
 base de données
Redis
Parlons brièvement de deux solutions permettant à Redis de gérer l'idempotence de l'interface.
base de données
Redis
Parlons brièvement de deux solutions permettant à Redis de gérer l'idempotence de l'interface.
Parlons brièvement de deux solutions permettant à Redis de gérer l'idempotence de l'interface.


Apprentissage recommandé : Tutoriel vidéo Redis
Avant-propos : La question de l'idempotence de l'interface est une question publique qui n'a rien à voir avec le langage pour les développeurs. Pour certaines requêtes utilisateur, elles peuvent être envoyées à plusieurs reprises dans certains cas. S'il s'agit d'une opération de requête, ce n'est pas grave. Cependant, certaines d'entre elles impliquent des opérations d'écriture. Une fois répétées, cela peut entraîner de graves conséquences, comme des transactions. . Si l'interface est demandée à plusieurs reprises, des commandes répétées peuvent être passées. L'idempotence de l'interface signifie que les résultats d'une ou de plusieurs requêtes initiées par l'utilisateur pour la même opération sont cohérents et qu'il n'y aura aucun effet secondaire causé par plusieurs clics. 接口幂等性问题,对于开发人员来说,是一个跟语言无关的公共问题。对于一些用户请求,在某些情况下是可能重复发送的,如果是查询类操作并无大碍,但其中有些是涉及写入操作的,一旦重复了,可能会导致很严重的后果,例如交易的接口如果重复请求可能会重复下单。接口幂等性是指用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。
一、接口幂等性
1.1、什么是接口幂等性
在HTTP/1.1中,对幂等性进行了定义。它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果,即第一次请求的时候对资源产生了副作用,但是以后的多次请求都不会再对资源产生副作用。这里的副作用是不会对结果产生破坏或者产生不可预料的结果。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
这类问题多发于接口的:
-
insert操作,这种情况下多次请求,可能会产生重复数据。 -
update操作,如果只是单纯的更新数据,比如:update user set status=1 where id=1,是没有问题的。如果还有计算,比如:update user set status=status+1 where id=1,这种情况下多次请求,可能会导致数据错误。
1.2、为什么需要实现幂等性
在接口调用时一般情况下都能正常返回信息不会重复提交,不过在遇见以下情况时可以就会出现问题,如:
- 前端重复提交表单: 在填写一些表格时候,用户填写完成提交,很多时候会因网络波动没有及时对用户做出提交成功响应,致使用户认为没有成功提交,然后一直点提交按钮,这时就会发生重复提交表单请求。
- 用户恶意进行刷单: 例如在实现用户投票这种功能时,如果用户针对一个用户进行重复提交投票,这样会导致接口接收到用户重复提交的投票信息,这样会使投票结果与事实严重不符。
- 接口超时重复提交: 很多时候 HTTP 客户端工具都默认开启超时重试的机制,尤其是第三方调用接口时候,为了防止网络波动超时等造成的请求失败,都会添加重试机制,导致一个请求提交多次。
- 消息进行重复消费: 当使用 MQ 消息中间件时候,如果发生消息中间件出现错误未及时提交消费信息,导致发生重复消费。
本文讨论的是如何在服务端优雅地统一处理这种接口幂等性情况,如何禁止用户重复点击等客户端操作不在此次讨论范围。
1.3、引入幂等性后对系统的影响
幂等性是为了简化客户端逻辑处理,能放置重复提交等操作,但却增加了服务端的逻辑复杂性和成本,其主要是:
- 把并行执行的功能改为串行执行,降低了执行效率。
- 增加了额外控制幂等的业务逻辑,复杂化了业务功能;
所以在使用时候需要考虑是否引入幂等性的必要性,根据实际业务场景具体分析,除了业务上的特殊要求外,一般情况下不需要引入的接口幂等性。
二、如何设计幂等
幂等意味着一条请求的唯一性。不管是你哪个方案去设计幂等,都需要一个全局唯一的ID ,去标记这个请求是独一无二的。
- 如果你是利用唯一索引控制幂等,那唯一索引是唯一的
- 如果你是利用数据库主键控制幂等,那主键是唯一的
- 如果你是悲观锁的方式,底层标记还是全局唯一的ID
2.1、全局的唯一性ID
全局唯一性ID,我们怎么去生成呢?你可以回想下,数据库主键Id怎么生成的呢?
