
 base de données
Redis
Explication détaillée des exemples de mise en œuvre du protocole Redis RESP
base de données
Redis
Explication détaillée des exemples de mise en œuvre du protocole Redis RESP
Explication détaillée des exemples de mise en œuvre du protocole Redis RESP


Apprentissage recommandé : Tutoriel vidéo Redis
Révision du protocole RESP
RESP是基于TCP来实现的Redis通信协议,该协议是以/r/n (ligne) pour la segmentation, le protocole prend en charge 5 types, les informations spécifiques sont les suivantes :
| type | préfixe | Remarques |
|---|---|---|
| Chaîne simple | + | Chaîne simple commence par + |
| Données d'erreur | - | Les données d'erreur commencent par - |
| Entier | : | Les entiers commencent par : |
| Chaîne complexe | $ | Chaîne complexe commence par $ |
| Array | * | Array commence par * |
即,我们向redis发送命令:set name pdudo,其实发送的具体信息是
*3 $3 set $4 name $5 pdudo
而服务器返回的信息也是类似的,只不过还需要了解+和-,这2个前缀分别代表正确消息和错误的消息。
我们准备2个例子,我们来敲一下
例子1
set name pdudo
例子2
lpush pdudo data1 lpush pdudo data2 lrange pdudo 0 -1
快来动动你的小手指,看能不能根据RESP协议规则,将上述例子命令敲出来。现在你体会到了Redis官网介绍RESP协议时所述的 简单 和 易读 可么?
对于RESP来说,一定要搞清楚协议后,最好能够手写协议去执行,再考虑写程序去实现协议!!!
如何拆解RESP协议
终于到了喜闻乐见的环节了,我们要拆解和组装协议了。 那我们至少来解决如下3个问题:
- 该协议是基于
TCP流的,我们如何判断整个命令什么时候结束? - 如何拆解命令?
协议什么时候结束
一般而言,我们自己在使用TCP传输数据,都会在数据开头定义2个或者4个字节,用于存储该数据有多少个字节,这样方便检验接收,类似于这种情况。

而RESP有意思了,它是以/r/n来分割的。最前面会以前缀来判断其类型,例如我们发送命令,其会用到的前缀有*以及$,那么我们如何来判断,我们要读取多少个/r/n呢?
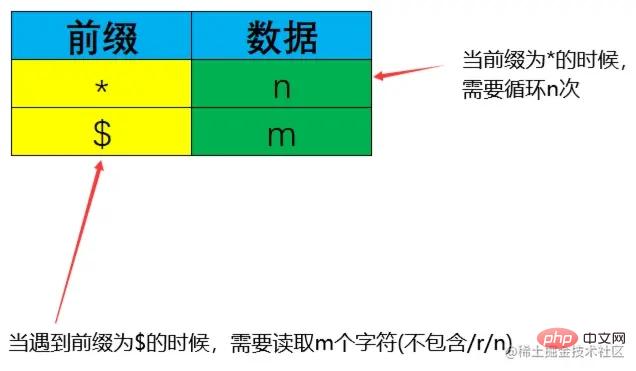
因为上述*代表数组,即有多少组数据需要处理,图中为n。
而$表示复杂字符串,即需要获取m个字符数据,不包含/r/n
如何拆解RESP协议
若要拆解命令,则我们得获取命令,如上图所示,报文$m,其实记录的有m长度的数据(不包含\r\n),所以我们可以这样来写伪代码。
根据如上,我们很容易写出伪代码。
func toArgs(rd *bufio.Reader) {
data , _ , _ := rd.ReadLine()
switch data[0] {
case '*':
n := data[1:] // 循环n次
for i:=0;i<n;i++ {
toArgs(rd)
}
case '$':
m := data[1:] // 获取m个数据
// 获取m长度的数据即可
}
}如上我们先获取前缀为*的,继而获取其值n,我们则循环n次,即可获取该报文的数据。而前缀为$的,我们可以直接获取该m长度的数据即可,这里主要要处理一下\r\n。
将命令构建RESP报文规范,根据拆解反操作就可以了,这里暂不介绍了。
上述,我们核心功能已经探讨完毕了。
功能实现
代码已经编写完毕,放置在了gitee上: gitee
如上我们已经学会了如何拆解和组装RESP协议了,我们接着来看,我们如何用go来编写拆解和组装协议的代码呢? 我们可以看。
