
 titres
Réponse à l'entretien : il est préférable que chaque table MySQL ne contienne pas plus de 20 millions de données, n'est-ce pas ?
titres
Réponse à l'entretien : il est préférable que chaque table MySQL ne contienne pas plus de 20 millions de données, n'est-ce pas ?
Réponse à l'entretien : il est préférable que chaque table MySQL ne contienne pas plus de 20 millions de données, n'est-ce pas ?

Combien de données chaque table de MySQL peut-elle stocker ? Dans les situations réelles, en raison des différents champs et de l'espace occupé par chaque table, la quantité de données qu'elles peuvent stocker avec des performances optimales est également différente, ce qui nécessite un calcul manuel.
Le truc est comme ça
Ce qui suit est le dossier d'entretien de mon ami :
Enquêteur : Parlez-moi de ce que vous avez fait pendant votre stage.
Ami : Au cours de mon stage, j'ai construit une fonction pour stocker les enregistrements des opérations des utilisateurs. Elle obtient principalement les informations sur les opérations des utilisateurs envoyées par le service en amont de MQ, puis stocke ces informations dans MySQL pour une utilisation par les collègues de l'entrepôt de données.
Ami : Étant donné que la quantité de données est relativement importante, il y a environ 40 à 50 millions d'éléments chaque jour, j'ai donc également effectué des opérations de sous-tables pour celles-ci. Trois tables sont générées régulièrement chaque jour, puis les données sont modélisées et stockées respectivement dans ces trois tables pour éviter qu'un excès de données dans les tables ne ralentisse la vitesse des requêtes.
Il semble qu'il n'y ait rien de mal avec cette expression, n'est-ce pas ? Ne vous inquiétez pas, lisons la suite :
Intervieweur : Alors pourquoi la divisez-vous en trois tables, deux tables ne peuvent-elles pas fonctionner ? Quatre tables ne fonctionneraient-elles pas ?
Amis : Parce que chaque table MySQL ne doit pas dépasser 20 millions de données, sinon la vitesse des requêtes sera réduite et les performances seront affectées. Nos données quotidiennes représentent environ 50 millions de données, il est donc plus sûr de les diviser en trois tableaux.
Intervieweur : Encore plus ?
Ami : Pas plus...Qu'est-ce que tu fais ? Oups
Intervieweur : Alors retourne en arrière et attends la notification.
Maintenant que j'ai fini de parler, voyez-vous quelque chose ? Pensez-vous qu'il y a des questions auxquelles mon ami a répondu ?
Avant-propos
Beaucoup de gens disent qu'il est préférable de ne pas dépasser 20 millions de données dans chaque table MySQL, sinon cela entraînerait une dégradation des performances. Le manuel de développement Java d'Alibaba indique également qu'il n'est recommandé d'implémenter des sous-bases de données et des tables que lorsque le nombre de lignes dans une seule table dépasse 5 millions ou que la capacité d'une seule table dépasse 2 Go.
Mais en fait, ces 20 millions ou 5 millions ne sont qu'un nombre approximatif et ne s'applique pas à tous les scénarios. Si vous pensez aveuglément qu'il n'y aura pas de problème tant que les données du tableau ne dépassent pas 20 millions, c'est le cas. susceptible de provoquer une panne du système. Les performances chutent considérablement.
Dans des situations réelles, chaque table a des champs différents et l'espace occupé par les champs, etc., donc la quantité de données qu'elles peuvent stocker avec des performances optimales est également différente.
Alors, comment calculer la quantité appropriée de données pour chaque table ? Ne vous inquiétez pas, baissez lentement les yeux.
Cet article convient aux lecteurs Pour lire cet article, vous devez avoir une certaine base MySQL. Il est préférable d'avoir une certaine compréhension des arbres InnoDB et B+. Vous devrez peut-être en avoir plusieurs. année d'expérience d'apprentissage MySQL (environ un an ?), connaître les connaissances théoriques "Il est généralement préférable de maintenir la hauteur de l'arborescence B+ dans InnoDB à moins de trois niveaux".
