
 Java
javaDidacticiel
Méthode d'implémentation Java pour spécifier l'encodage lors de la création d'un fichier
Java
javaDidacticiel
Méthode d'implémentation Java pour spécifier l'encodage lors de la création d'un fichier
Méthode d'implémentation Java pour spécifier l'encodage lors de la création d'un fichier

Cet article vous apporte des connaissances pertinentes sur java. Il présente principalement la méthode d'implémentation de spécification de l'encodage lors de la création d'un fichier en Java. L'article le présente en détail à travers un exemple de code, ce qui est d'une certaine importance pour l'étude ou le travail de chacun. valeur d'apprentissage, j'espère qu'il sera utile à tout le monde.

Étude recommandée : "Tutoriel vidéo Java"
Préface : Récemment, j'ai appris les connaissances liées au flux Java IO et je voulais mettre en pratique et consolider les connaissances acquises en lisant et en écrivant des fichiers. Lorsque j'utilisais la classe File pour créer un fichier, je me suis soudainement demandé : comment dois-je spécifier l'encodage utilisé par le fichier ? Puis j’ai pensé : comment dois-je vérifier l’encodage d’un fichier ?
1. Analyse du problème
Allez d'abord sur Internet pour trouver la réponse. Les résultats sont les suivants :
FileInputStream fis=new FileInputStream(“xxxx.txt”); OutputStreamWriter osw=new OutputStreamWriter(fis,“UTF-8”);
Le code ci-dessus signifie probablement que lors de l'écriture d'un fichier, les caractères écrits sont codés en UTF-8, ce qui est différent de ce à quoi je m'attendais. Je souhaite spécifier l'encodage lors de la création du fichier. Comme ce qui suit,
File myfile = new File("test.txt”, “UTF-8”);
if (!myfile.exists()) myfile.createNewFile();Donc, j'ai vérifié la documentation officielle de l'API Java 8 et File n'a pas fourni de constructeur capable de spécifier le codage des caractères.

En même temps, il ne fournit pas d'autres méthodes d'accès au codage de caractères telles que set ou get, indiquant que le codage de caractères n'est pas un attribut inhérent au fichier. Tels que l'heure de création du fichier, l'heure de modification du fichier, qu'il soit lisible, inscriptible et exécutable, ce sont les attributs inhérents au fichier, ou méta-informations, ils font partie du fichier.
2. Codage des caractères
Nous savons que toute information stockée dans l'ordinateur est une chaîne de 01, et le texte ne fait pas exception.
Le traitement des caractères comprend deux processus : Encodage et décodage
Encodage : "mapper" les caractères à la chaîne 01
Décodage : "mapper" la chaîne 01 aux caractères
Différents encodages de caractères, tels que comme GBK, UTF-8, l'encodage et le décodage utilisent des règles différentes.
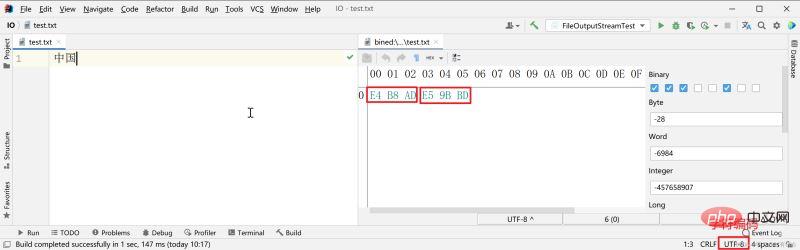
Pour la même chaîne de texte : "Chine", utilisez l'encodage UTF-8 pour la sauvegarder. Généralement, trois octets sont utilisés pour sauvegarder un caractère chinois (la forme hexadécimale de la chaîne 01 sous-jacente).
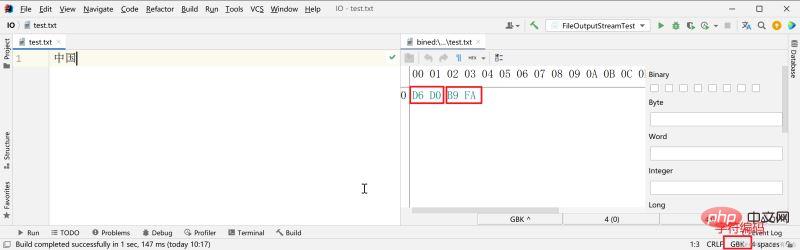
Utilisation de l'encodage GBK pour enregistrer, en utilisant deux octets pour représenter un caractère chinois.
