
 interface Web
js tutoriel
Les effets spéciaux à choix multiples d'images très populaires de Douyin peuvent être rapidement mis en œuvre à l'aide du frontal !
interface Web
js tutoriel
Les effets spéciaux à choix multiples d'images très populaires de Douyin peuvent être rapidement mis en œuvre à l'aide du frontal !
Les effets spéciaux à choix multiples d'images très populaires de Douyin peuvent être rapidement mis en œuvre à l'aide du frontal !

Cet article vous apporte des connaissances pertinentes sur les effets spéciaux d'image front-end. Il présente principalement comment le front-end implémente un effet spécial d'image à choix multiples qui est devenu très populaire sur Douyin récemment. Il est très complet et détaillé. regardez-le ensemble. J'espère que cela vous aidera si vous en avez besoin.


Pour des raisons de sécurité, les Nuggets n'ont pas défini allow="microphone *;camera *" sur la balise iframe, ce qui a empêché l'ouverture de la caméra ! Veuillez cliquer sur « Afficher les détails » dans le coin supérieur droit pour voir ! Ou cliquez sur le lien ci-dessous pour voir
//复制链接预览 https://code.juejin.cn/pen/7160886403805970445
Avant-propos
Récemment, il y a une question à choix multiples avec image dans les effets spéciaux Douyin qui est très populaire. Aujourd'hui, je vais parler de la façon de mettre en œuvre le front-. fin. Ci-dessous, je parlerai principalement de la façon de Déterminer si vous devez bouger la tête à gauche ou à droite. 图片选择题特别火,今天就来讲一下前端如何实现,下面我主要讲一下如何判断左右摆头。
架构和概念
抽象整体的实现思路如下

MediaPipe Face Mesh是一个解决方案,即使在移动设备上也能实时估计468个3D面部地标。它使用机器学习(ML)来推断3D面部表面,只需要一个摄像头输入,而无需专用的深度传感器。该解决方案利用轻量级模型架构以及整个管道中的GPU加速,为实时体验提供了至关重要的实时性能。
引入
import '@mediapipe/face_mesh'; import '@tensorflow/tfjs-core'; import '@tensorflow/tfjs-backend-webgl'; import * as faceLandmarksDetection from '@tensorflow-models/face-landmarks-detection';
创建人脸模型
引入tensorflow训练好的人脸特征点检测模型,预测 486 个 3D 人脸特征点,推断出人脸的近似面部几何图形。
maxFaces默认为1。模型将检测到的最大人脸数量。返回的面孔数量可以小于最大值(例如,当输入中没有人脸时)。强烈建议将此值设置为预期的最大人脸数量,否则模型将继续搜索缺失的面孔,这可能会减慢性能。refineLandmarks默认为false。如果设置为真,则细化眼睛和嘴唇周围的地标坐标,并在虹膜周围输出其他地标。(这里我可以设置false,因为我们没有用到眼部坐标)solutionPath通往am二进制文件和模型文件所在位置的路径。(强烈建议将模型放到国内的对象存储里面,首次加载可以节省大量时间,大小大概10M)
async createDetector(){
const model = faceLandmarksDetection.SupportedModels.MediaPipeFaceMesh;
const detectorConfig = {
maxFaces:1, //检测到的最大面部数量
refineLandmarks:false, //可以完善眼睛和嘴唇周围的地标坐标,并在虹膜周围输出其他地标
runtime: 'mediapipe',
solutionPath: 'https://cdn.jsdelivr.net/npm/@mediapipe/face_mesh', //WASM二进制文件和模型文件所在的路径
};
this.detector = await faceLandmarksDetection.createDetector(model, detectorConfig);
}
人脸识别
返回的面孔列表包含图像中每个面孔的检测面。如果模型无法检测到任何面孔,列表将是空的。 对于每个面,它包含一个检测到的面孔的边界框,以及一个关键点数组。MediaPipeFaceMesh返回468个关键点。每个关键点都包含x和y,以及一个名称。