Cet article explique principalement le sujet "Combien de données peuvent être stockées dans un arbre B+ d'une hauteur de 3 dans InnoDB ?" De plus, le calcul des données dans cet article est relativement strict (au moins plus strict que 95 % des articles de blog associés sur Internet). Si vous vous souciez de ces détails et n'êtes pas clair pour le moment, veuillez continuer à lire.
Cela vous prendra environ 10 à 20 minutes pour lire cet article. Si vous vérifiez les données pendant la lecture, cela peut prendre environ 30 minutes.
Carte mentale de cet article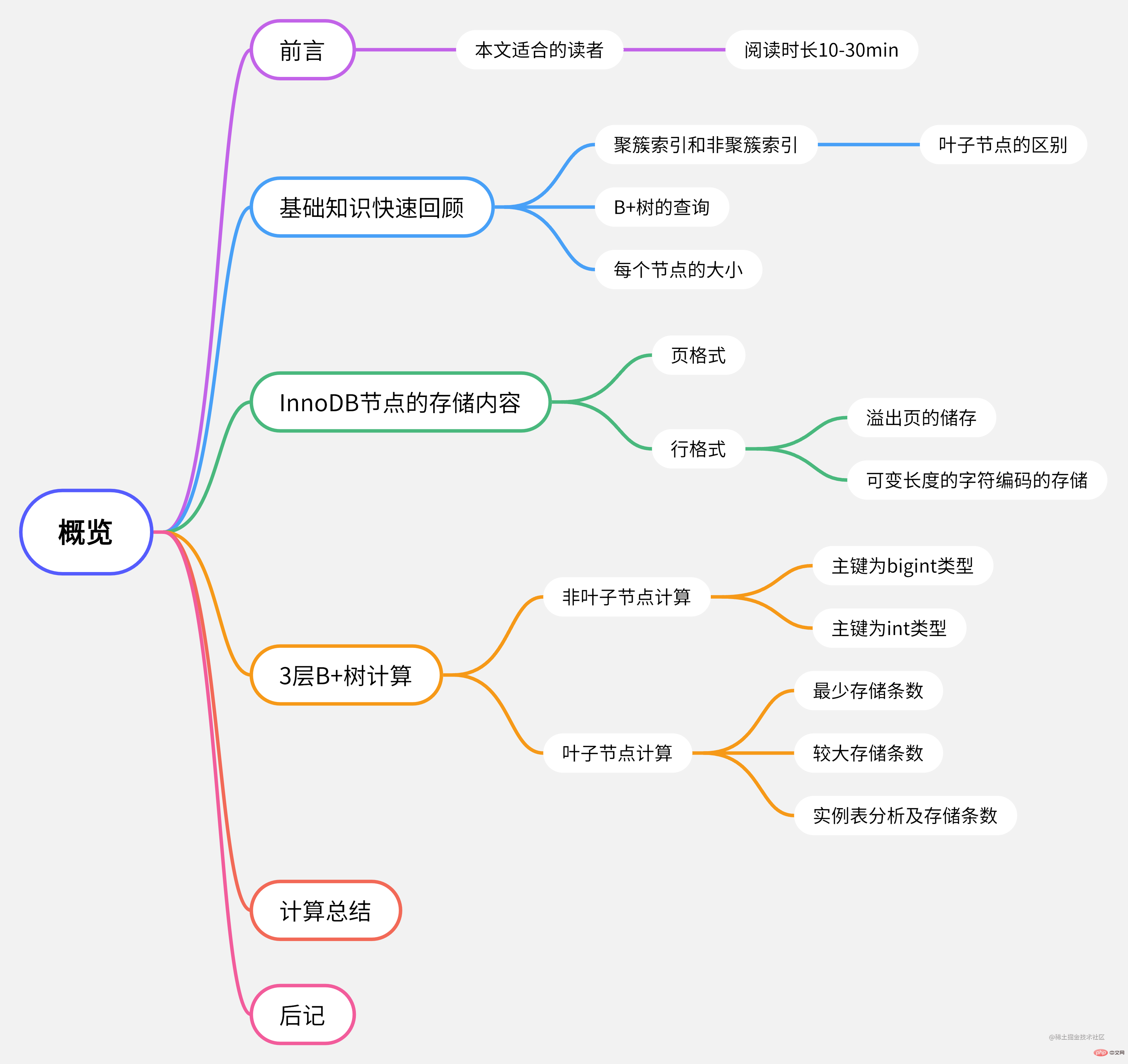
Comme nous le savons tous, la structure de stockage d'InnoDB dans MySQL est un arbre B+ Tout le monde connaît l'arbre B+. , droite? Les fonctionnalités sont à peu près les suivantes, passons-les rapidement en revue ensemble !
