqing', 'Comments': '', 'Company': '', 'CreationDate': "D:20220330113508+03'35'", 'Creator': 'WPS 文字', 'Keywords': '', 'ModDate': "D:20220330113508+03'35'", 'Producer': '', 'SourceModified': "D:20220330113508+03'35'", 'Subject': '', 'Title': '', 'Trapped': 'False'}2. 输出总页数
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(len(pdf.pages))运行结果:
2
4. pdfplumber.Page类
pdfplumber.Page类是pdfplumber整个的核心,大多数操作都围绕这个类进行操作,它具有以下几个属性:
| 属性 | 说明 |
|---|---|
.page_number |
顺序页码,从1第一页开始,从第二页开始2,依此类推。 |
.width |
页面的宽度。 |
.height |
页面的高度。 |
.objects/.chars/.lines/.rects/.curves/.figures/.images |
这些属性中的每一个都是一个列表,每个列表包含一个字典,用于嵌入页面上的每个此类对象。有关详细信息,请参阅下面的“对象”。 |
常用方法如下:
| 方法名 | 说明 |
|---|---|
.extract_text() |
用来提页面中的文本,将页面的所有字符对象整理为的那个字符串 |
.extract_words() |
返回的是所有的单词及其相关信息 |
.extract_tables() |
提取页面的表格 |
.to_image() |
用于可视化调试时,返回PageImage类的一个实例 |
.close() | 2. module pdfplumber Plusieurs autres bibliothèques Python aident les utilisateurs à extraire des informations à partir de PDF. D'une manière générale, pdfplumber se différencie des autres bibliothèques de traitement PDF en combinant les fonctionnalités suivantes : |
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
# 查看页码
print('页码:', first_page.page_number)
# 查看页宽
print('页宽:', first_page.width)
# 查看页高
print('页高:', first_page.height)页码: 1页宽: 595.3页高: 841.9
 🎜🎜2. Charger le PDF🎜🎜Lire le code PDF :
🎜🎜2. Charger le PDF🎜🎜Lire le code PDF : pdfplumber.open("path/filename.pdf", password = " test", laparams = { "line_overlap": 0.7 })🎜🎜Interprétation des paramètres :🎜-
mot de passe: obligatoire Pour charger un PDF protégé par mot de passe, transmettez le mot de passe Argument de mot-clé -
