

Index MySQL à colonne unique et résumé de l'index conjoint

Cet article vous apporte des connaissances pertinentes sur mysql, qui introduit principalement des problèmes liés aux index à une seule colonne et aux index conjoints. L'utilisation de colonnes supplémentaires dans l'index peut restreindre la portée de la recherche, mais l'utilisation d'un index à deux colonnes est différente. de l'utilisation de deux index distincts. Examinons-le ensemble, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo MySQL
1. Introduction
En utilisant des colonnes supplémentaires dans l'index, vous pouvez restreindre la portée de la recherche, mais l'utilisation d'un index avec deux colonnes est différente de l'utilisation de deux index distincts .
La structure de l'index commun est similaire à celle d'un annuaire téléphonique. Les noms des personnes sont composés de noms et de prénoms. L'annuaire téléphonique est d'abord trié par nom, puis trié par prénom pour les personnes portant le même nom. Un annuaire téléphonique est très utile si vous connaissez votre nom de famille, encore plus utile si vous connaissez votre prénom et votre nom, mais inutile si vous ne connaissez que votre prénom mais pas votre nom de famille.
Ainsi, lors de la création d'un index conjoint, vous devez soigneusement considérer l'ordre des colonnes. Les index unions sont utiles lors d'une recherche sur toutes les colonnes de l'index ou uniquement sur les premières colonnes ; ils ne sont pas utiles lors d'une recherche sur les colonnes suivantes ;
2. Index à colonne unique
Lorsque plusieurs index à colonne unique sont utilisés pour des requêtes multi-conditions, l'optimiseur donnera la priorité à la stratégie d'index optimale. Il ne peut utiliser qu'un seul index, ou il peut utiliser tous les index multiples. Cependant, plusieurs index à colonne unique créeront plusieurs arborescences d'index B+ en bas, ce qui prend plus de place et gaspille une certaine efficacité de recherche. Par conséquent, il est préférable de créer un index conjoint s'il n'y a que des requêtes conjointes à plusieurs conditions. .
3. Le principe du préfixe le plus à gauche
Comme son nom l'indique, il s'agit de la priorité la plus à gauche. Tout index consécutif commençant par l'extrême gauche peut être mis en correspondance. Si le premier champ est une requête de plage, un index distinct doit être construit lors de la création d'un. index conjoint , selon les besoins de l'entreprise, la colonne la plus fréquemment utilisée dans la clause Where est placée à l'extrême gauche. Dans ce cas, l'évolutivité est meilleure. Par exemple, le nom d'utilisateur est souvent utilisé comme condition de requête, mais l'âge n'est pas souvent utilisé, le nom d'utilisateur doit donc être placé en première position de l'index conjoint, c'est-à-dire à l'extrême gauche. .
1. Créez un index composite
ALTER TABLE employee ADD INDEX idx_name_salary (name,salary)
2. Si la caractéristique la plus à gauche de l'index composite est satisfaite, même si ce n'est qu'une partie de celui-ci, l'index composite prendra effet
SELECT * FROM employee WHERE NAME='哪吒编程'
3. apparaît, la caractéristique la plus à gauche n'est pas satisfaite et l'index sera invalide
SELECT * FROM employee WHERE salary=5000
4. Tous les index composites sont utilisés. Le nom et le salaire apparaissent dans l'ordre de gauche, et l'index prend effet
SELECT * FROM employee WHERE NAME='哪吒编程' AND salary=5000
5. caractéristique la plus à gauche, MySQL optimisera lors de l'exécution de SQL et la couche inférieure sera optimisée à l'envers
SELECT * FROM employee WHERE salary=5000 AND NAME='哪吒编程'
6 Raison
L'index composé est également appelé index conjoint Lorsque nous créons un index conjoint, tel que (k1,k2, k3), cela équivaut à créer trois index (k1), (k1,k2) et (k1,k2,k3), c'est le principe de correspondance le plus à gauche.
L'index conjoint ne satisfait pas au principe le plus à gauche et l'index échouera généralement.
4. Il existe à la fois des index conjoints et des index à colonne unique (les champs sont répétés). Comment l'index sera-t-il utilisé pour interroger MySQL à ce moment-là ?
Cela implique la stratégie d'optimisation de requêtes de MySQL lui-même. Lorsqu'une table a plusieurs index, MySQL choisit quel index utiliser en fonction du coût de l'instruction de requête.
Certaines personnes disent que la requête Where est dans l'ordre de gauche à droite ; , de sorte que les conditions avec la force d'écran la plus forte doivent être placées autant que possible à l'avant. Baidu Online a cette déclaration, mais je l'ai personnellement testée. L'optimiseur d'exécution MySQL l'optimisera. Lorsque l'index n'est pas pris en compte, l'ordre des conditions n'a pas d'impact sur l'efficacité. utilisé!
