

Cet article analyse principalement du point de vue de la structure de stockage de données InnoDB, dans quelles circonstances l'efficacité des requêtes SQL sera réduite. Je vois souvent des articles s'en plaindre sur Internet. Lorsque la quantité de données est importante, l'efficacité des requêtes sera considérablement réduite. Lorsqu'il existe de nombreuses tables liées, l'efficacité des requêtes diminue. La quantité de données dans une seule table ne doit pas dépasser un million, etc.

Version de la base de données : 8.0 Moteur : InnoDB Matériel de référence : livret Nuggets "Comprendre Mysql depuis les racines". Si vous avez le temps, je vous suggère de le lire vous-même.
Exemple de tableau :
CREATE TABLE `hospital_info` ( `pk_id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `id` varchar(36) NOT NULL COMMENT '外键', `hospital_code` varchar(36) NOT NULL COMMENT '医院编码', `hospital_name` varchar(36) NOT NULL COMMENT '医院名称', `is_deleted` tinyint DEFAULT NULL COMMENT '是否删除 0否 1是', `gmt_created` datetime DEFAULT NULL COMMENT '创建时间', `gmt_modified` datetime DEFAULT NULL COMMENT 'gmt_modified', `gmt_deleted` datetime(3) DEFAULT '9999-12-31 23:59:59.000' COMMENT '删除时间', PRIMARY KEY (`pk_id`), KEY `hospital_code` (`hospital_code`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='医院信息';
En partant d'une ligne de données, comprenons d'abord le format de stockage d'une seule ligne de données.
Il existe actuellement 4 formats de lignes, à savoir Compact, Redundant, Dynamic et Compressedrow format.
Il n'est généralement pas nécessaire de le spécifier délibérément lors de la création d'une table. Les versions 5.7 et supérieures seront par défaut Dynamic.
Chaque format de ligne est similaire. Ici, nous prenons Compact comme exemple pour comprendre brièvement comment chaque ligne de données est enregistrée. 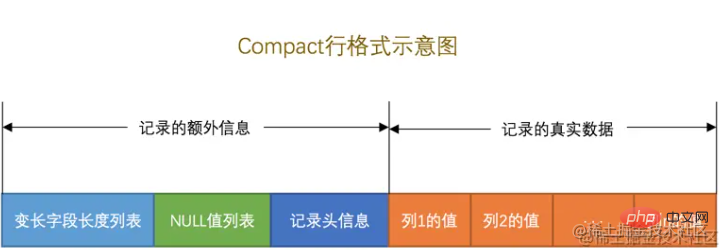
Comme le montre l'image ci-dessus. Divisé en deux parties : « Informations complémentaires » et « Données réelles ».
C'est plus intéressant Généralement, lors de la définition d'un champ, vous devez spécifier le type et la longueur du champ,
Par exemple : hospital_codedéfinition du champVARCHAR. (36). En utilisation réelle, la longueur du champ hospital_code n'utilise que 32 bits.
Que va-t-il se passer avec les 4 personnages restants ? Si vous remplissez de force des caractères vides, ne serait-ce pas une perte de 4 caractères de mémoire. S'il n'est pas renseigné, comment déterminer combien de caractères sont enregistrés dans le champ courant ? Combien de mémoire cela prend-il ?
À ce stade, la liste des champs de longueur variable sera triée par champ dans l'ordre inverse, en utilisant 1 à 2 octets pour enregistrer la longueur réelle de chaque champ de longueur variable. Cela peut utiliser efficacement l'espace mémoire.
Champs similaires : VARBINARY, divers types TEXT, divers types BLOB.
En conséquence, il existe également des "champs de longueur fixe", tels que : CHAR(10) Ce type de champ occupera par défaut l'espace de la longueur de caractère spécifiée lors de l'initialisation. être rempli de caractères vides, donc l'espace est relativement inutile et il est généralement recommandé de définir la longueur selon les besoins.
Bien sûr, la "liste de champs de longueur variable" n'existe pas forcément. Si le type de champ défini n'a pas de "champ de longueur variable", il n'existera pas.
Extension : Pour les champs de type TEXTE ou BLOB, la longueur ne pourra pas être enregistrée sur une page. Dans ce cas, la plupart des données seront enregistrées dans d'autres pages, et l'adresse de la page de données suivante sera conservée. dans le dossier actuel.
Lors de la sauvegarde réelle des données, certaines colonnes peuvent stocker des valeurs NULL Si ces valeurs sont enregistrées dans des données réelles, l'espace de stockage sera gaspillé. Au format Compact, ces colonnes avec des valeurs NULL sont gérées de manière uniforme et stockées dans une liste de valeurs NULL.
Si aucun champ dans une ligne de données n'est NULL, cette colonne ne sera pas générée.
La méthode de stockage est également assez intéressante, elle est binaire enregistrée dans l'ordre inverse.
