

Quelles sont les caractéristiques de base de la technologie web2.0

Caractéristiques de base de la technologie web2.0 : 1. « Plusieurs personnes participant » ; dans le Web1.0, le contenu Internet était personnalisé par quelques éditeurs (ou webmasters), mais dans le Web2.0, tout le monde contribue au contenu qui . 2. « Internet lisible et inscriptible » ; l'Internet dans le Web1.0 est un « Internet lisible », tandis que le Web2.0 est un « Internet lisible et inscriptible ».

L'environnement d'exploitation de ce tutoriel : système Windows 7, ordinateur Dell G3.
Web 2.0 est le nom collectif d'un nouveau type d'applications Internet par rapport au Web 1.0 (le modèle Internet d'avant 2003). Il s'agit d'une révolution du contenu de base vers les applications externes. L'évolution du modèle Web 1.0 consistant à simplement parcourir des pages Web HTML via un navigateur Web au modèle Internet Web 2.0 avec un contenu plus riche, des connexions plus solides et des outils plus puissants est devenue une nouvelle tendance de développement d'Internet. Le Web 2.0 est une incarnation typique du modèle Innovation 2.0 orienté vers l'avenir et axé sur les personnes dans le domaine de l'Internet, provoqué par la révolution des réseaux déclenchée par le développement des technologies de l'information. Il s'agit d'une annotation vivante du processus d'innovation et de démocratisation de la part des professionnels du tissage. le Web à tous les utilisateurs participant au tissage du Web.
Caractéristiques de base de la technologie web2.0
Par rapport au web1.0, le web2.0 présente les caractéristiques suivantes :
1 Participation de plusieurs personnes
Dans le Web1.0, le contenu Internet est édité. par quelques-uns personnalisés par le personnel (ou les webmasters), comme Sohu dans le Web2.0, tout le monde est contributeur de contenu. Le contenu du Web2.0 est plus diversifié : tags, multimédia, collaboration en ligne, etc. Dans le canal d'acquisition d'informations Web2.0, l'abonnement RSS joue un rôle très important.
2. Internet lisible et inscriptible
Dans le Web1.0, Internet est un « Internet en lecture », tandis que le Web2.0 est un « Internet inscriptible et lisible ». Même si tout le monde contribue au flux d’informations, à grande échelle, c’est un petit nombre de personnes qui contribuent à l’essentiel du contenu.
Sept principes du Web 2.0
1. L'Internet en tant que plate-forme
Comme de nombreux concepts importants, le Web 2.0 n'a pas de frontière claire, mais un noyau de gravité. Nous pourrions tout aussi bien considérer le Web 2.0 comme un ensemble de principes et de pratiques dans lesquels les sites Web éloignés ou proches du noyau sont organisés en un système de réseau semblable à celui du système solaire. Ces sites Web incarnent plus ou moins les principes du Web 2.0. On peut dire que le Web 2.0 est une incarnation typique du modèle Innovation 2.0, tourné vers l'avenir et axé sur les personnes, caractérisé par l'innovation ouverte et l'innovation conjointe provoquée par la révolution de l'information provoquée par le développement du domaine Internet. tisser le Web et tous les utilisateurs participent au tissage du Web Un commentaire saisissant sur le processus de démocratisation de l'innovation.
Lors de la première conférence Web 2.0 en octobre 2004, John Battelle et moi avons exposé un ensemble préliminaire de principes dans nos remarques d'ouverture respectives. Le premier de ces principes est « Internet en tant que plateforme ». C'était aussi le cri de guerre de Netscape, le chouchou du Web 1.0, mais Netscape est tombé dans la guerre contre Microsoft. De plus, deux de nos premiers modèles du Web 1.0, DoubleClick et Akamai, ont été des pionniers dans l'utilisation du Web comme plate-forme. Souvent, les gens ne considèrent pas cela comme un service réseau, mais en fait, le service de publicité a été le premier service réseau largement utilisé, et c'était aussi le premier mashup largement utilisé si vous utilisez un autre mot récemment populaire. Chaque bannière publicitaire est conçue pour fonctionner de manière transparente entre les deux sites, offrant une page intégrée aux lecteurs sur un autre ordinateur.
Akamai considère également le réseau comme une plate-forme et, à un niveau plus profond, construit un réseau transparent de mise en cache et de distribution de contenu pour réduire la congestion du haut débit.
Néanmoins, ces pionniers fournissent une comparaison utile, car lorsque les retardataires rencontrent les mêmes problèmes, ils peuvent étendre davantage les solutions des pionniers, et ainsi avoir une compréhension plus profonde de la nature de la nouvelle plateforme. DoubleClick et Akamai sont tous deux pionniers du Web 2.0. Dans le même temps, nous pouvons également constater que davantage d'applications peuvent être réalisées en introduisant davantage de modèles de conception Web 2.0.
2. Tirer parti de l'intelligence collective
Derrière les réussites de ces géants qui sont nés à l'ère du Web 1.0, ont survécu et continuent de diriger l'ère du Web 2.0, il y a un principe fondamental : ils ont tiré parti de l'intelligence collective. puissance du réseau. Venez exploiter l'intelligence collective
- Les hyperliens sont le fondement d'Internet. Lorsque les utilisateurs ajoutent du nouveau contenu et de nouveaux sites Web, ils seront limités à une structure de réseau spécifique où d'autres utilisateurs découvrent le contenu et établissent des liens. Comme les synapses dans le cerveau, les réseaux interconnectés se développeront de manière organique à mesure que les connexions entre eux se renforceront grâce à la réplication et au renforcement, résultat direct de toutes les activités de tous les utilisateurs du réseau.
