
 base de données
Redis
Comment assurer la cohérence des doubles écritures entre Redis et MySQL ? (Meituan Ermian)
base de données
Redis
Comment assurer la cohérence des doubles écritures entre Redis et MySQL ? (Meituan Ermian)
Comment assurer la cohérence des doubles écritures entre Redis et MySQL ? (Meituan Ermian)

Avant-propos
En avril, un ami s'est rendu à Meituan pour une interview. Il a dit qu'on lui avait demandé comment assurer la cohérence de la double écriture entre Redis et MySQL ? Cette question demande en fait comment assurer la cohérence du cache et de la base de données dans un scénario de double écriture ? Cet article discutera avec vous de la manière de répondre à cette question.

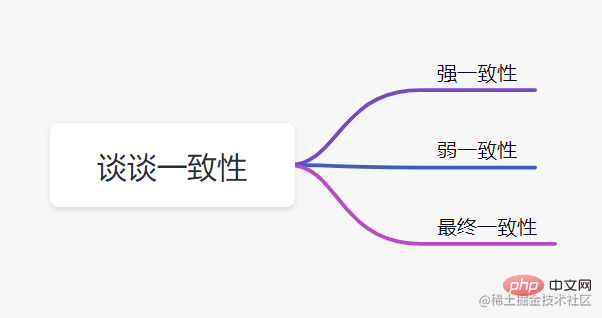
Parlez de cohérence
La cohérence est la cohérence des données Dans un système distribué, elle peut être comprise comme la cohérence des données dans plusieurs. nœuds Les valeurs sont cohérentes.
- Forte cohérence : ce niveau de cohérence est le plus conforme à l'intuition de l'utilisateur. Ce que le système doit écrire sera ce qui est lu. L'expérience utilisateur est bonne, mais sa mise en œuvre a souvent un grand impact sur les performances de. le système
- Faible cohérence : Ce niveau de cohérence empêche le système de promettre que la valeur écrite peut être lue immédiatement après la réussite de l'écriture, ni de promettre combien de temps il faudra pour que les données soient cohérentes, mais il fera de son mieux pour garantir qu'après un certain niveau de temps (tel que le niveau des secondes), les données peuvent atteindre un état cohérent
- Cohérence éventuelle : La cohérence finale est un cas particulier de cohérence faible. Le système garantira la cohérence des données. Cet état peut être atteint dans un certain laps de temps. La raison pour laquelle la cohérence ultime est mentionnée séparément ici est qu'il s'agit d'un modèle de cohérence très respecté en cohérence faible, et c'est également un modèle très respecté dans l'industrie pour la cohérence des données dans les grands systèmes distribués
Trois classiques Le mode mise en cache
la mise en cache peut améliorer les performances et soulager la pression sur la base de données, mais l'utilisation du cache peut également entraîner une incohérence des données. Comment utilisons-nous généralement le cache ? Il existe trois modèles de mise en cache classiques :
- Modèle de cache-aside
- Lecture/écriture continue
- Écriture derrière
Modèle de cache-aside
Modèle de cache-aside, c'est-à-dire Mode de contournement du cache, son Il est proposé de résoudre autant que possible le problème d'incohérence des données entre le cache et la base de données.
Processus de lecture en cache-aside
Modèle en cache-asideLe processus de demande de lecture est le suivant :
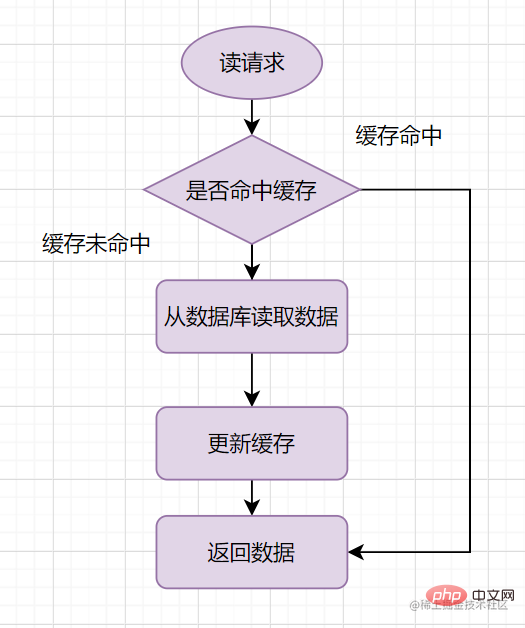
- Lors de la lecture, lisez d'abord le cache. Si le cache atteint, les données seront renvoyées directement. Si le cache ne fonctionne pas, lisez simplement la base de données, récupérez les données de la base de données, placez-les dans le cache et renvoyez la réponse en même temps.
