

Résumé de l'utilisation détaillée de Stream en Java8

Cet article vous apporte des connaissances pertinentes sur Java, qui présentent principalement des problèmes liés à l'utilisation détaillée de Stream. Le nouveau Stream dans la version, ainsi que le Lambda qui apparaît dans la même version, nous offrent un excellent moyen d'exploiter les collections ( Collection). Très pratique, jetons-y un coup d'œil ci-dessous, j'espère que cela sera utile à tout le monde.

Etude recommandée : "Tutoriel vidéo Java"
1. Présentation
Java 8 est une version très réussie Le nouveau Stream de cette version, combiné au Lambda qui apparaît dans la même version, nous donne. un ensemble d'opérations ( Collection) offre une grande commodité. Stream est un nouveau membre du JDK8, qui permet le traitement des collections de données de manière déclarative. Le flux Stream peut être considéré comme un itérateur avancé pour parcourir la collection de données. Stream est le concept abstrait clé pour le traitement des collections dans Java 8. Il peut spécifier les opérations que vous souhaitez effectuer sur la collection et effectuer des opérations très complexes telles que la recherche/filtrage/filtrage, le tri, l'agrégation et le mappage des données. L'utilisation de l'API Stream pour opérer sur les données de collecte est similaire à l'utilisation de SQL pour effectuer des requêtes de base de données. Vous pouvez également utiliser l'API Stream pour effectuer des opérations en parallèle. En bref, l'API Stream offre un moyen efficace et facile à utiliser de traiter les données.
1. Avantages de l'utilisation de streams
Le code est écrit de manière déclarative, décrivant ce qu'il veut accomplir, plutôt que comment accomplir une opération.
Plusieurs opérations de base peuvent être connectées pour exprimer des pipelines de traitement de données complexes tout en gardant le code clair et lisible.
2. Qu'est-ce qu'un flux ?
Génère une séquence d'éléments à partir d'une source qui prend en charge les opérations de traitement de données. La source de données peut être une collection, un tableau ou une ressource IO.
D'un point de vue opérationnel, les flux sont différents des collections. Les flux ne stockent pas de valeurs de données ; le but des flux est de traiter les données, il s'agit d'algorithmes et de calculs.
Si vous utilisez une collection comme source de données d'un flux, la création du flux ne provoquera pas le flux de données ; si l'opération de terminaison du flux nécessite une valeur, le flux obtiendra uniquement la valeur de la collection ; utilisé une fois.
L'idée centrale des flux est de retarder le calcul, et les flux ne calculent les valeurs que lorsque cela est nécessaire. 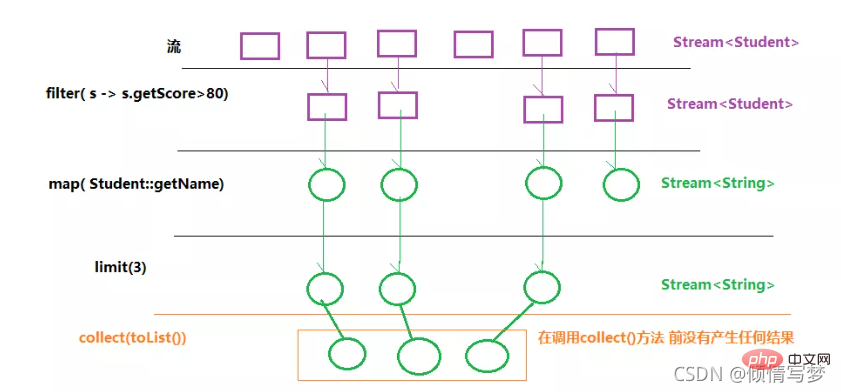
Le flux peut être créé à partir d'un tableau ou d'une collection. Les opérations sur les flux sont divisées en deux types :
Opérations intermédiaires, à chaque fois qu'un nouveau flux est renvoyé, il peut y en avoir plusieurs.