--Yahoo! a été la première grande success story, née d'un catalogue, ou catalogue de liens, une compilation des meilleurs travaux de dizaines de milliers, voire de millions d'internautes. Bien que Yahoo! se soit ensuite lancé dans la création de contenus variés, son rôle de portail rassemblant les œuvres collectives des internautes reste au cœur de sa valeur.
--La percée de Google en matière de recherche réside dans la technologie PageRank, qui en a rapidement fait le leader incontesté du marché de la recherche. Le PageRank est une méthode qui utilise la structure des liens du réseau, plutôt que d'utiliser simplement les attributs du document, pour obtenir de meilleurs résultats de recherche.
--Le produit d'eBay est l'activité collective de tous ses utilisateurs. Comme le réseau lui-même, eBay se développe de manière organique avec les activités de ses utilisateurs, et le rôle de l'entreprise est de faciliter un environnement spécifique et les actions de ses utilisateurs. se passe dans cet environnement. De plus, l'avantage concurrentiel d'eBay provient presque entièrement de sa masse critique d'acheteurs et de vendeurs, ce qui rend les produits de bon nombre de ses concurrents nettement moins attractifs.
--Amazon vend les mêmes produits que ses concurrents tels que Barnesandnoble.com, et ces sociétés reçoivent les mêmes descriptions de produits, images de couverture et catalogues de la part des vendeurs. La différence est qu’Amazon a créé une science visant à stimuler la participation des utilisateurs. Amazon a des notes d'utilisateurs plus d'un ordre de grandeur supérieures à celles de ses concurrents, plus d'invitations à engager les utilisateurs de diverses manières sur presque chaque page et, plus important encore, ils utilisent l'activité des utilisateurs pour produire de meilleurs résultats de recherche. Les résultats de recherche sur Barnesandnoble.com sont susceptibles de pointer vers les propres produits de l'entreprise ou vers des résultats sponsorisés, tandis qu'Amazon arrive toujours en tête avec ce qu'on appelle « le plus populaire », un calcul en temps réel basé non seulement sur les ventes mais sur un certain nombre d'autres critères. les initiés appellent un facteur entourant le produit « flux ». Avec un engagement des utilisateurs d'un ordre de grandeur supérieur à celui de ses concurrents, il n'est pas surprenant qu'Amazon surpasse ses concurrents.
Maintenant, les entreprises innovantes qui possèdent cette connaissance et peuvent l'étendre laissent leur marque sur Internet.
Wikipédia est une encyclopédie en ligne basée sur un concept apparemment impossible. L'idée est qu'une entrée peut être ajoutée par n'importe quel internaute et modifiée par n'importe qui d'autre. Il s'agit sans aucun doute d'une expérience extrême en matière de confiance, qui met en application la maxime d'Eric Raymond (dérivée du contexte des logiciels open source) : "Avec suffisamment d'attention, tous les défauts du programme seront éliminés". à la création de contenu. Wikipédia figure déjà parmi les 100 meilleurs sites Web au monde, et nombreux sont ceux qui pensent qu’il figurera bientôt parmi les 10 premiers. Il s’agit d’un changement profond dans la création de contenu.
Des sites Web comme del.icio.us (délicieux signets) et Flickr, leurs sociétés ont récemment attiré beaucoup d'attention et sont devenues un concept dans ce que les gens appellent la « folksonomie » (folksonomie), qui est différente de la taxonomie traditionnelle. pionnier. La « classification de focus » est un moyen de classer de manière collaborative des sites Web à l'aide de mots-clés librement sélectionnés par les utilisateurs, et ces mots-clés sont généralement appelés balises. L’étiquetage utilise de multiples associations qui se chevauchent comme celles utilisées par le cerveau lui-même, plutôt que des catégories rigides. Pour donner un exemple classique, sur le site Flickr, une photo d'un chiot peut être étiquetée avec « chiot » et « mignon », permettant au système d'effectuer une recherche d'une manière naturelle qui résulte du comportement de l'utilisateur.
Les produits collaboratifs de filtrage du spam, tels que Cloudmark, regroupent les nombreuses décisions indépendantes que prennent les utilisateurs de messagerie quant à savoir si un e-mail est ou non du spam, surpassant ainsi les systèmes qui reposent sur l'analyse de l'e-mail lui-même.
Il est presque axiome que les grands succès d'Internet ne font pas activement la promotion de leurs produits partout. Ils utilisent le « marketing viral », ce qui signifie que certaines références se propagent directement d'un utilisateur à un autre. Si un site Web ou un produit s'appuie sur la publicité pour sa promotion, vous pouvez presque certainement conclure qu'il ne s'agit pas du Web 2.0.
Même une grande partie de l'infrastructure Internet elle-même, y compris le code Linux, Apache, MySQL et Perl, PHP ou Python utilisé dans la plupart des serveurs Web, repose sur une production homologue open source. Il contient une sagesse collective issue du réseau. Il existe au moins 100 000 projets de logiciels open source répertoriés sur le site Web SourceForge.net. N'importe qui peut ajouter un projet, et n'importe qui peut télécharger et utiliser le code du projet.
Dans le même temps, les nouveaux projets migrent de la périphérie vers le centre du fait des usages des utilisateurs. Un processus d’acceptation organique d’un logiciel repose presque entièrement sur le marketing viral. Dans le même temps, les nouveaux projets migrent de la périphérie vers le centre en raison de l'adoption par les utilisateurs, un processus organique d'adoption de logiciels qui repose presque entièrement sur le marketing viral.
