

Cet article vous apporte des connaissances pertinentes sur mysql Il présente principalement les méthodes de requête en streaming et de requête par curseur dans MySQL. Il a une bonne valeur de référence et j'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo MySQL
Maintenant, le système d'entreprise doit lire 5 millions de lignes de données de la base de données MySQL pour le traitement
Par défaut, l'ensemble complet des résultats de récupération sera stocké en mémoire . Dans la plupart des cas, il s’agit de la manière la plus efficace de fonctionner et la plus facile à mettre en œuvre.
En supposant qu'une seule table ait un volume de données de 5 millions, personne ne la chargera dans la mémoire en même temps et la pagination est généralement utilisée.
Ici, la démo de test sert uniquement à surveiller la JVM, donc la pagination n'est pas utilisée et les données sont chargées dans la mémoire en même temps
@Test
public void generalQuery() throws Exception {
// 1核2G:查询一百条记录:47ms
// 1核2G:查询一千条记录:2050 ms
// 1核2G:查询一万条记录:26589 ms
// 1核2G:查询五万条记录:135966 ms
String sql = "select * from wh_b_inventory limit 10000";
ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
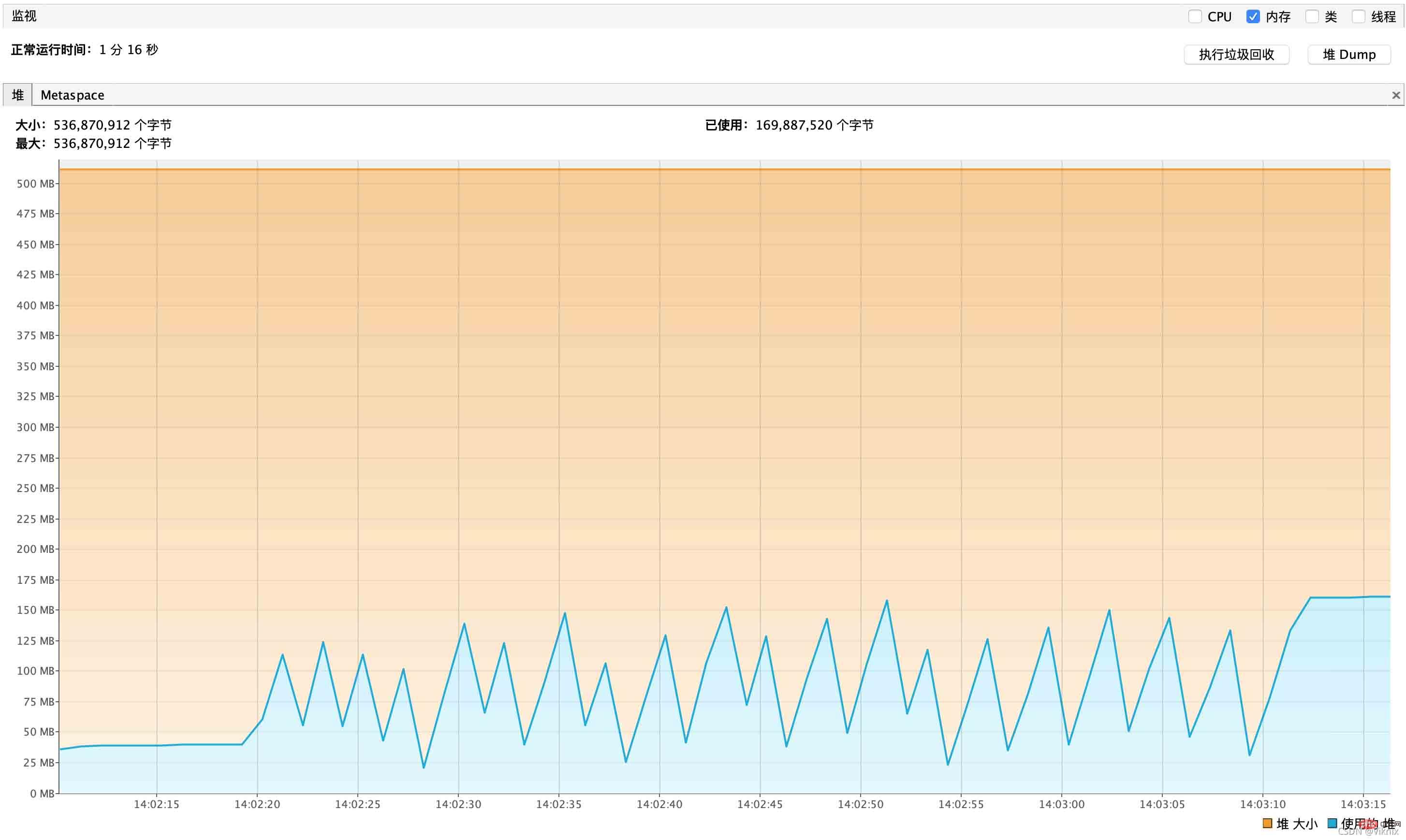
}Surveillance JVM
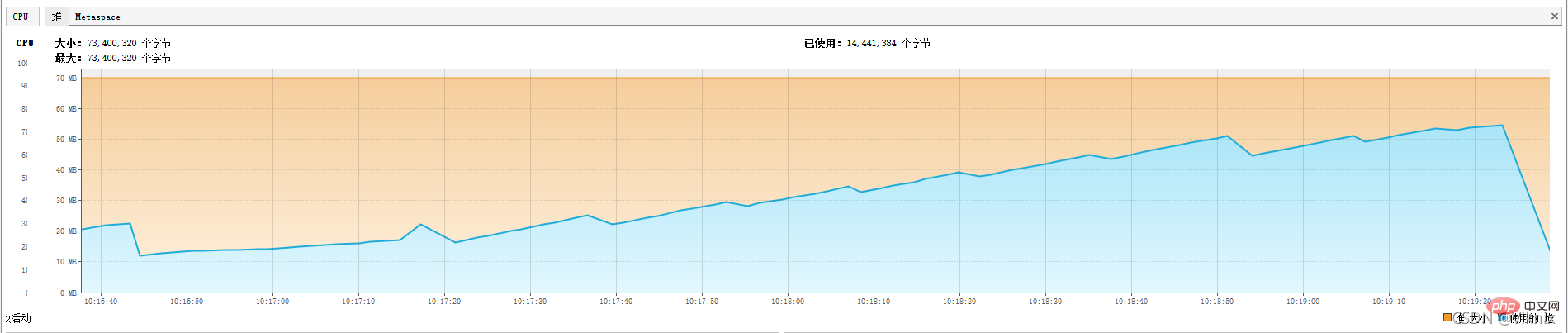
Nous ajusterons la mémoire à -Xms70m -Xmx70m
tout le processus de requête, l'utilisation de la mémoire du tas augmente progressivement et conduit finalement à un MOO :
java.lang.OutOfMemoryError : limite de surcharge du GC dépassée
1 Déclenchement fréquent du GC
2.
