
 🎜
🎜
Une analyse approfondie de Stream dans Node

Qu'est-ce que le flux ? Comment comprendre le flux ? L'article suivant vous donnera une compréhension approfondie des flux dans Nodejs. J'espère qu'il vous sera utile !

stream est une interface de données abstraite. Elle hérite d'EventEmitter. Elle peut envoyer/recevoir des données. Son essence est de faire circuler les données, comme indiqué ci-dessous : 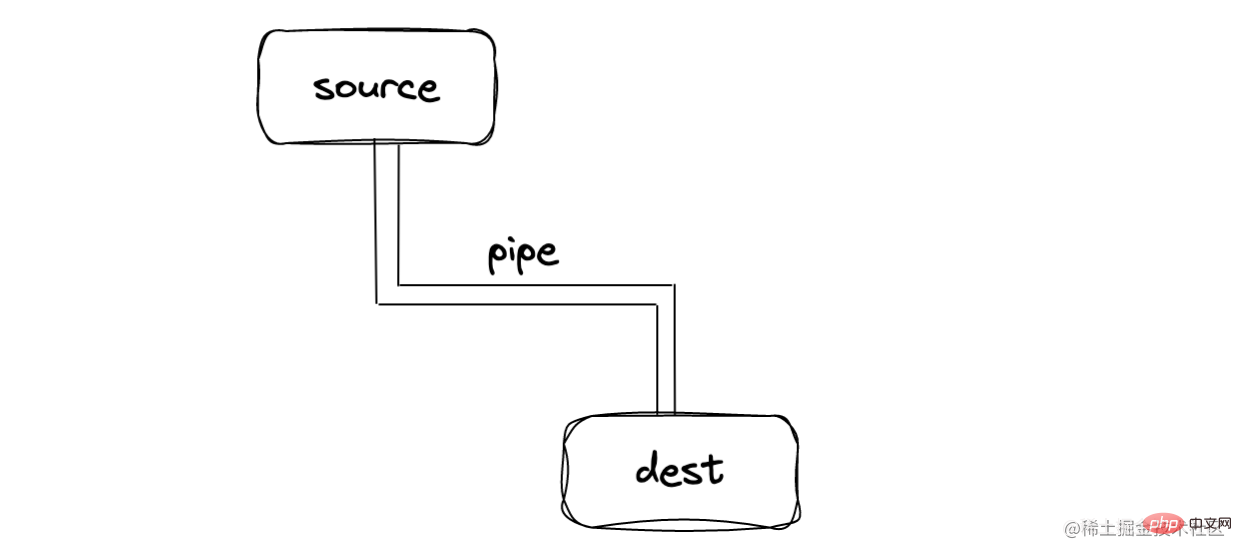
Stream n'est pas un concept unique dans Node, mais un fonctionnement. système. La méthode de fonctionnement la plus basique sous Linux | est Stream, mais elle est encapsulée au niveau du nœud et fournit l'API correspondante
Pourquoi devons-nous le faire petit à petit ?
Utilisez d'abord le code suivant pour créer un fichier d'environ 400 Mo [Recommandation du didacticiel associé : Tutoriel vidéo Nodejs]
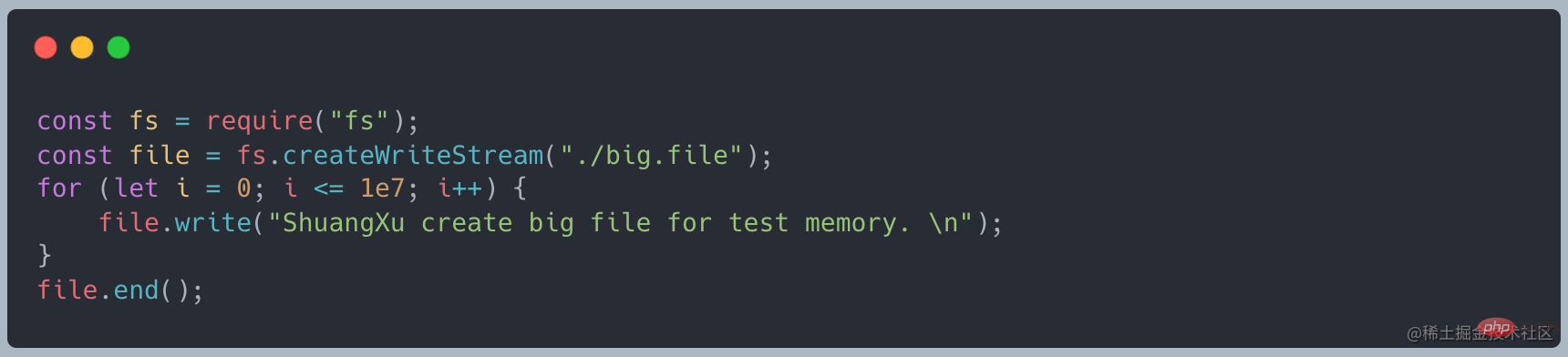
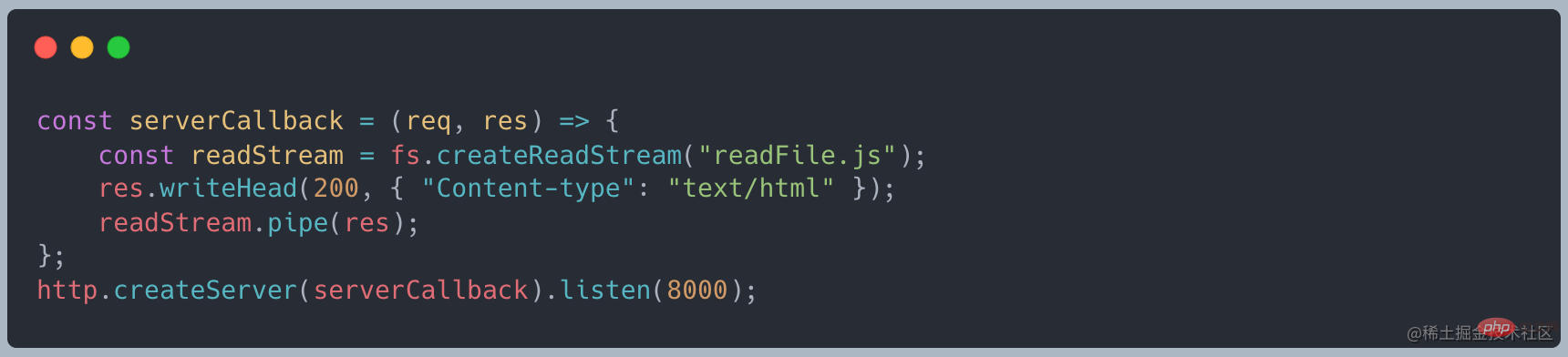
Lorsque nous utilisons readFile pour lire, le code suivant
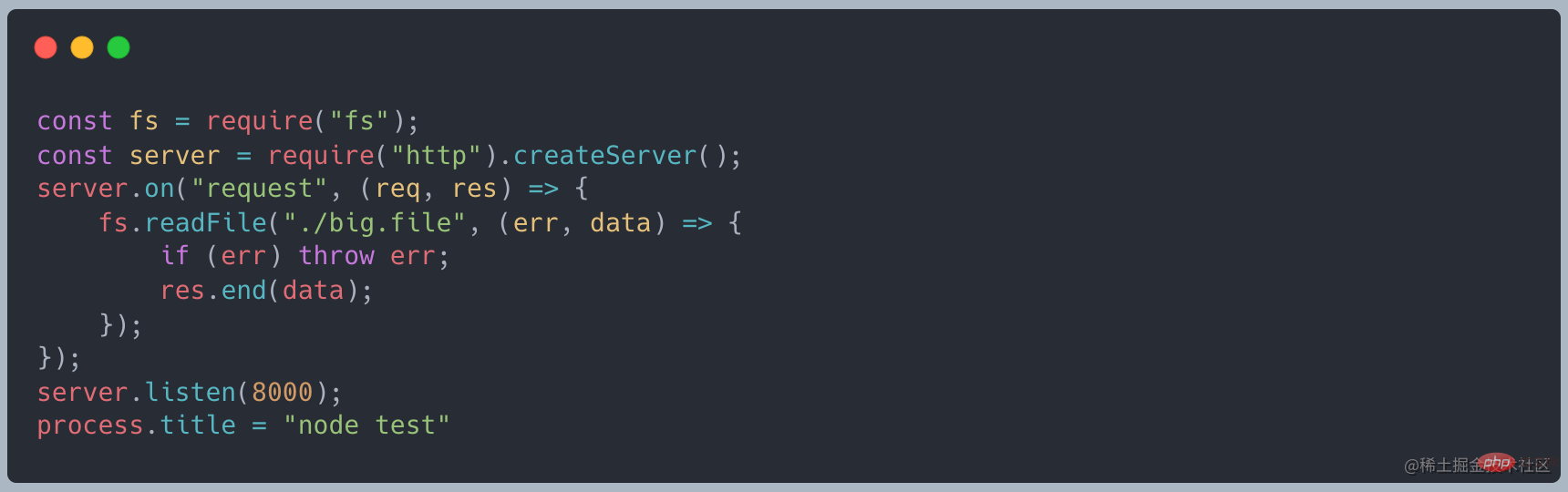
est normal Au démarrage le service, il occupe environ 10 Mo de mémoire
Lorsque vous utilisez curl http://127.0.0.1:8000 pour lancer une requête, la mémoire devient d'environ 420 Mo, ce qui est à peu près la même chose taille identique au fichier que nous avons créécurl http://127.0.0.1:8000发起请求时,内存变为了 420MB 左右,和我们创建的文件大小差不多

