

Comment dédoublonner des données dans Oracle

Méthode de suppression : 1. Utilisez le mot-clé distinct pour supprimer les doublons, syntaxe "SELECT DISTINCT field name FROM table name;"; 2. Utilisez la fonction de fenêtre row_number () over() pour supprimer les doublons ; dédupliquer, la syntaxe est "sélectionner le nom du champ dans le groupe de noms de table par nom de champ ;" 4. Utilisez rowid pour déduplicater les pseudo-colonnes.

L'environnement d'exploitation de ce tutoriel : système Windows 7, version Oracle 11g, ordinateur Dell G3.
Scénario commercial
Besoin d'interroger certaines données. Étant donné que trois tables sont requises pour les requêtes associées, les résultats de la requête sont les suivants :

Instruction SQL originale
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
Méthode 1 : déduplication distincte.
SELECT DISTINCT peut être utilisé pour filtrer les lignes en double dans l'ensemble de résultats afin de garantir que les valeurs de la ou des colonnes spécifiées renvoyées dans la clause SELECT sont uniques. La syntaxe de l'instruction
DISTINCT est la suivante :
SELECT DISTINCT column_1,
column_2,
...
FROM
table_name;Exemple :
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
Remarque : DISTINCT doit être suivi d'un champ ORDER BY. Oracle exécute d'abord DISTINCT pour supprimer les doublons, puis utilise ORDER BY pour le tri. Par conséquent, si le champ qui doit être trié dans ORDER BY n'est pas dans le champ après distinct, une erreur sera naturellement générée.
Le message d'erreur est le suivant :
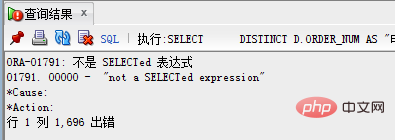
Méthode 2 : row_number() over()
Format de syntaxe
select * from (select A.*, row_number() over(partition by A.name1 order by A.name12 desc) rn from A) where rn = 1
Exemple
select * from ( select d.order_num as "申请单号" , d.create_time , d.emp_name as "申请人", (select extractvalue(t1.row_data,'/root/row/FI13_wasteName') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "废料名称", (select extractvalue(t1.row_data,'/root/row/FI13_units') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "单位", (select extractvalue(t1.row_data,'/root/row/FI13_estimate') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "预估数量", (select extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "累计出库数量", (select extractvalue(t1.row_data,'/root/row/FI13_receivingTime') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdCGYTX' ) as "收购方收货时间", (select extractvalue(t2.row_data,'/root/row/FI13_collectionTime') from dat_table_row t2 where d.document_id = t2.document_id and t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) as "实际收款时间", row_number() over(partition by d.order_num order by d.create_time desc) rn from dat_document d, dat_table_row dtr where d.form_name ='FI14' and d.document_id =dtr.document_id and (d.document_status != 'deleted' or d.document_status is null ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' and d.order_num = 'FI1420210708002' --FI1420210708002 ) where rn = 1;
Résultats de la requête
Méthode 3 : regrouper par
select 字段名 from 表名 group by 字段名;
Méthode 4 : Utiliser rowid (déduplication de pseudo-colonnes)
select id,name,age from test t1 where t1.rowid in (select min(rowid) from test t2 where t1.name=t2.name and t1.age=t2.age);
Tutoriel recommandé : "Tutoriel Oracle"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'ordre des étapes de démarrage de la base de données Oracle est
May 10, 2024 am 01:48 AM
L'ordre des étapes de démarrage de la base de données Oracle est
May 10, 2024 am 01:48 AM
La séquence de démarrage de la base de données Oracle est la suivante : 1. Vérifiez les conditions préalables ; 2. Démarrez l'écouteur ; 3. Démarrez l'instance de base de données ; 4. Attendez que la base de données s'ouvre ; 6. Vérifiez l'état de la base de données ; . Activez le service (si nécessaire) ; 8. Testez la connexion.
 Combien de temps les journaux de la base de données Oracle seront-ils conservés ?
May 10, 2024 am 03:27 AM
Combien de temps les journaux de la base de données Oracle seront-ils conservés ?
May 10, 2024 am 03:27 AM
