

Qu'est-ce que la mémoire en javascript

En JavaScript, la mémoire fait généralement référence à l'espace mémoire divisé (abstrait) par le système d'exploitation de la mémoire principale. La mémoire peut être divisée en deux catégories : 1. La mémoire de pile, qui est un espace mémoire continu de petite capacité, est principalement utilisée pour stocker des données telles que les informations d'appel de fonction et les variables. Un grand nombre d'opérations d'allocation de mémoire entraîneront un débordement de pile. ; 2. Mémoire tas, Il s'agit d'un grand espace mémoire. L'allocation de mémoire tas est dynamique et discontinue. Les programmes peuvent demander de l'espace mémoire tas à la demande, mais la vitesse d'accès est beaucoup plus lente que la mémoire pile.
L'environnement d'exploitation de ce tutoriel : système Windows 7, JavaScript version 1.8.5, ordinateur Dell G3.
JavaScript est né en 1995 et a été initialement conçu pour la validation de formulaires dans des pages Web.
JavaScript s'est développé rapidement au fil des années et son écosystème s'est développé de jour en jour, devenant l'un des langages de développement les plus populaires parmi les programmeurs. Désormais, JavaScript ne se limite plus à la page Web, mais s'étend aux ordinateurs de bureau, aux appareils mobiles et aux serveurs.
Avec l'avènement de la grande ère du front-end, de plus en plus de développeurs utilisent JavaScript, mais de nombreux développeurs n'en restent qu'au niveau "pouvoir l'utiliser" sans en connaître davantage sur ce langage.
Si vous souhaitez devenir un meilleur développeur JavaScript, comprendre la mémoire est un point clé qui ne peut être ignoré.
Cet article contient principalement deux parties :
Explication détaillée de la mémoire JavaScript
Guide d'analyse de la mémoire JavaScript
Après avoir lu cet article, je pense que vous aurez une compréhension plus complète de JavaScript mémoire Comprendre et être capable d'effectuer une analyse de la mémoire de manière indépendante.
Mémoire
Qu'est-ce que la mémoire
Je crois que tout le monde a une certaine compréhension de la mémoire, je ne commencerai pas par le début de Pangu, juste une petite mention .
Tout d’abord, aucune application ne peut fonctionner sans mémoire.
De plus, la mémoire que nous avons mentionnée a des significations différentes à différents niveaux.
Niveau matériel (Hardware)
Au niveau matériel, la mémoire fait référence à la mémoire vive.
La mémoire est une partie importante de l'ordinateur. Elle est utilisée pour stocker diverses données nécessaires au fonctionnement de l'application. Le processeur peut échanger directement des données avec la mémoire pour garantir le bon fonctionnement de l'application.
De manière générale, il existe deux principaux types de mémoire vive dans un ordinateur : le cache (Cache) et la mémoire principale (Main memory).
Le cache est généralement intégré directement à l'intérieur du CPU et est relativement éloigné de nous, donc le plus souvent la mémoire (matérielle) que nous mentionnons est la mémoire principale.
? Random Access Memory (Random Access Memory, RAM)
La mémoire vive est divisée en mémoire vive statique (Static Random Access Memory, SRAM) et mémoire vive dynamique (Dynamic Random Access Memory, DRAM) deux. grandes catégories.
En termes de vitesse, la SRAM est beaucoup plus rapide que la DRAM, et la vitesse de la SRAM est juste derrière les registres à l'intérieur du CPU.
Dans les ordinateurs modernes, la SRAM est utilisée pour le cache et la DRAM est utilisée pour la mémoire principale.
? Mémoire principale (Mémoire principale)
Bien que le cache soit très rapide, sa capacité de stockage est très faible, allant de quelques Ko à un maximum de dizaines de Mo, ce qui n'est pas suffisant pour stocker les opérations de l'application . données.
Nous avons besoin d'un composant de stockage avec une capacité de stockage et une vitesse modérées qui nous permettent d'exécuter des dizaines voire des centaines d'applications en même temps tout en garantissant les performances. C'est le rôle de la mémoire principale.
La mémoire principale de l'ordinateur est en fait ce que nous appelons habituellement la clé USB (matériel).
La mémoire matérielle n'est pas notre sujet aujourd'hui, c'est donc tout. Si vous souhaitez en savoir plus, vous pouvez effectuer une recherche selon les mots-clés mentionnés ci-dessus.
Niveau logiciel (Software)
Au niveau logiciel, la mémoire fait généralement référence à l'espace mémoire divisé (abstrait) par le système d'exploitation de la mémoire principale.
À l'heure actuelle, la mémoire peut être divisée en deux catégories : la mémoire de pile et la mémoire de tas.
Ensuite, j'expliquerai la mémoire autour du langage JavaScript.
La mémoire mentionnée dans les articles suivants fait référence à la mémoire au niveau logiciel.
Stack & Heap
Stack memory
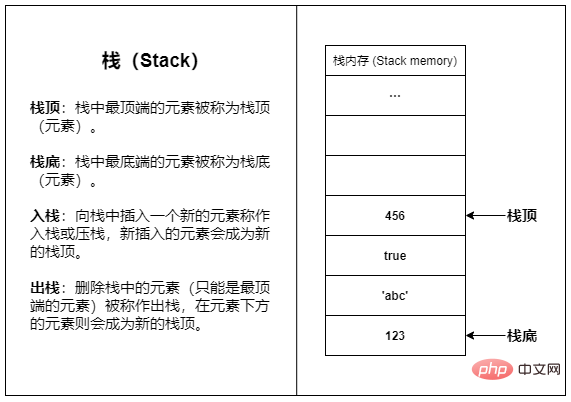
Stack (Stack)
Stack est une structure de données commune. , et toutes les données suivent le principe Last-In First-Out (LIFO).
L'exemple le plus approprié dans la vie réelle est le seau de badminton. Habituellement, nous n'accédons qu'à un côté du seau. Le premier badminton mis en place ne peut être retiré qu'en dernier, et le dernier mis en place sera le premier à être retiré. sortir.
La raison pour laquelle la mémoire de pile est appelée mémoire de pile est que la mémoire de pile utilise la structure de pile.
La mémoire de pile est un espace de mémoire continu. Grâce à la simplicité et à la simplicité de la structure de la pile, la vitesse d'accès et de fonctionnement de la mémoire de pile est très rapide.
La mémoire de la pile a une petite capacité et est principalement utilisée pour stocker des données telles que les informations d'appel de fonction et les variables. Un grand nombre d'opérations d'allocation de mémoire entraîneront un débordement de pile.
Le stockage des données dans la mémoire de la pile est fondamentalement temporaire et les données seront recyclées immédiatement après utilisation (par exemple, les variables locales créées dans une fonction seront recyclées après le retour de la fonction).
Pour faire simple : La mémoire pile est adaptée au stockage de données avec un cycle de vie court, un faible encombrement et des données fixes.
? La taille de la mémoire de la pile
La mémoire de la pile est directement gérée par le système d'exploitation, donc la taille de la mémoire de la pile est également déterminée par le système d'exploitation.
De manière générale, chaque thread (Thread) aura un espace mémoire de pile indépendant. La taille par défaut de la mémoire de pile allouée par Windows à chaque thread est de 1 Mo.
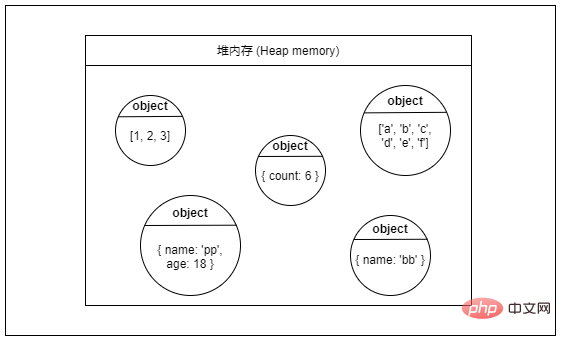
Heap memory
? Heap
Heap est également une structure de données courante, mais elle sort du cadre de cet article, donc je n'en dirai pas beaucoup plus.
Bien que la mémoire tas ait le mot « tas » dans son nom, cela n'a rien à voir avec le tas dans la structure de données. C'est juste un nom.
La mémoire tas est un grand espace mémoire. L'allocation de la mémoire tas est dynamique et discontinue. Les programmes peuvent demander de l'espace mémoire tas à la demande, mais la vitesse d'accès est beaucoup plus lente que la mémoire pile.
Les données dans la mémoire tas peuvent exister pendant une longue période. Les données inutiles doivent être activement recyclées par le programme. Si une grande quantité de données inutiles occupe de la mémoire, cela entraînera une fuite de mémoire.
En termes simples : La mémoire tas convient au stockage de données qui ont un long cycle de vie, occupent un grand espace ou occupent un espace irrégulier.
? Limite supérieure de la mémoire tas
Dans Node.js, la limite supérieure par défaut de la mémoire tas est d'environ 1,4 Go dans les systèmes 64 bits et de 0,7 Go dans les systèmes 32 bits.
Dans Chrome, la limite de mémoire par onglet est d'environ 4 Go (systèmes 64 bits) et 1 Go (systèmes 32 bits).
? Mémoire de processus, de thread et de tas
De manière générale, un processus (Process) n'aura qu'une seule mémoire de tas, et plusieurs threads sous le même processus partageront la même mémoire de tas.
Dans le navigateur Chrome, chaque onglet a généralement un processus distinct, mais dans certains cas, plusieurs onglets partagent un processus.
Appel de fonction
Après avoir compris ce que sont la mémoire de pile et la mémoire de tas, voyons maintenant ce qui arrive à la mémoire de pile et à la mémoire de tas lorsqu'une fonction est appelée.
Lorsqu'une fonction est appelée, elle sera poussée dans la mémoire de la pile pour générer un cadre de pile. Le cadre de pile peut être compris comme un bloc composé de l'adresse de retour, des paramètres et des variables locales de la fonction ; Lorsqu'une fonction est appelée, une autre fonction sera poussée dans la mémoire de la pile et le cycle recommencera ; jusqu'au retour de la dernière fonction, les éléments de la mémoire de la pile seront extraits un par un du haut de la pile, jusqu'à ce qu'il y en ait. plus d'éléments dans la mémoire de la pile. L'appel se termine.
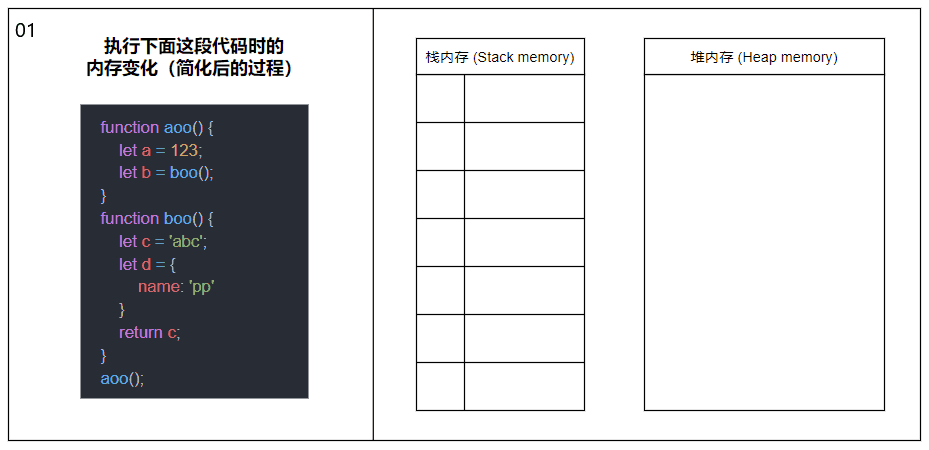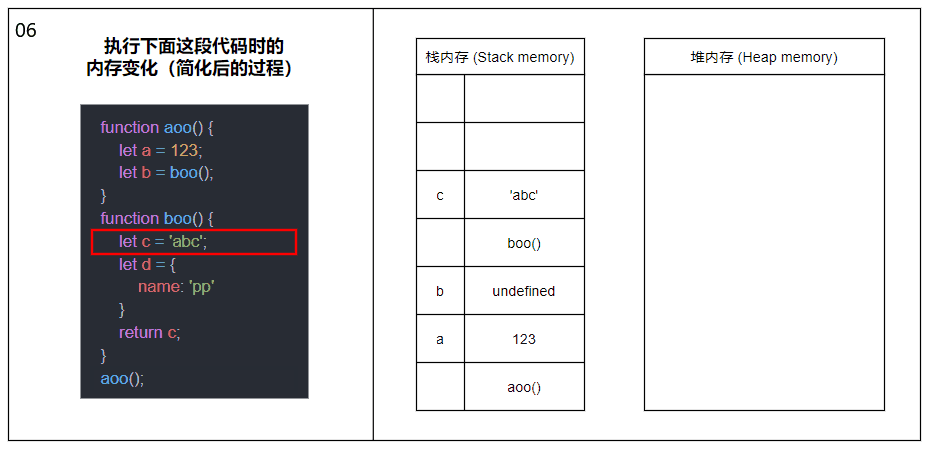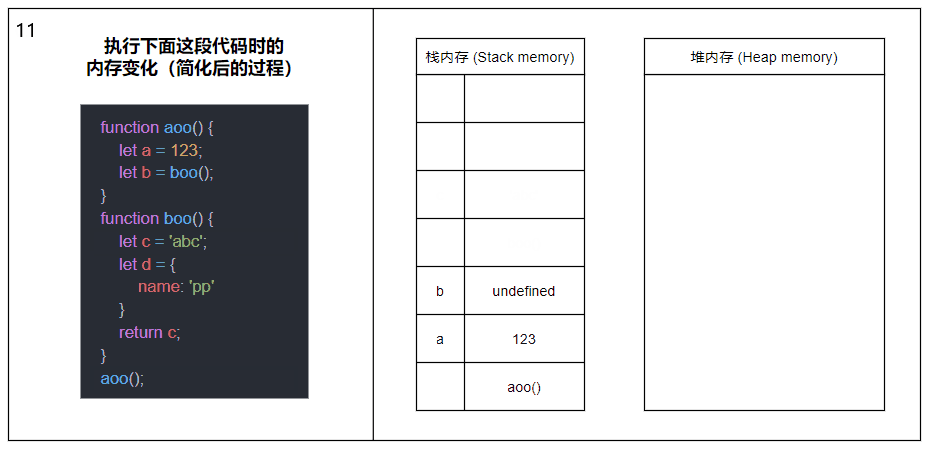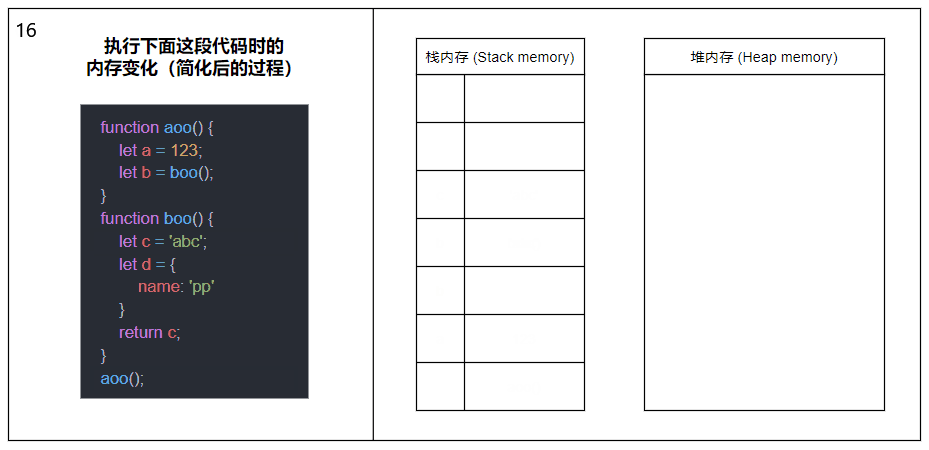
Le contenu de l'image ci-dessus a été simplifié, supprimant les concepts de cadres de pile et de divers pointeurs, et montrant principalement le processus général d'appel de fonction et d'allocation de mémoire.
Dans le même thread (JavaScript est monothread), toutes les fonctions exécutées, les paramètres de fonction et les variables locales seront poussés dans la même mémoire de pile. Cela signifie qu'un grand nombre de récursions entraîneront un débordement de pile.
Veuillez poursuivre votre lecture pour plus de détails sur l'allocation de mémoire des variables internes des fonctions impliquées dans l'image.
Store variables
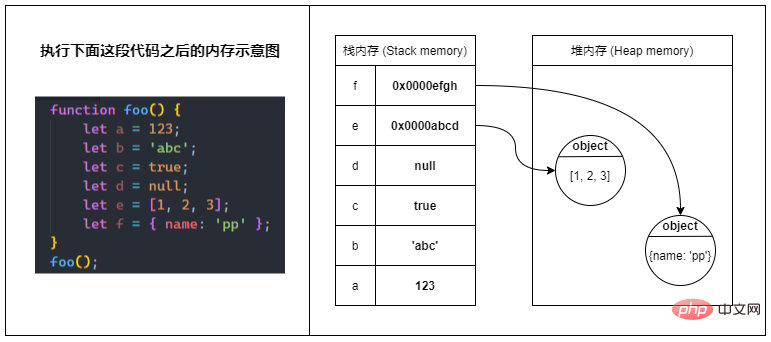
Lorsque le programme JavaScript est en cours d'exécution, les variables locales générées dans la portée non globale sont stockées dans la mémoire de la pile.
Cependant, seules les variables de type primitif stockent réellement les valeurs dans la mémoire de la pile.