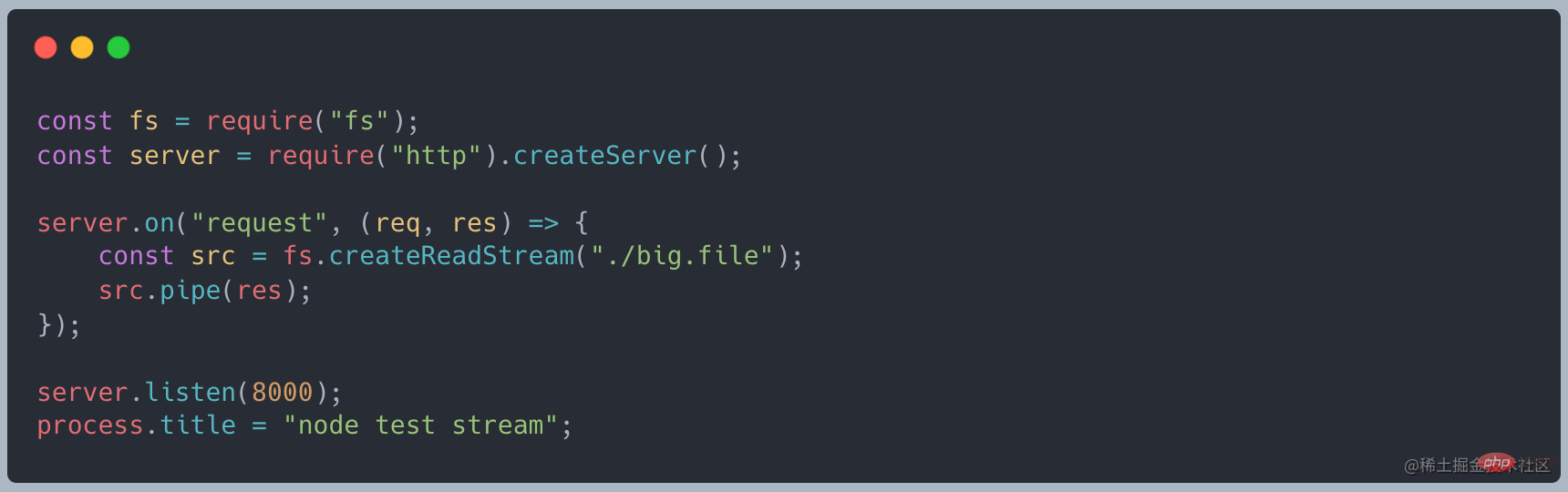
改为使用使用 stream 的写法,代码如下
再次发起请求时,发现内存只占用了 35MB 左右,相比 readFile 大幅减少

如果我们不采用流的模式,等待大文件加载完成在操作,会有如下的问题:
- 内存暂用过多,导致系统崩溃
- CPU 运算速度有限制,且服务于多个程序,大文件加载过大且时间久
总结来说就是,一次性读取大文件,内存和网络都吃不消
如何才能一点一点?
我们读取文件的时候,可以采用读取完成之后在输出数据
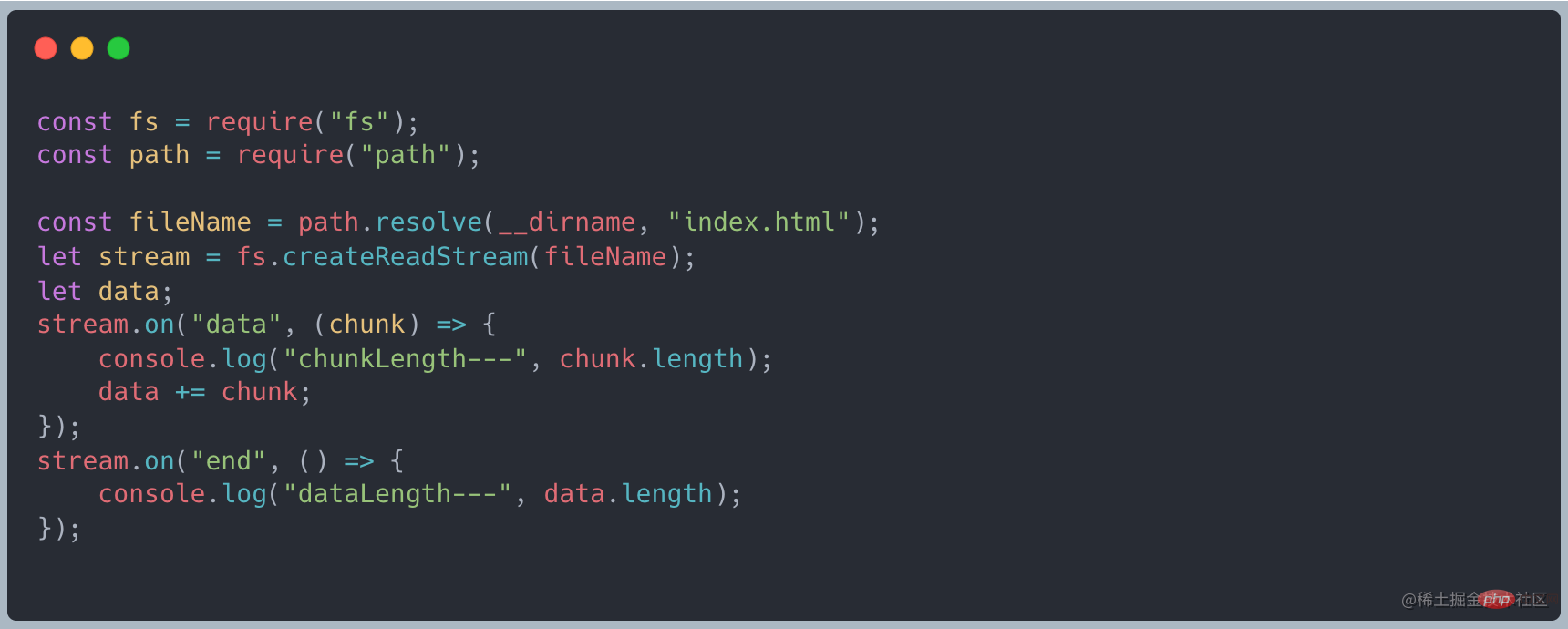
上述说到 stream 继承了 EventEmitter 可以是实现监听数据。首先将读取数据改为流式读取,使用 on("data", ()⇒{}) 接收数据,最后通过 on("end", ()⇒{}) 最后的结果
有数据传递过来的时候就会触发 data 事件,接收这段数据做处理,最后等待所有的数据全部传递完成之后触发 end 事件。
数据的流转过程
数据从哪里来—source
数据是从一个地方流向另一个地方,先看看数据的来源。
-
http 请求,请求接口来的数据

-
console 控制台,标准输入 stdin
file 文件,读取文件内容,例如上面的例子

连接的管道—pipe
在 source 和 dest 中有一个连接的管道 pipe,基本语法为 source.pipe(dest)
Changement Pour utiliser l'écriture de flux, le code est le suivant
Lorsque j'ai réitéré la requête, j'ai constaté que la mémoire n'occupait qu'environ 35 Mo, ce qui était considérablement réduit par rapport à readFile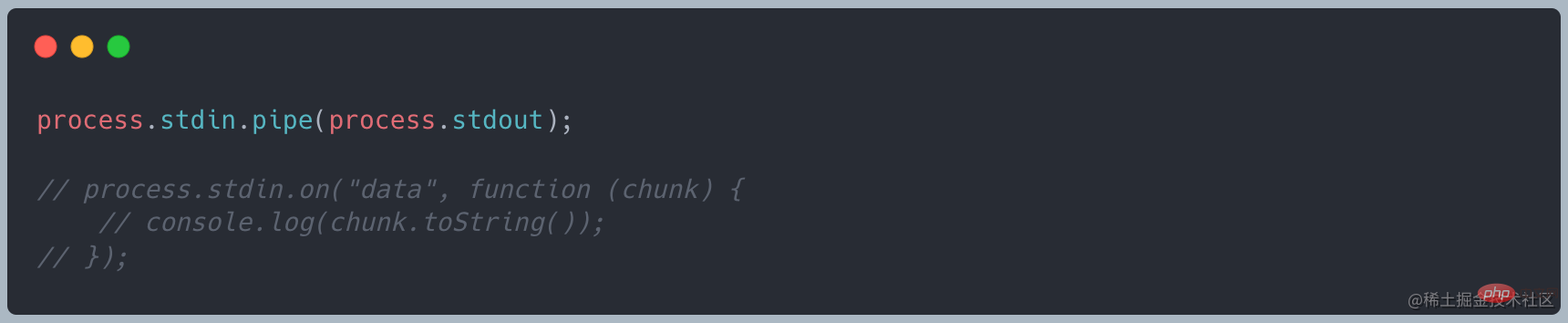
- Trop de mémoire est temporairement utilisée, provoquant un crash du système
- En résumé En d'autres termes, lire un fichier volumineux en une seule fois est trop lourd pour la mémoire et le réseau
Comment puis-je le faire petit à petit ?
