

Cet article vous apporte des connaissances pertinentes sur Python. Il présente en détail comment utiliser le langage Python pour réaliser des fonctions de téléchargement automatique d'e-mails et d'analyse des pièces jointes. L'exemple de code dans l'article est expliqué en détail. J'espère que cela sera utile à tout le monde.

[Recommandation associée : Tutoriel vidéo Python3 ]
Avant de commencer à coder, comprenons d'abord les trois protocoles du service de messagerie :
1. Protocole SMTP
SMTP (Simple Mail Transfer Protocol), le Protocole de transfert de courrier simple. Elle équivaut à une station de transfert et envoie des emails au client.
2. Protocole POP3
POP3 (Post Office Protocol 3), la troisième version du protocole du bureau de poste, est la première norme de protocole hors ligne pour le courrier électronique. Ce protocole télécharge les e-mails sur l'ordinateur local et ne se synchronise pas avec le serveur. L'inconvénient est qu'il est plus susceptible de perdre des e-mails ou de télécharger les mêmes e-mails plusieurs fois.
3. Protocole IMAP
IMAP (Internet Mail Access Protocol), qui est le protocole d'accès au courrier interactif. Ce protocole se connecte aux boîtes aux lettres distantes pour un fonctionnement direct et synchronise le contenu avec le serveur.
Présentons ensuite le package de messagerie
Le composant central de ce package est le « modèle objet » qui représente les messages électroniques. Les applications interagissent avec ce package principalement via l'interface de modèle objet définie dans le sous-module de message. Les applications peuvent utiliser cette API pour poser des questions sur les e-mails existants, créer de nouveaux e-mails ou ajouter ou supprimer des sous-composants d'e-mail qui utilisent eux-mêmes la même interface de modèle objet. Autrement dit, selon la nature des messages électroniques et de leurs sous-composants MIME, le modèle objet de courrier électronique est une structure arborescente de tous les objets qui fournissent l'API EmailMessage.
Ensuite, nous utilisons un code spécifique pour implémenter les fonctions de connexion au client de messagerie, de téléchargement d'e-mails et d'analyse du contenu des pièces jointes aux e-mails.
Nous devons d'abord définir une classe d'analyse d'e-mail, qui nécessite trois variables :
1. L'adresse du service imap à laquelle appartient l'e-mail ;
3. nécessitent une politique de sécurité différente, par exemple, la boîte aux lettres qq nécessite une vérification par SMS et obtient le code d'autorisation de connexion au lieu du mot de passe en texte brut pour se connecter au client distant】
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
# imap服务地址
self.remote_server_url = remote_server_url
# 邮箱账号
self.email_url = email_url
# 邮箱密码
self.password = passwordDéfinissez ensuite la fonction d'entrée dans la classe, connectez-vous au client distant , et recevez tous les e-mails sur la première page par défaut. Nous récupérons le sujet de l'e-mail et l'imprimons [L'encodage des différents sujets d'e-mail peut être différent, et le binaire doit être transcodé pour s'afficher correctement]
def main_parse_Email(self):
"""入口函数,登录imap服务"""
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
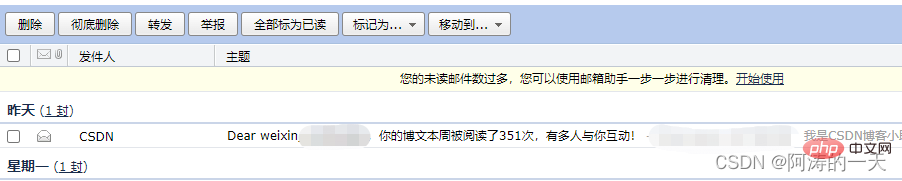
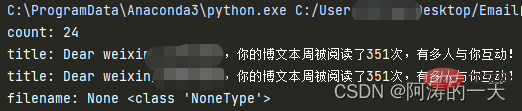
print("count:",mail_counts)
# 邮件的遍历是按时间从后往前,这里我们选择最新的一封邮件
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
#获取邮件主题title
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)Parmi elles, la variable msg enregistre le corps de l'e-mail, car msg et tilt seront réutilisés, nous construirons une fonction de classe pour renvoyer msg et title.
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return titleLors de l'analyse de l'e-mail, nous le divisons en deux parties, le corps de l'e-mail [HTML] et la pièce jointe [xlsx, etc.]. S'il y a une pièce jointe, nous la sauvegarderons dans un chemin fixe. L'analyse de la table ne sera pas décrite en détail. Des packages tels que pandas suffisent pour la gérer.
def get_att(msg):
"""获取附件并下载"""
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
passPour le contenu du corps de l'e-mail, nous analysons directement le code HTML et enregistrons le contenu du texte directement dans un fichier .txt pour une lecture facile.
def get_text_from_HTML(msg):
"""获取邮件中的html"""
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return resultLe code complet est le suivant :
import email
import imaplib
from email.header import decode_header
import pandas as pd
import datetime
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
self.remote_server_url = remote_server_url
self.email_url = email_url
self.password = password
def get_att(msg):
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
pass
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return title
def get_email_name(msg):
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
h = email.header.Header(file_name)
dh = email.header.decode_header(h)
filename = dh[0][0]
if dh[0][1]:
value, charset = decode_header(str(filename, dh[0][1]))[0]
if charset:
filename = value.decode(charset)
print("附件名称:", filename)
return filename
def main_parse_Email(self):
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
print("count:",mail_counts)
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
Email_parse.get_att(msg)
Email_parse.get_text_from_HTML(msg)
def get_text_from_HTML(msg):
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return result
if __name__ == "__main__":
remote_server_url = 'imap.qq.com'
email_url = "*********@qq.com"
password = "**********"
demo = Email_parse(remote_server_url,email_url,password)
demo.main_parse_Email()Résultats d'exécution :
 [Recommandations associées :
[Recommandations associées :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