Les variables de type référence stockent uniquement une référence (référence) dans la mémoire de la pile, et cette référence pointe vers la valeur réelle dans la mémoire du tas.
? Type primitif (Type primitif)
Les types primitifs sont également appelés types de base, y compris
string、number、bigint、boolean、undefined、null和symbol(nouveau dans ES6).Les valeurs des types primitifs sont appelées valeurs primitives.
Supplément : bien que
typeof nullrenvoie'object',nulln'est vraiment pas un objet. Un tel résultat est en fait causé par JavaScript. ~typeof null返回的是'object',但是null真的不是对象,会出现这样的结果其实是 JavaScript 的一个 Bug~
? 引用类型(Reference type)
除了原始类型外,其余类型都属于引用类型,包括
Object、Array、Function、Date、RegExp、String、Number、Boolean等等…实际上
Object是最基本的引用类型,其他引用类型均继承自Object。也就是说,所有引用类型的值实际上都是对象。引用类型的值被称为引用值(Reference value)。
? 简单来说
在多数情况下,原始类型的数据储存在Quest-ce que la mémoire en javascript,而引用类型的数据(对象)则储存在Quest-ce que la mémoire en javascript。
特别注意(Attention)
全局变量以及被闭包引用的变量(即使是原始类型)均储存在Quest-ce que la mémoire en javascript中。
? 全局变量(Global variables)
在全局作用域下创建的所有变量都会成为全局对象(如 window
Type de référence (Type de référence)
À l'exception des types primitifs, tous les autres types sont des types de référence, y comprisObject, Array, Fonction, Date, RegExp, String, Nombre, Booléen code> etc...En fait, Object est le type de référence le plus basique, et d'autres types de référence héritent de Object. Autrement dit, toutes les valeurs de type référence sont en réalité des objets.
? Pour faire simple
Dans la plupart des cas, les données de type primitif sont stockées dans la mémoire pile, tandis que les données de type référence (objets) sont stockées dans la mémoire tas.
Attention particulière (Attention )
Les variables globales et les variables référencées par des fermetures (même les types primitifs) sont stockées dans la mémoire tas.
? Variables globales
Toutes les variables créées dans la portée globale deviendront des attributs d'objets globaux (tels que les objets window), c'est-à-dire des variables globales.
Les objets globaux sont stockés dans la mémoire tas, les variables globales doivent donc également être stockées dans la mémoire tas.
Ne me demandez pas pourquoi les objets globaux sont stockés dans la mémoire tas, je vais tomber au bout d'un moment !
? FermeturesLes variables créées dans une fonction (portée locale) sont toutes des variables locales. Lorsqu'une variable locale est référencée par d'autres fonctions que la fonction actuelle (c'est-à-dire qu'un
escapese produit), alors la variable locale ne peut pas être recyclée avec le retour de la fonction actuelle, alors la variable doit être stockée dans le tas mémoire. Les "autres fonctions" ici sont ce que nous appelons des fermetures, tout comme l'exemple suivant :
function getCounter() {
let count = 0;
function counter() {
return ++count;
}
return counter;
}
// closure 是一个闭包函数
// 变量 count 发生了逃逸
let closure = getCounter();
closure(); // 1
closure(); // 2
closure(); // 3Apprenez les fermetures JavaScript : http://www.ruanyifeng.com/blog/2009/08/learning_javascript_closures.html
? analyse d'échappement pour décider si la variable doit être stockée dans la mémoire de pile ou dans la mémoire de tas.
En termes simples, l'analyse d'échappement est un mécanisme utilisé pour analyser la portée des variables.Immuable et Mutable
Deux types de données variables seront stockés dans la mémoire de la pile : la valeur d'origine et la référence d'objet.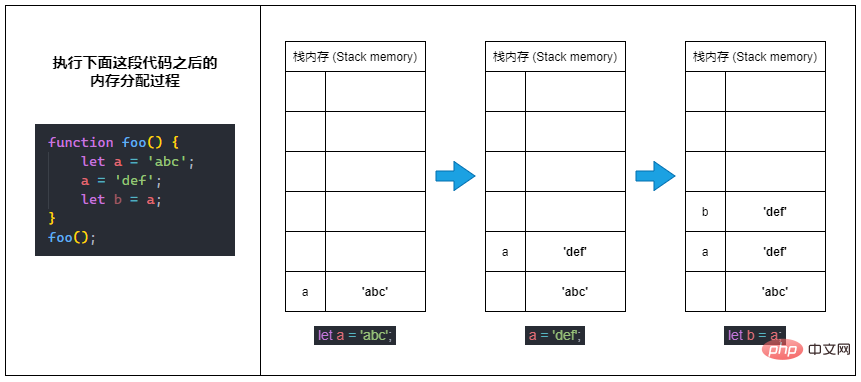 Non seulement les types sont différents, mais leurs performances spécifiques en mémoire de pile sont également différentes.
Non seulement les types sont différents, mais leurs performances spécifiques en mémoire de pile sont également différentes.
Valeurs primitives
? Les valeurs primitives sont immuables !
Comme mentionné précédemment : les données de type primitif (valeurs primitives) sont stockées directement dans la mémoire de la pile.
⑴Lorsque nous définissons une variable de type primitif, JavaScript va activer une mémoire dans la mémoire de la pile pour stocker la valeur de la variable (valeur d'origine).
⑵ Lorsque nous modifions la valeur d'une variable de type primitif,
activera en fait une nouvelle mémoire pour stocker la nouvelle valeur et pointera la variable vers le nouvel espace mémoireau lieu de modifier la valeur de la mémoire d'origine.
⑶ Lorsque nous attribuons une variable de type primitif à une autre nouvelle variable (c'est-à-dire une variable de copie), une nouvelle mémoire sera activée et une copie de la valeur dans la mémoire de la variable source sera copiée dans la nouvelle variable. en mémoire . ? En bref :
La valeur d'origine dans la mémoire de la pile ne peut pas être modifiée (immuable) une fois déterminée.Comparaison des valeurs originales (Comparaison)
🎜Lorsque nous comparons des variables de type primitif, nous comparerons directement les valeurs dans la mémoire de la pile Tant que les valeurssont égales, elles. sont égaux. 🎜🎜🎜🎜Références d'objet🎜🎜🎜 ? 🎜Les références d'objet sont mutables !🎜🎜🎜Comme mentionné précédemment : les variables de type référence stockent uniquement une référence à la mémoire de tas dans la mémoire de la pile. 🎜🎜🎜⑴🎜 Lorsque nous définissons une variable de type référence, JavaScript va d'abord 🎜trouver un endroit approprié dans la mémoire tas pour stocker l'objet🎜, et 🎜activer un morceau de mémoire pile pour stocker la référence de l'objet (mémoire tas adresse)🎜 , et enfin 🎜pointez la variable vers cette pile mémoire🎜. 🎜🎜🎜 ? Ainsi, lorsque nous accédons à un objet via une variable, le processus d'accès réel doit être : 🎜🎜🎜Variable ->let a = '123'; let b = '123'; let c = '110'; let d = 123; console.log(a === b); // true console.log(a === c); // false console.log(a === d); // falseCopier après la connexion
⑵ 当我们把引用类型变量赋值给另一个变量时,会将源变量指向的Quest-ce que la mémoire en javascript中的对象引用复制到新变量的Quest-ce que la mémoire en javascript中,所以实际上只是复制了个对象引用,并没有在Quest-ce que la mémoire en javascript中生成一份新的对象。
⑶ 而当我们给引用类型变量分配为一个新的对象时,则会直接修改变量指向的Quest-ce que la mémoire en javascript中的引用,新的引用指向Quest-ce que la mémoire en javascript中新的对象。
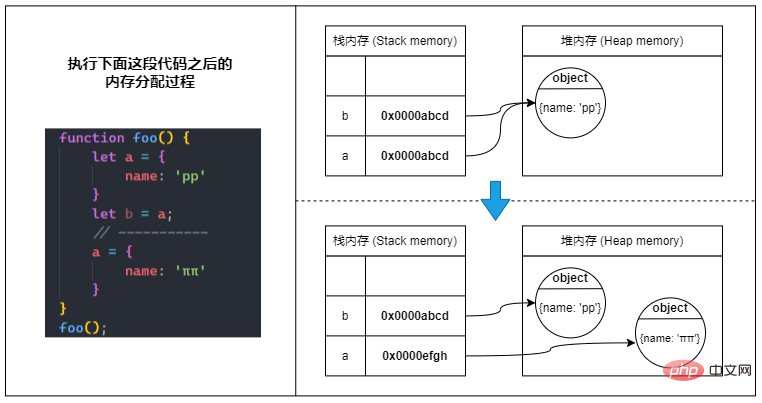
? 总之就是:Quest-ce que la mémoire en javascript中的对象引用是可以被更改的(可变的)。
对象的比较(Comparison)
所有引用类型的值实际上都是对象。
当我们比较引用类型的变量时,实际上是在比较Quest-ce que la mémoire en javascript中的引用,只有引用相同时变量才相等。
即使是看起来完全一样的两个引用类型变量,只要他们的引用的不是同一个值,那么他们就是不一样。
// 两个变量指向的是两个不同的引用
// 虽然这两个对象看起来完全一样
// 但它们确确实实是不同的对象实例
let a = { name: 'pp' }
let b = { name: 'pp' }
console.log(a === b); // false
// 直接赋值的方式复制的是对象的引用
let c = a;
console.log(a === c); // true对象的深拷贝(Deep copy)
当我们搞明白引用类型变量在内存中的表现时,就能清楚地理解为什么浅拷贝对象是不可靠的。
在浅拷贝中,简单的赋值只会复制对象的引用,实际上新变量和源变量引用的都是同一个对象,修改时也是修改的同一个对象,这显然不是我们想要的。
想要真正的复制一个对象,就必须新建一个对象,将源对象的属性复制过去;如果遇到引用类型的属性,那就再新建一个对象,继续复制…
此时我们就需要借助递归来实现多层次对象的复制,这也就是我们说的深拷贝。
对于任何引用类型的变量,都应该使用深拷贝来复制,除非你很确定你的目的就是复制一个引用。
内存生命周期(Memory life cycle)
通常来说,所有应用程序的内存生命周期都是基本一致的:
分配 -> 使用 -> 释放
当我们使用高级语言编写程序时,往往不会涉及到内存的分配与释放操作,因为分配与释放均已经在底层语言中实现了。
对于 JavaScript 程序来说,内存的分配与释放是由 JavaScript 引擎自动完成的(目前的 JavaScript 引擎基本都是使用 C++ 或 C 编写的)。
但是这不意味着我们就不需要在乎内存管理,了解内存的更多细节可以帮助我们写出性能更好,稳定性更高的代码。
垃圾回收(Garbage collection)
垃圾回收即我们常说的 GC(Garbage collection),也就是清除内存中不再需要的数据,释放内存空间。
由于Quest-ce que la mémoire en javascript由操作系统直接管理,所以当我们提到 GC 时指的都是Quest-ce que la mémoire en javascript的垃圾回收。
基本上现在的浏览器的 JavaScript 引擎(如 V8 和 SpiderMonkey)都实现了垃圾回收机制,引擎中的垃圾回收器(Garbage collector)会定期进行垃圾回收。
? 紧急补课
在我们继续之前,必须先了解“可达性”和“内存泄露”这两个概念:
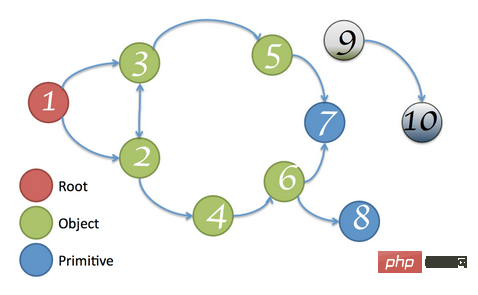
? 可达性(Reachability)
在 JavaScript 中,可达性指的是一个变量是否能够直接或间接通过全局对象访问到,如果可以那么该变量就是可达的(Reachable),否则就是不可达的(Unreachable)。
上图中的节点 9 和节点 10 均无法通过节点 1(根节点)直接或间接访问,所以它们都是不可达的,可以被安全地回收。
? 内存泄漏(Memory leak)
内存泄露指的是程序运行时由于某种原因未能释放那些不再使用的内存,造成内存空间的浪费。
轻微的内存泄漏或许不太会对程序造成什么影响,但是一旦泄露变严重,就会开始影响程序的性能,甚至导致程序的崩溃。
垃圾回收算法(Algorithms)
垃圾回收的基本思路很简单:确定哪个变量不会再使用,然后释放它占用的内存。
实际上,在回收过程中想要确定一个变量是否还有用并不简单。
直到现在也还没有一个真正完美的垃圾回收算法,接下来介绍 3 种最广为人知的垃圾回收算法。
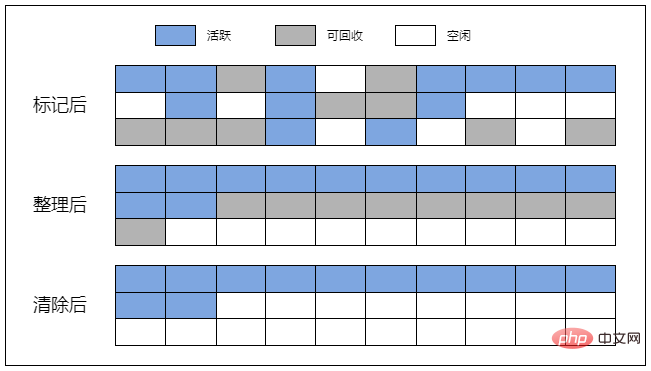
标记-清除(Mark-and-Sweep)
标记清除算法是目前最常用的垃圾收集算法之一。
从该算法的名字上就可以看出,算法的关键就是标记与清除。
标记指的是标记变量的状态的过程,标记变量的具体方法有很多种,但是基本理念是相似的。
对于标记算法我们不需要知道所有细节,只需明白标记的基本原理即可。
需要注意的是,这个算法的效率不算高,同时会引起内存碎片化的问题。
? 举个栗子
当一个变量进入执行上下文时,它就会被标记为“处于上下文中”;而当变量离开执行上下文时,则会被标记为“已离开上下文”。
? 执行上下文(Execution context)
执行上下文是 JavaScript 中非常重要的概念,简单来说的是代码执行的环境。
如果你现在对于执行上下文还不是很了解,我强烈建议你抽空专门去学习下!!!
垃圾回收器将定期扫描内存中的所有变量,将处于上下文中以及被处于上下文中的变量引用的变量的标记去除,将其余变量标记为“待删除”。
随后,垃圾回收器会清除所有带有“待删除”标记的变量,并释放它们所占用的内存。
标记-整理(Mark-Compact)
准确来说,Compact 应译为紧凑、压缩,但是在这里我觉得用“整理”更为贴切。
标记整理算法也是常用的垃圾收集算法之一。
使用标记整理算法可以解决内存碎片化的问题(通过整理),提高内存空间的可用性。
但是,该算法的标记阶段比较耗时,可能会堵塞主线程,导致程序长时间处于无响应状态。
虽然算法的名字上只有标记和整理,但这个算法通常有 3 个阶段,即标记、整理与清除。
? 以 V8 的标记整理算法为例
① 首先,在标记阶段,垃圾回收器会从全局对象(根)开始,一层一层往下查询,直到标记完所有活跃的对象,那么剩下的未被标记的对象就是不可达的了。
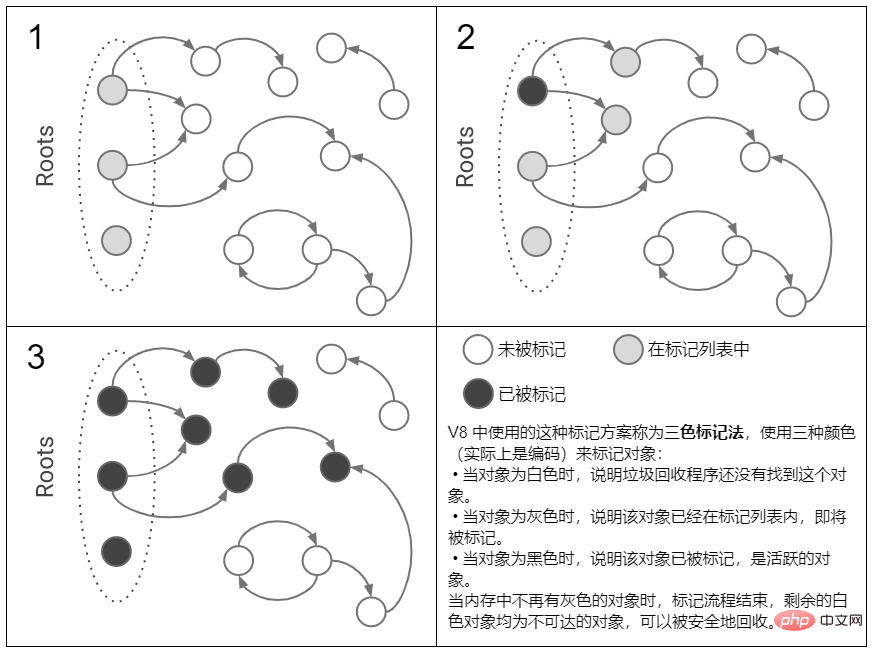
② 然后是整理阶段(碎片整理),垃圾回收器会将活跃的(被标记了的)对象往内存空间的一端移动,这个过程可能会改变内存中的对象的内存地址。
③ 最后来到清除阶段,垃圾回收器会将边界后面(也就是最后一个活跃的对象后面)的对象清除,并释放它们占用的内存空间。
引用计数(Reference counting)
引用计数算法是基于“引用计数”实现的垃圾回收算法,这是最初级但已经被弃用的垃圾回收算法。
引用计数算法需要 JavaScript 引擎在程序运行时记录每个变量被引用的次数,随后根据引用的次数来判断变量是否能够被回收。
虽然垃圾回收已不再使用引用计数算法,但是引用计数技术仍非常有用!
