

Comment résoudre le problème de pagination profonde MySQL

Cet article vous apporte des connaissances pertinentes sur mysql. Il présente principalement la solution élégante au problème de pagination profonde mysql. Cet article explique comment optimiser le problème de pagination profonde lorsque la table mysql contient une grande quantité de données et joint le. pseudo-code d'un cas récent d'optimisation de problèmes SQL lents, j'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
Dans le processus quotidien de développement de la demande, je pense que tout le monde sera familier avec limit, mais lors de l'utilisation de limit, lorsque le décalage (offset) est très grand, vous trouverez une requête efficacité De plus en plus lentement. Lorsque la limite est de 2 000 au début, l'interrogation des données requises peut prendre 200 ms. Cependant, lorsque la limite est de 4 000 avec un décalage de 100 000, vous constaterez que son efficacité de requête nécessite déjà environ 1S. de pire en pire.
Résumé
Cet article expliquera comment optimiser le problème de pagination profonde lorsque la table mysql contient une grande quantité de données, et joindra le pseudocode d'un cas récent d'optimisation du problème SQL lent.
1. Limiter la description du problème de pagination profonde
Jetons d'abord un coup d'œil à la structure de la table (donnez simplement un exemple, la structure de la table est incomplète et les champs inutiles ne seront pas affichés)
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
Supposons le SQL de pagination profonde que nous voulons la requête ressemble à ceci
select * from p2p_detail_record ppdr where ppdr .start_time_stamp >1656666798000 limit 0,2000

L'efficacité de la requête est de 94 ms, est-ce rapide ? Donc si nous limitons 100 000 ou 2 000, l'efficacité des requêtes est de 1,5S, ce qui est déjà très lent. Et s'il y en avait plus ?

