
 Java
JavaQuestions d'entretien
[Compilation d'hématémèse] Questions et réponses d'entretien de base à haute fréquence Java 2023 (Collection)
Java
JavaQuestions d'entretien
[Compilation d'hématémèse] Questions et réponses d'entretien de base à haute fréquence Java 2023 (Collection)
[Compilation d'hématémèse] Questions et réponses d'entretien de base à haute fréquence Java 2023 (Collection)

Cet article résume pour vous quelques questions d'entretien de base à haute fréquence Java sélectionnées en 2023 qui méritent d'être collectées (avec réponses). Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.
![[Compilation d'hématémèse] Questions et réponses d'entretien de base à haute fréquence Java 2023 (Collection)](https://img.php.cn/upload/article/000/000/024/62c79d0ce0756800.jpg)
1. Trois caractéristiques fondamentales de l'orienté objet ?
Les trois caractéristiques fondamentales de l'orientation objet sont : l'encapsulation, l'héritage et le polymorphisme.
Héritage : Une méthode qui permet à un objet d'un certain type d'obtenir les propriétés d'un objet d'un autre type. L'héritage signifie qu'une sous-classe hérite des caractéristiques et des comportements de la classe parent, de sorte que l'objet de la sous-classe (instance) possède les champs d'instance et les méthodes de la classe parent, ou que la sous-classe hérite des méthodes de la classe parent, de sorte que la sous-classe ait le même comportement que la classe parent. (Tutoriel recommandé : Tutoriel d'introduction au didacticiel Java)
Encapsulation : masquez les propriétés et les détails d'implémentation de certains objets, et l'accès aux données ne peut se faire que via des interfaces exposées en externe. De cette manière, les objets offrent différents niveaux de protection pour les données internes afin d'empêcher des parties non liées du programme de modifier accidentellement ou d'utiliser incorrectement les parties privées de l'objet.
Polymorphisme : Pour un même comportement, différents objets de sous-classe ont des expressions différentes. Il existe trois conditions pour l'existence du polymorphisme : 1) l'héritage ; 2) l'écrasement ; 3) les points de référence de la classe parent vers l'objet de la sous-classe.
Un exemple simple : Dans League of Legends, on appuie sur la touche Q :
- Pour Yasuo, c'est Steel Flash
- Pour Teemo, c'est Blinding Dart
- Pour Juggernaut, c'est Alpha Strike
Le même événement produira des résultats différents lorsque cela se produit sur différents objets.
Laissez-moi vous donner un autre exemple simple pour vous aider à comprendre. Cet exemple n'est peut-être pas tout à fait exact, mais je pense qu'il est utile pour comprendre.
public class Animal { // 动物
public void sleep() {
System.out.println("躺着睡");
}
}
class Horse extends Animal { // 马 是一种动物
public void sleep() {
System.out.println("站着睡");
}
}
class Cat extends Animal { // 猫 是一种动物
private int age;
public int getAge() {
return age + 1;
}
@Override
public void sleep() {
System.out.println("四脚朝天的睡");
}
}Dans cet exemple :
House et Cat sont tous deux des animaux, ils héritent donc tous les deux d'Animal et héritent également du comportement de sommeil d'Animal.
Mais pour le comportement de sommeil, House et Cat ont été réécrits et ont des expressions (implémentations) différentes. C'est ce qu'on appelle le polymorphisme.
Dans Cat, l'attribut age est défini comme privé et n'est pas directement accessible au monde extérieur. Le seul moyen d'obtenir les informations sur l'âge de Cat est d'utiliser la méthode getAge, cachant ainsi l'attribut age de l'extérieur. Bien sûr, l’âge n’est ici qu’un exemple, et il peut s’agir d’un objet beaucoup plus complexe en utilisation réelle.
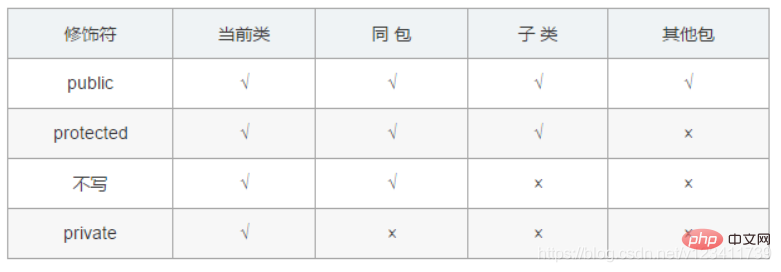
2. Quelle est la différence entre les modificateurs d'accès public, privé, protégé et non écrit ?
3. Les deux blocs de code suivants peuvent-ils être compilés et exécutés normalement ?
// 代码块1 short s1 = 1; s1 = s1 + 1; // 代码块2 short s1 = 1; s1 += 1;
Une erreur est signalée lors de la compilation du bloc de code 1. La raison de l'erreur est : type incompatible : il peut y avoir une perte lors de la conversion de int en short
Le bloc de code 2 se compile et s'exécute normalement. bloc de code 2, le bytecode est le suivant :
public class com.joonwhee.open.demo.Convert {
public com.joonwhee.open.demo.Convert();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: iconst_1 // 将int类型值1入(操作数)栈
1: istore_1 // 将栈顶int类型值保存到局部变量1中
2: iload_1 // 从局部变量1中装载int类型值入栈
3: iconst_1 // 将int类型值1入栈
4: iadd // 将栈顶两int类型数相加,结果入栈
5: i2s // 将栈顶int类型值截断成short类型值,后带符号扩展成int类型值入栈。
6: istore_1 // 将栈顶int类型值保存到局部变量1中
7: return
}Vous pouvez voir que le bytecode contient l'instruction i2s, qui est utilisée pour convertir int en short i2s est l'abréviation de int en short
En fait, s1 += 1. est équivalent à s1 =. (short)(s1 + 1). Si vous êtes intéressé, vous pouvez compiler vous-même le bytecode de ces deux lignes de code. Vous constaterez qu'elles sont exactement les mêmes. Les questions que vous avez mentionnées sont redevenues anormales
4. Soulignez le résultat de la question suivante 
public static void main(String[] args) {
Integer a = 128, b = 128, c = 127, d = 127;
System.out.println(a == b);
System.out.println(c == d);
}La réponse est : faux, vrai Exécuter Integer a = 128, ce qui équivaut à. exécutant : Integer a = Integer.valueOf(128 ), le processus de conversion automatique d'un type de base en classe wrapper est appelé autoboxing
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}IntegerCache est introduit dans Integer pour mettre en cache une certaine plage de valeurs. : -128~127. 127 dans cette question atteint IntegerCache, donc c et d sont les mêmes objets, mais 128 n'est pas atteint, donc a et b sont des objets différents