. ??
- Une table de données correspond généralement au stockage d'un ou plusieurs arbres. Le nombre d'arbres est lié au nombre d'index. Chaque index aura un arbre distinct.
- Index clusterisé et index non clusterisé :
-
L'index de clé primaire est également un index clusterisé, et l'index de clé non primaire est un index non clusterisé.
À l'exception des informations de format, les nœuds non-feuilles des deux index stockent uniquement les données d'indexPar exemple, si l'index est id, alors le nœud non-feuille stocke les données d'identification. Les différences entre les nœuds feuilles sont les suivantes :
- Les nœuds feuilles de l'index clusterisé stockent généralement toutes les informations de champ de ces données. Ainsi, lorsque nous
select * from table where id = 1, nous allons toujours aux nœuds feuilles pour obtenir les données. - Les nœuds feuilles de l'index non clusterisé stockent les informations de clé primaire et colonne d'index correspondant à cette donnée. Par exemple, si cet index non clusterisé est le nom d'utilisateur et que la clé primaire de la table est l'identifiant, alors les nœuds feuilles de l'index non clusterisé stockent le nom d'utilisateur et l'identifiant, mais pas les autres champs. Cela équivaut à trouver d'abord la valeur de la clé primaire à partir de l'index non clusterisé, puis à vérifier le contenu des données en fonction de l'index de clé primaire. Généralement, cela doit être vérifié deux fois (à moins que l'index ne soit couvert). également appelé retour de table, ce qui est un peu similaire au stockage d'un pointeur, pointant vers l'adresse réelle où les données sont stockées.
- Les nœuds feuilles de l'index clusterisé stockent généralement toutes les informations de champ de ces données. Ainsi, lorsque nous
-
Les requêtes de l'arbre B+ sont interrogées couche par couche de haut en bas. De manière générale, nous pensons qu'il est préférable de garder la hauteur de l'arbre B+ dans 3 couches, c'est-à-dire que les deux couches supérieures sont des index et la. dernière couche Stocker les données, de sorte que lors de la recherche de la table, seules trois E/S disque soient nécessaires (en fait une fois de moins, car le nœud racine résidera dans la mémoire), et la quantité de données pouvant être stockée est également considérable.
Si la quantité de données est trop importante, ce qui fait que le nombre B+ devient 4 niveaux, chaque requête nécessitera 4 E/S disque, réduisant ainsi les performances. C'est pourquoi nous calculons le nombre maximum de données que l'arborescence B+ à 3 couches d'InnoDB peut stocker.
-
La taille par défaut de chaque nœud MySQL est de 16 Ko, ce qui signifie que chaque nœud peut stocker jusqu'à 16 Ko de données. Il peut être modifié, avec un maximum de 64 Ko et un minimum de 4 Ko.
Extension : que se passe-t-il si les données d'une certaine ligne sont particulièrement volumineuses et dépassent la taille du nœud ?
