

Sous Linux, disque fait référence à « disque », qui est un périphérique de stockage en bloc, c'est-à-dire un périphérique utilisé pour stocker des fichiers ; le système de fichiers est en fait un mappage de l'espace disque. Afin d'éviter de stocker ou de lire des données dans un espace trop grand pour réduire l'efficacité de l'accès, ou de stocker et gérer des données en catégories, il est nécessaire de diviser un espace disque en plusieurs zones, ce que l'on appelle la partition de disque.

L'environnement d'exploitation de ce tutoriel : système linux7.3, ordinateur Dell G3.
Disk (disque) est un périphérique de stockage en bloc utilisé pour stocker des fichiers. Le système de fichiers est en fait un mappage de l'espace disque.
Dans le système Linux, le système de fichiers est créé sur le disque dur. Par conséquent, si vous souhaitez bien comprendre le mécanisme de gestion du système de fichiers, vous devez commencer par comprendre le disque dur. . Les disques durs peuvent être divisés en disques durs mécaniques (Hard Disk Drive, HDD) et disques SSD (Solid State Disk, SSD). Les disques durs mécaniques utilisent des plateaux magnétiques pour stocker les données, tandis que les disques SSD utilisent des particules de mémoire flash pour stocker les données.

Le disque dur mécanique ulouscred est principalement composé d'un disque, d'une piste, d'un secteur, Composé d'un cylindre et d'un arbre de transmission.
Disque : Un disque comporte généralement un ou plusieurs plateaux. Chaque disque peut avoir deux faces, c'est-à-dire que la face avant du premier disque est la face 0 et la face arrière est la face 1 ; la face avant du deuxième disque est la face 2... et ainsi de suite. 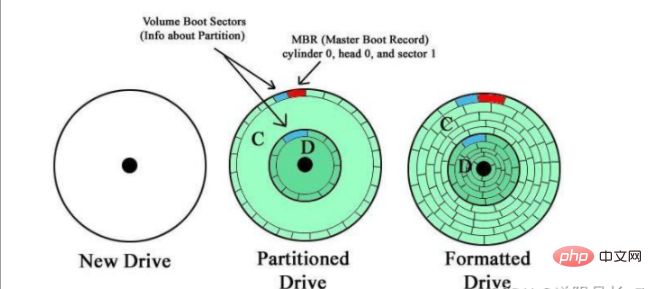
Le processus de lecture et d'écriture de données sur un disque dur
Les disques durs modernes utilisent la méthode CHS (Cylinder Head Sector) pour la recherche. Lorsque le disque dur lit des données, les têtes de lecture et d'écriture se déplacent radialement vers le secteur. être lu. Au-dessus de la piste, cette période de temps est appelée temps de recherche. Étant donné que la distance entre la position de départ de la tête de lecture et d'écriture et la position cible est différente, le temps de recherche est également différent. Les disques durs actuels prennent généralement entre 2 et 30 millisecondes, avec une moyenne d'environ 9 millisecondes. Une fois que la tête magnétique atteint la piste désignée, le secteur à lire est déplacé sous la tête de lecture et d'écriture pendant la rotation du disque. Cette période de temps est appelée latence de rotation d'un disque dur de 7 200 (tours par minute). requis pour chaque rotation est de 60×1000÷7200=8,33 millisecondes, alors le temps de retard moyen de rotation est de 8,33÷2=4,17 millisecondes (en moyenne, un demi-tour est nécessaire). Le temps de recherche moyen et le délai facultatif moyen sont appelés temps d'accès moyen. Solid State Drive (SSD)Actuellement, les interfaces de disque dur mécaniques courantes incluent les types suivants :
Interface de disque dur IDE : (Integrated Drive Eectronics, port parallèle, lecteur électronique intégré), également connu sous le nom de « disque dur ATA » ou « disque dur PATA », est l'interface principale des premiers disques durs mécaniques. La vitesse théorique du disque dur ATA133. Le disque peut atteindre 133 Mo/s (cette vitesse est la moyenne théorique) Parce que les performances anti-interférences du câble du port parallèle sont trop mauvaises et que le câble occupe un grand espace, ce qui n'est pas propice à la dissipation thermique interne du ordinateur, il a été progressivement remplacé par le SATA.
Interface SATA : le nom complet est Serial ATA, qui est une interface ATA utilisant un port série. Elle se caractérise par une forte anti-interférence, a des exigences bien inférieures en matière de lignes de données que ATA et prend en charge les échanges à chaud et autres. fonctions. La vitesse d'interface du SATA-II est de 300 Mo/s, tandis que la nouvelle norme SATA-III peut atteindre une vitesse de transmission de 600 Mo/s. Les câbles de données SATA sont également beaucoup plus fins que les câbles ATA, ce qui favorise la circulation de l'air dans le châssis et facilite l'organisation des câbles.