Mais cette plage de cache peut être modifiée, et certaines personnes. ne le sait peut-être pas via les paramètres de démarrage de la JVM : -XX:AutoBoxCacheMax= 5. Utilisez la méthode la plus efficace pour calculer 2 fois 8 ? ; 3. Avancé : dans des circonstances normales, les opérations sur les bits peuvent être considérées comme ayant les performances les plus élevées. Cependant, en fait, les compilateurs sont désormais "très intelligents", et de nombreux compilateurs d'instructions peuvent faire leur propre optimisation. Pour poursuivre des opérations pratiques sur les bits, cela entraînera non seulement une mauvaise lisibilité du code, mais également certaines optimisations intelligentes induiront le compilateur en erreur, rendant impossible pour le compilateur d'effectuer de meilleures optimisations. Cela peut être ce qu'on appelle les « coéquipiers Pig ». . &&:逻辑与运算符。当运算符左右两边的表达式都为 true,才返回 true。同时具有短路性,如果第一个表达式为 false,则直接返回 false。 &:逻辑与运算符、按位与运算符。 按位与运算符:用于二进制的计算,只有对应的两个二进位均为1时,结果位才为1 ,否则为0。 逻辑与运算符:& 在用于逻辑与时,和 && 的区别是不具有短路性。所在通常使用逻辑与运算符都会使用 &&,而 & 更多的适用于位运算。 答:不是。Java 中的基本数据类型只有8个:byte、short、int、long、float、double、char、boolean;除了基本类型(primitive type),剩下的都是引用类型(reference type)。 基本数据类型:数据直接存储在栈上 引用数据类型区别:数据存储在堆上,栈上只存储引用地址 不行。String 类使用 final 修饰,无法被继承。 String:String 的值被创建后不能修改,任何对 String 的修改都会引发新的 String 对象的生成。 StringBuffer:跟 String 类似,但是值可以被修改,使用 synchronized 来保证线程安全。 StringBuilder:StringBuffer 的非线程安全版本,没有使用 synchronized,具有更高的性能,推荐优先使用。 一个或两个。如果字符串常量池已经有“xyz”,则是一个;否则,两个。 当字符创常量池没有 “xyz”,此时会创建如下两个对象: 一个是字符串字面量 "xyz" 所对应的、驻留(intern)在一个全局共享的字符串常量池中的实例,此时该实例也是在堆中,字符串常量池只放引用。 另一个是通过 new String() 创建并初始化的,内容与"xyz"相同的实例,也是在堆中。 两个语句都会先去字符串常量池中检查是否已经存在 “xyz”,如果有则直接使用,如果没有则会在常量池中创建 “xyz” 对象。 另外,String s = new String("xyz") 还会通过 new String() 在堆里创建一个内容与 "xyz" 相同的对象实例。 所以前者其实理解为被后者的所包含。 ==:运算符,用于比较基础类型变量和引用类型变量。 对于基础类型变量,比较的变量保存的值是否相同,类型不一定要相同。 对于引用类型变量,比较的是两个对象的地址是否相同。 equals:Object 类中定义的方法,通常用于比较两个对象的值是否相等。 equals 在 Object 方法中其实等同于 ==,但是在实际的使用中,equals 通常被重写用于比较两个对象的值是否相同。 不对。hashCode() 和 equals() 之间的关系如下: 当有 a.equals(b) == true 时,则 a.hashCode() == b.hashCode() 必然成立, 反过来,当 a.hashCode() == b.hashCode() 时,a.equals(b) 不一定为 true。 反射是指在运行状态中,对于任意一个类都能够知道这个类所有的属性和方法;并且对于任意一个对象,都能够调用它的任意一个方法;这种动态获取信息以及动态调用对象方法的功能称为反射机制。 数据分为基本数据类型和引用数据类型。基本数据类型:数据直接存储在栈中;引用数据类型:存储在栈中的是对象的引用地址,真实的对象数据存放在堆内存里。 浅拷贝:对于基础数据类型:直接复制数据值;对于引用数据类型:只是复制了对象的引用地址,新旧对象指向同一个内存地址,修改其中一个对象的值,另一个对象的值随之改变。 深拷贝:对于基础数据类型:直接复制数据值;对于引用数据类型:开辟新的内存空间,在新的内存空间里复制一个一模一样的对象,新老对象不共享内存,修改其中一个对象的值,不会影响另一个对象。 深拷贝相比于浅拷贝速度较慢并且花销较大。 并发:两个或多个事件在同一时间间隔发生。 并行:两个或者多个事件在同一时刻发生。 并行是真正意义上,同一时刻做多件事情,而并发在同一时刻只会做一件事件,只是可以将时间切碎,交替做多件事情。 网上有个例子挺形象的: 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。 Constructor 不能被 override(重写),但是可以 overload(重载),所以你可以看到⼀个类中有多个构造函数的情况。 值传递。Java 中只有值传递,对于对象参数,值的内容是对象的引用。 成员变量存在于堆内存中。静态变量存在于方法区中。 成员变量与对象共存亡,随着对象创建而存在,随着对象被回收而释放。静态变量与类共存亡,随着类的加载而存在,随着类的消失而消失。 成员变量所属于对象,所以也称为实例变量。静态变量所属于类,所以也称为类变量。 成员变量只能被对象所调用 。静态变量可以被对象调用,也可以被类名调用。 区分两种情况,发出调用时是否显示创建了对象实例。 1)没有显示创建对象实例:不可以发起调用,非静态方法只能被对象所调用,静态方法可以通过对象调用,也可以通过类名调用,所以静态方法被调用时,可能还没有创建任何实例对象。因此通过静态方法内部发出对非静态方法的调用,此时可能无法知道非静态方法属于哪个对象。 2)显示创建对象实例:可以发起调用,在静态方法中显示的创建对象实例,则可以正常的调用。 执行结果:ABabab,两个考察点: 1)静态变量只会初始化(执行)一次。 2)当有父类时,完整的初始化顺序为:父类静态变量(静态代码块)->子类静态变量(静态代码块)->父类非静态变量(非静态代码块)->父类构造器 ->子类非静态变量(非静态代码块)->子类构造器 。 关于初始化,这题算入门题,我之前还写过一道有(fei)点(chang)意(bian)思(tai)的进阶题目,有兴趣的可以看看:一道有意思的“初始化”面试题 方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。 重载:一个类中有多个同名的方法,但是具有有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)。 重写:发生在子类与父类之间,子类对父类的方法进行重写,参数都不能改变,返回值类型可以不相同,但是必须是父类返回值的派生类。即外壳不变,核心重写!重写的好处在于子类可以根据需要,定义特定于自己的行为。 如果我们有两个方法如下,当我们调用:test(1) 时,编译器无法确认要调用的是哪个。 方法的返回值只是作为方法运行之后的一个“状态”,但是并不是所有调用都关注返回值,所以不能将返回值作为重载的唯一区分条件。 抽象类只能单继承,接口可以多实现。 抽象类可以有构造方法,接口中不能有构造方法。 抽象类中可以有成员变量,接口中没有成员变量,只能有常量(默认就是 public static final) 抽象类中可以包含非抽象的方法,在 Java 7 之前接口中的所有方法都是抽象的,在 Java 8 之后,接口支持非抽象方法:default 方法、静态方法等。Java 9 支持私有方法、私有静态方法。 抽象类中的方法类型可以是任意修饰符,Java 8 之前接口中的方法只能是 public 类型,Java 9 支持 private 类型。 设计思想的区别: 接口是自上而下的抽象过程,接口规范了某些行为,是对某一行为的抽象。我需要这个行为,我就去实现某个接口,但是具体这个行为怎么实现,完全由自己决定。 抽象类是自下而上的抽象过程,抽象类提供了通用实现,是对某一类事物的抽象。我们在写实现类的时候,发现某些实现类具有几乎相同的实现,因此我们将这些相同的实现抽取出来成为抽象类,然后如果有一些差异点,则可以提供抽象方法来支持自定义实现。 我在网上看到有个说法,挺形象的: 普通类像亲爹 ,他有啥都是你的。 抽象类像叔伯,有一部分会给你,还能指导你做事的方法。 接口像干爹,可以给你指引方法,但是做成啥样得你自己努力实现。 Error 和 Exception 都是 Throwable 的子类,用于表示程序出现了不正常的情况。区别在于: Error 表示系统级的错误和程序不必处理的异常,是恢复不是不可能但很困难的情况下的一种严重问题,比如内存溢出,不可能指望程序能处理这样的情况。 Exception 表示需要捕捉或者需要程序进行处理的异常,是一种设计或实现问题,也就是说,它表示如果程序运行正常,从不会发生的情况。 修饰类:该类不能再派生出新的子类,不能作为父类被继承。因此,一个类不能同时被声明为abstract 和 final。 修饰方法:该方法不能被子类重写。 修饰变量:该变量必须在声明时给定初值,而在以后只能读取,不可修改。 如果变量是对象,则指的是引用不可修改,但是对象的属性还是可以修改的。 其实是三个完全不相关的东西,只是长的有点像。。 final 如上所示。 finally:finally 是对 Java 异常处理机制的最佳补充,通常配合 try、catch 使用,用于存放那些无论是否出现异常都一定会执行的代码。在实际使用中,通常用于释放锁、数据库连接等资源,把资源释放方法放到 finally 中,可以大大降低程序出错的几率。 finalize:Object 中的方法,在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。finalize()方法仅作为了解即可,在 Java 9 中该方法已经被标记为废弃,并添加新的 java.lang.ref.Cleaner,提供了更灵活和有效的方法来释放资源。这也侧面说明了,这个方法的设计是失败的,因此更加不能去使用它。 执行结果:31。 相信很多同学应该都做对了,try、catch。finally 的基础用法,在 return 前会先执行 finally 语句块,所以是先输出 finally 里的 3,再输出 return 的 1。 执行结果:3。 这题有点陷阱,但也不难,try 返回前先执行 finally,结果 finally 里不按套路出牌,直接 return 了,自然也就走不到 try 里面的 return 了。 finally 里面使用 return 仅存在于面试题中,实际开发中千万不要这么用。 执行结果:2。 这边估计有不少同学会以为结果应该是 3,因为我们知道在 return 前会执行 finally,而 i 在 finally 中被修改为 3 了,那最终返回 i 不是应该为 3 吗?确实很容易这么想,我最初也是这么想的,当初的自己还是太年轻了啊。 这边的根本原因是,在执行 finally 之前,JVM 会先将 i 的结果暂存起来,然后 finally 执行完毕后,会返回之前暂存的结果,而不是返回 i,所以即使这边 i 已经被修改为 3,最终返回的还是之前暂存起来的结果 2。 En fait, cela peut être facilement vu en fonction du bytecode. Avant d'entrer définitivement, la JVM utilisera les instructions iload et istore pour stocker temporairement les résultats. Lorsqu'elle reviendra finalement, elle renverra les résultats temporaires via les instructions iload et istore. . Afin d'éviter que l'atmosphère ne redevienne anormale, je ne publierai pas ici le programme de bytecode spécifique. Les étudiants intéressés peuvent le compiler eux-mêmes et le vérifier. Méthode par défaut de l'interface : Java 8 nous permet d'ajouter une implémentation de méthode non abstraite à l'interface, utilisez simplement le mot-clé par défaut Expression lambda et interface fonctionnelle : l'expression lambda est essentiellement une classe interne anonyme, elle peut également être une morceau de code qui peut être transmis. Lambda permet d'utiliser la fonction comme paramètre d'une méthode (la fonction est passée à la méthode en tant que paramètre). Utilisez des expressions Lambda pour rendre le code plus concis, mais n'en abusez pas, sinon il y aura des problèmes de lisibilité, Josh. Bloch, auteur de "Effective Java", a suggéré qu'il est préférable d'utiliser des expressions lambda ne dépassant pas 3 lignes. API Stream : un outil permettant d'effectuer des opérations complexes sur des classes de collection