La documentation MySQL5.7 explique :
Pour les paramètres 4 Ko, 8 Ko, 16 Ko et 32 Ko, la longueur maximale des lignes est légèrement inférieure à la moitié de la page de la base de données. Par exemple : pour la taille de page par défaut de 16 Ko, la longueur maximale de ligne est légèrement inférieure à 8 Ko, et pour la taille de page par défaut de 32 Ko, la longueur maximale de ligne est légèrement inférieure à 16 Ko.
Et pour une page de 64 Ko, la longueur maximale des lignes est légèrement inférieure à 16 Ko.
Si une ligne dépasse la longueur maximale de ligne, la colonne de longueur variable est stockée dans des pages externes jusqu'à ce que la ligne atteigne la limite de longueur maximale de ligne. C'est-à-dire que le varchar et le texte de longueur variable sont stockés dans des pages externes pour réduire la longueur des données de cette ligne.

Adresse du document : MySQL :: MySQL 5.7 Reference Manual :: 14.12.2 Gestion de l'espace fichier
-
La vitesse des requêtes MySQL dépend principalement de la vitesse de lecture et d'écriture du disque, car lorsque Requêtes MySQL Un seul nœud est lu dans la mémoire à la fois, l'emplacement du prochain nœud à lire est trouvé grâce aux données de ce nœud et les données du nœud suivant sont lues à nouveau jusqu'à ce que les données requises soient interrogées ou que les données n’existent pas.
Quelqu'un doit se demander : n'avons-nous pas besoin d'interroger les données de chaque nœud ? Pourquoi le temps pris n'est-il pas calculé ici ?
En effet, après avoir lu l'intégralité des données du nœud, elles seront stockées dans la mémoire. L'interrogation des données du nœud dans la mémoire prend en fait un temps très court. Couplée à la méthode de requête MySQL, la complexité temporelle est presque . , par rapport aux E/S du disque en général parlant, il peut être ignoré.
Contenu de stockage du nœud MySQL InnoDB
Dans l'arborescence B+ d'Innodb, le nœud que nous appelons souvent s'appelle page (page), chaque page stocke les données utilisateur et toutes les pages sont combinées Ensemble, elles forment un arbre B+ ( bien sûr, ce sera beaucoup plus compliqué en réalité, mais il suffit de calculer combien de données peuvent être stockées, pour pouvoir le comprendre de cette façon ?).
Page est la plus petite unité de disque utilisée par le moteur de stockage InnoDB pour gérer la base de données. On dit souvent que chaque nœud fait 16 Ko, ce qui signifie en fait que la taille de chaque page est de 16 Ko.
Cet espace de 16 Ko doit stocker les informations de format de page et les informations de format de ligne Les informations de format de ligne contiennent également des métadonnées et des données utilisateur. Par conséquent, lorsque nous calculons, nous devons inclure toutes ces données.
Format de la page
Le format de base de chaque page, c'est-à-dire certaines informations que chaque page contiendra. Le tableau récapitulatif est le suivant :
| Nom | Espace | Signification et fonction, etc. |
|---|---|---|
En-tête de fichierFile Header
|
38字节 | 文件头,用来记录页的一些头信息。 包括校验和、页号、前后节点的两个指针、 页的类型、表空间等。 |
Page Header |
56字节 | 页头,用来记录页的状态信息。 包括页目录的槽数、空闲空间的地址、本页的记录数、 已删除的记录所占用的字节数等。 |
Infimum & supremum |
26字节 | 用来限定当前页记录的边界值,包含一个最小值和一个最大值。 |
User Records |
不固定 | 用户记录,我们插入的数据就存储在这里。 |
Free Space |
不固定 | 空闲空间,用户记录增加的时候从这里取空间。 |
Page Directort |
不固定 | 页目录,用来存储页当中用户数据的位置信息。 每个槽会放4-8条用户数据的位置,一个槽占用1-2个字节, 当一个槽位超过8条数据的时候会自动分成两个槽。 |
File Trailer | 38 octetsEn-tête de fichier, utilisé pour enregistrer certaines informations d'en-tête de la page. | Y compris la somme de contrôle, le numéro de page, deux pointeurs vers les nœuds précédent et suivant, | le type de page, l'espace table, etc.