Lorsque nous écrivons et enregistrons le texte dans l'éditeur de texte, l'éditeur "mappera" le texte dans une chaîne de 01 en fonction du type d'encodage de caractères que vous avez défini.
Le type de caractère que vous définissez n'est qu'une règle de conversion permettant à l'éditeur d'encoder le texte en 10 chaînes, et n'est pas un attribut du texte.
Lorsque l'éditeur ouvre le fichier texte, ce qui est affiché n'est pas la chaîne 01 sous-jacente, mais le texte. En effet, l'éditeur utilise un certain codage de texte pour décoder la chaîne 01 en caractères. Si, lors du décodage, le codage des caractères utilisé est cohérent ou compatible avec le codage, le texte peut s'afficher correctement. Si le codage de caractères utilisé lors du décodage est incohérent ou incompatible avec le codage, les caractères seront tronqués.
Par exemple, j'ai un fichier texte utilisant l'encodage GBK, le contenu est "Quand la lune brillante sortira",

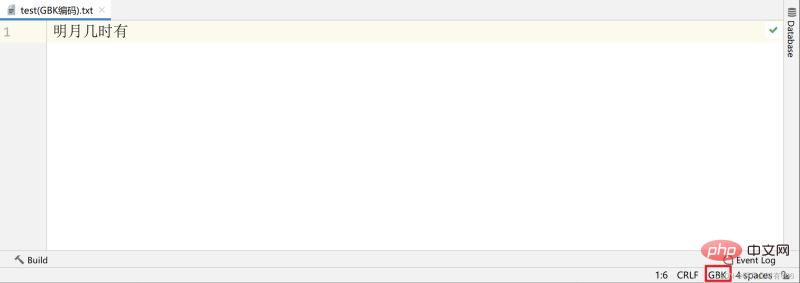
J'utilise VS code (un éditeur de texte très simple à utiliser de Microsoft) ouvrir le fichier, dans la terminologie, signifie décoder le fichier. Le codage de texte par défaut utilisé est UTF-8 et le décodage est le même. Cependant, comme la couche inférieure de mon texte est une chaîne 01 codée en GBK (deux octets et un caractère), l'utilisation de UTF-8 pour décoder la chaîne 01 entraînera inévitablement des caractères tronqués en raison d'un codage et d'un décodage incohérents. À ce stade, tant que vous sélectionnez manuellement l'encodage GBK correspondant, le fichier décodé ne sera pas tronqué.