Lorsque nous lisons le fichier, nous pouvons sortir les données une fois la lecture terminée🎜🎜🎜🎜Comme mentionné ci-dessus, stream hérite d'EventEmitter et peut être utilisé pour surveiller les données. Tout d'abord, changez les données de lecture en lecture en streaming, utilisez on("data", ()⇒{})pour recevoir les données, et enfin utilisezon("end", ()⇒ { })Le résultat final🎜🎜🎜🎜Lorsque les données sont transférées, l'événement de données sera déclenché, les données seront reçues pour traitement et l'événement de fin sera déclenché une fois que toutes les données auront été transférées. 🎜🎜Processus de flux de données🎜🎜
🎜D'où viennent les données – source🎜🎜🎜Les données circulent d'un endroit à un autre d'abord , regardons la source des données. 🎜🎜🎜🎜Requête http, demande de données depuis l'interface🎜🎜
🎜 🎜🎜console console, entrée standard stdin🎜🎜
- La vitesse de fonctionnement du processeur est limitée et il sert plusieurs programmes. Les fichiers volumineux sont trop volumineux et prennent beaucoup de temps à charger
 🎜🎜🎜fichier, lisez le contenu du fichier, comme l'exemple ci-dessus🎜
🎜🎜🎜fichier, lisez le contenu du fichier, comme l'exemple ci-dessus🎜🎜Tuyau connecté—pipe🎜🎜🎜Il y a un tube connecté dans source et dest La syntaxe de base est source.pipe(dest), Source. et dest sont connectés via un tube, permettant aux données de circuler de la source à la destination🎜🎜Nous n'avons pas besoin de surveiller manuellement l'événement de données/de fin comme le code ci-dessus.🎜🎜Il existe des exigences strictes lors de l'utilisation du tube. La source doit être lisible. stream, et dest must C'est un flux inscriptible🎜🎜 ??? Qu'est-ce que les données qui circulent exactement ? Qu’est-ce qu’un morceau dans le code ? 🎜🎜🎜Où aller—dest🎜🎜🎜streaming trois méthodes de sortie courantes🎜🎜🎜🎜console console, sortie standard stdout🎜🎜🎜🎜