En-tête de page🎜🎜56 octets🎜🎜En-tête de page, utilisé pour enregistrer les informations sur l'état de la page. 🎜Y compris le nombre d'emplacements dans le répertoire de la page, l'adresse de l'espace libre, le nombre d'enregistrements sur cette page, 🎜le nombre d'octets occupés par les enregistrements supprimés, etc. 🎜🎜🎜🎜Infimum & supremum🎜🎜26 octets🎜🎜 est utilisé pour limiter la valeur limite de l'enregistrement de la page actuelle, y compris une valeur minimale et une valeur maximale. 🎜🎜🎜🎜Enregistrements utilisateur🎜🎜Non corrigé🎜🎜Enregistrements utilisateur, les données que nous insérons sont stockées ici. 🎜🎜🎜🎜Espace libre🎜🎜Non fixe🎜🎜espace libre, lorsque des enregistrements utilisateur sont ajoutés, de l'espace est pris à partir d'ici. 🎜🎜🎜🎜Directeur de page🎜🎜Non fixé🎜🎜Le répertoire de page est utilisé pour stocker les informations d'emplacement des données utilisateur dans la page. 🎜Chaque emplacement contiendra 4 à 8 éléments de données utilisateur et un emplacement occupe 1 à 2 octets. 🎜Lorsqu'un emplacement dépasse 8 éléments de données, il sera automatiquement divisé en deux emplacements. 🎜🎜🎜🎜File Trailer🎜🎜8 octets🎜🎜Informations de fin de fichier, principalement utilisées pour vérifier l'intégrité de la page. 🎜🎜🎜🎜Schéma schématique :
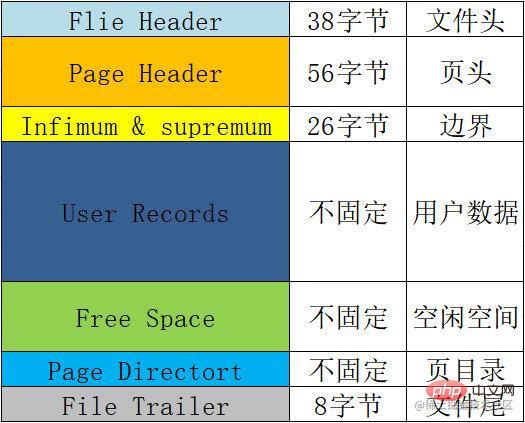
Le contenu du format de page, j'ai longuement parcouru le site officiel, mais je ne l'ai tout simplement pas trouvé ?. . . . Je ne sais pas si c’est parce que je ne l’ai pas écrit ou parce que je suis aveugle. Si quelqu’un l’a trouvé, j’espère qu’il pourra m’aider à le publier dans la zone de commentaires ?
Le contenu du tableau au format de la page ci-dessus est donc principalement basé sur l'apprentissage et la synthèse de certains blogs.
De plus, lorsqu'un nouvel enregistrement est inséré dans un index clusterisé InnoDB, InnoDB essaiera de laisser 1/16 de la page libre pour les futures insertions et mises à jour des enregistrements d'index. Si les enregistrements d'index sont insérés dans l'ordre (ordre croissant ou décroissant), la page résultante dispose d'environ 15/16 de l'espace disponible. Si les enregistrements sont insérés dans un ordre aléatoire, environ 1/2 à 15/16 de l'espace de page est disponible. Documentation de référence : MySQL :: MySQL 5.7 Reference Manual :: 14.6.2.2 La structure physique d'un index InnoDB
La mémoire occupée sauf User Records和Free Space est = 1523216 fois frac{15} {16}fois 1024 - 128 = 15232Tout d'abord, je pense qu'il est nécessaire de mentionner que le format de ligne par défaut de MySQL5.6 est COMPACT (compact), et le format de ligne par défaut de 5.7 et versions ultérieures est DYNAMIC (dynamique) . Différents formats de lignes Les méthodes de stockage sont également différentes et il existe deux autres formats de lignes. Le contenu ultérieur de cet article est principalement expliqué sur la base de DYNAMIC.
