

Si vous souhaitez apprendre MySQL en profondeur, vous devez commencer par l'architecture des macros. Dans cet article, nous apprendrons le processus d'exécution des instructions de requête MySQL. J'espère que cela sera utile à tout le monde !

La version MySQL de cet article est 8.0.18
Le rôle de l'analyseur est d'effectuer les tâches suivantes sur les instructions SQL envoyées depuis le client :
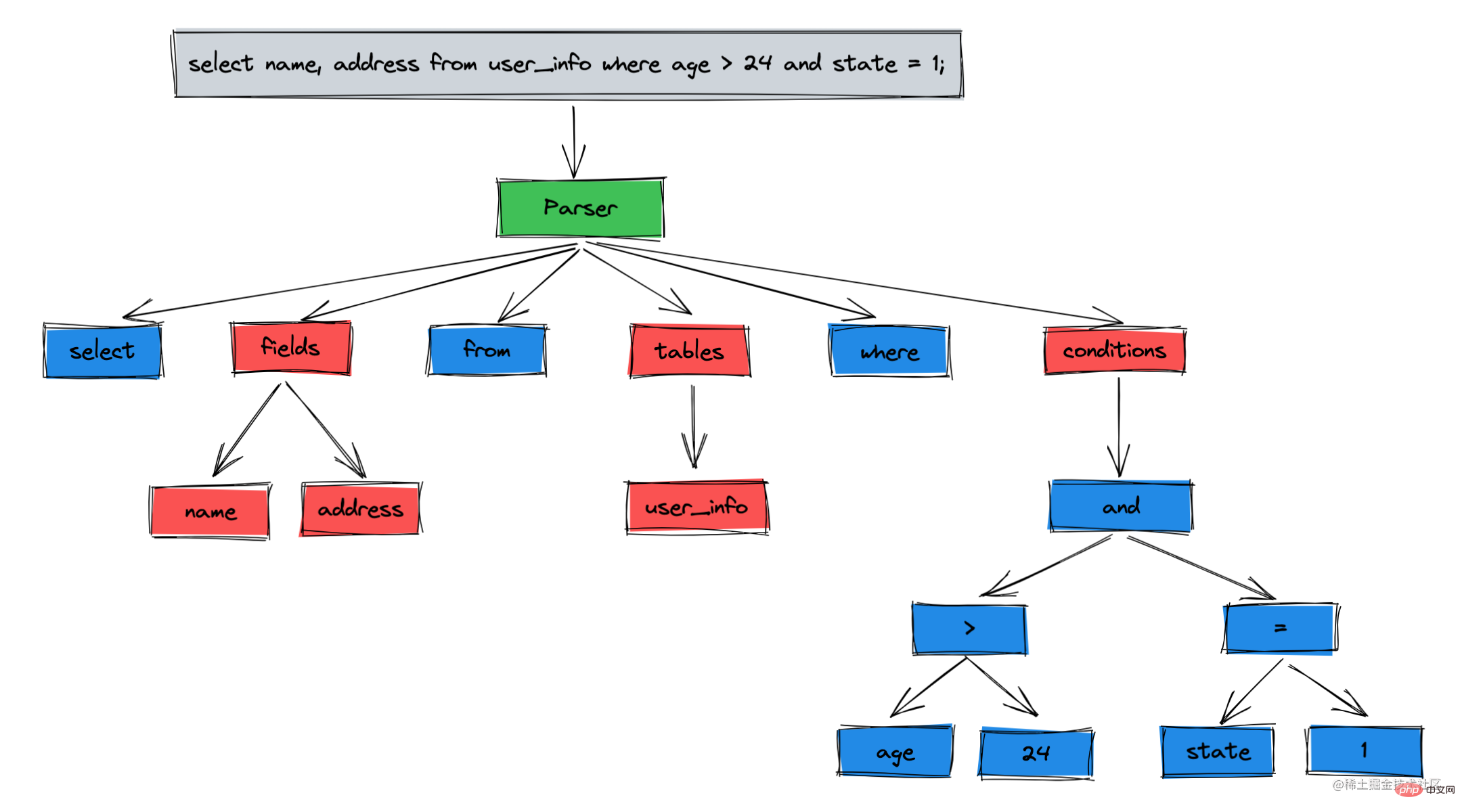
L'analyseur vérifie principalement la grammaire et le lexique. Cependant, si la grammaire et le lexique sont corrects, mais que la table et les champs n'existent pas, alors cette instruction SQL ne peut pas. être exécuté correctement.