? 举个栗子
注意:垃圾回收不是即使生效的!但是在下面的例子中我们将假设回收是立即生效的,这样会更好理解~
// 下面我将 name 属性为 ππ 的对象简称为 ππ
// 而 name 属性为 pp 的对象则简称为 pp
// ππ 的引用:1,pp 的引用:1
let a = {
name: 'ππ',
z: {
name: 'pp'
}
}
// b 和 a 都指向 ππ
// ππ 的引用:2,pp 的引用:1
let b = a;
// x 和 a.z 都指向 pp
// ππ 的引用:2,pp 的引用:2
let x = a.z;
// 现在只有 b 还指向 ππ
// ππ 的引用:1,pp 的引用:2
a = null;
// 现在 ππ 没有任何引用了,可以被回收了
// 在 ππ 被回收后,pp 的引用也会相应减少
// ππ 的引用:0,pp 的引用:1
b = null;
// 现在 pp 也可以被回收了
// ππ 的引用:0,pp 的引用:0
x = null;
// 哦豁,这下全完了!? 循环引用(Circular references)
引用计数算法看似很美好,但是它有一个致命的缺点,就是无法处理循环引用的情况。
在下方的例子中,当 foo() 函数执行完毕之后,对象 a 与 b 都已经离开了作用域,理论上它们都应该能够被回收才对。
但是由于它们互相引用了对方,所以垃圾回收器就认为他们都还在被引用着,导致它们哥俩永远都不会被回收,这就造成了内存泄露。
function foo() {
let a = { o: null };
let b = { o: null };
a.o = b;
b.o = a;
}
foo();
// 即使 foo 函数已经执行完毕
// 对象 a 和 b 均已离开函数作用域
// 但是 a 和 b 还在互相引用
// 那么它们这辈子都不会被回收了
// Oops!内存泄露了!V8 中的垃圾回收(GC in V8)
8️⃣ V8
V8 是一个由 Google 开源的用 C++ 编写的高性能 JavaScript 引擎。
V8 是目前最流行的 JavaScript 引擎之一,我们熟知的 Chrome 浏览器和 Node.js 等软件都在使用 V8。
在 V8 的内存管理机制中,把Quest-ce que la mémoire en javascript(Heap memory)划分成了多个区域。
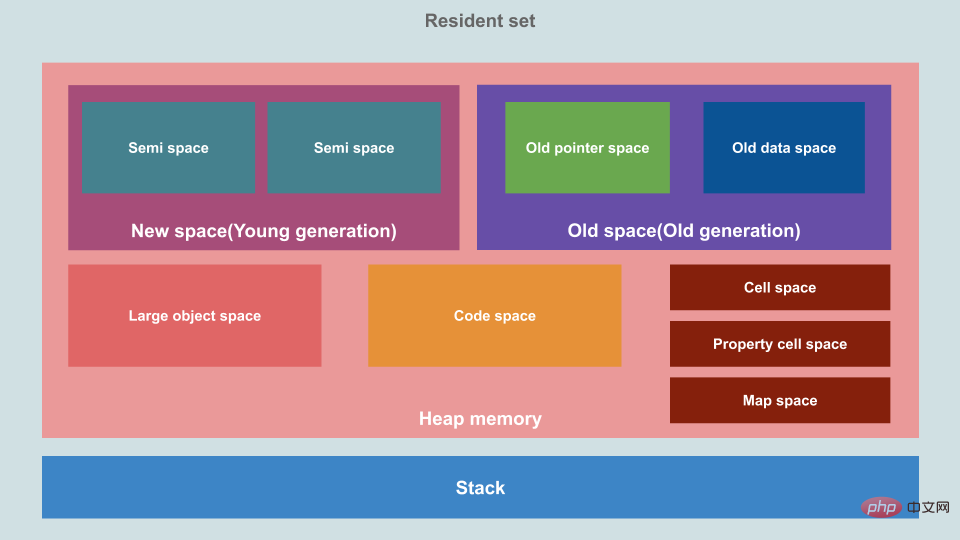
这里我们只关注这两个区域:
- New Space(新空间):又称 Young generation(新世代),用于储存新生成的对象,由 Minor GC 进行管理。
- Old Space(旧空间):又称 Old generation(旧世代),用于储存那些在两次 GC 后仍然存活的对象,由 Major GC 进行管理。
也就是说,只要 New Space 里的对象熬过了两次 GC,就会被转移到 Old Space,变成老油条。
? 双管齐下
V8 内部实现了两个垃圾回收器:
- Minor GC(副 GC):它还有个名字叫做 Scavenger(清道夫),具体使用的是 Cheney’s Algorithm(Cheney 算法)。
- Major GC(主 GC):使用的是文章前面提到的 Mark-Compact Algorithm(标记-整理算法)。
储存在 New Space 里的新生对象大多都只是临时使用的,而且 New Space 的容量比较小,为了保持内存的可用率,Minor GC 会频繁地运行。
而 Old Space 里的对象存活时间都比较长,所以 Major GC 没那么勤快,这一定程度地降低了频繁 GC 带来的性能损耗。
? 加点魔法
我们在上方的“标记整理算法”中有提到这个算法的标记过程非常耗时,所以很容易导致应用长时间无响应。
为了提升用户体验,V8 还实现了一个名为Quest-ce que la mémoire en javascript(Incremental marking)的特性。
Quest-ce que la mémoire en javascript的要点就是把标记工作分成多个小段,夹杂在主线程(Main thread)的 JavaScript 逻辑中,这样就不会长时间阻塞主线程了。
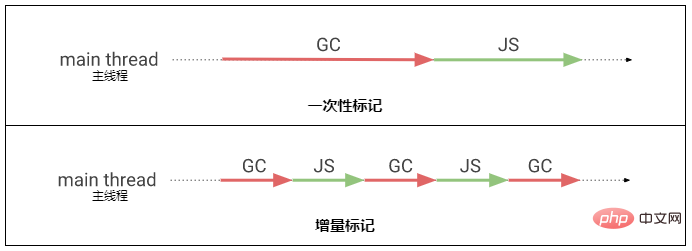
当然Quest-ce que la mémoire en javascript也有代价的,在Quest-ce que la mémoire en javascript过程中所有对象的变化都需要通知垃圾回收器,好让垃圾回收器能够正确地标记那些对象,这里的“通知”也是需要成本的。
另外 V8 中还有使用工作线程(Worker thread)实现的平行标记(Parallel marking)和并行标记(Concurrent marking),这里我就不再细说了~
? 总结一下
为了提升性能和用户体验,V8 内部做了非常非常多的“骚操作”,本文提到的都只是冰山一角,但足以让我五体投地佩服连连!
总之就是非常 Amazing 啊~
内存管理(Memory management)
或者说是:内存优化(Memory optimization)?
虽然我们写代码的时候一般不会直接接触内存管理,但是有一些注意事项可以让我们避免引起内存问题,甚至提升代码的性能。
全局变量(Global variable)
全局变量的访问速度远不及局部变量,应尽量避免定义非必要的全局变量。
在我们实际的项目开发中,难免会需要去定义一些全局变量,但是我们必须谨慎使用全局变量。
因为全局变量永远都是可达的,所以全局变量永远不会被回收。
? 还记得“可达性”这个概念吗?
因为全局变量直接挂载在全局对象上,也就是说全局变量永远都可以通过全局对象直接访问。
所以全局变量永远都是可达的,而可达的变量永远都不会被回收。
? 应该怎么做?
当一个全局变量不再需要用到时,记得解除其引用(置空),好让垃圾回收器可以释放这部分内存。
// 全局变量不会被回收
window.me = {
name: '吴彦祖',
speak: function() {
console.log(`我是${this.name}`);
}
};
window.me.speak();
// 解除引用后才可以被回收
window.me = null;隐藏类(HiddenClass)
实际上的隐藏类远比本文所提到的复杂,但是今天的主角不是它,所以我们点到为止。
在 V8 内部有一个叫做“隐藏类”的机制,主要用于提升对象(Object)的性能。
V8 里的每一个 JS 对象(JS Objects)都会关联一个隐藏类,隐藏类里面储存了对象的形状(特征)和属性名称到属性的映射等信息。
隐藏类内记录了每个属性的内存偏移(Memory offset),后续访问属性的时候就可以快速定位到对应属性的内存位置,从而提升对象属性的访问速度。
在我们创建对象时,拥有完全相同的特征(相同属性且相同顺序)的对象可以共享同一个隐藏类。
? 再想象一下
我们可以把隐藏类想象成工业生产中使用的模具,有了模具之后,产品的生产效率得到了很大的提升。
但是如果我们更改了产品的形状,那么原来的模具就不能用了,又需要制作新的模具才行。
? 举个栗子
在 Chrome 浏览器 Devtools 的 Console 面板中执行以下代码:
// 对象 A
let objectA = {
id: 'A',
name: '吴彦祖'
};
// 对象 B
let objectB = {
id: 'B',
name: '彭于晏'
};
// 对象 C
let objectC = {
id: 'C',
name: '刘德华',
gender: '男'
};
// 对象 A 和 B 拥有完全相同的特征
// 所以它们可以使用同一个隐藏类
// good!随后在 Memory 面板打一个堆快照,通过堆快照中的 Comparison 视图可以快速找到上面创建的 3 个对象:
注:关于如何查看内存中的对象将会在文章的第二大部分中进行讲解,现在让我们专注于隐藏类。

在上图中可以很清楚地看到对象 A 和 B 确实使用了同一个隐藏类。
而对象 C 因为多了一个 gender 属性,所以不能和前面两个对象共享隐藏类。
? 动态增删对象属性
一般情况下,当我们动态修改对象的特征(增删属性)时,V8 会为该对象分配一个能用的隐藏类或者创建一个新的隐藏类(新的分支)。
例如动态地给对象增加一个新的属性:
注:这种操作被称为“先创建再补充(ready-fire-aim)”。
// 增加 gender 属性 objectB.gender = '男'; // 对象 B 的特征发生了变化 // 多了一个原本没有的 gender 属性 // 导致对象 B 不能再与 A 共享隐藏类 // bad!
动态删除(delete)对象的属性也会导致同样的结果:
// 删除 name 属性 delete objectB.name; // A:我们不一样! // bad!
不过,添加数组索引属性(Array-indexed properties)并不会有影响:
其实就是用整数作为属性名,此时 V8 会另外处理。
// 增加 1 属性 objectB[1] = '数字组引属性'; // 不影响共享隐藏类 // so far so good!
? 那问题来了
说了这么多,隐藏类看起来确实可以提升性能,那它和内存又有什么关系呢?
实际上,隐藏类也需要占用内存空间,这其实就是一种用空间换时间的机制。
如果由于动态增删对象属性而创建了大量隐藏类和分支,结果就是会浪费不少内存空间。
? 举个栗子
创建 1000 个拥有相同属性的对象,内存中只会多出 1 个隐藏类。
而创建 1000 个属性信息完全不同的对象,内存中就会多出 1000 个隐藏类。
? 应该怎么做?
所以,我们要尽量避免动态增删对象属性操作,应该在构造函数内就一次性声明所有需要用到的属性。
如果确实不再需要某个属性,我们可以将属性的值设为 null,如下:
// 将 age 属性置空 objectB.age = null; // still good!
另外,相同名称的属性尽量按照相同的顺序来声明,可以尽可能地让更多对象共享相同的隐藏类。
即使遇到不能共享隐藏类的情况,也至少可以减少隐藏类分支的产生。
其实动态增删对象属性所引起的性能问题更为关键,但因本文篇幅有限,就不再展开了。
闭包(Closure)
前面有提到:被闭包引用的变量储存在Quest-ce que la mémoire en javascript中。
这里我们再重点关注一下闭包中的内存问题,还是前面的例子:
function getCounter() {
let count = 0;
function counter() {
return ++count;
}
return counter;
}
// closure 是一个闭包函数
let closure = getCounter();
closure(); // 1
closure(); // 2
closure(); // 3现在只要我们一直持有变量(函数) closure,那么变量 count 就不会被释放。
或许你还没有发现风险所在,不如让我们试想变量 count 不是一个数字,而是一个巨大的数组,一但这样的闭包多了,那对于内存来说就是灾难。
// 我将这个作品称为:闭包炸弹
function closureBomb() {
const handsomeBoys = [];
setInterval(() => {
for (let i = 0; i < 100; i++) {
handsomeBoys.push(
{ name: '陈皮皮', rank: 0 },
{ name: ' 你 ', rank: 1 },
{ name: '吴彦祖', rank: 2 },
{ name: '彭于晏', rank: 3 },
{ name: '刘德华', rank: 4 },
{ name: '郭富城', rank: 5 }
);
}
}, 100);
}
closureBomb();
// 即将毁灭世界
// ? ? ? ?? 应该怎么做?
所以,我们必须避免滥用闭包,并且谨慎使用闭包!
当不再需要时记得解除闭包函数的引用,让闭包函数以及引用的变量能够被回收。
closure = null; // 变量 count 终于得救了
如何分析内存(Analyze)
说了这么多,那我们应该如何查看并分析程序运行时的内存情况呢?
“工欲善其事,必先利其器。”
对于 Web 前端项目来说,分析内存的最佳工具非 Memory 莫属!