是的,我们可以使用UUID
1. L'idempotence de l'interface
1.1. Qu'est-ce que l'idempotence de l'interface
Dans HTTP/1.1, l'idempotence est définie . Il décrit qu'une et plusieurs requêtes pour une ressource doivent avoir le même résultat pour la ressource elle-même, c'est-à-dire que la première requête a des effets secondaires sur la ressource, mais que les requêtes suivantes n'auront pas d'effets secondaires sur la ressource. Les effets secondaires ici n’endommagent pas les résultats et ne produisent pas de résultats imprévisibles. En d’autres termes, toute exécution multiple a le même impact sur la ressource elle-même qu’une seule exécution. 🎜🎜Ce type de problème survient souvent dans l'interface : 🎜Opération-
insertDans ce cas, plusieurs requêtes peuvent produire des données en double. Opération -
update, si vous mettez simplement à jour les données, par exemple :update user set status=1 which id=1, il n'y a pas de problème. S'il existe des calculs, tels que :update user set status=status+1 which id=1, plusieurs requêtes dans ce cas peuvent provoquer des erreurs de données.
1.2. Pourquoi est-il nécessaire d'implémenter l'idempotence ?
🎜En général, lorsque l'interface est appelée, les informations peuvent être renvoyées normalement et le seront. ne pas être soumis à plusieurs reprises. Cependant, des problèmes peuvent survenir dans les situations suivantes, telles que : 🎜- Soumission répétée de formulaires sur le front-end : lorsqu'il remplit certains formulaires, l'utilisateur termine la soumission et le fait souvent. ne répond pas à l'utilisateur à temps en raison des fluctuations du réseau, ce qui fait penser à l'utilisateur que la soumission n'a pas réussi, puis continue de cliquer sur le bouton de soumission. À ce moment-là, des soumissions répétées de demandes de formulaire se produiront.
- Les utilisateurs glissent les commandes de manière malveillante : par exemple, lors de la mise en œuvre de la fonction de vote des utilisateurs, si l'utilisateur soumet à plusieurs reprises des votes pour un utilisateur, l'interface recevra les informations de vote soumises à plusieurs reprises par l'utilisateur, ce qui provoquera le vote. Les résultats sont sérieusement incompatibles avec les faits.
- Délai d'expiration de l'interface et soumission répétée : de nombreux outils clients HTTP activent le mécanisme de nouvelle tentative d'expiration par défaut, en particulier lorsqu'un tiers appelle l'interface. Afin d'éviter les échecs de requête causés par des fluctuations du réseau, des délais d'attente, etc., Un mécanisme de nouvelle tentative sera ajouté, provoquant la soumission d'une demande plusieurs fois.
- Consommation répétée de messages : lors de l'utilisation du middleware de messages MQ, si une erreur se produit dans le middleware de messages et que les informations de consommation ne sont pas soumises à temps, une consommation répétée se produira.
1.3. Impact sur le système après l'introduction de l'idempotence
🎜L'idempotence consiste à simplifier le traitement de la logique client et peut placer des opérations telles que des soumissions répétées, mais elle augmente également la complexité logique des services et Les coûts du terminal sont principalement : 🎜- Le changement de la fonction d'exécution parallèle en exécution série réduit l'efficacité de l'exécution.
- Ajout d'une logique métier supplémentaire pour contrôler l'idempotence, compliquant les fonctions commerciales
2. Comment concevoir l'idempotence
🎜L'impuissance signifie le caractère unique d'une demande. Quelle que soit la solution que vous choisissez pour concevoir l’idempotence, vous avez besoin d’un identifiant unique au monde pour marquer cette demande comme unique. 🎜- Si vous utilisez un index unique pour contrôler l'idempotence, alors l'index unique est unique
- Si vous utilisez une clé primaire de base de données pour contrôler l'idempotence, alors la clé primaire est unique Si vous utilisez le verrouillage pessimiste, la balise sous-jacente est toujours un identifiant globalement unique
2.1 ID d'unicité globale
🎜ID d'unicité globale. , comment le générer ? Vous pouvez y réfléchir, comment l'identifiant de clé primaire de la base de données est-il généré ? 🎜🎜Oui, nous pouvons utiliserUUID, mais les inconvénients de l'UUID sont évidents. Sa chaîne prend beaucoup de place, l'ID généré est trop aléatoire, a une mauvaise lisibilité et n'est pas incrémenté. 🎜Nous pouvons également utiliser l'Algorithme Snowflake (Snowflake) pour générer des identifiants uniques. 雪花算法(Snowflake) 生成唯一性ID。
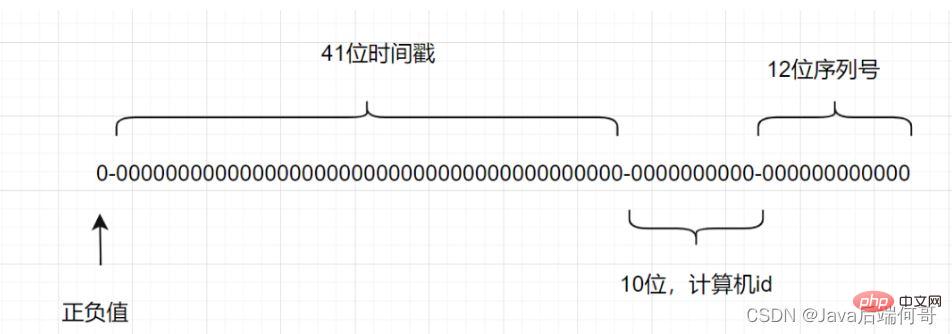
雪花算法是一种生成分布式全局唯一ID的算法,生成的ID称为Snowflake IDs。这种算法由Twitter创建,并用于推文的ID。
一个Snowflake ID有64位。
- 第1位:Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
- 接下来前41位是时间戳,表示了自选定的时期以来的毫秒数。
- 接下来的10位代表计算机ID,防止冲突。
- 其余12位代表每台机器上生成ID的序列号,这允许在同一毫秒内创建多个Snowflake ID。
当然,全局唯一性的ID,还可以使用百度的Uidgenerator,或者美团的Leaf。
2.2、幂等设计的基本流程
幂等处理的过程,说到底其实就是过滤一下已经收到的请求,当然,请求一定要有一个全局唯一的ID标记
Identifiants Snowflake. Cet algorithme a été créé par Twitter et est utilisé pour les identifiants des tweets. Un identifiant Snowflake a 64 bits. 