En utilisant un exemple de tableau à analyser, il y a trois champs dans le tableau : is_deleted, gmt_created, gmt_modified, qui peuvent être vides. En supposant que gmt_created et gmt_modified soient vides dans un enregistrement, la liste de valeurs NULL correspondante devrait ressembler à ce qui suit.
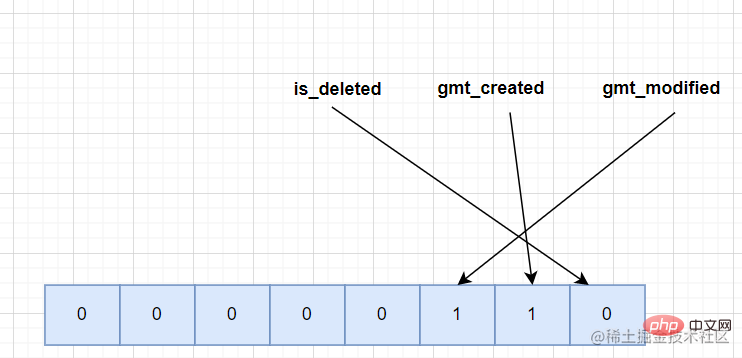
Agrandir : Mysql prend en charge le stockage de données binaires et une utilisation complète peut réduire une grande quantité d'espace de stockage.
Les informations d'en-tête d'enregistrement se composent de 5 caractères fixes, d'une longueur de 40 bits binaires.
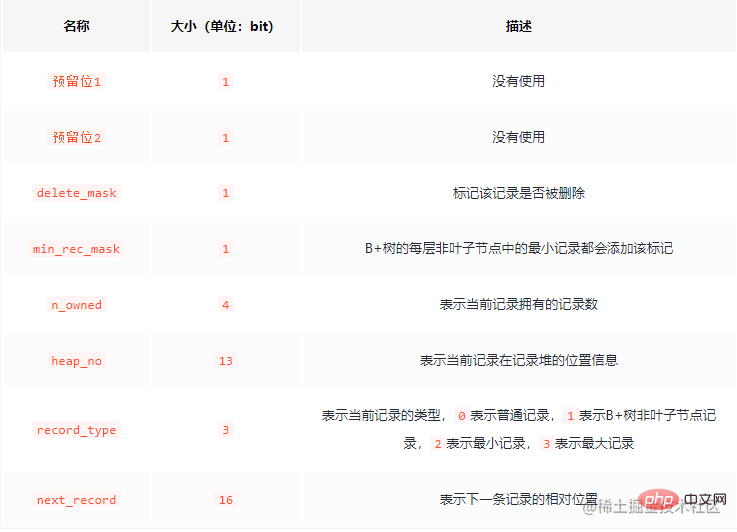
Tout d'abord, pour comprendre, voici un logo plus intéressant : delete_maskTous ceux qui ont utilisé Redis savent que les données supprimées dans Redis ne seront pas effacées immédiatement. La même chose est vraie dans le même MySQL. Les données ne seront pas nettoyées immédiatement car le processus de nettoyage déclenchera des opérations d'E/S, ce qui affectera grandement l'efficacité. Les données supprimées formeront une liste chaînée, qui pourra être utilisée comme espace réutilisable.
En fait, il n'y a rien à dire à ce sujet, il s'agit d'enregistrer des données réelles non NULL.
Il y a une question que l'on retrouve souvent sur Internet : Que se passera-t-il si la clé primaire n'est pas définie ?
Sous InnoDB, la clé primaire est l'identifiant unique d'un enregistrement. Si l'utilisateur ne le précise pas, mysql en sélectionnera une parmi la Clé unique (unique) comme clé primaire. il ajoutera une clé nommée row_idhide column comme clé primaire. De plus, les deux colonnes
transaction_id (ID de transaction)et roll_pointer (pointeur de restauration) seront ajoutées.
Résumé. De nombreux types de pages sont conçus selon différents objectifs, tels que : une page pour stocker les informations d'en-tête de l'espace table, une page pour stocker les informations Insert Buffer, une page pour stocker les informations INODE, une page pour stocker undo informations de journalisation, etc. L'espace de la page est divisé comme suit :
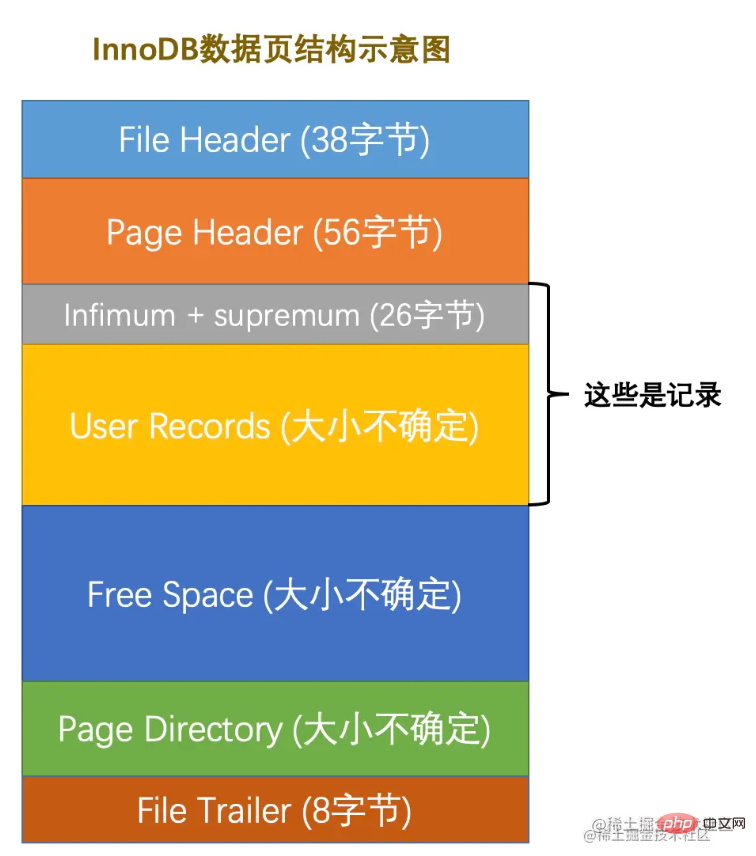 Il y a 7 composants au total. Décrivons grossièrement les 7 parties.