现在,您可以使用探测器来检测人脸。estimateFaces方法接受多种格式的图像和视频,包括:
HTMLVideoElement、HTMLImageElement、HTMLCanvasElement和Tensor3D。
flipHorizontal可选。默认为false。当图像数据来自相机时,结果必须水平翻转。
async renderPrediction() {
var video = this.$refs['video'];
var canvas = this.$refs['canvas'];
var context = canvas.getContext('2d');
context.clearRect(0, 0, canvas.width, canvas.height);
const Faces = await this.detector.estimateFaces(video, {
flipHorizontal:false, //镜像
});
if (Faces.length > 0) {
this.log(`检测到人脸`);
} else {
this.log(`没有检测到人脸`);
}
}
该框表示图像像素空间中面部的边界框,xMin、xMax表示x-bounds、yMin、yMax表示y-bounds,宽度、高度表示边界框的尺寸。 对于关键点,x和y表示图像像素空间中的实际关键点位置。z表示头部中心为原点的深度,值越小,键点离相机越近。Z的大小使用与x大致相同的比例。 这个名字为一些关键点提供了一个标签,例如“嘴唇”、“左眼”等。请注意,并非每个关键点都有标签。
如何判断
找到人脸上的两个两个点
第一个点 额头中心位置第二个点 下巴中心位置
const place1 = (face.keypoints || []).find((e,i)=>i===10); //额头位置
const place2 = (face.keypoints || []).find((e,i)=>i===152); //下巴位置
/*
x1,y1
|
|
|
x2,y2 -------|------- x4,y4
x3,y3
*/
const [x1,y1,x2,y2,x3,y3,x4,y4] = [
place1.x,place1.y,
0,place2.y,
place2.x,place2.y,
this.canvas.width, place2.y
];通过canvas.width 额头中心位置和下巴中心位置计算出 x1,y1,x2,y2,x3,y3,x4,y4
Architecture et concepts
L'idée générale de mise en œuvre de l'abstraction est la suivante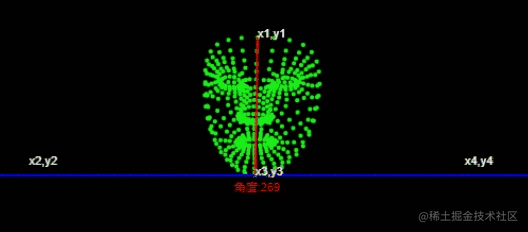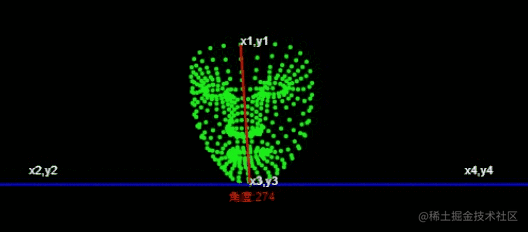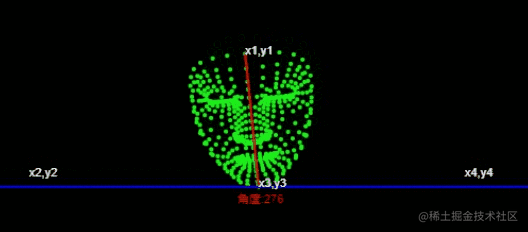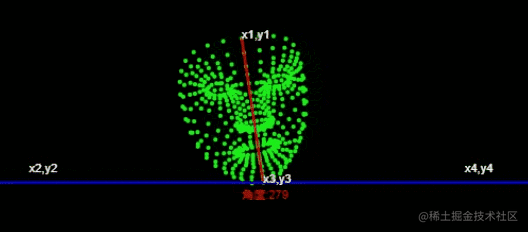
🎜🎜MediaPipe Face Mesh est une solution même sur les appareils mobiles, il peut également estimer 468 repères faciaux 3D en temps réel. Il utilise l'apprentissage automatique (ML) pour déduire des surfaces faciales 3D, ne nécessitant qu'une entrée de caméra et aucun capteur de profondeur dédié. La solution s'appuie sur une architecture de modèle légère ainsi que sur l'accélération GPU tout au long du pipeline pour offrir des performances en temps réel critiques pour les expériences en temps réel. 🎜Présentez 🎜getAngle({ x: x1, y: y1 }, { x: x2, y: y2 }){
const dot = x1 * x2 + y1 * y2
const det = x1 * y2 - y1 * x2
const angle = Math.atan2(det, dot) / Math.PI * 180
return Math.round(angle + 360) % 360
}
const angle = this.getAngle({
x: x1 - x3,
y: y1 - y3,
}, {
x: x2 - x3,
y: y2 - y3,
});
console.log('角度',angle)Copier après la connexionCopier après la connexion pour créer un modèle de visage 🎜🎜Présentez le modèle de détection de points caractéristiques du visage formé par Tensorflow</code >, prédisez <code>486 points caractéristiques du visage 3D et déduisez la géométrie faciale approximative du visage. 