demande http, réponse dans la requête d'interface
fichier fichier, écriture fichier
type de flux

lisible Flux lisibles
Un flux lisible est une abstraction de la source qui fournit des données
Tous les Readables implémentent l'interface définie par le stream.Readable class

?
Readable Stream a deux modes,
flowing modeet  pause mode
pause mode
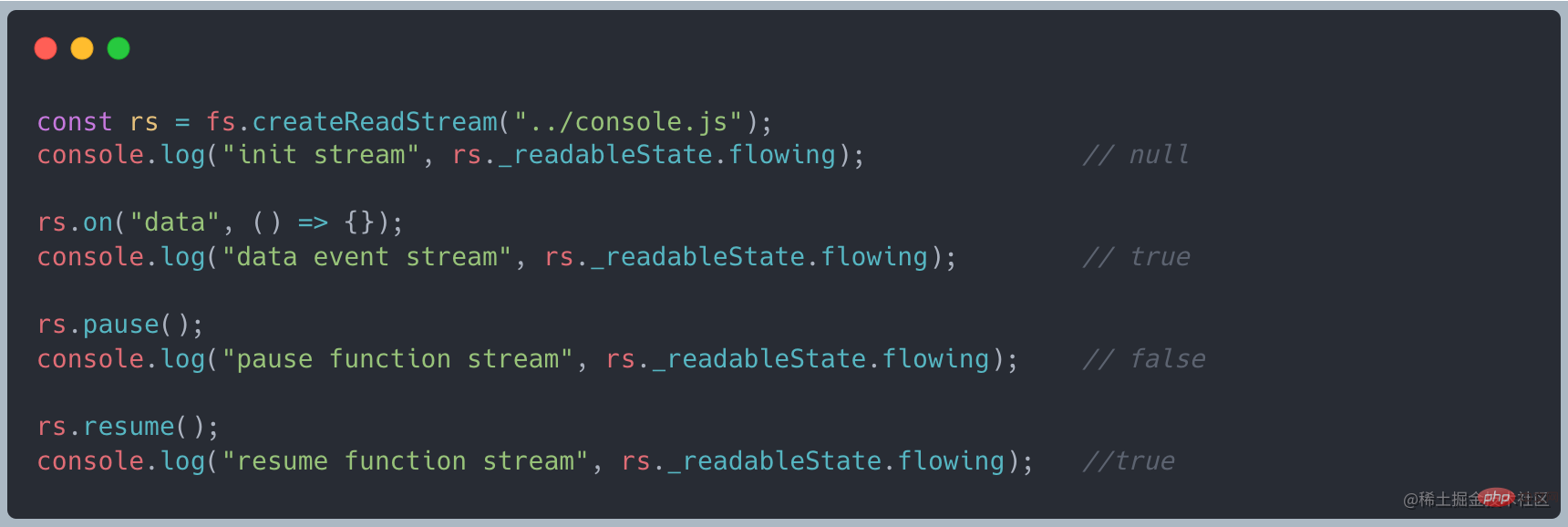
Il existe un attribut _readableState dans ReadableStream, dans lequel il y a un attribut flowing pour déterminer le mode d'écoulement. Il a trois valeurs d'état :
ture : indique le mode d'écoulement false : indique le mode pause null : état initial
- Vous pouvez utiliser le modèle de chauffe-eau pour simuler. le flux de données. Le réservoir du chauffe-eau (cache tampon) stocke l'eau chaude (données requises). Lorsque nous ouvrons le robinet, l'eau chaude continuera à s'écouler du réservoir d'eau et l'eau du robinet continuera à couler dans le réservoir d'eau. mode débit. Lorsque nous fermons le robinet, le réservoir d'eau met en pause l'entrée d'eau et le robinet met en pause la sortie d'eau. C'est le mode pause.
- Mode flux
Les données sont automatiquement lues à partir de la couche inférieure, formant un phénomène de flux, et fournies à l'application via des événements. 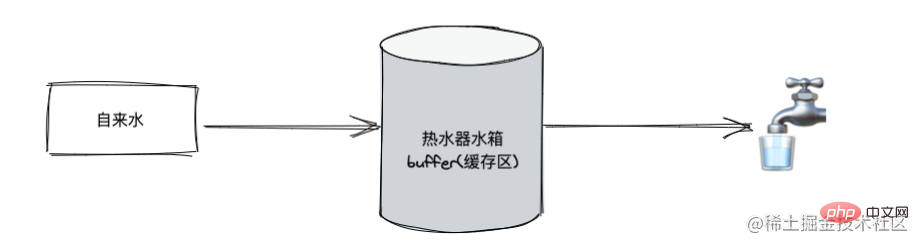
Lorsque l'événement de données est ajouté, s'il y a des données dans le flux inscriptible, les données seront poussées vers la fonction de rappel d'événement. Vous devez consommer le bloc de données. vous-même s'il n'est pas traité, les données seront perdues
Appelez la méthode stream.pipe pour envoyer les données à Writeable
Appelez la méthode stream.resume
- Mode pause
Les données s'accumuleront dans le tampon interne et doivent être affichées. Appelez stream.read() pour lire le bloc de données
- Comment convertir entre les deux modes
-