à l'aide de la programmation fonctionnelle. Il peut être utilisé avec des expressions Lambda pour traiter facilement des collections. Une abstraction clé pour travailler avec des collections dans Java 8. Elle vous permet de spécifier les opérations que vous souhaitez effectuer sur les collections et peut effectuer des opérations très complexes telles que la recherche, le filtrage et le mappage de données. L'utilisation de l'API Stream pour opérer sur les données de collecte est similaire à l'utilisation de SQL pour effectuer des requêtes de base de données. Vous pouvez également utiliser l'API Stream pour effectuer des opérations en parallèle. En bref, l'API Stream offre un moyen efficace et facile à utiliser de traiter les données. Référence de méthode : la référence de méthode fournit une syntaxe très utile qui peut référencer directement des méthodes ou des constructeurs de classes ou d'objets Java existants (instances). Utilisées conjointement avec lambda, les références de méthodes peuvent rendre la structure du langage plus compacte et concise et réduire le code redondant. API Date et heure : Java 8 introduit une nouvelle API de date et d'heure pour améliorer la gestion de la date et de l'heure. Classe facultative : la fameuse NullPointerException est la cause la plus courante de panne du système. Le projet Google Guava a introduit Facultatif il y a longtemps comme moyen de résoudre les exceptions de pointeur nul, désapprouvant le code pollué par du code de vérification nul et s'attendant à ce que les programmeurs écrivent du code propre. Inspiré de Google Guava, Optionnel fait désormais partie de la bibliothèque Java 8. Nouveaux outils : Nouveaux outils de compilation, tels que : le moteur Nashorn jjs, l'analyseur de dépendances de classe jdeps. vient de différentes sources : sleep() vient de la classe Thread, wait() vient de la classe Object. L'impact sur les verrous de synchronisation est différent : sleep() ne se comportera pas comme un verrou de synchronisation sur la table. Si le thread actuel détient un verrou de synchronisation, alors sleep ne laissera pas le thread libérer le verrou de synchronisation. wait() libérera le verrou de synchronisation et permettra aux autres threads d'entrer dans le bloc de code synchronisé pour l'exécution. Différents domaines d'utilisation : sleep() peut être utilisé n'importe où. wait() ne peut être utilisé que dans des méthodes de contrôle synchronisées ou des blocs de contrôle synchronisés, sinon IllegalMonitorStateException sera levée. Les méthodes de récupération sont différentes : les deux mettront en pause le fil de discussion en cours, mais les méthodes de récupération sont différentes. sleep() reprendra une fois le temps écoulé ; wait() nécessite que d'autres threads appellent notify()/nofityAll() du même objet pour reprendre. Le thread entre dans l'état d'attente d'expiration (TIMED_WAITING) après avoir exécuté la méthode sleep() et entre dans l'état READY après avoir exécuté la méthode rendement(). La méthode sleep() ne prend pas en compte la priorité du thread lorsqu'elle donne une chance à d'autres threads de s'exécuter, elle donnera donc une chance aux threads de faible priorité de s'exécuter ; la méthode rendement() ne donnera que les threads de même priorité ; ou une priorité plus élevée pour exécuter l'opportunité. est utilisé pour attendre la fin du fil de discussion en cours. Si un thread A exécute l'instruction threadB.join(), la signification est la suivante : le thread actuel A attend la fin du thread threadB avant de revenir de threadB.join() et de continuer à exécuter son propre code. De manière générale, il existe trois manières : 1) hériter de la classe Thread ; 2) implémenter l'interface Runnable ; 3) implémenter l'interface Callable. Parmi eux, Thread implémente effectivement l'interface Runable. La principale différence entre Runnable et Callable est de savoir s'il existe une valeur de retour. run() : Les appels de méthode ordinaires sont exécutés dans le thread principal et ne créeront pas de nouveau thread pour l'exécution. start() : Démarrez un nouveau thread. À ce stade, le thread est dans l'état prêt (exécutable) et n'est pas en cours d'exécution. Une fois la tranche de temps CPU obtenue, la méthode run() commence à être exécutée. Un fil de discussion peut être dans l'un des états suivants : NEW:新建但是尚未启动的线程处于此状态,没有调用 start() 方法。 RUNNABLE:包含就绪(READY)和运行中(RUNNING)两种状态。线程调用 start() 方法会会进入就绪(READY)状态,等待获取 CPU 时间片。如果成功获取到 CPU 时间片,则会进入运行中(RUNNING)状态。 BLOCKED:线程在进入同步方法/同步块(synchronized)时被阻塞,等待同步锁的线程处于此状态。 WAITING:无限期等待另一个线程执行特定操作的线程处于此状态,需要被显示的唤醒,否则会一直等待下去。例如对于 Object.wait(),需要等待另一个线程执行 Object.notify() 或 Object.notifyAll();对于 Thread.join(),则需要等待指定的线程终止。 TIMED_WAITING:在指定的时间内等待另一个线程执行某项操作的线程处于此状态。跟 WAITING 类似,区别在于该状态有超时时间参数,在超时时间到了后会自动唤醒,避免了无期限的等待。 TERMINATED:执行完毕已经退出的线程处于此状态。 线程在给定的时间点只能处于一种状态。这些状态是虚拟机状态,不反映任何操作系统线程状态。 1)Lock 是一个接口;synchronized 是 Java 中的关键字,synchronized 是内置的语言实现; 2)Lock 在发生异常时,如果没有主动通过 unLock() 去释放锁,很可能会造成死锁现象,因此使用 Lock 时需要在 finally 块中释放锁;synchronized 不需要手动获取锁和释放锁,在发生异常时,会自动释放锁,因此不会导致死锁现象发生; 3)Lock 的使用更加灵活,可以有响应中断、有超时时间等;而 synchronized 却不行,使用 synchronized 时,等待的线程会一直等待下去,直到获取到锁; 4)在性能上,随着近些年 synchronized 的不断优化,Lock 和 synchronized 在性能上已经没有很明显的差距了,所以性能不应该成为我们选择两者的主要原因。官方推荐尽量使用 synchronized,除非 synchronized 无法满足需求时,则可以使用 Lock。 1.作用于非静态方法,锁住的是对象实例(this),每一个对象实例有一个锁。 2.作用于静态方法,锁住的是类的Class对象,因为Class的相关数据存储在永久代元空间,元空间是全局共享的,因此静态方法锁相当于类的一个全局锁,会锁所有调用该方法的线程。 3.作用于 Lock.class,锁住的是 Lock 的Class对象,也是全局只有一个。 4.作用于 this,锁住的是对象实例,每一个对象实例有一个锁。 5.作用于静态成员变量,锁住的是该静态成员变量对象,由于是静态变量,因此全局只有一个。 死锁的四个必要条件: 1)互斥条件:进程对所分配到的资源进行排他性控制,即在一段时间内某资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。 2)请求和保持条件:进程已经获得了至少一个资源,但又对其他资源发出请求,而该资源已被其他进程占有,此时该进程的请求被阻塞,但又对自己获得的资源保持不放。 3)不可剥夺条件:进程已获得的资源在未使用完毕之前,不可被其他进程强行剥夺,只能由自己释放。 4)环路等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。即存在一个处于等待状态的进程集合{Pl, P2, …, pn},其中 Pi 等待的资源被 P(i+1) 占有(i=0, 1, …, n-1),Pn 等待的资源被 P0占 有,如下图所示。 预防死锁的方式就是打破四个必要条件中的任意一个即可。 1)打破互斥条件:在系统里取消互斥。若资源不被一个进程独占使用,那么死锁是肯定不会发生的。但一般来说在所列的四个条件中,“互斥”条件是无法破坏的。因此,在死锁预防里主要是破坏其他几个必要条件,而不去涉及破坏“互斥”条件。。 2)打破请求和保持条件:1)采用资源预先分配策略,即进程运行前申请全部资源,满足则运行,不然就等待。 2)每个进程提出新的资源申请前,必须先释放它先前所占有的资源。 