Opération de terminal, chaque flux ne peut effectuer qu'une seule opération de terminal et le flux ne peut pas être réutilisé une fois l'opération de terminal terminée. Les opérations du terminal produisent une nouvelle collection ou valeur.
Caractéristiques :
n'est pas une structure de données et ne sauvegardera pas les données.
Il ne modifiera pas la source de données d'origine, il enregistrera les données exploitées dans un autre objet. (Réservation : après tout, la méthode peek peut modifier les éléments du flux)
Évaluation paresseuse Lors du traitement intermédiaire du flux, l'opération est uniquement enregistrée et ne sera pas exécutée immédiatement. Elle doit attendre l'opération de terminaison. est effectué avant que l'opération proprement dite soit effectuée.
2. Classification
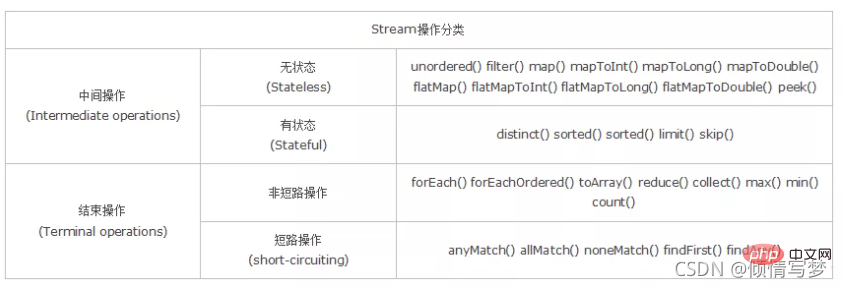
Stateless : signifie que le traitement des éléments n'est pas affecté par les éléments précédents ;
Stateful : signifie que l'opération ne peut continuer qu'après avoir obtenu tous les éléments ;
Fonctionnement sans court-circuit : signifie que tous les éléments doivent être traités pour obtenir le résultat final
Fonctionnement en court-circuit : signifie que le résultat final peut être obtenu lorsque certains éléments répondant aux conditions sont rencontrés, comme A ; || B. Tant que A est vrai, aucun jugement n'est requis. Le résultat de B.
3. Création de Stream
Le flux peut être créé via un tableau de collection.
1. Utilisez la méthode java.util.Collection.stream() pour créer un flux avec une collection
List<string> list = Arrays.asList("a", "b", "c");// 创建一个顺序流
Stream<string> stream = list.stream();// 创建一个并行流
Stream<string> parallelStream = list.parallelStream();</string></string></string>2 Utilisez la méthode java.util.Arrays.stream(T[]array) pour créer un flux avec un. array
int[] array={1,3,5,6,8};IntStream stream = Arrays.stream(array);3. Utilisez des méthodes Stream Static : of(), iterate(), generate()