L'expérience est la suivante : l'effet de réseau dérivé des contributions des utilisateurs est la clé pour dominer le marché à l'ère du Web 2.0.
3. Les données sont le prochain Intel Inside
Chaque application Internet importante est désormais pilotée par une base de données spécialisée : le robot d'exploration Web de Google, l'annuaire (et le robot d'exploration Web) de Yahoo!, la base de données de produits d'Amazon, la base de données de produits et de vendeurs d'eBay, la base de données de cartes de MapQuest, la bibliothèque de chansons distribuée de Napster. Comme l'a déclaré Hal Varian lors d'une conversation privée l'année dernière, "SQL est le nouveau HTML". La gestion de bases de données est une compétence essentielle des entreprises du Web 2.0, et son importance est telle que nous appelons parfois ces programmes « infoware » plutôt que simplement logiciel.
Ce fait soulève également une question clé : à qui appartiennent les données ?
À l'ère d'Internet, nous avons peut-être vu des cas où le contrôle des bases de données a conduit à une domination du marché et à d'énormes rendements financiers. Le monopole sur l'enregistrement des noms de domaine initialement accordé par décret du gouvernement américain à Network Solutions (acquis plus tard par Verisign) a été la première vache à lait d'Internet. Même si nous affirmons qu'il deviendra beaucoup plus difficile de générer un avantage commercial en contrôlant les API des logiciels à l'ère d'Internet, il n'en va pas de même pour le contrôle des ressources de données critiques, en particulier lorsque ces ressources de données sont coûteuses à créer ou faciles à proliférer via les effets de réseau. dos.
Faites attention à la déclaration de droit d'auteur sous chaque carte fournie par MapQuest, maps.yahoo.com, maps.msn.com ou maps.google.com. Vous trouverez une ligne comme "Map copyright NavTeq, TeleAtlas", ou si. Si vous utilisez un nouveau service d'imagerie satellite, vous verrez "Image copyright Digital Globe". Ces entreprises ont réalisé des investissements importants dans leurs bases de données. (NavTeq à lui seul a annoncé un investissement de 750 millions de dollars pour créer sa base de données d'adresses postales et d'itinéraires. Digital Globe investit 500 millions de dollars pour lancer ses propres satellites afin d'améliorer les images fournies par le gouvernement.) NavTeq a en fait fait beaucoup d'imitations du système Intel familier d'Intel. Logo intérieur : les voitures équipées d'un système de navigation, par exemple, portent la mention « NavTeq Onboard ». Les données constituent de facto l'Intel Inside pour de nombreux programmes de ce type et constituent le seul composant source d'informations pour certains systèmes dont les logiciels sont pour la plupart open source ou commerciaux.
La concurrence féroce actuelle dans le domaine de la cartographie Web montre que négliger l'importance de posséder les données de base du logiciel finira par affaiblir sa position concurrentielle. MapQuest a été le premier à se lancer dans le domaine de la cartographie en 1995, suivi par Yahoo !, puis Microsoft et, plus récemment, Google a décidé d'entrer sur le marché. Ils peuvent facilement proposer un programme compétitif en octroyant une licence pour les mêmes données.
Cependant, à titre de comparaison, c'est la position concurrentielle d'Amazon.com. Comme des concurrents comme Barnesandnoble.com, sa base de données originale provient du registraire ISBN R. Bowker. Mais contrairement à MapQuest, Amazon a considérablement amélioré ses données, en ajoutant des données fournies par les éditeurs, telles que des images de couverture, des tables des matières, des index et des exemples de documents. Plus important encore, ils ont mis à profit leurs utilisateurs pour annoter les données, de sorte qu'une décennie plus tard, c'est Amazon, et non Bowker, qui est devenu la principale source d'informations bibliographiques, une source de référence pour les universitaires, les bibliothécaires et les consommateurs. Amazon a également introduit son identifiant propriétaire, l'ASIN, qui correspond à un ISBN lorsqu'il existe, et crée un espace de noms équivalent lorsqu'un produit ne possède pas d'ISBN. Amazon « absorbe et développe » ainsi effectivement ses fournisseurs de données.
Imaginez si MapQuest avait fait la même chose, en utilisant ses utilisateurs pour annoter des cartes et des itinéraires, ajoutant ainsi une nouvelle couche de valeur. Cela entraînera alors des difficultés bien plus grandes pour les autres concurrents qui n'entrent sur ce marché qu'en acquérant des licences sur les données de base.
L'introduction récente de Google Maps a constitué un laboratoire vivant pour la concurrence entre les vendeurs d'applications et leurs fournisseurs de données. Le modèle de programmation léger de Google a conduit à l'émergence d'innombrables services à valeur ajoutée qui utilisent l'hybridation des données pour combiner les cartes de Google avec d'autres sources de données accessibles via Internet. Un bon exemple de cet hybride est housingmaps.com de Paul Rademacher, qui combine les cartes Google avec les données de location d'appartements et d'achat de maison de Craigslist pour créer une carte interactive des outils de recherche de logements.
Actuellement, ces hybrides sont pour la plupart des produits expérimentaux innovants mis en œuvre par des programmeurs. Mais des actions sur titres suivront. Et on peut déjà le constater chez au moins une catégorie de développeurs. Google a retiré à Navteq son rôle de fournisseur de sources de données et s'est positionné comme un intermédiaire privilégié. Au cours des prochaines années, nous assisterons à une bataille entre les fournisseurs de données et les éditeurs d'applications, les deux camps réalisant l'importance de certaines catégories de données en tant qu'éléments de base pour la création d'applications Web 2.0.