Le flux lisible est à l'état Initial //TODO : Incohérent avec le partage en ligne
- 监听 data 事件
- 调用 stream.resume 方法
- 调用 stream.pipe 方法将数据发送到 Writable
Copier après la connexion
- 监听 data 事件 - 调用 stream.resume 方法 - 调用 stream.pipe 方法将数据发送到 Writable
- Passer du mode flux en mode pause
- 移除 data 事件 - 调用 stream.pause 方法 - 调用 stream.unpipe 移除管道目标
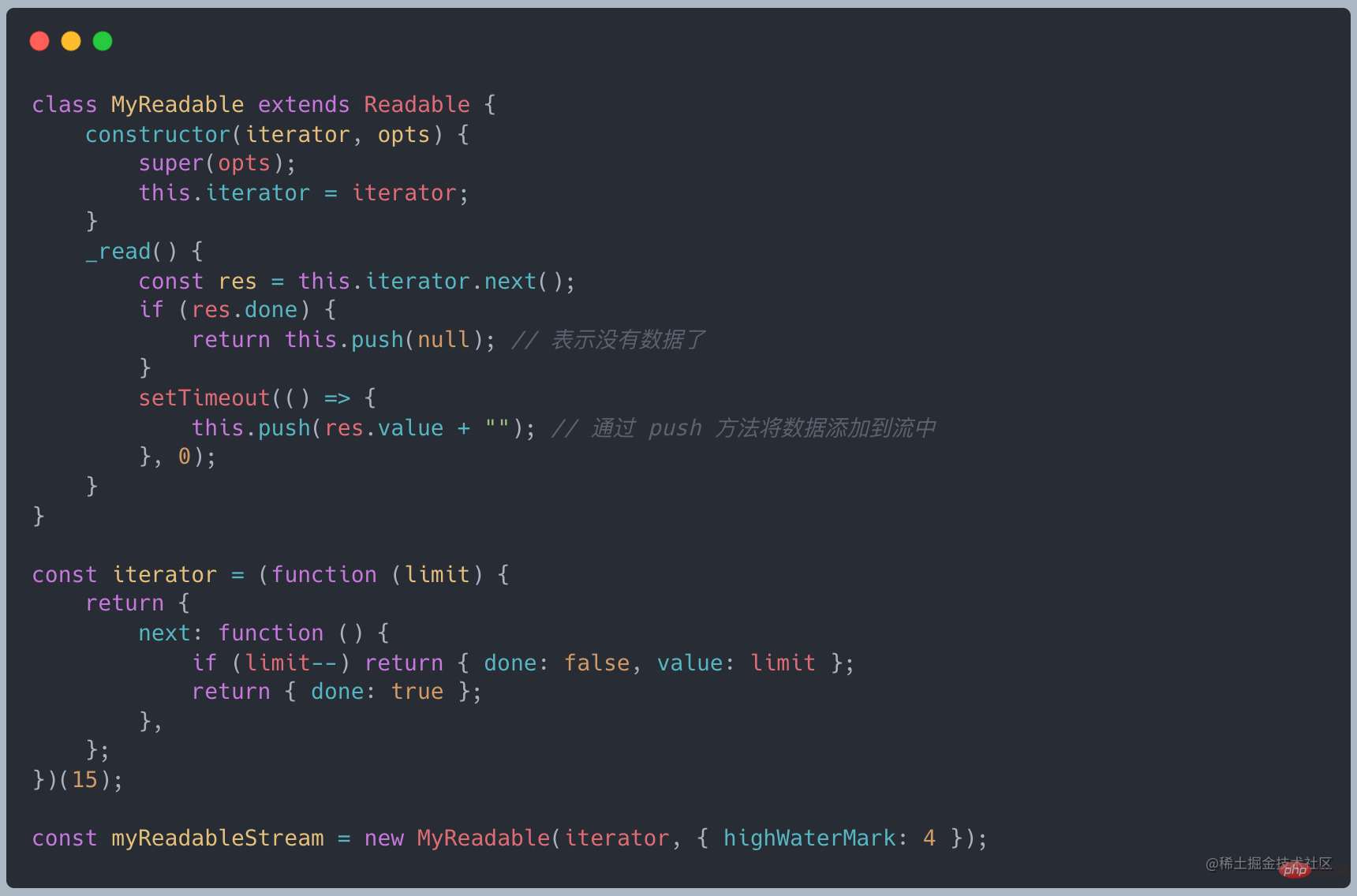
Copier après la connexionPrincipe de mise en œuvre- Créer un flux lisible Quand, nous besoin d'hériter de l'objet Readable et d'implémenter la méthode _read
-
Écrivez les données via l'écriture
-
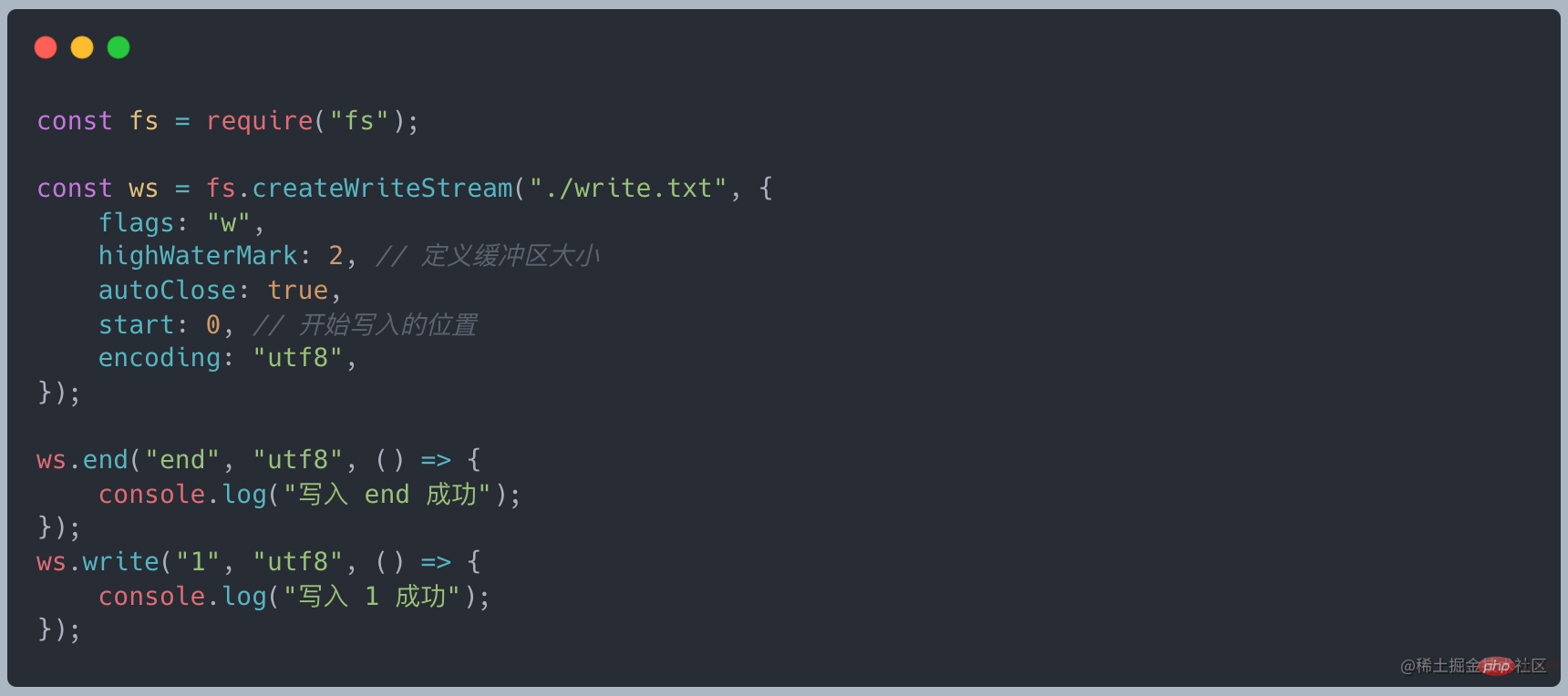
Écrivez les données jusqu'à la fin et fermez le flux, fin = écriture + fermeture
-
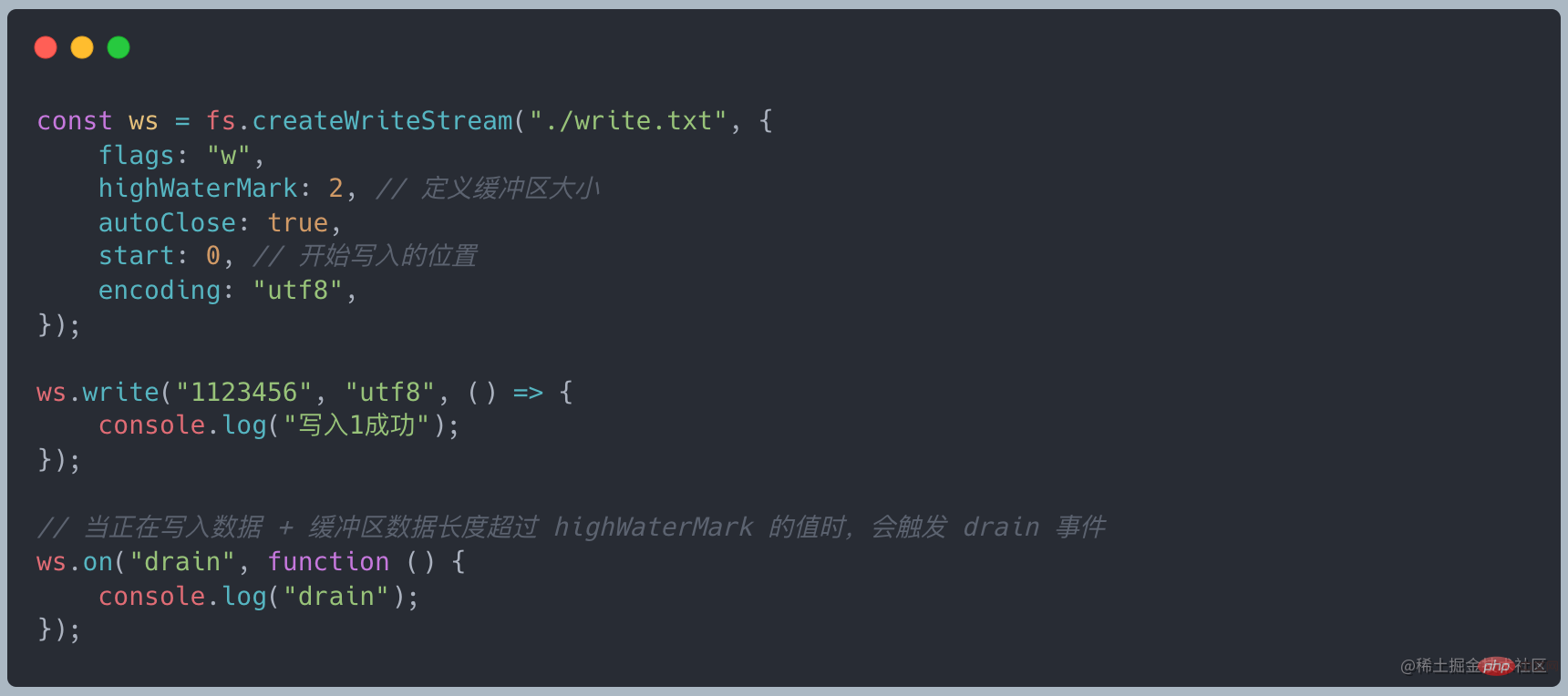
Lorsque les données écrites atteignent la taille de highWaterMark, la vidange sera déclenchée L'événement
appelle ws.write(chunk) et renvoie false, indiquant que les données actuelles du tampon sont supérieures ou égales à la valeur de highWaterMark, et l'événement drain sera déclenché. En fait, cela sert d'avertissement. Nous pouvons toujours écrire des données, mais les données non traitées seront toujours en retard dans le tampon interne du flux inscriptible. Elles ne seront pas forcées tant que le backlog n'est pas plein du tampon Node.js. . Interruption
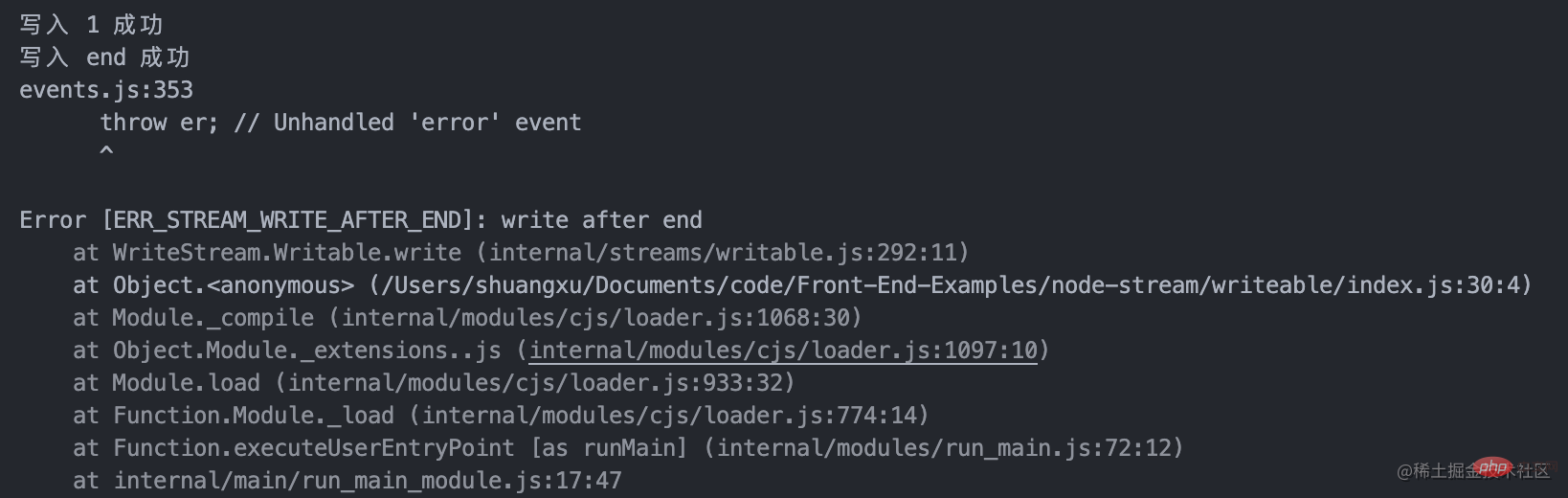
- En appelant Appelez la méthode writable.write pour écrire des données dans le flux, et la méthode _write sera appelée pour écrire les données dans la couche inférieure. Lorsque _write data réussit, vous devez appeler la méthode suivante pour traiter les données suivantes. appelez writable.end( data) pour terminer le flux inscriptible, les données sont facultatives. Après cela, write ne peut pas être appelé pour ajouter de nouvelles données, sinon une erreur sera signalée