Il y a 7 composants au total. Décrivons grossièrement les 7 parties.
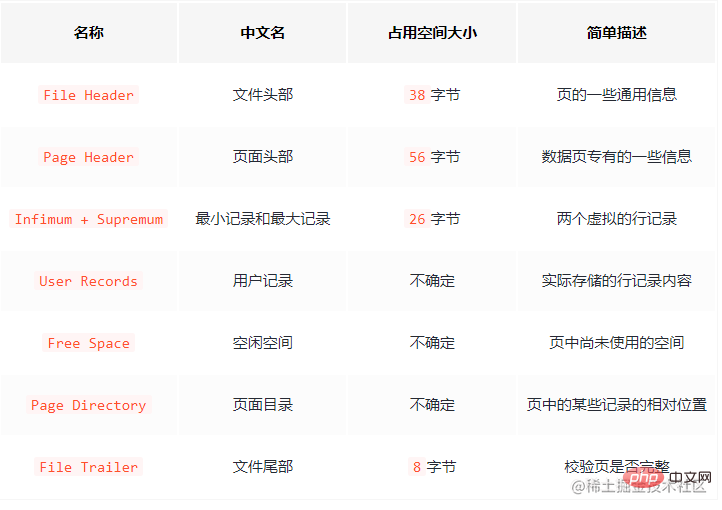 Il y a de nombreux attributs dans
Il y a de nombreux attributs dans
et En-tête de page Je ne les présenterai pas un par un ici tant que vous savez que ces deux endroits enregistrent certains attributs de page. : numéro de page, page précédente et Le numéro de page de la page suivante, le type de page, l'utilisation mémoire de la page, etc. Laissez-moi parler ici, les pages sont reliées par une double liste chaînée. L'enregistrement de données est un collier unique.
File Trailerest utilisé pour vérifier l'intégrité des données de la page lorsque les données de la page sont réécrites de la mémoire sur le disque, elles doivent être vérifiées pour éviter d'endommager la page de données. Concentrez-vous sur les
Enregistrements utilisateur (espace utilisé)et Espace libre (espace restant), voici les véritables enregistrements de données enregistrés. De plus,
Infimumet Supremum identifient respectivement le record minimum et le record maximum. Autrement dit, lorsqu'une page est générée, elle contiendra ces deux enregistrements par défaut, mais ne vous inquiétez pas, ces deux enregistrements ne sont utilisés que comme tête et queue de la liste chaînée de données et n'affectent pas les données réelles. Pour résumer, le stockage des enregistrements dans la page est le suivant :
En termes simples, il s'agit de laconversion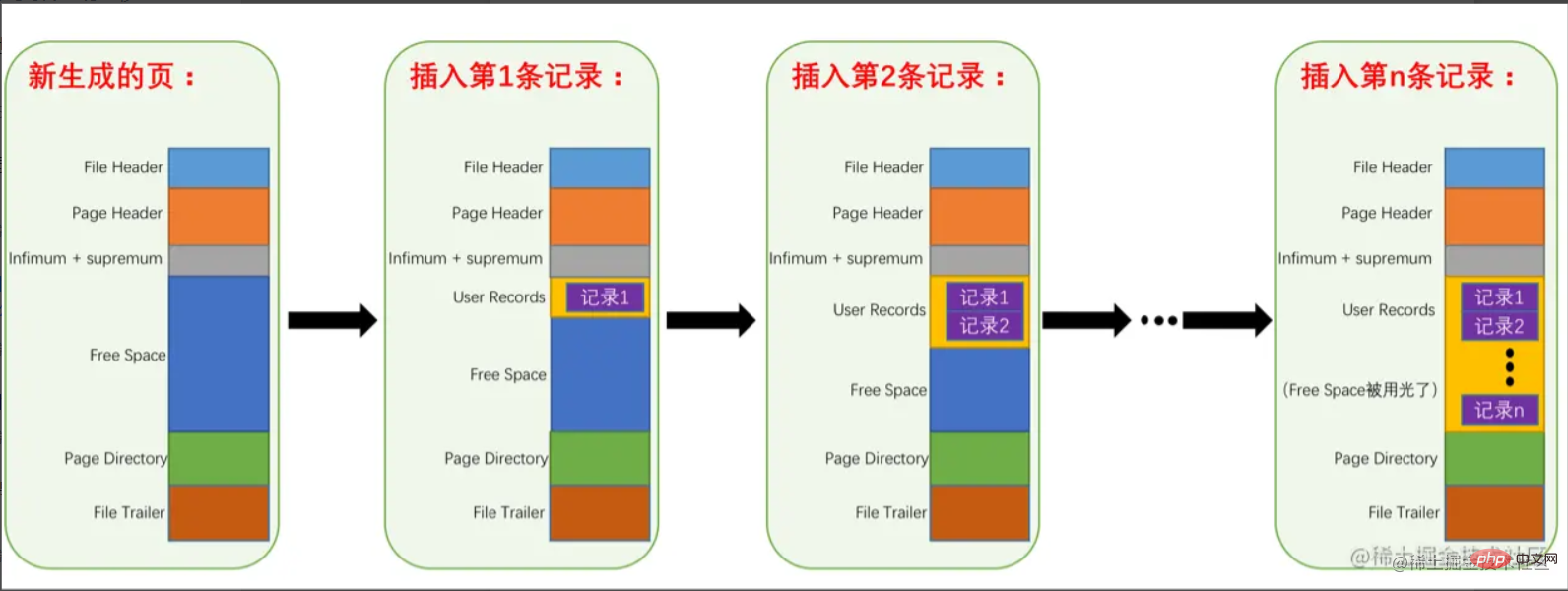 de l'espace libre en enregistrements utilisateur Lorsque l'espace libre est épuisé, la page de données est considérée comme étant. complet. À ce stade, les données ont été écrites dans la page de données. Comment le sortir ? Nous savons ci-dessus que l'enregistrement de données est composé d'une seule liste chaînée. Devons-nous partir de l'enregistrement