这里的 Memory 指的是 DevTools 中的一个工具,为了避免混淆,下面我会用“Memory 面板”或”内存面板“代称。
? DevTools(开发者工具)
DevTools 是浏览器里内置的一套用于 Web 开发和调试的工具。
使用 Chromuim 内核的浏览器都带有 DevTools,个人推荐使用 Chrome 或者 Edge(新)。
Memory in Devtools(内存面板)
在我们切换到 Memory 面板后,会看到以下界面(注意标注):
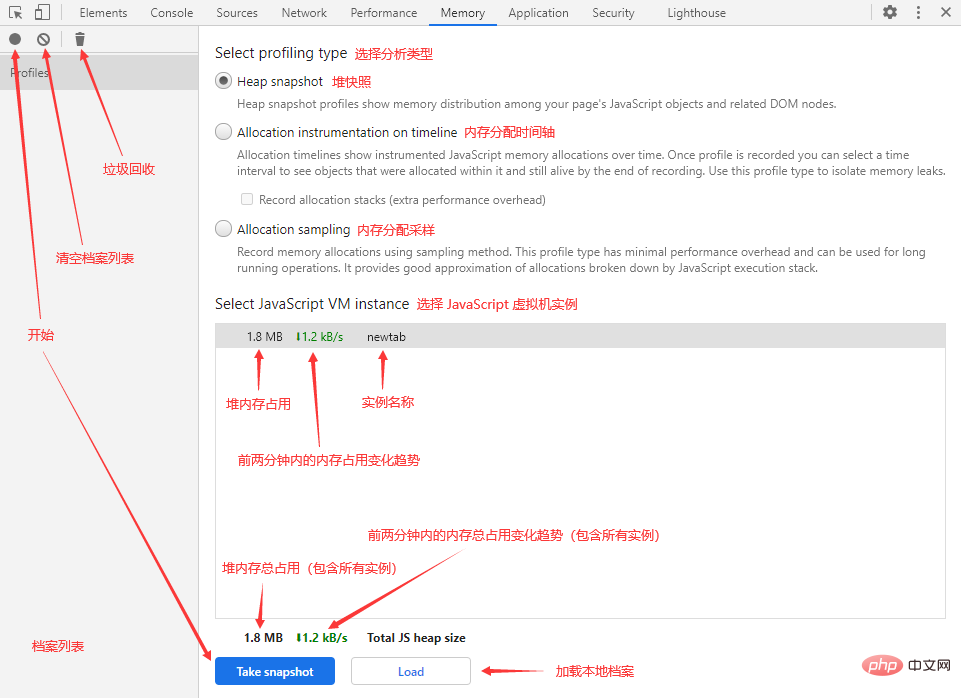
在这个面板中,我们可以通过 3 种方式来记录内存情况:
- Heap snapshot:堆快照
- Allocation instrumentation on timeline:内存分配时间轴
- Allocation sampling:内存分配采样
小贴士:点击面板左上角的 Collect garbage 按钮(垃圾桶图标)可以主动触发垃圾回收。
? 在正式开始分析内存之前,让我们先学习几个重要的概念:
? Shallow Size(浅层大小)
浅层大小指的是当前对象自身占用的内存大小。
浅层大小不包含自身引用的对象。
? Retained Size(保留大小)
保留大小指的是当前对象被 GC 回收后总共能够释放的内存大小。
换句话说,也就是当前对象自身大小加上对象直接或间接引用的其他对象的大小总和。
需要注意的是,保留大小不包含那些除了被当前对象引用之外还被全局对象直接或间接引用的对象。
Heap snapshot(堆快照)
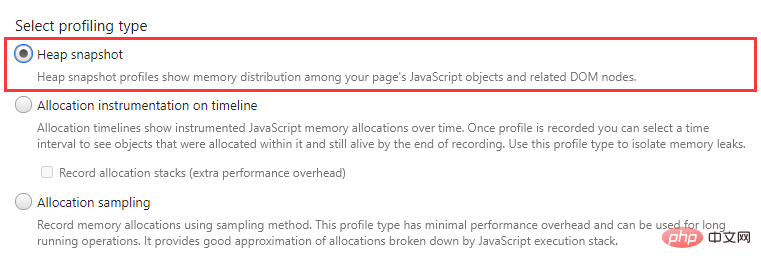
堆快照可以记录页面当前时刻的 JS 对象以及 DOM 节点的内存分配情况。
? 如何开始
点击页面底部的 Take snapshot 按钮或者左上角的 ⚫ 按钮即可打一个堆快照,片刻之后就会自动展示结果。
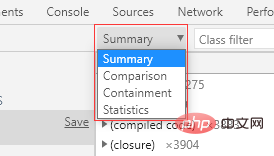
在堆快照结果页面中,我们可以使用 4 种不同的视图来观察内存情况:
- Summary:摘要视图
- Comparison:比较视图
- Containment:包含视图
- Statistics:统计视图
默认显示 Summary 视图。
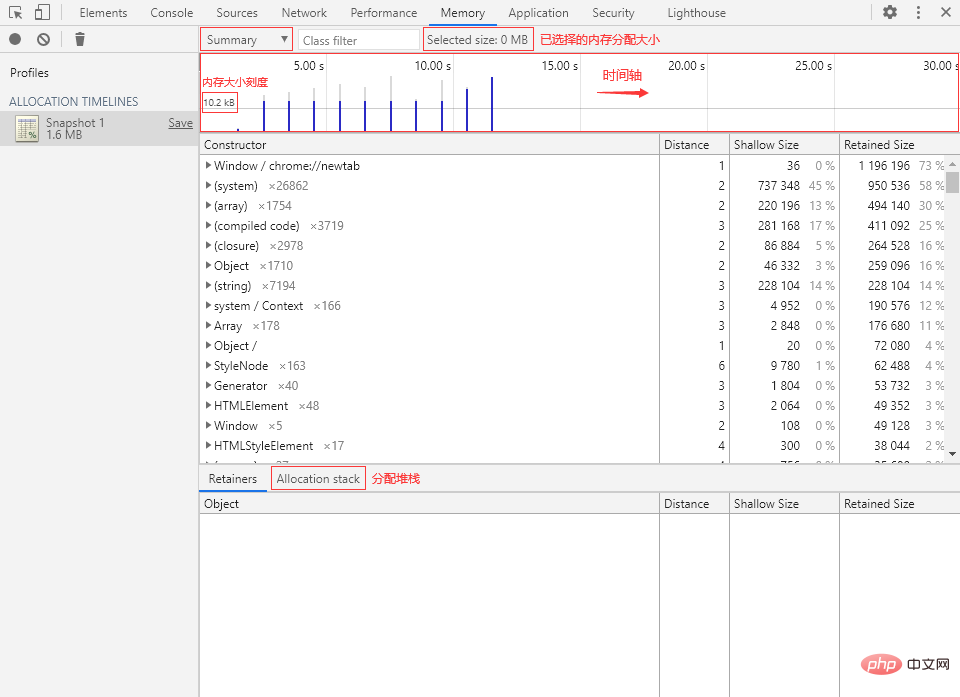
Summary(摘要视图)
摘要视图根据 Constructor(构造函数)来将对象进行分组,我们可以在 Class filter(类过滤器)中输入构造函数名称来快速筛选对象。
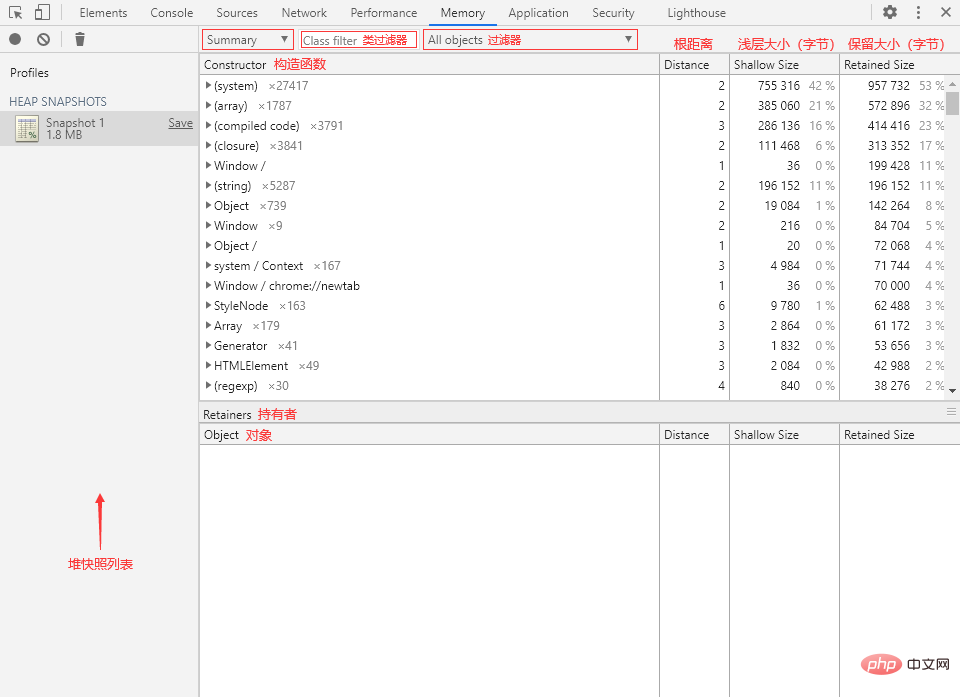
页面中的几个关键词:
- Constructor:构造函数。
- Distance:(根)距离,对象与 GC 根之间的最短距离。
- Shallow Size:浅层大小,单位:Bytes(字节)。
- Retained Size:保留大小,单位:Bytes(字节)。
- Retainers:持有者,也就是直接引用目标对象的变量。
? Retainers(持有者)
Retainers 栏在旧版的 Devtools 里叫做 Object’s retaining tree(对象保留树)。
Retainers 下的对象也展开为树形结构,方便我们进行引用溯源。
在视图中的构造函数列表中,有一些用“()”包裹的条目:
- (compiled code):已编译的代码。
- (closure):闭包函数。
- (array, string, number, symbol, regexp):对应类型(
Array、String、Number、Symbol、RegExp)的数据。 - (concatenated string):使用
concat()函数拼接而成的字符串。 - (sliced string):使用
slice()、substring()等函数进行边缘切割的字符串。 - (system):系统(引擎)产生的对象,如 V8 创建的 HiddenClasses(隐藏类)和 DescriptorArrays(描述符数组)等数据。
? DescriptorArrays(描述符数组)
描述符数组主要包含对象的属性名信息,是隐藏类的重要组成部分。
不过描述符数组内不会包含整数索引属性。
而其余没有用“()”包裹的则为全局属性和 GC 根。
另外,每个对象后面都会有一串“@”开头的数字,这是对象在内存中的唯一 ID。
小贴士:按下快捷键 Ctrl/Command + F 展示搜索栏,输入名称或 ID 即可快速查找目标对象。
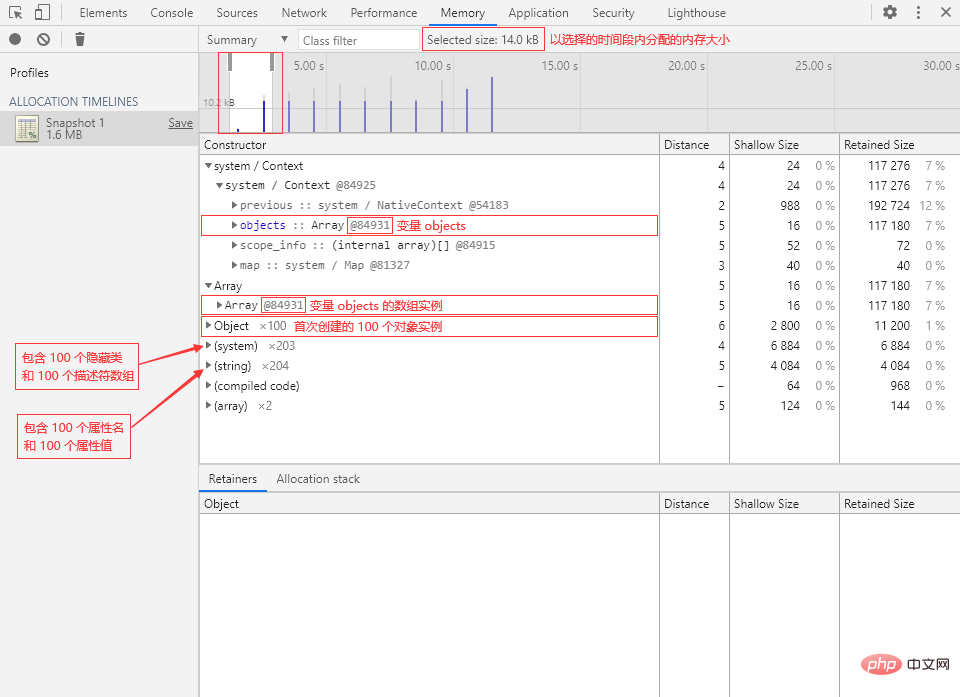
? 实践一下:Quest-ce que la mémoire en javascript
① 切换到 Console 面板,执行以下代码来Quest-ce que la mémoire en javascript:
function TestClass() {
this.number = 123;
this.string = 'abc';
this.boolean = true;
this.symbol = Symbol('test');
this.undefined = undefined;
this.null = null;
this.object = { name: 'pp' };
this.array = [1, 2, 3];
this.getSet = {
_value: 0,
get value() {
return this._value;
},
set value(v) {
this._value = v;
}
};
}
let testObject = new TestClass();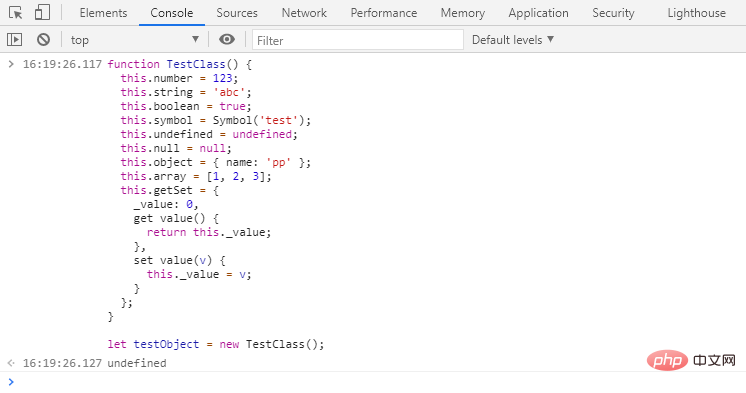
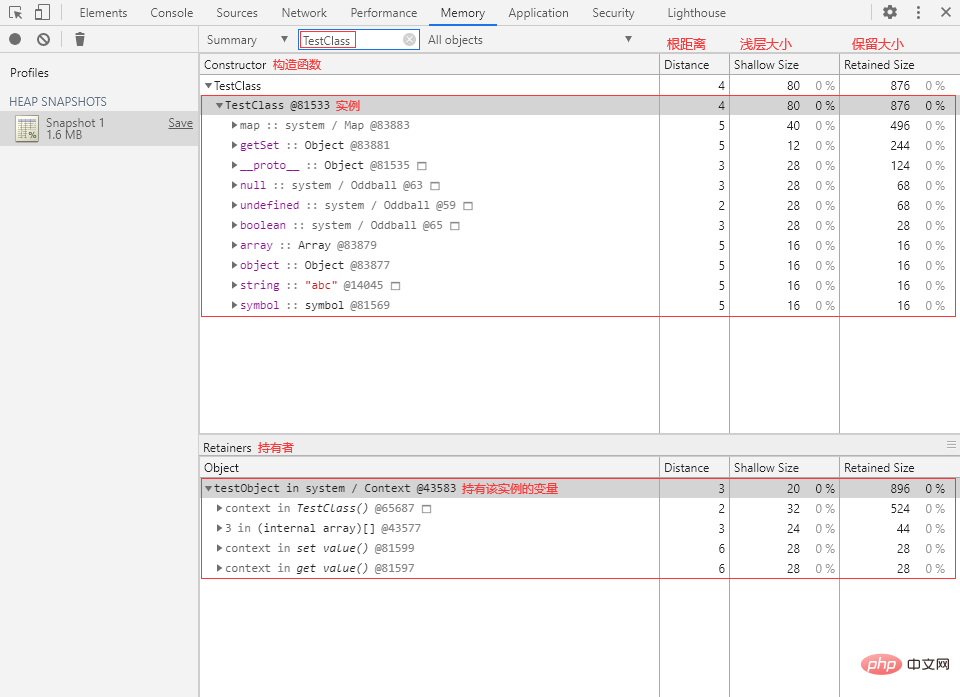
② 回到 Memory 面板,打一个堆快照,在 Class filter 中输入“TestClass”:
可以看到内存中有一个 TestClass 的实例,该实例的浅层大小为 80 字节,保留大小为 876 字节。
? 注意到了吗?
堆快照中的
TestClass实例的属性中少了一个名为number属性,这是因为堆快照不会捕捉数字属性。
? 实践一下:创建一个字符串
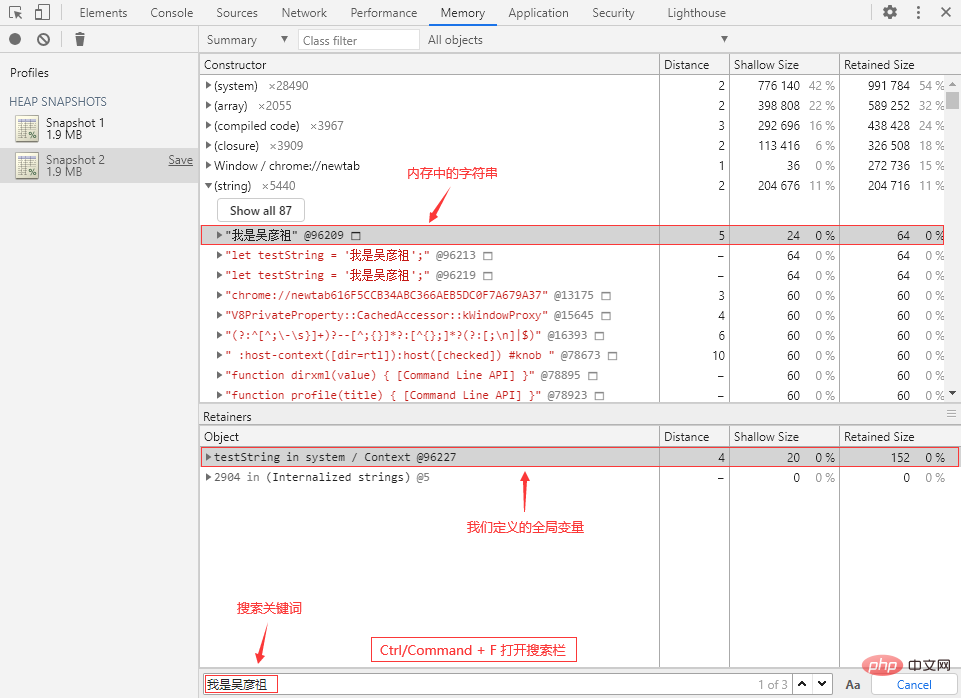
① 切换到 Console 面板,执行以下代码来创建一个字符串:
// 这是一个全局变量 let testString = '我是吴彦祖';
② 回到 Memory 面板,打一个堆快照,打开搜索栏(Ctrl/Command + F)并输入“我是吴彦祖”:
Comparison(比较视图)
只有同时存在 2 个或以上的堆快照时才会出现 Comparison 选项。
比较视图用于展示两个堆快照之间的差异。
使用比较视图可以让我们快速得知在执行某个操作后的内存变化情况(如新增或减少对象)。
通过多个快照的对比还可以让我们快速判断并定位内存泄漏。
文章前面提到隐藏类的时候,就是使用了比较视图来快速查找新创建的对象。
? 实践一下
① 新建一个无痕(匿名)标签页并切换到 Memory 面板,打一个堆快照 Snapshot 1。
? 为什么是无痕标签页?