- Après l'appel de la méthode end, lorsque toutes les opérations d'écriture sous-jacentes sont terminées, l'événement finish sera déclenché
- Duplex Stream
- Flux duplex, à la fois lisible et inscriptible. En fait, c'est un flux qui hérite de Readable et Writable. Il peut être utilisé à la fois comme flux lisible et comme flux inscriptible. Un flux duplex personnalisé doit implémenter la méthode _read de Readable et la méthode _write de Writable. Le module
 Principe de mise en œuvre
Principe de mise en œuvrepour créer un flux lisible personnalisé
Lorsque nous appelons la méthode read, le processus global est le suivant :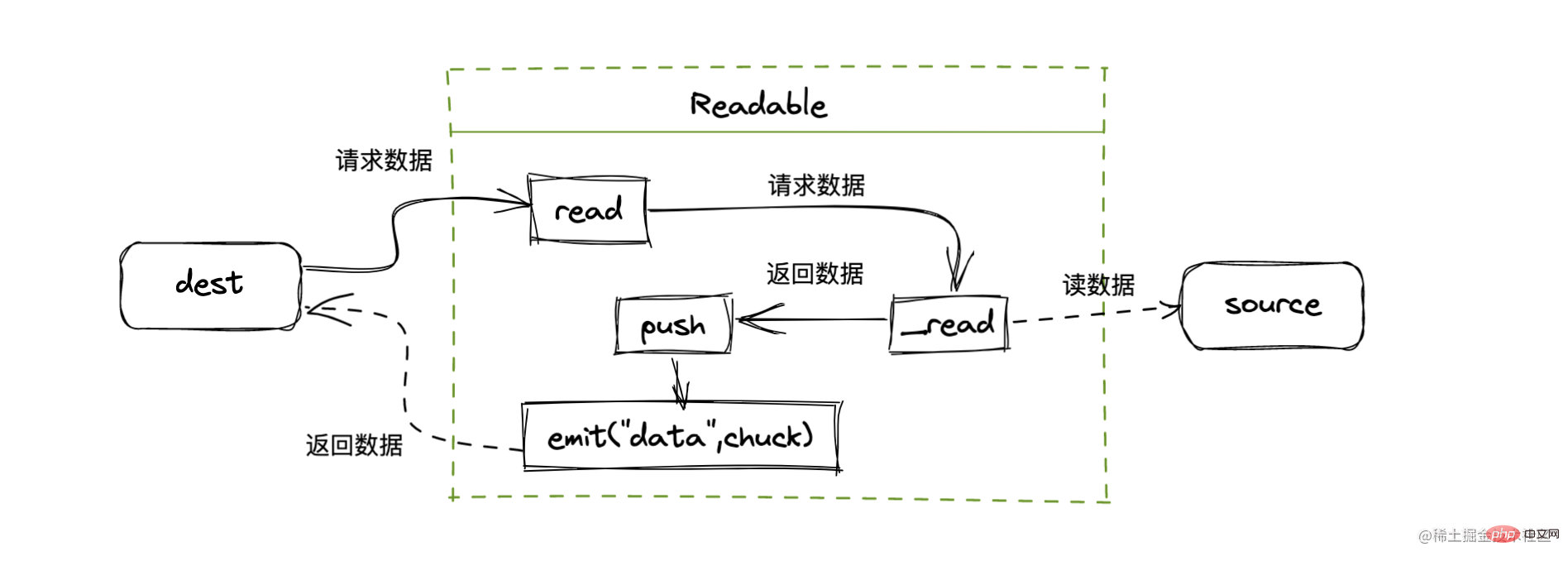
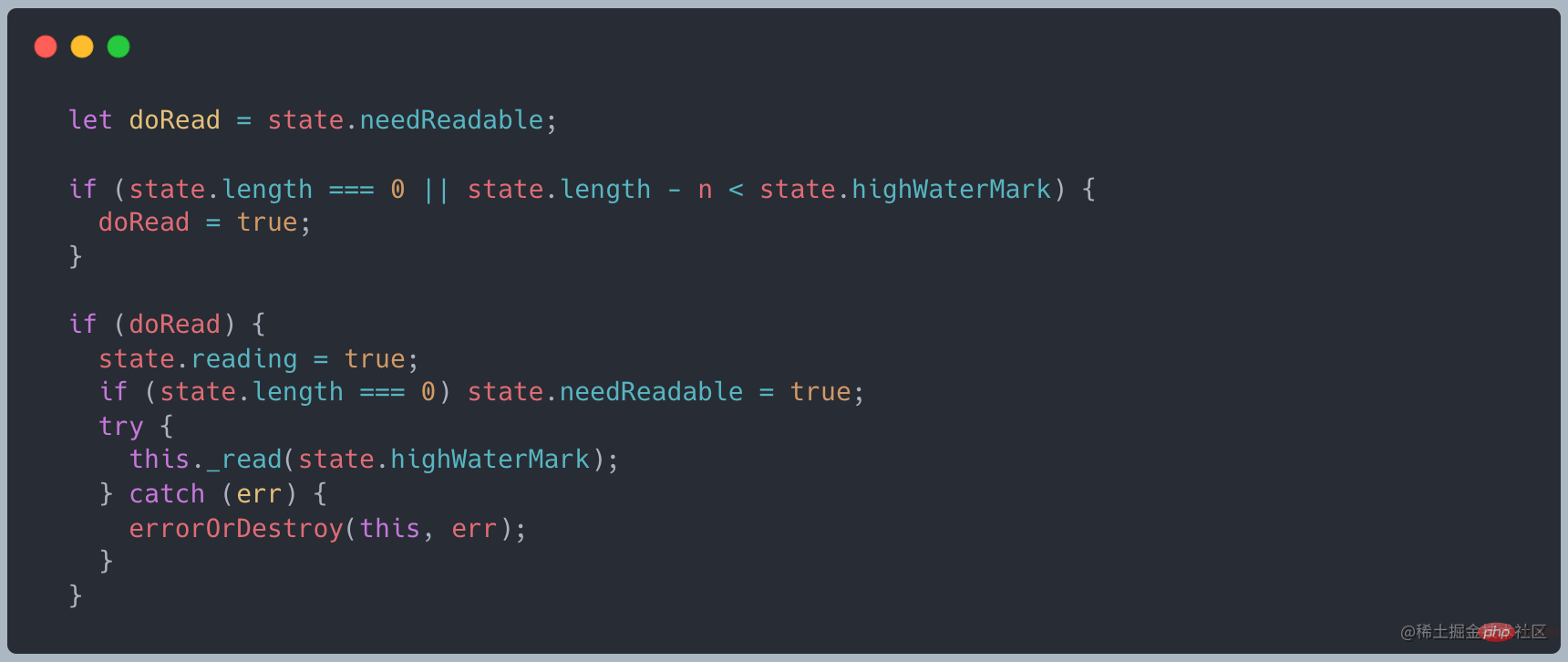
 A le cache est conservé dans le flux Lorsque la méthode de lecture est appelée, il est jugé si les données doivent être demandées à la couche inférieure
A le cache est conservé dans le flux Lorsque la méthode de lecture est appelée, il est jugé si les données doivent être demandées à la couche inférieure
Lorsque la longueur du tampon est de 0 ou inférieure à la valeur de highWaterMark, _read sera appelé pour obtenir les données de la couche inférieureLien du code source
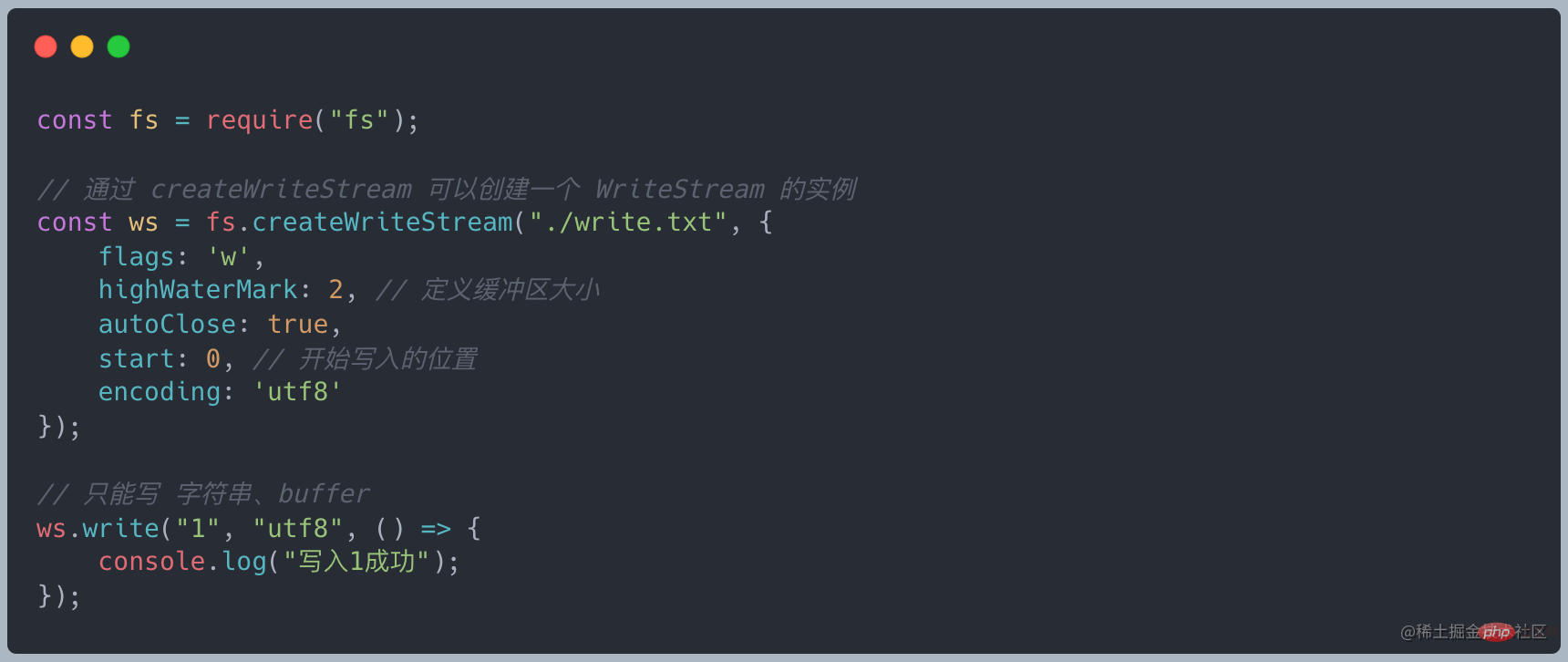
Writable StreamWritable Stream
Writable Stream doit écrire des données Une abstraction de la destination est utilisée pour consommer les données circulant en amont et écrire les données sur l'appareil via un flux inscriptible. Un flux d'écriture courant écrit sur le disque local

Caractéristiques des flux inscriptibles
.
Flux inscriptible personnalisé
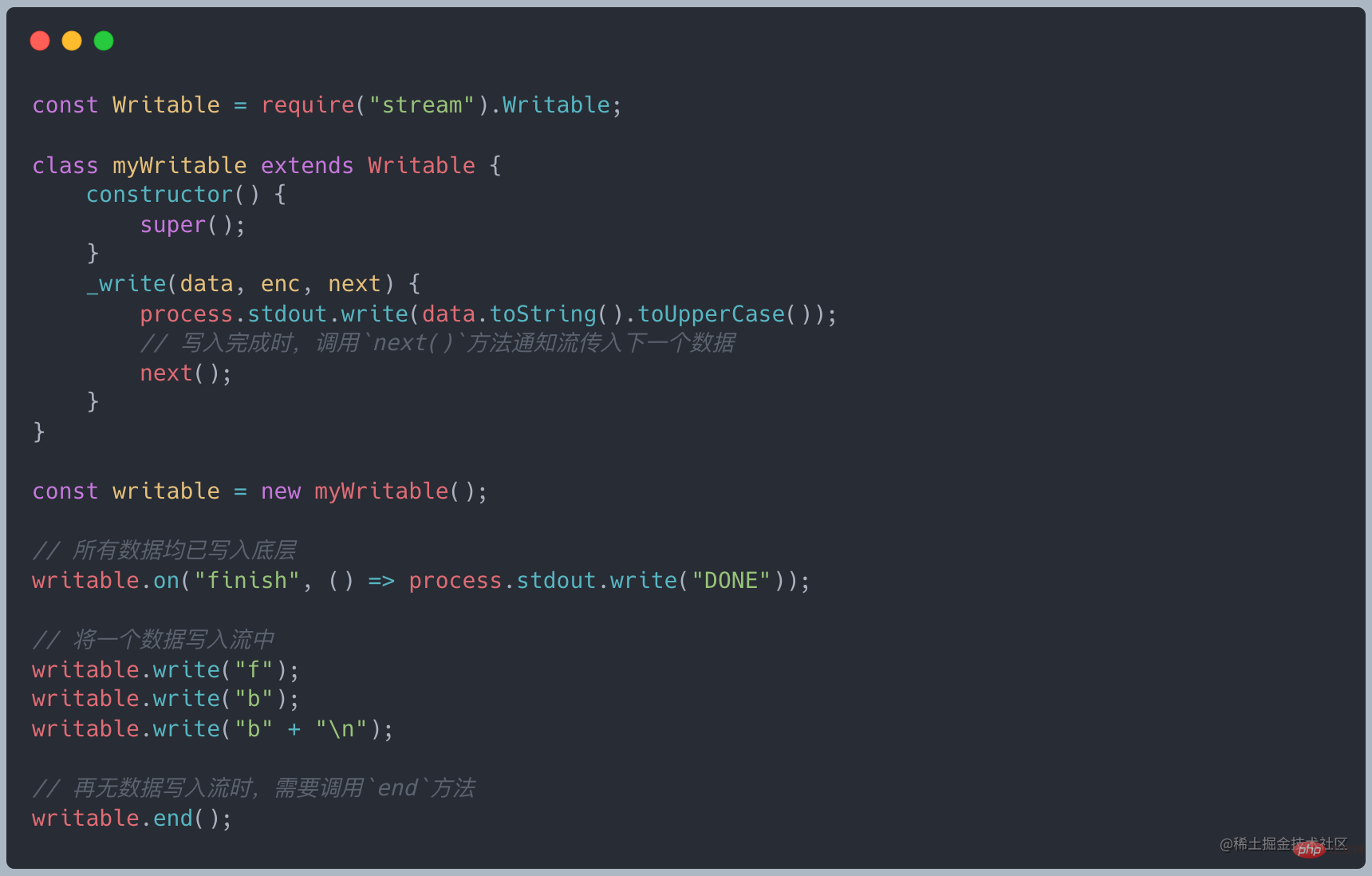
Tous les Writeables implémentent l'interface définie par le flux.Classe inscriptible
Il vous suffit d'implémenter la méthode _write pour écrire des données dans la couche inférieure
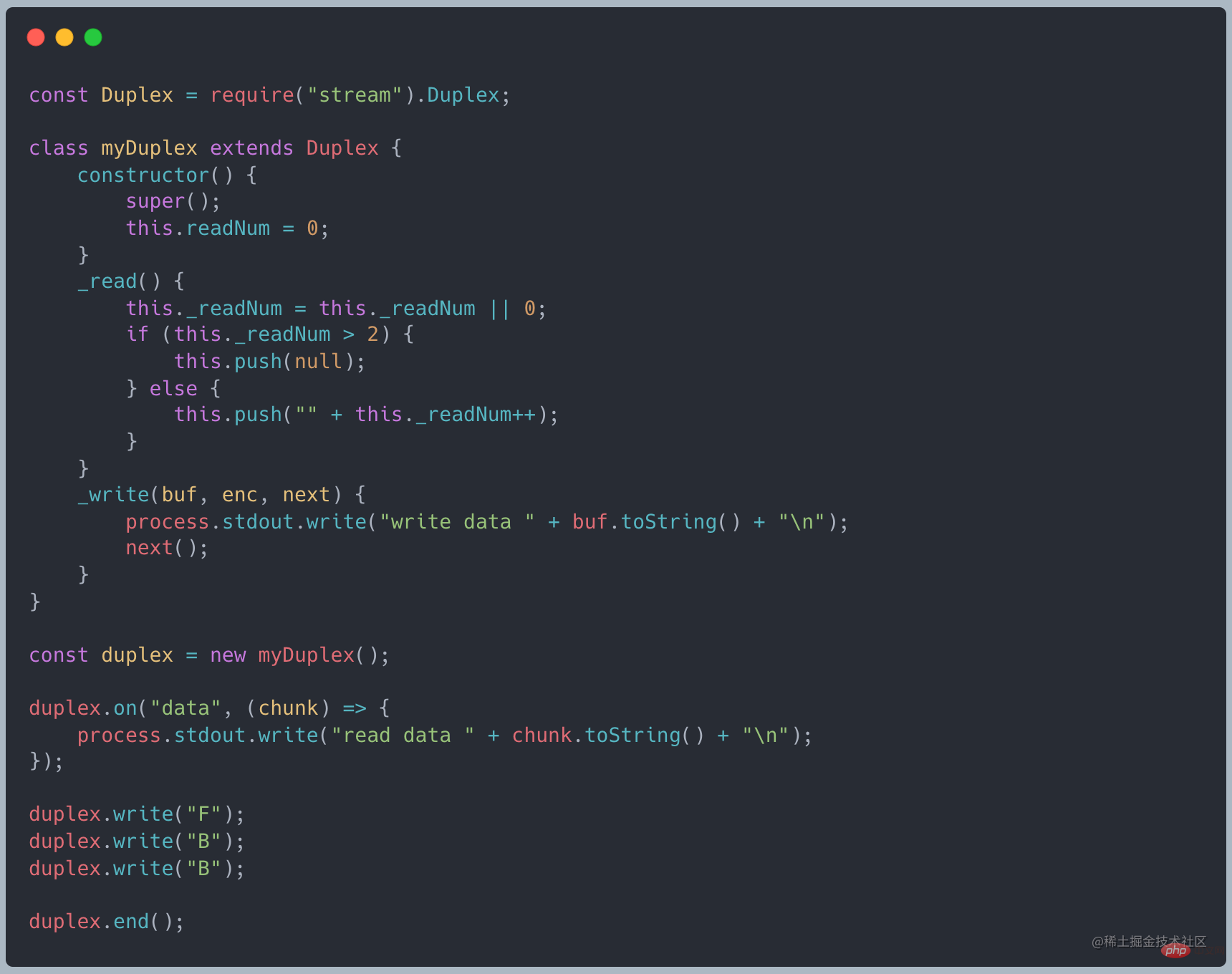