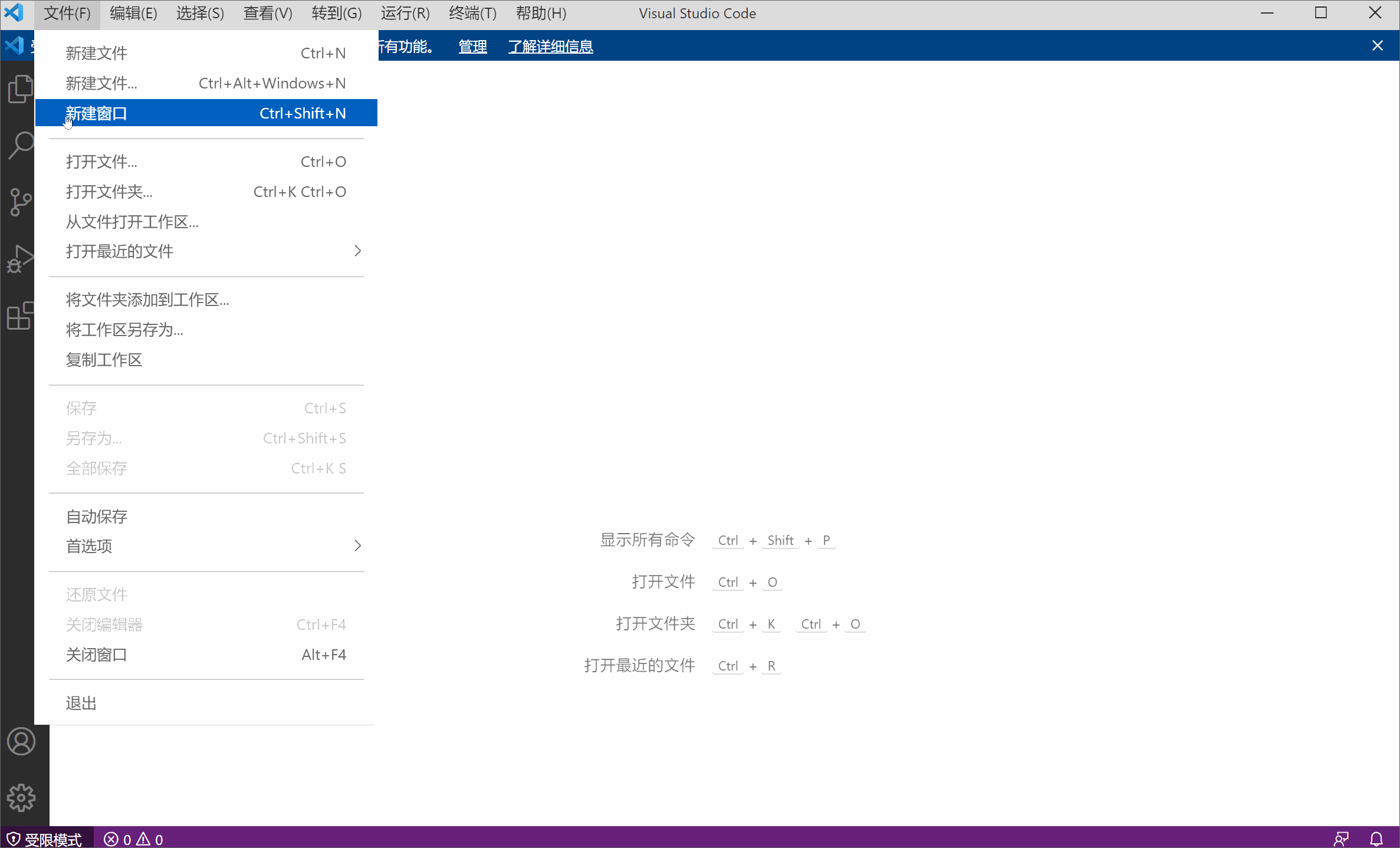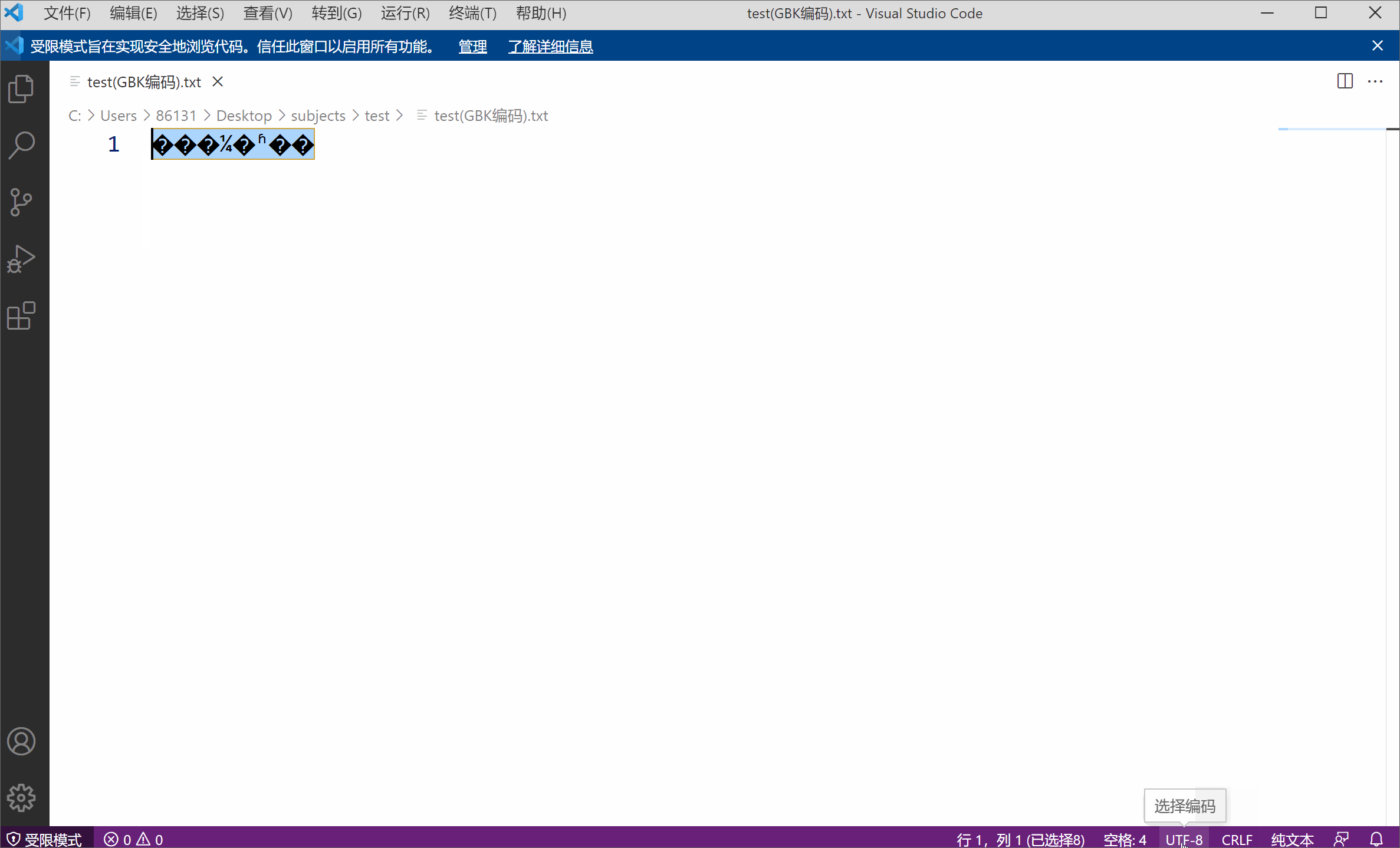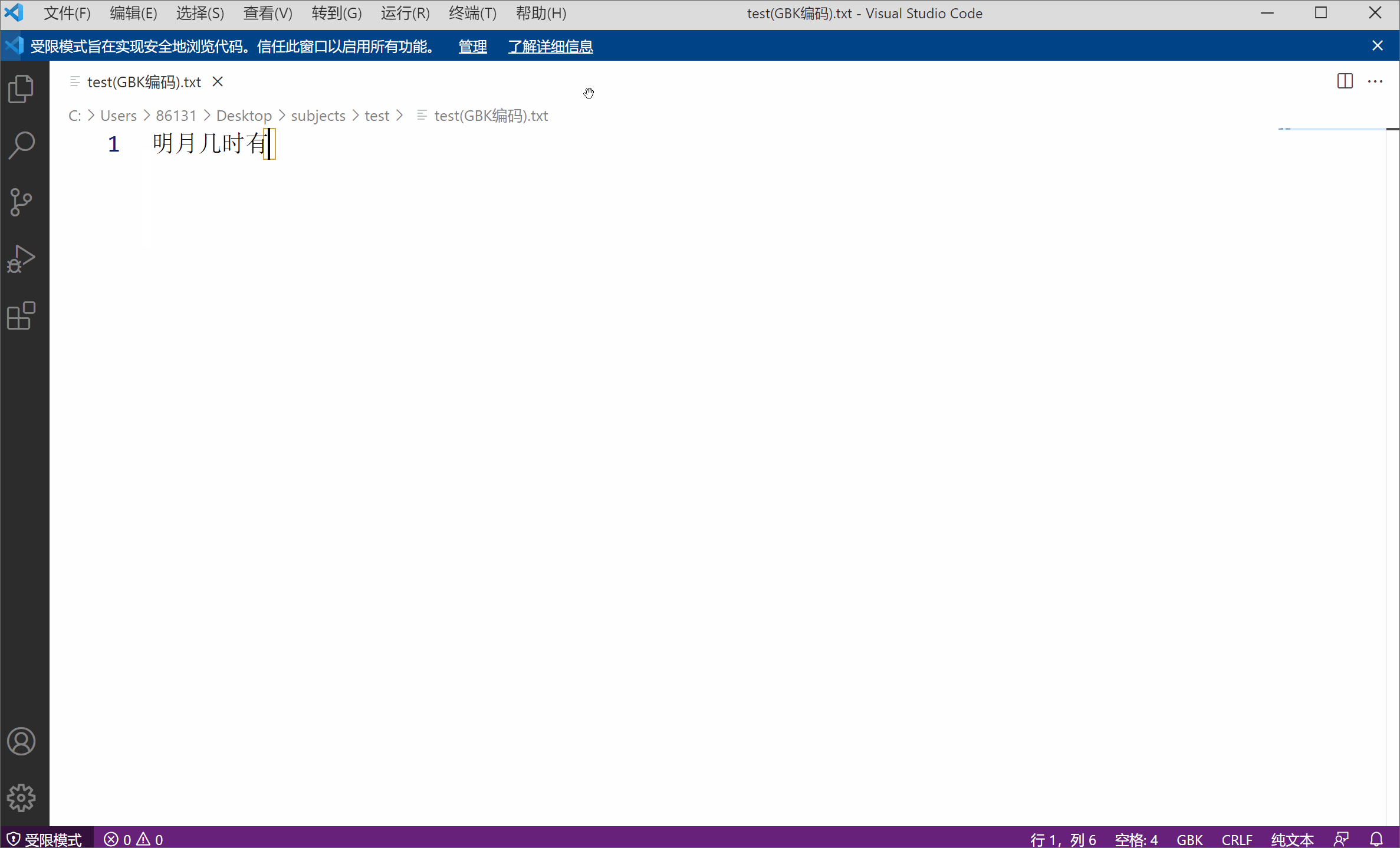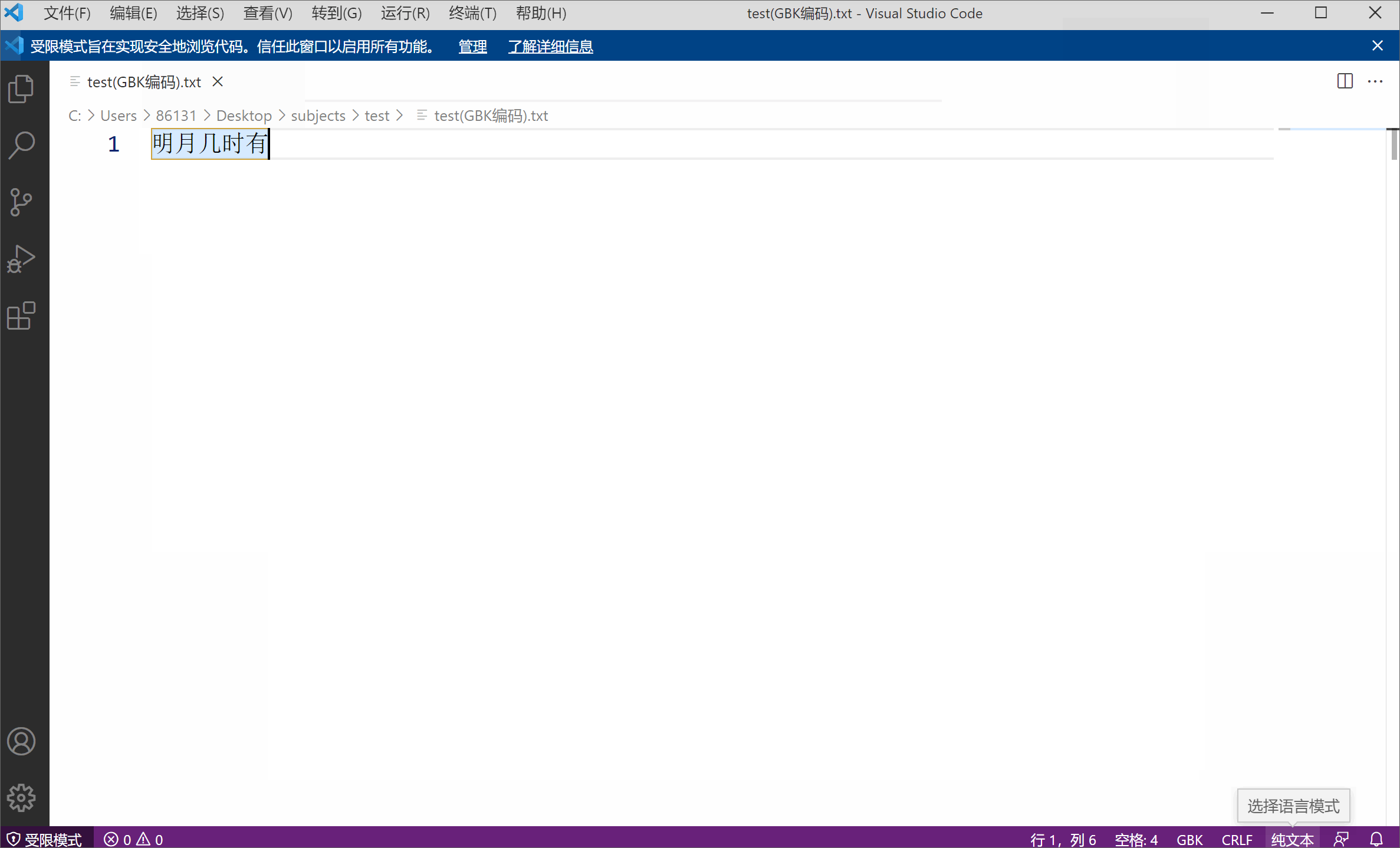
Les caractères tronqués illustrent également de côté que l'encodage des caractères n'est pas un attribut inhérent au fichier.
J'ai tellement parlé juste pour illustrer ce point : Le codage des caractères est la règle utilisée lors du décodage et de l'encodage, et non un attribut inhérent au fichier.
Je ne peux m'empêcher de me demander pourquoi le codage des caractères n'a-t-il pas été défini dans les propriétés du fichier ?
En supposant qu'il puisse être défini et défini sur GBK, le système d'exploitation doit alors maintenir la fonction. Tout comme un fichier n'est pas accessible en