

Comment compresser un stockage de texte volumineux dans MySQL


Comme mentionné précédemment, le contenu de l'instantané de notre projet de document cloud est stocké directement dans la base de données, qui est un grand stockage de texte. La plupart des champs de contenu de l'instantané du document sont au niveau du Ko, et certains sont même au niveau du Ko. Niveau Mo. À l'heure actuelle, l'optimisation de la mise en cache CDN a été effectuée pour la lecture des données (outil de mise en cache des ressources statiques - CDN) L'écriture et le stockage des données doivent encore être optimisés. Si certains algorithmes de compression peuvent être utilisés pour compresser et stocker du texte volumineux, vous pouvez le faire. Économisez considérablement l'espace de stockage de la base de données et soulagez la pression des E/S de la base de données.
Analyse des données d'inventaire
select
table_name as '表名',
table_rows as '记录数',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)',
truncate(DATA_FREE/1024/1024, 2) as '碎片占用(MB)'
from
information_schema.tables
where
table_schema=${数据库名}
order by
data_length desc, index_length desc;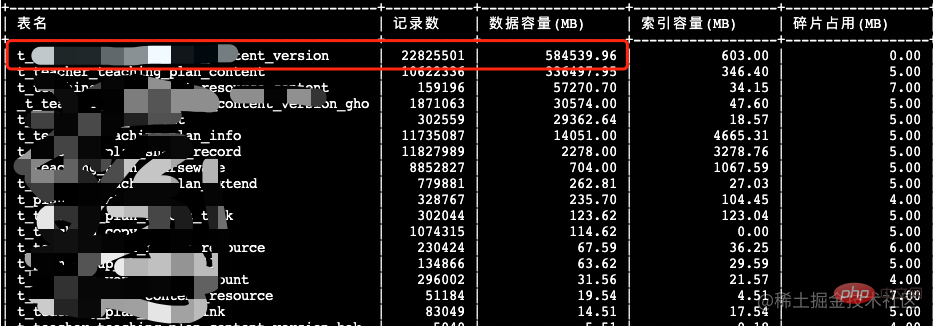

Introduction au contenu associé
Que dois-je faire si les données de la page du moteur innodb dépassent 16 Ko ?
Nous savons tous que la taille de bloc de page par défaut d'innodb est de 16 Ko. Si la longueur des données d'une ligne dans le tableau dépasse 16 Ko, un débordement de ligne se produira et la ligne débordée est stockée à un autre endroit (décompression de la page blob). Étant donné qu'Innodb utilise un index clusterisé pour stocker les données, c'est-à-dire une structure B+Tree, il y a au moins deux lignes de données dans chaque bloc de page, sinon la signification de B+Tree sera perdue, donc la limite de longueur maximale d'une ligne de les données obtenues sont de 8 Ko (le grand champ stockera 768 octets de données dans la page de données, et les données restantes déborderont vers une autre page. La page de données dispose également de 20 octets pour enregistrer l'adresse de la page de débordement)
- Pour format dynamique, si Si la taille des données stockées dans le champ d'objet volumineux (texte/blob) est inférieure à 40 octets, la totalité est placée sur la page de données. Dans les scénarios restants, la page de données ne conserve qu'un pointeur de 20 octets. pointant vers la page de débordement. Dans ce scénario, si les données stockées dans chaque champ d'objet volumineux font moins de 40 octets, cela aura le même effet que varchar(40).
- innodb-row-format-dynamic : dev.mysql.com/doc/refman/…
Linux Sparse Files & Holes
- Sparse File : les fichiers fragmentés sont fondamentalement les mêmes que les autres fichiers ordinaires. La différence. c'est que certaines données du fichier sont toutes à 0, et cette partie des données n'occupe pas d'espace disque
- Trous de fichiers : le déplacement du fichier peut être supérieur à la longueur réelle du fichier (les octets qui sont dans le fichier mais n'ont pas été écrits sont définis sur 0), le fait que le trou occupe l'espace disque est déterminé par le système d'exploitation

La partie trou du fichier n'occupe pas d'espace disque et l'espace disque occupé par le fichier est toujours continu
Le schéma de compression fourni par innodb
Compression de page
est applicable Scénario : en raison de la grande quantité de données et de l'espace disque insuffisant, la charge se reflète principalement dans les E/S et le processeur du serveur a une marge relativement importante .