net peut être utilisé pour créer un socket. Le socket est un Duplex typique dans NodeJS. Regardez un exemple de client TCP
Le flux inscriptible est utilisé pour envoyer des messages. Le flux de lecture est utilisé pour recevoir les messages du serveur. Il n'y a pas de relation directe entre les données des deux flux
 Transform Stream
Transform Stream
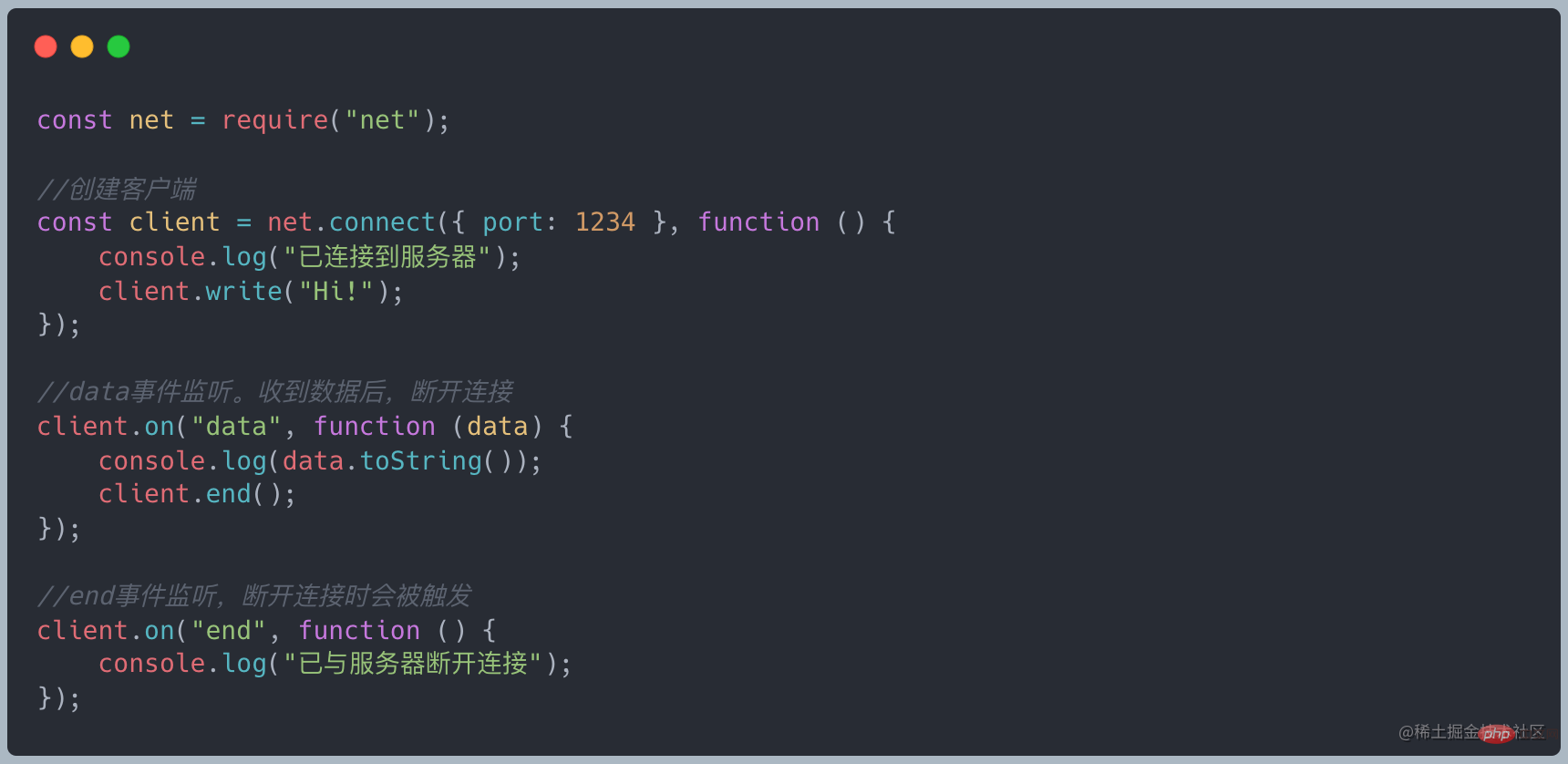 Transform hérite de Duplex et a déjà implémenté les méthodes _write et _read Il vous suffit d'implémenter la méthode _tranform
Transform hérite de Duplex et a déjà implémenté les méthodes _write et _read Il vous suffit d'implémenter la méthode _tranform
gulp est un outil de construction automatisé basé sur Stream. Jetez un œil à un exemple de code du site officiel. site Web
less → less converti en CSS → effectuer une compression CSS → CSS compressé
En fait, less() et minifyCss() effectuent tous deux un traitement sur les données d'entrée, puis transmettent les données de sortie
Options duplex et transformation
Par rapport à l'exemple ci-dessus, nous constatons que lorsqu'un flux dessert à la fois les producteurs et les consommateurs, nous choisirons Duplex Lorsque nous effectuons simplement un travail de conversion sur les données, nous choisirons d'utiliser Transform
Problème de contre-pression
.Qu'est-ce que la contre-pression
Le problème de la contre-pression vient du modèle producteur-consommateur, où la vitesse de traitement du consommateur est trop lente
Par exemple, lors de notre processus de téléchargement, la vitesse de traitement est de 3 Mo/s, tandis que lors de la compression processus, la vitesse de traitement est trop lente. Dans ce cas, la file d'attente du tampon va bientôt s'accumuler, soit la consommation de mémoire de l'ensemble du processus augmentera, soit l'ensemble du tampon sera lent et certaines données seront. perdu. Qu'est-ce que le traitement de contre-pression ?