Modèle de cache-asideLe processus de demande d'écriture est le suivant :
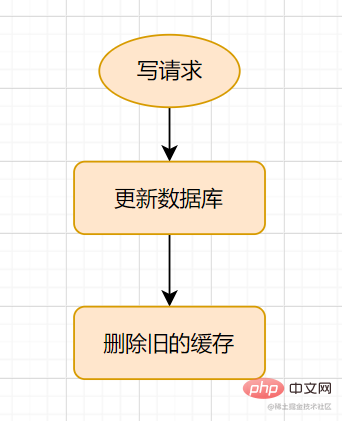
mettez d'abord à jour la base de données, puis supprimez le cache.
Read-Through/Write-Through (pénétration lecture-écriture)Read/Write Through mode, le serveur utilise le cache comme stockage de données principal. L'interaction entre l'application et le cache de la base de données s'effectue via la couche de cache abstraite.
Read-ThroughRead-ThroughLe bref processus est le suivant
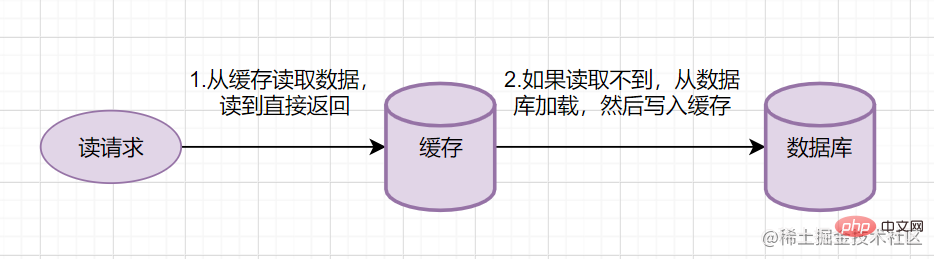
- Lire les données du cache, les lire et les renvoyer directement
- Si elles ne peuvent pas être lues, chargez-les à partir de la base de données et écrivez versez-le dans le cache. Renvoyez ensuite la réponse.
Cache-Aside ? En fait, Read-Through n'est qu'une couche supplémentaire de Cache-Provider. Le processus est le suivant :
