
 développement back-end
Tutoriel Python
Comment télécharger des images simultanément avec plusieurs threads en Python
développement back-end
Tutoriel Python
Comment télécharger des images simultanément avec plusieurs threads en Python
Comment télécharger des images simultanément avec plusieurs threads en Python


Parfois, cela prend des heures pour télécharger un grand nombre d'images - réparons cela
Je comprends - vous en avez assez d'attendre que votre programme télécharge des images. Parfois, je dois télécharger des milliers d'images, ce qui prend des heures, et vous ne pouvez pas attendre que votre programme ait fini de télécharger ces images stupides. Vous avez beaucoup de choses importantes à faire.
Créons un script de téléchargement d'images simple qui lira un fichier texte et téléchargera très rapidement toutes les images répertoriées dans un dossier.
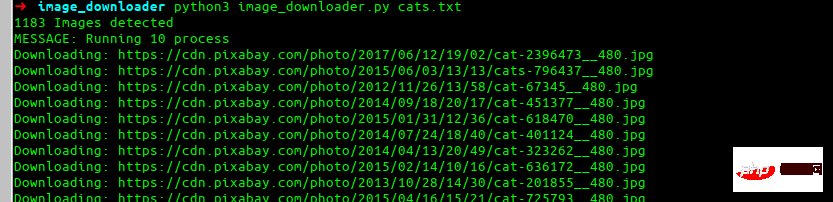
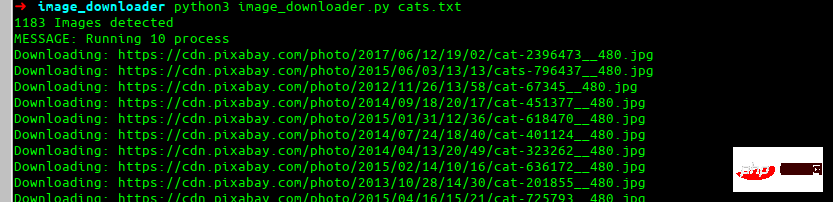
Effet Final
C'est ce que nous allons construire à la fin.

Installation des dépendances
Installons la bibliothèque de requêtes préférées de chacun.
pip install requests
Nous allons maintenant voir du code de base pour télécharger une seule URL et essayer de trouver automatiquement le nom de l'image et comment utiliser les tentatives.
import requests
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <p>Ici, nous réessayons de télécharger l'image cinq fois en cas d'échec. Essayons maintenant de trouver automatiquement le nom de l'image et de l'enregistrer. </p><pre class="brush:php;toolbar:false">import more required library
import io
from PIL import Image
# lets try to find the image name
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]Explication
Disons que l'URL que nous voulons télécharger est :
instagram.fktm7-1.fna.fbcdn.net/vp…
D'accord, c'est le bordel. Décomposons ce que fait le code pour l'URL. Nous utilisons d'abord rfind pour trouver la dernière barre oblique (/), puis nous sélectionnons tout après cela. Voici les résultat >? et prenez n'importe quoi devant. rfind 找到最后一个正斜杠(/),然后选择之后的所有内容。这是结果:
65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111
现在我们的第二部分找到一个 ?,然后只取它前面的任何东西。
这是我们最终的图像名称:
65872070_1200425330158967_6201268309743367902_n.jpg
这个结果非常好,适用于大多数用例。
现在我们已经下载了图像名称和图像,我们将保存它。
i = Image.open(io.BytesIO(res.content)) i.save(image_name)
如果你在想,「我到底应该怎么使用上面的代码?」那么你的想法是正确的。这是一个漂亮的函数,我们在上面所做的一切都被扁平处理了。在这里,我们还测试了下载的类型是否为图像,以防找不到图像名称。
def image_downloader(img_url: str):
"""
Input:
param: img_url str (Image url)
Tries to download the image url and use name provided in headers. Else it randomly picks a name
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <p>现在,你可能会问:「这个人所说的多处理在哪里?」。</p><p>这很简单。我们将简单地定义我们的池并将我们的函数和图像 URL 传递给它。</p><pre class="brush:php;toolbar:false">results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)让我们把它放在一个函数中:
def run_downloader(process:int, images_url:list):
"""
Inputs:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)再一次,你可能会说,「这一切都很好,但我想立即开始下载我的 1000 张图像列表。我不想复制和粘贴所有这些代码并试图弄清楚如何合并所有内容。」
这是一个完整的脚本。它执行以下操作:
以图像列表文本文件和进程号作为输入
按照您想要的速度下载它们
打印下载文件的总时间
还有一些不错的函数可以帮助我们读取文件名并处理错误和其他东西
完整的脚本
# -*- coding: utf-8 -*-
import io
import random
import shutil
import sys
from multiprocessing.pool import ThreadPool
import pathlib
import requests
from PIL import Image
import time
start = time.time()
def get_download_location():
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n$python image_downloader.py cats.txt')
name = url_input.split('.')[0]
pathlib.Path(name).mkdir(parents=True, exist_ok=True)
return name
def get_urls():
"""
通过读取终端中作为参数提供的 txt 文件返回 url 列表
"""
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n Example \n\n$python image_downloader.py dogs.txt \n\n')
sys.exit()
with open(url_input, 'r') as f:
images_url = f.read().splitlines()
print('{} Images detected'.format(len(images_url)))
return images_url
def image_downloader(img_url: str):
"""
输入选项:
参数: img_url str (Image url)
尝试下载图像 url 并使用标题中提供的名称。否则它会随机选择一个名字
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <p>将其保存到 Comment télécharger des images simultanément avec plusieurs threads en Comment télécharger des images simultanément avec plusieurs threads en Python 文件中,然后运行它。</p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">python3 image_downloader.py cats.txt这是 GitHub 存储库的链接。
用法
python3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process></num_of_process></filename_with_urls_seperated_by_newline.txt>
这将读取文本文件中的所有 URL,并将它们下载到名称与文件名相同的文件夹中。
num_of_process
65872070_1200425330158967_6201268309743367902_n.jpg
 Ce résultat est très bon et convient à la plupart des cas d'utilisation.