🎜maxFaces La valeur par défaut est 1. Le nombre maximum de visages que le modèle détectera. Le nombre de visages renvoyés peut être inférieur au maximum (par exemple, lorsqu'il n'y a aucun visage dans l'entrée). Il est fortement recommandé de définir cette valeur sur le nombre maximum de faces attendu, sinon le modèle continuera à rechercher les faces manquantes, ce qui pourrait ralentir les performances. refineLandmarks La valeur par défaut est false. Si la valeur est true, affine les coordonnées des points de repère autour des yeux et des lèvres et génère des points de repère supplémentaires autour de l'iris. (Je peux définir false ici car nous n'utilisons pas les coordonnées oculaires) solutionPath Le chemin d'accès à l'emplacement des fichiers binaires et modèles am. (Il est fortement recommandé de stocker le modèle dans un stockage d'objets domestiques. Le premier chargement peut faire gagner beaucoup de temps. La taille est d'environ 10M)
rrreee🎜 🎜< h2 data-id="head-4">Reconnaissance faciale🎜🎜La liste des visages renvoyée contient les visages détectés pour chaque visage de l'image. Si le modèle ne détecte aucun visage, la liste sera vide.
Pour chaque visage, il contient un cadre de délimitation du visage détecté et un tableau de points clés. MediaPipeFaceMesh renvoie 468 points clés. Chaque point clé contient x et y, ainsi qu'un nom. 🎜🎜🎜Vous pouvez désormais utiliser le détecteur pour détecter les visages. La méthodeestimateFaces accepte des images et des vidéos dans divers formats, notamment :
🎜< h2 data-id="head-4">Reconnaissance faciale🎜🎜La liste des visages renvoyée contient les visages détectés pour chaque visage de l'image. Si le modèle ne détecte aucun visage, la liste sera vide.
Pour chaque visage, il contient un cadre de délimitation du visage détecté et un tableau de points clés. MediaPipeFaceMesh renvoie 468 points clés. Chaque point clé contient x et y, ainsi qu'un nom. 🎜🎜🎜Vous pouvez désormais utiliser le détecteur pour détecter les visages. La méthodeestimateFaces accepte des images et des vidéos dans divers formats, notamment : HTMLVideoElement, HTMLImageElement, HTMLCanvasElement et Tensor3D. >. 🎜🎜flipHorizontal Facultatif. La valeur par défaut est fausse. Lorsque les données d'image proviennent d'une caméra, le résultat doit être inversé horizontalement.
rrreee🎜🎜🎜Cette zone représente la zone de délimitation du visage dans l'espace des pixels de l'image, xMin et xMax représentent les limites x, yMin et yMax représentent les limites y, et la largeur et la hauteur représentent la taille de la zone de délimitation .
Pour les points clés, x et y représentent l'emplacement réel du point clé dans l'espace des pixels de l'image. z représente la profondeur à laquelle le centre de la tête est l'origine. Plus la valeur est petite, plus le point clé est proche de la caméra. La taille de Z utilise à peu près la même échelle que x.
