
 Opération et maintenance
exploitation et maintenance Linux
Quelle est la partition LVM de Linux ?
Opération et maintenance
exploitation et maintenance Linux
Quelle est la partition LVM de Linux ?
Quelle est la partition LVM de Linux ?

La partition lvm de Linux fait référence à la « gestion des volumes logiques ». Le nom anglais complet de lvm est « Logical Volume Manager », qui est un mécanisme de gestion des partitions de disque dans l'environnement Linux construit sur le disque dur et les partitions ; Une couche logique pour améliorer la flexibilité de la gestion des partitions de disque.

L'environnement d'exploitation de ce tutoriel : système linux5.9.8, ordinateur Dell G3.
1. Qu'est-ce que LVM
LVM (Logical Volume Manager), ou gestion de volumes logiques, est un mécanisme de gestion des partitions de disque dans l'environnement Linux. Il s'agit d'une couche logique construite sur le disque dur et les partitions. gestion des partitions de disque. Les administrateurs système LVM peuvent facilement gérer les partitions de disque, par exemple en connectant plusieurs partitions de disque dans un groupe de volumes pour former un pool de stockage. Les administrateurs peuvent librement créer des volumes logiques sur des groupes de volumes et créer davantage de systèmes de fichiers sur des groupes de volumes logiques. Les administrateurs peuvent facilement ajuster la taille des groupes de volumes de stockage via LVM et peuvent nommer, gérer et allouer le stockage sur disque en fonction des groupes. Lorsqu'un nouveau disque est ajouté au système, l'administrateur LVM n'a pas besoin de déplacer les fichiers du disque vers le nouveau disque pour utiliser pleinement le nouvel espace de stockage, mais peut directement étendre le système de fichiers sur le disque.
De manière générale, les disques ou partitions physiques sont séparés, les données ne peuvent pas s'étendre sur des disques ou des partitions et la taille de chaque disque ou partition est fixe, le réajustement est donc difficile. LVM peut intégrer ces disques ou partitions physiques sous-jacents, les résumer dans des pools de ressources de capacité et les diviser en volumes logiques à utiliser par la couche supérieure. Sa fonction principale est qu'il peut être utilisé sans arrêt ni reformatage (pour être précis, Le). la taille du volume logique peut être ajustée de manière flexible sans formater la partie originale (seule la nouvelle partie est formatée).
Le processus de mise en œuvre de LVM est le suivant :
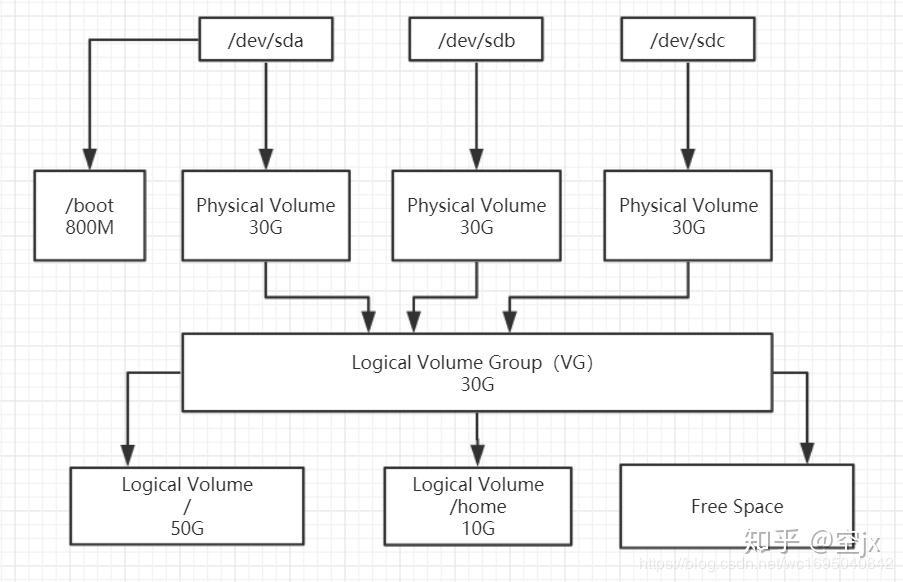

2. Explication des termes LVM
PV (volume physique) : Le volume physique se trouve au bas du système de gestion de volume logique, qui Il peut s'agir de l'intégralité du disque dur physique ou de la partition réelle du disque dur physique. Il réserve simplement une zone spéciale dans la partition physique pour enregistrer les paramètres de gestion liés à LVM.
