
 développement back-end
Tutoriel Python
Explication détaillée de trois méthodes d'analyse des paramètres en Python
développement back-end
Tutoriel Python
Explication détaillée de trois méthodes d'analyse des paramètres en Python
Explication détaillée de trois méthodes d'analyse des paramètres en Python

Cet article vous apporte des connaissances pertinentes sur Python. Il organise principalement les problèmes liés à trois méthodes d'analyse des paramètres. La première option consiste à utiliser argparse, qui est un module Python populaire spécifiquement utilisé pour l'analyse de lignes de commandes. lisez un fichier JSON, où nous pouvons placer tous les hyperparamètres ; la troisième méthode, la moins connue, consiste à utiliser un fichier YAML, jetons-y un coup d'œil, j'espère que cela sera utile à tout le monde.

【Recommandation associée : Tutoriel vidéo Python3】
L'objectif principal de ce que nous partageons aujourd'hui est d'améliorer l'efficacité du code en utilisant la ligne de commande et les fichiers de configuration en Python
C'est parti !
Nous utilisons l'apprentissage automatique Pour pratiquer le processus de réglage des paramètres, vous avez le choix entre trois façons. La première option est d'utiliser argparse, qui est un module Python populaire dédié à l'analyse en ligne de commande ; l'autre est de lire un fichier JSON où l'on peut mettre tous les hyperparamètres ; la troisième est également moins connue. La solution est d'utiliser des fichiers YAML ! Curieux, commençons !
Prérequis
Dans le code ci-dessous, j'utiliserai Visual Studio Code, un environnement de développement Python intégré très efficace. La beauté de cet outil est qu'il prend en charge tous les langages de programmation en installant des extensions, intègre le terminal et permet de travailler avec un grand nombre de scripts Python et de notebooks Jupyter
ensembles de données en même temps, en utilisant l'ensemble de données Shared Bicycle sur Kaggle
en utilisant argparse
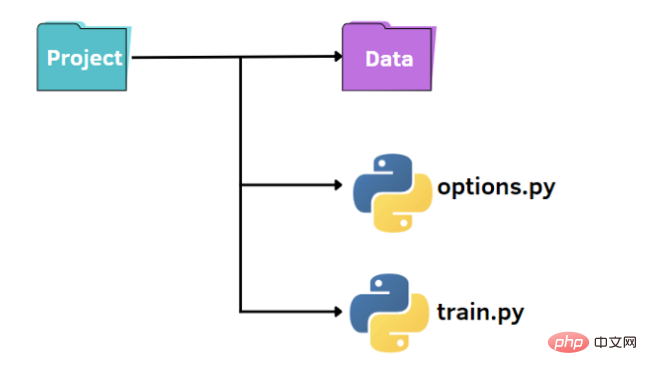
Comme le montre l'image ci-dessus, nous avons une structure standard pour organiser notre petit projet :
- Un dossier nommé data qui contient notre ensemble de données
- fichier train.py
- pour spécifier les hyperparamètres, fichier options.py
Tout d'abord, nous pouvons créer un fichier train.py dans lequel nous avons la procédure de base pour importer les données, entraîner le modèle sur les données d'entraînement et l'évaluer sur l'ensemble de test :
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from options import train_options
df = pd.read_csv('data\hour.csv')
print(df.head())
opt = train_options()
X=df.drop(['instant','dteday','atemp','casual','registered','cnt'],axis=1).values
y =df['cnt'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
if opt.normalize == True:
scaler = StandardScaler()
X = scaler.fit_transform(X)
rf = RandomForestRegressor(n_estimators=opt.n_estimators,max_features=opt.max_features,max_depth=opt.max_depth)
model = rf.fit(X_train,y_train)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_pred, y_test))
mae = mean_absolute_error(y_pred, y_test)
print("rmse: ",rmse)
print("mae: ",mae)Dans le code, nous avons également importé la fonction train_options contenu dans le fichier options.py. Ce dernier fichier est un fichier Python à partir duquel on peut modifier les hyperparamètres considérés dans train.py :
import argparse
def train_options():
parser = argparse.ArgumentParser()
parser.add_argument("--normalize", default=True, type=bool, help='maximum depth')
parser.add_argument("--n_estimators", default=100, type=int, help='number of estimators')
parser.add_argument("--max_features", default=6, type=int, help='maximum of features',)
parser.add_argument("--max_depth", default=5, type=int,help='maximum depth')
opt = parser.parse_args()
return optDans cet exemple, nous utilisons la bibliothèque argparse, très populaire lors de l'analyse des arguments de ligne de commande. Tout d’abord, nous initialisons l’analyseur, puis nous pouvons ajouter les paramètres auxquels nous souhaitons accéder.
Voici un exemple d'exécution de code :
python train.py