Les 10 chiffres suivants représentent l'ID de l'ordinateur pour éviter les conflits.
Les 12 bits restants représentent le numéro de série sur lequel l'ID a été généré sur chaque machine, ce qui permet de créer plusieurs ID Snowflake dans la même milliseconde.
Bien sûr, l'identifiant unique au monde, Vous pouvez également utiliser le Uidgenerator de Baidu ou le Leaf de Meituan.
- Le processus de traitement idempotent, en dernière analyse, consiste à filtrer les demandes reçues. Bien entendu, les demandes doivent avoir une
balise d'identification unique globale Ha. Alors, comment déterminer si la demande a déjà été reçue ? Stockez la demande. Lors de la réception de la demande, vérifiez d'abord l'enregistrement de stockage. Si l'enregistrement existe, le dernier résultat sera renvoyé. Si l'enregistrement n'existe pas, la demande sera traitée. <li>Le traitement général de l'idempotence est le suivant :
- 3. Solutions courantes pour interfacer l'idempotence
- 3.1 Transmettre les numéros de demande uniques en aval
- Le numéro de séquence de demande unique signifie en fait que chaque fois qu'une demande est adressée au serveur, elle est accompagnée d'un numéro de séquence unique et non répétitif dans un court laps de temps. peut être un identifiant séquentiel ou un numéro de commande, généralement généré par l'aval, lors de l'appel de l'interface serveur en amont, le numéro de série et l'identifiant utilisé pour l'authentification sont ajoutés.
- Lorsque le serveur en amont reçoit les informations de demande, il combine le numéro de série et l'ID d'authentification en aval pour former une clé pour faire fonctionner Redis, puis interroge Redis pour voir s'il existe une paire clé-valeur pour la clé correspondante. le résultat :
S'il existe, cela signifie que la demande en aval du numéro de série a été traitée. A ce moment, vous pouvez répondre directement au message d'erreur de la demande répétée.
Si elle n'existe pas, utilisez la clé comme clé de Redis, utilisez les informations de clé en aval comme valeur stockée (telles que certaines informations de logique métier transmises par le fournisseur en aval), stockez la paire clé-valeur dans Redis et puis exécutez la correspondance normalement selon la logique métier. 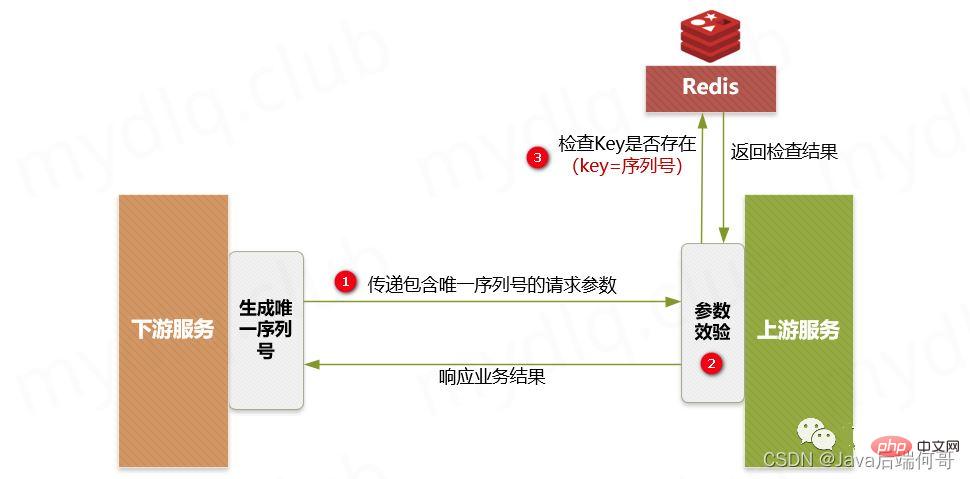
Opérations applicables :
- Opération d'insertion
- Opération de mise à jour
- Opération de suppression
Restrictions d'utilisation :
Nécessite qu'un tiers transmette un numéro de série unique
Nécessite l'utilisation d'un composant tiers ; Redis pour la validation des données ;Processus principal :
🎜🎜🎜🎜 Étapes principales : 🎜🎜🎜 Le service en aval génère un identifiant distribué sous forme de numéro de série, puis exécute la demande d'appel de l'interface en amont, ainsi que le "unique numéro de série" et "l'identifiant d'authentification" demandé. 🎜🎜 Le service en amont effectue une vérification de sécurité et détecte si le « numéro de série » et « l'identifiant d'identification » existent dans les paramètres transmis en aval. 🎜🎜 Le service en amont détecte s'il existe une clé composée du "numéro de série" et de "l'ID d'authentification" correspondants dans Redis. Si elle existe, il lancera un message d'exception d'exécution répété, puis répondra au message d'erreur correspondant du serveur. en aval. S'il n'existe pas, la combinaison du « numéro de série » et de « l'ID d'authentification » sera utilisée comme clé, et les informations de clé en aval seront utilisées comme valeur, puis stockées dans Redis, puis la logique métier suivante sera être exécuté normalement. 