@Test
public void streamQuery() throws Exception {
// 1核2G:查询一百条记录:138ms
// 1核2G:查询一千条记录:2304 ms
// 1核2G:查询一万条记录:26536 ms
// 1核2G:查询五万条记录:135931 ms
String sql = "select * from wh_b_inventory limit 50000";
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(Integer.MIN_VALUE);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
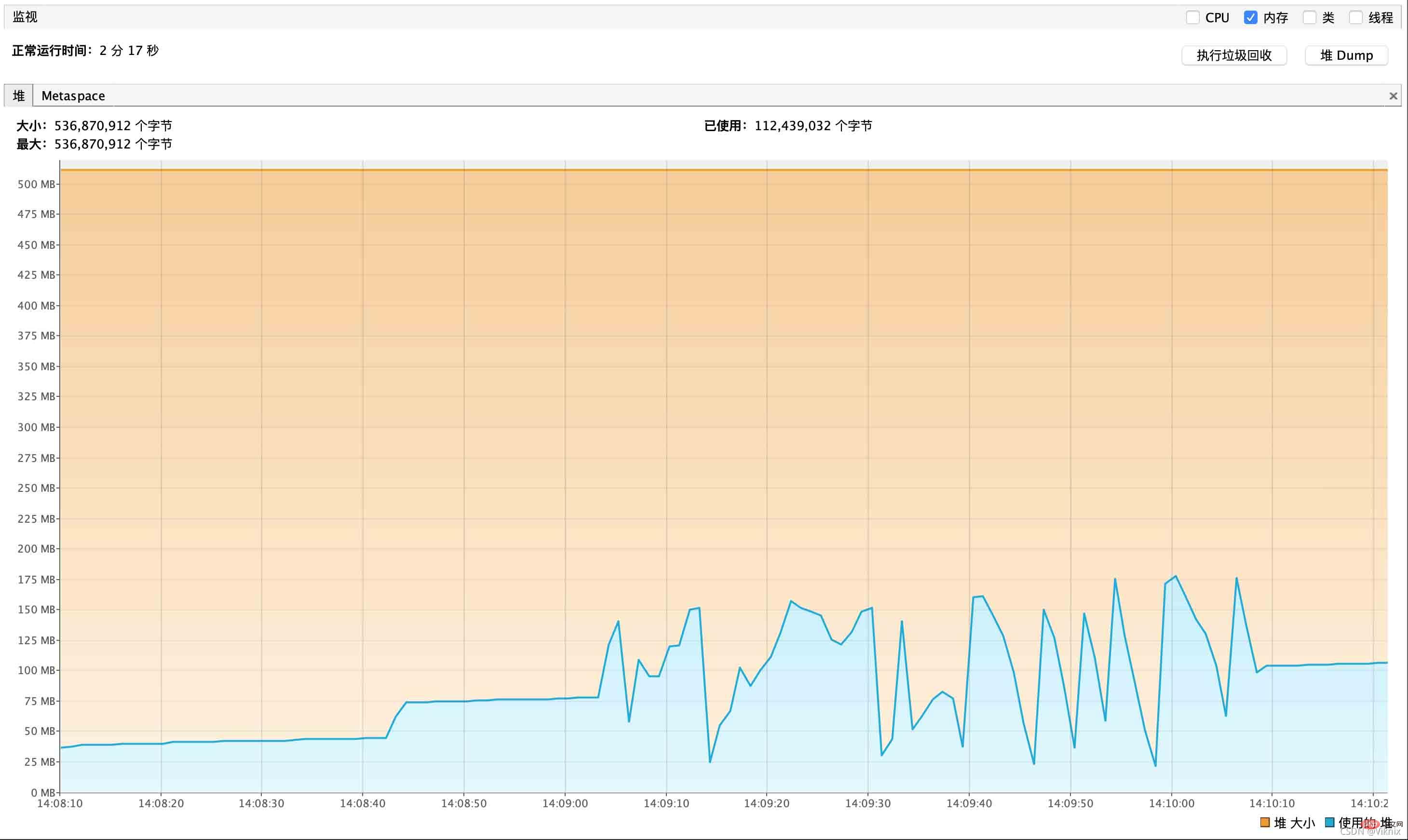
}Surveillance JVM
Nous avons réduit la mémoire du tas -Xms70m -Xmx70mNous avons constaté que même si la mémoire du tas n'était que de 70 m, elle restait ne s'est pas produit MOO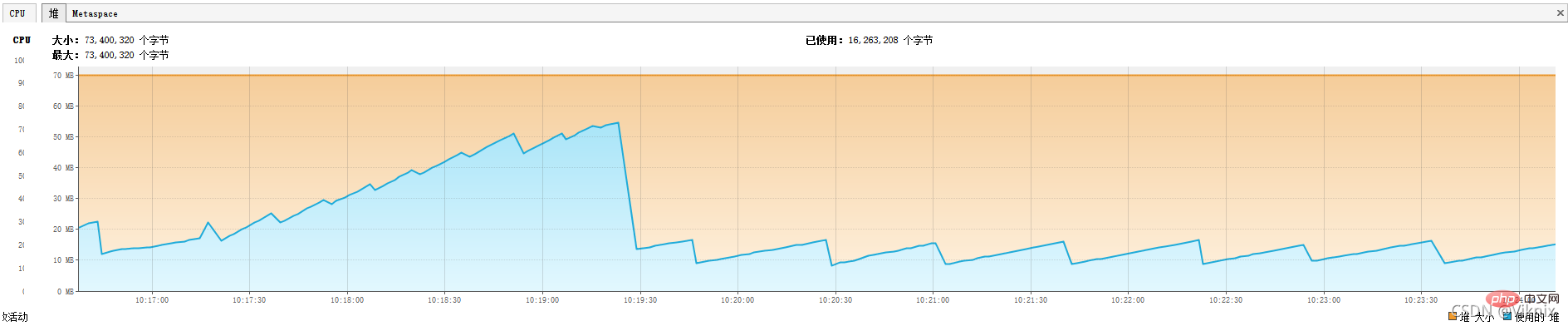
useCursorFetch=true
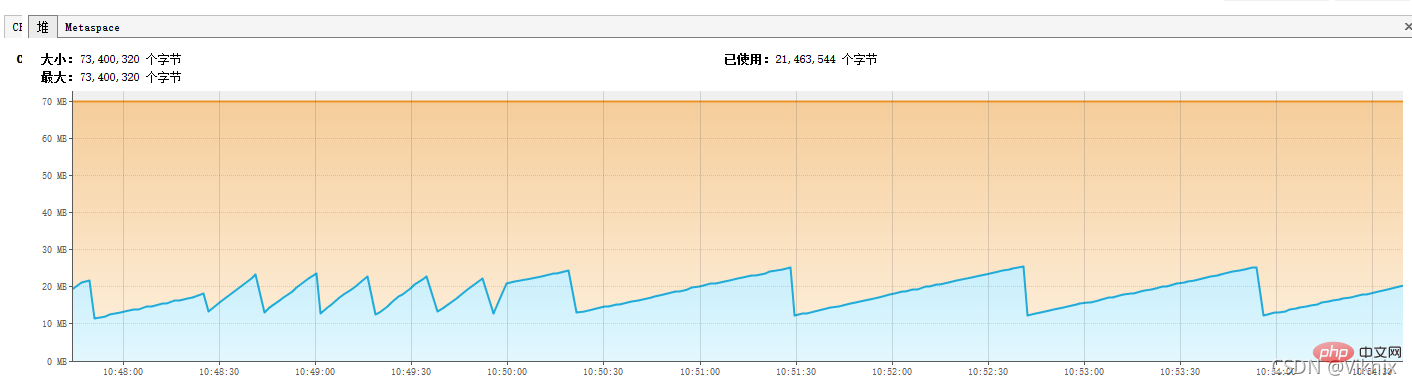
2. Deuxièmement, définissez le nombre de données lues par Statement à chaque fois. , comme en lire 1 000 à la foisÀ en juger par les résultats des tests, la requête du curseur a réduit la vitesse de requête dans une certaine mesure
Nous avons réduit la mémoire du tas -Xms70m -Xmx70m Nous avons trouvé que dans un cas monothread, les requêtes de curseur Comme les requêtes de streaming, le MOO peut être très bien évité et les requêtes de curseur peuvent optimiser la vitesse des requêtes. 3.2 RowDataDynamic 3.3 RowDataCursor Le RowDataStatic par défaut lit toutes les données dans la mémoire du client, il s'agit également de notre JVM ; RowDataDynamic lit une donnée par appel IO RowDataCursor lit les lignes fetchSize à la fois, puis lance un appel de demande une fois la consommation terminée. 