我们先创建一个字符,然后将其封装为bufio.Reader,我们来看下:
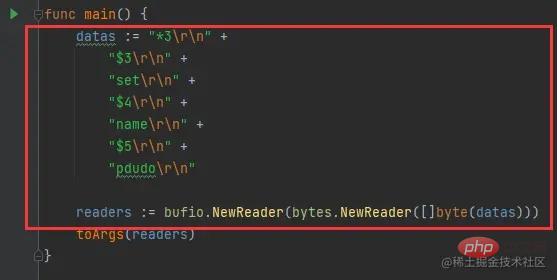
因为我们要使用readLine()函数,所以我们需要将其转换为bufio.Reader类型,若是直接从net.Conn中获取,不用转换,直接可以使用 bufio.Reader的。
我们将上述伪代码编写一下,实现拆解的功能。
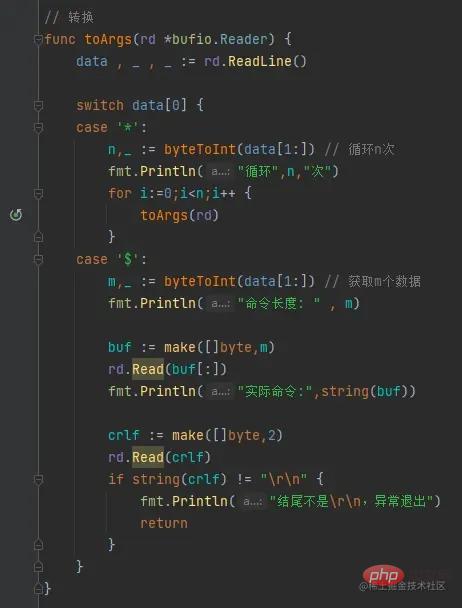
其具体执行过程是我们先获取一行数据,放置到data中,而后判断其前缀是什么,若是*则取其后面的数据,将其转为int类型n,而后再递归该函数n次,而后中遇到$,我们则取后面的数据,也是将其转为int类型m,而后再取m长度的实际数据,这就是我们的命令了,最后我们再踢掉命令的\r\n即可。
其中,有一个函数是byteToInt是我们自己写的通过切片转为数字的函数,我们看下
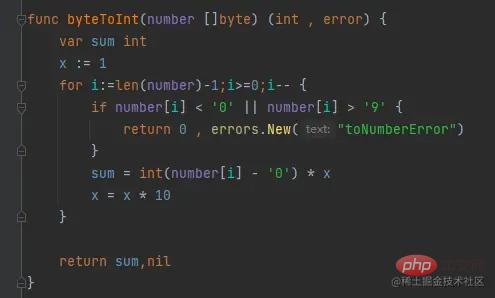
该函数主要的功能是将其[]byte数字转换为int数据。
如上,我们整个RESP协议功能写完了,我们运行下看下实际效果:
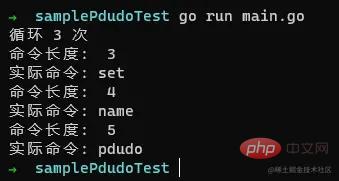
Évidemment, nous avons réussi à démonter les données.
Dans cet article, nous expliquons comment utiliser go pour démonter simplement le contenu du protocole RESP. Pourquoi ne pas présenter comment écrire redis<.> Qu'en est-il du middleware maître-esclave ? <code>go简单的拆解RESP协议的内容,为什么我们不介绍如何编写redis主从中间件呢?
最开始是打算这样写的,但是知识多了,介绍起来会很杂,很难把一个点讲清楚,所以我们就单独挑了一个核心点来介绍,我愿意将其称之为面向核心编程(我的基友很早之前告诉我的),所谓的面向核心编程简而易在就是我们在涉及一个功能的时候,要学会拆解该功能,将核心功能先用demo做出来,而后再慢慢丰富周边,从而完成整个需求涉及。
最后我们再来聊聊RESPJ'avais initialement prévu de l'écrire comme ça, mais avec trop de connaissances, l'introduction sera très compliquée et il est difficile d'expliquer clairement un point, nous avons donc simplement choisi un point central à introduire que j'aimerais l'appeler. Programmation orientée cœur (mon ami me l'a dit il y a longtemps), la programmation dite orientée cœur est simple et facile. Lorsque nous sommes impliqués dans une fonction, nous devons apprendre à démonter la fonction et à utiliser demo<. pour la fonction principale le code> est d'abord créé, puis enrichit lentement les zones environnantes pour compléter l'ensemble des exigences. </.>Enfin, parlons du protocole RESP. Le site officiel le résume comme suit : mise en œuvre simple, analyse rapide
directement lisible. Si vous étudiez attentivement ces deux articles, vous en aurez certainement une profonde compréhension.
Apprentissage recommandé : 🎜Tutoriel vidéo Redis🎜🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