3) Briser la condition inaliénable : Lorsqu'un processus occupe certaines ressources puis postule en outre pour d'autres ressources mais ne peut les satisfaire, le processus doit libérer les ressources qu'il occupait initialement. 4) Brisez la condition d'attente de la boucle : mettez en œuvre une stratégie d'allocation ordonnée des ressources, numérotez uniformément toutes les ressources du système et tous les processus ne peuvent s'appliquer aux ressources que sous la forme de numéros de série croissants. Si nous créons directement un nouveau thread dans la méthode, de nombreux threads seront créés lorsque cette méthode est appelée fréquemment, ce qui non seulement consommera des ressources système, mais réduira également la stabilité du système et fera planter accidentellement le système. vous pouvez vous rendre directement au service financier pour vérifier. Si nous utilisons le pool de threads de manière raisonnable, nous pouvons éviter le dilemme du crash du système. En général, l'utilisation d'un pool de threads peut apporter les avantages suivants : threadFactory : Usine utilisée pour créer des threads de travail. corePoolSize (nombre de threads principaux) : lorsque le pool de threads a moins de threads en cours d'exécution que corePoolSize, un nouveau thread sera créé pour gérer la demande, même si d'autres threads de travail sont inactifs. workQueue (file d'attente) : une file d'attente de blocage utilisée pour conserver les tâches et les transmettre aux threads de travail. maximumPoolSize (nombre maximum de threads) : le nombre maximum de threads autorisés à être ouverts dans le pool de threads. handler (politique de rejet) : Lors de l'ajout d'une tâche au pool de threads, la politique de rejet sera déclenchée dans les deux situations suivantes : 1) L'état d'exécution du pool de threads n'est pas RUNNING 2) Le pool de threads a atteint le nombre maximum de threads et la file d'attente de blocage est pleine. keepAliveTime (durée de conservation) : si le nombre actuel de threads dans le pool de threads dépasse corePoolSize, les threads en excès seront terminés lorsque leur temps d'inactivité dépasse keepAliveTime. AbortPolicy : politique d'abandon. La stratégie de rejet par défaut lève directement RejectedExecutionException. L'appelant peut intercepter cette exception et écrire son propre code de gestion en fonction des besoins. DiscardPolicy : politique de suppression. Ne faites rien et abandonnez simplement la tâche rejetée. DiscardOldestPolicy : supprime la stratégie la plus ancienne. Abandonner la tâche la plus ancienne de la file d'attente de blocage équivaut à exécuter la tâche suivante de la file d'attente, puis à soumettre à nouveau la tâche rejetée. Si la file d'attente bloquante est une file d'attente prioritaire, alors la stratégie « supprimer les plus anciennes » entraînera la suppression des tâches les plus prioritaires, il est donc préférable de ne pas utiliser cette stratégie avec une file d'attente prioritaire. CallerRunsPolicy : politique d'exécution de l'appelant. Exécutez la tâche dans le thread appelant. Cette stratégie implémente un mécanisme d'ajustement qui n'abandonne pas la tâche et ne lève pas d'exception, mais renvoie la tâche à l'appelant (le thread principal qui appelle le pool de threads pour exécuter la tâche). Puisque l'exécution de la tâche prend un certain temps, Ainsi, le thread principal ne peut pas soumettre de tâches pendant au moins un certain temps, ce qui permet au pool de threads de terminer le traitement des tâches en cours d'exécution. List (une bonne aide pour gérer la commande) : L'interface List stocke un ensemble de non-uniques (peut avoir plusieurs éléments référençant le même objet). ), objet commandé. Set (concentrez-vous sur les propriétés uniques) : les ensembles en double ne sont pas autorisés et plusieurs éléments ne feront pas référence au même objet. Map (utilisateurs professionnels qui utilisent Key pour rechercher) : utilisez le stockage par paire clé-valeur. Map conserve les valeurs associées à Key. Deux Keys peuvent faire référence au même objet, mais la Key ne peut pas être répétée. Une Key typique est de type String, mais elle peut également être n'importe quel objet. ArrayList est implémenté sur la base de tableaux dynamiques en bas, et LinkedList est implémenté sur la base de listes chaînées en bas. Pour l'indexation des données par index (méthode get/set) : ArrayList localise directement le nœud à la position correspondante du tableau via index, tandis que LinkedList doit parcourir depuis le nœud principal ou le nœud de queue jusqu'à ce que le nœud cible soit trouvé, donc ArrayList est supérieur en efficacité dans LinkedList. Pour l'insertion et la suppression aléatoires : ArrayList doit déplacer les nœuds derrière le nœud cible (utilisez la méthode System.arraycopy pour déplacer les nœuds), tandis que LinkedList n'a besoin que de modifier les attributs next ou prev des nœuds avant et après la cible. nœud, donc LinkedList est meilleur que LinkedList en termes d'efficacité ArrayList. Pour l'insertion et la suppression séquentielles : étant donné qu'ArrayList n'a pas besoin de déplacer les nœuds, il est meilleur que LinkedList en termes d'efficacité. C'est pourquoi ArrayList est davantage utilisé dans la réalité, car dans la plupart des cas, notre utilisation est une insertion séquentielle. Vector et ArrayList sont presque identiques. La seule différence est que Vector utilise la synchronisation sur la méthode pour garantir la sécurité des threads, donc ArrayList a de meilleures performances en termes de performances. Les relations similaires incluent : StringBuilder et StringBuffer, HashMap et Hashtable. Nous utilisons maintenant le JDK 1.8. La couche inférieure est composée de "tableau + liste chaînée + arbre rouge-noir", comme indiqué ci-dessous. composé d'une composition "tableau" + liste chaînée". Principalement pour améliorer les performances de recherche lorsque les conflits de hachage sont graves (la liste chaînée est trop longue). Les performances de recherche utilisant une liste chaînée sont O(n), tandis que l'utilisation d'un arbre rouge-noir est O(logn). Pour l'insertion, la valeur par défaut est d'utiliser des nœuds de liste chaînée. Lorsque le nombre de nœuds à la même position d'index dépasse 8 (seuil 8) après avoir été ajouté : si la longueur du tableau est supérieure ou