4.Principe de communication JDBC Client JDBC -> Client Socket -> MySQL -> Récupérer les données renvoyées -> MySQL Kernel Socket Buffer -> Client Socket Buffer -> Une requête ordinaire chargera toutes les données interrogées dans la JVM, puis les traitera. 1 L'IOPS monte en flèche 2. L'espace disque monte en flèche Le rapport sur les performances de la mémoire de la requête de curseur est le suivant 6. Résumé 1. La requête de curseur et la requête de streaming peuvent éviter le MOO dans un seul thread Tutoriel vidéo mysql Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!@Test
public void cursorQuery() throws Exception {
Class.forName("com.mysql.jdbc.Driver");
// 注意这里需要拼接参数,否则就是普通查询
conn = DriverManager.getConnection("jdbc:mysql://101.34.50.82:3306/mysql-demo?useCursorFetch=true", "root", "123456");
start = System.currentTimeMillis();
// 1核2G:查询一百条记录:52 ms
// 1核2G:查询一千条记录:1095 ms
// 1核2G:查询一万条记录:17432 ms
// 1核2G:查询五万条记录:90244 ms
String sql = "select * from wh_b_inventory limit 50000";
((JDBC4Connection) conn).setUseCursorFetch(true);
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(1000);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}
3. RowDataResultSet.next() La logique est d'implémenter la classe ResultSetImpl pour obtenir la ligne de données suivante de RowData à chaque fois. RowData est une interface et le diagramme de relation d'implémentation est le suivant