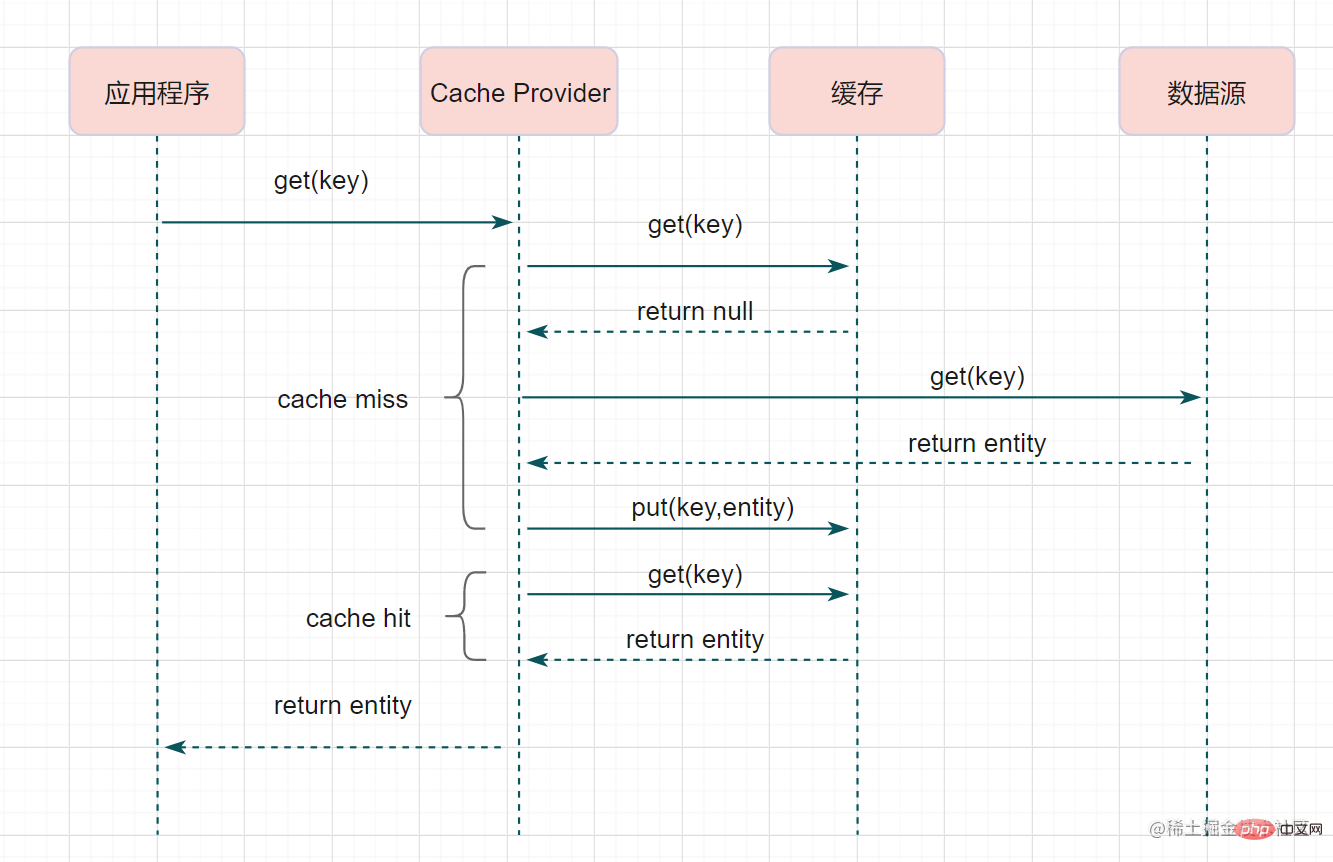
Cache-Aside, ce qui rendra le code du programme plus concis tout en réduisant la charge sur la source de données. En mode
Write-ThroughWrite-Through, lorsqu'une demande d'écriture se produit, la couche d'abstraction du cache termine également la mise à jour de la source de données et des données mises en cache. Le processus est le suivant : 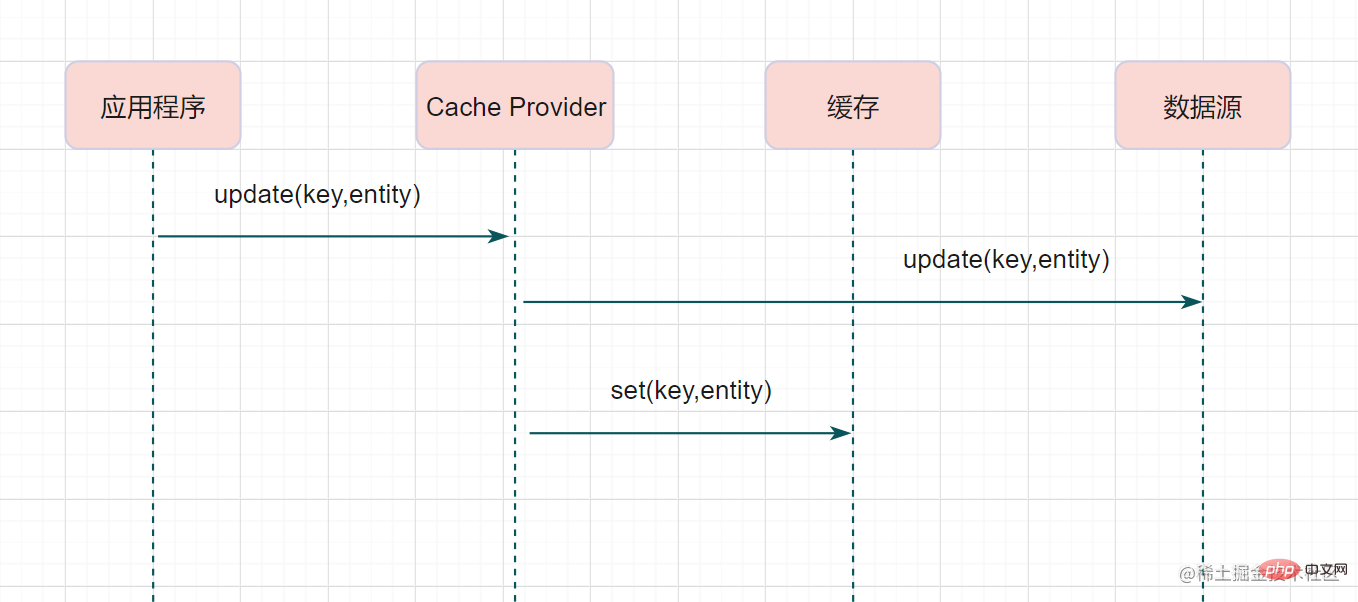
Write Behind est similaire à Read-Through/Write-Through, en ce sens que est responsable de la lecture et de l'écriture du cache et de la base de données. Il y a une grande différence entre eux : Cache ProviderRead/Write Through met à jour le cache et les données de manière synchrone, tandis que Write Behind met uniquement à jour le cache, pas directement la base de données, et met à jour la base de données via batch asynchronous.