La course a consisté à disposer de catégories spécifiques de données de base : emplacement, identité, calendrier des événements publics, identité du produit, espace de noms, etc. Dans de nombreux cas, lorsque le coût de création des données est énorme, il peut être possible de tout faire avec une seule source de données, comme le fait Intel Inside. Dans d’autres cas, les gagnants seront les entreprises qui atteignent une masse critique grâce à l’agrégation d’utilisateurs et intègrent les données agrégées dans les services système.
Par exemple, dans le domaine de l’identité, PayPal, One-Click d’Amazon et les systèmes de communication comptant des millions d’utilisateurs peuvent devenir des concurrents légitimes dans la création d’une base de données d’identité à l’échelle du réseau. (D'ailleurs, la récente tentative de Google d'utiliser les numéros de téléphone mobile comme identifiants de compte Gmail pourrait être une étape vers l'emprunt et l'extension du système téléphonique.) Pendant ce temps, des startups comme Sxip explorent la possibilité d'identités fédérées pour rechercher un « système distribué en un clic ». " pour fournir un sous-système d'identité Web 2.0 transparent. Dans le domaine du calendrier, EVDB tente de créer le plus grand calendrier partagé au monde grâce à un système de participation de type wiki. Même si le succès d'une startup ou d'une approche particulière n'est pas encore déterminé, il est clair que les normes et les solutions dans ces domaines transforment effectivement certaines données en « sous-systèmes d'exploitation Internet » fiables et fiables et permettront des applications de nouvelle génération.
Concernant les données, un autre aspect à noter est que les utilisateurs sont préoccupés par leur confidentialité et leurs autorisations sur leurs propres données. Dans de nombreux premiers programmes Web, le droit d’auteur n’était que vaguement appliqué. Amazon, par exemple, revendique la propriété de tout avis soumis sur son site, mais ne fait pas respecter les règles et les utilisateurs peuvent republier le même avis n'importe où ailleurs. Cependant, à mesure que de nombreuses entreprises commencent à réaliser que le contrôle des données peut potentiellement devenir leur principale source d’avantage concurrentiel, nous assisterons à des tentatives plus intenses en faveur de tels contrôles.
Tout comme la croissance des logiciels propriétaires a conduit au mouvement du logiciel libre, au cours de la prochaine décennie, nous verrons la croissance des bases de données propriétaires conduire au mouvement des données libres. Nous pouvons voir des précurseurs de ce contre-mouvement dans des projets de données ouvertes comme Wikipédia, Creative Commons et des projets logiciels comme Greasemonkey (qui permet aux utilisateurs de décider comment les données sont affichées sur leurs ordinateurs).
4. La fin du cycle de publication des logiciels
Comme mentionné ci-dessus dans la comparaison entre Google et Netscape, la caractéristique représentative des logiciels à l'ère d'Internet est qu'ils doivent être fournis en tant que service. Ce fait entraîne de nombreux changements fondamentaux dans les modèles économiques de ces entreprises.
1. Les opérations doivent devenir un cœur de compétitivité. L'expertise de Google ou Yahoo! en matière de développement de produits doit correspondre à une expertise dans les opérations quotidiennes. Le passage du logiciel en tant que produit manufacturé au logiciel en tant que service est si fondamental que le logiciel ne pourra plus faire son travail s'il n'est pas entretenu quotidiennement. Google doit continuellement explorer Internet et mettre à jour son index, filtrer en permanence le spam de liens et d'autres éléments qui affectent ses résultats, répondre de manière continue et dynamique aux dizaines de millions de requêtes asynchrones des utilisateurs et faire correspondre de manière synchrone ces requêtes avec des publicités contextuellement pertinentes.
Il n’est donc pas surprenant que la technologie de gestion du système, de réseau et d’équilibrage de charge de Google soit plus étroitement surveillée que son algorithme de recherche. Le succès de Google dans l'automatisation de ces étapes est un aspect clé de son avantage en termes de coûts par rapport à ses concurrents.
Il n'est pas non plus surprenant que les langages de script comme Perl, Python, PHP et maintenant Ruby jouent un rôle majeur dans les entreprises du Web 2.0. Le premier administrateur réseau de Sun, Hassan Schroeder, a un jour décrit Perl comme « le ruban adhésif d'Internet ». En fait, les langages dynamiques (souvent appelés langages de script et décriés par les ingénieurs logiciels à l'ère des artefacts logiciels) sont les outils préférés des administrateurs système et réseau, ainsi que des développeurs de programmes qui créent des systèmes dynamiques pouvant être fréquemment mis à jour. .
2. Les utilisateurs doivent être traités comme des co-développeurs, ce qui résulte d'une réflexion sur les pratiques de développement open source (même s'il est peu probable que les logiciels concernés soient publiés sous licence open source). La devise open source « publier tôt et publier souvent » a en fait évolué vers un positionnement plus extrême : « la version bêta perpétuelle ». Le produit est développé dans un état ouvert et de nouvelles fonctionnalités sont ajoutées à un rythme mensuel, hebdomadaire ou même quotidien. Gmail, Google Maps, Flickr, del.icio.us et d'autres services similaires resteront probablement en version bêta pendant des années.