普通标签页会受到浏览器扩展或者其他脚本影响,内存占用不稳定。
使用无痕窗口的标签页可以保证页面的内存相对纯净且稳定,有利于我们进行对比。
另外,建议打开窗口一段之间之后再开始测试,这样内存会比较稳定(控制变量)。
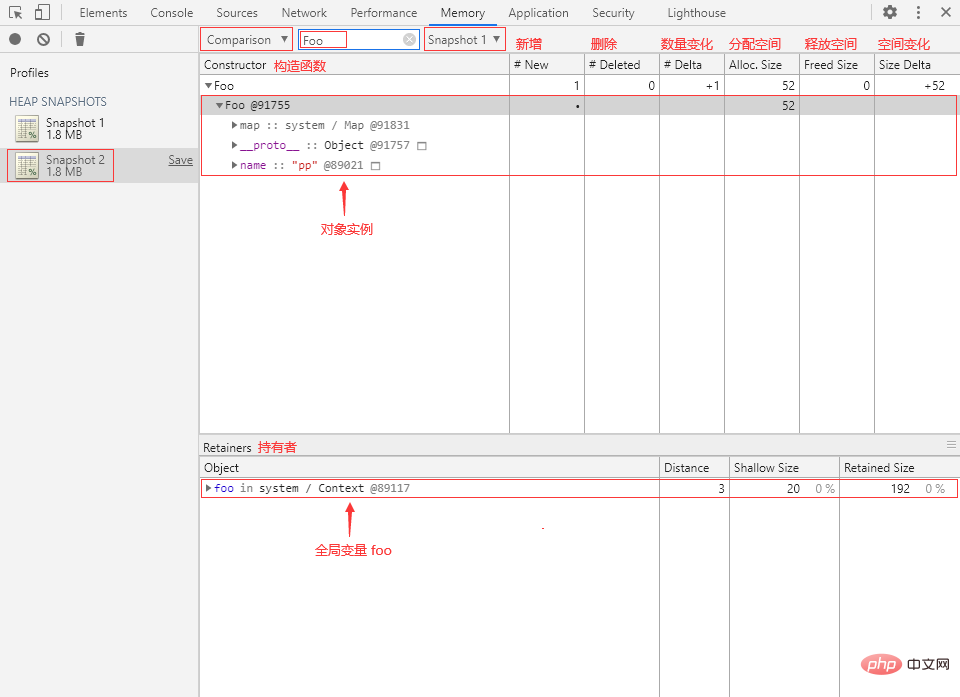
② 切换到 Console 面板,执行以下代码来实例化一个 Foo 对象:
function Foo() {
this.name = 'pp';
this.age = 18;
}
let foo = new Foo();③ 回到 Memory 面板,再打一个堆快照 Snapshot 2,切换到 Comparison 视图,选择 Snapshot 1 作为 Base snapshot(基本快照),在 Class filter 中输入“Foo”:
可以看到内存中新增了一个 Foo 对象实例,分配了 52 字节内存空间,该实例的引用持有者为变量 foo。
④ 再次切换到 Console 面板,执行以下代码来解除变量 foo 的引用:
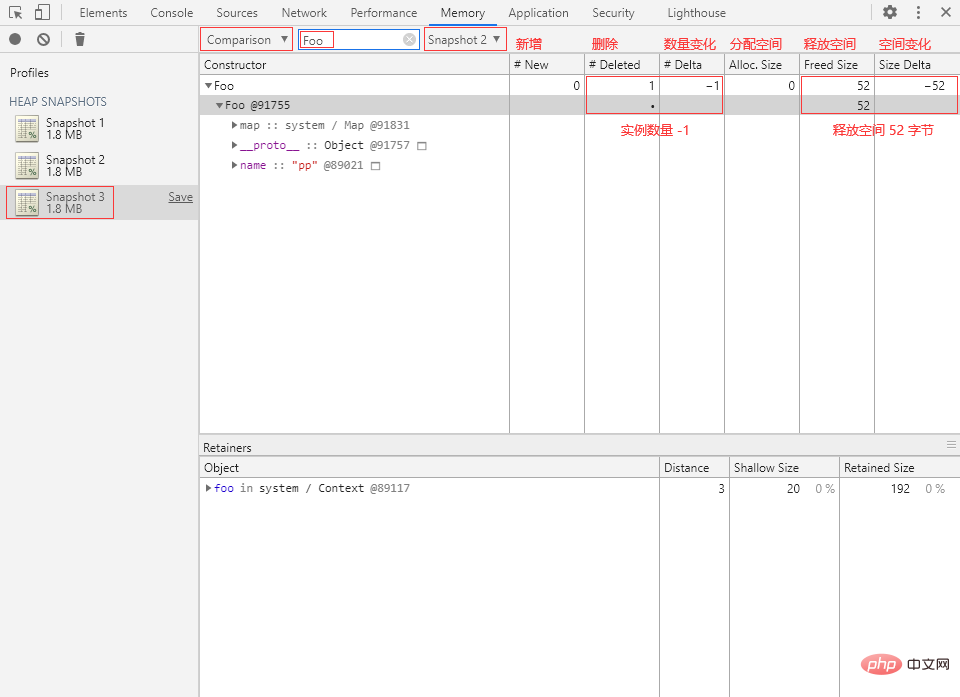
// 解除对象的引用 foo = null;
⑤ 再回到 Memory 面板,打一个堆快照 Snapshot 3,选择 Snapshot 2 作为 Base snapshot,在 Class filter 中输入“Foo”:
内存中的 Foo 对象实例已经被删除,释放了 52 字节的内存空间。
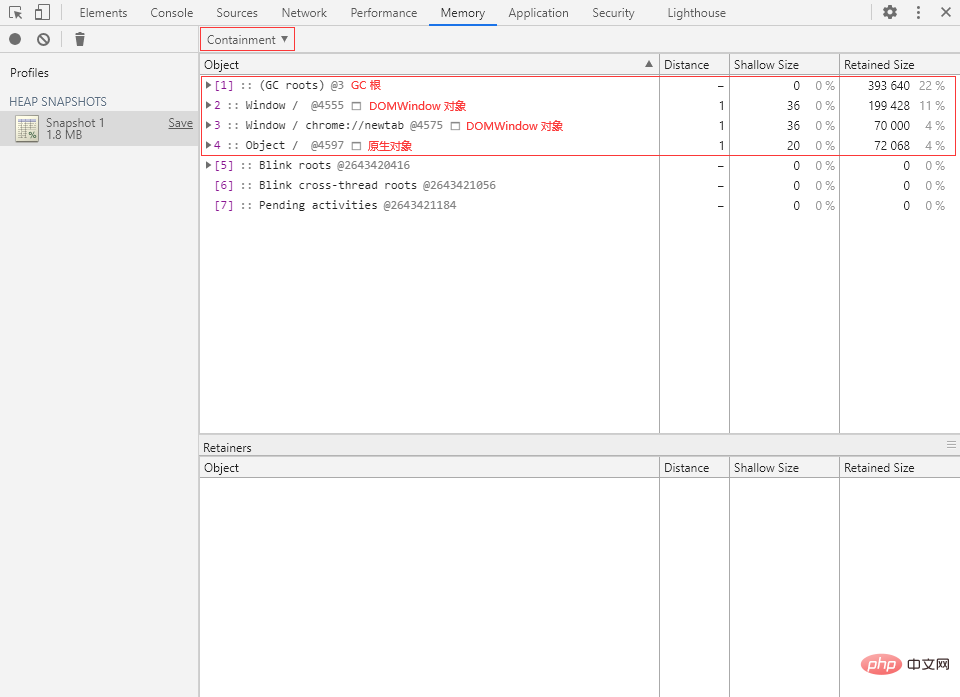
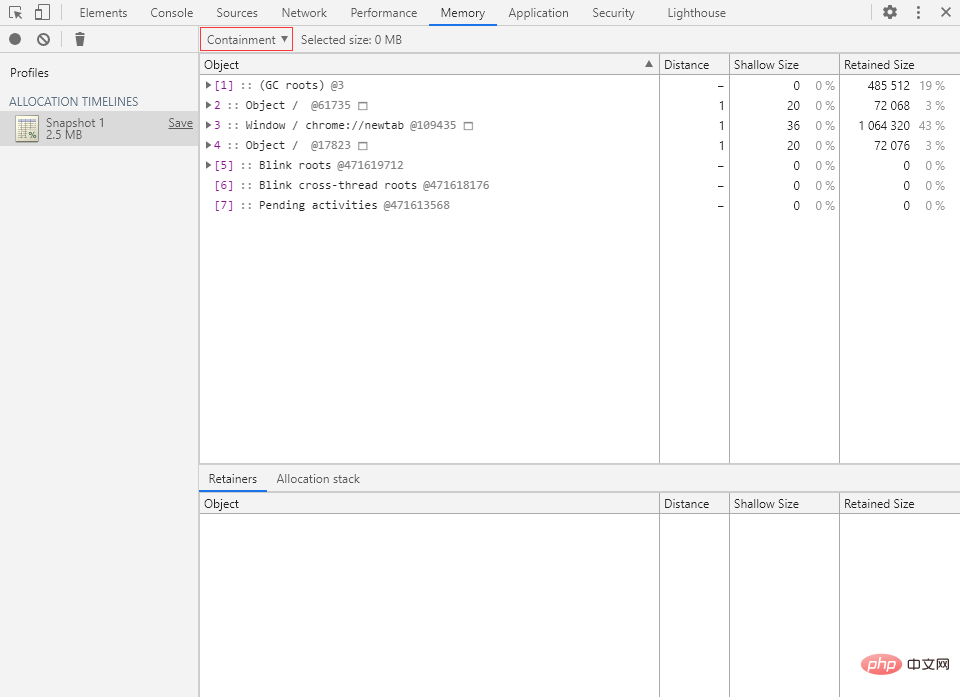
Containment(包含视图)
包含视图就是程序对象结构的“鸟瞰图(Bird’s eye view)”,允许我们通过全局对象出发,一层一层往下探索,从而了解内存的详细情况。
包含视图中有以下几种全局对象:
GC roots(GC 根)
GC roots 就是 JavaScript 虚拟机的垃圾回收中实际使用的根节点。
GC 根可以由 Built-in object maps(内置对象映射)、Symbol tables(符号表)、VM thread stacks(VM 线程堆栈)、Compilation caches(编译缓存)、Handle scopes(句柄作用域)和 Global handles(全局句柄)等组成。
DOMWindow objects(DOMWindow 对象)
DOMWindow objects 指的是由宿主环境(浏览器)提供的顶级对象,也就是 JavaScript 代码中的全局对象 window,每个标签页都有自己的 window 对象(即使是同一窗口)。
Native objects(原生对象)
Native objects 指的是那些基于 ECMAScript 标准实现的内置对象,包括 Object、Function、Array、String、Boolean、Number、Date、RegExp、Math 等对象。
? 实践一下
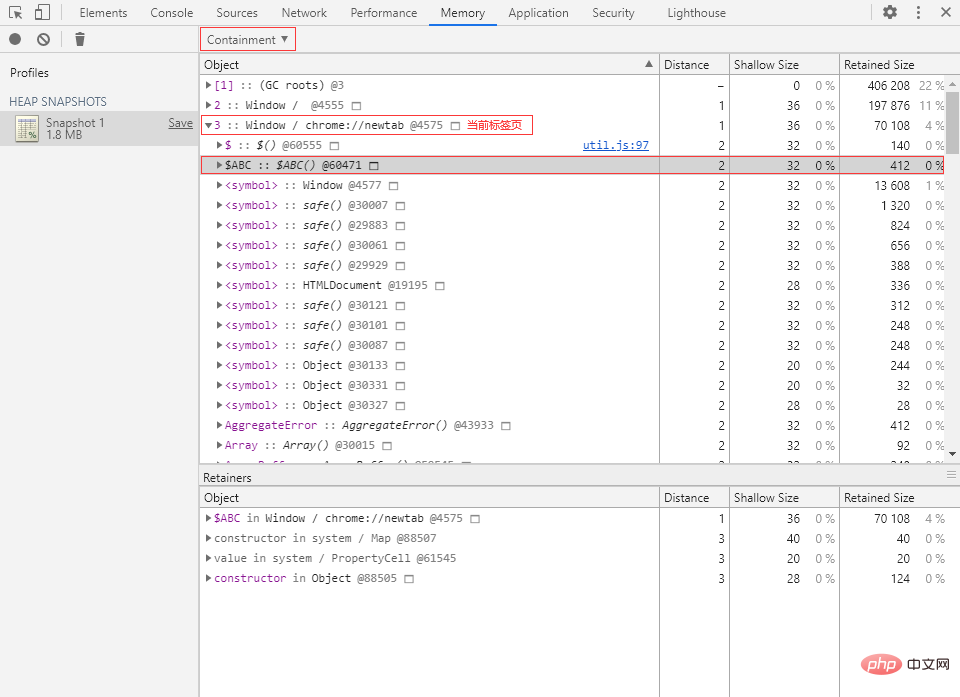
① 切换到 Console 面板,执行以下代码来创建一个构造函数 $ABC:
构造函数命名前面加个 $ 是因为这样排序的时候可以排在前面,方便找。
function $ABC() {
this.name = 'pp';
}② 切换到 Memory 面板,打一个堆快照,切换为 Containment 视图:
在当前标签页的全局对象下就可以找到我们刚刚创建的构造函数 $ABC。
Statistics(统计视图)
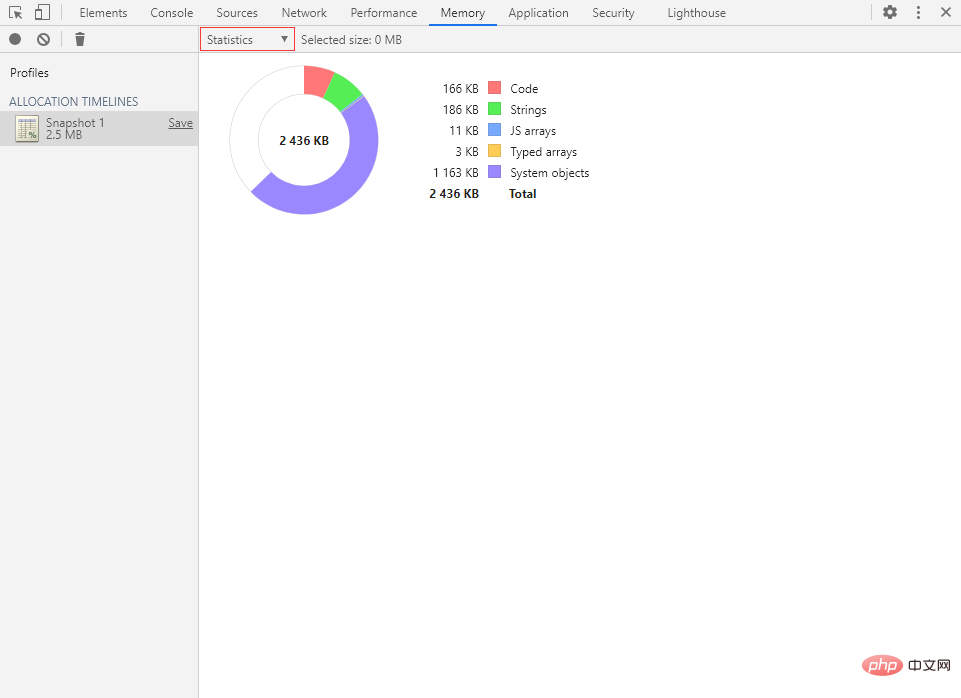
统计视图可以很直观地展示内存整体分配情况。
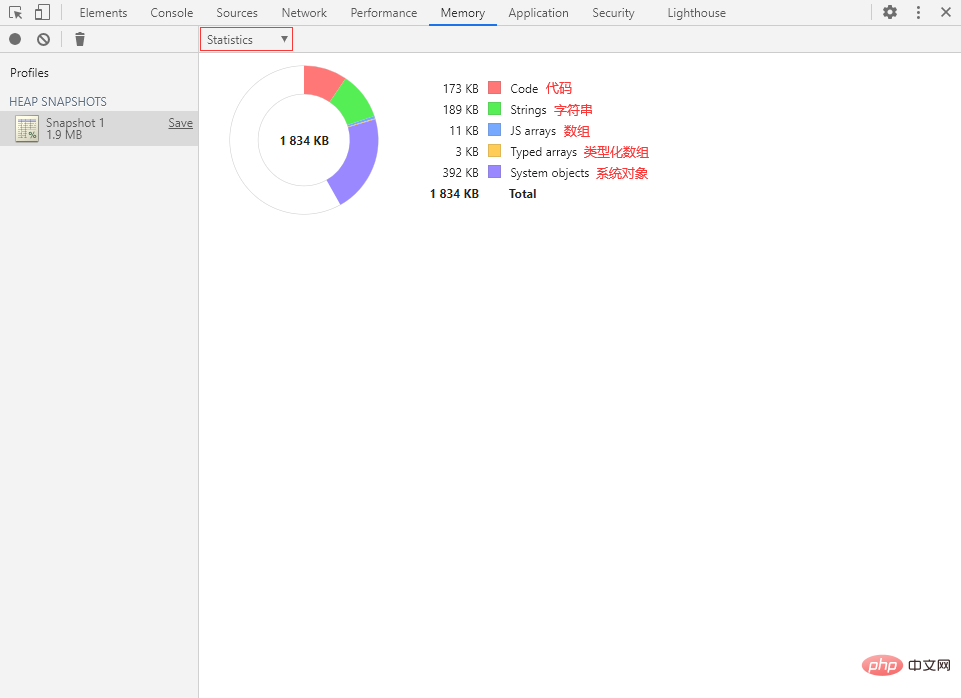
在该视图里的空心饼图中共有 6 种颜色,各含义分别为:
- 红色:Code(代码)
- 绿色:Strings(字符串)
- 蓝色:JS arrays(数组)
- 橙色:Typed arrays(类型化数组)
- 紫色:System objects(系统对象)
- 白色:空闲内存
Allocation instrumentation on timeline(分配时间轴)
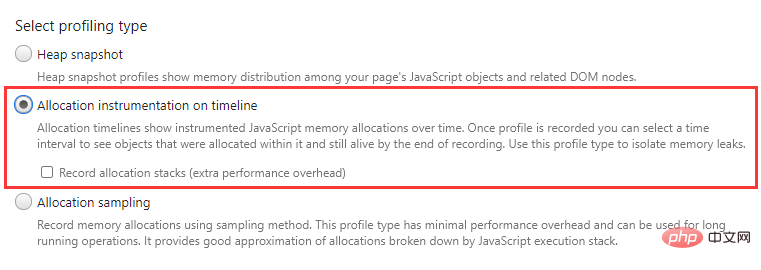