égale à 64 à ce moment, cela déclenchera la conversion du nœud de la liste chaînée en rouge-noir nœud d'arbre (treeifyBin) ; et si la longueur du tableau est inférieure à 64, alors la liste chaînée ne sera pas déclenchée pour se convertir en arbre rouge-noir, mais sera étendue car la quantité de données à ce moment est encore relativement petite. Pour la suppression, lorsque le nombre de nœuds à la même position d'index atteint 6 après la suppression et que le nœud à la position d'index est un nœud d'arbre rouge-noir, la conversion du nœud d'arbre rouge-noir en nœud de liste chaînée ( untreeify) sera déclenché. La capacité initiale par défaut est de 16. La capacité de HashMap doit être de 2 à la puissance N. HashMap calculera le plus petit 2 à la puissance N qui est supérieur ou égal à la capacité en fonction de la capacité que nous transmettons. Par exemple, si 9 est transmis, la capacité est 16. HashMap permet à la clé et à la valeur d'être nulles, ce qui n'est pas le cas de Hashtable. La capacité initiale par défaut de HashMap est de 16 et celle de Hashtable est de 11. L'extension de HashMap est 2 fois supérieure à l'original, et l'extension de Hashtable est 2 fois supérieure à l'original plus 1. HashMap n'est pas thread-safe, Hashtable est thread-safe. La valeur de hachage de HashMap a été recalculée et Hashtable utilise directement hashCode. HashMap supprime la méthode contain dans Hashtable. HashMap hérite de la classe AbstractMap, Hashtable hérite de la classe Dictionary. Compteur de programme : Thread privé. Un petit espace mémoire qui peut être considéré comme un indicateur de numéro de ligne du bytecode exécuté par le thread actuel. Si le thread exécute une méthode Java, ce compteur enregistre l'adresse de l'instruction de bytecode de la machine virtuelle en cours d'exécution ; si le thread exécute une méthode native, la valeur du compteur est vide. Pile de machines virtuelles Java : fil de discussion privé. Son cycle de vie est le même que celui d'un fil. La pile de machine virtuelle décrit le modèle de mémoire d'exécution des méthodes Java : lorsque chaque méthode est exécutée, un cadre de pile est créé pour stocker les tables de variables locales, les piles d'opérandes, les liens dynamiques, les sorties de méthode et d'autres informations. Le processus depuis l'appel jusqu'à la fin de l'exécution de chaque méthode correspond au processus allant de l'insertion d'un cadre de pile dans la pile de la machine virtuelle jusqu'à son extraction. Pile de méthodes locales : thread privé. Les fonctions jouées par la pile de méthodes locale et la pile de machines virtuelles sont très similaires. La seule différence entre elles est que la pile de machines virtuelles sert à la machine virtuelle à exécuter des méthodes Java (c'est-à-dire du bytecode), tandis que la pile de méthodes locales est utilisée. par la machine virtuelle. Vers le service de méthode native. Tas Java : partage de fils de discussion. Pour la plupart des applications, le tas Java constitue la plus grande pièce de mémoire gérée par la machine virtuelle Java. Le tas Java est une zone mémoire partagée par tous les threads et est créée au démarrage de la machine virtuelle. Le seul objectif de cette zone mémoire est de stocker des instances d'objet, et presque toutes les instances d'objet y allouent de la mémoire. Zone méthode : Comme le tas Java, il s'agit d'une zone mémoire partagée par chaque thread. Elle est utilisée pour stocker les informations de classe (méthodes de construction, définitions d'interface), les constantes, les variables statiques et le code compilé par le juste-à-temps. compilateur qui ont été chargés par la machine virtuelle (bytecode) et d'autres données. La zone de méthode est un concept défini dans la spécification JVM. Là où elle est placée, différentes implémentations peuvent être placées à différents endroits. 运行时常量池:运行时常量池是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。 上面的语句中变量 str 放在栈上,用 new 创建出来的字符串对象放在堆上,而"hello"这个字面量是放在堆中。 如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。 启动类加载器(Bootstrap ClassLoader): 这个类加载器负责将存放在 扩展类加载器(Extension ClassLoader): 这个加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载 应用程序类加载器(Application ClassLoader): 这个类加载器由sun.misc.Launcher$AppClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。 自定义类加载器: 用户自定义的类加载器。 类加载的过程包括:加载、验证、准备、解析、初始化,其中验证、准备、解析统称为连接。 加载:通过一个类的全限定名来获取定义此类的二进制字节流,在内存中生成一个代表这个类的java.lang.Class对象。 验证:确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。 准备:为静态变量分配内存并设置静态变量初始值,这里所说的初始值“通常情况”下是数据类型的零值。 解析:将常量池内的符号引用替换为直接引用。 初始化:到了初始化阶段,才真正开始执行类中定义的 Java 初始化程序代码。主要是静态变量赋值动作和静态语句块(static{})中的语句。 在什么时候? 在触发GC的时候,具体如下,这里只说常见的 Young GC 和 Full GC。 触发Young GC:当新生代中的 Eden 区没有足够空间进行分配时会触发Young GC。 触发Full GC: 对什么? 对那些JVM认为已经“死掉”的对象。即从GC Root开始搜索,搜索不到的,并且经过一次筛选标记没有复活的对象。 做了什么? 对这些JVM认为已经“死掉”的对象进行垃圾收集,新生代使用复制算法,老年代使用标记-清除和标记-整理算法。 在Java语言中,可作为GC Roots的对象包括下面几种: Mark - Algorithme clair marque d'abord tous les objets qui doivent être recyclés, et une fois le marquage terminé, tous les objets marqués sont recyclés uniformément. Il y a deux inconvénients principaux : l'un est le problème d'efficacité, l'efficacité des processus de marquage et d'effacement n'est pas élevée ; l'autre est le problème d'espace, après le marquage et l'effacement produiront un grand nombre de fragments de mémoire discontinus, trop de fragments d'espace peuvent cause À l'avenir, lorsqu'un objet plus grand doit être alloué pendant l'exécution du programme, une mémoire contiguë suffisante ne peut pas être trouvée et une autre action de garbage collection doit être déclenchée à l'avance. Algorithme de copie Afin de résoudre le problème d'efficacité, un algorithme de collecte appelé "Copie" est apparu, qui divise la mémoire disponible en deux blocs de taille égale en fonction de la capacité, et n'en utilise qu'un à la fois. Lorsque ce bloc de mémoire est épuisé, copiez les objets survivants dans un autre bloc, puis nettoyez immédiatement l'espace mémoire utilisé. De cette façon, la moitié de la zone entière est recyclée à chaque fois, et il n'est pas nécessaire de prendre en compte des situations complexes telles que la fragmentation de la mémoire lors de l'allocation de mémoire. Il suffit de déplacer le pointeur supérieur du tas et d'allouer