Par conséquent, surveiller le comportement des utilisateurs en temps réel pour examiner quelles nouvelles fonctionnalités sont utilisées et comment elles sont utilisées deviendra un autre élément de compétitivité essentiel. Un développeur travaillant pour un grand réseau de services en ligne a commenté : « Nous proposons chaque jour deux ou trois nouvelles fonctionnalités dans certaines parties du site, et si les utilisateurs ne les adoptent pas, nous les supprimons. Je les déploierai sur tout le site." Cal Henderson, le développeur en chef de Flickr, a récemment révélé comment ils déployaient une nouvelle version toutes les demi-heures seulement. Il s’agit évidemment d’un modèle de développement très différent de la méthode traditionnelle. Bien que tous les programmes Web ne soient pas développés de manière extrême comme Flickr, presque tous les programmes Web ont un cycle de développement très différent de celui de n'importe quelle époque de PC ou de client-serveur. Pour cette raison, le magazine ZDnet a conclu que Microsoft ne vaincra pas Google : « Le modèle économique de Microsoft repose sur la mise à niveau de son environnement informatique par chacun tous les deux ou trois ans. Le modèle de Google repose sur le fait que chacun effectue quotidiennement son propre travail dans son environnement informatique. .”
Bien que Microsoft ait démontré une forte capacité à apprendre de la concurrence et, en fin de compte, à faire de son mieux, il ne fait aucun doute que cette fois, la concurrence exige que Microsoft (et par extension tout éditeur de logiciels existant) devienne une entreprise clairement différente. à un niveau plus profond. Les entreprises nées du Web 2.0 bénéficient d'un avantage naturel car elles n'ont pas besoin de s'éloigner des modèles existants (et des modèles économiques et des sources de revenus qui les accompagnent).
5. Modèle de programmation légerUne fois que le concept de services réseau aura pris racine, les grandes entreprises se joindront à la mêlée avec des piles de services réseau complexes. Cette pile de services réseau est conçue pour établir un environnement de programmation plus fiable pour les programmes distribués.
Cependant, tout comme Internet a réussi précisément parce qu'il a renversé de nombreuses théories hypertextes, RSS a remplacé le simple pragmatisme par une conception parfaite et est probablement devenu le service réseau le plus utilisé en raison de sa simplicité, et ces services réseau d'entreprise complexes ne sont pas encore largement répandus. adoption.
De même, les services Web d'Amazon.com se présentent sous deux formes : l'une adhère au formalisme de la pile de services Web SOAP (Simple Object Access Protocol, Simple Object Access Protocol) ; l'autre est simplement fournie en dehors du protocole HTTP. , qui est parfois appelé REST (Representational State Transfer) de manière légère. Alors que les connexions B2B à plus forte valeur commerciale (telles que celles entre Amazon et certains partenaires de vente au détail comme ToysRUs) utilisent la pile SOAP, Amazon rapporte que 95 % de l'utilisation provient de services REST légers.
La même volonté de simplicité se retrouve dans d’autres services web « simples ». Le récent lancement de Google Maps par Google en est un exemple. L'interface simple AJAX (Javascript et XML) de Google Maps a été rapidement déchiffrée par les programmeurs, qui ont ensuite mélangé ses données dans de nouveaux services.
Les services Web liés aux cartes existent depuis un certain temps, tels que les SIG (systèmes d'information géographique) comme ESRI et MapPoint de MapQuest et Microsoft. Mais Google Maps a enthousiasmé le monde par sa simplicité. Alors que les services Web pris en charge par les fournisseurs nécessitaient auparavant des accords formels entre les parties, Google Maps a été mis en œuvre de manière à permettre la capture des données, et les programmeurs ont rapidement découvert des moyens de réutiliser les données de manière créative.
Il y a plusieurs leçons importantes ici :
1. Prise en charge de modèles de programmation légers qui autorisent des systèmes faiblement couplés. La conception complexe des piles de services Web développées par les entreprises est conçue pour permettre une intégration étroite. Bien que cela soit nécessaire dans de nombreux cas, bon nombre des applications les plus importantes peuvent en fait rester faiblement couplées, voire ténues. Le concept du Web 2.0 est complètement différent du concept de l'informatique traditionnelle.
2. Pensez syndication plutôt que coordination. Des services Web simples, tels que les services Web basés sur RSS et REST, sont utilisés pour regrouper les données sortantes, mais ne contrôlent pas ce qui se passe lorsqu'elles atteignent l'autre extrémité de la connexion. Cette idée est fondamentale pour Internet lui-même, reflet du principe dit de bout en bout.
3. Conception de programmabilité et de mixabilité. Comme l'Internet d'origine, les systèmes comme RSS et AJAX ont tous ceci en commun : les barrières à la réutilisation sont très faibles. De nombreux logiciels utiles sont en fait open source, et même si ce n’est pas le cas, il n’existe pas grand-chose en place pour protéger leur propriété intellectuelle. L'option « Afficher la source » des navigateurs Internet permet à de nombreux utilisateurs de copier la page Web de n'importe quel autre utilisateur ; RSS est conçu pour permettre aux utilisateurs de visualiser le contenu dont ils ont besoin lorsqu'ils en ont besoin, plutôt qu'à la demande du fournisseur d'informations le plus performant ; les services sont les plus susceptibles d'adopter de nouvelles orientations auxquelles les créateurs du service n'avaient pas pensé. Le terme « Certains droits réservés », popularisé par l'accord Creative Commons, sert de guide utile par rapport au terme plus général « tous droits réservés ».