在一段时间内持续地记录内存分配(约每 50 毫秒打一张堆快照),记录完成后可以选择查看任意时间段的内存分配详情。
另外还可以勾选同时记录分配堆栈(Allocation stacks),也就是记录调用堆栈,不过这会产生额外的性能消耗。
? 如何开始
点击页面底部的 Start 按钮或者左上角的 ⚫ 按钮即可开始记录,记录过程中点击左上角的 ? 按钮来结束记录,片刻之后就会自动展示结果。
? 操作一下
① 打开 Memory 面板,开始记录分配时间轴。
② 切换到 Console 面板,执行以下代码:
代码效果:每隔 1 秒钟创建 100 个对象,共创建 1000 个对象。
console.log('测试开始');
let objects = [];
let handler = setInterval(() => {
// 每秒创建 100 个对象
for (let i = 0; i < 100; i++) {
const name = `n${objects.length}`;
const value = `v${objects.length}`;
objects.push({ [name]: value});
}
console.log(`对象数量:${objects.length}`);
// 达到 1000 个后停止
if (objects.length >= 1000) {
clearInterval(handler);
console.log('测试结束');
}
}, 1000);? 又是一个细节
不知道你有没有发现,在上面的代码中,我干了一件坏事。
在 for 循环创建对象时,会根据对象数组当前长度生成一个唯一的属性名和属性值。
这样一来 V8 就无法对这些对象进行优化,方便我们进行测试。
另外,如果直接使用对象数组的长度作为属性名会有惊喜~
③ 静静等待 10 秒钟,控制台会打印出“测试结束”。
④ 切换回 Memory 面板,停止记录,片刻之后会自动进入结果页面。
分配时间轴结果页有 4 种视图:
- Summary:摘要视图
- Containment:包含视图
- Allocation:分配视图
- Statistics:统计视图
默认显示 Summary 视图。
Summary(摘要视图)
看起来和堆快照的摘要视图很相似,主要是页面上方多了一条横向的时间轴(Timeline)。
? 时间轴
时间轴中主要的 3 种线:
- 细横线:内存分配大小刻度线
- 蓝色竖线:表示内存在对应时刻被分配,最后仍然活跃
- 灰色竖线:表示内存在对应时刻被分配,但最后被回收
时间轴的几个操作:
- 鼠标移动到时间轴内任意位置,点击左键或长按左键并拖动即可选择一段时间
- 鼠标拖动时间段框上方的方块可以对已选择的时间段进行调整
- 鼠标移到已选择的时间段框内部,滑动滚轮可以调整时间范围
- 鼠标移到已选择的时间段框两旁,滑动滚轮即可调整时间段
- 双击鼠标左键即可取消选择
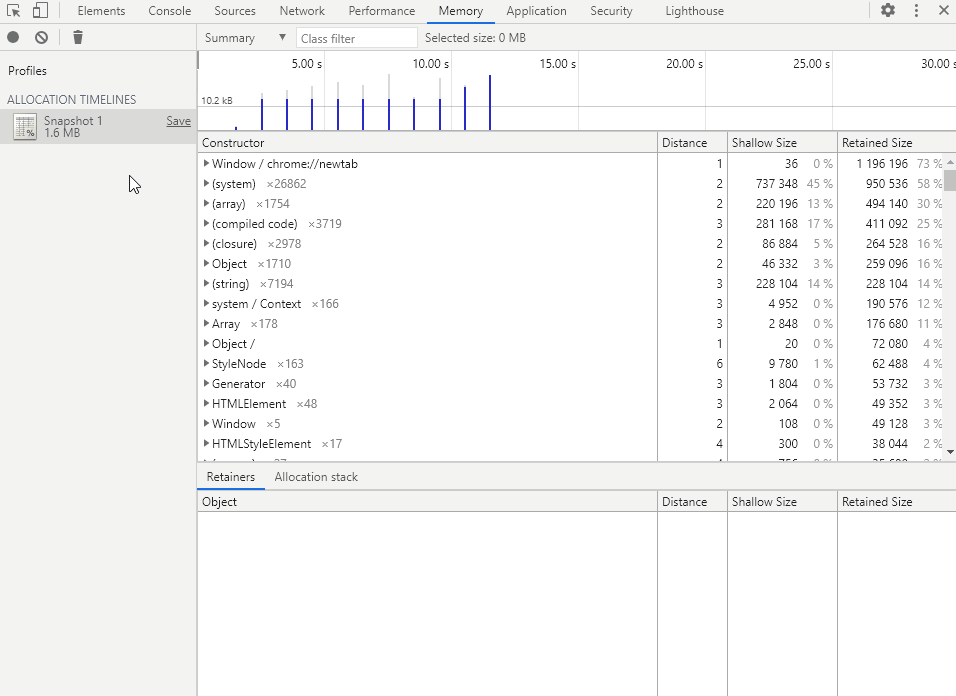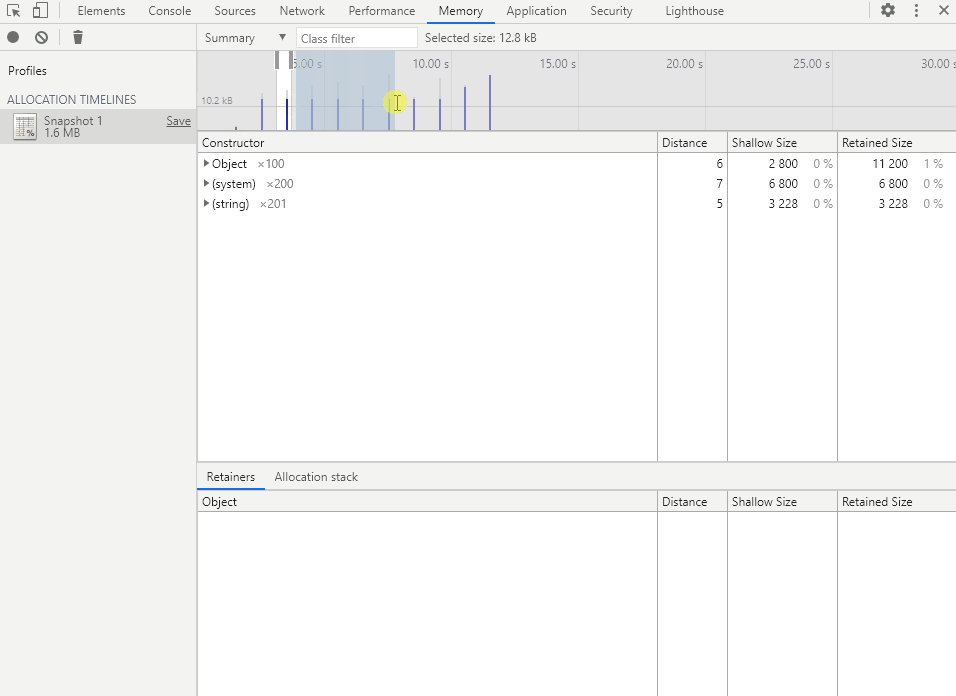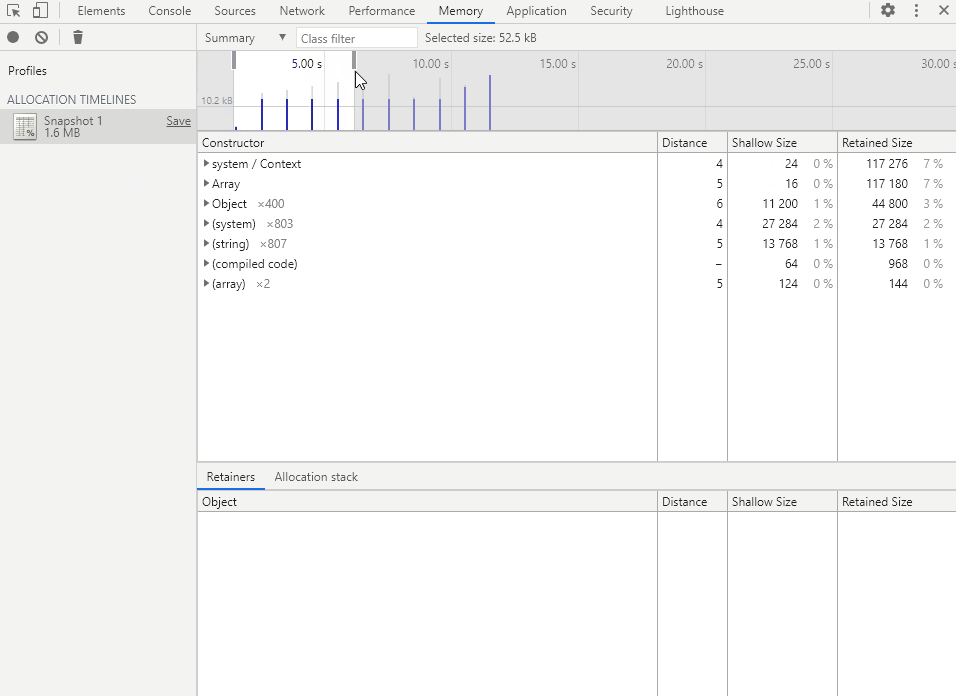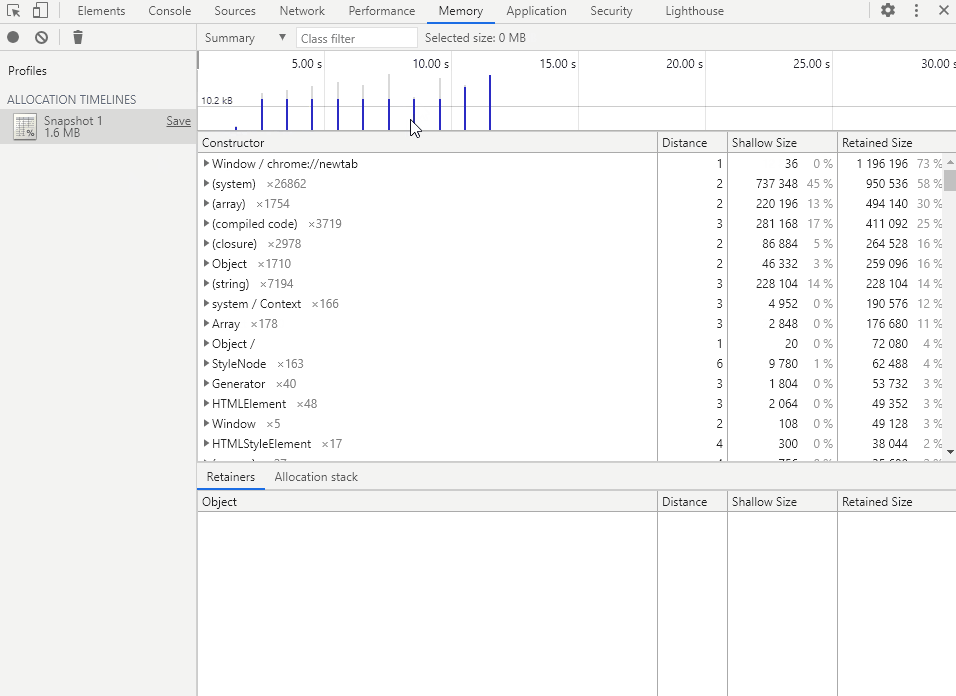
在时间轴中选择要查看的时间段,即可得到该段时间的内存分配详情。
Containment(包含视图)
分配时间轴的包含视图与堆快照的包含视图是一样的,这里就不再重复介绍了。
Allocation(分配视图)
对不起各位,这玩意儿我也不知道有啥用…
打开就直接报错,我:喵喵喵?
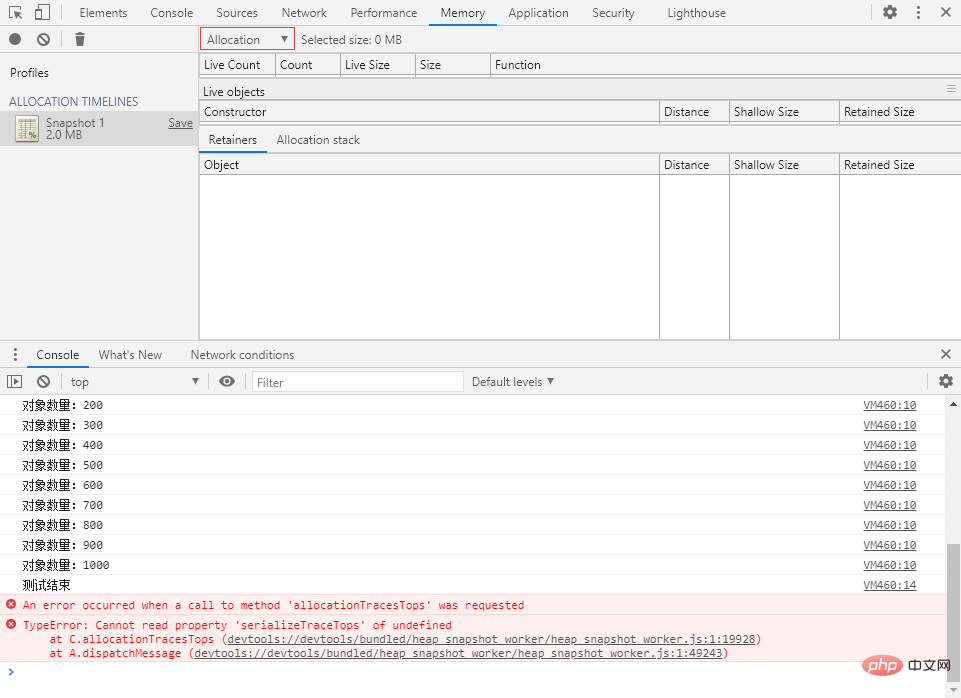
是不是因为没人用这玩意儿,所以没人发现有问题…
Statistics(统计视图)
分配时间轴的统计视图与堆快照的统计视图也是一样的,不再赘述。
Allocation sampling(分配采样)
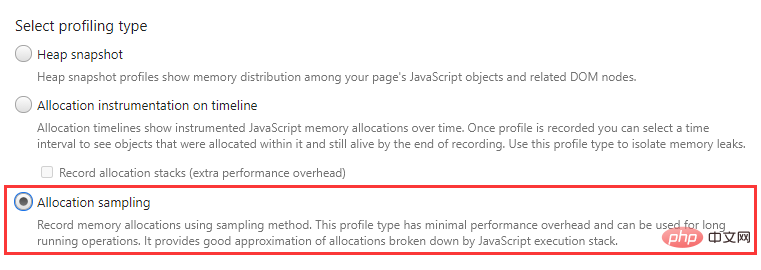
Memory 面板上的简介:使用采样方法记录内存分配。这种分析方式的性能开销最小,可以用于长时间的记录。
好家伙,这个简介有够模糊,说了跟没说似的,很有精神!
我在官方文档里没有找到任何关于分配采样的介绍,Google 上也几乎没有与之有关的信息。所以以下内容仅为个人实践得出的结果,如有不对的地方欢迎各位指出!