Stream<integer> stream = Stream.of(1, 2, 3, 4, 5, 6); Stream<integer> stream2 = Stream.iterate(0, (x) -> x + 3).limit(4);stream2.forEach(System.out::println); Stream<double> stream3 = Stream.generate(Math::random).limit(3);stream3.forEach(System.out::println);</double></integer></integer>
Résultats de sortie :
0 3 6 90.67961569092719940.19143142088542830.8116932592396652
Une distinction simple entre stream et parallelStream : stream est un flux séquentiel et le thread principal. effectue des opérations sur le flux en séquence, tandis que parallelStream est un flux parallèle, exploite en interne le flux de manière multithread en exécution parallèle, mais le principe est qu'il n'y a aucune exigence d'ordre pour le traitement des données dans le flux. Par exemple, en filtrant les nombres impairs dans une collection, la différence de traitement entre les deux est la suivante : 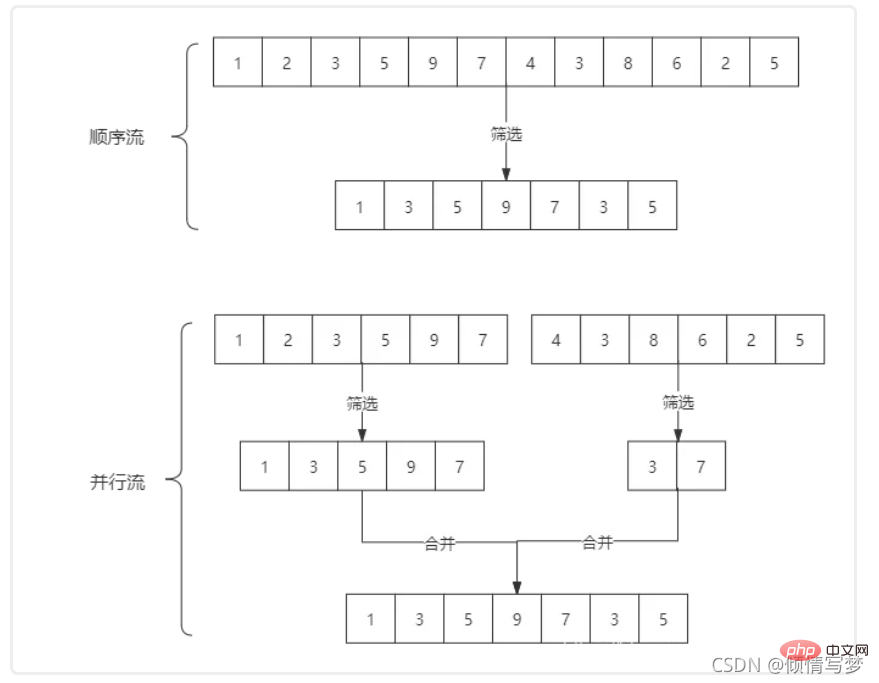
Si la quantité de données dans le flux est suffisamment importante, les flux parallèles peuvent accélérer le traitement.
En plus de créer directement des flux parallèles, vous pouvez également convertir des flux séquentiels en flux parallèles via parallel() :
Optional<integer> findFirst = list.stream().parallel().filter(x->x>6).findFirst();</integer>
IV Introduction à l'API Stream
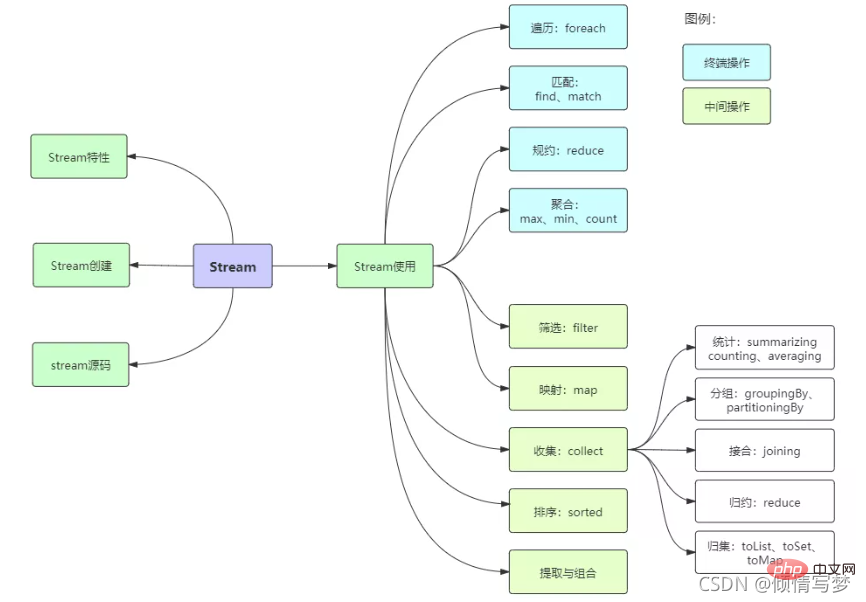
先贴上几个案例,水平高超的同学可以挑战一下:从员工集合中筛选出salary大于8000的员工,并放置到新的集合里。统计员工的最高薪资、平均薪资、薪资之和。将员工按薪资从高到低排序,同样薪资者年龄小者在前。将员工按性别分类,将员工按性别和地区分类,将员工按薪资是否高于8000分为两部分。用传统的迭代处理也不是很难,但代码就显得冗余了,跟Stream相比高下立判。
Prérequis : Classe d'employés
static List<person> personList = new ArrayList<person>();private static void initPerson() {
personList.add(new Person("张三", 8, 3000));
personList.add(new Person("李四", 18, 5000));
personList.add(new Person("王五", 28, 7000));
personList.add(new Person("孙六", 38, 9000));}</person></person>1. . Traversal/ Matching (foreach/find/match)
Stream prend également en charge les éléments de parcours et de correspondance de type collection, sauf que les éléments du Stream existent en tant que types facultatifs. La traversée et la correspondance des flux sont très simples.