Interface SCSI : le nom complet est Small Computer System Interface (Small Computer System Interface). Elle a connu de nombreuses générations de développement, du premier SCSI-II à l'actuel Ultra320 SCSI et Fibre-Channel (Fiber Channel). également divers types d'interfaces. Les disques durs SCSI sont largement utilisés dans les ordinateurs personnels et les serveurs au niveau des postes de travail. Par conséquent, ils utilisent des technologies plus avancées, telles qu'une vitesse de disque élevée de 15 000 tr/min, et l'utilisation du processeur est inférieure lors de la transmission des données. supérieur à celui des disques durs ATA et SATA de même capacité sont plus chers.
Interface SAS : Le nom complet est Serial Attached SCSI. Il s'agit d'une nouvelle génération de technologie SCSI compatible avec les disques durs SATA. Ils utilisent tous la technologie série pour obtenir des vitesses de transmission plus élevées, pouvant atteindre 12 Gb/s. De plus, l'espace interne du système est amélioré en réduisant les câbles de connexion.
Interface FC : Le nom complet est Fibre Channel (interface Fibre Channel). Les disques durs dotés de cette interface ont les caractéristiques de remplaçabilité à chaud, de bande passante haut débit (4 Gb/s ou 10 Gb/s), de connexion à distance, etc. utilisant une connexion par fibre optique ; taux de transmission interne Il est également supérieur à celui des disques durs ordinaires. Mais son prix est élevé, donc l'interface FC n'est généralement utilisée que dans le domaine des serveurs haut de gamme
Maintenant, la plupart des interfaces de disque mécaniques ordinaires sont SATA, et la plupart des interfaces de disque SSD sont SAS
Un système de fichiers est une méthode et une structure de données utilisées par le système d'exploitation pour identifier les fichiers sur un périphérique de stockage (généralement un disque, mais aussi un disque SSD NAND Flash) ou une partition, c'est-à-dire une méthode d'organisation des fichiers sur un périphérique de stockage. L'organisation logicielle chargée de gérer et de stocker les informations sur les fichiers dans le système d'exploitation est appelée système de gestion de fichiers, ou système de fichiers en abrégé. Une interface vers un système de fichiers, un ensemble de logiciels de manipulation et de gestion d'objets, d'objets et d'attributs. Du point de vue du système, un système de fichiers est un système qui organise et alloue l'espace des périphériques de stockage de fichiers, est responsable du stockage des fichiers, et protège et récupère les fichiers stockés. Plus précisément, il est responsable de la création de fichiers pour les utilisateurs, du stockage, de la lecture, de la modification et du vidage des fichiers, du contrôle de l'accès aux fichiers et de la révocation des fichiers lorsque les utilisateurs ne les utilisent plus. Le système de fichiers fait partie du système logiciel. Son existence permet aux applications d'utiliser facilement des objets de données nommés abstraits et un espace de taille variable. Gérer et planifier l'espace de stockage des fichiers, fournir la structure logique, la structure physique et la méthode de stockage des fichiers ; réaliser le mappage des fichiers de l'identification aux adresses réelles, réaliser les opérations de contrôle et d'accès aux fichiers, réaliser le partage des informations sur les fichiers et fournir des fichiers fiables Mesures de confidentialité et de protection Prévoir des mesures de sécurité pour les documents.
FAT :
Sous Win 9X, la partition maximale prise en charge par FAT16 est de 2 Go. Nous savons que les ordinateurs stockent les informations sur le disque dur dans des zones appelées « clusters ». Plus les clusters utilisés sont petits, plus les informations peuvent être enregistrées efficacement. Dans le cas de FAT16, plus la partition est grande, plus le cluster est grand et plus l'efficacité du stockage est faible, ce qui entraînera inévitablement un gaspillage d'espace de stockage. Et avec l'amélioration continue du matériel informatique et des applications, le système de fichiers FAT16 ne peut plus bien s'adapter aux exigences du système. Dans ce cas, le système de fichiers amélioré FAT32 a été introduit.
NTFS :
Le système de fichiers NTFS est un système de fichiers basé sur la sécurité et une structure de système de fichiers unique adoptée par Windows NT. Il est basé sur la protection des données de fichiers et de répertoires, tout en prenant soin d'économiser les ressources de stockage et de réduire l'empreinte disque de. un système de fichiers avancé. Windows NT 4.0, largement utilisé, utilise le système de fichiers NTFS 4.0. Je pense que la puissante sécurité du système qu'il apporte a dû laisser une profonde impression sur la majorité des utilisateurs. Win 2000 utilise une version mise à jour du système de fichiers NTFS NTFS 5.0. Son lancement permet aux utilisateurs non seulement d'utiliser et de gérer des ordinateurs aussi facilement et rapidement que Win 9X, mais également de profiter de la sécurité du système apportée par NTFS.
