
 développement back-end
Tutoriel Python
Le robot d'exploration Python explore les données des pages Web et analyse les données
développement back-end
Tutoriel Python
Le robot d'exploration Python explore les données des pages Web et analyse les données
Le robot d'exploration Python explore les données des pages Web et analyse les données

Cet article vous apporte des connaissances pertinentes sur Python Il présente principalement comment les robots d'exploration Python explorent les données des pages Web et analysent les données pour vous aider à mieux utiliser les robots pour analyser les pages Web. J'espère que ce sera le cas. utile à tout le monde.

【Recommandation associée : Tutoriel vidéo Python3】
1. Le concept de base du robot d'exploration Web
Le robot d'exploration Web (également connu sous le nom d'araignée Web, robot) est de simuler le client pour envoyer des requêtes réseau et recevoir des réponses aux demandes , un programme qui capture automatiquement les informations Internet selon certaines règles.
Tant que le navigateur peut faire n'importe quoi, en principe, le robot d'exploration peut le faire.
2. Fonctions des robots d'exploration Web
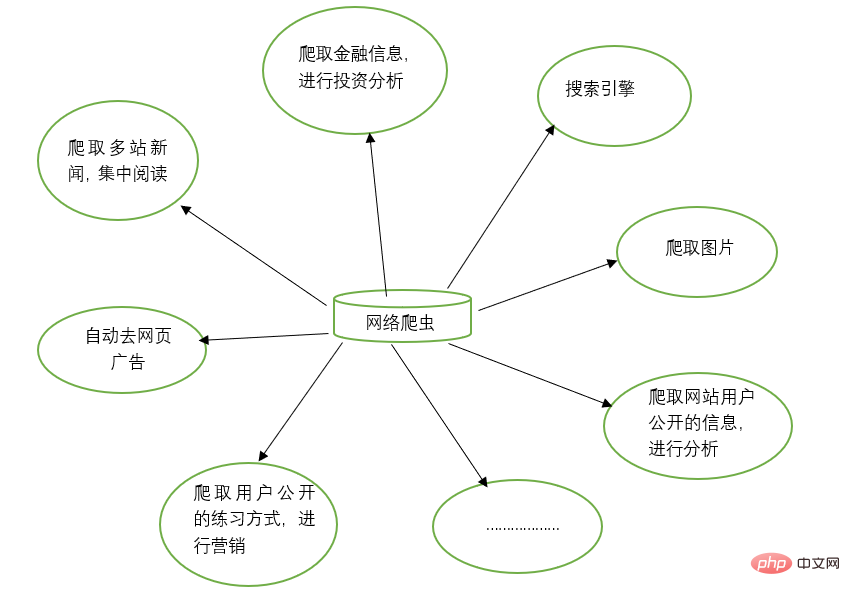
Les robots d'exploration Web peuvent remplacer le travail manuel dans de nombreuses tâches, telles que les moteurs de recherche et l'exploration d'images sur des sites Web. Par exemple, certains amis vont explorer et parcourir toutes les images. Dans le même temps, les robots d'exploration Web peuvent également être utilisés dans le domaine des investissements financiers. Par exemple, ils peuvent explorer automatiquement certaines informations financières et effectuer des analyses d'investissement.
Parfois, nous pouvons avoir plusieurs sites d'actualités préférés, et il est difficile d'ouvrir ces sites d'actualités séparément à chaque fois pour les parcourir. À ce stade, vous pouvez utiliser un robot d'exploration Web pour explorer les informations d'actualité de ces multiples sites Web d'actualités et les lire ensemble.
Parfois, lorsque nous parcourons des informations sur le Web, nous trouvons de nombreuses publicités. À ce stade, vous pouvez également utiliser un robot pour explorer les informations sur la page Web correspondante, afin que ces publicités puissent être automatiquement filtrées pour faciliter la lecture et l'utilisation des informations.
Parfois, nous devons faire du marketing, alors comment trouver des clients cibles et leurs coordonnées est une question clé. Nous pouvons effectuer une recherche manuelle sur Internet, mais cela sera très inefficace. À l'heure actuelle, nous pouvons utiliser des robots d'exploration pour définir des règles correspondantes et collecter automatiquement les informations de contact des utilisateurs cibles et d'autres données sur Internet à des fins marketing.