// import已省略,请自行添加,后面代码亦是
public class StreamTest {
public static void main(String[] args) {
List<integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);
// 遍历输出符合条件的元素
list.stream().filter(x -> x > 6).forEach(System.out::println);
// 匹配第一个
Optional<integer> findFirst = list.stream().filter(x -> x > 6).findFirst();
// 匹配任意(适用于并行流)
Optional<integer> findAny = list.parallelStream().filter(x -> x > 6).findAny();
// 是否包含符合特定条件的元素
boolean anyMatch = list.stream().anyMatch(x -> x <h3 id="按条件匹配filter">2、按条件匹配filter</h3>
<p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/c32799257ddfee7ae65dfaf7bce4b27c-5.png" class="lazy" alt="在这里插入Résumé de lutilisation détaillée de Stream en Java8描述"></p>
<p><strong>(1)筛选员工中已满18周岁的人,并形成新的集合</strong></p>
<pre class="brush:php;toolbar:false">/**
* 筛选员工中已满18周岁的人,并形成新的集合
* @思路
* List<person> list = new ArrayList<person>();
* for(Person person : personList) {
* if(person.getAge() >= 18) {
* list.add(person);
* }
* }
*/
private static void filter01() {
initPerson();
List<person> collect = personList.stream().filter(x -> x.getAge()>=18).collect(Collectors.toList());
System.out.println(collect);}</person></person></person>
(2)自定义条件匹配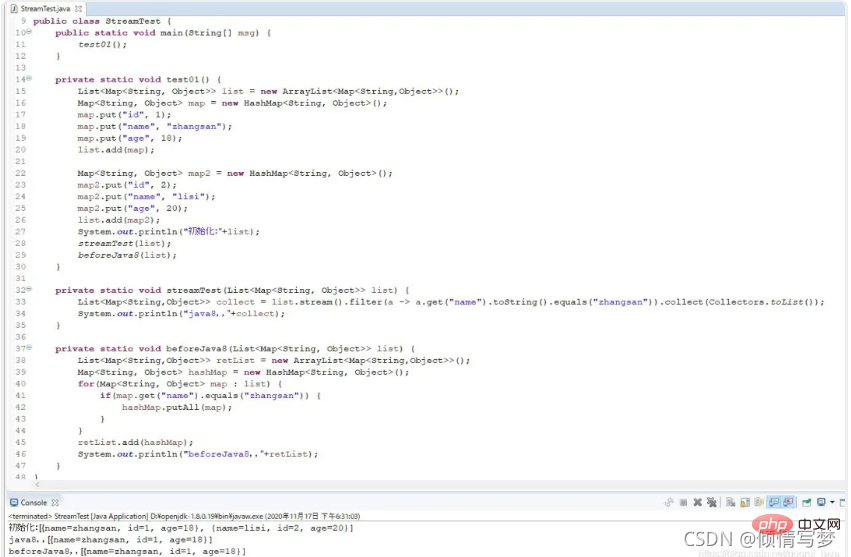
3、聚合max、min、count
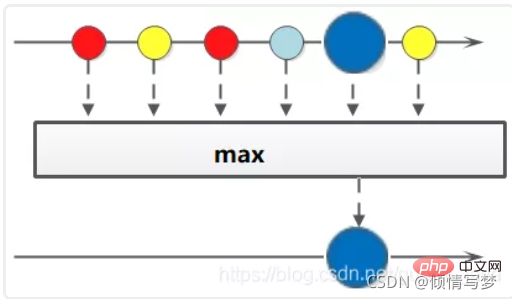
(1)获取String集合中最长的元素
/**
* 获取String集合中最长的元素
* @思路
* List<string> list = Arrays.asList("zhangsan", "lisi", "wangwu", "sunliu");
* String max = "";
* int length = 0;
* int tempLength = 0;
* for(String str : list) {
* tempLength = str.length();
* if(tempLength > length) {
* length = str.length();
* max = str;
* }
* }
* @return zhangsan
*/
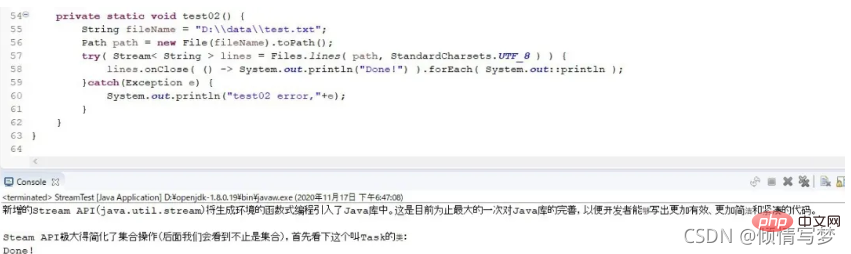
private static void test02() {
List<string> list = Arrays.asList("zhangsan", "lisi", "wangwu", "sunliu");
Comparator super String> comparator = Comparator.comparing(String::length);
Optional<string> max = list.stream().max(comparator);
System.out.println(max);}</string></string></string>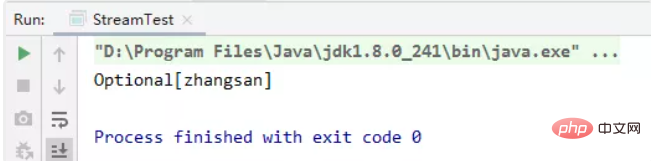