exFAT :
Le nom complet est Extended File Allocation Table File System, Extended FAT, qui est la table d'allocation de fichiers étendue, est un système introduit par Microsoft dans Windows Embeded 5.0 et supérieur (y compris Windows CE 5.0, 6.0, Windows Mobile5, 6, 6.1) Un système de fichiers adapté à la mémoire flash, introduit pour résoudre le problème du FAT32 et d'autres fichiers qui ne prennent pas en charge les fichiers 4G et plus.
RAW :
Le système de fichiers RAW est un système de fichiers généré par des disques non traités ou non formatés. De manière générale, il existe plusieurs possibilités qui font qu'un système de fichiers normal devient un système de fichiers RAW : pas de formatage, formatage Annulation de l'opération à mi-chemin, mauvais. secteurs du disque dur, des erreurs imprévisibles sur le disque dur ou des virus. Le moyen le plus rapide de résoudre le problème du système de fichiers RAW est de le formater immédiatement et d'utiliser un logiciel antivirus pour le désinfecter complètement.
Ext :
Ext2 : Ext est le système de fichiers standard du système GNU/Linux. se caractérise par des performances extrêmement élevées dans l'accès aux fichiers. Eh bien, il présente plus d'avantages pour les fichiers de petite et moyenne taille, ce qui est principalement dû à l'excellente conception de sa couche de cache de cluster.
Ext3 : C'est un système de fichiers de journalisation, une extension du système ext2, et il est compatible avec ext2. L'avantage d'un système de fichiers journalisé est que, comme le système de fichiers dispose d'une couche de cache impliquée dans son fonctionnement, le système de fichiers doit être démonté lorsqu'il n'est pas utilisé afin que les données de la couche de cache puissent être réécrites sur le disque. Par conséquent, chaque fois que le système souhaite s'arrêter, tous ses systèmes de fichiers doivent être arrêtés avant d'arrêter Ext4 : Le noyau Linux prend officiellement en charge le nouveau système de fichiers Ext4 depuis le 2.6.28. Ext4 est une version améliorée d'Ext3, qui modifie certaines structures de données importantes dans Ext3, et ne se contente pas d'ajouter une fonction de journalisation comme Ext3 l'a fait à Ext2. Ext4 peut offrir de meilleures performances et fiabilité, ainsi que des fonctionnalités plus riches.
XFS :
Il s'agit d'un système de fichiers journaux hautes performances et du système de gestion de fichiers par défaut dans RHEL 7. Ses avantages sont particulièrement évidents après un temps d'arrêt inattendu, c'est-à-dire qu'il peut restaurer rapidement les fichiers qui auraient pu être endommagés. . et la puissante fonction de journalisation ne nécessite que des performances de calcul et de stockage très faibles. Et sa capacité de stockage maximale prise en charge est de 18 Mo, ce qui répond à presque tous les besoins.HFS : Le système de fichiers hiérarchique (HFS) est un système de fichiers développé par Apple Computer et utilisé sur Mac OS. Conçu à l'origine pour être utilisé avec des disquettes et des disques durs, il peut également être trouvé sur des supports en lecture seule tels que les CD-ROM.
La répartition des données enregistre les fragments de données sur plusieurs disques différents. Plusieurs fragments de données forment ensemble une copie de données complète, différente de plusieurs copies d'un miroir. Elle est généralement utilisée pour des raisons de performances. Le striping des données a une granularité de concurrence plus élevée. Lors de l'accès aux données, les données situées sur différents disques peuvent être lues et écrites en même temps, obtenant ainsi une amélioration très considérable des performances d'E/S.
La vérification des données utilise des données redondantes pour détecter et réparer les erreurs de données. Les données redondantes sont généralement calculées à l'aide d'algorithmes tels que les codes de Hamming et les opérations XOR. L'utilisation de la fonction de vérification peut améliorer considérablement la fiabilité, la robustesse et la tolérance aux pannes de la baie de disques. Cependant, la vérification des données nécessite de lire des données à plusieurs endroits et d'effectuer des calculs et des comparaisons, ce qui affectera les performances du système.
