

Cet article vous apporte des connaissances pertinentes sur Redis, qui présente principalement le contenu pertinent sur l'avalanche de cache, la panne de cache et la pénétration du cache. J'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Redis
Concernant les problèmes à haute fréquence de Redis, l'avalanche de cache, la panne de cache et la pénétration du cache doivent être indispensables. Je pense que tout le monde s'est vu poser des questions similaires lors des entretiens. Pourquoi ces questions sont-elles si populaires ? Car lorsque nous utilisons le cache Redis, ces problèmes sont faciles à rencontrer. Voyons ensuite comment ces problèmes surviennent et quelles sont les solutions correspondantes.
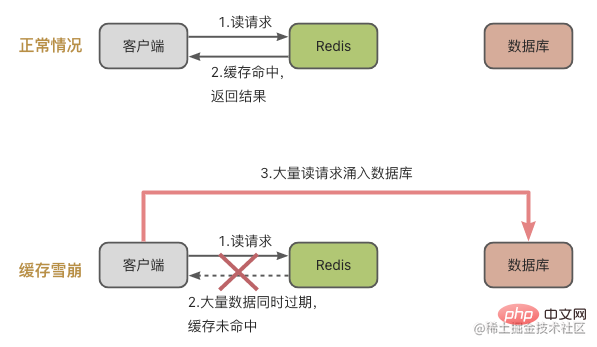
Tout d'abord, jetons un coup d'œil à l'avalanche de cache Le concept d'avalanche de cache est le suivant : un grand nombre de requêtes ne sont pas traitées dans le cache Redis, ce qui entraîne un afflux de requêtes dans la base de données, puis la pression sur. la base de données augmente considérablement.
Les raisons de l'avalanche de cache peuvent être résumées en 2 raisons :
Regardons le premier scénario : une grande quantité de données dans le cache expire en même temps.
Combiné avec la légende, cela signifie qu'une grande quantité de données a expiré en même temps, et puis il y a eu de nombreuses demandes de lecture des données à ce moment-là. Bien entendu, une avalanche de cache se produira, provoquant une augmentation spectaculaire de la pression sur la base de données.
Pour faire face au problème d'une grande quantité de données qui expire en même temps, il existe généralement deux solutions :
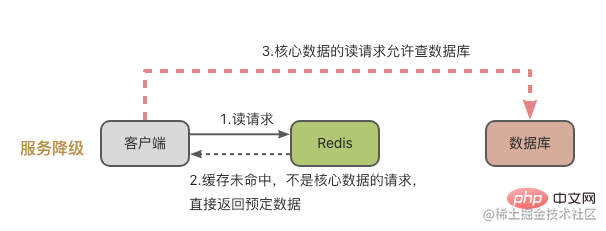
Après avoir examiné la situation dans laquelle une grande quantité de données expire en même temps, examinons la situation d'échec de l'instance de cache Redis.
Dans ce cas, Redis ne peut pas traiter la demande de lecture et la demande sera naturellement envoyée à la base de données.
De manière générale, nous avons deux manières de gérer cette situation :
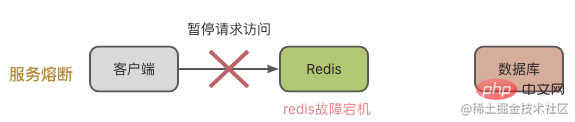
Disjoncteur de service, c'est-à-dire qu'en cas de panne de Redis, les demandes d'accès au système de cache sont suspendues. Attendez que Redis revienne à la normale avant d'ouvrir la demande d'accès.
De cette façon, nous devons surveiller l'état d'exécution de Redis ou de la base de données, comme la pression de charge de MySQL, l'utilisation du processeur de Redis, l'utilisation de la mémoire et le QPS, etc. Lorsqu'il est découvert que le cache de l'instance Redis s'est effondré, le service sera suspendu.
Cette situation peut effectivement générer un grand nombre de requêtes et mettre la pression sur la base de données. Cependant, les demandes d'accès seront suspendues, ce qui aura un impact important sur le côté commercial.