de l'espace libre en enregistrements utilisateur Lorsque l'espace libre est épuisé, la page de données est considérée comme étant. complet. À ce stade, les données ont été écrites dans la page de données. Comment le sortir ? Nous savons ci-dessus que l'enregistrement de données est composé d'une seule liste chaînée. Devons-nous partir de l'enregistrement
(minimum) et parcourir la liste chaînée ? Évidemment, le responsable du développement de MySQL ne peut pas être aussi stupide, sinon je peux le faire, haha.
Ici, nous devons mentionner
Page Directory(annuaire de pages). Dans la page, les données sont regroupées et le décalage d'adresse du dernier enregistrement de chaque groupe est extrait séparément et stocké dans l'ordre dans le "répertoire de pages" vers la fin de la page. Ces décalages d'adresses dans le répertoire de pages sont. appelé Il s'agit de "slot". De plus, le dernier en-tête d'enregistrement (n_owned) stocke également le nombre d'enregistrements qu'il y a dans le groupe. Le répertoire des pages est composé de slots. Le schéma de structure global est le suivant :
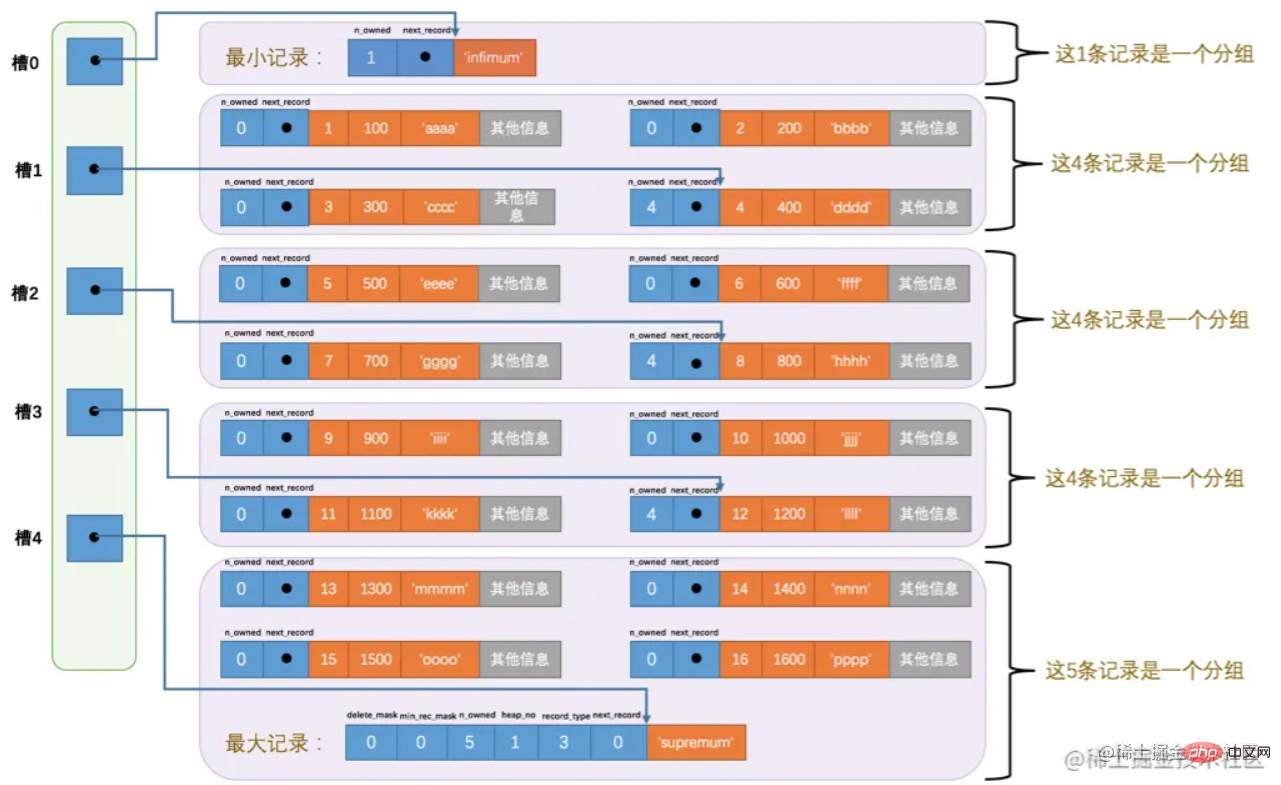 Une fois que vous avez l'annuaire, la requête est relativement simple. Vous pouvez utiliser la
Une fois que vous avez l'annuaire, la requête est relativement simple. Vous pouvez utiliser la
pour une recherche rapide. Dans la figure ci-dessus, nous savons que l'emplacement minimum est 0 et le maximum est 4. Par exemple : Supposons que vous souhaitiez interroger les données dont l'enregistrement de clé primaire est 6.
1) Calculez la position médiane de l'emplacement, qui est (0+4)/2 = 2. La clé primaire de l'enregistrement correspondant à l'emplacement extrait est 8, car 8>6.