(2)获取Integer集合中的最大值
//获取Integer集合中的最大值
private static void test05() {
List<integer> list = Arrays.asList(1, 17, 27, 7);
Optional<integer> max = list.stream().max(Integer::compareTo);
// 自定义排序
Optional<integer> max2 = list.stream().max(new Comparator<integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
});
System.out.println(max2);}</integer></integer></integer></integer>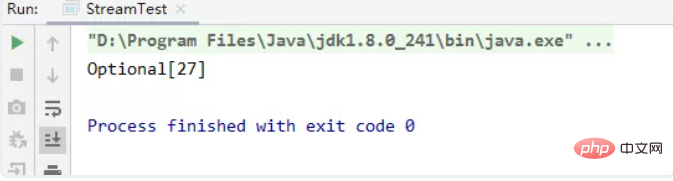
//获取员工中年龄最大的人
private static void test06() {
initPerson();
Comparator super Person> comparator = Comparator.comparingInt(Person::getAge);
Optional<person> max = personList.stream().max(comparator);
System.out.println(max);}</person>(3)获取员工中年龄最大的人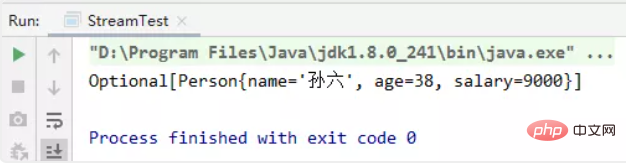
(4)计算integer集合中大于10的元素的个数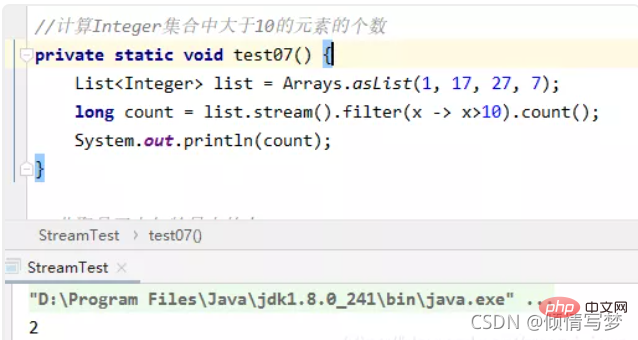
4、map与flatMap
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
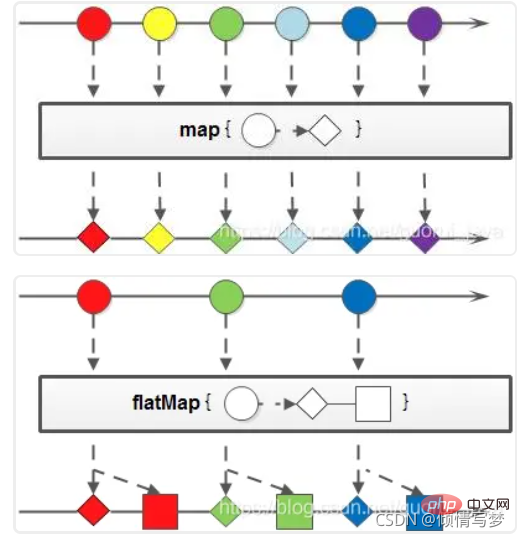
(1)字符串大写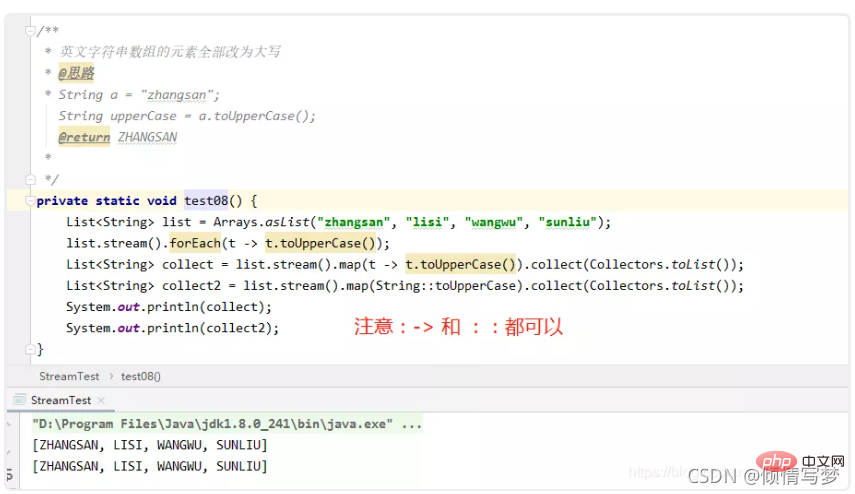
(2)整数数组每个元素+3
/**
* 整数数组每个元素+3
* @思路
* List<integer> list = Arrays.asList(1, 17, 27, 7);
List<integer> list2 = new ArrayList<integer>();
for(Integer num : list) {
list2.add(num + 3);
}
@return [4, 20, 30, 10]
*/
private static void test09() {
List<integer> list = Arrays.asList(1, 17, 27, 7);
List<integer> collect = list.stream().map(x -> x + 3).collect(Collectors.toList());
System.out.println(collect);}</integer></integer></integer></integer></integer>(3)公司效益好,每人涨2000
/**
* 公司效益好,每人涨2000
*
*/
private static void test10() {
initPerson();
List<person> collect = personList.stream().map(x -> {
x.setAge(x.getSalary()+2000);
return x;
}).collect(Collectors.toList());
System.out.println(collect);}</person>(4)将两个字符数组合并成一个新的字符数组
/**
* 将两个字符数组合并成一个新的字符数组
*
*/
private static void test11() {
String[] arr = {"z, h, a, n, g", "s, a, n"};
List<string> list = Arrays.asList(arr);
System.out.println(list);
List<string> collect = list.stream().flatMap(x -> {
String[] array = x.split(",");