1) Compression de page COMPRESS
Documents associés : dev.mysql.com/doc/refman/…
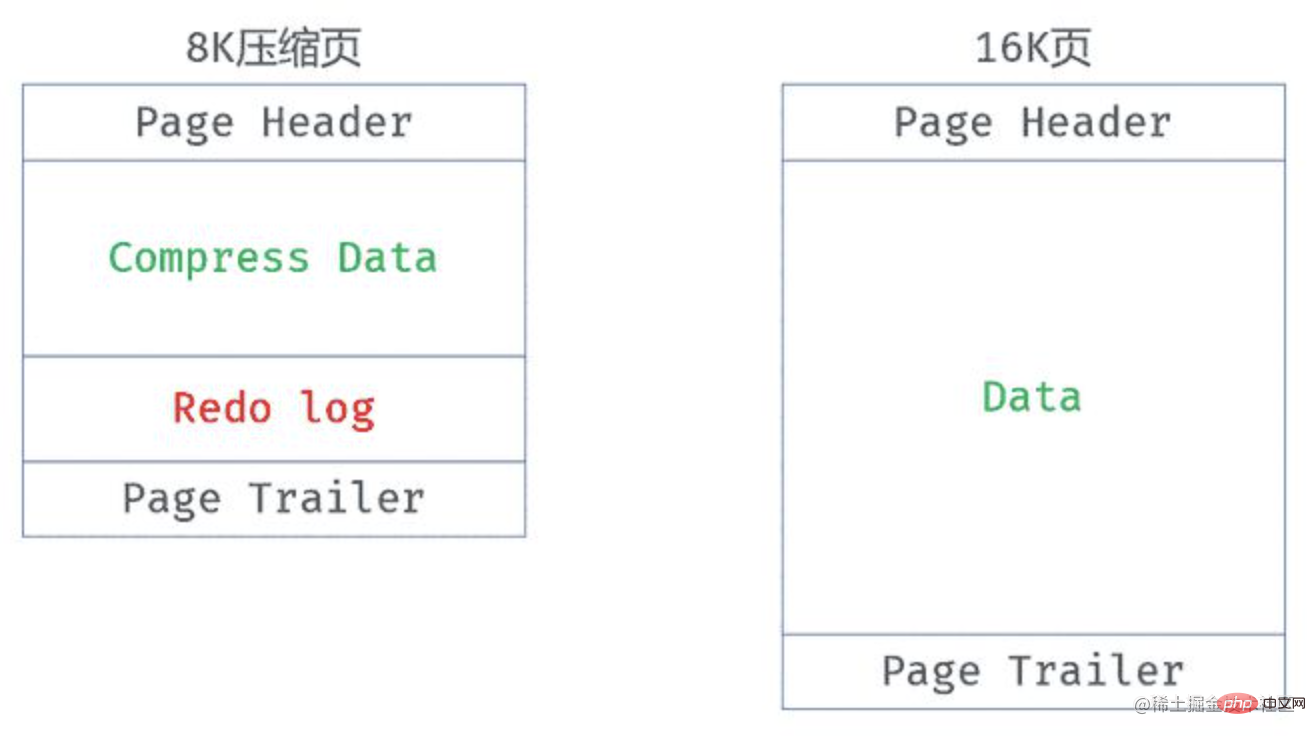
- La fonction de compression de page fournie avant MySQL version 5.7, spécifiez ROW_FORMAT = COMPRESS lors de la création de la table et définissez la taille de la page compressée via KEY_BLOCK_SIZE
- Il existe des défauts de conception qui peuvent entraîner une dégradation significative des performances, puis d'autres L'original l'intention de la conception est d'améliorer les performances, et le concept de "log is data" est introduit
- Pour la modification des données de la page compressée, la page elle-même ne sera pas modifiée directement, mais le journal des modifications sera stocké dans cette page , qui change effectivement les données. Il est plus convivial et n'a pas besoin d'être compressé/décompressé à chaque fois qu'il est modifié
- Pour la lecture des données, les données compressées ne peuvent pas être lues directement, donc cet algorithme conservera un fichier décompressé. 16 Ko dans la page mémoire pour la lecture des données
- Cela entraîne une page qui peut avoir deux versions (version compressée et version non compressée) dans le pool de tampons, provoquant un problème très grave, c'est-à-dire le pool de tampons. le nombre de pages pouvant être mises en cache est considérablement réduit, ce qui peut entraîner une forte diminution des performances de la base de données
- Pour la modification des données de la page compressée, la page elle-même ne sera pas modifiée directement, mais le journal des modifications sera stocké dans cette page , qui change effectivement les données. Il est plus convivial et n'a pas besoin d'être compressé/décompressé à chaque fois qu'il est modifié