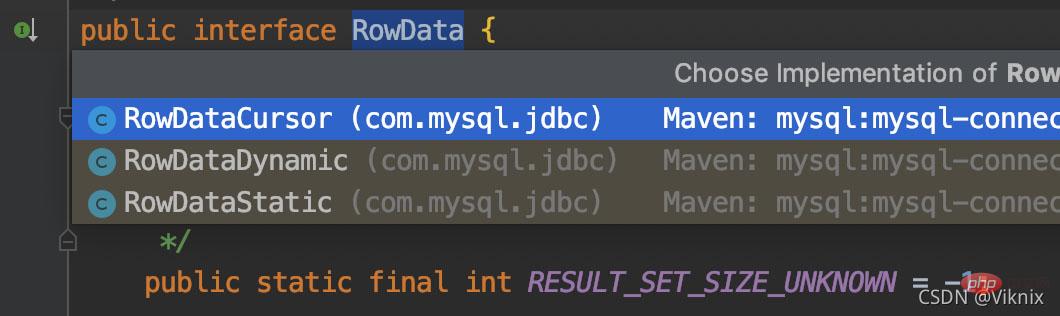 3.1 RowDataStatic
3.1 RowDataStaticPar défaut, ResultSet utilisera l'instance RowDataStatic lors de la génération de l'objet RowDataStatic, tous les enregistrements de ResultSet seront lus dans la mémoire, puis via. next() Lire à partir de la mémoire un par un
Lors de l'utilisation du traitement en streaming, ResultSet utilise l'objet RowDataDynamic, et cet objet lancera IO pour lire une seule ligne de données à chaque fois que next() est appelé
RowDataCursor L'appel est un traitement par lots, puis une mise en cache interne est effectuée. Le processus est le suivant :
Tout d'abord, il vérifiera s'il y a des données dans son tampon interne qui n'ont pas été renvoyées. S'il y en a, il le fera. revenez à la ligne suivante.
En résumé : L'interaction entre JDBC et le serveur MySQL s'effectue via Socket Correspondant à la programmation réseau, MySQL peut être considéré comme un SocketServer, donc un lien de requête complet doit être :
. 3. Une fois que le client JDBC a lancé SQL, le temps est long. en attente des données de réponse SQL. Pendant ce temps, le serveur prépare les données
requête de flux est le suivantLes appels simultanés sont également très bons pour l'utilisation de la mémoire, et il n'y a pas d'augmentation superposée
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