Ce nom fournit une étiquette pour certains points clés, tels que « lèvres », « œil gauche », etc. Notez que tous les points clés n'ont pas d'étiquette. 🎜Comment juger🎜🎜Trouver deux points sur le visage d'une personne🎜🎜Le premier point Position centrale du front Le deuxième point Position centrale du menton< /code>🎜rrreee🎜Calculez <code>x1,y1,x2,y2,x3, à travers canvas.width <code>position centrale du front et position centrale du menton y3,x4,y4 🎜🎜🎜🎜getAngle({ x: x1, y: y1 }, { x: x2, y: y2 }){
const dot = x1 * x2 + y1 * y2
const det = x1 * y2 - y1 * x2
const angle = Math.atan2(det, dot) / Math.PI * 180
return Math.round(angle + 360) % 360
}
const angle = this.getAngle({
x: x1 - x3,
y: y1 - y3,
}, {
x: x2 - x3,
y: y2 - y3,
});
console.log('角度',angle)Copier après la connexionCopier après la connexion
getAngle({ x: x1, y: y1 }, { x: x2, y: y2 }){
const dot = x1 * x2 + y1 * y2
const det = x1 * y2 - y1 * x2
const angle = Math.atan2(det, dot) / Math.PI * 180
return Math.round(angle + 360) % 360
}
const angle = this.getAngle({
x: x1 - x3,
y: y1 - y3,
}, {
x: x2 - x3,
y: y2 - y3,
});
console.log('角度',angle)modèle de détection de points caractéristiques du visage formé par Tensorflow</code >, prédisez <code>486 points caractéristiques du visage 3D et déduisez la géométrie faciale approximative du visage. 🎜maxFacesLa valeur par défaut est 1. Le nombre maximum de visages que le modèle détectera. Le nombre de visages renvoyés peut être inférieur au maximum (par exemple, lorsqu'il n'y a aucun visage dans l'entrée). Il est fortement recommandé de définir cette valeur sur le nombre maximum de faces attendu, sinon le modèle continuera à rechercher les faces manquantes, ce qui pourrait ralentir les performances.refineLandmarksLa valeur par défaut est false. Si la valeur est true, affine les coordonnées des points de repère autour des yeux et des lèvres et génère des points de repère supplémentaires autour de l'iris. (Je peux définirfalseici car nous n'utilisons pas les coordonnées oculaires)solutionPathLe chemin d'accès à l'emplacement des fichiers binaires et modèles am. (Il est fortement recommandé de stocker le modèle dans un stockage d'objets domestiques. Le premier chargement peut faire gagner beaucoup de temps. La taille est d'environ10M)
🎜< h2 data-id="head-4">Reconnaissance faciale🎜🎜La liste des visages renvoyée contient les visages détectés pour chaque visage de l'image. Si le modèle ne détecte aucun visage, la liste sera vide.
Pour chaque visage, il contient un cadre de délimitation du visage détecté et un tableau de points clés. MediaPipeFaceMesh renvoie 468 points clés. Chaque point clé contient x et y, ainsi qu'un nom. 🎜🎜🎜Vous pouvez désormais utiliser le détecteur pour détecter les visages. La méthodeestimateFaces accepte des images et des vidéos dans divers formats, notamment : HTMLVideoElement, HTMLImageElement, HTMLCanvasElement et Tensor3D. >. 🎜🎜flipHorizontalFacultatif. La valeur par défaut est fausse. Lorsque les données d'image proviennent d'une caméra, le résultat doit être inversé horizontalement.
🎜🎜Cette zone représente la zone de délimitation du visage dans l'espace des pixels de l'image, xMin et xMax représentent les limites x, yMin et yMax représentent les limites y, et la largeur et la hauteur représentent la taille de la zone de délimitation .
Pour les points clés, x et y représentent l'emplacement réel du point clé dans l'espace des pixels de l'image. z représente la profondeur à laquelle le centre de la tête est l'origine. Plus la valeur est petite, plus le point clé est proche de la caméra. La taille de Z utilise à peu près la même échelle que x.