VG (groupe de volumes) : Le groupe de volumes est établi sur un volume physique. Un groupe de volumes doit inclure au moins un volume physique. Une fois le groupe de volumes établi, les volumes peuvent être ajoutés dynamiquement au groupe de volumes logique. projet de système de gestion Il peut y avoir plusieurs groupes de volumes.
LV (volume logique) : les volumes logiques sont construits sur des groupes de volumes. L'espace non alloué dans le groupe de volumes peut être utilisé pour créer de nouveaux volumes logiques. Une fois les volumes logiques créés, l'espace peut être étendu et réduit de manière dynamique.
PE (étendue physique) : La zone physique est la plus petite unité de stockage pouvant être allouée dans le volume physique. La taille de la zone physique est spécifiée lors de la création du groupe de volumes. La taille de la zone physique de tous les volumes physiques du même groupe de volumes doit être cohérente. Après l'ajout d'un nouveau pv au vg, la taille du pe est automatiquement remplacée par la taille pe définie dans le vg.
LE (étendue logique) : La zone logique est la plus petite unité de stockage disponible pour l'allocation dans le volume logique. La taille de la zone logique dépend de la taille de la zone physique dans le groupe de volumes où se trouve le volume logique. . En raison des limitations du noyau, Un volume logique (Logic Volume) ne peut contenir que jusqu'à 65 536 PE (étendue physique), donc la taille d'un PE détermine la capacité maximale du volume logique, et 4 Mo (par défaut) PE détermine le la capacité maximale d'un seul volume logique est de 256 Go. Si vous souhaitez utiliser un volume logique supérieur à 256 Go, vous devez spécifier un PE plus grand lors de la création d'un groupe de volumes. Dans Red Hat Enterprise Linux AS 4, la taille du PE varie de 8 Ko à 16 Go et doit toujours être un multiple de 2.
3. Mode d'écriture LVM
LVM a deux modes d'écriture : le mode linéaire et le mode bande.
- Le mode linéaire signifie écrire sur un périphérique avant d'écrire sur un autre périphérique.
- Le mode Stripe est quelque peu similaire au RAID0, c'est-à-dire que les données sont écrites sur chaque périphérique membre LVM de manière distribuée.
Étant donné que les données en mode stripe ne sont pas sécurisées et que LVM ne met pas l'accent sur les performances de lecture et d'écriture, LVM passe par défaut en mode linéaire, de sorte que même si un appareil est cassé, les données sur les autres appareils sont toujours là.
4. Comment fonctionne LVM
LVM conserve des métadonnées en tête de chaque volume physique. Chaque métadonnée contient des informations sur l'ensemble du VG (groupe de volumes : groupe de volumes), y compris la disposition de chaque VG Configuration, PV (physique. volume : numéro de volume physique), le numéro LV (volume logique : volume logique) et la relation de mappage de chaque PE (extensions physiques : unité d'extension physique) à LE (extensions logiques : unité d'extension physique). Les informations contenues dans l'en-tête de chaque PV d'un même VG sont les mêmes, ce qui facilite la récupération des données en cas de panne.
LVM fournit la couche LV pour le système de fichiers supérieur, masquant les détails de l'opération. Pour le système de fichiers, le fonctionnement de LV n'est pas différent du fonctionnement original de la partition. Lors de l'écriture sur le LV, LVM localise le LE correspondant et écrit les données sur le PE correspondant via la table de mappage dans l'en-tête PV. La plus grande fonctionnalité de LVM est qu’il peut gérer dynamiquement les disques. Parce que la taille du volume logique peut être ajustée dynamiquement sans perdre les données existantes. Si nous ajoutons un nouveau disque dur, cela ne modifiera pas le volume logique supérieur existant. La clé est d'établir une relation de mappage entre PE et LE. Différentes règles de mappage déterminent différents modèles de stockage LVM. LVM prend en charge la bande et le miroir de plusieurs PV.
