

Exemple détaillé de vue de base de données MySQL

Cet article vous apporte des connaissances pertinentes sur mysql, qui organise principalement les problèmes liés aux vues de base de données, y compris l'introduction et le rôle des vues, la création de vues, la modification de vues, la mise à jour de vues et la dénomination et la suppression de vues, les exercices de vues, etc. ., examinons-les ci-dessous, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
1 Introduction et rôle des vues
Introduction aux vues :
- View Une vue est une table virtuelle qui n'existe pas dans la vraie vie. C'est . L'essence est basée sur SQL L'instruction obtient l'ensemble de données dynamiques et le nomme. Lors de son utilisation, les utilisateurs n'ont qu'à utiliser le nom de la vue pour obtenir l'ensemble de résultats et l'utiliser comme table.
- La base de données stocke uniquement la définition de la vue, mais pas les données de la vue. Les données existent toujours dans le tableau de données d'origine. Lorsque vous utilisez une vue pour interroger des données, le système de base de données récupérera les données correspondantes de la table d'origine. Par conséquent, les données de la
- vue dépendent des données de la table d'origine. Lorsque les données du tableau changent, les données de la vue changeront également en conséquence.
- Simplifier le code, Nous pouvons encapsuler les requêtes réutilisées dans des vues pour les réutiliser, et en même temps rendre les requêtes complexes faciles à comprendre ;
- Plus de sécurité, Par exemple, s'il y a beaucoup de données dans un tableau et que beaucoup d'informations ne veulent pas être vues par d'autres, vous pouvez utiliser des vues et utiliser différentes vues pour différents utilisateurs.
La syntaxe de création d'une vue est la suivante :
create [or replace] [algorithm = {undefined | merge | temptable}]
view view_name [(column_list)]
as select_statement
[with [cascaded | local] check option]
Description du paramètre :
- algorithme : représente l'algorithme facultatif de sélection de vue, ;
- view_name : Nom de la vue créée ;
- column_list : Spécifie le nom de chaque attribut dans la vue, qui par défaut est le même que l'attribut interrogé dans l'instruction SELECT ; select_statement : représente une instruction de requête complète pour importer les enregistrements de requête dans la vue ;
- [avec l'option de vérification [cascaded | local]] : signifie que lors de la mise à jour de la vue, assurez-vous que la vue est dans la portée des autorisations. .
- 3 Modification de vueModifier une vue signifie modifier la définition d'une table existante dans la base de données. Lorsque certains champs de la table de base changent,
Format de syntaxe : alter view 视图名 as select语句;
Toutes les vues ne peuvent pas être mises à jour. Les vues peuvent être utilisées dans les instructions UPDATE, DELETE ou INSERT pour mettre à jour le contenu de la table sous-jacente. Pour qu'une vue puisse être mise à jour, il doit y avoir une relation biunivoque entre les lignes de la vue et les lignes de la table sous-jacente.
Une vue ne peut pas être mise à jour si elle contient l'une des structures suivantes :Fonctions d'agrégation (SUM(), MIN(), MAX(), etc.);
- DISTINCT;
- HAVING
- UNION ALL ; ;
- JOIN ;
- Vue non modifiable dans la clause FROM ;
- Sous-requête dans la clause WHERE, table de référence dans la clause FROM ; tables de base à mettre à jour).
Remarque :
- Bien que les données puissent être mises à jour dans la vue, il existe de nombreuses restrictions. En général, il est préférable d'utiliser les vues comme tables virtuelles pour interroger les données plutôt que de mettre à jour les données via les vues.
- Lorsqu'un champ de la vue est modifié dans la table réelle, la vue doit être mise à jour, sinon la vue deviendra une vue invalide !
5 Renommer et supprimer la vue
Renommer la vue : rename table 视图名 to 新视图名;
Supprimer la vue : drop view if exists 视图名;
Si vous souhaitez supprimer plusieurs vues en même temps, utilisez le format de syntaxe suivant :drop view if exists 视图名1, 视图名2, 视图名3...;
6.1 Préparation des données
Lorsque vous faites des exercices, vous pouvez créez d'abord deux tableaux de base pour la pratique :create table college( cno int null, cname varchar(20) null);
create table student( sid int null, name varchar(20) null, gender varchar(20) null, age int null, birth date null, address varchar(20) null, score double null);
两表的基本数据如下图所示:

6.2 查询平均分最高的学校名称
结合之前学过的知识可以 尝试使用子查询和连接查询 来实现,参考代码如下:
SELECT cname FROM (SELECT cname, rank() over (order by avg_score desc ) item FROM (SELECT cname, avg(score) avg_score FROM student JOIN college ON sid = cno GROUP BY cname) t) tt WHERE item = 1;
在上述代码中,先将student 与 college两表关联,将关联的查询作为子表,并根据子表进行平均数的排序,平均数序号为1的平均分数最高,再以此为子表进行子查询,查询出了平均分最高的学校。具体结果如下:
这种方式虽然能够解决问题,但是相对复杂,不容易看懂,为了简化代码,我们可以将每一个子查询创建为一个视图
视图解决方式代码:
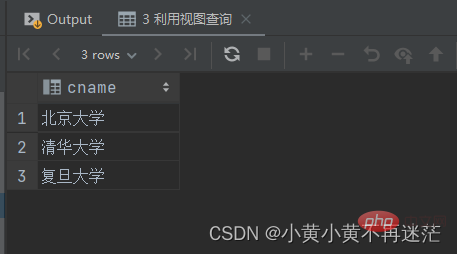
-- 1 视图一,连接两表并计算平均数 CREATE VIEW t_view AS SELECT cname, avg(score) avg_score FROM student JOIN college ON sid = cno GROUP BY cname; -- 2 视图二,利用视图一对平均分数进行排序标号 CREATE VIEW tt_view AS SELECT cname, rank() over (order by avg_score desc ) item FROM (t_view); -- 3 利用视图查询 SELECT cname FROM (tt_view) WHERE item = 1;
在创建完视图后,如果想要查询平均分前三名学校,则方便很多,创建好的视图可以直接使用!
参考代码及结果:
SELECT cnameFROM (tt_view)WHERE item = 1 OR item = 2 OR item = 3;
推荐学习:mysql视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