La durée de conservation des journaux de la base de données Oracle dépend du type de journal et de la configuration, notamment : Redo logs : déterminé par la taille maximale configurée avec le paramètre "LOG_ARCHIVE_DEST". Redo logs archivés : Déterminé par la taille maximale configurée par le paramètre "DB_RECOVERY_FILE_DEST_SIZE". Redo logs en ligne : non archivés, perdus au redémarrage de la base de données et la durée de conservation est cohérente avec la durée d'exécution de l'instance. Journal d'audit : Configuré par le paramètre "AUDIT_TRAIL", conservé 30 jours par défaut.
 De quelle quantité de mémoire Oracle a-t-il besoin ?
May 10, 2024 am 04:12 AM
De quelle quantité de mémoire Oracle a-t-il besoin ?
May 10, 2024 am 04:12 AM
La quantité de mémoire requise par Oracle dépend de la taille de la base de données, du niveau d'activité et du niveau de performances requis : pour le stockage des tampons de données, des tampons d'index, l'exécution d'instructions SQL et la gestion du cache du dictionnaire de données. Le montant exact dépend de la taille de la base de données, du niveau d'activité et du niveau de performances requis. Les meilleures pratiques incluent la définition de la taille SGA appropriée, le dimensionnement des composants SGA, l'utilisation d'AMM et la surveillance de l'utilisation de la mémoire.
 Comment lire le fichier dbf dans Oracle
May 10, 2024 am 01:27 AM
Comment lire le fichier dbf dans Oracle
May 10, 2024 am 01:27 AM
Oracle peut lire les fichiers dbf en suivant les étapes suivantes : créer une table externe et référencer le fichier dbf ; interroger la table externe pour récupérer les données dans la table Oracle ;
 Exigences de configuration matérielle du serveur de base de données Oracle
May 10, 2024 am 04:00 AM
Exigences de configuration matérielle du serveur de base de données Oracle
May 10, 2024 am 04:00 AM
Exigences de configuration matérielle du serveur de base de données Oracle : Processeur : multicœur, avec une fréquence principale d'au moins 2,5 GHz Pour les grandes bases de données, 32 cœurs ou plus sont recommandés. Mémoire : au moins 8 Go pour les petites bases de données, 16 à 64 Go pour les tailles moyennes, jusqu'à 512 Go ou plus pour les grandes bases de données ou les charges de travail lourdes. Stockage : disques SSD ou NVMe, matrices RAID pour la redondance et les performances. Réseau : réseau haut débit (10GbE ou supérieur), carte réseau dédiée, réseau à faible latence. Autres : alimentation stable, composants redondants, système d'exploitation et logiciels compatibles, dissipation thermique et système de refroidissement.
 Quelle quantité de mémoire est nécessaire pour utiliser la base de données Oracle
May 10, 2024 am 03:42 AM
Quelle quantité de mémoire est nécessaire pour utiliser la base de données Oracle
May 10, 2024 am 03:42 AM
La quantité de mémoire requise pour une base de données Oracle dépend de la taille de la base de données, du type de charge de travail et du nombre d'utilisateurs simultanés. Recommandations générales : petites bases de données : 16 à 32 Go, bases de données moyennes : 32 à 64 Go, grandes bases de données : 64 Go ou plus. D'autres facteurs à prendre en compte incluent la version de la base de données, les options d'optimisation de la mémoire, la virtualisation et les meilleures pratiques (surveiller l'utilisation de la mémoire, ajuster les allocations).
 Les tâches planifiées Oracle exécutent l'étape de création une fois par jour
May 10, 2024 am 03:03 AM
Les tâches planifiées Oracle exécutent l'étape de création une fois par jour
May 10, 2024 am 03:03 AM
Pour créer une tâche planifiée dans Oracle qui s'exécute une fois par jour, vous devez effectuer les trois étapes suivantes : Créer une tâche. Ajoutez un sous-travail au travail et définissez son expression de planification sur "INTERVAL 1 DAY". Activez le travail.
 De quelle quantité de mémoire une base de données Oracle a-t-elle besoin ?
May 10, 2024 am 02:09 AM
De quelle quantité de mémoire une base de données Oracle a-t-elle besoin ?
May 10, 2024 am 02:09 AM
Les besoins en mémoire d'Oracle Database dépendent des facteurs suivants : taille de la base de données, nombre d'utilisateurs actifs, requêtes simultanées, fonctionnalités activées et configuration matérielle du système. Les étapes permettant de déterminer les besoins en mémoire incluent la détermination de la taille de la base de données, l'estimation du nombre d'utilisateurs actifs, la compréhension des requêtes simultanées, la prise en compte des fonctionnalités activées et l'examen de la configuration matérielle du système.