5. Avantages et inconvénients de LVM
Avantages :
- Le système de fichiers peut s'étendre sur plusieurs disques, de sorte que la taille du système de fichiers n'est pas limitée par le disque physique.
- Vous pouvez augmenter dynamiquement la taille du système de fichiers pendant que le système est en cours d'exécution.
- Vous pouvez ajouter de nouveaux disques au pool de stockage LVM.
- Peut redondant des données importantes sur plusieurs disques physiques de manière miroir.
- Vous pouvez facilement exporter l'intégralité du groupe de volumes vers une autre machine.
Inconvénients :
- La commande réduirevg doit être utilisée lors de la suppression d'un disque d'un groupe de volumes (cette commande nécessite les privilèges root et n'est pas autorisée dans les groupes de volumes d'instantanés).
- Lorsqu'un disque d'un groupe de volumes est endommagé, l'ensemble du groupe de volumes est affecté.
- En raison de l'ajout d'opérations supplémentaires, les performances de stockage sont affectées.
6. Méthode de création de PV/VG/LV
1. Définissez le type de système de chaque disque physique ou partition sur Linux LVM, son ID système est 8e, et définissez-le via la commande t dans l'outil fdisk.
[root@localhost ~]# fdisk /dev/sdb ...
Command (m for help): n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): p
Partition number (2-4, default 2): 2First sector (20973568-62914559, default 20973568):
Using default value 20973568Last sector, +sectors or +size{K,M,G} (20973568-62914559, default 62914559): +5G
...
Command (m for help): t
Partition number (1,2, default 2): 2Hex code (type L to list all codes): 8e # 指定system id为8eChanged type of partition 'Linux' to 'Linux LVM'...
Command (m for help): p
...
/dev/sdb1 2048 20973567 10485760 8e Linux LVM
/dev/sdb2 20973568 31459327 5242880 8e Linux LVM
Command (m for help): w
...2. Initialisez chaque disque physique ou partition dans un PV (volume physique)
Les commandes qui peuvent être utilisées à ce stade sont pvcreate, pvremove, pvscan, pvdisplay (pvs)
1) pvcreate : Créer un volume physique
用法:pvcreate [option] DEVICE 选项: -f:强制创建逻辑卷,不需用户确认 -u:指定设备的UUID -y:所有问题都回答yes 例 pvcreate /dev/sdb1 /dev/sdb2
2) pvscan : Scanner tous les volumes physiques sur le système actuel
用法:pvscan [option] 选项: -e:仅显示属于输出卷组的物理卷 -n:仅显示不属于任何卷组的物理卷 -u:显示UUID
3) pvdisplay : Afficher les propriétés du volume physique
用法:pvdisplay [PV_DEVICE]
4) pvremove : Remplacer le volume physique Les informations sur le volume sont supprimées afin qu'elles ne soient plus considérées comme un volume physique
用法:pvremove [option] PV_DEVICE 选项: -f:强制删除 -y:所有问题都回答yes 例 pvremove /dev/sdb1
5) Exemples de création et de suppression de pv
[root@localhost ~]# pvcreate /dev/sdb{1,2} # 将两个分区初始化为物理卷
Physical volume "/dev/sdb1" successfully created.
Physical volume "/dev/sdb2" successfully created.
[root@localhost ~]# pvscan
PV /dev/sdb2 lvm2 [5.00 GiB]
PV /dev/sdb1 lvm2 [10.00 GiB]
Total: 2 [15.00 GiB] / in use: 0 [0 ] / in no VG: 2 [15.00 GiB]
[root@localhost ~]# pvdisplay /dev/sdb1 # 显示物理卷sdb1的详细信息
"/dev/sdb1" is a new physical volume of "10.00 GiB"
--- NEW Physical volume ---
PV Name /dev/sdb1
VG Name
PV Size 10.00 GiB
Allocatable NO
PE Size 0 # 由于PE是在VG阶段才划分的,所以此处看到的都是0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID GrP9Gi-ubau-UAcb-za3B-vSc3-er2Q-MVt9OO
[root@localhost ~]# pvremove /dev/sdb2 # 删除sdb2的物理卷信息
Labels on physical volume "/dev/sdb2" successfully wiped.