简单来说,通过分配采样我们可以很直观地看到代码中的每个函数(API)所分配的内存大小。
由于是采样的方式,所以结果并非百分百准确,即使每次执行相同的操作也可能会有不同的结果,但是足以让我们了解内存分配的大体情况。
✍ 如何开始
点击页面底部的 Start 按钮或者左上角的 ⚫ 按钮即可开始记录,记录过程中点击左上角的 ? 按钮来结束记录,片刻之后就会自动展示结果。
? 操作一下
① 打开 Memory 面板,开始记录分配采样。
② 切换到 Console 面板,执行以下代码:
代码看起来有点长,其实就是 4 个函数分别以不同的方式往数组里面添加对象。
// 普通单层调用
let array_a = [];
function aoo1() {
for (let i = 0; i < 10000; i++) {
array_a.push({ a: 'pp' });
}
}
aoo1();
// 两层嵌套调用
let array_b = [];
function boo1() {
function boo2() {
for (let i = 0; i < 20000; i++) {
array_b.push({ b: 'pp' });
}
}
boo2();
}
boo1();
// 三层嵌套调用
let array_c = [];
function coo1() {
function coo2() {
function coo3() {
for (let i = 0; i < 30000; i++) {
array_c.push({ c: 'pp' });
}
}
coo3();
}
coo2();
}
coo1();
// 两层嵌套多个调用
let array_d = [];
function doo1() {
function doo2_1() {
for (let i = 0; i < 20000; i++) {
array_d.push({ d: 'pp' });
}
}
doo2_1();
function doo2_2() {
for (let i = 0; i < 20000; i++) {
array_d.push({ d: 'pp' });
}
}
doo2_2();
}
doo1();③ 切换回 Memory 面板,停止记录,片刻之后会自动进入结果页面。
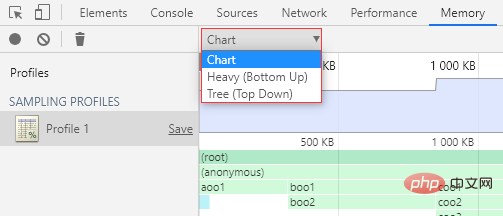
分配采样结果页有 3 种视图可选:
- Chart:图表视图
- Heavy (Bottom Up):扁平视图(调用层级自下而上)
- Tree (Top Down):树状视图(调用层级自上而下)
这个 Heavy 我真的不知道该怎么翻译,所以我就按照具体表现来命名了。
默认会显示 Chart 视图。
Chart(图表视图)
Chart 视图以图形化的表格形式展现各个函数的内存分配详情,可以选择精确到内存分配的不同阶段(以内存分配的大小为轴)。
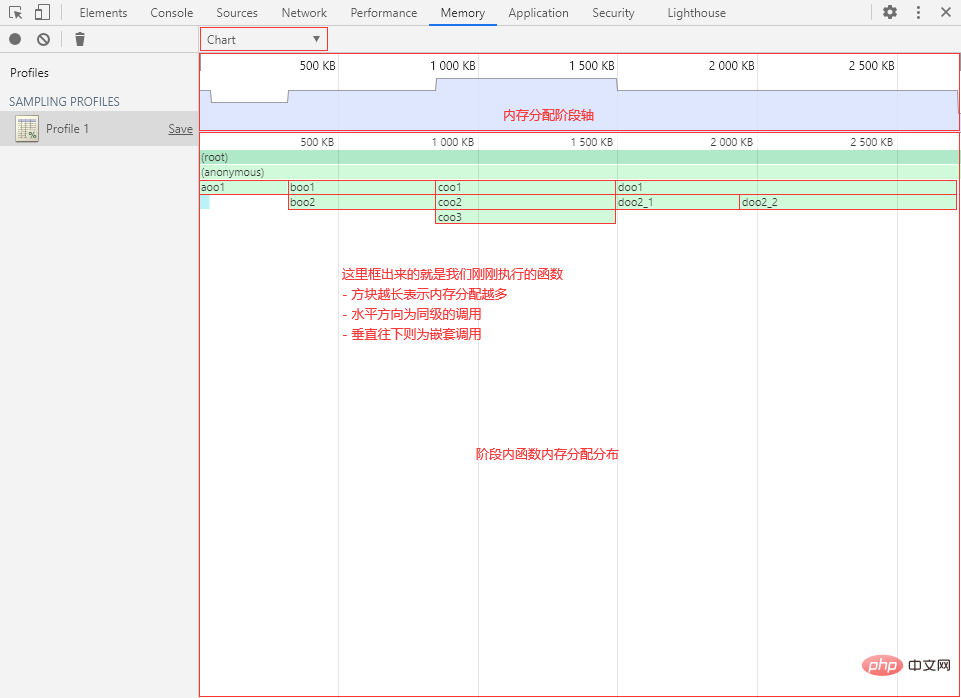
鼠标左键点击、拖动和双击以操作内存分配阶段轴(和时间轴一样),选择要查看的阶段范围。
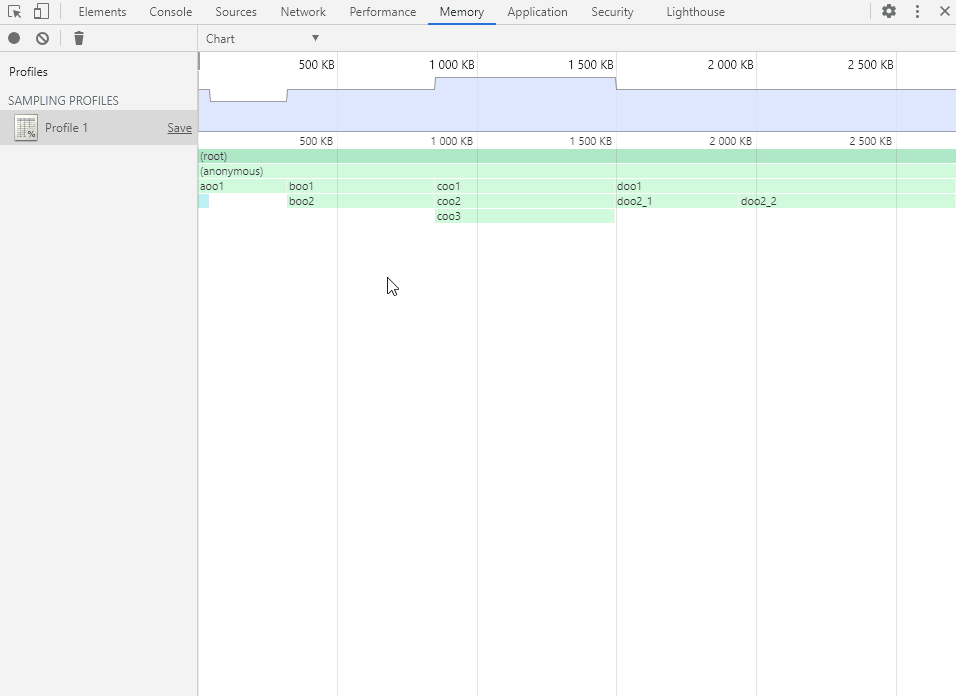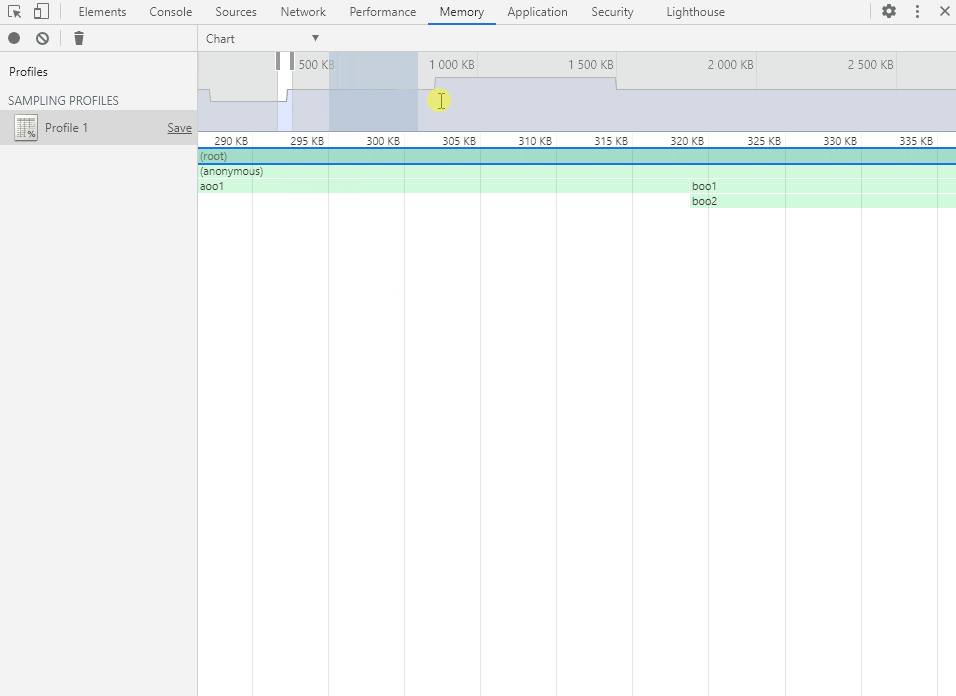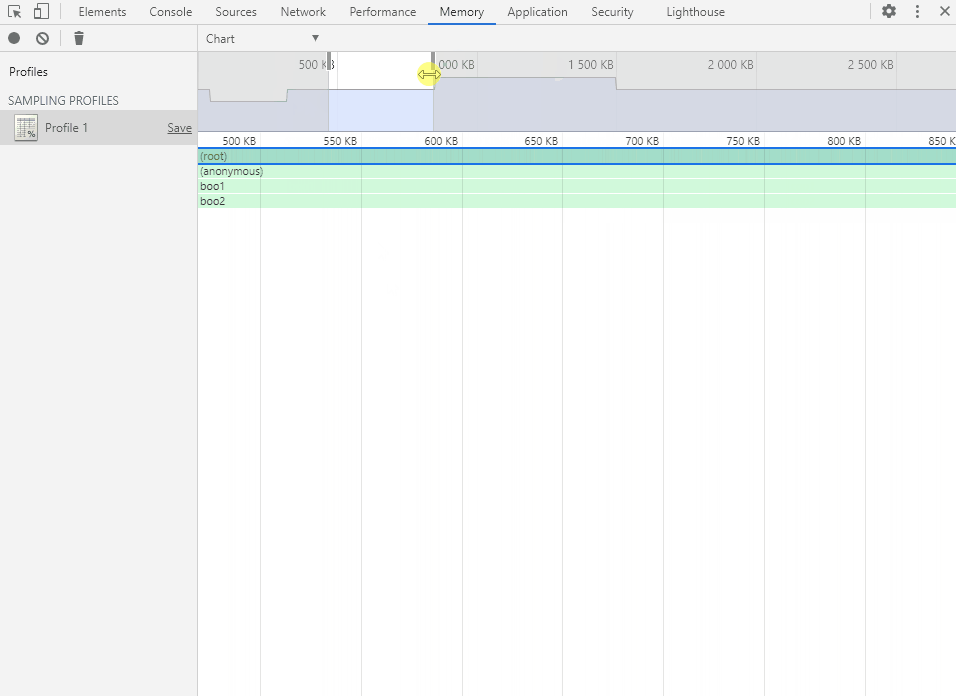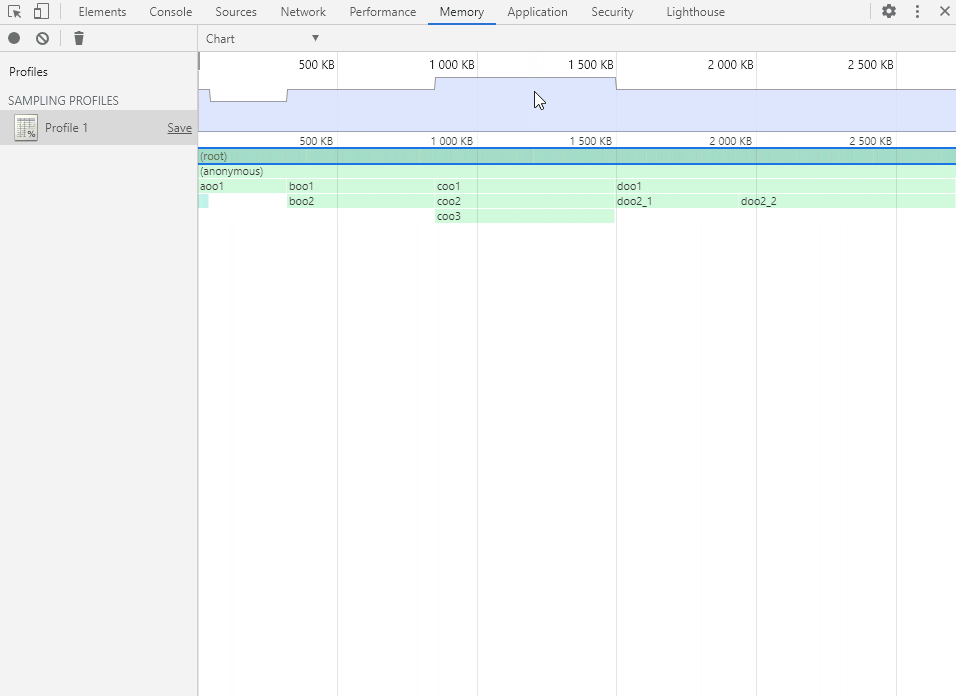
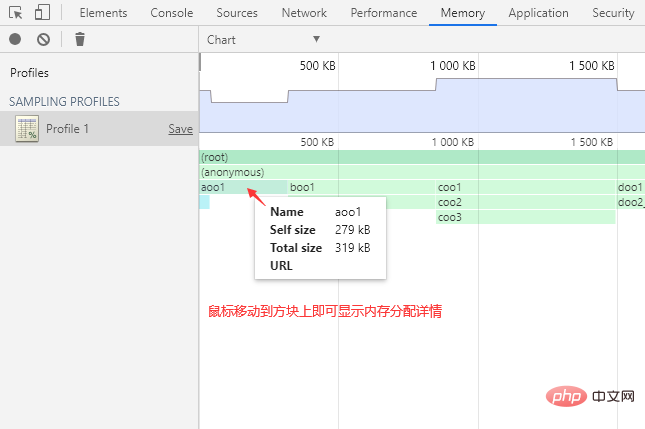
将鼠标移动到函数方块上会显示函数的内存分配详情。
鼠标左键点击函数方块可以Quest-ce que la mémoire en javascript。
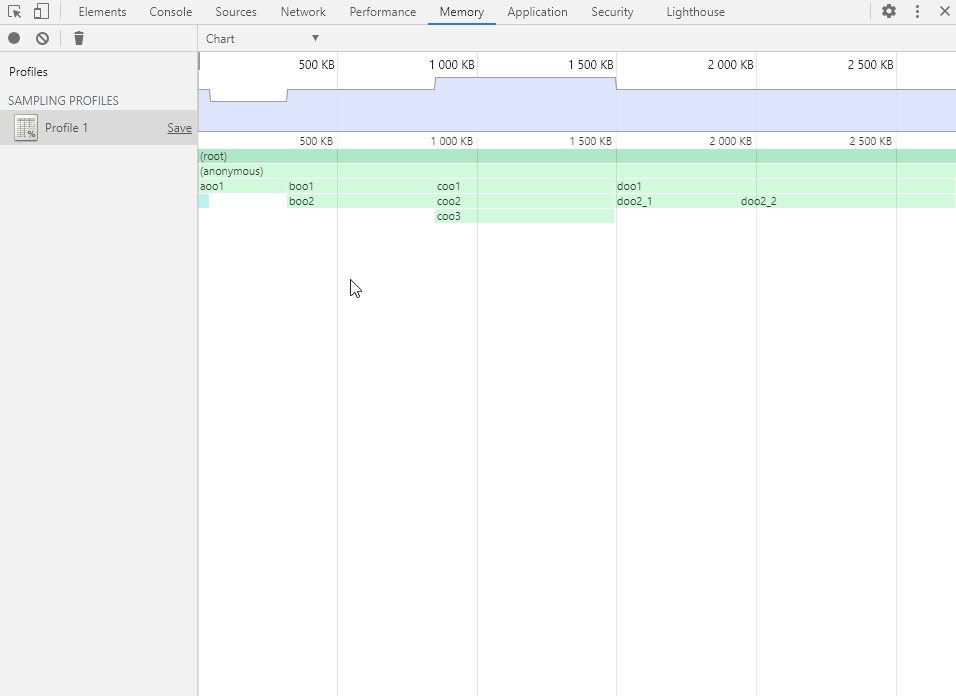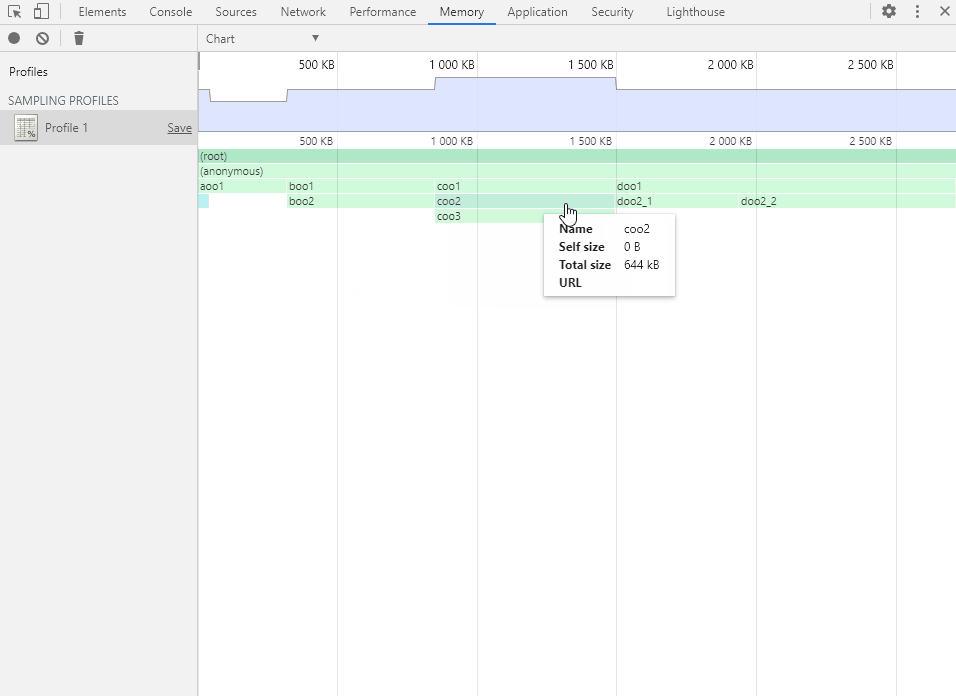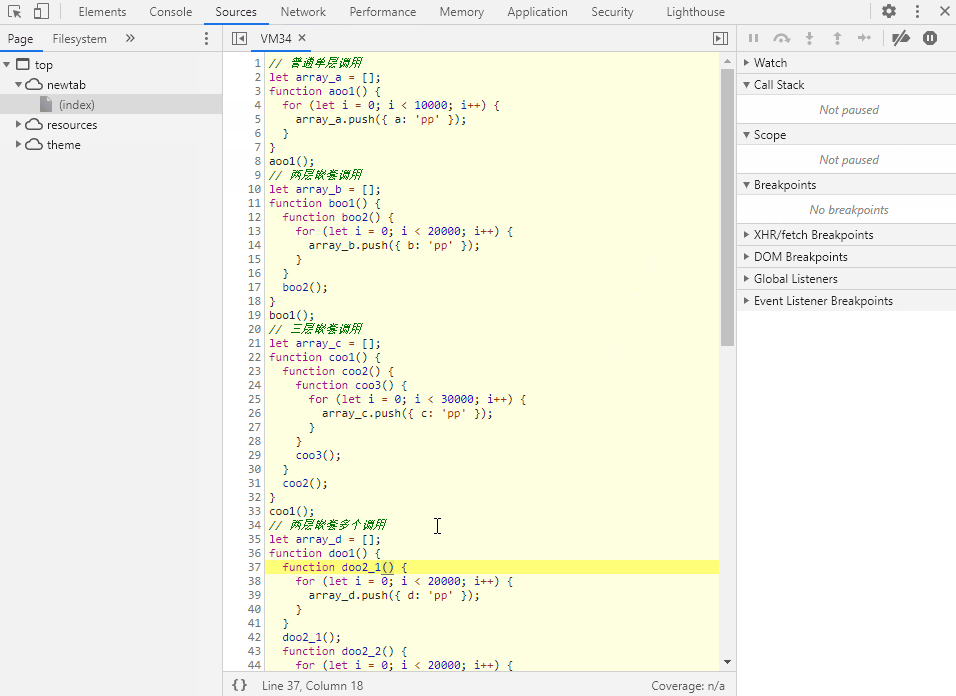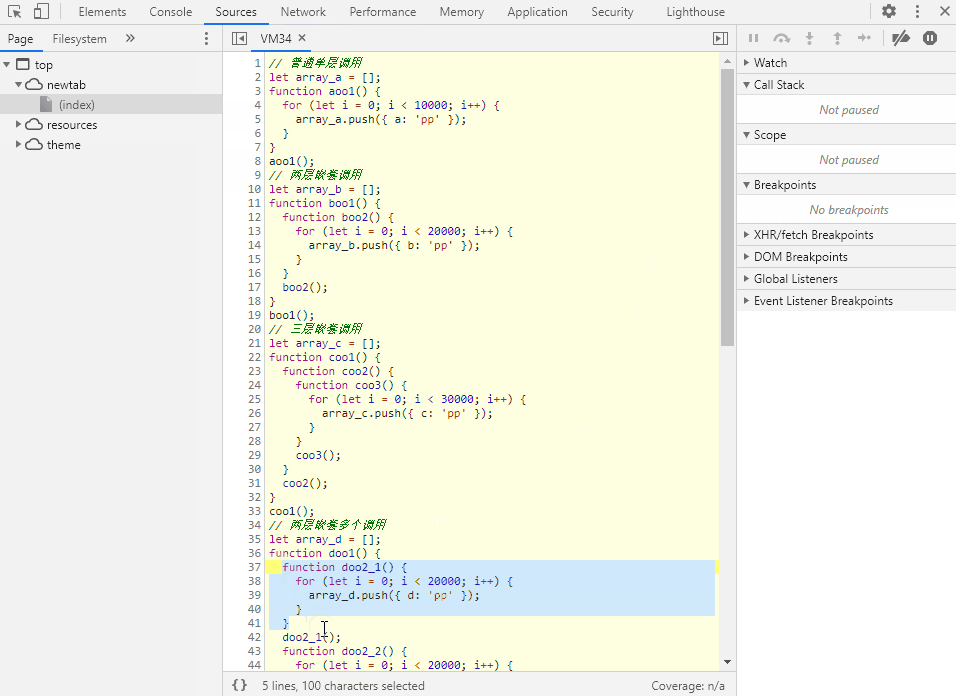
Heavy(扁平视图)
Heavy 视图将函数调用层级压平,函数将以独立的个体形式展现。另外也可以展开调用层级,不过是自下而上的结构,也就是一个反向的Quest-ce que la mémoire en javascript。
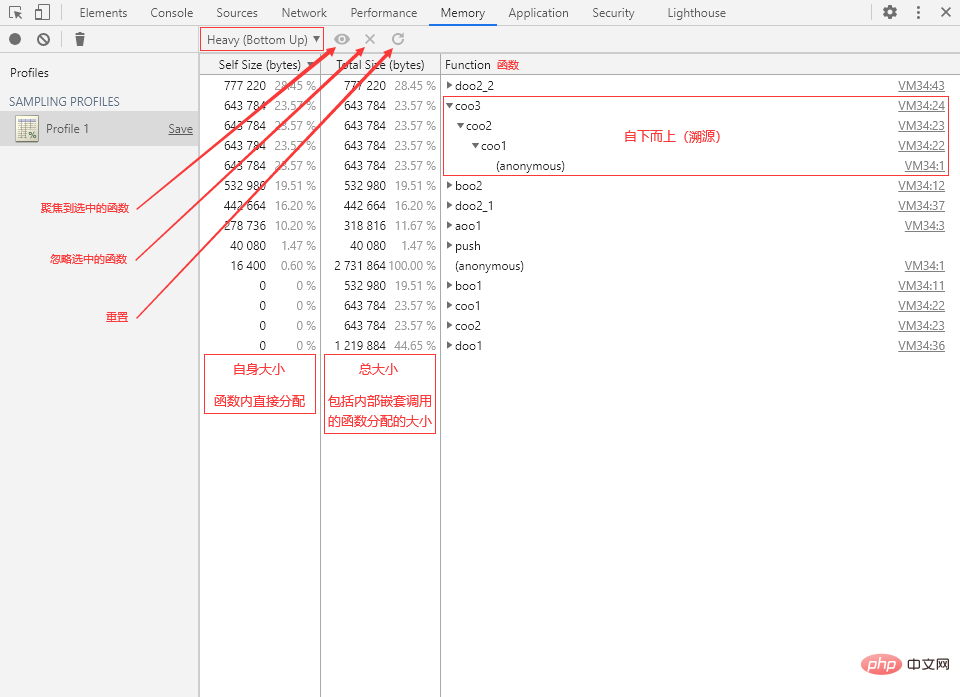
视图中的两种 Size(大小):
- Self Size:自身大小,指的是在函数内部直接分配的内存空间大小。
- Total Size:总大小,指的是函数总共分配的内存空间大小,也就是包括函数内部嵌套调用的其他函数所分配的大小。
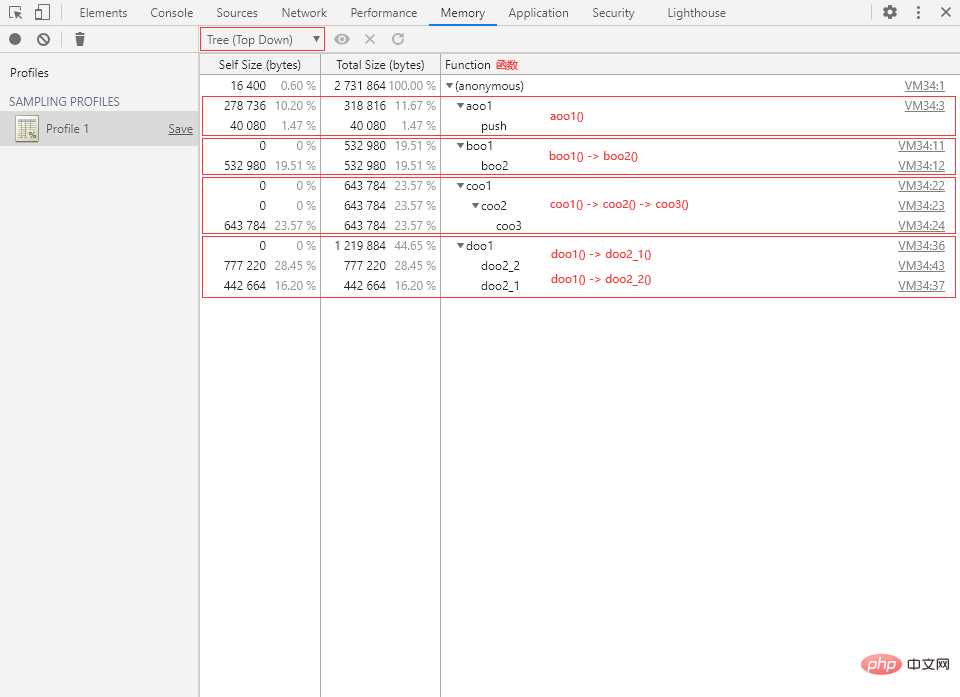
Tree(树状视图)
Tree 视图以树形结构展现函数调用层级。我们可以从代码执行的源头开始自上而下逐层展开,呈现一个完整的正向的Quest-ce que la mémoire en javascript。
【相关推荐:javascript视频教程、编程基础视频】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Optimisation importante de la mémoire, que dois-je faire si l'ordinateur passe à une vitesse de mémoire de 16 Go/32 Go et qu'il n'y a aucun changement ?
Jun 18, 2024 pm 06:51 PM
Optimisation importante de la mémoire, que dois-je faire si l'ordinateur passe à une vitesse de mémoire de 16 Go/32 Go et qu'il n'y a aucun changement ?
Jun 18, 2024 pm 06:51 PM
Pour les disques durs mécaniques ou les disques SSD SATA, vous ressentirez l'augmentation de la vitesse d'exécution du logiciel. S'il s'agit d'un disque dur NVME, vous ne la ressentirez peut-être pas. 1. Importez le registre sur le bureau et créez un nouveau document texte, copiez et collez le contenu suivant, enregistrez-le sous 1.reg, puis cliquez avec le bouton droit pour fusionner et redémarrer l'ordinateur. WindowsRegistryEditorVersion5.00[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\MemoryManagement]"DisablePagingExecutive"=d
 Comment vérifier l'utilisation de la mémoire sur Xiaomi Mi 14Pro ?
Mar 18, 2024 pm 02:19 PM
Comment vérifier l'utilisation de la mémoire sur Xiaomi Mi 14Pro ?
Mar 18, 2024 pm 02:19 PM
Récemment, Xiaomi a lancé un puissant smartphone haut de gamme, le Xiaomi 14Pro, qui présente non seulement un design élégant, mais également une technologie noire interne et externe. Le téléphone offre des performances optimales et d'excellentes capacités multitâches, permettant aux utilisateurs de profiter d'une expérience de téléphonie mobile rapide et fluide. Cependant, les performances seront également affectées par la mémoire. De nombreux utilisateurs souhaitent savoir comment vérifier l’utilisation de la mémoire du Xiaomi 14Pro, alors jetons-y un coup d’œil. Comment vérifier l’utilisation de la mémoire sur Xiaomi Mi 14Pro ? Introduction à la façon de vérifier l'utilisation de la mémoire du Xiaomi 14Pro. Ouvrez le bouton [Gestion des applications] dans [Paramètres] du téléphone Xiaomi 14Pro. Pour afficher la liste de toutes les applications installées, parcourez la liste et recherchez l'application que vous souhaitez afficher, cliquez dessus pour accéder à la page de détails de l'application. Dans la page de détails de la candidature
 Y a-t-il une grande différence entre 8 Go et 16 Go de mémoire dans les ordinateurs ? (Choisissez 8 Go ou 16 Go de mémoire informatique)
Mar 13, 2024 pm 06:10 PM
Y a-t-il une grande différence entre 8 Go et 16 Go de mémoire dans les ordinateurs ? (Choisissez 8 Go ou 16 Go de mémoire informatique)
Mar 13, 2024 pm 06:10 PM
Lorsque les utilisateurs novices achèteront un ordinateur, ils seront curieux de connaître la différence entre 8 Go et 16 Go de mémoire informatique ? Dois-je choisir 8g ou 16g ? En réponse à ce problème, l'éditeur va aujourd'hui vous l'expliquer en détail. Y a-t-il une grande différence entre 8 Go et 16 Go de mémoire informatique ? 1. Pour les familles ordinaires ou le travail ordinaire, la mémoire courante de 8 Go peut répondre aux exigences, il n'y a donc pas beaucoup de différence entre 8 g et 16 g pendant l'utilisation. 2. Lorsqu'ils sont utilisés par des passionnés de jeux, les jeux à grande échelle commencent actuellement à 6 Go, et 8 Go est la norme minimale. Actuellement, lorsque l'écran est en 2K, une résolution plus élevée n'apportera pas de performances de fréquence d'images plus élevées, il n'y a donc pas de grande différence entre 8g et 16g. 3. Pour les utilisateurs de montage audio et vidéo, il y aura des différences évidentes entre 8g et 16g.