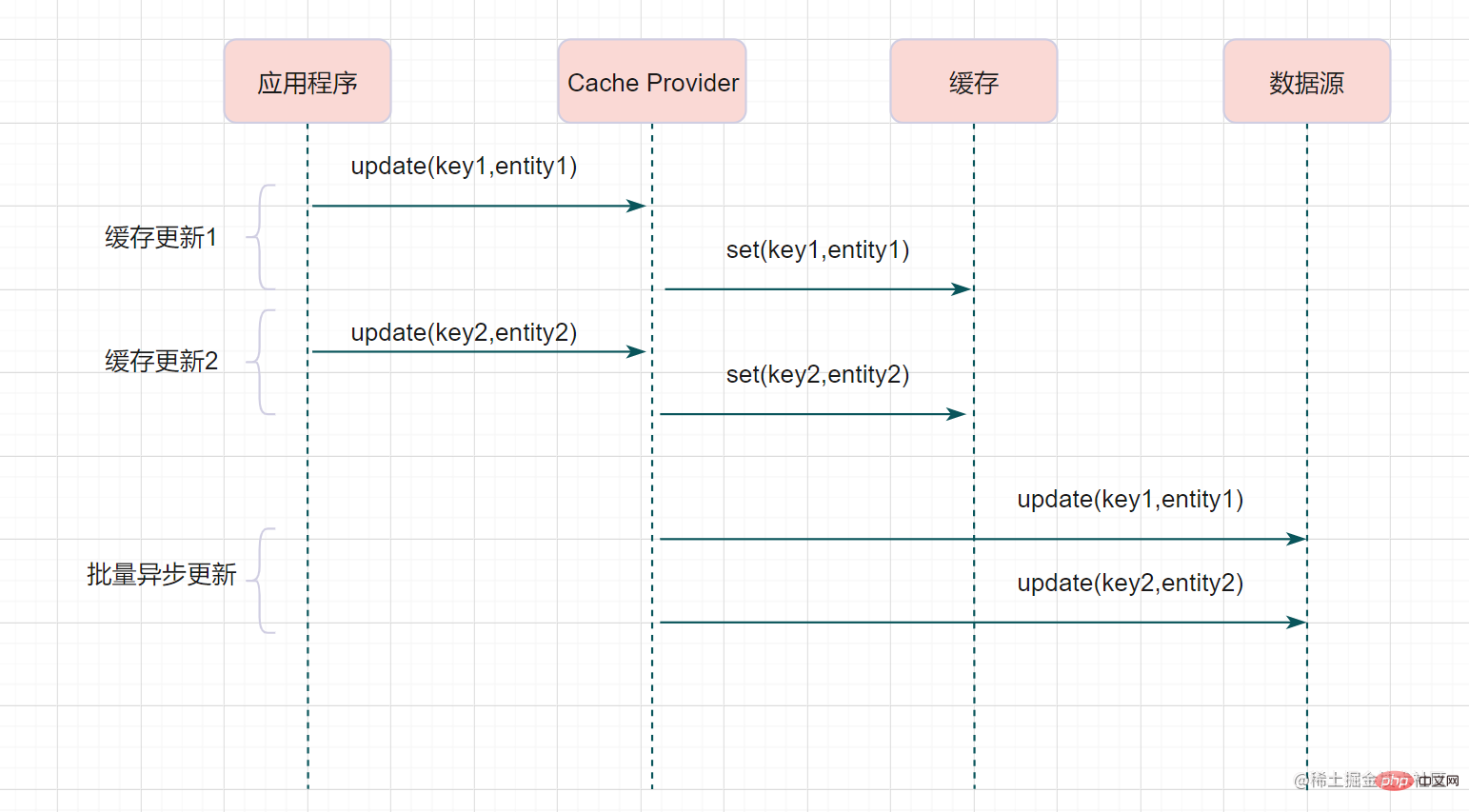
Les systèmes ayant des exigences de cohérence élevées doivent être utilisés avec prudence. Mais il convient aux scénarios d’écriture fréquents. Le Mécanisme InnoDB Buffer Pool de MySQL utilise ce mode.
Lors de l'utilisation du cache, devez-vous supprimer le cache ou mettre à jour le cache ? Dans les scénarios commerciaux généraux, nous utilisons le modeCache-Aside. Certains amis peuvent demander : Cache-AsideLors de la rédaction d'une demande, pourquoi supprimer le cache au lieu de mettre à jour le cache ?