2) TPC (Transparent Page Compression)
Documents associés : dev.mysql.com/doc/ refman/…
- Principe de fonctionnement : lors de l'écriture d'une page, utilisez l'algorithme de compression spécifié pour compresser la page et écrivez-la sur le disque après compression, dans lequel l'espace vide est libéré à partir de la fin de la page via le mécanisme de perforation ( le système d'exploitation doit prendre en charge les
trousFonctionnalité)空洞特性) ALTER TABLE xxx COMPRESSION = ZLIB可以启用TPC页压缩功能,但这只是对后续增量数据进行压缩,如果期望对整个表进行压缩,则需要执行OPTIMIZE TABLE xxx实现过程:一个压缩页在缓冲池中都是一个16K的非压缩页,只有在数据刷盘的时候,会进行一次压缩,压缩后剩余的空间会用 0x00 填满,利用文件系统的空洞特性(hole punch)对文件进行裁剪,释放 0x00 占用的稀疏空间
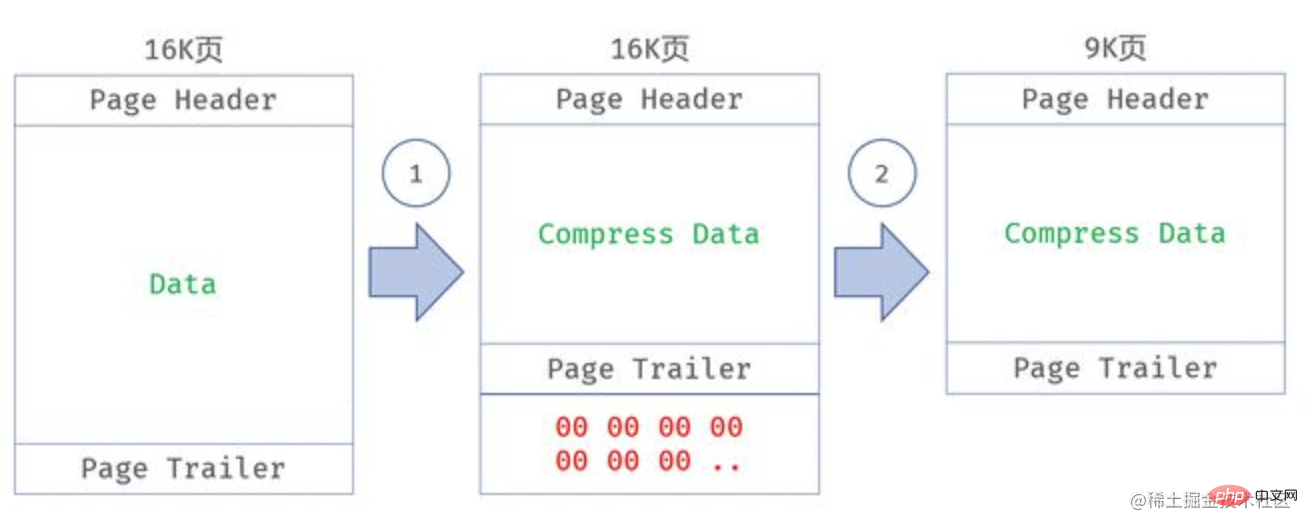
- TPC虽好,但它依赖操作系统的 Hole Punch 特性,且裁剪后的文件大小需要和文件系统块大小对齐(4K)。即假如压缩后的页大小是9K,那么实际占用的空间是12K
列压缩
MySQL目前没有直接针对列压缩的方案,有一个曲线救国的方法,就是在业务层使用MySQL提供的压缩和解压函数来针对列进行压缩和解压操作。也就是如果需要对某一列做压缩,在写入时调用COMPRESS函数对那个列的内容进行压缩,读取的时候,使用UNCOMPRESS函数对压缩过的数据进行解压。
- 使用场景:针对表中某些列数据长度比较大的情况,一般是 varchar、text、blob、json等数据类型
- 相关函数:
- 压缩函数:
COMPRESS() - 解压缩函数:
UNCOMPRESS() - 字符串长度函数:
LENGTH() - 未解压字符串长度函数:
UNCOMPRESSED_LENGTH()
- 压缩函数:
- 测试:
- 插入数据:
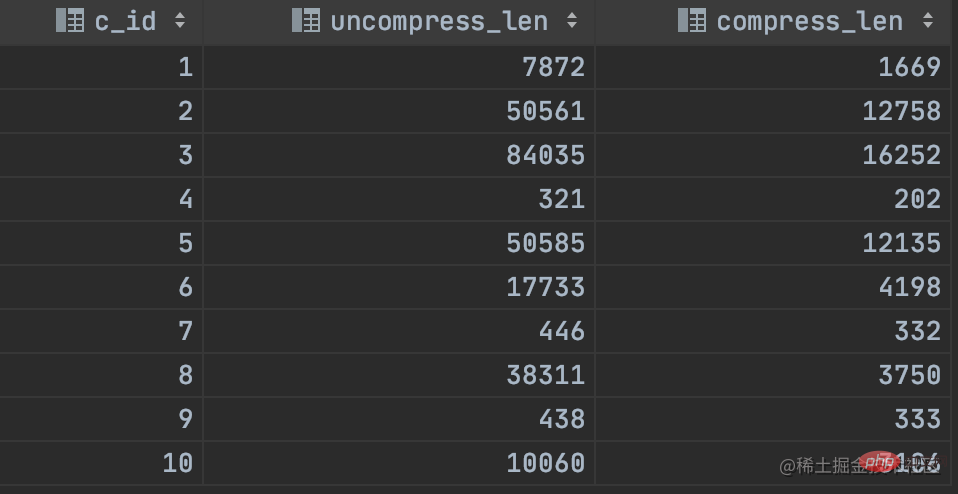
insert into xxx (content) values (compress('xxx....')) 读取压缩的数据:
select c_id, uncompressed_length(c_content) uncompress_len, length(c_content) compress_len from xxx
- 插入数据:
ALTER TABLE xxx COMPRESSION = ZLIB Vous pouvez activer la fonction de compression de page TPC, mais cela ne compresse que les données incrémentielles suivantes si vous le faites. Si vous prévoyez compresser la table entière, vous devez exécuter OPTIMIZE TABLE xxx
 🎜🎜🎜TPC est bon, mais il repose sur le La fonction Hole Punch du système d'exploitation et la taille du fichier recadré doivent être alignées sur la taille de bloc du système de fichiers (4K). Autrement dit, si la taille de la page compressée est de 9 Ko, alors l'espace réel occupé est de 12 Ko. 🎜🎜