5. L'essence de l'index conjoint
Lors de la création d'un index conjoint ** (a, b, c), cela équivaut à créer (a) un index à une seule colonne, (a, b) un index conjoint et (a, b , c) index conjoint Index, si vous souhaitez que l'index prenne effet, vous ne pouvez utiliser que trois combinaisons bien sûr, comme nous l'avons testé ci-dessus, la combinaison de a et c peut également être utilisée, mais en fait uniquement l'index de a ; est utilisé et c n’est pas utilisé.
6. Échec de l'index
1. Comme la sous-requête, mettez % devant
2. Le jugement non nul n'est pas nul ; aucun index n'est utilisé avant et après l'instruction ou. Lorsqu'un seul des champs de requête gauche et droit de ou est un index, l'index ne sera valide que lorsque les champs de requête gauche et droit de ou sont des index
Or (uniquement s'il y a). sont des index avant et après, l'optimisation SQL doit éviter d'écrire des instructions );
4. Il y a une conversion implicite du type de données. Si varchar n'est pas placé entre guillemets simples, il peut être automatiquement converti en type int, invalidant l'index et provoquant une analyse complète de la table.
7. Autres points de connaissances
1. Les champs qui doivent être indexés doivent être dans la condition où
2 Les champs contenant une petite quantité de données n'ont pas besoin d'être indexés, car il y a une certaine surcharge dans la construction d'un. index. Si la quantité de données est petite, ce n'est pas nécessaire. La création d'index est lente.
3. Les index conjoints présentent plus d'avantages que la création d'index sur chaque colonne, car plus d'index sont créés, plus ils occupent d'espace disque et plus la mise à jour des données sera lente. , il faut également prêter attention à l'ordre, nous devons d'abord mettre en place une indexation stricte, afin que le dépistage soit plus fort et plus efficace.
八、MySQL存储引擎简介
1、InnoDB
支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交和回滚。
2、MyISAM
插入速度快,空间和内存使用比较低。如果表主要是用于插入新纪录和读取记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发要求比较低,也可以使用。
注意,同一个数据库也可以使用多种存储引擎的表。如果一个表要求比较高的事务处理,可以选择InnoDB。这个数据库中可以将查询要求比较高的表选择MyISAM存储。如果该数据库需要一个用于查询的临时表,可以选择MEMORY存储引擎。
九、索引结构(方法、算法)
在mysql中常用两种索引结构(算法)BTree和Hash,两种算法检索方式不一样,对查询的作用也不一样。
1、Hash
Hash索引的底层实现是由Hash表来实现的,非常适合以 key-value 的形式查询,也就是单个key 查询,或者说是等值查询。
Hash 索引可以比较方便的提供等值查询的场景,由于是一次定位数据,不像BTree索引需 要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。但是对于范围查询的话,就需要进行全表扫描了。
但为什么我们使用BTree比使用Hash多呢?主要Hash本身由于其特殊性,也带来了很多限制和弊端:
Hash索引仅仅能满足“=”,“IN”,“”查询,不能使用范围查询。
联合索引中,Hash索引不能利用部分索引键查询。 对于联合索引中的多个列,Hash是要么全部使用,要么全部不使用,并不支持BTree支持的联合索引的最优前缀,也就是联合索引的前面一个或几个索引键进行查询时,Hash索引无法被利用。
Hash索引无法避免数据的排序操作 由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。
Hash索引任何时候都不能避免表扫描 Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果。
Hash索引遇到大量Hash值相等的情况后性能并不一定会比BTree高 对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据访问,而造成整体性能底下。
2、B+ Tree
B+Tree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,
例如:
select * from user where name like 'jack%'; select * from user where name like 'jac%k%';
如果一通配符开头,或者没有使用常量,则不会使用索引,
例如:
select * from user where name like '%jack'; select * from user where name like simply_name;
3、 B+/-Tree原理
在数据库中,数据量相对较大,多路查找树显然更加适合数据库的应用场景,接下来我们就介绍这两类多路查找树,毕竟作为程序员,心里没点B树怎么能行呢?