[root@localhost ~]# pvscan # 可以看到PV列表中已无sdb2
PV /dev/sdb1 lvm2 [10.00 GiB]
Total: 1 [10.00 GiB] / in use: 0 [0 ] / in no VG: 1 [10.00 GiB]
[root@localhost ~]# pvcreate /dev/sdb2
Physical volume "/dev/sdb2" successfully created.3. groupe). Un groupe de volumes intègre plusieurs volumes physiques (protégeant les détails sous-jacents) et divise PE (extension physique)
PE est la plus petite unité de stockage dans un volume physique, un peu similaire à un bloc dans un système de fichiers. La taille du PE peut être spécifiée. . La valeur par défaut est 4M. Les commandes utilisées à ce stade sont vgcreate, vgscan, vgdisplay, vgextend, vgreduce
1) vgcreate : Créer un groupe de volumes
用法:vgcreate [option] VG_NAME PV_DEVICE 选项: -s:卷组中的物理卷的PE大小,默认为4M -l:卷组上允许创建的最大逻辑卷数 -p:卷级中允许添加的最大物理卷数 例 vgcreate -s 8M myvg /dev/sdb1 /dev/sdb2
2) vgscan : Rechercher le groupe de volumes LVM qui existe dans le système et afficher celui trouvé Liste des groupes de volumes
3) vgdisplay : Afficher les propriétés du groupe de volumes
用法:vgdisplay [option] [VG_NAME] 选项: -A:仅显示活动卷组的信息 -s:使用短格式输出信息
4) vgextend : étendre dynamiquement le groupe de volumes LVM, ce qui augmente la capacité du groupe de volumes en ajoutant des volumes physiques au volume group
用法:vgextend VG_NAME PV_DEVICE 例 vgextend myvg /dev/sdb3
5) vgreduce : Réduisez la capacité du groupe de volumes en supprimant les volumes physiques du groupe de volumes LVM. Le dernier volume physique restant du groupe de volumes LVM ne peut pas être supprimé
用法:vgreduce VG_NAME PV_DEVICE
6) vgremove. : Supprimez le groupe de volumes, le volume logique dessus doit être hors ligne
用法:vgremove [-f] VG_NAME -f:强制删除
7)vgchange:常用来设置卷组的活动状态
用法:vgchange -a n/y VG_NAME -a n为休眠状态,休眠之前要先确保其上的逻辑卷都离线; -a y为活动状态
8)vg创建例子
[root@localhost ~]# vgcreate -s 8M myvg /dev/sdb{1,2}
Volume group "myvg" successfully created
[root@localhost ~]# vgscan
Reading volume groups from cache.
Found volume group "myvg" using metadata type lvm2
[root@localhost ~]# vgdisplay
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 2
Act PV 2
VG Size 14.98 GiB
PE Size 8.00 MiB
Total PE 1918
Alloc PE / Size 0 / 0
Free PE / Size 1918 / 14.98 GiB
VG UUID aM3RND-aUbQ-7RjC-dCci-JiS4-Oj2Z-wv9poA4、在卷组上创建LV(logical volume,逻辑卷)
为了便于管理,逻辑卷对应的设备文件保存在卷组目录下,为/dev/VG_NAME/LV_NAME。LV中可以分配的最小存储单元称为LE(logical extend),在同一个卷组中,LE的大小和PE是一样的,且一一对应。这一阶段用到的命令有lvcreate、lvscan、lvdisplay、lvextend、lvreduce、lvresize
1)lvcreate:创建逻辑卷或快照
用法:lvcreate [选项] [参数] 选项: -L:指定大小 -l:指定大小(LE数) -n:指定名称 -s:创建快照 -p r:设置为只读(该选项一般用于创建快照中) 注:使用该命令创建逻辑卷时当然必须指明卷组,创建快照时必须指明针对哪个逻辑卷 例 lvcreate -L 500M -n mylv myvg
2)lvscan:扫描当前系统中的所有逻辑卷,及其对应的设备文件
3)lvdisplay:显示逻辑卷属性
用法:lvdisplay [/dev/VG_NAME/LV_NAME]
4)lvextend:可在线扩展逻辑卷空间