 Samsung a annoncé l'achèvement de la vérification de la technologie du processus d'empilement de liaisons hybrides à 16 couches, qui devrait être largement utilisée dans la mémoire HBM4.
Apr 07, 2024 pm 09:19 PM
Samsung a annoncé l'achèvement de la vérification de la technologie du processus d'empilement de liaisons hybrides à 16 couches, qui devrait être largement utilisée dans la mémoire HBM4.
Apr 07, 2024 pm 09:19 PM
Selon le rapport, Dae Woo Kim, directeur de Samsung Electronics, a déclaré que lors de la réunion annuelle 2024 de la Korean Microelectronics and Packaging Society, Samsung Electronics terminerait la vérification de la technologie de mémoire HBM à liaison hybride à 16 couches. Il est rapporté que cette technologie a passé avec succès la vérification technique. Le rapport indique également que cette vérification technique jettera les bases du développement du marché de la mémoire dans les prochaines années. DaeWooKim a déclaré que Samsung Electronics avait réussi à fabriquer une mémoire HBM3 empilée à 16 couches basée sur la technologie de liaison hybride. À l'avenir, la technologie de liaison hybride empilée à 16 couches sera utilisée pour la production en série de mémoire HBM4. ▲ Source de l'image TheElec, comme ci-dessous. Par rapport au processus de liaison existant, la liaison hybride n'a pas besoin d'ajouter de bosses entre les couches de mémoire DRAM, mais connecte directement les couches supérieure et inférieure de cuivre au cuivre.
 Des sources affirment que Samsung Electronics et SK Hynix commercialiseront de la mémoire mobile empilée après 2026
Sep 03, 2024 pm 02:15 PM
Des sources affirment que Samsung Electronics et SK Hynix commercialiseront de la mémoire mobile empilée après 2026
Sep 03, 2024 pm 02:15 PM
Selon des informations publiées sur ce site Web le 3 septembre, le média coréen etnews a rapporté hier (heure locale) que les produits de mémoire mobile à structure empilée « de type HBM » de Samsung Electronics et SK Hynix seraient commercialisés après 2026. Des sources ont indiqué que les deux géants coréens de la mémoire considèrent la mémoire mobile empilée comme une source importante de revenus futurs et prévoient d'étendre la « mémoire de type HBM » aux smartphones, tablettes et ordinateurs portables afin de fournir de la puissance à l'IA finale. Selon des rapports précédents sur ce site, le produit de Samsung Electronics s'appelle LPWide I/O memory, et SK Hynix appelle cette technologie VFO. Les deux sociétés ont utilisé à peu près la même voie technique, à savoir combiner emballage en sortance et canaux verticaux. La mémoire LPWide I/O de Samsung Electronics a une largeur de 512 bits.
 Mar 22, 2024 pm 08:16 PM
Mar 22, 2024 pm 08:16 PM
Ce site rapportait le 21 mars que Micron avait tenu une conférence téléphonique après la publication de son rapport financier trimestriel. Lors de la conférence, le PDG de Micron, Sanjay Mehrotra, a déclaré que par rapport à la mémoire traditionnelle, la HBM consomme beaucoup plus de plaquettes. Micron a déclaré qu'en produisant la même capacité sur le même nœud, la mémoire HBM3E la plus avancée actuelle consomme trois fois plus de tranches que la DDR5 standard, et on s'attend à ce qu'à mesure que les performances s'améliorent et que la complexité de l'emballage s'intensifie, à l'avenir HBM4, ce ratio augmentera encore. . Si l’on se réfère aux rapports précédents sur ce site, ce ratio élevé est en partie dû au faible taux de rendement de HBM. La mémoire HBM est empilée avec des connexions TSV de mémoire DRAM multicouche. Un problème avec une couche signifie que l'ensemble.
 Lexar lance le kit de mémoire Ares Wings of War DDR5 7600 16 Go x2 : particules Hynix A-die, 1 299 yuans
May 07, 2024 am 08:13 AM
Lexar lance le kit de mémoire Ares Wings of War DDR5 7600 16 Go x2 : particules Hynix A-die, 1 299 yuans
May 07, 2024 am 08:13 AM
Selon les informations de ce site Web le 6 mai, Lexar a lancé la mémoire d'overclocking DDR57600CL36 de la série Ares Wings of War. L'ensemble de 16 Go x 2 sera disponible en prévente à 00h00 le 7 mai avec un dépôt de 50 yuans, et le prix est de 50 yuans. 1 299 yuans. La mémoire Lexar Wings of War utilise des puces mémoire Hynix A-die, prend en charge Intel XMP3.0 et fournit les deux préréglages d'overclocking suivants : 7600MT/s : CL36-46-46-961.4V8000MT/s : CL38-48-49 -1001.45V En termes de dissipation thermique, cet ensemble de mémoire est équipé d'un gilet de dissipation thermique tout en aluminium de 1,8 mm d'épaisseur et est équipé du tampon de graisse en silicone thermoconducteur exclusif de PMIC. La mémoire utilise 8 perles LED haute luminosité et prend en charge 13 modes d'éclairage RVB.
 La mémoire installée n'apparaît pas sous Windows 11
Mar 10, 2024 am 09:31 AM
La mémoire installée n'apparaît pas sous Windows 11
Mar 10, 2024 am 09:31 AM
Si vous avez installé une nouvelle RAM mais qu'elle n'apparaît pas sur votre ordinateur Windows, cet article vous aidera à résoudre le problème. Habituellement, nous améliorons les performances du système en mettant à niveau la RAM. Cependant, les performances du système dépendent également d'autres matériels tels que le processeur, le SSD, etc. La mise à niveau de la RAM peut également améliorer votre expérience de jeu. Certains utilisateurs ont remarqué que la mémoire installée n'apparaît pas sous Windows 11/10. Si cela vous arrive, vous pouvez utiliser les conseils fournis ici. La RAM installée n'apparaît pas sur Windows 11 Si la RAM installée n'apparaît pas sur votre PC Windows 11/10, les suggestions suivantes vous aideront. La mémoire installée est-elle compatible avec la carte mère de votre ordinateur ? dans la BIO