B树:B树就是B-树,他有着如下的特性:
B树不同于二叉树,他们的一个节点可以存储多个关键字和多个子树指针,这就是B+树的特点;
一个m阶的B树要求除了根节点以外,所有的非叶子子节点必须要有[m/2,m]个子树;
根节点必须只能有两个子树,当然,如果只有根节点一个节点的情况存在;
B树是一个查找二叉树,这点和二叉查找树很像,他都是越靠前的子树越小,并且,同一个节点内,关键字按照大小排序;
B树的一个节点要求子树的个数等于关键字的个数+1;
B+树就是B树的plus版
B+树将所有的查找结果放在叶子节点中,这也就意味着查找B+树,就必须到叶子节点才能返回结果;
Le nombre de mots-clés dans chaque nœud de l'arbre B+ est le même que le nombre de pointeurs de sous-arbre
Chaque mot-clé du nœud non-feuille de l'arbre B+ correspond à un pointeur, et le mot-clé est le maximum du sous-arbre, ou valeur minimale ;
Optimisez le B-Tree dans la section précédente. Étant donné que les nœuds non-feuilles de B+Tree ne stockent que les informations sur les valeurs clés, en supposant que chaque bloc de disque puisse stocker 4 valeurs clés. et les informations du pointeur, cela devient La structure de B+Tree est comme indiqué ci-dessous :
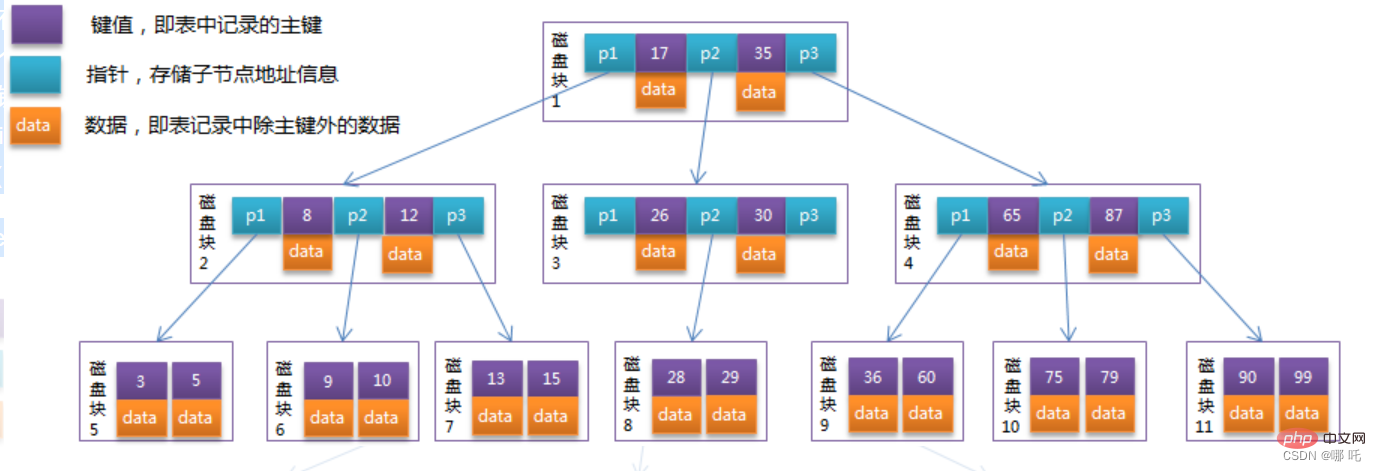
Habituellement, il y a deux pointeurs de tête sur B+Tree, l'un pointe vers le nœud racine, l'autre pointe vers le nœud feuille avec le plus petit mot-clé et tous les nœuds feuilles (c'est-à-dire les nœuds de données). Il y a une structure en anneau de chaîne entre les deux. Par conséquent, deux opérations de recherche peuvent être effectuées sur B+Tree : l’une est une recherche par plage et une recherche par pagination pour la clé primaire, et l’autre est une recherche aléatoire à partir du nœud racine.
Peut-être qu'il n'y a que 22 enregistrements de données dans l'exemple ci-dessus et que les avantages de B+Tree ne sont pas visibles. Voici un calcul :
La taille de la page dans le moteur de stockage InnoDB est de 16 Ko et le type de clé primaire du. la table générale est la section INT (occupe 4 mots)) ou BIGINT (occupe 8 octets), le type de pointeur est généralement de 4 ou 8 octets, ce qui signifie qu'une page (un nœud dans B+Tree) stocke probablement 16 Ko/( 8B+8B )=1K valeurs clés (car il s'agit d'une estimation, pour faciliter le calcul, la valeur de K ici est 〖10〗^3). 16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。
也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 En d'autres termes, un index B+Tree d'une profondeur de 3 peut conserver 10^3 * 10^3 * 10^3 = 1 milliard d'enregistrements.
Dans les situations réelles, chaque nœud peut ne pas être entièrement rempli, donc dans la base de données, la hauteur de B+Tree est généralement de 2 à 4 couches. Le moteur de stockage InnoDB de MySQL est conçu de telle sorte que le nœud racine réside en mémoire, ce qui signifie que seules 1 à 3 opérations d'E/S disque sont nécessaires pour trouver l'enregistrement de ligne d'une certaine valeur de clé.
L'index B+Tree dans la base de données peut être divisé en index clusterisé et index secondaire. L'exemple de diagramme B+Tree ci-dessus est implémenté dans la base de données en tant qu'index clusterisé. Les nœuds feuilles du B+Tree de l'index clusterisé stockent les données d'enregistrement de ligne de la table entière. La différence entre un index auxiliaire et un index clusterisé est que les nœuds feuilles de l'index auxiliaire ne contiennent pas toutes les données de l'enregistrement de ligne, mais la clé d'index clusterisé qui stocke les données de ligne correspondantes, c'est-à-dire la clé primaire. Lors de l'interrogation de données via un index secondaire, le moteur de stockage InnoDB parcourt l'index secondaire pour trouver la clé primaire, puis trouve les données complètes de l'enregistrement de ligne dans l'index clusterisé via la clé primaire.
Apprentissage recommandé : Tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