🎜🎜🎜TPC est bon, mais il repose sur le La fonction Hole Punch du système d'exploitation et la taille du fichier recadré doivent être alignées sur la taille de bloc du système de fichiers (4K). Autrement dit, si la taille de la page compressée est de 9 Ko, alors l'espace réel occupé est de 12 Ko. 🎜🎜Compression de colonne
🎜MySQL n'a actuellement pas de solution directe pour la compression de colonne. Il y en a un. La façon de sauver le pays est d'utiliser les fonctions de compression et de décompression fournies par MySQL au niveau de la couche métier pour effectuer des opérations de compression et de décompression sur les colonnes. Autrement dit, si vous devez compresser une certaine colonne, appelez la fonctionCOMPRESS pour compresser le contenu de cette colonne lors de l'écriture et utilisez la fonction UNCOMPRESS pour compresser le contenu compressé. lors de la lecture. Les données sont décompressées. 🎜🎜🎜Scénario d'utilisation : pour la situation où la longueur des données de certaines colonnes du tableau est relativement grande, généralement varchar, text, blob, json et d'autres types de données🎜🎜Fonctions associées : 🎜🎜Fonction de compression : COMPRESS( )</code >🎜🎜Fonction de décompression : <code>UNCOMPRESS()🎜🎜Fonction de longueur de chaîne : LENGTH()🎜🎜Fonction de longueur de chaîne non compressée : UNCOMPRESSED_LENGTH()< /code>🎜🎜🎜🎜Test : 🎜🎜Insérer des données : <code>insérer dans les valeurs xxx (contenu) (compress('xxx....'))🎜🎜🎜Lire les données compressées : < code>sélectionnez c_id, uncompressed_length(c_content) uncompress_len, length(c_content) compress_len de xxx🎜🎜🎜🎜🎜🎜为什么innodb提供的都是基于页面的压缩技术?