MySQL :: Manuel de référence MySQL 5.7 : 14.11 Format de ligne InnoDB (la plupart du contenu du format de ligne suivant peut être trouvé à l'intérieur)
Chaque enregistrement de ligne contient les informations suivantes, dont la plupart se trouvent dans des documents officiels. Ce que j'ai écrit ici n'est pas très détaillé. J'ai seulement écrit quelques connaissances qui peuvent nous aider à calculer l'espace. Pour des informations plus détaillées, vous pouvez rechercher « Format de ligne MySQL » en ligne.
Nom Espace Signification et fonction, etc. Informations d'en-tête d'enregistrement de ligne 5 octets Informations d'en-tête de l'enregistrement de ligne
contient des bits d'indicateur, un type de données et d'autres informations
Tel comme : indicateur de suppression, indicateur d'enregistrement minimum, enregistrements triés, type de données,
La position du prochain enregistrement dans la page, etc.Liste de champs de longueur variable non fixe pour enregistrer les octets occupés par ces variables champs de longueur Nombres, tels que varchar, texte, blob, etc.
Si la longueur du champ de longueur variable est inférieure à 255 octets, elle est représentée par1 octet1字节表示;
若大于 255字节,用2字节Si elle est supérieure à 255 octets, elle est représentée par2 octets; code>. <br>Il y a plusieurs champs de longueur variable dans le champ du tableau. Il y aura plusieurs valeurs dans la liste. S'il n'y en a pas, elles ne seront pas enregistrées.liste de valeurs nulles non fixe est utilisée pour stocker si un champ qui peut être nul est nul.
Chaque champ nullable occupe ici un bit, ce qui est l'idée du bitmap.
L'espace occupé par cette liste augmente en octets. Par exemple, s'il y a 9 à 16
colonnes pouvant être nulles, deux octets sont utilisés au lieu de 1,5 octets.ID de transaction et champ de pointeur 6+7 octets Les amis qui connaissent MVCC devraient savoir que la ligne de données contient un identifiant de transaction de 6 octets et
un champ de pointeur de 7 octets.
Si la clé primaire n'est pas définie, il y aura un champ d'ID de ligne supplémentaire de 6 octets
Bien sûr, nous avons tous une clé primaire, nous ne calculons donc pas cet ID de ligne.Les données réelles ne sont pas fixes Cette partie est nos données réelles. Diagramme schématique :
Il y a quelques points supplémentaires à noter :
Stockage des pages de débordement (pages externes)
Remarque : Il s'agit d'une fonctionnalité de DYNAMIC.
Lorsque vous utilisez DYNAMIC pour créer une table, InnoDB supprimera les valeurs des colonnes de longueur variable plus longues (telles que les types VARCHAR, VARBINARY, BLOB et TEXT) et les stockera sur une page de débordement, uniquement sur celle-ci. colonne Réservez un pointeur de 20 octets vers la page de débordement.
Le format de ligne COMPACT (format par défaut MySQL5.6) stocke les 768 premiers octets et le pointeur de 20 octets dans l'enregistrement du nœud de l'arborescence B+, et le reste est stocké sur la page de débordement.
Le fait qu'une colonne soit stockée hors page dépend de la taille de la page et de la taille totale des lignes. Lorsqu'une ligne est trop longue, la colonne la plus longue est sélectionnée pour le stockage hors page jusqu'à ce que l'enregistrement d'index clusterisé tienne sur la page de l'arborescence B+ (le document ne dit pas combien ?). Le TEXTE et les BLOB inférieurs ou égaux à 40 octets sont stockés directement dans la ligne et ne sont pas paginés.