Le rôle du préprocesseur est donc : Analyse sémantique, pour déterminer si la sémantique de l'arbre d'analyse est correcte et si des tables et des champs existent. Après le prétraitement, un nouvel arbre d'analyse sera obtenu.
Structure de l'optimiseur de requête
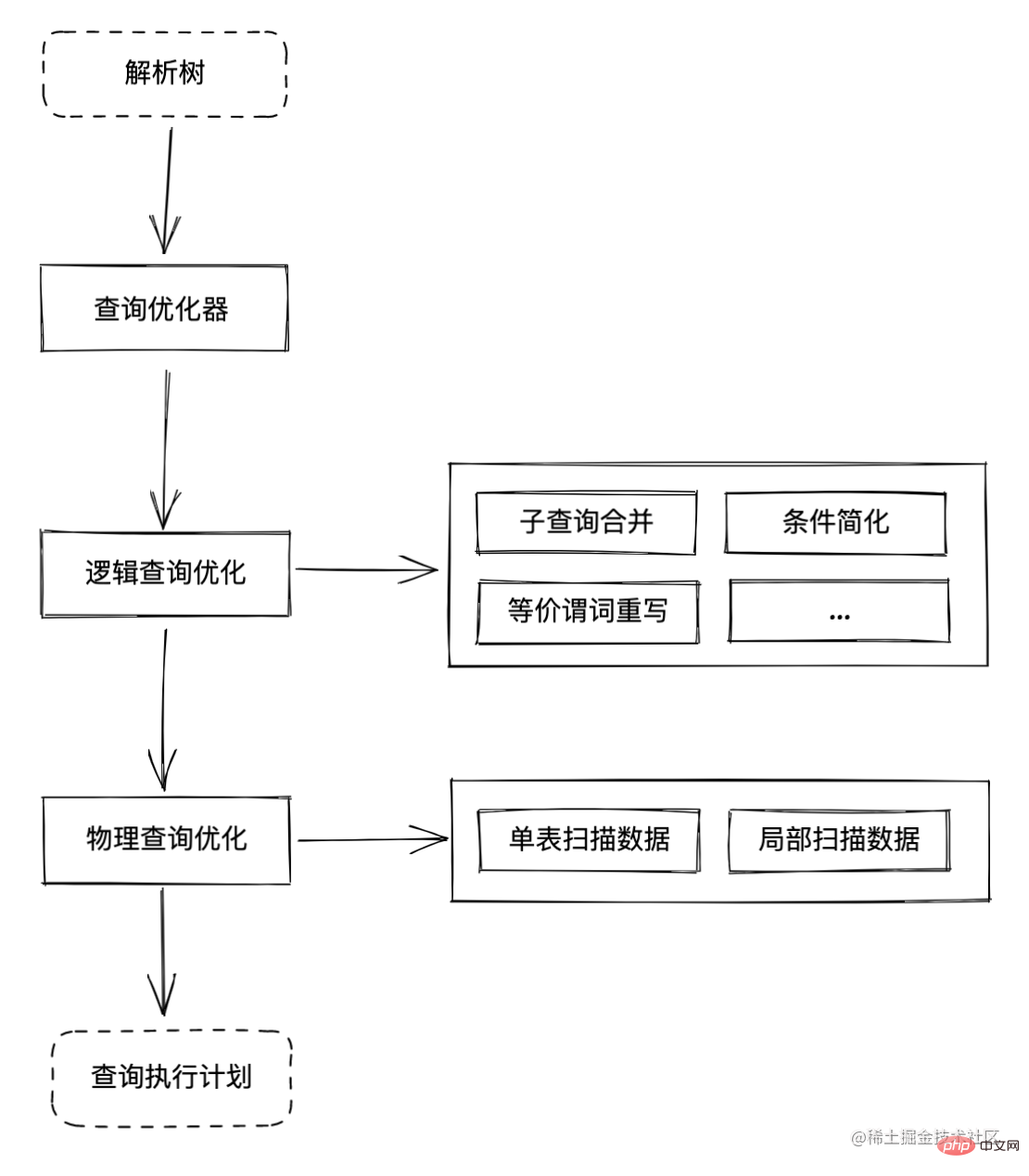
Il existe de nombreuses façons d'exécuter une instruction SQL dans MySQL Bien que le même résultat soit obtenu à la fin, il existe des différences de surcharge, des choix spécifiques. La méthode d'exécution est déterminée par l'optimiseur de requêtes. Par exemple :
Query Optimizer Il s'agit de un optimiseur basé sur les coûts . Son principe de fonctionnement est de générer plusieurs plans d'exécution basés sur l'arbre d'analyse. Il évaluera le coût (coût) requis pour diverses méthodes d'exécution et obtiendra finalement un plan d'exécution avec le coût minimum. solution finale .