2) De la même manière, définissez le plus grand emplacement sur 2, c'est-à-dire (0+2)/2 = 1. La clé primaire correspondant à l'emplacement 1 est 4. Parce que 4
Afin de faciliter la description ultérieure, le formulaire de données de la page est simplifié comme le montre la figure ci-dessous.
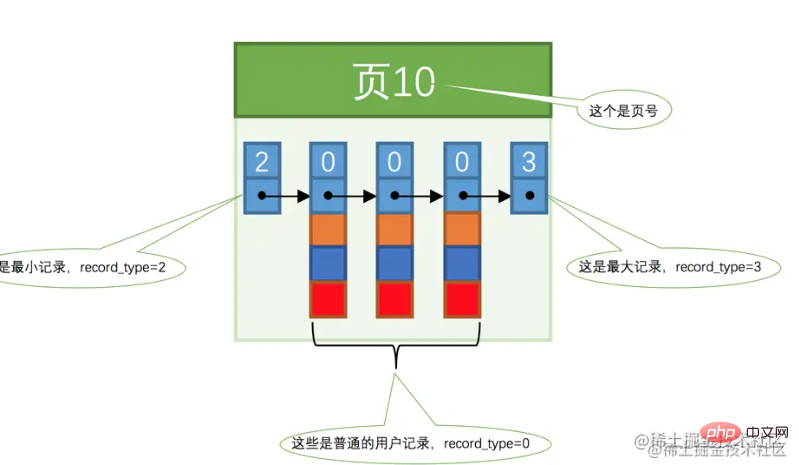
les numéros de page ne sont pas continus En supposant que chaque page peut stocker 3 enregistrements et qu'il y a maintenant 100 000 enregistrements à sauvegarder, alors 30 000 pages de données sont nécessaires à ce stade, nous serons confrontés au même problème de requête que trop de données sur une seule page, et nous ne pouvons pas. parcourez-les un à un. A cette époque, un répertoire pouvant être interrogé rapidement est également nécessaire. Ce répertoire est "Index". Sur la base de la page de données présentée dans la figure ci-dessus, la structure d'index suivante peut être formée : En termes simples, c'est comme la croissance d'un arbre, en commençant par les racines puis jusqu'au tronc, aux branches, aux feuilles, etc. Index secondaireL'idée est la même que celle de l'index clusterisé. La différence est que les nœuds feuilles de l'index secondaire ne sont pas des données réelles, mais la clé primaire des données. Vous devez effectuer l'opération table de retour pour obtenir les données réelles. Jusqu'à présent, nous connaissons déjà la structure de stockage d'une seule donnée, ainsi que la plus petite page d'unité de données de stockage. Les pages de données sont connectées via une liste doublement chaînée et les pages de données ne sont pas nécessairement continues. À ce moment-là, un problème surgit. Que se passe-t-il si les pages d'enregistrements d'une même table sont trop éloignées les unes des autres dans les adresses mémoire ?