2. Analyse des causes de la lenteur de sql
Jetons un œil au plan d'exécution de ce sql

Il a également atteint l'index, alors pourquoi est-il toujours lent ? Passons d'abord en revue les points de connaissances pertinents de MySQL.
Index clusterisé et index non cluster
Index clusterisé : Les nœuds feuilles stockent la ligne entière de données.
Index non clusterisé : Le nœud feuille stocke la valeur de clé primaire correspondant à la ligne entière de données.
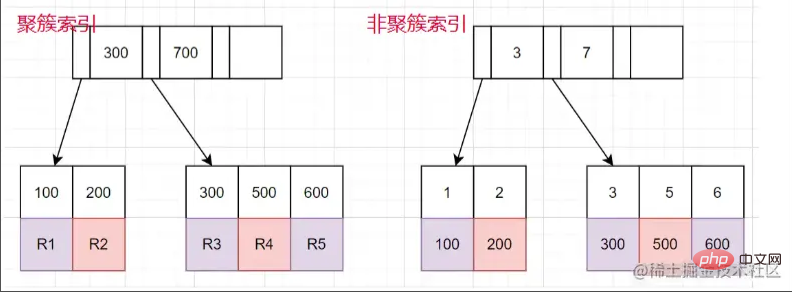
Le processus d'utilisation d'une requête d'index non clusterisé
- Trouvez le nœud feuille correspondant via l'arborescence d'index non clusterisé et obtenez la valeur de la clé primaire.
- Ensuite, récupérez la valeur de la clé primaire et revenez à l'arbre d'index clusterisé pour trouver la ligne entière de données correspondante. (L'ensemble du processus est appelé retour de table)
Retour à la question de savoir pourquoi ce SQL est lent, les raisons sont les suivantes
1 L'instruction limit analysera d'abord les lignes offset+n, puis supprimera les lignes. lignes de décalage précédentes. Après avoir renvoyé n lignes de données. En d'autres termes, limit 100000,10 analysera 100010 lignes, tandis que limit 0,10 analysera uniquement 10 lignes. Ici, nous devons revenir à la table 100010 fois, et beaucoup de temps est consacré au retour de la table. limit 100000,10,就会扫描100010行,而limit 0,10,只扫描10行。这里需要回表100010次,大量的时间都在回表这个上面。
方案核心思路: 能不能事先知道要从哪个主键ID开始,减少回表的次数
常见解决方案
通过子查询优化
select * from p2p_detail_record ppdr where id >= (select id from p2p_detail_record ppdr2 where ppdr2 .start_time_stamp >1656666798000 limit 100000,1) limit 2000
相同的查询结果,也是10W条开始的第2000条,查询效率为200ms,是不是快了不少。
标签记录法
标签记录法: 其实标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。类似书签的作用
select * from p2p_detail_record ppdr where ppdr.id > 'bb9d67ee6eac4cab9909bad7c98f54d4' order by id limit 2000 备注:bb9d67ee6eac4cab9909bad7c98f54d4是上次查询结果的最后一条ID
使用标签记录法,性能都会不错的,因为命中了idIdée de base de la solution :
- Solutions courantes
- Optimiser via des sous-requêtesLa même requête le résultat est également le 2000e à partir d'un article de 100 000 articles, l'efficacité des requêtes est de 200 ms, ce qui est beaucoup plus rapide.
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
Copier après la connexionCopier après la connexionCopier après la connexion
Méthode d'enregistrement des balises- Méthode d'enregistrement des balises : En fait, marquez l'élément que vous avez vérifié la dernière fois. Lorsque vous vérifierez à nouveau la prochaine fois, lancez la numérisation à partir de cet élément. Similaire à la fonction des signets
//最小ID
String lastId = null;
//一页的条数
Integer pageSize = 2000;
List<P2pRecordVo> list ;
do{
list = listP2pRecordByPage(lastId,pageSize); //标签记录法,记录上次查询过的Id
lastId = list.get(list.size()-1).getId(); //获取上一次查询数据最后的ID,用于记录
//对数据的操作逻辑
XXXXX();
}while(isNotEmpty(list));
<select id ="listP2pRecordByPage">
select *
from p2p_detail_record ppdr where 1=1
<if test = "lastId != null">
and ppdr.id > #{lastId}
</if>
order by id asc
limit #{pageSize}
</select>id est atteint. Mais cette méthode présente plusieurs inconvénients. 1. Vous ne pouvez interroger que sur des pages consécutives, pas sur plusieurs pages. 2. Un champ similaire à auto-incrémentation continue est nécessaire (orber par identifiant peut être utilisé).
- Comparaison des solutions Utilisation de la méthode
Avantages : Une requête multipage est possible et vous pouvez vérifier les données sur la page de votre choix.
🎜Inconvénients : 🎜 Pas aussi efficace que la 🎜méthode d'enregistrement par tag🎜. 🎜Raison :🎜 Par exemple, après avoir vérifié 100 000 éléments de données, vous devez également d'abord interroger le 1 000e élément de données correspondant à l'index non clusterisé, puis obtenir l'ID à partir du 100 000e élément pour la requête. 🎜🎜🎜Utilisation de la 🎜méthode d'enregistrement des tags🎜🎜🎜🎜🎜Avantages : 🎜 L'efficacité des requêtes est très stable et très rapide. 🎜🎜🎜Inconvénients :🎜🎜- 不跨页查询,
- 需要一种类似连续自增的字段
关于第二点的说明: 该点一般都好解决,可使用任意不重复的字段进行排序即可。若使用可能重复的字段进行排序的字段,由于mysql对于相同值的字段排序是无序,导致如果正好在分页时,上下页中可能存在相同的数据。
实战案例
需求: 需要查询查询某一时间段的数据量,假设有几十万的数据量需要查询出来,进行某些操作。
需求分析 1、分批查询(分页查询),设计深分页问题,导致效率较慢。
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
伪代码实现:
//最小ID
String lastId = null;
//一页的条数
Integer pageSize = 2000;
List<P2pRecordVo> list ;
do{
list = listP2pRecordByPage(lastId,pageSize); //标签记录法,记录上次查询过的Id
lastId = list.get(list.size()-1).getId(); //获取上一次查询数据最后的ID,用于记录
//对数据的操作逻辑
XXXXX();
}while(isNotEmpty(list));
<select id ="listP2pRecordByPage">
select *
from p2p_detail_record ppdr where 1=1
<if test = "lastId != null">
and ppdr.id > #{lastId}
</if>
order by id asc
limit #{pageSize}
</select>这里有个小优化点: 可能有的人会先对所有数据排序一遍,拿到最小ID,但是这样对所有数据排序,然后去min(id),耗时也蛮长的,其实第一次查询,可不带lastId进行查询,查询结果也是一样。速度更快。
总结
1、当业务需要从表中查出大数据量时,而又项目架构没上ES时,可考虑使用标签记录法的方式,对查询效率进行优化。
2、从需求上也应该尽可能避免,在大数据量的情况下,分页查询最后一页的功能。或者限制成只能一页一页往后划的场景。
推荐学习:mysql视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