la mémoire dans l'ordre. efficace à exécuter. C'est juste que le coût de cet algorithme est de réduire la mémoire à la moitié de sa taille d'origine, ce qui est un peu trop élevé. Tag - Algorithme de classement L'algorithme de collecte de copies effectuera davantage d'opérations de copie lorsque le taux de survie des objets est élevé et que l'efficacité deviendra moindre. Plus important encore, si vous ne voulez pas gaspiller 50 % de l'espace, vous devez disposer d'un espace supplémentaire pour la garantie d'allocation pour faire face à la situation extrême où tous les objets de la mémoire utilisée sont vivants à 100 %, donc cette méthode ne peut généralement pas être directement utilisé dans l’algorithme d’ancienne génération. Selon les caractéristiques de l'ancienne génération, quelqu'un a proposé un autre algorithme "Mark-Compact". Le processus de marquage est toujours le même que l'algorithme "Mark-Clear", mais les étapes suivantes ne consistent pas à nettoyer directement les matières recyclables. Au lieu de cela, tous les objets vivants sont déplacés vers une extrémité, puis la mémoire en dehors de la limite d'extrémité est directement effacée. Algorithme de collecte générationnelle Actuellement, les machines virtuelles commerciales utilisent l'algorithme "Generational Collection" (Generational Collection) pour la collecte des ordures. Cet algorithme n'a pas de nouvelles idées. Il divise simplement la mémoire en fonction des différents cycles de vie des objets. quelques dollars. Généralement, le tas Java est divisé en nouvelle génération et ancienne génération, afin que l'algorithme de collecte le plus approprié puisse être utilisé en fonction des caractéristiques de chaque génération. Dans la nouvelle génération, on constate qu'un grand nombre d'objets meurent à chaque fois lors du ramasse-miettes, et seuls quelques-uns survivent. Utilisez ensuite l'algorithme de copie et n'avez besoin de payer que le coût de copie d'un petit nombre d'objets survivants. pour compléter la collection. Dans l'ancienne génération, parce que le taux de survie des objets est élevé et qu'il n'y a pas d'espace supplémentaire pour garantir son allocation, l'algorithme mark-clean ou mark-clean doit être utilisé pour le recyclage. Dans la saison de l'or, du trois et de l'argent, je crois que de nombreux étudiants se préparent à changer d'emploi. J'ai résumé mes récents articles originaux : un résumé original, qui contient une analyse de nombreuses questions d'entretien à haute fréquence, dont beaucoup que j'ai rencontrées lors d'entretiens avec de grandes entreprises. J'analyserai chaque question pour une analyse approfondie basée sur une analyse plus approfondie. standard, vous ne pourrez peut-être pas le comprendre entièrement en le lisant une seule fois, mais je pense que vous gagnerez quelque chose en le lisant encore et encore. Pour plus de connaissances liées à la programmation, veuillez visiter : Cours de programmation ! ! Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!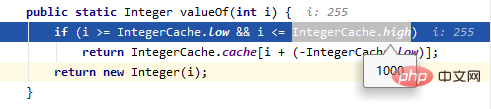
6、&和&&的区别?
7、String 是 Java 基本数据类型吗?
8、String 类可以继承吗?
9、String和StringBuilder、StringBuffer的区别?
10、String s = new String("xyz") 创建了几个字符串对象?
11、String s = "xyz" 和 String s = new String("xyz") 区别?
12、== 和 equals 的区别是什么?
short s1 = 1; long l1 = 1;
// 结果:true。类型不同,但是值相同
System.out.println(s1 == l1);
Integer i1 = new Integer(1);
Integer i2 = new Integer(1);
// 结果:false。通过new创建,在内存中指向两个不同的对象
System.out.println(i1 == i2);
Integer i1 = new Integer(1);
Integer i2 = new Integer(1);
// 结果:true。两个不同的对象,但是具有相同的值
System.out.println(i1.equals(i2));
// Integer的equals重写方法
public boolean equals(Object obj) {
if (obj instanceof Integer) {
// 比较对象中保存的值是否相同
return value == ((Integer)obj).intValue();
}
return false;
}13、两个对象的 hashCode() 相同,则 equals() 也一定为 true,对吗?
14、什么是反射
15、深拷贝和浅拷贝区别是什么?
16、并发和并行有什么区别?
17、构造器是否可被 重写?
18、当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
19、Java 静态变量和成员变量的区别。
public class Demo {
/**
* 静态变量:又称类变量,static修饰
*/
public static String STATIC_VARIABLE = "静态变量";
/**
* 实例变量:又称成员变量,没有static修饰
*/
public String INSTANCE_VARIABLE = "实例变量";
}20、是否可以从一个静态(static)方法内部发出对非静态(non-static)方法的调用?
public class Demo {
public static void staticMethod() {
// 直接调用非静态方法:编译报错
instanceMethod();
}
public void instanceMethod() {
System.out.println("非静态方法");
}
}public class Demo {
public static void staticMethod() {
// 先创建实例对象,再调用非静态方法:成功执行
Demo demo = new Demo();
demo.instanceMethod();
}
public void instanceMethod() {
System.out.println("非静态方法");
}
}21、初始化考察,请指出下面程序的运行结果。
public class InitialTest {
public static void main(String[] args) {
A ab = new B();
ab = new B();
}
}
class A {
static { // 父类静态代码块
System.out.print("A");
}
public A() { // 父类构造器
System.out.print("a");
}
}
class B extends A {
static { // 子类静态代码块
System.out.print("B");
}
public B() { // 子类构造器
System.out.print("b");
}
}22、重载(Overload)和重写(Override)的区别?
23、为什么不能根据返回类型来区分重载?
// 方法1
int test(int a);
// 方法2
long test(int a);
24、抽象类(abstract class)和接口(interface)有什么区别?
25、Error 和 Exception 有什么区别?
26、Java 中的 final 关键字有哪些用法?
public class FinalDemo {
// 不可再修改该变量的值
public static final int FINAL_VARIABLE = 0;
// 不可再修改该变量的引用,但是可以直接修改属性值
public static final User USER = new User();
public static void main(String[] args) {
// 输出:User(id=0, name=null, age=0)
System.out.println(USER);
// 直接修改属性值
USER.setName("test");
// 输出:User(id=0, name=test, age=0)
System.out.println(USER);
}
}27、阐述 final、finally、finalize 的区别。
28、try、catch、finally 考察,请指出下面程序的运行结果。
public class TryDemo {
public static void main(String[] args) {
System.out.println(test());
}
public static int test() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
System.out.print("3");
}
}
}29、try、catch、finally 考察2,请指出下面程序的运行结果。
public class TryDemo {
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
try {
return 2;
} finally {
return 3;
}
}
}30、try、catch、finally 考察3,请指出下面程序的运行结果。
public class TryDemo {
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
int i = 0;
try {
i = 2;
return i;
} finally {
i = 3;
}
}
}
31. Quelles sont les nouvelles fonctionnalités après JDK1.8 ?
32. La différence entre les méthodes wait() et sleep()
33. Quelle est la différence entre la méthode sleep() du thread et la méthode rendement() ?
34. À quoi sert la méthode join() du thread ?