Imaginez que pour trouver trois personnes, ils se rendent respectivement à Pékin, New York et Londres. Il faut les chercher un par un et perdre beaucoup de temps en voyage. Si vous les rassemblez dans un pays ou même une ville, ce sera beaucoup plus rapide. C'est ainsi qu'est né le concept de District. Une zone est composée de 64 pages consécutives. Par défaut, une zone occupe 1M de mémoire. Lors de la demande de mémoire, il occupe 1 M d'espace à la fois et les pages de données sont adjacentes, ce qui résout dans une certaine mesure le problème des IO aléatoires. Sur la base des zones, afin d'améliorer plus efficacement l'efficacité des requêtes, les nœuds feuilles et les nœuds non feuilles de l'arbre B+ sont enregistrés dans différentes zones. L'ensemble de ces zones est appelé "segment".
Selon ce concept, pour insérer le premier enregistrement, vous devez demander 2 espaces de zone, un nœud racine d'index clusterisé et une page de données. Cette fois, vous devez demander 2 M d'espace !
Je n'ai rien fait et l'espace 2M a disparu. Est-ce raisonnable ? Évidemment, c’est déraisonnable. Nous avons donc imaginé le concept de "zone de fragmentation". La zone fragmentée appartient directement à l'espace table et n'appartient à aucun segment. Le processus d'allocation de mémoire devient : 1) Lorsque les données sont insérées pour la première fois, l'espace de stockage est alloué sous la forme d'une seule page à partir de la zone de fragment. 2) Lorsqu'un segment a occupé 32 pages de zone de fragment, l'espace sera alloué comme une zone complète. L'espace table est également divisé en : tablespace système et tablespace indépendant De plus, il existe également une structure de données XDES Entryde zone. Le contenu est trop long et compliqué. Si vous avez besoin d'en savoir plus, vous pouvez lire le livre original. 1) Plus d'index est-il préférable ? Quel impact y aura-t-il s’il y en a davantage ? Plus il y en a, mieux c'est. Comme vous pouvez le voir ci-dessus, les enregistrements d'index nécessitent également une consommation de mémoire. Chaque index correspond à un arbre B+, et chaque arbre nécessite deux segments pour enregistrer respectivement les nœuds feuilles et les nœuds non feuilles. Cela entraînera beaucoup de gaspillage de mémoire.
Ce n’est pas inacceptable. Après tout, le sens de l’index lui-même est d’échanger de l’espace contre du temps. Mais il faut savoir que l'ajout, la suppression et la modification de données entraîneront des changements dans l'index, ce qui nécessitera une réallocation des nœuds par l'index ainsi que le recyclage et l'allocation de la mémoire des pages. Ce sont toutes des opérations d'E/S. S'il y a trop d'index, cela entraînera inévitablement une diminution des performances. Par conséquent, une utilisation raisonnable d'index conjoints peut résoudre le problème du trop grand nombre d'index uniques. De plus, l'index a une limite de longueur et les champs trop longs ne conviennent pas à l'indexation. 2) Pourquoi l'efficacité des requêtes d'index est-elle si élevée ? Il s'agit en fait d'un problème d'algorithme. Prenons l'exemple de l'index clusterisé. Supposons que les pages d'index des nœuds non-feuilles puissent chacune enregistrer 1 000 éléments de données et que chaque nœud feuille puisse enregistrer 500 éléments de données. Arbre B+ (sans compter le nœud racine), il peut stocker 10001000500 enregistrements. Un index avec une structure à trois couches peut stocker autant d'enregistrements qu'il suffit de quelques requêtes pour localiser les données à chaque fois, l'efficacité est donc naturellement élevée. En fait, les données pouvant être enregistrées sur une seule page d'index sont bien plus volumineuses que cela. De même, vous pouvez penser à un problème ici. Si la seule donnée dans le nœud feuille est très volumineuse, si grande qu'une page de données ne peut stocker que 3 enregistrements, alors la profondeur de l'arborescence B+ augmentera, donc elle est raisonnable de réduire l'enregistrement unique dans la table. La taille est également une optimisation. 3) Si la quantité de données est importante, l'exécution de SQL sera-t-elle lente ? En fait, je veux vraiment me plaindre de ce problème. L'efficacité des requêtes sur des millions de données est de xx secondes, ce qui est trop lent. Il est indéniable que les performances de MySQL sont effectivement plus faibles que celles de certaines bases de données, mais elles seront lentes avec des millions de données. Réfléchissez si la conception de votre SQL et de votre structure de table est raisonnable. Sans parler des requêtes au niveau d'un million, même des dizaines de millions de niveaux peuvent réaliser des requêtes au niveau de la milliseconde.