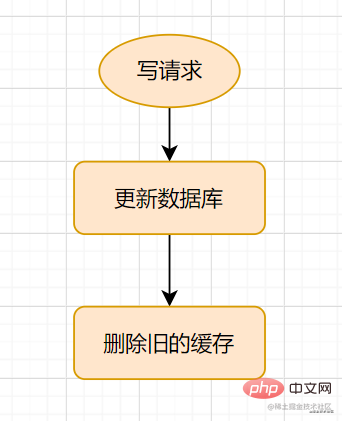
Lorsque nous exploitons le cache, devons-nous supprimer le cache ou mettre à jour le cache ? Regardons d'abord un exemple :
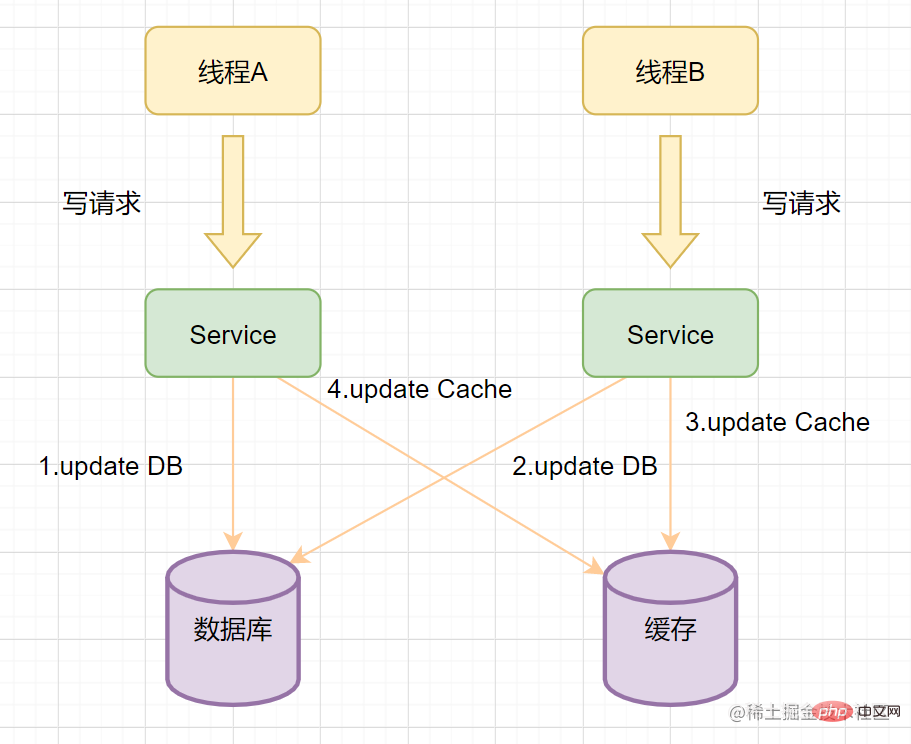
- Le Thread A lance d'abord une opération d'écriture, la première étape consiste à mettre à jour la base de données
- Le Thread B lance ensuite une opération d'écriture et la deuxième étape met à jour la base de données
- En raison de réseau et pour d'autres raisons, le fil B a d'abord mis à jour le cache
- Le fil A a mis à jour le cache.
À ce moment, le cache enregistre les données de A (anciennes données) et la base de données enregistre les données de B (nouvelles données). Les données sont incohérentes et des données sales apparaissent. Si supprimez le cache au lieu de mettre à jour le cache, ce problème de données sales ne se produira pas.
La mise à jour du cache présente deux inconvénients par rapport à la suppression du cache :
- Si la valeur du cache que vous écrivez est obtenue après des calculs complexes. Si le cache est mis à jour fréquemment, les performances seront gaspillées.
- Lorsqu'il existe de nombreux scénarios d'écriture de base de données et peu de scénarios de lecture de données, les données sont souvent mises à jour avant d'être lues, ce qui gaspille également les performances (en fait, dans les scénarios où il y a beaucoup d'écriture, la mise en cache n'est pas la meilleure solution) Très rentable)
En cas de double écriture, la base de données ou le cache doivent-ils être exploités en premier ?