Ce nom fournit une étiquette pour certains points clés, tels que « lèvres », « œil gauche », etc. Notez que tous les points clés n'ont pas d'étiquette. 🎜Comment juger🎜🎜Trouver deux points sur le visage d'une personne🎜🎜Le premier point Position centrale du front Le deuxième point Position centrale du menton< /code>🎜rrreee🎜Calculez <code>x1,y1,x2,y2,x3, à travers canvas.width <code>position centrale du front et position centrale du menton y3,x4,y4 🎜🎜🎜🎜getAngle({ x: x1, y: y1 }, { x: x2, y: y2 }){
const dot = x1 * x2 + y1 * y2
const det = x1 * y2 - y1 * x2
const angle = Math.atan2(det, dot) / Math.PI * 180
return Math.round(angle + 360) % 360
}
const angle = this.getAngle({
x: x1 - x3,
y: y1 - y3,
}, {
x: x2 - x3,
y: y2 - y3,
});
console.log('角度',angle)Copier après la connexionCopier après la connexion
getAngle({ x: x1, y: y1 }, { x: x2, y: y2 }){
const dot = x1 * x2 + y1 * y2
const det = x1 * y2 - y1 * x2
const angle = Math.atan2(det, dot) / Math.PI * 180
return Math.round(angle + 360) % 360
}
const angle = this.getAngle({
x: x1 - x3,
y: y1 - y3,
}, {
x: x2 - x3,
y: y2 - y3,
});
console.log('角度',angle)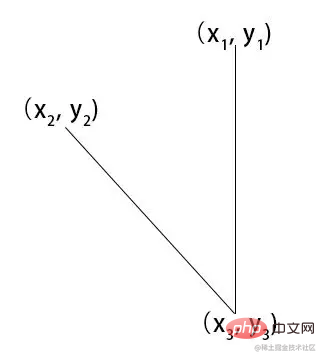
通过获取角度,通过角度的大小来判断左右摆头。
推荐:《web前端开发视频教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Une collection complète de packs d'expression de femmes étrangères
Jul 15, 2024 pm 05:48 PM
Une collection complète de packs d'expression de femmes étrangères
Jul 15, 2024 pm 05:48 PM
Quelles sont les émoticônes des femmes étrangères ? Récemment, le package d'émoticônes d'une femme étrangère est devenu très populaire sur Internet. Je pense que de nombreux amis le rencontreront en regardant des vidéos. Ci-dessous, l'éditeur partagera avec vous quelques packages d'émoticônes correspondants. Si vous êtes intéressé, venez jeter un œil. Une collection complète de packs d'expression de femmes étrangères
 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 J'ai été honnête et j'ai demandé d'abandonner l'introduction du mème.
Jul 17, 2024 am 05:44 AM
J'ai été honnête et j'ai demandé d'abandonner l'introduction du mème.
Jul 17, 2024 am 05:44 AM
Que signifie être honnête et lâcher prise ? En tant que mot à la mode sur Internet, « J'ai été honnête et j'ai supplié d'être laissé partir » est né d'une série de discussions humoristiques sur la hausse des prix des matières premières. Cette expression est désormais principalement utilisée dans des situations d'autodérision ou de ridicule, ce qui signifie que les individus sont confrontés à des situations spécifiques. (comme la pression, lorsque vous taquinez ou plaisantez), vous sentez que vous ne pouvez pas résister ou argumenter. Suivons l'éditeur pour voir l'introduction de ce mème. Source d'introduction au mème de « Déjà suppliant de le laisser partir » : « Déjà suppliant de le laisser partir » vient de « Si vous ajoutez un trésor ponctuel, vous serez honnête », et a ensuite évolué vers « Si Liqun monte par deux yuans, vous serez honnête" et "Le thé noir glacé augmentera d'un yuan." Les internautes ont crié « J'ai été honnête et j'ai demandé une réduction de prix », qui s'est finalement transformé en « J'ai été honnête et j'ai demandé à être relâché » et un paquet d'émoticônes est né. Utilisation : Utilisé pour briser la défense, ou lorsqu'il n'y a pas d'autre moyen, ou même pour soi-même
 Je t'adore, je t'adore, une liste complète d'émoticônes
Jul 15, 2024 am 11:25 AM
Je t'adore, je t'adore, une liste complète d'émoticônes
Jul 15, 2024 am 11:25 AM
Quelles sont certaines des émoticônes de « Je t'adore, je t'adore » ? Le pack d'expressions "Je t'adore, je t'adore" vient de la "Série Big Brother et Little Brother" créée par le blogueur en ligne He Diudiu Buchuudi. Dans cette série, le frère aîné aide le frère cadet à temps lorsqu'il fait face à des difficultés. et puis le jeune frère utilisera cette ligne pour exprimer L'admiration et la gratitude extrêmes ont formé un mème Internet drôle et respectueux. Suivons l'éditeur pour profiter des émoticônes. Je t'adore, je t'adore, une liste complète d'émoticônes
 Introduction à la signification du terrier rouge chaud
Jul 12, 2024 pm 03:39 PM
Introduction à la signification du terrier rouge chaud
Jul 12, 2024 pm 03:39 PM
Qu'est-ce que la température rouge ? Le mème rouge chaud est originaire du cercle des sports électroniques, faisant spécifiquement référence au phénomène du visage de l'ancien joueur professionnel de "League of Legends", Uzi, qui devient rouge lorsqu'il est nerveux ou excité pendant le jeu. C'est devenu une expression intéressante sur Internet. pour décrire les visages des gens qui deviennent rouges à cause de l'excitation et de l'anxiété. Ce qui suit est Suivons l'éditeur pour voir l'introduction détaillée de ce mème. Introduction à la signification du mème Hongwen « Red Wen » en tant que mème Internet originaire de la culture de la diffusion en direct dans le domaine des sports électroniques, en particulier de la communauté liée à « League of Legends » (League of Legends). Ce mème a été utilisé à l'origine pour décrire un phénomène caractéristique de l'ancien joueur professionnel Uzi (Jian fièrement) dans le jeu. Lorsque Uzi joue, son visage devient extrêmement rose en raison de la nervosité, de la concentration ou de l'émotion. Cet état est comparé en plaisantant au héros du jeu "Rambo" par le public.