- 记录压缩:每次读写记录的时候,都要进行压缩或解压,过度依赖CPU的计算能力,性能相对会比较差
- 表空间压缩:压缩效率高,但要求表空间文件是静态不增长的,这对于我们大部分的场景都是不适用的
- 页面压缩:既能提升效率,又能在性能中取得一定的平衡
总结
- 对于一些性能不敏感的业务表,如日志表、监控表、告警表等,这些表只期望对存储空间进行优化,对性能的影响不是很关注,可以使用COMPRESS页压缩
- 对于一些比较核心的表,则比较推荐使用TPC压缩
- 列压缩过度依赖CPU,性能方面会稍差,且对业务有一定的改造成本,不够灵活,需要评估影响范围,做好切换的方案。好处是可以由业务端决定哪些数据需要压缩,并控制解压操作
- 对页面进行压缩,在业务侧不用进行什么改动,对线上完全透明,压缩方案也非常成熟
为什么要进行数据压缩?
- 由于处理器和高速缓存存储器的速度提高超过了磁盘存储设备,因此很多时候工作负载都是受限于磁盘I/O。数据压缩可以使数据占用更小的空间,可以节省磁盘I/O、减少网络I/O从而提高吞吐量,虽然会牺牲部分CPU资源作为代价
- 对于OLTP系统,经常进行update、delete、insert等操作,通过压缩表能够减少存储占用和IO消耗
- 压缩其实是一种平衡,并不一定是为了提升数据库的性能,这种平衡取决于解压缩带来的收益和开销之间的一种权衡,但压缩对存储空间来说,收益无疑是很大的
简单测试
innodb透明页压缩(TPC)
测试数据
1)创建表
- create table table_origin ( ...... ) comment '测试原表';
- create table table_compression_zlib ( ...... ) comment '测试压缩表_zlib' compression = 'zlib';
- create table table_compression_lz4 ( ...... ) comment '测试压缩表_lz4' compression = 'lz4';
2)往表中写入10w行测试数据
压缩率
SELECT NAME, FS_BLOCK_SIZE, FILE_SIZE, ALLOCATED_SIZE FROM information_schema.INNODB_TABLESPACES WHERE NAME like 'test_compress%';
-
FS_BLOCK_SIZE:文件系统块大小,也就是打孔使用的单位大小 -
FILE_SIZE:文件的表观大小,表示文件的最大大小,未压缩 -
ALLOCATED_SIZE:文件的实际大小,即磁盘上分配的空间量
压缩率:
- zlib:1320636416/3489660928 = 37.8%
- lz4:1566949376/3489660928 = 45%
耗时
- 循环插入10w条记录
- 原表:918275 ms
- zlib:878540 ms
- lz4:875259 ms
- 循环查询10w条记录
- 原表:332519 ms
- zlib:373387 ms
- lz4:343501 ms
【相关推荐:mysql视频教程】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