🎜🎜🎜Dans les étapes ci-dessus, lors de l'insertion de données dans Redis, vous devez définir le délai d'expiration. Cela garantit que dans cet intervalle de temps, si l'interface est appelée à plusieurs reprises, un jugement et une identification peuvent être effectués. Si le délai d'expiration n'est pas défini, il est probable qu'une quantité illimitée de données sera stockée dans Redis, ce qui empêchera Redis de fonctionner correctement. 🎜🎜🎜3.2. Jeton anti-duplication 🎜🎜🎜Description du projet : 🎜🎜Compte tenu des clics continus du client ou des tentatives d'expiration du délai de l'appelant, comme la soumission d'une commande, cette opération peut utiliser le mécanisme du jeton pour empêcher les soumissions répétées. Pour faire simple, l'appelant demande d'abord un identifiant global (jeton) au backend lors de l'appel de l'interface, et transporte cet identifiant global avec la demande (il est préférable de mettre le jeton dans les en-têtes. Le backend doit utiliser ce jeton). . En tant que clé, les informations utilisateur sont envoyées à Redis en tant que valeur pour la vérification du contenu de la valeur de la clé. Si la clé existe et que la valeur correspond, la commande de suppression est exécutée, puis la logique métier suivante est exécutée normalement. S'il n'y a pas de clé correspondante ou si la valeur ne correspond pas, un message d'erreur répété sera renvoyé pour garantir des opérations idempotentes. 🎜Restrictions d'utilisation :
- Besoin de générer une chaîne de jeton unique au monde ;
- Besoin d'utiliser le composant tiers Redis pour la validation des données
Processus principal :
Le serveur fournit une interface pour obtenir le jeton, qui peut être un numéro de séquence, qui peut également être un ID distribué ou une chaîne UUID.
Le client appelle l'interface pour obtenir le Token. A ce moment, le serveur générera une chaîne de Token.
Stockez ensuite la chaîne dans la base de données Redis, en utilisant le Token comme clé Redis (notez le délai d'expiration).
Retournez le jeton au client. Une fois que le client l'a reçu, il doit être stocké dans le champ caché du formulaire.
Lorsque le client exécute et soumet le formulaire, il stocke le jeton dans les en-têtes et transporte les en-têtes lors de l'exécution de la demande commerciale.
Après avoir reçu la demande, le serveur récupère le jeton des en-têtes, puis vérifie si la clé existe dans Redis en fonction du jeton.
Le serveur détermine si la clé existe dans Redis. Si elle existe, supprimez la clé puis exécutez la logique métier normalement. S'il n'existe pas, une exception sera levée et un message d'erreur pour les soumissions répétées sera renvoyé.
Notez que dans des conditions concurrentes, l'exécution de la recherche et de la suppression de données Redis doit garantir l'atomicité, sinon l'idempotence peut ne pas être garantie en cas de concurrence. Son implémentation peut utiliser des verrous distribués ou utiliser des expressions Lua pour se déconnecter des opérations de requête et de suppression.
Apprentissage recommandé : Tutoriel vidéo Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
