

Cet article vous donnera une analyse approfondie de l'optimiseur de requêtes dans MySQL et vous aidera à comprendre le principe de fonctionnement de l'optimiseur de requêtes MySQL. J'espère qu'il vous sera utile !

Pour une instruction SQL, l'optimiseur de requête vérifie d'abord si elle peut être convertie en JOIN, puis optimise le JOIN.
L'optimisation est divisée en : 1. Optimisation conditionnelle, 2. Calculer le coût complet de l'analyse de la table. , 3. Découvrez tous les index pouvant être utilisés, 4. Calculez le coût des différentes méthodes d'accès pour chaque index, 5. Sélectionnez l'index et la méthode d'accès avec le plus petit coût
-- 开启 set optimizer_trace="enabled=on"; -- 执行sql -- 查看日志信息 select * from information_schema.OPTIMIZER_TRACE; -- 关闭 set optimizer_trace="enabled=off";
1. Propagation constante (constant_propagation)
a = 1 AND b > a
Le SQL ci-dessus peut être converti en :
a = 1 AND b >
a = 5 et b = 5 et c = 5
a = 1
Le moteur de stockage InnoDB stocke à la fois les données et les index sur le disque Lorsque nous voulons interroger les enregistrements de la table, nous devons d'abord charger les données ou l'index dans la mémoire, puis opérer. Le temps perdu dans le processus de chargement du disque vers la mémoire est appelé coût d'E/S
2) Coût du processeur
Le temps perdu pour lire et vérifier si les enregistrements répondent aux conditions de recherche correspondantes, trier l'ensemble de résultats, etc. est appelé le Coût du processeur.
Le moteur de stockage InnoDB stipule que le coût de lecture d'une page est de 1,0 par défaut, et le coût de lecture et de vérification si un enregistrement répond aux conditions de recherche est de 0,2 par défaut.
select * from employees.titles where emp_no > '10101' and emp_no < '20000' and to_date = '1991-10-10';
• emp_no > peut utiliser l'index de clé primaire PRIMARY. • to_date = '1991-10-10', cette condition de recherche peut utiliser l'index secondaire idx_titles_to_date.
Pour résumer, les index qui peuvent être utilisés dans l'instruction de requête ci-dessus, c'est-à-dire que les seules clés possibles sont PRIMARY et idx_titles_to_date.
Pour le moteur de stockage InnoDB, l'analyse complète de la table signifie comparer les enregistrements de l'index clusterisé avec les conditions de recherche données dans l'ordre et faire correspondre les enregistrements du les conditions de recherche sont ajoutées à l'ensemble de résultats, de sorte que la page correspondant à l'index clusterisé doit être chargée dans la mémoire, puis si l'enregistrement répond aux conditions de recherche est détecté. Puisque coût de la requête = coût d'E/S + coût du CPU, deux informations sont nécessaires pour calculer le coût d'une analyse complète de table :
1) Le nombre de pages occupées par l'index clusterisé 2) Le nombre d'enregistrements dans la table MySQL pour chaque Chaque table conserve une série d'informations statistiques. Utilisez l'instruction SHOW TABLE STATUS pour afficher les informations statistiques de la table.SHOW TABLE STATUS LIKE 'titles';
Rows
représente le nombre d'enregistrements dans le tableau. Cette valeur est précise pour les tables utilisant le moteur de stockage MyISAM et constitue une estimation pour les tables utilisant le moteur de stockage InnoDB.
Data_length
indique le nombre d'octets d'espace de stockage occupé par la table. Pour les tables utilisant le moteur de stockage MyISAM, cette valeur est la taille du fichier de données. Pour les tables utilisant le moteur de stockage InnoDB, cette valeur est équivalente à l'espace de stockage occupé par l'index clusterisé, ce qui signifie que la valeur peut être calculée comme ceci. Taille : Data_length = 聚簇索引的页面数量 x 每个页面的大小
聚簇索引的页面数量 = Data_length ÷ 16 ÷ 1024 = 20512768 ÷ 16 ÷ 1024 = 1252
1 = 1252. 1252 fait référence au nombre de pages occupées par l'index clusterisé et 1,0 fait référence à la constante de coût de chargement d'une page.
Coût du CPU : 442070
0,2=88414. 442070 fait référence au nombre d'enregistrements dans le tableau des statistiques, qui est une estimation pour le moteur de stockage InnoDB, et 0,2 fait référence à la constante de coût requise pour accéder à un enregistrementCoût total : 1252+88414 = 89666.