En mode cache Cache-Aside, certains amis se posent encore des questions lors de la rédaction d'une requête, pourquoi Cache-Aside缓存模式中,有些小伙伴还是有疑问,在写入请求的时候,为什么是先操作数据库呢?为什么不先操作缓存呢?
假设有A、B两个请求,请求A做更新操作,请求B做查询读取操作。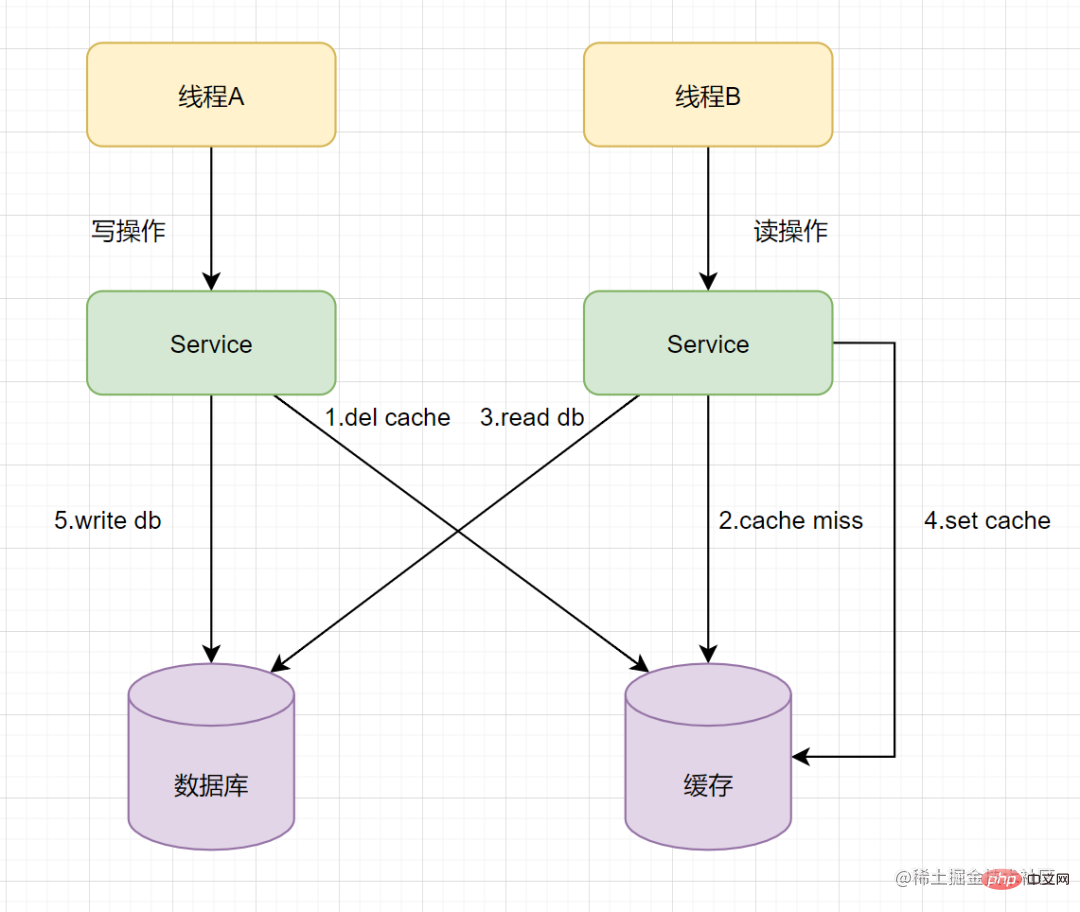
- 线程A发起一个写操作,第一步del cache
- 此时线程B发起一个读操作,cache miss
- 线程B继续读DB,读出来一个老数据
- 然后线程B把老数据设置入cache
- 线程A写入DB最新的数据
酱紫就有问题啦,缓存和数据库的数据不一致了。缓存保存的是老数据,数据库保存的是新数据。因此,Cache-Asideexploiter la base de données en premier
ne pas utiliser le cache en premier
?Supposons qu'il y ait deux requêtes, A et B, demandant à A d'effectuer l'opération de mise à jour et demandant à B d'effectuer l'opération de requête et de lecture.
Thread A Initiez une opération d'écriture, la première étape est de supprimer le cache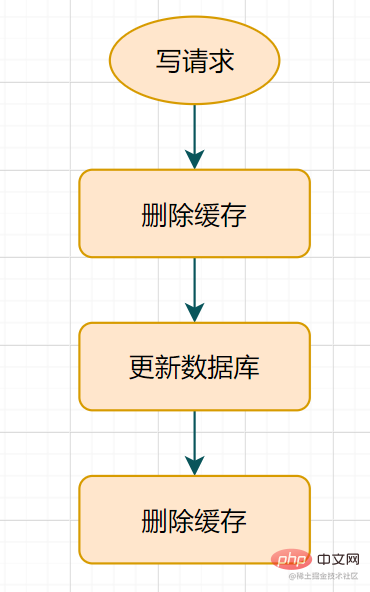
- Le thread B continue de lire la base de données et lit une ancienne donnée
- Ensuite, le thread B définit l'ancienne données dans le cache
- thread A écrit les dernières données dans DB
Il y a un problème avec Jiang Zi Les données dans le cache et la base de données sont incohérentes. Le cache stocke les anciennes données et la base de données stocke les nouvelles données
. Par conséquent, le mode de mise en cacheCache-Aside choisit d'exploiter d'abord la base de données au lieu du cache en premier. Certains amis diront peut-être que vous n'avez pas besoin d'exploiter la base de données en premier, utilisez simplement la stratégieDouble suppression retardée du cache
Double suppression retardée du cache
? Qu’est-ce que la double suppression différée ?Supprimez d'abord le cache
, puis mettez à jour la base de données Veillez pendant un moment (par exemple 1 seconde) et supprimez à nouveau le cache.