Différents niveaux de RAID utilisent une ou plusieurs des trois technologies pour obtenir différentes fiabilité, disponibilité et performances d'E/S des données. Quant au type de RAID à concevoir (ou même à un nouveau niveau ou type) ou au mode de RAID à utiliser, il est nécessaire de faire un choix raisonnable basé sur une compréhension approfondie des exigences du système et de faire un choix de compromis en évaluer la fiabilité, les performances et le coût.
Les hautes performances du RAID bénéficient de la technologie de répartition des données. Les performances d'E/S d'un seul disque sont limitées par la technologie informatique telle que l'interface et la bande passante. Les performances sont souvent très limitées et peuvent facilement devenir un goulot d'étranglement pour les performances du système. Grâce à la répartition des données, le RAID répartit les E/S de données sur les disques membres, ce qui entraîne des performances d'E/S globales exponentiellement supérieures à celles d'un seul disque.
(3) Fiabilité
La disponibilité et la fiabilité sont d'autres caractéristiques importantes du RAID. En théorie, un système RAID composé de plusieurs disques devrait être moins fiable qu'un seul disque. Il existe ici une hypothèse implicite : une seule panne de disque rendra l'ensemble du RAID indisponible. RAID brise cette hypothèse en utilisant des technologies de redondance des données telles que la mise en miroir et la parité des données. La mise en miroir est la technologie de redondance la plus primitive. Elle copie complètement les données d'un certain ensemble de disques sur un autre ensemble de disques pour garantir qu'une copie des données est toujours disponible. Par rapport à la surcharge de redondance de 50 % de la mise en miroir, la vérification des données est beaucoup plus petite. Elle utilise des informations de vérification redondantes pour vérifier et corriger les données. La technologie de redondance RAID améliore considérablement la disponibilité et la fiabilité des données, garantissant que lorsque plusieurs erreurs de disque se produisent, les données ne seront pas perdues et le fonctionnement continu du système ne sera pas affecté.
(4) Gérabilité
En fait, RAID est une technologie de virtualisation qui virtualise plusieurs disques physiques en un disque logique de grande capacité. RAID est un lecteur de disque de grande capacité unique, rapide et fiable pour un système hôte externe. De cette manière, les utilisateurs peuvent organiser et stocker les données du système d'application sur ce lecteur virtuel. Du point de vue des applications utilisateur, le système de stockage peut être simple et facile à utiliser, et la gestion est également très pratique. Étant donné que RAID effectue une grande partie du travail de gestion du stockage en interne, les administrateurs n'ont besoin de gérer qu'un seul disque virtuel, ce qui permet d'économiser beaucoup de travail de gestion. RAID peut ajouter ou supprimer dynamiquement des lecteurs de disque et effectuer automatiquement une vérification et une reconstruction des données, ce qui peut grandement simplifier le travail de gestion.
RAID0
RAID1
RAID3
RAID5
RAID6
RAID10
Pour éviter de stocker ou de lire des données dans un espace trop grand et réduire l'efficacité de l'accès, ou pour classer et stocker des données, il est nécessaire de diviser un espace disque en plusieurs zones. C'est ce qu'on appelle la partition de disque.
Partition MBR (aussi appelée partition msdos, traditionnelle)


Secteur | Bloc physique Sur un périphérique de stockage sur disque dur, un secteur est la plus petite unité de stockage. La taille traditionnelle d'un secteur est de 512 Go, mais lorsque de nouveaux disques durs quittent l'usine, un secteur peut être défini sur 4 Ko.
Un cluster ou un bloc logique peut correspondre à un secteur ou un groupe de secteurs, et est utilisé pour l'espace dans le système de fichiers Un seul  bit d'alloué logique.
bit d'alloué logique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!









![[Introduction aux débutants, facile à comprendre] Apprenez Linux en une semaine](https://img.php.cn/upload/course/000/000/068/6242a86a890b1568.png)


![Cours de base sur l'exploitation et la maintenance de Linux [explication détaillée de l'ensemble du processus]](https://img.php.cn/upload/course/000/000/068/63ff173c79edd672.jpg)






![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