laparams: Pour définir les paramètres d'analyse de mise en page sur le moteur de mise en page de pdfminer.six, transmettez l'argument de mot-clé laparams
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
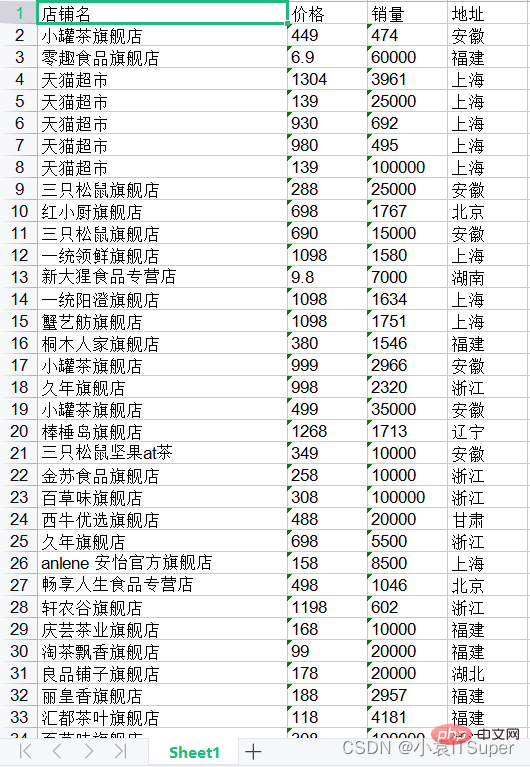
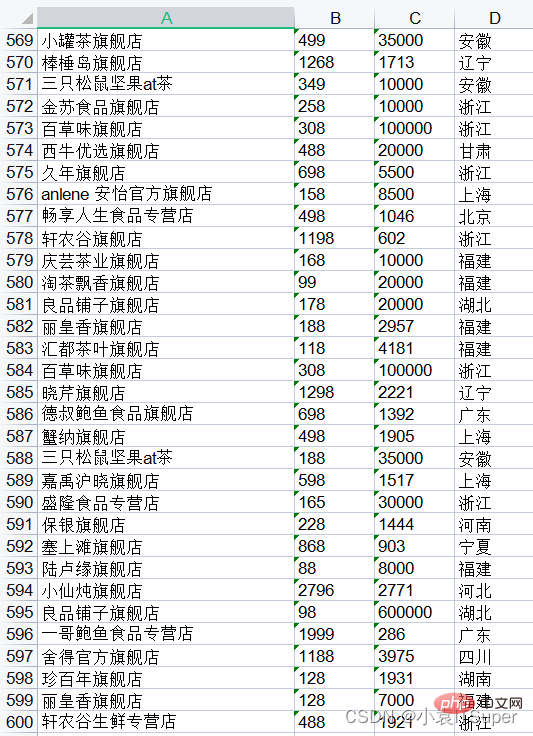
text = first_page.extract_text()
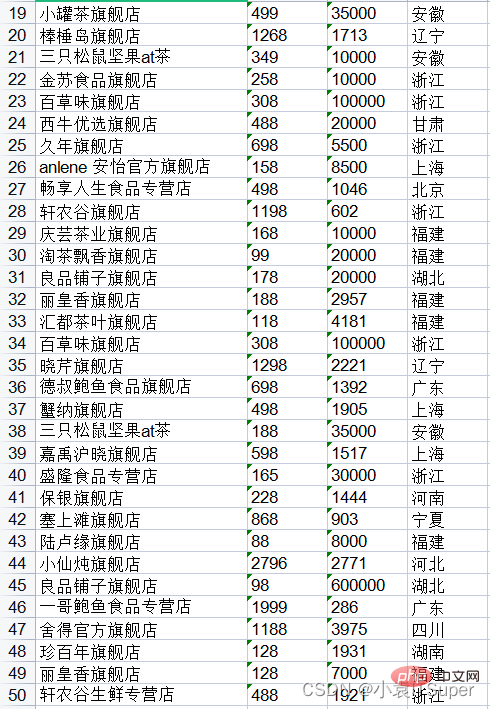
print(text)店铺名 价格 销量 地址 小罐茶旗舰店 449 474 安徽 零趣食品旗舰店 6.9 60000 福建 天猫超市 1304 3961 上海 天猫超市 139 25000 上海 天猫超市 930 692 上海 天猫超市 980 495 上海 天猫超市 139 100000 上海 三只松鼠旗舰店 288 25000 安徽 红小厨旗舰店 698 1767 北京 三只松鼠旗舰店 690 15000 安徽 一统领鲜旗舰店 1098 1580 上海 新大猩食品专营9.8 7000 湖南.......舰店 蟹纳旗舰店 498 1905 上海 三只松鼠坚果at茶 188 35000 安徽 嘉禹沪晓旗舰店 598 1517 上海
pdfplumber.PDF représente un seul PDF et possède deux propriétés principales : 🎜| Attribut | Description | 🎜||
|---|---|---|---|
| Attribut | Description | 🎜
|---|---|
| Nom de la méthode | Description | 🎜
|---|---|
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Il n'y a pas de fonction de somme intégrée dans le langage C, il doit donc être écrit par vous-même. La somme peut être obtenue en traversant le tableau et en accumulant des éléments: Version de boucle: la somme est calculée à l'aide de la longueur de boucle et du tableau. Version du pointeur: Utilisez des pointeurs pour pointer des éléments de tableau, et un résumé efficace est réalisé grâce à des pointeurs d'auto-incitation. Allouer dynamiquement la version du tableau: allouer dynamiquement les tableaux et gérer la mémoire vous-même, en veillant à ce que la mémoire allouée soit libérée pour empêcher les fuites de mémoire.
 Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Il n'y a pas de salaire absolu pour les développeurs Python et JavaScript, selon les compétences et les besoins de l'industrie. 1. Python peut être davantage payé en science des données et en apprentissage automatique. 2. JavaScript a une grande demande dans le développement frontal et complet, et son salaire est également considérable. 3. Les facteurs d'influence comprennent l'expérience, la localisation géographique, la taille de l'entreprise et les compétences spécifiques.
 Comment convertir XML en mp3
Apr 03, 2025 am 09:00 AM
Comment convertir XML en mp3
Apr 03, 2025 am 09:00 AM
Les étapes pour convertir XML en MP3 incluent: Extraire les données audio de XML: analyser le fichier XML, trouver la chaîne de codage Base64 contenant les données audio et les décoder en format binaire. Encoder les données audio à MP3: Installez l'encodeur MP3 et définissez les paramètres de codage, encodez les données audio binaires au format MP3 et enregistrez-les dans un fichier.
 Est-ce que distincte est lié?
Apr 03, 2025 pm 10:30 PM
Est-ce que distincte est lié?
Apr 03, 2025 pm 10:30 PM
Bien que distincts et distincts soient liés à la distinction, ils sont utilisés différemment: distinct (adjectif) décrit le caractère unique des choses elles-mêmes et est utilisée pour souligner les différences entre les choses; Distinct (verbe) représente le comportement ou la capacité de distinction, et est utilisé pour décrire le processus de discrimination. En programmation, distinct est souvent utilisé pour représenter l'unicité des éléments d'une collection, tels que les opérations de déduplication; Distinct se reflète dans la conception d'algorithmes ou de fonctions, tels que la distinction étrange et uniforme des nombres. Lors de l'optimisation, l'opération distincte doit sélectionner l'algorithme et la structure de données appropriés, tandis que l'opération distincte doit optimiser la distinction entre l'efficacité logique et faire attention à l'écriture de code clair et lisible.
 Comment changer le format de XML
Apr 03, 2025 am 08:42 AM
Comment changer le format de XML
Apr 03, 2025 am 08:42 AM
Il existe plusieurs façons de modifier les formats XML: édition manuellement avec un éditeur de texte tel que le bloc-notes; Formatage automatique avec des outils de mise en forme XML en ligne ou de bureau tels que XMLBeautifier; Définir les règles de conversion à l'aide d'outils de conversion XML tels que XSLT; ou analyser et fonctionner à l'aide de langages de programmation tels que Python. Soyez prudent lorsque vous modifiez et sauvegardez les fichiers d'origine.
 Apr 03, 2025 am 08:12 AM
Apr 03, 2025 am 08:12 AM
La modification des données XML peut être effectuée manuellement ou en utilisant des langages de programmation et des bibliothèques. Les modifications manuelles conviennent à de petites quantités de modifications aux petits documents, notamment en ajoutant, modifiant ou supprimant les éléments et attributs. Pour des modifications plus complexes, des langages de programmation et des bibliothèques tels que Python's XML.Dom et Java Javax.xml.PARSERS, qui fournissent des outils pour le traitement des données XML. Lors de la modification des données XML, assurez-vous sa validité, créez des sauvegardes et suivez les règles de syntaxe XML, y compris les balises et propriétés correctes.
 Comment convertir XML en mot
Apr 03, 2025 am 08:15 AM
Comment convertir XML en mot
Apr 03, 2025 am 08:15 AM
Il existe trois façons de convertir XML en Word: utilisez Microsoft Word, utilisez un convertisseur XML ou utilisez un langage de programmation.
 Comment comprendre! X en C?
Apr 03, 2025 pm 02:33 PM
Comment comprendre! X en C?
Apr 03, 2025 pm 02:33 PM
! x Compréhension! X est un non-opérateur logique dans le langage C. Il booléen la valeur de x, c'est-à-dire que les véritables modifications sont fausses et fausses modifient true. Mais sachez que la vérité et le mensonge en C sont représentés par des valeurs numériques plutôt que par les types booléens, le non-zéro est considéré comme vrai, et seul 0 est considéré comme faux. Par conséquent,! X traite des nombres négatifs de la même manière que des nombres positifs et est considéré comme vrai.