Le traitement de contre-pression peut être compris comme un processus de « pleurer » vers le haut
Lorsque le processus de compression constate que la compression des données de sa mémoire tampon dépasse le seuil, il « pleure » vers le traitement de téléchargement. trop occupé. Veuillez ne plus publier. 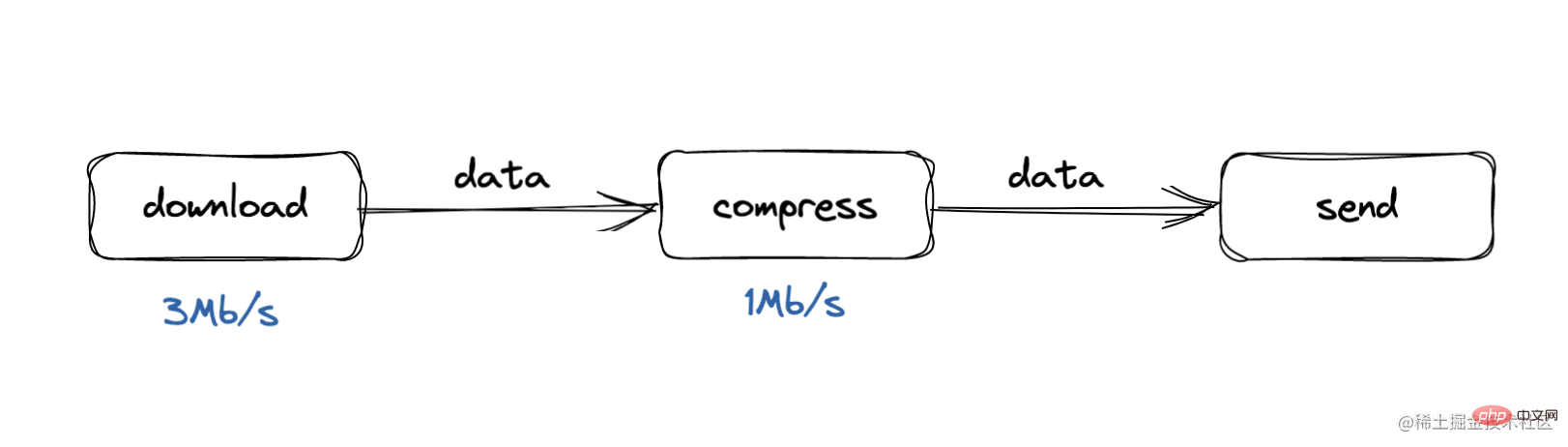
Comment gérer la contre-pression
Nous avons différentes fonctions pour transférer des données d'un processus à un autre. Dans Node.js, il existe une fonction intégrée appelée .pipe(), et en fin de compte, à un niveau de base dans ce processus, nous avons deux composants indépendants : la source des données et le consommateur
Quand .pipe() est appelé par la source, il informe le consommateur qu'il y a des données à transférer. La fonction pipeline établit un package de backlog approprié pour le déclenchement d'événements
Lorsque false est renvoyé, le système de backlog intervient. Il mettra en pause les Readables entrants de tout flux de données qui envoie des données. Une fois le flux de données effacé, l'événement de drainage sera déclenché et le flux de données entrant sera consommé. Une fois la file d'attente entièrement traitée, le mécanisme de backlog permettra aux données d'être renvoyées. L'espace mémoire utilisé se libérera et se préparera à recevoir le prochain lot de données
Nous pouvons voir le traitement de la contre-pression du tuyau :
Divisez les données en fonction des morceaux et écrivez Quand le morceau passe Lorsque la file d'attente est trop grande ou que la file d'attente est occupée, la lecture est suspendueLorsque la file d'attente est vide, continuez à lire les données
tutoriel Nodejs
!Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Vue : une combinaison parfaite d'outils de développement front-end
Mar 16, 2024 pm 12:09 PM
PHP et Vue : une combinaison parfaite d'outils de développement front-end
Mar 16, 2024 pm 12:09 PM
PHP et Vue : une combinaison parfaite d'outils de développement front-end À l'ère actuelle de développement rapide d'Internet, le développement front-end est devenu de plus en plus important. Alors que les utilisateurs ont des exigences de plus en plus élevées en matière d’expérience des sites Web et des applications, les développeurs front-end doivent utiliser des outils plus efficaces et plus flexibles pour créer des interfaces réactives et interactives. En tant que deux technologies importantes dans le domaine du développement front-end, PHP et Vue.js peuvent être considérés comme une arme parfaite lorsqu'ils sont associés. Cet article explorera la combinaison de PHP et Vue, ainsi que des exemples de code détaillés pour aider les lecteurs à mieux comprendre et appliquer ces deux éléments.
 Comment utiliser le langage Go pour le développement front-end ?
Jun 10, 2023 pm 05:00 PM
Comment utiliser le langage Go pour le développement front-end ?
Jun 10, 2023 pm 05:00 PM
Avec le développement de la technologie Internet, le développement front-end est devenu de plus en plus important. La popularité des appareils mobiles, en particulier, nécessite une technologie de développement frontal efficace, stable, sûre et facile à entretenir. En tant que langage de programmation en développement rapide, le langage Go est utilisé par de plus en plus de développeurs. Alors, est-il possible d’utiliser le langage Go pour le développement front-end ? Ensuite, cet article expliquera en détail comment utiliser le langage Go pour le développement front-end. Voyons d’abord pourquoi le langage Go est utilisé pour le développement front-end. Beaucoup de gens pensent que le langage Go est un
 Questions fréquemment posées par les enquêteurs front-end
Mar 19, 2024 pm 02:24 PM
Questions fréquemment posées par les enquêteurs front-end
Mar 19, 2024 pm 02:24 PM
Lors des entretiens de développement front-end, les questions courantes couvrent un large éventail de sujets, notamment les bases HTML/CSS, les bases JavaScript, les frameworks et les bibliothèques, l'expérience du projet, les algorithmes et les structures de données, l'optimisation des performances, les requêtes inter-domaines, l'ingénierie front-end, les modèles de conception et les nouvelles technologies et tendances. Les questions de l'intervieweur sont conçues pour évaluer les compétences techniques du candidat, son expérience en matière de projet et sa compréhension des tendances du secteur. Par conséquent, les candidats doivent être parfaitement préparés dans ces domaines pour démontrer leurs capacités et leur expertise.
 Django est-il front-end ou back-end ? Vérifiez-le!
Jan 19, 2024 am 08:37 AM
Django est-il front-end ou back-end ? Vérifiez-le!
Jan 19, 2024 am 08:37 AM
Django est un framework d'application Web écrit en Python qui met l'accent sur un développement rapide et des méthodes propres. Bien que Django soit un framework Web, pour répondre à la question de savoir si Django est un front-end ou un back-end, vous devez avoir une compréhension approfondie des concepts de front-end et de back-end. Le front-end fait référence à l'interface avec laquelle les utilisateurs interagissent directement, et le back-end fait référence aux programmes côté serveur. Ils interagissent avec les données via le protocole HTTP. Lorsque le front-end et le back-end sont séparés, les programmes front-end et back-end peuvent être développés indépendamment pour mettre en œuvre respectivement la logique métier et les effets interactifs, ainsi que l'échange de données.
 Golang peut-il être utilisé comme frontal ?
Jun 06, 2023 am 09:19 AM
Golang peut-il être utilisé comme frontal ?
Jun 06, 2023 am 09:19 AM
Golang peut être utilisé comme frontal. Golang est un langage de programmation très polyvalent qui peut être utilisé pour développer différents types d'applications, y compris des applications frontales. En utilisant Golang pour écrire le front-end, vous pouvez vous débarrasser d'un front-end. série de problèmes causés par des langages tels que JavaScript. Par exemple, des problèmes tels qu'une mauvaise sécurité des types, de faibles performances et un code difficile à maintenir.
 Partage d'expérience en développement C# : compétences en développement collaboratif front-end et back-end
Nov 23, 2023 am 10:13 AM
Partage d'expérience en développement C# : compétences en développement collaboratif front-end et back-end
Nov 23, 2023 am 10:13 AM
En tant que développeur C#, notre travail de développement comprend généralement le développement front-end et back-end. À mesure que la technologie se développe et que la complexité des projets augmente, le développement collaboratif du front-end et du back-end est devenu de plus en plus important et complexe. Cet article partagera quelques techniques de développement collaboratif front-end et back-end pour aider les développeurs C# à effectuer leur travail de développement plus efficacement. Après avoir déterminé les spécifications de l’interface, le développement collaboratif du front-end et du back-end est indissociable de l’interaction des interfaces API. Pour assurer le bon déroulement du développement collaboratif front-end et back-end, le plus important est de définir de bonnes spécifications d’interface. La spécification de l'interface implique le nom de l'interface
 Explorer la technologie front-end du langage Go : une nouvelle vision du développement front-end
Mar 28, 2024 pm 01:06 PM
Explorer la technologie front-end du langage Go : une nouvelle vision du développement front-end
Mar 28, 2024 pm 01:06 PM
En tant que langage de programmation rapide et efficace, le langage Go est très populaire dans le domaine du développement back-end. Cependant, peu de gens associent le langage Go au développement front-end. En fait, l’utilisation du langage Go pour le développement front-end peut non seulement améliorer l’efficacité, mais également ouvrir de nouveaux horizons aux développeurs. Cet article explorera la possibilité d'utiliser le langage Go pour le développement front-end et fournira des exemples de code spécifiques pour aider les lecteurs à mieux comprendre ce domaine. Dans le développement front-end traditionnel, JavaScript, HTML et CSS sont souvent utilisés pour créer des interfaces utilisateur.
 Comment implémenter la messagerie instantanée sur le front-end
Oct 09, 2023 pm 02:47 PM
Comment implémenter la messagerie instantanée sur le front-end
Oct 09, 2023 pm 02:47 PM
Les méthodes de mise en œuvre de la messagerie instantanée incluent WebSocket, Long Polling, Server-Sent Events, WebRTC, etc. Introduction détaillée : 1. WebSocket, qui peut établir une connexion persistante entre le client et le serveur pour obtenir une communication bidirectionnelle en temps réel. Le frontal peut utiliser l'API WebSocket pour créer une connexion WebSocket et obtenir une messagerie instantanée en envoyant et en recevant. messages 2. Long Polling, une technologie qui simule la communication en temps réel, etc.