Pour résumer, le coût total de numérisation de la table complète des titres est de 89666.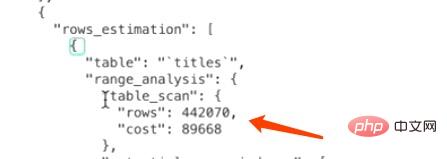
我们前边说过表中的记录其实都存储在聚簇索引对应B+树的叶子节点中,所以只要我们通过根节点获得了最左边的叶子节点,就可以沿着叶子节点组成的双向链表把所有记录都查看一遍。也就是说全表扫描这个过程其实有的B+树内节点是不需要访问的,但是MySQL在计算全表扫描成本时直接使用聚簇索引占用的页面数作为计算I/O成本的依据,是不区分内节点和叶子节点的。
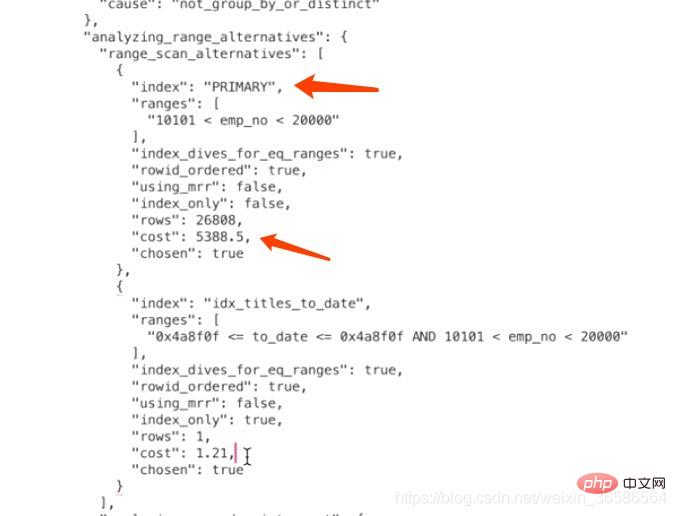
3、计算PRIMARY需要成本
计算PRIMARY需要多少成本的关键问题是:需要预估出根据对应的where条件在主键索引B+树中存在多少条符合条件的记录。
范围区间数
当我们从索引中查询记录时,不管是=、in、>、<这些操作都需要从索引中确定一个范围,不论这个范围区间的索引到底占用了多少页面,查询优化器粗暴的认为读取索引的一个范围区间的I/O成本和读取一个页面是相同的。
本例中使用PRIMARY的范围区间只有一个:(10101, 20000),所以相当于访问这个范围区间的索引付出的I/O成本就是:1 x 1.0 = 1.0
预估范围内的记录数
优化器需要计算索引的某个范围区间到底包含多少条记录,对于本例来说就是要计算PRIMARY在(10101, 20000)这个范围区间中包含多少条数据记录,计算过程是这样的:
步骤1:先根据emp_no > 10101这个条件访问一下PRIMARY对应的B+树索引,找到满足emp_no > 10101这个条件的第一条记录,我们把这条记录称之为区间最左记录。
步骤2:然后再根据emp_no < 20000这个条件继续从PRIMARY对应的B+树索引中找出第一条满足这个条件的记录,我们把这条记录称之为区间最右记录。
步骤3:如果区间最左记录和区间最右记录相隔不太远(只要相隔不大于10个页面即可),那就可以精确统计出满足emp_no > '10101' and emp_no < '20000'条件的记录条数。否则只沿着区间最左记录向右读10个页面,计算平均每个页面中包含多少记录,然后用这个平均值乘以区间最左记录和区间最右记录之间的页面数量就可以了。那么问题又来了,怎么估计区间最左记录和区间最右记录之间有多少个页面呢?计算它们父节点中对应的目录项记录之间隔着几条记录就可以了。
根据上面的步骤可以算出来PRIMARY索引的记录条数,所以读取记录的CPU成本为:26808*0.2=5361.6,其中26808是预估的需要读取的数据记录条数,0.2是读取一条记录成本常数。
PRIMARY的总成本
确定访问的IO成本+过滤数据的CPU成本=1+5361.6=5362.6
4、计算idx_titles_to_date需要成本
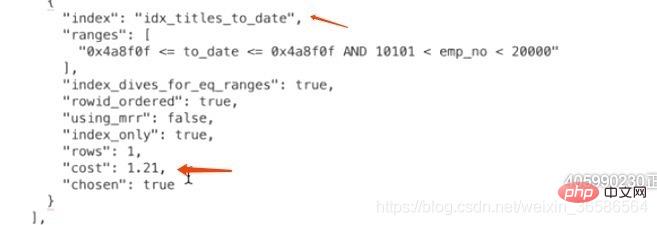
因为通过二级索引查询需要回表,所以在计算二级索引需要成本时还要加上回表的成本,而回表的成本就相当于下面这个SQL执行:
select * from employees.titles where 主键字段 in (主键值1,主键值2,。。。,主键值3);
所以idx_titles_to_date的成本 = 辅助索引的查询成本 + 回表查询的成本
5、比较各成本选出最优者
选择成本最小的索引
有时候使用索引执行查询时会有许多单点区间,比如使用IN语句就很容易产生非常多的单点区间,比如下边这个查询:
select * from employees.titles where to_date in ('a','b','c','d', ..., 'e');
很显然,这个查询可能使用到的索引就是idx_titles_to_date,由于这个索引并不是唯一二级索引,所以并不能确定一个单点区间对应的二级索引记录的条数有多少,需要我们去计算。计算方式我们上边已经介绍过了,就是先获取索引对应的B+树的区间最左记录和区间最右记录,然后再计算这两条记录之间有多少记录(记录条数少的时候可以做到精确计算,多的时候只能估算)。这种通过直接访问索引对应的B+树来计算某个范围区间对应的索引记录条数的方式称之为index pe。