35. Combien existe-t-il de façons d'écrire des programmes multithread ?
36. La différence entre Thread appelant la méthode start() et la méthode run()
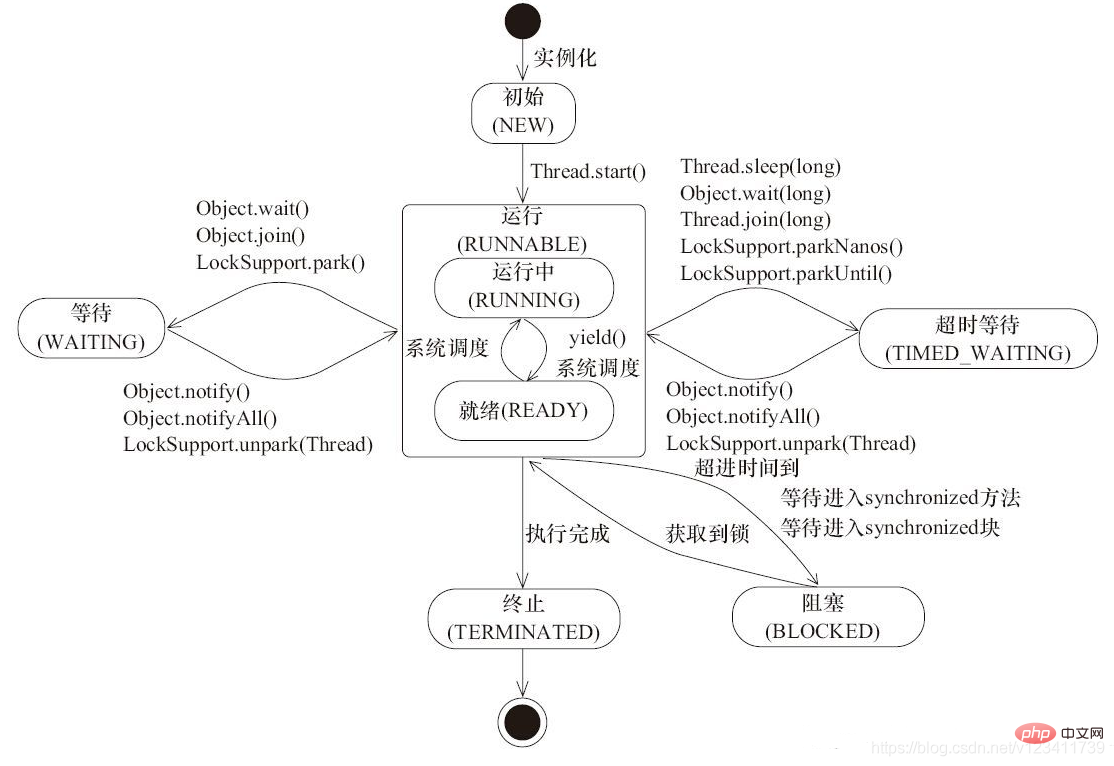
37. Flux d'état du fil de discussion
38、synchronized 和 Lock 的区别
39、synchronized 各种加锁场景的作用范围
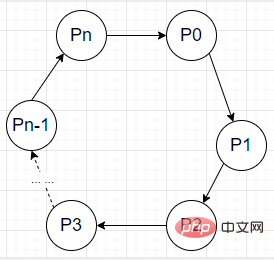
public synchronized void method() {}public static synchronized void method() {}synchronized (Lock.class) {}synchronized (this) {}public static Object monitor = new Object(); synchronized (monitor) {}40、如何检测死锁?
41、怎么预防死锁?
42. Pourquoi utiliser le pool de threads ? N'est-il pas confortable de créer directement un nouveau fil de discussion ?
43. Quels sont les principaux attributs du pool de threads ?
44. Parlons du processus de fonctionnement du pool de threads.