Combien de temps faut-il habituellement pour dormir pendant un certain temps ? Sont-ils tous 1 seconde ? 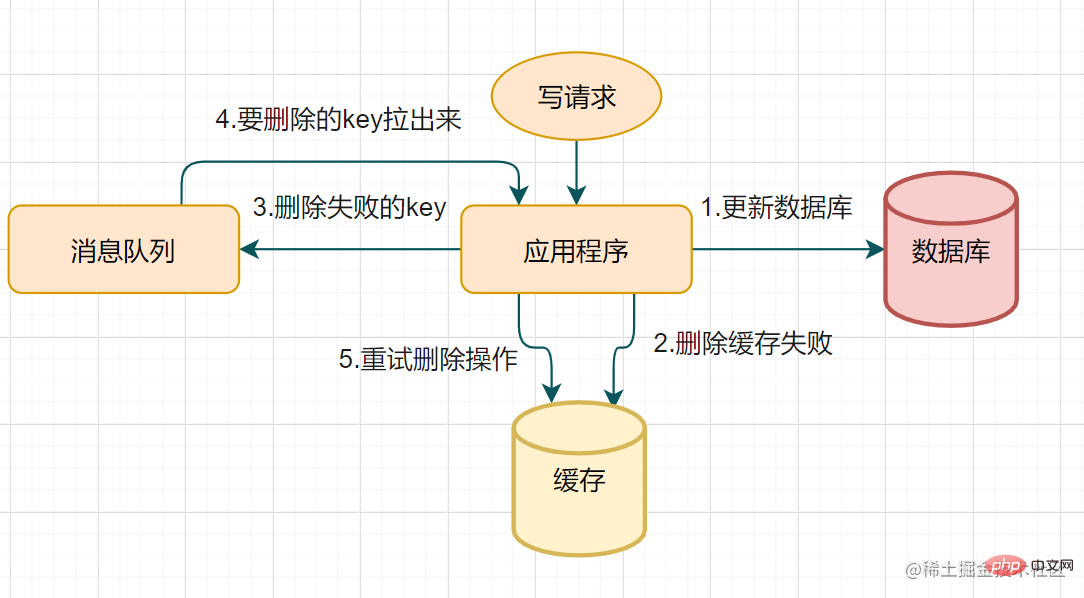
- Ce temps de veille = le temps nécessaire pour lire les données de la logique métier + quelques centaines de millisecondes. Afin de garantir la fin de la demande de lecture, la demande d'écriture peut supprimer les données sales mises en cache qui peuvent être apportées par la demande de lecture.
- Mécanisme de nouvelle tentative de suppression du cache
- Qu'il s'agisse d'une double suppression retardée
- ou d'un Cache-Aside qui exploite d'abord la base de données puis supprime le cache
- , si la deuxième étape de suppression du cache échoue, l'échec de la suppression entraînera données sales ~
Si la suppression échoue, supprimez-la plusieurs fois pour vous assurer que la suppression du cache est réussie~ Par conséquent, vous pouvez introduire le
mécanisme de nouvelle tentative de suppression du cache
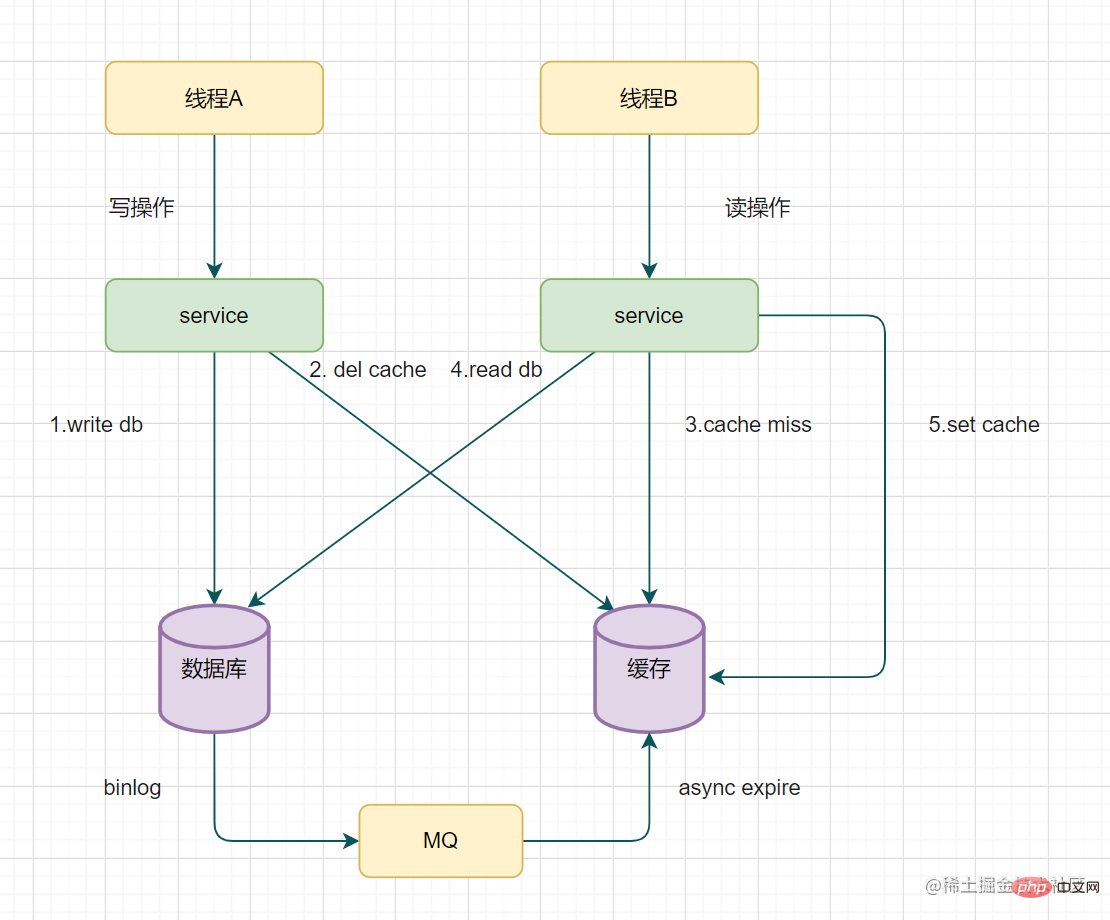
demande d'écriture pour mettre à jour la base de données
La suppression du cache a échoué pour certaines raisonsMettez la clé qui n'a pas pu être supprimée dans la file d'attente des messages
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Pour afficher toutes les touches dans Redis, il existe trois façons: utilisez la commande Keys pour retourner toutes les clés qui correspondent au modèle spécifié; Utilisez la commande SCAN pour itérer les touches et renvoyez un ensemble de clés; Utilisez la commande info pour obtenir le nombre total de clés.