Stream<string> stream = Arrays.stream(array);
return stream;
}).collect(Collectors.toList());
System.out.println(collect);}</string></string></string>(5)将两个字符数组合并成一个新的字符数组
/**
* 将两个字符数组合并成一个新的字符数组
* @return [z, h, a, n, g, s, a, n]
*/
private static void test11() {
String[] arr = {"z, h, a, n, g", "s, a, n"};
List<string> list = Arrays.asList(arr);
List<string> collect = list.stream().flatMap(x -> {
String[] array = x.split(",");
Stream<string> stream = Arrays.stream(array);
return stream;
}).collect(Collectors.toList());
System.out.println(collect);}</string></string></string>5、规约reduce
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
(1)求Integer集合的元素之和、乘积和最大值
/**
* 求Integer集合的元素之和、乘积和最大值
*
*/
private static void test13() {
List<integer> list = Arrays.asList(1, 2, 3, 4);
//求和
Optional<integer> reduce = list.stream().reduce((x,y) -> x+ y);
System.out.println("求和:"+reduce);
//求积
Optional<integer> reduce2 = list.stream().reduce((x,y) -> x * y);
System.out.println("求积:"+reduce2);
//求最大值
Optional<integer> reduce3 = list.stream().reduce((x,y) -> x>y?x:y);
System.out.println("求最大值:"+reduce3);}</integer></integer></integer></integer>(2)求所有员工的工资之和和最高工资
/*
* 求所有员工的工资之和和最高工资
*/
private static void test14() {
initPerson();
Optional<integer> reduce = personList.stream().map(Person :: getSalary).reduce(Integer::sum);
Optional<integer> reduce2 = personList.stream().map(Person :: getSalary).reduce(Integer::max);
System.out.println("工资之和:"+reduce);
System.out.println("最高工资:"+reduce2);}</integer></integer>6、收集(toList、toSet、toMap)
取出大于18岁的员工转为map
/**
* 取出大于18岁的员工转为map
*
*/
private static void test15() {
initPerson();
Map<string> collect = personList.stream().filter(x -> x.getAge() > 18).collect(Collectors.toMap(Person::getName, y -> y));
System.out.println(collect);}</string>7、collect
Collectors提供了一系列用于数据统计的静态方法:
计数: count
平均值: averagingInt、 averagingLong、 averagingDouble
最值: maxBy、 minBy
求和: summingInt、 summingLong、 summingDouble
统计以上所有: summarizingInt、 summarizingLong、 summarizingDouble
/**
* 统计员工人数、平均工资、工资总额、最高工资
*/
private static void test01(){
//统计员工人数
Long count = personList.stream().collect(Collectors.counting());
//求平均工资
Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
//求最高工资
Optional<integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));
//求工资之和
Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary));
//一次性统计所有信息
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println("统计员工人数:"+count);
System.out.println("求平均工资:"+average);
System.out.println("求最高工资:"+max);
System.out.println("求工资之和:"+sum);
System.out.println("一次性统计所有信息:"+collect);}</integer>8、分组(partitioningBy/groupingBy)
分区:将stream按条件分为两个 Map,比如员工按薪资是否高于8000分为两部分。
分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。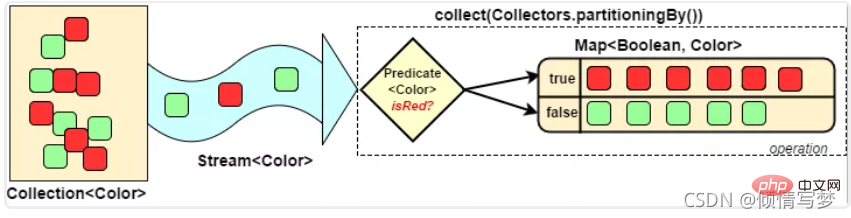
将员工按薪资是否高于8000分为两部分;将员工按性别和地区分组
public class StreamTest {
public static void main(String[] args) {
personList.add(new Person("zhangsan",25, 3000, "male", "tieling"));
personList.add(new Person("lisi",27, 5000, "male", "tieling"));
personList.add(new Person("wangwu",29, 7000, "female", "tieling"));
personList.add(new Person("sunliu",26, 3000, "female", "dalian"));
personList.add(new Person("yinqi",27, 5000, "male", "dalian"));
personList.add(new Person("guba",21, 7000, "female", "dalian"));
// 将员工按薪资是否高于8000分组
Map<boolean>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));
// 将员工按性别分组
Map<string>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));
// 将员工先按性别分组,再按地区分组
Map<string>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));
System.out.println("员工按薪资是否大于8000分组情况:" + part);
System.out.println("员工按性别分组情况:" + group);
System.out.println("员工按性别、地区:" + group2);
}}</string></string></boolean>9、连接joining
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。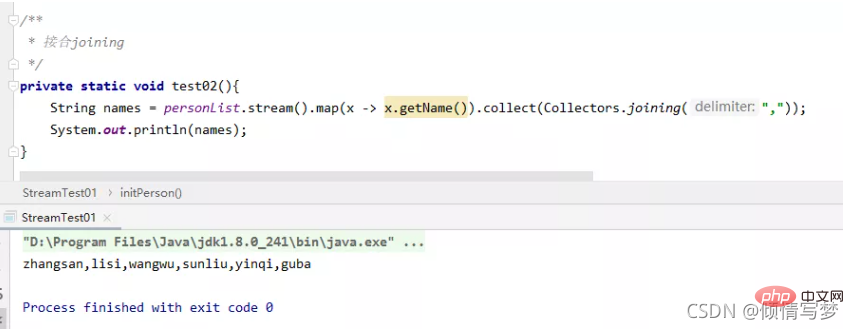
10、排序sorted
将员工按工资由高到低(工资一样则按年龄由大到小)排序
private static void test04(){
// 按工资升序排序(自然排序)
List<string> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName)