Mais cette méthode d'exécution avec la plus petite surcharge n'est pas nécessairement la méthode d'exécution optimale. Par exemple, un index doit être utilisé, mais une analyse complète de la table est effectuée. Bien qu'il y ait deux mots « optimisation » dans l'optimiseur de requêtes, cette optimisation n'est pas omnipotente. Dans de nombreux cas, il est plus nécessaire de se demander si l'instruction SQL est écrite de manière raisonnable.
L'optimisation des requêtes logiques est principalement responsable de l'exécution d'une certaine algèbre relationnelle pour optimiser les instructions SQL, afin que les instructions SQL puissent être exécutées plus efficacement
Optimisation des requêtes logiques Nous pouvons utiliser plusieurs cas pour comprendre simplement
Fusion de sous-requêtes
Avant la fusion
SELECT * FROM t1 WHERE a1<10 AND ( EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=1) OR EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=2) );
Après la fusion
SELECT * FROM t1 WHERE a1<10 AND ( EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND (t2.b2=1 OR t2.b2=2) );
Fusionnez plusieurs sous-requêtes en fusionnant les conditions de requête et réduisez plusieurs opérations de connexion à une seule analyse de table et une seule connexion
Prédicat équivalent lourd Write
comme le familier comme la requête floue, % est écrit après la condition pour effectuer la requête de plage d'index. En fait, c'est le mérite de l'optimiseur de requête
Supposons que les conditions utilisées soient toutes indexées, avant la réécriture
SELECT * FROM USERINFO WHERE name LIKE 'Abc%';
Après la réécriture
SELECT * FROM USERINFO WHERE name >= 'Abc' AND name < 'Abd';
Ceci. est la réponse à la requête de plage d'index
Simplification conditionnelle
La simplification conditionnelle utilise également certaines équations et relations algébriques pour parvenir à la simplification
((a AND b) AND (c AND d)) est simplifié en a AND b AND c AND d((a AND b) AND (c AND d)) 简化为 a AND b AND c AND d
col1 = col2 AND col2 = 3 简化为 col1 = 3 AND col2 = 3
col1 = 1+2 简化为 col1 = 3 col1 = col2 AND col2 = 3 est simplifié en col1 = 3 AND col2 = 3
col1 = 3
Optimisation des requêtes physiques
Principalement effectué par l'optimisation des requêtes physiques Le travail consiste à évaluer le coût de plusieurs plans d'exécution basés sur des instructions SQL.| Méthode de numérisation | |
|---|---|
| Analyse séquentielle | |
| Index scan |
Les paramètres ci-dessus sont expliqués comme suit :
Vous pouvez vous référer à cet article pour le calcul du coût de l'index : Pourquoi la requête MySQL a-t-elle choisi d'utiliser cet index ? ——Basé sur le calcul du coût de l'index MySQL 8.0.22
Le plan d'exécution est le produit de l'optimiseur de requêtes et sera éventuellement transmis au moteur de stockage pour exécution. Le plan d'exécution peut nous aider à savoir comment MySQL exécutera cette instruction SQL.