Parler simplement de la quantité est absurde. Vous devez réellement examiner la taille de la mémoire occupée par le verrou s'il y a des centaines de champs dans votre table ou s'il y a des champs avec des caractères extrêmement longs. Alors même les dieux ne peuvent pas vous sauver. L'article présente principalement le concept de structure de données MySql. La plupart du contenu provient du livre "Comprendre Mysql depuis la racine". De nombreuses simplifications ont été apportées, qui peuvent servir de base à la compréhension de certains concepts. S'il y a des erreurs ou des omissions, merci de me corriger. 【Recommandations associées : tutoriel vidéo mysql】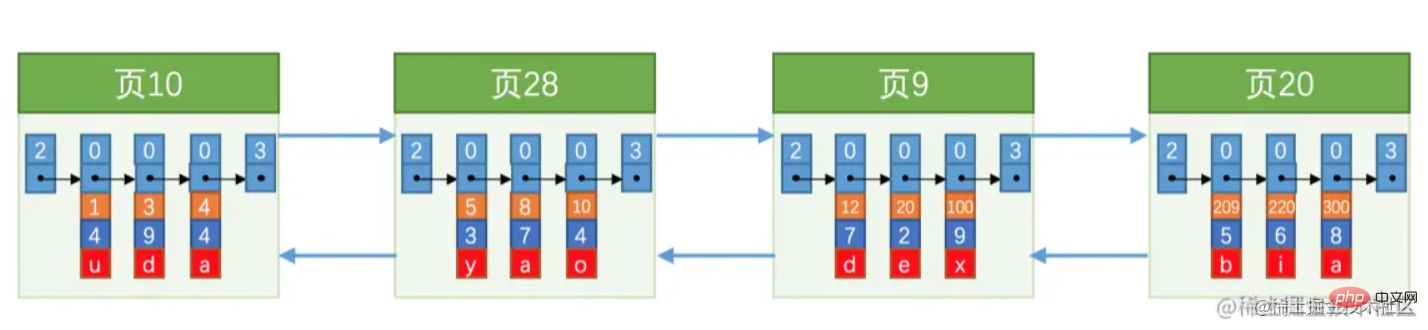 , et ne sont pas nécessairement des espaces mémoire continus (rappelez-vous ce qui suit phrase) J'en parlerai).
, et ne sont pas nécessairement des espaces mémoire continus (rappelez-vous ce qui suit phrase) J'en parlerai). 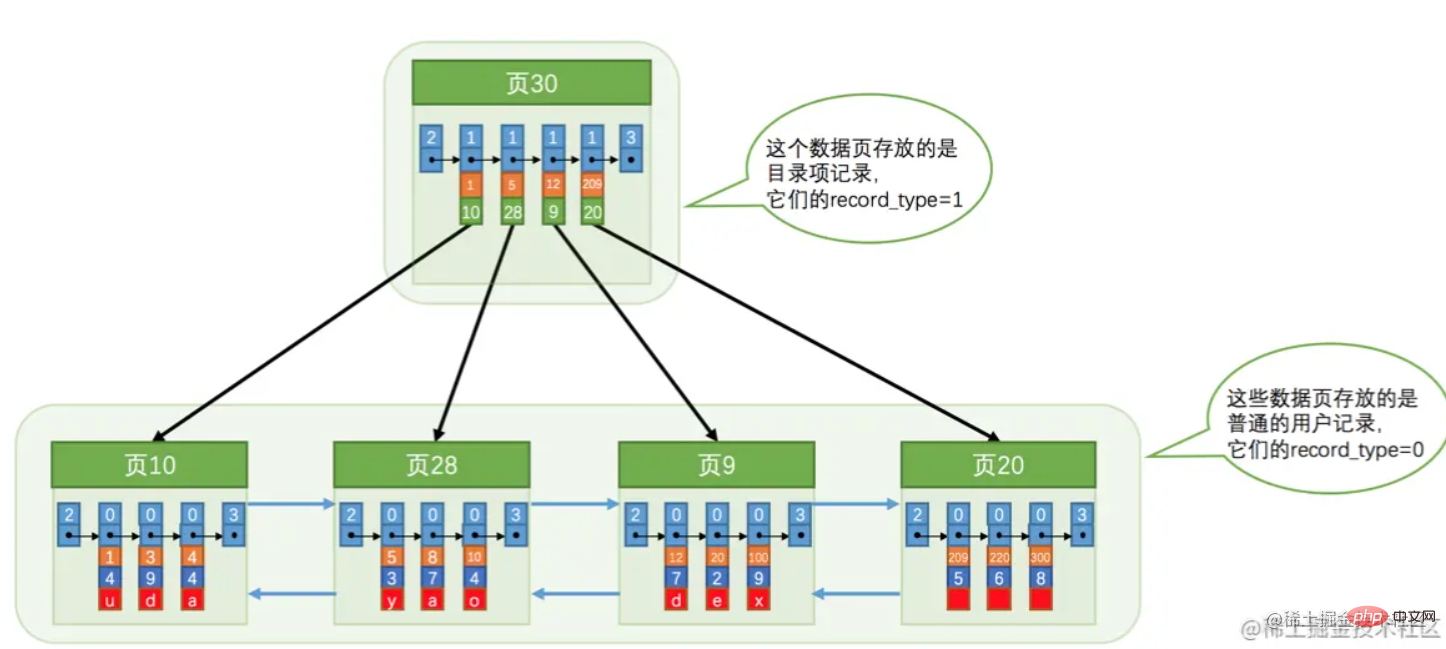 C'est ce qu'on appelle souvent un index clusterisé, et les feuilles sont des données. Une chose à noter ici est que « Page 30 » stocke la clé primaire et le numéro de page où elle se trouve.