Avantages
Le format de ligne DYNAMIQUE évite le problème du remplissage des nœuds d'arbre B+ avec de grandes quantités de données, ce qui entraîne de longues colonnes.
L'idée du format de ligne DYNAMIQUE est que si une partie d'une valeur de données longue est stockée hors page, il est généralement plus efficace de stocker la valeur entière hors page.
En utilisant le format DYNAMIC, les colonnes plus courtes sont conservées dans les nœuds d'arborescence B+ autant que possible, minimisant ainsi le nombre de pages de débordement requises pour une ligne donnée.
Stockage sous différents encodages de caractères
Les caractères, varchar, texte, etc. doivent définir le type d'encodage de caractères lors du calcul de l'espace occupé, l'espace occupé par les différents encodages doit être pris en compte.
Varchar, text et autres types auront une liste de champs de longueur pour enregistrer la longueur qu'ils occupent, mais char est un type de longueur fixe, donc la situation est particulière. Supposons que le type de nom de champ soit char(10), alors. la situation suivante se produira :
Pour le codage de caractères de longueur fixe (comme le code ASCII), le nom du champ sera stocké dans un format de longueur fixe. Chaque caractère du code ASCII occupe un octet, donc le nom occupe. 10 octets.
Pour les encodages de caractères de longueur variable (tels que utf8mb4), au moins 10 octets seront réservés pour le nom. Si possible, InnoDB le stockera sur 10 octets en supprimant les espaces de fin.
Si l'espace ne peut pas être enregistré après le découpage, coupez les espaces de fin à la longueur minimale en octets de la valeur de la colonne (généralement 1 octet). La longueur maximale d'une colonne est de :
motLe du degré ×
Pour être honnête, je ne comprends pas très bien le design de char. Bien que je le lise depuis longtemps, y compris des documents officiels et certains blogs, j'espère que les étudiants qui comprennent pourront clarifier leurs doutes dans la zone de commentaires :
Pour les caractères à longueur variable En termes d'encodage, char n'est-il pas un peu comme un type à longueur variable ? L'utf8mb4 couramment utilisé occupe 1 à 4 octets, donc l'espace occupé par char(10) est de 10 à 40 octets. Ce changement est assez important, mais il ne lui laisse pas assez d'espace, ni n'est-il spécial d'utiliser un. liste de champs de longueur variable pour enregistrer l'utilisation de l'espace des champs de caractères ?
Démarrer le calcul
D'accord, nous connaissons déjà les éléments spécifiques stockés dans chaque page, et maintenant nous avons la puissance de calcul.
Puisque j'ai déjà calculé l'espace restant de la page dans le format de page ci-dessus, il y aura 15232 octets disponibles pour chaque page. Calculons les lignes directement en dessous.
Calcul de nœud non-feuille
Calcul d'un nœud unique
La page d'index est le nœud où l'index est stocké, c'est-à-dire le nœud non-feuille.
Chaque enregistrement d'index contient la valeur de l'index actuel, des informations de pointeur de 6 octets, un en-tête de ligne de 5 octets, qui est utilisé pour pointer vers le pointeur vers la couche suivante de la page de données.
Je n'ai pas trouvé l'espace occupé par le pointeur dans l'enregistrement d'index dans le document officiel ? Je me réfère à d'autres articles de blog pour ces 6 octets. Ils ont dit que c'était 6 octets dans le code source, mais je ne le fais pas. Je ne sais pas de quelle section du code source il s'agit.
J'espère que les étudiants qui en savent plus pourront clarifier leurs doutes dans la zone de commentaires.
En supposant que notre identifiant de clé primaire est de type bigint, soit 8 octets, alors l'espace occupé par chaque ligne de données dans la page d'index est égal à octets. Chaque page peut enregistrer


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés