

Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement des problèmes liés à l'optimisation des requêtes courantes. Examinons-le ensemble, j'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo MySQL
Une fois le programme en ligne et exécuté pendant un certain temps, une fois que la quantité de données augmente, vous ressentirez plus ou moins des retards, des décalages, etc. dans le système Ce type de problème se produit. Les programmeurs ou les architectes sont tenus d'effectuer des travaux de réglage du système. Une grande quantité d'expérience pratique montre que même s'il existe de nombreuses méthodes de réglage, le contenu impliquant le réglage SQL reste une partie très importante. , résumant certaines stratégies d'optimisation SQL qui peuvent être impliquées dans le travail ;
On peut dire que pour la plupart des systèmes, lire plus et écrire moins doit être la norme, ce qui signifie que le SQL impliquant des requêtes est très fréquent ;
Préparation, ajoutez 100 000 éléments de données à une table de test
Utilisez la procédure stockée suivante pour créer un lot de données pour une seule table, remplacez simplement la table par la vôtre
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
Ensuite, appelez cette procédure stockée
1 |
|
Cet article a préparé 3 tables, à savoir la table des étudiants, la table des classes et la table des comptes, chacune avec 500 000, 10 000 et 100 000 données à tester ;
 1. rencontré dans le développement.Une situation est que lorsque le nombre de pagination est très important, la requête prend souvent beaucoup de temps, comme pour interroger la table étudiant, utilisez la requête SQL suivante, qui prend 0,2 seconde ;
1. rencontré dans le développement.Une situation est que lorsque le nombre de pagination est très important, la requête prend souvent beaucoup de temps, comme pour interroger la table étudiant, utilisez la requête SQL suivante, qui prend 0,2 seconde ;
limit 400000,10
 , vous besoin de
, vous besoin de MySQL 4000 avant le tri 10 record enregistrement, seulement 400000 - 4 00 seront renvoyés 010 enregistrements, autres Le coût de la suppression des enregistrements et du tri des requêtes est très élevé
Idées d'optimisation :
1) Terminez l'opération de tri et de pagination sur l'index, et enfin associez-le au contenu des autres colonnes requis pour la requête de table d'origine basée sur la clé primaire
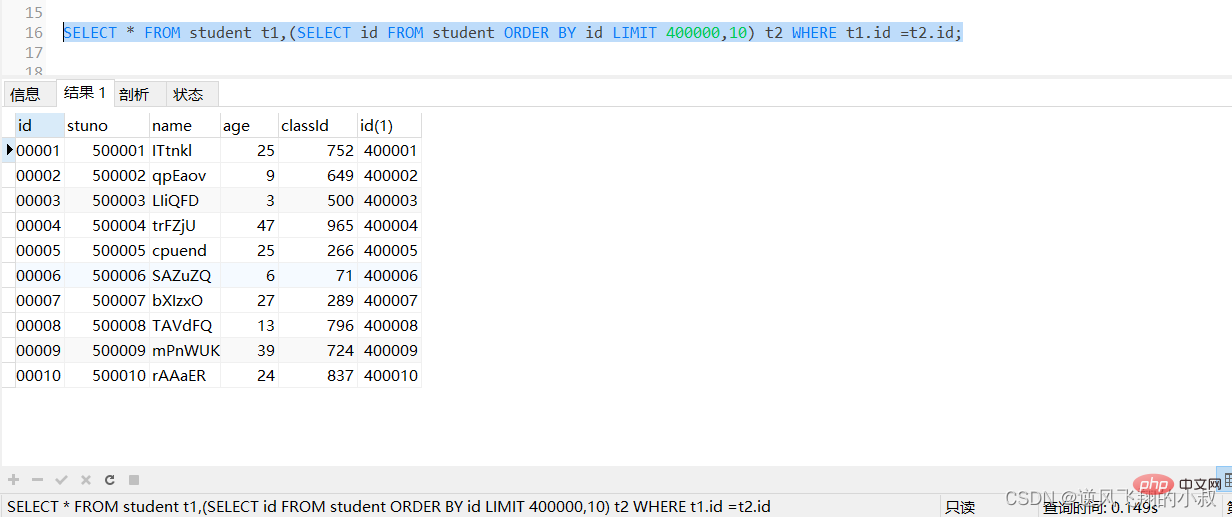
SELECT * FROM student t1,(SELECT id FROM student ORDER BY id LIMIT 400000,10) t2 WHERE t1.id =t2.id;
执行上面的sql,可以看到响应时间有一定的提升;
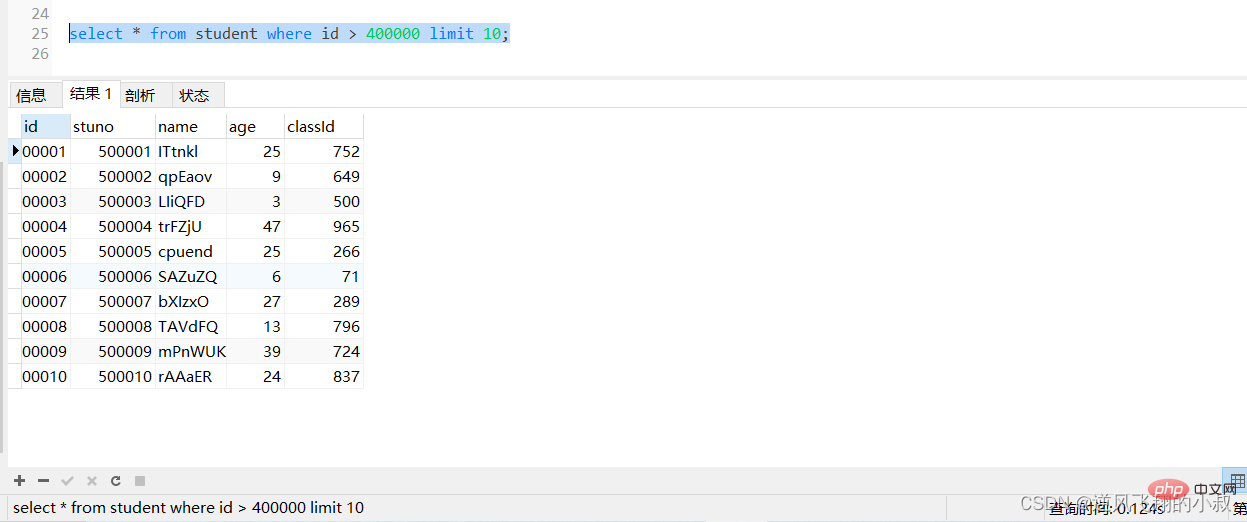
2)对于主键自增的表,可以把Limit 查询转换成某个位置的查询
select * from student where id > 400000 limit 10;