.collect(Collectors.toList());
// 按工资倒序排序
List<string> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed())
.map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄升序排序
List<string> newList3 = personList.stream()
.sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName)
.collect(Collectors.toList());
// 先按工资再按年龄自定义排序(降序)
List<string> newList4 = personList.stream().sorted((p1, p2) -> {
if (p1.getSalary() == p2.getSalary()) {
return p2.getAge() - p1.getAge();
} else {
return p2.getSalary() - p1.getSalary();
}
}).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资升序排序:" + newList);
System.out.println("按工资降序排序:" + newList2);
System.out.println("先按工资再按年龄升序排序:" + newList3);
System.out.println("先按工资再按年龄自定义降序排序:" + newList4);}</string></string></string></string>11、提取/组合
流也可以进行合并、去重、限制、跳过等操作。
private static void test05(){
String[] arr1 = { "a", "b", "c", "d" };
String[] arr2 = { "d", "e", "f", "g" };
Stream<string> stream1 = Stream.of(arr1);
Stream<string> stream2 = Stream.of(arr2);
// concat:合并两个流 distinct:去重
List<string> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
// limit:限制从流中获得前n个数据
List<integer> collect = Stream.iterate(1, x -> x + 2).limit(10).collect(Collectors.toList());
// skip:跳过前n个数据
List<integer> collect2 = Stream.iterate(1, x -> x + 2).skip(1).limit(5).collect(Collectors.toList());
System.out.println("流合并:" + newList);
System.out.println("limit:" + collect);
System.out.println("skip:" + collect2);}</integer></integer></string></string></string>12、读取文件的流操作
13、计算两个list中的差集
//计算两个list中的差集 List<string> reduce1 = allList.stream().filter(item -> !wList.contains(item)).collect(Collectors.toList());</string>
推荐学习:《java视频教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Guide du générateur de nombres aléatoires en Java. Nous discutons ici des fonctions en Java avec des exemples et de deux générateurs différents avec d'autres exemples.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