Parfois, nous souhaitons analyser les informations utilisateur d'un certain site Web, comme l'analyse de l'activité de l'utilisateur, le nombre de commentaires, les articles populaires et d'autres informations du site Web. Si nous ne sommes pas l'administrateur du site Web, les statistiques manuelles seront très utiles. énorme projet. À l'heure actuelle, les robots d'exploration peuvent être utilisés pour collecter facilement ces données pour une analyse plus approfondie. Toutes les opérations d'exploration sont effectuées automatiquement. Il suffit d'écrire le robot d'exploration correspondant et de concevoir les règles correspondantes.
De plus, les robots d'exploration peuvent également réaliser de nombreuses fonctions puissantes. En bref, l'émergence des robots d'exploration peut remplacer dans une certaine mesure l'accès manuel aux pages Web. Par conséquent, les opérations qui nécessitaient auparavant un accès manuel aux informations Internet peuvent désormais être automatisées à l'aide de robots d'exploration, afin que les informations efficaces sur Internet puissent être utilisées plus efficacement. .
3. Installer des bibliothèques tierces
Avant d'explorer et d'analyser les données, vous devez télécharger et installer les requêtes de bibliothèques tierces dans l'environnement d'exécution Python.
Dans le système Windows, ouvrez l'interface cmd (invite de commande), saisissez les demandes d'installation pip dans l'interface et appuyez sur Entrée pour installer. (Faites attention à la connexion réseau) Comme indiqué ci-dessous
L'installation est terminée, comme indiqué sur l'image
4 Explorez la page d'accueil de Taobao
# 请求库
import requests
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.textLes résultats en cours d'exécution sont tels qu'indiqués dans le. image
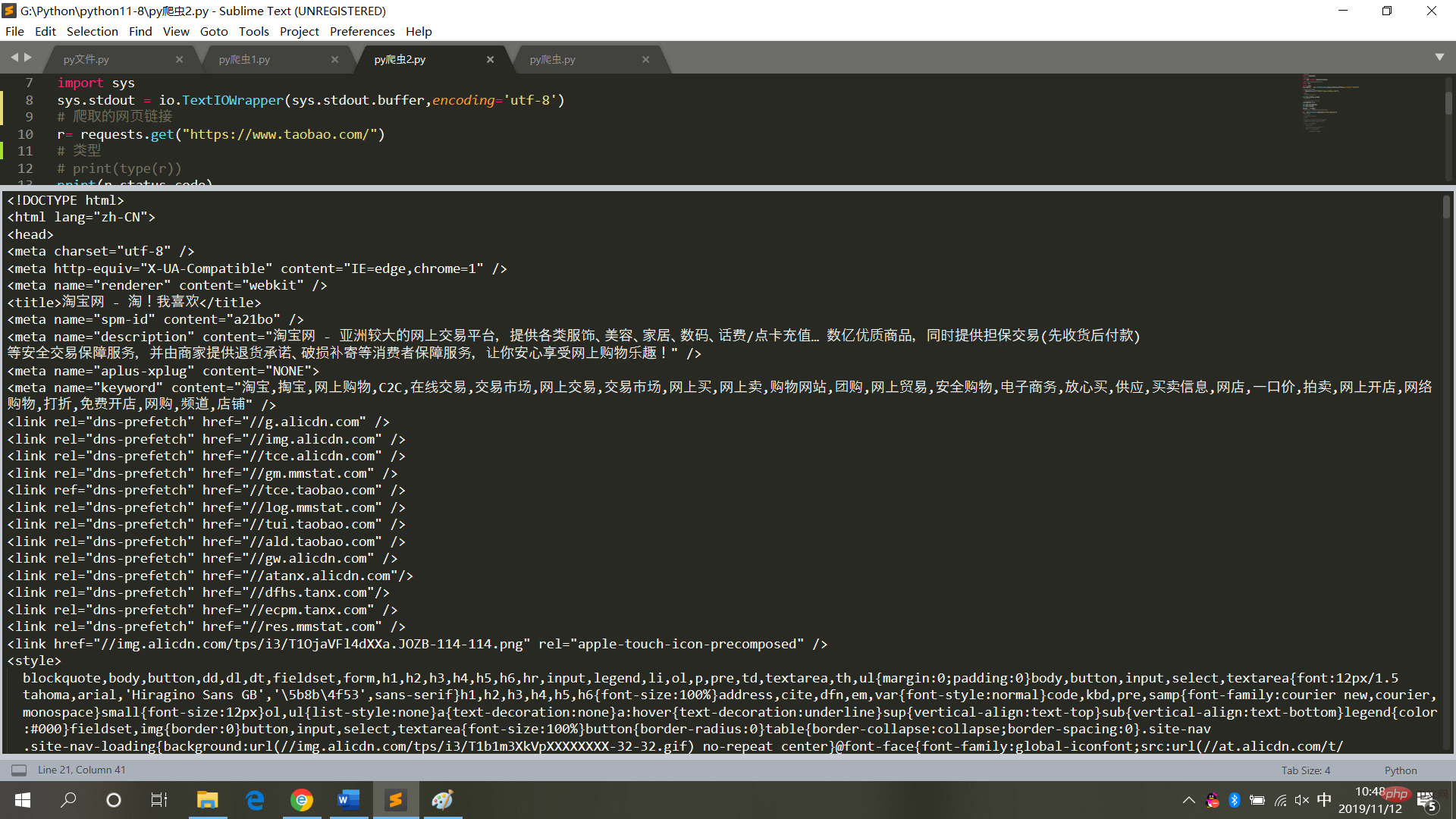
5. Explorer et analyser Les résultats d'exécution de la page d'accueil de Taobao
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
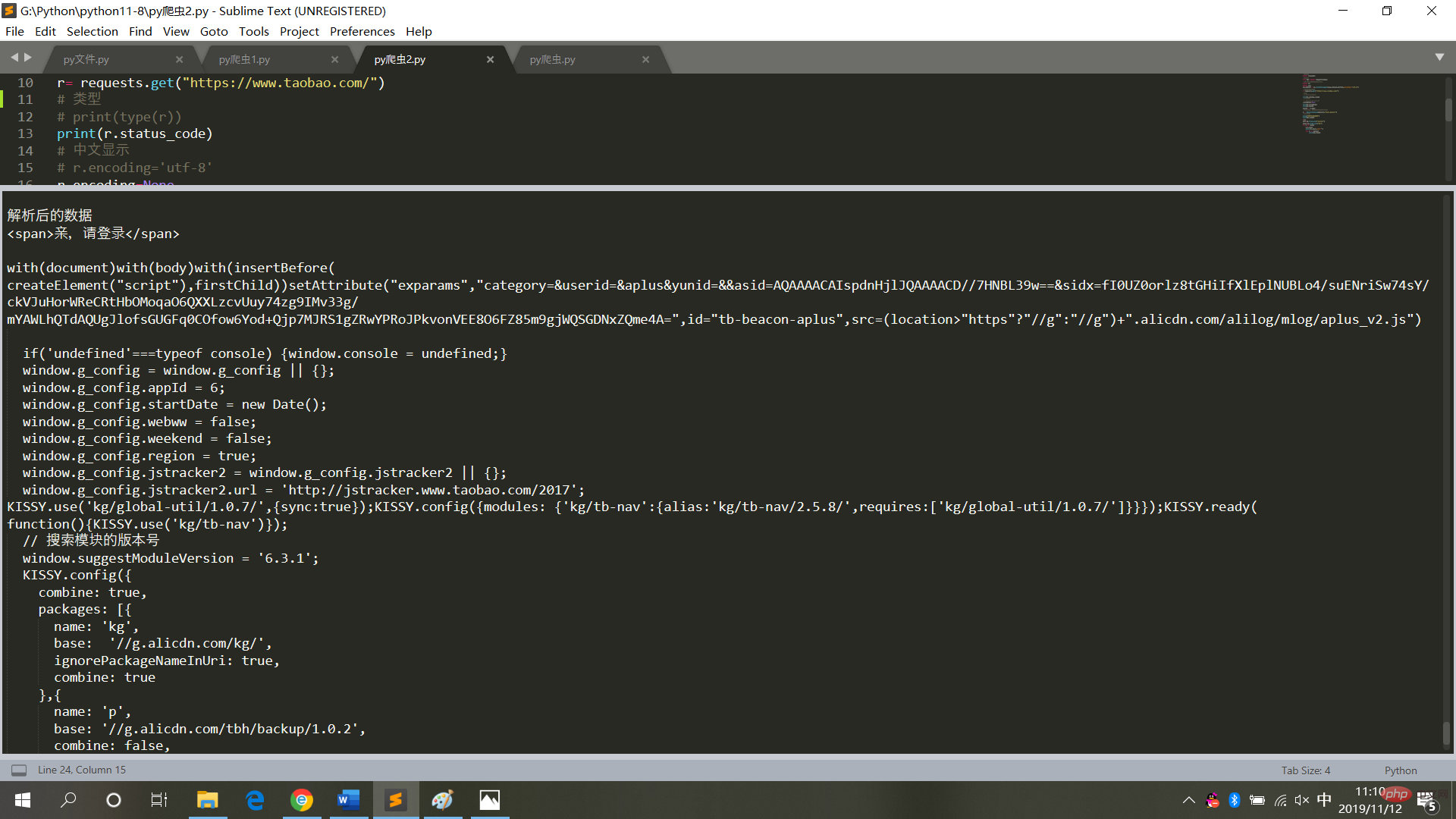
print("解析后的数据")
print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('td')
# 循环打印输出
for i in data:
a=i.text
print(i.text,end='')
for j in data1:
print(j.text)sont comme indiqué dans la figure
6. Résumé
Lors de l'exploration du code de la page Web, n'utilisez pas le fréquemment, et encore moins le définir en mode boucle infinie (à chaque fois, l'exploration fait référence à l'accès à des pages Web. Des opérations fréquentes entraîneront un crash du système et la responsabilité légale sera engagée).