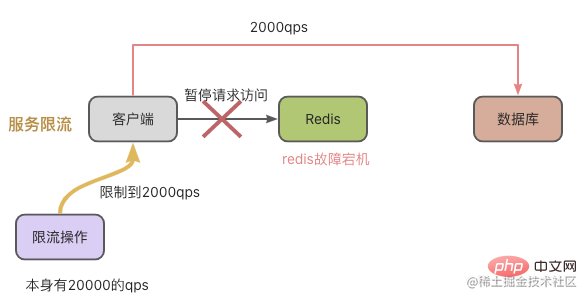
Par conséquent, afin de réduire l'impact sur le côté commercial, nous pouvons utiliser la limitation du courant de requête pour contrôler le QPS et éviter trop de requêtes à la base de données. Par exemple, dans l'illustration ci-dessous, il y a 20 000 requêtes par seconde, mais elles ont été interrompues en raison d'une panne de Redis. Notre opération de limitation actuelle a réduit le nombre de qps à 2 000 par seconde, et la base de données n'a toujours eu aucun problème à traiter 2 000 qps.
La panne du cache signifie que les données de points d'accès individuelles fréquemment consultées ne peuvent pas être mises en cache, puis les demandes sont versées dans la base de données. Cela arrive souvent lorsque les données du hotspot expirent.
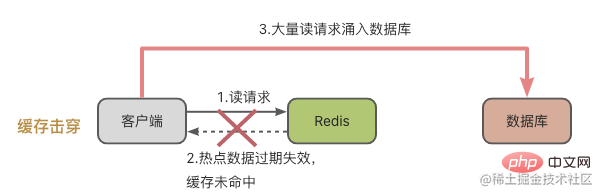
Concernant le problème de panne de cache, nous savons qu'il s'agit de données chaudes auxquelles on accède très fréquemment, donc la méthode de traitement est simple et grossière, et le délai d'expiration n'est pas défini directement. Attendez simplement que les données du hotspot ne soient pas consultées fréquemment, puis gérez-les manuellement.
L'avalanche de cache est quelque chose de spécial, cela signifie que les données auxquelles on accède ne se trouvent ni dans le cache Redis ni dans la base de données. Lorsqu'un grand nombre de requêtes entrent dans le système, Redis et la base de données seront soumis à une pression énorme.
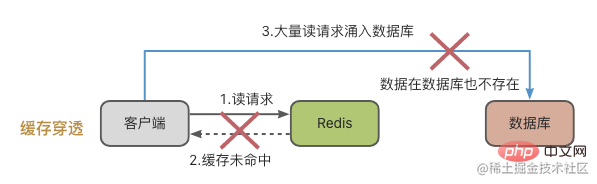
Il y a généralement deux raisons à la pénétration du cache :
Pour la pénétration du cache, vous pouvez vous référer aux solutions suivantes :
Les premier et troisième points sont plus faciles à comprendre et ne seront pas décrits ici. Concentrons-nous sur le deuxième point : les filtres Bloom.
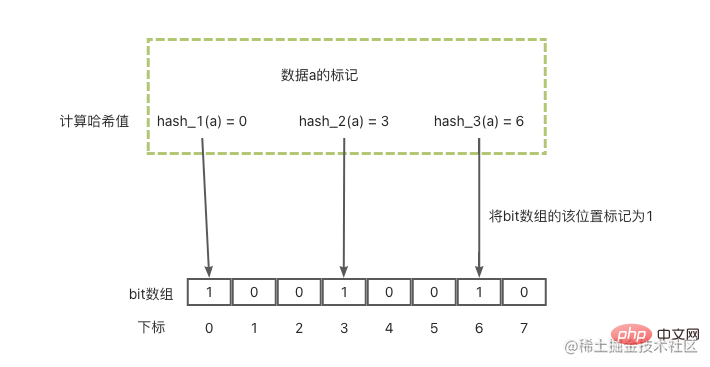
Le filtre Bloom est principalement utilisé pour déterminer si un élément est dans un ensemble. Il se compose d'un vecteur binaire de taille fixe (peut être compris comme un tableau de bits avec une valeur par défaut de 0) et d'une série de fonctions de mappage.
Voyons d'abord comment le filtre Bloom marque une donnée comme une :
Avec ces 3 étapes, l'étiquetage des données est terminé. Ensuite, pour interroger les données lorsqu'elles ne sont pas là, procédez comme suit :
En regardant l'image ci-dessous, le principe de base est le suivant.
Apprentissage recommandé : Tutoriel vidéo Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé
 Que sont les bases de données en mémoire ?
Que sont les bases de données en mémoire ?
 Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
 Comment utiliser Redis comme serveur de cache
Comment utiliser Redis comme serveur de cache
 Comment Redis résout la cohérence des données
Comment Redis résout la cohérence des données
 Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
 Quelles données le cache Redis stocke-t-il généralement ?
Quelles données le cache Redis stocke-t-il généralement ?
 Quels sont les 8 types de données de Redis
Quels sont les 8 types de données de Redis









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