Ce résultat est très bon et convient à la plupart des cas d'utilisation.
Maintenant que nous avons téléchargé le nom de l'image et l'image, nous allons l'enregistrer. 
python3 image_downloader.py cats.txt
rrreee
Maintenant, vous vous demandez peut-être : « Où est le multitraitement dont cette personne parle ? ».Mettons cela dans une fonction : Il s'agit d'un script complet. Il effectue les opérations suivantes : 🎜C'est facile. Nous allons simplement définir notre pool et lui transmettre notre fonction et l'URL de notre image.
rrreee
- 🎜 prend en entrée un fichier texte de liste d'images et un numéro de processus 🎜
- 🎜 à la vitesse à laquelle vous voulez les télécharger 🎜
- 🎜Imprimer la durée totale de téléchargement du fichier🎜
- 🎜Il existe également des fonctions intéressantes qui nous aident à lire les noms de fichiers et à gérer les erreurs et autres éléments🎜
num_of_process est facultatif (par défaut, il utilise 10 processus). 🎜🎜🎜Exemple🎜🎜rrreee🎜🎜🎜🎜🎜🎜🎜Je serais heureux de recevoir toute réponse sur la façon d'améliorer cela davantage. 🎜🎜🎜Adresse originale en anglais : https://betterprogramming.pub/building-an-imagedownloader-with-multiprocessing-in-python-44aee36e0424🎜🎜🎜【Recommandations associées : 🎜Tutoriel vidéo Comment télécharger des images simultanément avec plusieurs threads en Comment télécharger des images simultanément avec plusieurs threads en Python3🎜】🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Vous pouvez apprendre les concepts de programmation de base et les compétences de Python dans les 2 heures. 1. Apprenez les variables et les types de données, 2. Flux de contrôle maître (instructions et boucles conditionnelles), 3. Comprenez la définition et l'utilisation des fonctions, 4. Démarrez rapidement avec la programmation Python via des exemples simples et des extraits de code.
 Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python est largement utilisé dans les domaines du développement Web, de la science des données, de l'apprentissage automatique, de l'automatisation et des scripts. 1) Dans le développement Web, les cadres Django et Flask simplifient le processus de développement. 2) Dans les domaines de la science des données et de l'apprentissage automatique, les bibliothèques Numpy, Pandas, Scikit-Learn et Tensorflow fournissent un fort soutien. 3) En termes d'automatisation et de script, Python convient aux tâches telles que les tests automatisés et la gestion du système.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
 Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Les étapes pour démarrer un serveur Redis incluent: Installez Redis en fonction du système d'exploitation. Démarrez le service Redis via Redis-Server (Linux / MacOS) ou Redis-Server.exe (Windows). Utilisez la commande redis-Cli Ping (Linux / MacOS) ou redis-Cli.exe Ping (Windows) pour vérifier l'état du service. Utilisez un client redis, tel que redis-cli, python ou node.js pour accéder au serveur.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment afficher la version serveur de redis
Apr 10, 2025 pm 01:27 PM
Comment afficher la version serveur de redis
Apr 10, 2025 pm 01:27 PM
Question: Comment afficher la version Redis Server? Utilisez l'outil de ligne de commande redis-Cli --version pour afficher la version du serveur connecté. Utilisez la commande Info Server pour afficher la version interne du serveur et devez analyser et retourner des informations. Dans un environnement de cluster, vérifiez la cohérence de la version de chaque nœud et peut être vérifiée automatiquement à l'aide de scripts. Utilisez des scripts pour automatiser les versions de visualisation, telles que la connexion avec les scripts Python et les informations d'impression.
 Dans quelle mesure le mot de passe de Navicat est-il sécurisé?
Apr 08, 2025 pm 09:24 PM
Dans quelle mesure le mot de passe de Navicat est-il sécurisé?
Apr 08, 2025 pm 09:24 PM
La sécurité du mot de passe de Navicat repose sur la combinaison de cryptage symétrique, de force de mot de passe et de mesures de sécurité. Des mesures spécifiques incluent: l'utilisation de connexions SSL (à condition que le serveur de base de données prenne en charge et configure correctement le certificat), à la mise à jour régulièrement de NAVICAT, en utilisant des méthodes plus sécurisées (telles que les tunnels SSH), en restreignant les droits d'accès et, surtout, à ne jamais enregistrer de mots de passe.