Ainsi, après avoir obtenu les données de la page Web, enregistrez-les en mode texte local, puis analysez-les (plus besoin d'accéder à la page Web).
【Recommandation associée : Tutoriel vidéo Python3】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
De nombreux développeurs de sites Web sont confrontés au problème de l'intégration de Node.js ou des services Python sous l'architecture de lampe: la lampe existante (Linux Apache MySQL PHP) a besoin d'un site Web ...
 Quelle est la raison pour laquelle les fichiers de stockage persistants de pipeline ne peuvent pas être écrits lors de l'utilisation du robot Scapy?
Apr 01, 2025 pm 04:03 PM
Quelle est la raison pour laquelle les fichiers de stockage persistants de pipeline ne peuvent pas être écrits lors de l'utilisation du robot Scapy?
Apr 01, 2025 pm 04:03 PM
Lorsque vous utilisez Scapy Crawler, la raison pour laquelle les fichiers de stockage persistants ne peuvent pas être écrits? Discussion Lorsque vous apprenez à utiliser Scapy Crawler pour les robots de données, vous rencontrez souvent un ...
 Quelle est la raison pour laquelle le pool de processus Python gère les demandes TCP simultanées et fait coincé le client?
Apr 01, 2025 pm 04:09 PM
Quelle est la raison pour laquelle le pool de processus Python gère les demandes TCP simultanées et fait coincé le client?
Apr 01, 2025 pm 04:09 PM
Python Process Pool gère les demandes TCP simultanées qui font coincé le client. Lorsque vous utilisez Python pour la programmation réseau, il est crucial de gérer efficacement les demandes TCP simultanées. ...
 Comment afficher les fonctions originales encapsulées en interne par Python Functools.Partial Objet?
Apr 01, 2025 pm 04:15 PM
Comment afficher les fonctions originales encapsulées en interne par Python Functools.Partial Objet?
Apr 01, 2025 pm 04:15 PM
Explorez profondément la méthode de visualisation de Python Functools.Partial Objet dans Functools.Partial en utilisant Python ...
 Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Solution aux problèmes d'autorisation Lors de la visualisation de la version Python dans Linux Terminal Lorsque vous essayez d'afficher la version Python dans Linux Terminal, entrez Python ...
 Python multiplateform de bureau de bureau de bureau: quelle bibliothèque GUI est la meilleure pour vous?
Apr 01, 2025 pm 05:24 PM
Python multiplateform de bureau de bureau de bureau: quelle bibliothèque GUI est la meilleure pour vous?
Apr 01, 2025 pm 05:24 PM
Choix de la bibliothèque de développement d'applications de bureau multiplateforme Python De nombreux développeurs Python souhaitent développer des applications de bureau pouvant s'exécuter sur Windows et Linux Systems ...
 Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
Précision avec Python: Source de sablier Dessin graphique et vérification d'entrée Cet article résoudra le problème de définition variable rencontré par un novice Python dans le programme de dessin graphique de sablier. Code...
 Comment compter et trier efficacement de grands ensembles de données de produit dans Python?
Apr 01, 2025 pm 08:03 PM
Comment compter et trier efficacement de grands ensembles de données de produit dans Python?
Apr 01, 2025 pm 08:03 PM
Conversion et statistiques de données: traitement efficace des grands ensembles de données Cet article introduira en détail comment convertir une liste de données contenant des informations sur le produit en une autre contenant ...