 Parce qu'il est doué pour les présentations
Jul 16, 2024 pm 08:59 PM
Parce qu'il est doué pour les présentations
Jul 16, 2024 pm 08:59 PM
Qu'est-ce que cela signifie parce qu'il est doué pour traquer ? Je crois que de nombreux amis ont vu un tel commentaire dans de nombreuses zones de commentaires vidéo courts. Alors qu'est-ce que cela signifie parce qu'il est bon ? Aujourd'hui, l'éditeur vous a présenté une introduction au mème « parce qu'il est bon » ? qui ne le sait pas encore, venez jeter un oeil. L'origine du mème « Parce qu'il est bon » : Le mème « Parce qu'il est bon » provient d'Internet, en particulier d'un mème populaire sur les plateformes de vidéos courtes telles que Douyin, et est lié à une blague du célèbre cross talk l'acteur Guo Degang. Dans ce paragraphe, Guo Degang a énuméré plusieurs raisons de ne pas faire quelque chose de manière humoristique. Chaque raison se terminait par « parce qu'il est bon », formant une boucle logique humoristique. En fait, il n'y a pas de relation causale directe, mais une absurdité. et une expression drôle. Mèmes chauds : par exemple : « Je ne peux pas le faire
 Pourquoi n'y a-t-il pas de climatiseur dans le dortoir ?
Jul 11, 2024 pm 07:36 PM
Pourquoi n'y a-t-il pas de climatiseur dans le dortoir ?
Jul 11, 2024 pm 07:36 PM
Pourquoi n'y a-t-il pas de climatiseur dans le dortoir ? Le mème Internet « Où est la climatisation dans le dortoir ? » est né des plaintes humoristiques formulées par des étudiants concernant le manque de climatisation dans les dortoirs, exprimant par exagération et autodérision le désir d'un environnement frais et confortable dans le dortoir. l'été chaud et les conditions réalistes. Le contraste, suivons l'éditeur pour jeter un œil à l'introduction de ce mème. Où est la climatisation dans le dortoir ? L'origine du mème : « Où est la climatisation dans le dortoir ? » Ce mème vient d'un ridicule de la vie sur le campus, en particulier pour les dortoirs scolaires avec des conditions d'hébergement relativement basiques et pas de climatisation. . Il reflète le désir des étudiants d'améliorer les conditions de logement, notamment le besoin de climatisation pendant les chauds mois d'été. Ce mème circule sur Internet et est souvent utilisé dans la communication entre étudiants pour exprimer avec humour la frustration et la frustration face au manque de climatisation par temps chaud.
 Aligner l'introduction de la tige de granularité
Jul 16, 2024 pm 12:36 PM
Aligner l'introduction de la tige de granularité
Jul 16, 2024 pm 12:36 PM
Que signifie aligner la granularité ? « Aligner la granularité » est apparu pour la première fois dans le film « La réunion annuelle ne peut pas s'arrêter ! » et a été proposé par l'acteur Dapeng dans une interview. Jetons un coup d'œil à ce qui s'est passé en détail. J'espère que cela pourra être utile à tout le monde. Introduction au mème « Align the granularity » [Align the granularity] n'est pas un terme anglais ou professionnel standard, mais une sorte d'argot de travail dans une situation spécifique. Le sens de l'argot du lieu de travail est que les deux parties synchronisent les informations et forment une compréhension commune. Ce à quoi le film fait référence, c'est de faire connaître tous les détails aux deux parties.