Pour modifier les valeurs par défaut des hyperparamètres, il existe deux manières. La première option consiste à définir différentes valeurs par défaut dans le fichier options.py. Une autre option consiste à transmettre la valeur de l'hyperparamètre depuis la ligne de commande :
python train.py --n_estimators 200
Nous devons spécifier le nom de l'hyperparamètre que nous voulons modifier et la valeur correspondante.
python train.py --n_estimators 200 --max_depth 7
Utilisation de fichiers JSON
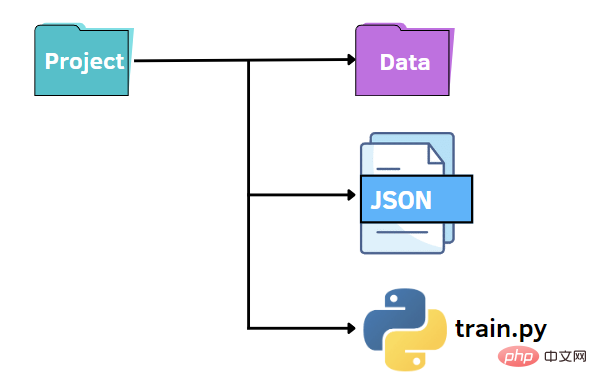
Comme auparavant, nous pouvons conserver une structure de fichiers similaire. Dans ce cas, nous remplaçons le fichier options.py par un fichier JSON. Autrement dit, nous souhaitons préciser les valeurs des hyperparamètres dans un fichier JSON et les transmettre au fichier train.py. Les fichiers JSON peuvent constituer une alternative rapide et intuitive à la bibliothèque argparse, exploitant les paires clé-valeur pour stocker les données. Ensuite, nous créons un fichier options.json qui contient les données que nous devons transmettre ultérieurement à un autre code.
{
"normalize":true,
"n_estimators":100,
"max_features":6,
"max_depth":5
}Comme vous pouvez le voir ci-dessus, il ressemble beaucoup à un dictionnaire Python. Mais contrairement à un dictionnaire, il contient des données au format texte/chaîne. De plus, il existe certains types de données courants avec une syntaxe légèrement différente. Par exemple, les valeurs booléennes sont faux/vrai, alors que Python reconnaît Faux/Vrai. D'autres valeurs possibles dans JSON sont les tableaux, qui sont représentés sous forme de listes Python à l'aide de crochets.
La beauté de travailler avec des données JSON en Python est qu'elles peuvent être converties en dictionnaire Python via la méthode de chargement :
f = open("options.json", "rb")
parameters = json.load(f)Pour accéder à un élément spécifique, il suffit de citer son nom de clé entre crochets :
if parameters["normalize"] == True: scaler = StandardScaler() X = scaler.fit_transform(X) rf=RandomForestRegressor(n_estimators=parameters["n_estimators"],max_features=parameters["max_features"],max_depth=parameters["max_depth"],random_state=42) model = rf.fit(X_train,y_train) y_pred = model.predict(X_test)
Utiliser les fichiers YAML
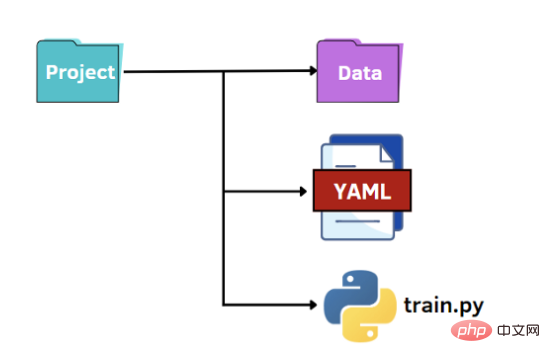
La dernière option est de profiter du potentiel de YAML. Comme pour les fichiers JSON, on lit le fichier YAML en code Python comme un dictionnaire pour accéder aux valeurs des hyperparamètres. YAML est un langage de représentation de données lisible par l'homme dans lequel les hiérarchies sont représentées à l'aide de caractères à double espace au lieu de parenthèses comme dans les fichiers JSON. Ci-dessous, nous montrons ce que contiendra le fichier options.yaml :
normalize: True n_estimators: 100 max_features: 6 max_depth: 5
Dans train.py, nous ouvrons le fichier options.yaml, qui sera toujours converti en dictionnaire Python à l'aide de la méthode de chargement, cette fois importé de la bibliothèque yaml :
import yaml
f = open('options.yaml','rb')
parameters = yaml.load(f, Loader=yaml.FullLoader)Comme précédemment, nous pouvons accéder à la valeur de l'hyperparamètre en utilisant la syntaxe requise pour un dictionnaire.
Réflexions finales
Les profils se compilent très rapidement, alors que argparse nécessite d'écrire une ligne de code pour chaque argument que nous voulons ajouter.
Nous devons donc choisir la manière la plus appropriée en fonction de nos différentes situations
Par exemple, si nous devons ajouter des commentaires aux paramètres, JSON ne convient pas car il n'autorise pas les commentaires, tandis que YAML et argparse peuvent être très adaptés.
【Recommandation associée : Tutoriel vidéo Python3】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python excelle dans l'automatisation, les scripts et la gestion des tâches. 1) Automatisation: La sauvegarde du fichier est réalisée via des bibliothèques standard telles que le système d'exploitation et la fermeture. 2) Écriture de script: utilisez la bibliothèque PSUTIL pour surveiller les ressources système. 3) Gestion des tâches: utilisez la bibliothèque de planification pour planifier les tâches. La facilité d'utilisation de Python et la prise en charge de la bibliothèque riche en font l'outil préféré dans ces domaines.