6. Le logiciel va au-delà d'un seul appareilUne autre caractéristique du Web 2.0 qui mérite d'être mentionnée est le fait que le Web 2.0 ne se limite plus à la plate-forme PC. Dans son conseil d'adieu à Microsoft, Dave Stutz, développeur de longue date de Microsoft, a noté que "les logiciels utiles écrits qui vont au-delà d'un seul appareil seront plus rentables pendant longtemps". Bien sûr, tout programme réseau peut être considéré comme un logiciel au-delà d'un seul appareil. Après tout, même les programmes Internet les plus simples impliquent au moins deux ordinateurs : l'un est responsable du serveur Web et l'autre est responsable du navigateur. Et, comme nous l'avons déjà évoqué, le développement du réseau en tant que plate-forme étend ce concept aux applications composites composées de services fournis par plusieurs ordinateurs. Mais comme dans de nombreux domaines du Web 2.0, où le « caractère 2.0 » n'est pas entièrement nouveau, mais une réalisation plus complète du véritable potentiel de la plate-forme Internet, le logiciel transcende un seul appareil. Cette déclaration nous donne un aperçu critique de la conception de programmes et services pour la nouvelle plateforme. iTunes est de loin le meilleur exemple de ce principe. Le programme s'étend de manière transparente depuis l'appareil portable jusqu'au vaste backend Internet, où le PC joue le rôle de cache local et de site de contrôle. Il y a eu de nombreuses tentatives pour amener le contenu Internet sur des appareils portables, mais le combo iPod/iTunes a été le premier du genre conçu dès le départ pour fonctionner sur plusieurs appareils. TiVo est un autre bon exemple. iTunes et TiVo incarnent également d'autres principes fondamentaux du Web 2.0. Aucun d’entre eux n’est lui-même un programme réseau, mais ils exploitent tous la puissance de la plate-forme Internet pour faire du réseau une partie transparente et presque imperceptible de leur système. La gestion des données est clairement au cœur de la valeur qu’elles apportent. Ce sont également des services, et non des programmes packagés (même si dans le cas d'iTunes, il peut être utilisé comme programme packagé pour gérer uniquement les données locales de l'utilisateur). De plus, TiVo et iTunes présentent toutes deux certaines applications émergentes de l'intelligence collective. Cependant, pour chaque cas, l'expérience consiste à traiter la même entrée IP du réseau. Il n'existe qu'un système de participation limité sur iTunes, même si l'ajout récent du podcasting a rendu cette règle plus régulière. C'est un domaine du Web 2.0 dans lequel nous espérons voir de grands changements, à mesure que de plus en plus d'appareils sont connectés à cette nouvelle plateforme. Quels programmes pourraient émerger lorsque nos téléphones et nos voitures transmettent des données même s'ils ne les consomment pas ? La surveillance du trafic en temps réel, les flash mobs et les médias citoyens ne sont que quelques signes avant-coureurs de ce dont les nouvelles plateformes sont capables. 7. Expérience utilisateur riche Internet remonte au navigateur Viola développé par Pei Wei en 1992. Internet a été utilisé pour fournir des « applets » et d'autres contenus dans les navigateurs Web. L'introduction de Java en 1995 tournait autour de la livraison de ces petits programmes. JavaScript et plus tard DHTML ont été introduits comme moyens légers de fournir au client une programmabilité et des expériences utilisateur riches. Il y a quelques années, Macromedia a inventé le terme « Rich Internet Applications » (un terme également utilisé par le concurrent open source Laszlo Systems de Flash) pour souligner que Flash pouvait non seulement fournir du contenu multimédia, mais également une expérience d'application de type GUI (Graphical User Interface). Cependant, le potentiel d'Internet pour fournir des applications entières n'est devenu courant que lorsque Google a introduit Gmail, suivi de près par le programme Google Maps, un certain nombre d'applications basées sur Internet avec des interfaces utilisateur riches et une interactivité équivalente aux programmes PC. L'ensemble des technologies utilisées par Google a été nommé AJAX dans un document de séminaire rédigé par Jesse James Garrett de la société de conception Web Adaptive Path. Il a écrit : Ajax n'est pas une technologie. Il s’agit en fait de plusieurs technologies, chacune prospère de manière autonome, combinées de manière nouvelle et puissante. Ajax couvre : -Utilisation de XHTML et CSS pour obtenir un affichage basé sur diverses normes. --Utilisez le modèle objet de document pour obtenir un affichage et une interaction dynamiques. --Utilisez XML et XSLT pour réaliser l'échange et le fonctionnement des données. -- Utilisez XMLHttpRequest pour implémenter la récupération de données asynchrone. -- JavaScript relie tout cela ensemble. AJAX est également un élément clé des programmes Web 2.0 tels que Flickr, désormais propriété de Yahoo !, des programmes 37signals basecamp et backpack, et d'autres programmes Google tels que Gmail et Orkut. Nous entrons dans une période sans précédent d’innovation en matière d’interface utilisateur, car les développeurs Internet peuvent enfin créer des applications Web aussi riches que les applications natives basées sur PC. Ce qui est intéressant, c’est que la plupart des fonctionnalités actuellement explorées existent depuis des années. À la fin des années 1990, Microsoft et Netscape avaient une idée de ce qui était enfin reconnu, mais leurs batailles sur les normes à adopter rendaient difficile la mise en œuvre d'applications multi-navigateurs. L'écriture d'un tel programme n'était possible que lorsque Microsoft gagnait définitivement la guerre des navigateurs et qu'il n'y avait en réalité qu'un seul standard de navigateur à écrire. Dans le même temps, même si Firefox a réintroduit la concurrence sur le marché des navigateurs, du moins pour l'instant, nous n'avons pas assisté à une lutte si destructrice sur les normes Internet qui nous ramènerait aux années 90. Au cours des prochaines années, nous verrons de nombreux nouveaux programmes réseau qui ne sont pas seulement des programmes véritablement nouveaux, mais aussi de riches versions réseau de programmes PC. Jusqu’à présent, chaque changement de plateforme a également créé une opportunité de changer la direction des programmes qui dominaient dans l’ancienne plateforme. Gmail a apporté des innovations