écriture, si un programme tente d'écrire dans le fichier, le système d'exploitation refusera d'écrire. Les octets que le système d'exploitation doit écrire doivent répondre aux exigences de codage GBK. Ensuite, chaque octet est écrit. besoins du système d'exploitation La vérification de la légalité de l'octet nécessite beaucoup de surcharge de performances et est même impossible à mettre en œuvre, car certains octets spéciaux peuvent représenter soit GBK, soit UTF-8, ce qui est ambigu. Maintenant, quel est l'intérêt de faire cela ? Est-ce pour que l'éditeur puisse sélectionner le bon encodage en fonction des propriétés d'encodage lors de l'ouverture du fichier ? Ce n'est pas nécessaire. Un éditeur intelligent peut déduire le codage utilisé par votre chaîne 01 en fonction des premiers octets du contenu. De plus, vous pouvez également définir manuellement le codage des caractères utilisé pour le décodage.
3. Problème résolu
Lors de la création d'un fichier, l'encodage du fichier ne peut pas être spécifié. Lors de l'écriture de texte dans un fichier (par exemple, Ctrl + S enregistré dans un éditeur de texte, qui effectue essentiellement une opération d'écriture), vous pouvez choisir de convertir le texte en une règle d'encodage de chaîne 01.
Pour les programmes Java, le code est le suivant, qui est le code mentionné en début d'article :
FileInputStream fis=new FileInputStream(“xxxx.txt”); OutputStreamWriter osw=new OutputStreamWriter(fis,“UTF-8”);
Apprentissage recommandé : "Tutoriel vidéo Java"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