 Résumé des vulnérabilités de phpmyadmin
Apr 10, 2025 pm 10:24 PM
Résumé des vulnérabilités de phpmyadmin
Apr 10, 2025 pm 10:24 PM
La clé de la stratégie de défense de sécurité PHPMYADMIN est: 1. Utilisez la dernière version de PhpMyAdmin et mettez régulièrement à jour PHP et MySQL; 2. Contrôler strictement les droits d'accès, utiliser .htaccess ou le contrôle d'accès au serveur Web; 3. Activer le mot de passe fort et l'authentification à deux facteurs; 4. Sauvegarder régulièrement la base de données; 5. Vérifiez soigneusement les fichiers de configuration pour éviter d'exposer des informations sensibles; 6. Utiliser le pare-feu d'application Web (WAF); 7. Effectuer des audits de sécurité. Ces mesures peuvent réduire efficacement les risques de sécurité causés par le phpmyadmin en raison d'une configuration inappropriée, d'une version antérieure ou de risques de sécurité environnementale, et d'assurer la sécurité de la base de données.
 Guide de l'utilisation globale de phpmyadmin
Apr 10, 2025 pm 10:42 PM
Guide de l'utilisation globale de phpmyadmin
Apr 10, 2025 pm 10:42 PM
PhPMyAdmin n'est pas seulement un outil de gestion de la base de données, il peut vous donner une compréhension approfondie de MySQL et améliorer les compétences en programmation. Les fonctions principales incluent l'exécution de la requête CRUD et SQL, et il est crucial de comprendre les principes des instructions SQL. Les conseils avancés incluent l'exportation / l'importation de données et la gestion des autorisations, nécessitant une compréhension approfondie de la sécurité. Les problèmes potentiels incluent l'injection SQL et la solution est des requêtes paramétrées et des sauvegardes. L'optimisation des performances implique l'optimisation des instructions SQL et l'utilisation de l'index. Les meilleures pratiques mettent l'accent sur les spécifications du code, les pratiques de sécurité et les sauvegardes régulières.
 Que faire si redis-server ne peut être trouvé
Apr 10, 2025 pm 06:54 PM
Que faire si redis-server ne peut être trouvé
Apr 10, 2025 pm 06:54 PM
Étapes pour résoudre le problème que Redis-Server ne peut pas trouver: Vérifiez l'installation pour vous assurer que Redis est installé correctement; Définissez les variables d'environnement redis_host et redis_port; Démarrer le serveur Redis Redis-Server; Vérifiez si le serveur exécute Redis-Cli Ping.
 Comment utiliser redis zset
Apr 10, 2025 pm 07:27 PM
Comment utiliser redis zset
Apr 10, 2025 pm 07:27 PM
Les ensembles commandés par Redis (ZSETS) sont utilisés pour stocker des éléments commandés et trier par des scores associés. Les étapes à utiliser ZSET incluent: 1. Créer un ZSET; 2. Ajouter un membre; 3. Obtenez un score de membre; 4. Obtenez un classement; 5. Obtenez un membre dans la gamme de classement; 6. Supprimer un membre; 7. Obtenez le nombre d'éléments; 8. Obtenez le nombre de membres dans la plage de score.
 Comment la clé est-elle unique pour Redis Query
Apr 10, 2025 pm 07:03 PM
Comment la clé est-elle unique pour Redis Query
Apr 10, 2025 pm 07:03 PM
Redis utilise cinq stratégies pour assurer le caractère unique des clés: 1. Séparation des espaces de noms; 2. Structure de données de hachage; 3. Définir la structure des données; 4. Caractères spéciaux des touches de chaîne; 5. Vérification du script LUA. Le choix de stratégies spécifiques dépend de l'organisation des données, des performances et des exigences d'évolutivité.