45. Quelles sont les stratégies de rejet pour le pool de threads ?
46. Quelle est la différence entre List, Set et Map ?
47. La différence entre ArrayList et LinkedList.
48. La différence entre ArrayList et Vector.
49. Présentez la structure de données sous-jacente de HashMap
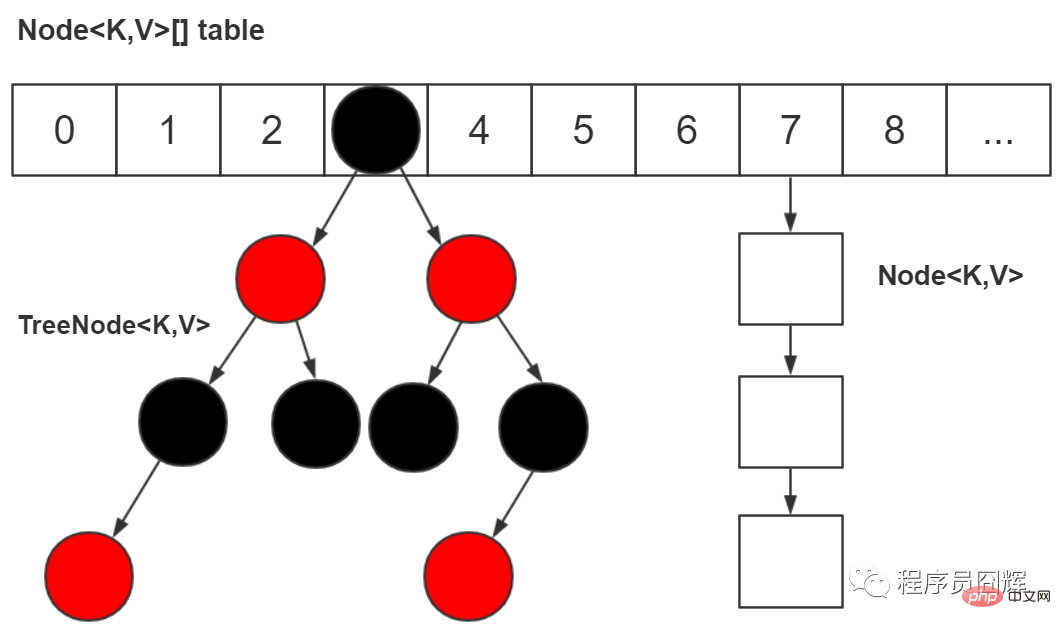
50. Pourquoi devrions-nous le changer en "tableau + liste chaînée + arbre rouge-noir" ?
51. Quand devriez-vous utiliser une liste chaînée ? Quand utiliser les arbres rouge-noir ?
52. Quelle est la capacité initiale par défaut de HashMap ? Y a-t-il une limite à la capacité de HashMap ?
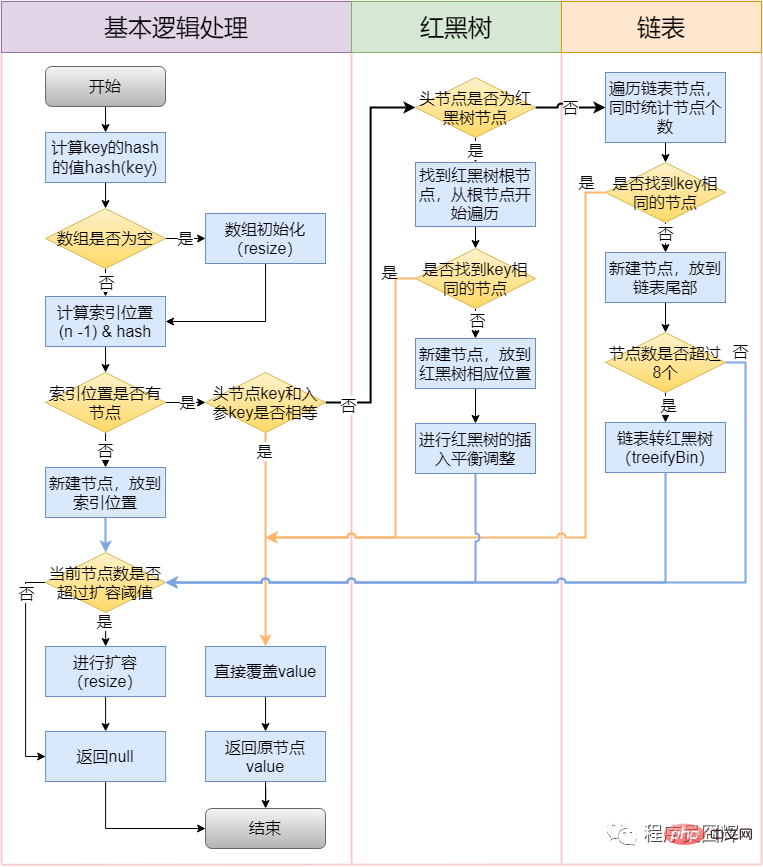
53. Quel est le processus d'insertion de HashMap ?
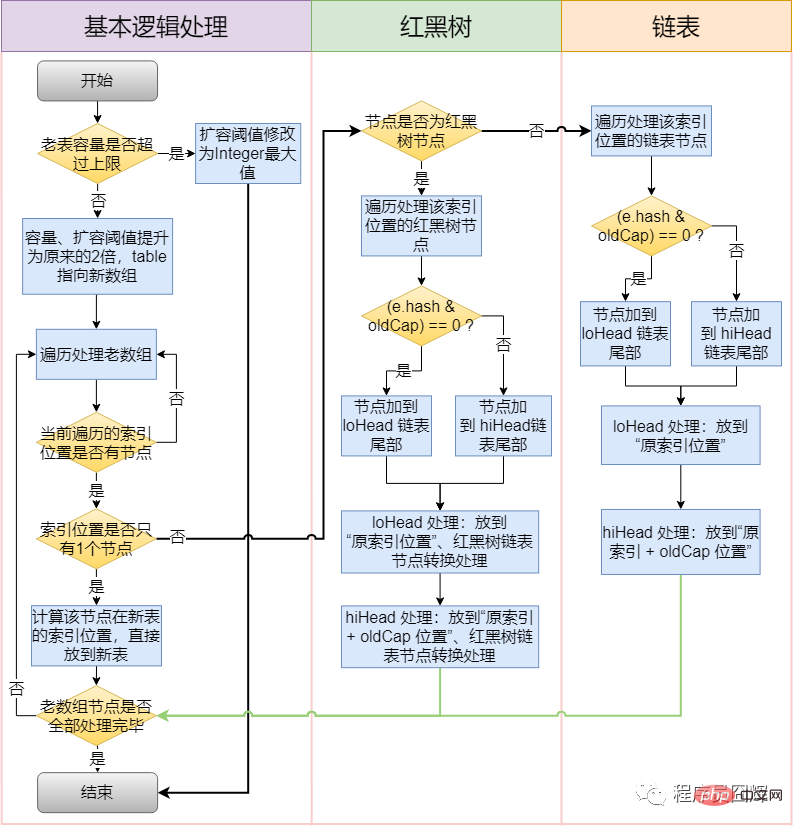
54. Quel est le processus d'expansion (redimensionnement) de HashMap ?
55. En plus de HashMap, quelles autres cartes ont été utilisées, et comment choisir lors de leur utilisation ?

56. La différence entre HashMap et Hashtable ?
57. Structure de la mémoire Java (zone de données d'exécution)
String str = new String("hello");58、什么是双亲委派模型?
59、Java虚拟机中有哪些类加载器?
60、类加载的过程
61、介绍下垃圾收集机制(在什么时候,对什么,做了什么)?
62、GC Root有哪些?
63. Quels sont les algorithmes de garbage collection et leurs caractéristiques respectives ?
Enfin

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Intervieweur : annotations communes et séquence d'exécution de Spring Aop
Aug 15, 2023 pm 04:32 PM
Intervieweur : annotations communes et séquence d'exécution de Spring Aop
Aug 15, 2023 pm 04:32 PM
Vous devez connaître Spring, alors parlons de l'ordre de toutes les notifications d'Aop. Comment Spring Boot ou Spring Boot 2 affecte-t-il l'ordre d'exécution d'aop ? Parlez-nous des pièges que vous avez rencontrés en AOP ?
 Entretien avec un certain groupe : si vous rencontrez un MOO en ligne, comment devez-vous le résoudre ? Comment le résoudre ? Quelles options ?
Aug 23, 2023 pm 02:34 PM
Entretien avec un certain groupe : si vous rencontrez un MOO en ligne, comment devez-vous le résoudre ? Comment le résoudre ? Quelles options ?
Aug 23, 2023 pm 02:34 PM
MOO signifie qu'il existe une vulnérabilité dans le programme, qui peut être causée par la configuration du code ou des paramètres JVM. Cet article explique aux lecteurs comment dépanner lorsqu'un processus Java déclenche le MOO.
 Les questions du test écrit d'Ele.me semblent simples, mais elles déconcertent beaucoup de gens
Aug 24, 2023 pm 03:29 PM
Les questions du test écrit d'Ele.me semblent simples, mais elles déconcertent beaucoup de gens
Aug 24, 2023 pm 03:29 PM
Ne sous-estimez pas les questions d’examen écrit de nombreuses entreprises. Il existe des pièges et vous pouvez y tomber accidentellement. Lorsque vous rencontrez ce genre de question de test écrit sur les cycles, je vous suggère de réfléchir calmement et de procéder étape par étape.
 La semaine dernière, j'ai eu un entretien avec XX Insurance et c'était cool ! ! !
Aug 25, 2023 pm 03:44 PM
La semaine dernière, j'ai eu un entretien avec XX Insurance et c'était cool ! ! !
Aug 25, 2023 pm 03:44 PM
La semaine dernière, un ami du groupe est allé passer un entretien avec Ping An Insurance. Le résultat a été un peu regrettable, ce qui est bien dommage, mais j'espère que vous ne vous découragerez pas, comme vous l'avez dit, essentiellement toutes les questions rencontrées. l'entretien peut être résolu en mémorisant les questions de l'entretien. C'est résolu, alors s'il vous plaît, travaillez dur !
 Les novices peuvent également rivaliser avec les enquêteurs BAT : CAS
Aug 24, 2023 pm 03:09 PM
Les novices peuvent également rivaliser avec les enquêteurs BAT : CAS
Aug 24, 2023 pm 03:09 PM
Le chapitre supplémentaire de la série de programmation simultanée Java, C A S (Comparer et échanger), est toujours dans un style facile à comprendre avec des images et des textes, permettant aux lecteurs d'avoir une conversation folle avec l'intervieweur.
 5 questions d'entretien à cordes, moins de 10 % des personnes peuvent toutes y répondre correctement ! (avec réponse)
Aug 23, 2023 pm 02:49 PM
5 questions d'entretien à cordes, moins de 10 % des personnes peuvent toutes y répondre correctement ! (avec réponse)
Aug 23, 2023 pm 02:49 PM
Cet article examinera 5 questions d'entretien sur la classe Java String. J'ai personnellement rencontré plusieurs de ces cinq questions au cours du processus d'entretien. Cet article vous aidera à comprendre pourquoi les réponses à ces questions sont ainsi.
 Meituan, tu vois si tu peux y répondre ?
Aug 24, 2023 pm 03:51 PM
Meituan, tu vois si tu peux y répondre ?
Aug 24, 2023 pm 03:51 PM
Meituan, tu vois si tu peux y répondre ?
 Il est recommandé de collecter 100 questions d'entretien Linux avec réponses
Aug 23, 2023 pm 02:37 PM
Il est recommandé de collecter 100 questions d'entretien Linux avec réponses
Aug 23, 2023 pm 02:37 PM
Cet article compte au total plus de 30 000 mots, couvrant la présentation de Linux, le disque, le répertoire, le fichier, la sécurité, le niveau de syntaxe, le combat pratique, les commandes de gestion de fichiers, les commandes d'édition de documents, les commandes de gestion de disque, les commandes de communication réseau, les commandes de gestion du système, la sauvegarde. commandes de compression, etc. Démantèlement des points de connaissances Linux.