用法:lvextend -L/-l 扩展的大小 /dev/VG_NAME/LV_NAME 选项: -L:指定扩展(后)的大小。例如,-L +800M表示扩大800M,而-L 800M表示扩大至800M -l:指定扩展(后)的大小(LE数) 例 lvextend -L 200M /dev/myvg/mylv
5)lvreduce:缩减逻辑卷空间,一般离线使用
用法:lvexreduce -L/-l 缩减的大小 /dev/VG_NAME/LV_NAME 选项: -L:指定缩减(后)的大小 -l:指定缩减(后)的大小(LE数) 例 lvreduce -L 200M /dev/myvg/mylv
6)lvremove:删除逻辑卷,需要处于离线(卸载)状态
用法:lvremove [-f] /dev/VG_NAME/LV_NAME -f:强制删除
7)lv创建例子
[root@localhost ~]# lvcreate -L 2G -n mylv myvg Logical volume "mylv" created. [root@localhost ~]# lvscan ACTIVE '/dev/myvg/mylv' [2.00 GiB] inherit [root@localhost ~]# lvdisplay --- Logical volume --- LV Path /dev/myvg/mylv LV Name mylv VG Name myvg LV UUID 2lfCLR-UEhm-HMiT-ZJil-3EJm-n2H3-ONLaz1 LV Write Access read/write LV Creation host, time localhost.localdomain, 2019-07-05 13:42:44 +0800 LV Status available # open 0 LV Size 2.00 GiB Current LE 256 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:0
5、格式化逻辑卷并挂载
[root@localhost ~]# mke2fs -t ext4 /dev/myvg/mylv
...
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
...
[root@localhost ~]# mkdir /data
[root@localhost ~]# mount
mount mountpoint
[root@localhost ~]# mount /dev/myvg/mylv /data
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 50G 1.5G 49G 3% /
devtmpfs 903M 0 903M 0% /dev
tmpfs 912M 0 912M 0% /dev/shm
tmpfs 912M 8.6M 904M 1% /run
tmpfs 912M 0 912M 0% /sys/fs/cgroup
tmpfs 183M 0 183M 0% /run/user/0
/dev/mapper/myvg-mylv 2.0G 6.0M 1.8G 1% /data
PS:更新
一、LV逻辑卷扩容后,必须对挂载目录在线扩容。
使用 resize2fs或xfs_growfs 对挂载目录在线扩容
resize2fs 针对文件系统ext2 ext3 ext4
xfs_growfs 针对文件系统xfs
xfs在线扩容
xfs_growfs /dev/mapper/vg--BHG-lv01 meta-data=/dev/mapper/vg--BHG-lv01 isize=512 agcount=4, agsize=32000 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=0 spinodes=0data = bsize=4096 blocks=128000, imaxpct=25 = sunit=0 swidth=0 blksnaming =version 2 bsize=4096 ascii-ci=0 ftype=1log =internal bsize=4096 blocks=855, version=2 = sectsz=512 sunit=0 blks, lazy-count=1realtime =none extsz=4096 blocks=0, rtextents=0data blocks changed from 128000 to 256000
ext4在线扩容
[root@localhost /]# resize2fs /dev/mapper/vg--BHG-lv02 resize2fs 1.42.9 (28-Dec-2013) Filesystem at /dev/mapper/vg--BHG-lv02 is mounted on /BHGPOS-data; on-line resizing required old_desc_blocks = 2, new_desc_blocks = 3 The filesystem on /dev/mapper/vg--BHG-lv02 is now 5242880 blocks long.
相关推荐:《Linux视频教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Utilisation de Python dans Linux Terminal ...
 Comment configurer la tâche de synchronisation APScheduler en tant que service sur macOS?
Apr 01, 2025 pm 06:09 PM
Comment configurer la tâche de synchronisation APScheduler en tant que service sur macOS?
Apr 01, 2025 pm 06:09 PM
Configurez la tâche de synchronisation APScheduler en tant que service sur la plate-forme MacOS, si vous souhaitez configurer la tâche de synchronisation APScheduler en tant que service, similaire à Ngin ...