如果只有几个单点区间的话,使用index pe的方式去计算这些单点区间对应的记录数也不是什么问题,可是如果很多呢,比如有20000次,MySQL的查询优化器为了计算这些单点区间对应的索引记录条数,要进行20000次index pe操作,那么这种情况下是很耗性能的,所以MySQL提供了一个系统变量eq_range_index_pe_limit,我们看一下这个系统变量的默认值:SHOW VARIABLES LIKE ‘%pe%’;为200。
也就是说如果我们的IN语句中的参数个数小于200个的话,将使用index pe的方式计算各个单点区间对应的记录条数,如果大于或等于200个的话,可就不能使用index pe了,要使用所谓的索引统计数据来进行估算。像会为每个表维护一份统计数据一样,MySQL也会为表中的每一个索引维护一份统计数据,查看某个表中索引的统计数据可以使用SHOW INDEX FROM 表名的语法。
Cardinality属性表示索引列中不重复值的个数。比如对于一个一万行记录的表来说,某个索引列的Cardinality属性是10000,那意味着该列中没有重复的值,如果Cardinality属性是1的话,就意味着该列的值全部是重复的。不过需要注意的是,对于InnoDB存储引擎来说,使用SHOW INDEX语句展示出来的某个索引列的Cardinality属性是一个估计值,并不是精确的。可以根据这个属性来估算IN语句中的参数所对应的记录数:
1)使用SHOW TABLE STATUS展示出的Rows值,也就是一个表中有多少条记录。
2)使用SHOW INDEX语句展示出的Cardinality属性。
3)根据上面两个值可以算出idx_key1索引对于的key1列平均单个值的重复次数:Rows/Cardinality
4)所以总共需要回表的记录数就是:IN语句中的参数个数*Rows/Cardinality。
NULL值处理
上面知道在统计列不重复值的时候,会影响到查询优化器。
对于NULL,有三种理解方式:
NULL值代表一个未确定的值,每一个NULL值都是独一无二的,在统计列不重复值的时候应该都当作独立的。
NULL值在业务上就是代表没有,所有的NULL值代表的意义是一样的,所以所有的NULL值都一样,在统计列不重复值的时候应该只算一个。
NULL完全没有意义,在统计列不重复值的时候应该忽略NULL。
innodb提供了一个系统变量:
show global variables like '%innodb_stats_method%';
这个变量有三个值:
nulls_equal:认为所有NULL值都是相等的。这个值也是innodb_stats_method的默认值。如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别多,所以倾向于不使用索引进行访问。
nulls_unequal:认为所有NULL值都是不相等的。如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别少,所以倾向于使用索引进行访问。
nulls_ignored:直接把NULL值忽略掉。
最好不在索引列中存放NULL值才是正解
InnoDB提供了两种存储统计数据的方式:
• 统计数据存储在磁盘上。
• 统计数据存储在内存中,当服务器关闭时这些这些统计数据就都被清除掉了。
MySQL给我们提供了系统变量innodb_stats_persistent来控制到底采用哪种方式去存储统计数据。在MySQL 5.6.6之前,innodb_stats_persistent的值默认是OFF,也就是说InnoDB的统计数据默认是存储到内存的,之后的版本中innodb_stats_persistent的值默认是ON,也就是统计数据默认被存储到磁盘中。
不过InnoDB默认是以表为单位来收集和存储统计数据的,也就是说我们可以把某些表的统计数据(以及该表的索引统计数据)存储在磁盘上,把另一些表的统计数据存储在内存中。我们可以在创建和修改表的时候通过指定STATS_PERSISTENT属性来指明该表的统计数据存储方式。
SELECT * FROM table1 USE|IGNORE|FORCE INDEX (col1_index,col2_index) WHERE col1=1 AND col2=2 AND col3=3
【相关推荐:mysql视频教程】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié











![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