Si une seule page d'index est pleine, elle sera divisée. Produit une structure arborescente comme indiqué ci-dessous.
C'est ce qu'on appelle souvent un index clusterisé, et les feuilles sont des données. Une chose à noter ici est que « Page 30 » stocke la clé primaire et le numéro de page où elle se trouve.
Si une seule page d'index est pleine, elle sera divisée. Produit une structure arborescente comme indiqué ci-dessous. 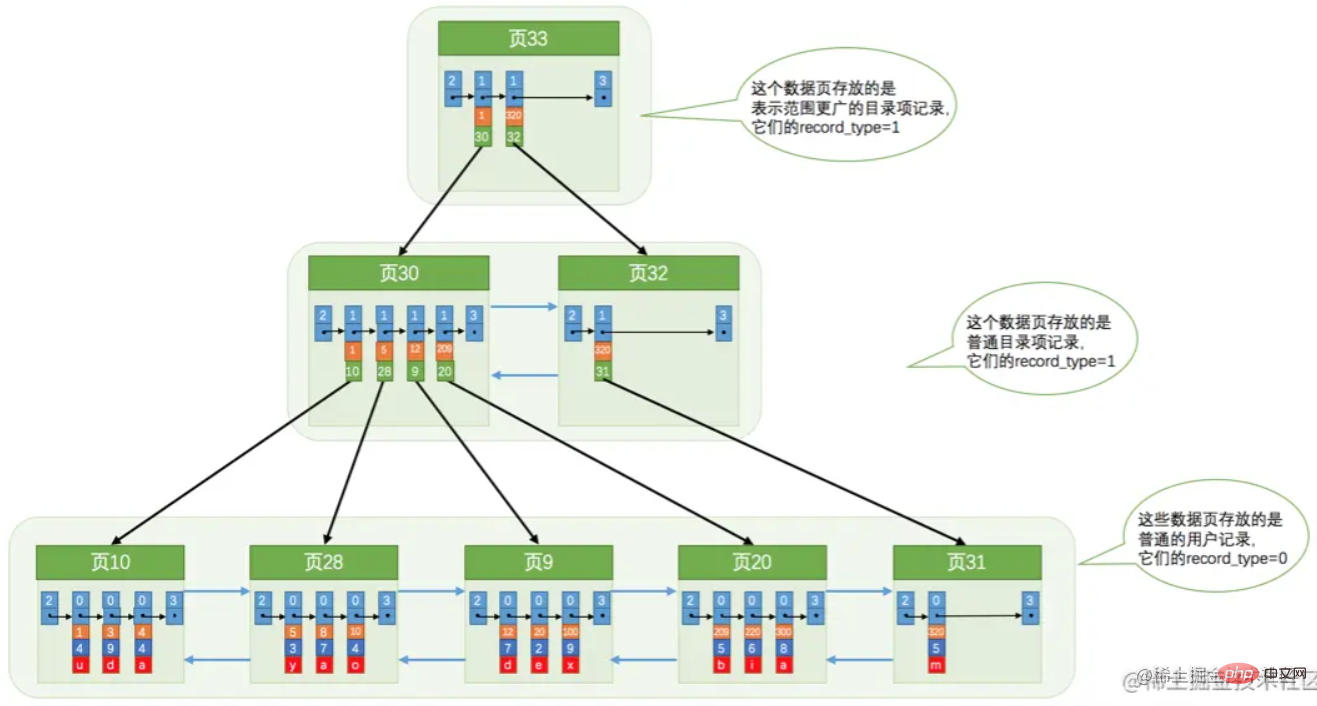 Cependant, l’image ci-dessus n’est pas tout à fait exacte pour faciliter l’étiquetage. Un nœud racine doit être généré en premier. Lorsque le nœud racine est plein, il sera divisé. Le nœud racine enregistre les informations de la page d'index après le fractionnement.
Cependant, l’image ci-dessus n’est pas tout à fait exacte pour faciliter l’étiquetage. Un nœud racine doit être généré en premier. Lorsque le nœud racine est plein, il sera divisé. Le nœud racine enregistre les informations de la page d'index après le fractionnement. Espace table
Réflexion
Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 Base de données trois paradigmes
Base de données trois paradigmes
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql


![Solution d'optimisation des requêtes MySQL [enseignée par des architectes de grands fabricants] [Démarrer avec MySQL Indexation] Tutoriel avancé |](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