intéressantes en matière de courrier électronique, combinant la puissance d'Internet (accès partout, capacités de base de données approfondies, possibilité de recherche) avec une interface utilisateur proche de l'interface PC en termes de facilité d'utilisation. Pendant ce temps, d'autres programmes de messagerie sur la plate-forme PC empiétaient sur le terrain en ajoutant des fonctionnalités de messagerie instantanée et de présence. Où sommes-nous des clients de communications intégrées ? Ces clients de communications intégrés doivent intégrer le courrier électronique, la messagerie instantanée et les téléphones mobiles, et doivent utiliser la VoIP pour ajouter des capacités vocales aux riches fonctionnalités des applications Web. La course a déjà commencé. On voit aussi facilement comment le Web 2.0 peut réinventer le carnet d'adresses. Un carnet d'adresses de style Web 2.0 traiterait le carnet d'adresses local de votre PC ou téléphone comme rien de plus qu'un cache de contacts dont vous avez explicitement demandé au système de se souvenir. Pendant ce temps, un proxy asynchrone de type Gmail basé sur Internet enregistrera chaque message envoyé ou reçu, chaque adresse e-mail et chaque numéro de téléphone utilisé, et créera des algorithmes inspirés des réseaux sociaux pour décider quand une réponse doit être fournie comme alternative. introuvable dans le cache local. En l’absence de réponse, le système interroge le réseau social au sens large. Un programme de traitement de texte Web 2.0 prendra en charge l'édition collaborative de style wiki, plutôt que de simplement traiter des documents autonomes. Mais le programme prendra également en charge le type de formatage riche auquel nous nous attendons dans les traitements de texte sur PC. Writely est un excellent exemple d’un tel programme, même s’il n’a pas encore retenu l’attention du grand public. De plus, la révolution Web 2.0 ne se limitera pas aux programmes PC. Par exemple, dans les applications d'entreprise telles que CRM, Salesforce.com montre comment le réseau peut être utilisé pour fournir des logiciels en tant que service. Pour les nouveaux entrants, l'opportunité compétitive réside dans le développement complet du potentiel du Web 2.0. Les entreprises qui réussissent créeront des programmes qui apprennent de leurs utilisateurs, en tirant parti des systèmes de participation pour créer un avantage décisif non seulement dans l'interface du logiciel mais également dans la richesse des données partagées. Pour plus de connaissances connexes, veuillez visiter la rubrique FAQ !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser python+Flask pour réaliser la mise à jour et l'affichage en temps réel des journaux sur les pages Web
May 17, 2023 am 11:07 AM
Comment utiliser python+Flask pour réaliser la mise à jour et l'affichage en temps réel des journaux sur les pages Web
May 17, 2023 am 11:07 AM
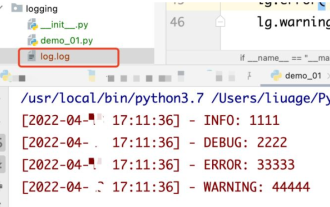
1. Enregistrez la sortie dans un fichier à l'aide du module : la journalisation peut générer des journaux de niveau personnalisé et peut générer des journaux vers un chemin spécifié. Niveau de journalisation : debug (journal de débogage) = 5) {clearTimeout (time) // Si tous sont obtenus 10 fois dans un. les lignes sont vides Tâche planifiée d'effacement du journal}return}if(data.log_type==2){//Si un nouveau journal est obtenu pour(i=0;i
 Comment utiliser le caddy du serveur Web Nginx
May 30, 2023 pm 12:19 PM
Comment utiliser le caddy du serveur Web Nginx
May 30, 2023 pm 12:19 PM
Introduction à Caddy Caddy est un serveur Web puissant et hautement évolutif qui compte actuellement plus de 38 000 étoiles sur Github. Caddy est écrit en langage Go et peut être utilisé pour l'hébergement de ressources statiques et le proxy inverse. Caddy présente les principales caractéristiques suivantes : par rapport à la configuration complexe de Nginx, sa configuration originale de Caddyfile est très simple ; il peut modifier dynamiquement la configuration via l'AdminAPI qu'il fournit, il prend en charge la configuration HTTPS automatisée par défaut et peut demander automatiquement des certificats HTTPS ; et configurez-les ; il peut être étendu aux données Des dizaines de milliers de sites ; peut être exécuté n'importe où sans dépendances supplémentaires écrites en langage Go, la sécurité de la mémoire est plus garantie ; Tout d’abord, nous l’installons directement dans CentO
 Utilisation de Jetty7 pour le traitement du serveur Web dans le développement d'API Java
Jun 18, 2023 am 10:42 AM
Utilisation de Jetty7 pour le traitement du serveur Web dans le développement d'API Java
Jun 18, 2023 am 10:42 AM
Utilisation de Jetty7 pour le traitement du serveur Web dans le développement JavaAPI Avec le développement d'Internet, le serveur Web est devenu l'élément central du développement d'applications et est également au centre de l'attention de nombreuses entreprises. Afin de répondre aux besoins croissants des entreprises, de nombreux développeurs choisissent d'utiliser Jetty pour le développement de serveurs Web, et sa flexibilité et son évolutivité sont largement reconnues. Cet article explique comment utiliser Jetty7 dans le développement JavaAPI pour We
 Protection en temps réel contre les barrages de blocage de visage sur le Web (basée sur l'apprentissage automatique)
Jun 10, 2023 pm 01:03 PM
Protection en temps réel contre les barrages de blocage de visage sur le Web (basée sur l'apprentissage automatique)
Jun 10, 2023 pm 01:03 PM
Le barrage de blocage du visage signifie qu'un grand nombre de barrages flottent sans bloquer la personne dans la vidéo, donnant l'impression qu'ils flottent derrière la personne. L'apprentissage automatique est populaire depuis plusieurs années, mais beaucoup de gens ne savent pas que ces fonctionnalités peuvent également être exécutées dans les navigateurs. Cet article présente le processus d'optimisation pratique des barrages vidéo. À la fin de l'article, il répertorie certains scénarios applicables. cette solution, dans l'espoir de l'ouvrir. mediapipeDemo (https://google.github.io/mediapipe/) montre le principe de mise en œuvre du calcul d'arrière-plan du serveur vidéo de téléchargement à la demande du barrage de blocage de visage grand public pour extraire la zone du portrait dans l'écran vidéo et la convertit en stockage SVG client pendant la lecture de la vidéo. Téléchargez svg depuis le serveur et combinez-le avec barrage, portrait.