Utilisez le mot-clé explain pour visualiser le plan d'exécution de l'instruction SQL, et vous pourrez obtenir les informations suivantes :
Le serveur MySQL stipule les spécifications sur la façon dont les données sont stockées, extraites et mises à jour. Cette spécification est implémentée par les moteurs de stockage. Différents moteurs de stockage ont des méthodes de mise en œuvre différentes, donc différents moteurs de stockage le feront. présentent leurs fonctions et caractéristiques uniques. Les moteurs de stockage les plus couramment utilisés sont InnoDB et MyISAM
Parlons brièvement des caractéristiques de ces deux moteurs de stockage
InnoDB :
MyISAM
Le moteur de stockage ne sera pas étendu pour l'instant, le sera Dans d'autres articles, ils continueront à intercaler leurs comparaisons, et analyseront en détail le processus de mise à jour des données dans InnoDB
Dans le passé, je savais seulement écrire des instructions SQL sur le logiciel client, cliquez sur pour exécuter et obtenir les données
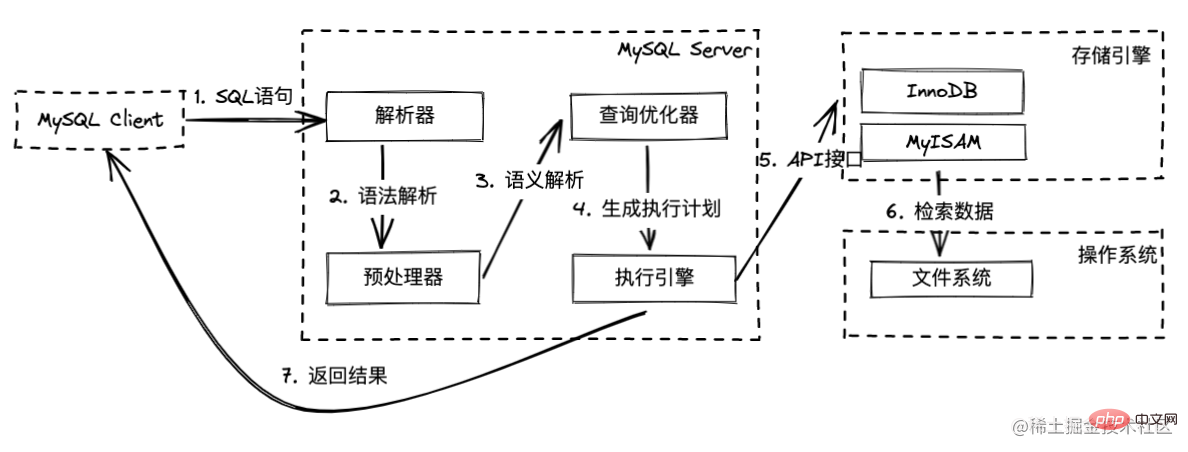
Jusqu'à présent, j'ai finalement appris qu'une instruction de requête doit passer par cette série d'opérations après avoir été transmise au serveur MySQL. L'analyseur vérifie la syntaxe et le lexique de l'instruction SQL s'il y en a. aucune erreur, il sera divisé en morceaux en fonction des nœuds de mots-clés, et formera enfin un arbre d'analyse
Le préprocesseur vérifiera la sémantique de l'instruction SQL, vérifiera si l'instruction SQL est ambiguë, si les champs, etc. exister et former un nouvel arbre d'analyse
L'optimiseur de requêtes l'obtient. Les différents plans d'exécution générés par cet arbre d'analyse sont obtenus grâce à l'optimisation de requêtes logiques et à l'optimisation de requêtes physiques pour obtenir un plan d'exécution au coût minimum
Le Le moteur d'exécution obtient ce plan d'exécution et appelle l'interface du moteur de stockage
Le moteur de stockage basé sur Le plan d'exécution effectue une requête de données. La requête interrogera et appellera certaines interfaces du système de fichiers dans le système d'exploitation, complétera la requête de données, et enfin le retourner au client
[Recommandations associées :
Tutoriel vidéo mysqlCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 Base de données trois paradigmes
Base de données trois paradigmes
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql

![Solution d'optimisation des requêtes MySQL [enseignée par des architectes de grands fabricants] [Démarrer avec MySQL Indexation] Tutoriel avancé |](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