 Quatre façons d'implémenter le multithreading dans le langage C
Apr 03, 2025 pm 03:00 PM
Quatre façons d'implémenter le multithreading dans le langage C
Apr 03, 2025 pm 03:00 PM
Le multithreading dans la langue peut considérablement améliorer l'efficacité du programme. Il existe quatre façons principales d'implémenter le multithreading dans le langage C: créer des processus indépendants: créer plusieurs processus en cours d'exécution indépendante, chaque processus a son propre espace mémoire. Pseudo-Multithreading: Créez plusieurs flux d'exécution dans un processus qui partagent le même espace mémoire et exécutent alternativement. Bibliothèque multi-thread: Utilisez des bibliothèques multi-threades telles que PTHEADS pour créer et gérer des threads, en fournissant des fonctions de fonctionnement de thread riches. Coroutine: une implémentation multi-thread légère qui divise les tâches en petites sous-tâches et les exécute tour à tour.
 Comment ouvrir web.xml
Apr 03, 2025 am 06:51 AM
Comment ouvrir web.xml
Apr 03, 2025 am 06:51 AM
Pour ouvrir un fichier web.xml, vous pouvez utiliser les méthodes suivantes: Utilisez un éditeur de texte (tel que le bloc-notes ou TextEdit) pour modifier les commandes à l'aide d'un environnement de développement intégré (tel qu'Eclipse ou NetBeans) (Windows: Notepad web.xml; Mac / Linux: Open -A TextEdit web.xml)
 L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
En ce qui concerne le problème de la suppression de l'interpréteur Python qui est livré avec des systèmes Linux, de nombreuses distributions Linux préinstalleront l'interpréteur Python lors de l'installation, et il n'utilise pas le gestionnaire de packages ...
 À quoi sert le mieux le Linux?
Apr 03, 2025 am 12:11 AM
À quoi sert le mieux le Linux?
Apr 03, 2025 am 12:11 AM
Linux est mieux utilisé comme gestion de serveurs, systèmes intégrés et environnements de bureau. 1) Dans la gestion des serveurs, Linux est utilisé pour héberger des sites Web, des bases de données et des applications, assurant la stabilité et la fiabilité. 2) Dans les systèmes intégrés, Linux est largement utilisé dans les systèmes électroniques intelligents et automobiles en raison de sa flexibilité et de sa stabilité. 3) Dans l'environnement de bureau, Linux fournit des applications riches et des performances efficaces.
 Comment est la compatibilité Debian Hadoop
Apr 02, 2025 am 08:42 AM
Comment est la compatibilité Debian Hadoop
Apr 02, 2025 am 08:42 AM
Debianlinux est connu pour sa stabilité et sa sécurité et est largement utilisé dans les environnements de serveur, de développement et de bureau. Bien qu'il y ait actuellement un manque d'instructions officielles sur la compatibilité directe avec Debian et Hadoop, cet article vous guidera sur la façon de déployer Hadoop sur votre système Debian. Exigences du système Debian: Avant de commencer la configuration de Hadoop, assurez-vous que votre système Debian répond aux exigences de fonctionnement minimales de Hadoop, qui comprend l'installation de l'environnement d'exécution Java (JRE) nécessaire et des packages Hadoop. Étapes de déploiement de Hadoop: Télécharger et unzip Hadoop: Téléchargez la version Hadoop dont vous avez besoin sur le site officiel d'Apachehadoop et résolvez-le
 Debian Strings est-il compatible avec plusieurs navigateurs
Apr 02, 2025 am 08:30 AM
Debian Strings est-il compatible avec plusieurs navigateurs
Apr 02, 2025 am 08:30 AM
"Debianstrings" n'est pas un terme standard, et sa signification spécifique n'est pas encore claire. Cet article ne peut pas commenter directement la compatibilité de son navigateur. Cependant, si "DebianStrings" fait référence à une application Web exécutée sur un système Debian, sa compatibilité du navigateur dépend de l'architecture technique de l'application elle-même. La plupart des applications Web modernes se sont engagées à compatibilité entre les navigateurs. Cela repose sur les normes Web suivantes et l'utilisation de technologies frontales bien compatibles (telles que HTML, CSS, JavaScript) et les technologies back-end (telles que PHP, Python, Node.js, etc.). Pour s'assurer que l'application est compatible avec plusieurs navigateurs, les développeurs doivent souvent effectuer des tests croisés et utiliser la réactivité