 Comment configurer nginx pour garantir que le serveur frps et le port de partage Web 80
Jun 03, 2023 am 08:19 AM
Comment configurer nginx pour garantir que le serveur frps et le port de partage Web 80
Jun 03, 2023 am 08:19 AM
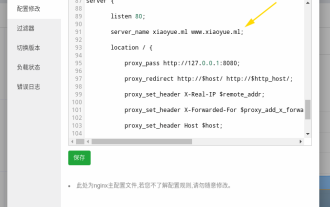
Tout d’abord, vous aurez un doute, qu’est-ce que le frp ? En termes simples, frp est un outil de pénétration intranet. Après avoir configuré le client, vous pouvez accéder à l'intranet via le serveur. Maintenant, mon serveur a utilisé nginx comme site Web et il n'y a qu'un seul port 80. Alors, que dois-je faire si le serveur FRP souhaite également utiliser le port 80 ? Après l'interrogation, cela peut être réalisé en utilisant le proxy inverse de nginx. A ajouter : frps est le serveur, frpc est le client. Étape 1 : Modifiez le fichier de configuration nginx.conf sur le serveur et ajoutez les paramètres suivants à http{} dans nginx.conf, server{listen80
 Comment implémenter la validation de formulaire pour les applications Web à l'aide de Golang
Jun 24, 2023 am 09:08 AM
Comment implémenter la validation de formulaire pour les applications Web à l'aide de Golang
Jun 24, 2023 am 09:08 AM
La validation du formulaire est un maillon très important dans le développement d'applications Web. Elle permet de vérifier la validité des données avant de soumettre les données du formulaire afin d'éviter les failles de sécurité et les erreurs de données dans l'application. La validation de formulaire pour les applications Web peut être facilement implémentée à l'aide de Golang. Cet article explique comment utiliser Golang pour implémenter la validation de formulaire pour les applications Web. 1. Éléments de base de la validation de formulaire Avant de présenter comment implémenter la validation de formulaire, nous devons savoir quels sont les éléments de base de la validation de formulaire. Éléments de formulaire : les éléments de formulaire sont
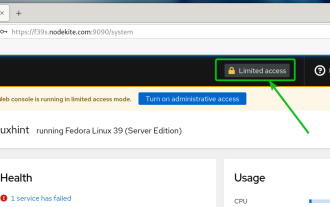 Comment activer l'accès administratif à partir de l'interface utilisateur Web du cockpit
Mar 20, 2024 pm 06:56 PM
Comment activer l'accès administratif à partir de l'interface utilisateur Web du cockpit
Mar 20, 2024 pm 06:56 PM
Cockpit est une interface graphique Web pour les serveurs Linux. Il est principalement destiné à faciliter la gestion des serveurs Linux pour les utilisateurs nouveaux/experts. Dans cet article, nous aborderons les modes d'accès à Cockpit et comment basculer l'accès administratif à Cockpit depuis CockpitWebUI. Sujets de contenu : Modes d'entrée du cockpit Trouver le mode d'accès actuel au cockpit Activer l'accès administratif au cockpit à partir de CockpitWebUI Désactiver l'accès administratif au cockpit à partir de CockpitWebUI Conclusion Modes d'entrée au cockpit Le cockpit dispose de deux modes d'accès : Accès restreint : il s'agit de la valeur par défaut pour le mode d'accès au cockpit. Dans ce mode d'accès vous ne pouvez pas accéder à l'internaute depuis le cockpit
 Que sont les standards du Web ?
Oct 18, 2023 pm 05:24 PM
Que sont les standards du Web ?
Oct 18, 2023 pm 05:24 PM
Les normes Web sont un ensemble de spécifications et de directives développées par le W3C et d'autres organisations associées. Elles incluent la normalisation du HTML, CSS, JavaScript, DOM, l'accessibilité du Web et l'optimisation des performances. En suivant ces normes, la compatibilité des pages peut être améliorée. , maintenabilité et performances. L'objectif des normes Web est de permettre au contenu Web d'être affiché et d'interagir de manière cohérente sur différentes plates-formes, navigateurs et appareils, offrant ainsi une meilleure expérience utilisateur et une meilleure efficacité de développement.