执行上面的sql,可以看到响应时间有一定的提升;
2、关联查询优化
在实际的业务开发过程中,关联查询可以说随处可见,关联查询的优化核心思路是,最好为关联查询的字段添加索引,这是关键,具体到不同的场景,还需要具体分析,这个跟mysql的引擎在执行优化策略的方案选择时有一定关系;
2.1 左连接或右连接
下面是一个使用left join 的查询,可以预想到这条sql查询的结果集非常大
1
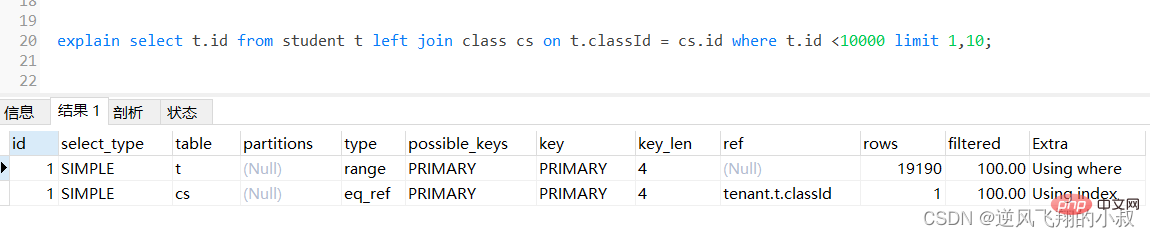
select t.* from student t left joinclasscs on t.classId = cs.id;Copier après la connexion为了检查下sql的执行效率,使用explain做一下分析,可以看到,第一张表即left join左边的表student走了全表扫描,而class表走了主键索引,尽管结果集较大,还是走了索引;
针对这种场景的查询,思路如下:
- 让查询的字段尽量包含在主键索引或者覆盖索引中;
- 查询的时候尽量使用分页查询;
关于左连接(右连接)的explain结果补充说明
- 左连接左边的表一般为驱动表,右边的表为被驱动表;
- 尽可能让数据集小的表作为驱动表,减少mysql内部循环的次数;
- 两表关联时,explain结果展示中,第一栏一般为驱动表;
2.2 关联查询关联的字段建立索引
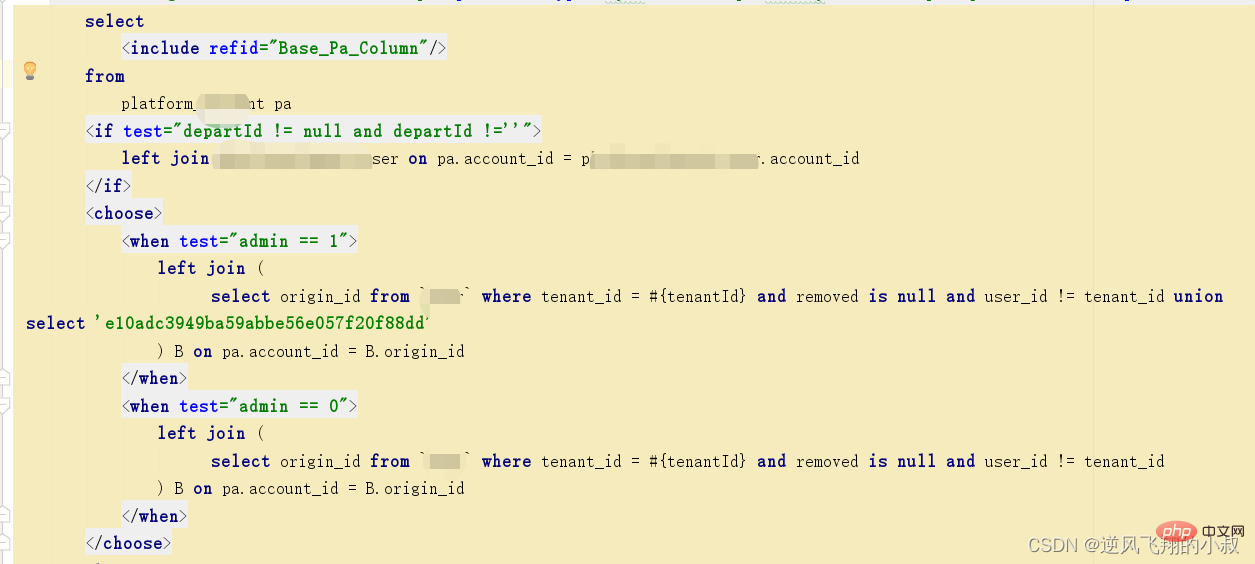
看下面的这条sql,其关联字段非表的主键,而是普通的字段;
1
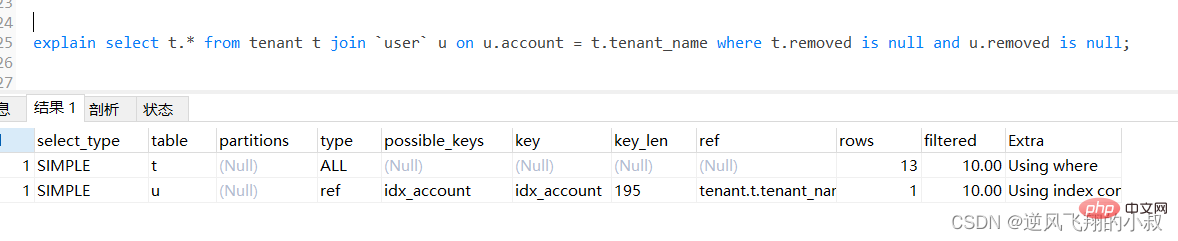
explain select u.* from tenant t left join `user` u on u.account = t.tenant_name where t.removed is nullandu.removed is null;Copier après la connexion
通过explain分析可以发现,左边的表走了全表扫描,可以考虑给左边的表的tenant_name和user表的account 各自创建索引;
create index idx_name on tenant(tenant_name);
create index idx_account on `user`(account);
再次使用explain分析结果如下
可以看到第二行type变为ref,rows的数量优化比较明显。这是由左连接特性决定的,LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引 。
2.3 内连接关联的字段建立索引
我们知道,左连接和右连接查询的数据分别是完全包含左表数据,完全包含右表数据,而内连接(inner join 或join) 则是取交集(共有的部分),在这种情况下,驱动表的选择是由mysql优化器自动选择的;
在上面的基础上,首先移除两张表的索引
ALTER TABLE `user` DROP INDEX idx_account;
ALTER TABLE `tenant` DROP INDEX idx_name;使用explain语句进行分析
然后给user表的account字段添加索引,再次执行explain我们发现,user表竟然被当作是被驱动表了;
此时,如果我们给tenant表的tenant_name加索引,并移除user表的account索引,得出的结果竟然都没有走索引,再次说明,使用内连接的情况下,查询优化器将会根据自己的判断进行选择;
3、子查询优化
子查询在日常编写业务的SQL时也是使用非常频繁的做法,不是说子查询不能用,而是当数据量超出一定的范围之后,子查询的性能下降是很明显的,关于这一点,本人在日常工作中深有体会;
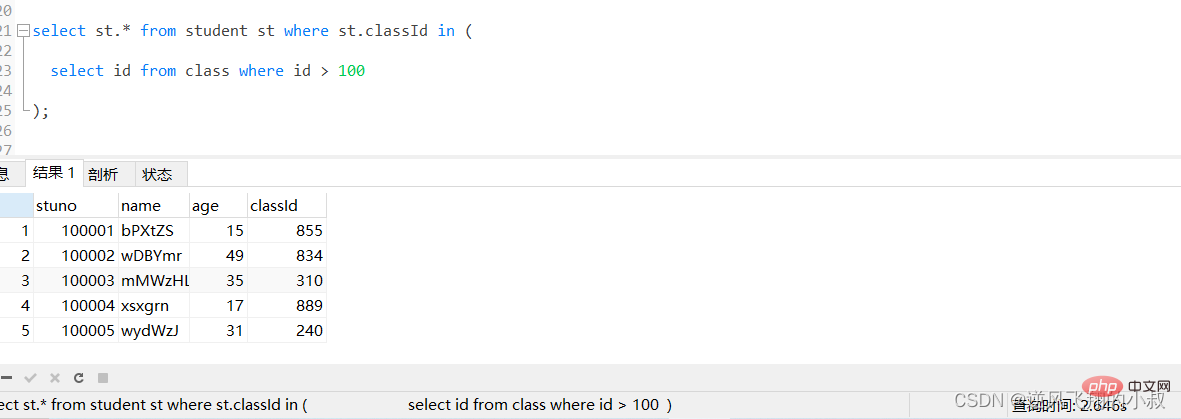
比如下面这条sql,由于student表数据量较大,执行起来耗时非常长,可以看到耗费了将近3秒;
1
2
3
4
5
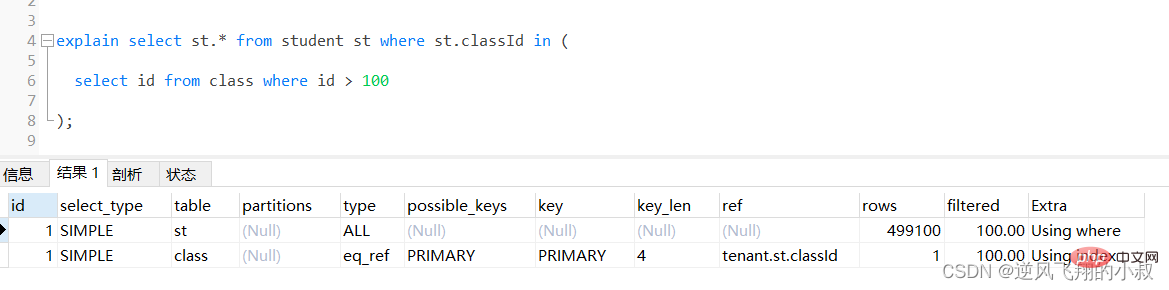
select st.* from student st where st.classId in (
select id fromclasswhere id > 100
);Copier après la connexion
通过执行explain进行分析得知,内层查询 id > 100的子查询尽管用上了主键索引,但是由于结果集太大,带入到外层查询,即作为in的条件时,查询优化器还是走了全表扫描;
针对上面的情况,可以考虑下面的优化方式
select st.id from student st join class cl on st.classId = cl.id where cl.id > 100;
子查询性能低效的原因
- 子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表 ,然后外层查询语句从临时表中查询记录,查询完毕后,再撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询;
- 子查询结果集存储的临时表,不论是内存临时表还是磁盘临时表都不能走索引 ,所以查询性能会受到一定的影响;
- 对于返回结果集比较大的子查询,其对查询性能的影响也就越大;
使用mysql查询时,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表 ,其速度比子查询要快 ,如果查询中使用索引的话,性能就会更好,尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代;
一个真实的案例
在下面的这段sql中,优化前使用的是子查询,在一次生产问题的性能分析中,发现某个tenant_id下的数据达到了35万多,这样直接导致某个列表页面的接口查询耗时达到了5秒左右;
找到了问题的根源后,尝试使用上面的优化思路进行解决即可,优化后的sql大概如下,
4、排序(order by)优化
在mysql,排序主要有两种方式
- Using filesort : 通过表索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort
buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序;- Using index : 通过有序的索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高;
对于以上两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index
4.1 使用age字段进行排序
由于age字段未加索引,查询结果按照age排序的时候发现使用了filesort,排序性能较低;
给age字段添加索引,再次使用order by时就走了索引;
4.2 使用多字段进行排序
通常在实际业务中,参与排序的字段往往不只一个,这时候,就可以对参与排序的多个字段创建联合索引;
如下根据stuno和age排序
给stuno和age添加联合索引
create index idx_stuno_age on `student`(stuno,age);
再次分析时结果如下,此时排序走了索引
关于多字段排序时的注意事项
1)排序时,需要满足最左前缀法则,否则也会出现 filesort;
L'ordre de l'index conjoint que nous avons créé ci-dessus est stuno et age, c'est-à-dire que stuno est au premier plan et age est à l'arrière. Que se passera-t-il si l'ordre de tri est inversé lors de la requête ? En analysant les résultats, il a été constaté que le tri des fichiers était utilisé
2) Lors du tri, le type de tri reste cohérent
En gardant l'ordre de tri des champs inchangé, par défaut, s'ils sont croissants ou décroissants. order, order By peut utiliser index. Que se passera-t-il si l'un est par ordre croissant et l'autre par ordre décroissant ? L'analyse a révélé que le tri par fichiers sera également utilisé dans ce cas ;
5. Optimisation du groupe par
La stratégie d'optimisation du groupe par est très similaire à la stratégie d'optimisation de l'ordre par.
group by peut utiliser l'index directement même s'il n'y a pas de condition de filtrage ;
- group by sorts d'abord, puis groups, en suivant la meilleure règle de préfixe gauche pour la construction de l'index
- Lorsque la colonne d'index ne peut pas être utilisée, augmentez max_length_for_sort_data et sort_buffer_size ; Paramètres des paramètres ;
- where est plus efficace que have. Si vous pouvez écrire les conditions définies dans Where, ne les écrivez pas dans have
- Réduisez l'utilisation de order by, ne triez pas si vous le pouvez, ou mettez le tri dedans ; le programme. Les instructions telles que order by, group by et distinct consomment plus de CPU, et les ressources CPU de la base de données sont extrêmement précieuses
- Si le SQL contient des instructions de requête telles que order by, group by et distinct, veuillez conserver l'ensemble de résultats ; filtré par la condition Where à 1000 Dans les lignes, sinon SQL sera très lent
- 5.1 Ajouter un index au groupe par champ
Si le champ n'est pas indexé, les résultats de l'analyse sont les suivants ; est évidemment très inefficace
Après avoir ajouté l'index à stuno
count() est une fonction d'agrégation pour l'ensemble de résultats renvoyé, elle est jugée ligne par ligne. . Si le paramètre de la fonction count n'est pas NULL, la valeur cumulée est ajoutée de 1, sinon elle n'est pas ajoutée, et finalement la valeur cumulée est renvoyée
Utilisation : count (*), count (clé primaire), count (champ), count (number)
Ce qui suit est une description détaillée de plusieurs façons d'écrire countUsagecount (clé primaire) count) ; (*)count (field) count (numéro)Résumé de la valeur de l'expérience
Explication InnoDB parcourra toute la table , supprimez la valeur de l'identifiant de clé primaire de chaque ligne et renvoyez-la à la couche de service une fois que la couche de service a obtenu la clé primaire, elle l'accumulera directement par ligne (la clé primaire ne peut pas être nulle InnoDB ne supprimera pas tous les champs, mais est spécifiquement optimisé pour ne pas prendre de valeurs. La couche service accumule directement les lignes n'a pas de contrainte non nulle : Le moteur InnoDB ; parcourra toute la table, supprimera les valeurs de champ de chaque ligne et les renverra à la couche de service. La couche de service déterminera si elle est nulle ou non, et le décompte sera accumulé s'il n'y a pas de contrainte nulle. : le moteur InnoDB parcourra toute la table. La valeur du champ de chaque ligne est extraite, renvoyée à la couche de service et accumulée directement par ligne Le moteur InnoDB parcourt toute la table ; mais ne prend pas la valeur. Pour chaque ligne renvoyée, la couche de service y met un chiffre "1" et l'accumule directement par ligne Par ordre d'efficacité, count(field) < ID de clé primaire) < count(1) ≈ count(*), alors essayez d'utiliser count(*)
Apprentissage recommandé :tutoriel vidéo MySQLCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié












 Après avoir ajouté l'index à stuno
Après avoir ajouté l'index à stuno  Ajouter un index conjoint à stuno et à l'âge
Ajouter un index conjoint à stuno et à l'âge  Si le préfixe gauche optimal n'est pas suivi, le groupe par performance sera relativement inefficace
Si le préfixe gauche optimal n'est pas suivi, le groupe par performance sera relativement inefficace  La situation pour suivre le préfixe gauche optimal est la suivante
La situation pour suivre le préfixe gauche optimal est la suivante  6. Optimisation du nombre
6. Optimisation du nombre







![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



