

En savoir plus sur le package dangereux dans Golang

Dans certaines bibliothèques de bas niveau, vous voyez souvent l'utilisation du package non sécurisé. Cet article vous amènera à comprendre le package non sécurisé dans Golang, à présenter le rôle du package non sécurisé et à utiliser Pointer. J'espère qu'il vous sera utile !

Le package unsafe fournit certaines opérations qui peuvent contourner le contrôle de sécurité de type go, exploitant ainsi directement les adresses mémoire et effectuant des opérations délicates. L'environnement d'exécution de l'exemple de code est
go version go1.18 darwin/amd64
Memory Alignment
Le package unsafe fournit la méthode Sizeof pour obtenir la taille de la mémoire occupée par les variables "à l'exclusion de la taille de la mémoire pointée par les pointeurs vers les variables", et Alignof obtient l'alignement de la mémoire coefficient. Vous pouvez rechercher sur Google des règles d'alignement de mémoire spécifiques.
type demo1 struct {
a bool // 1
b int32 // 4
c int64 // 8
}
type demo2 struct {
a bool // 1
c int64 // 8
b int32 // 4
}
type demo3 struct { // 64 位操作系统, 字长 8
a *demo1 // 8
b *demo2 // 8
}
func MemAlign() {
fmt.Println(unsafe.Sizeof(demo1{}), unsafe.Alignof(demo1{}), unsafe.Alignof(demo1{}.a), unsafe.Alignof(demo1{}.b), unsafe.Alignof(demo1{}.c)) // 16,8,1,4,8
fmt.Println(unsafe.Sizeof(demo2{}), unsafe.Alignof(demo2{}), unsafe.Alignof(demo2{}.a), unsafe.Alignof(demo2{}.b), unsafe.Alignof(demo2{}.c)) // 24,8,1,4,8
fmt.Println(unsafe.Sizeof(demo3{})) // 16
} // 16}复制代码Dans le cas ci-dessus, vous pouvez voir que demo1 et demo2 contiennent les mêmes attributs, mais l'ordre des attributs définis est différent, ce qui entraîne des tailles de mémoire différentes. variables. C'est parce que l'alignement de la mémoire se produit.
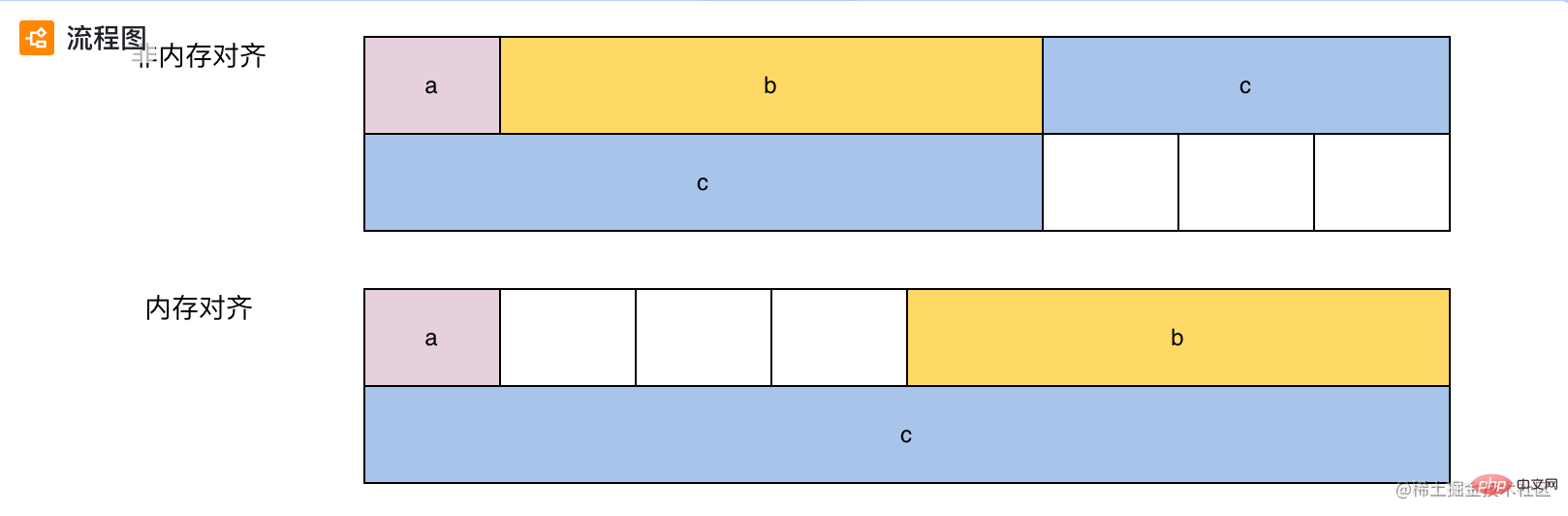
Lorsque l'ordinateur traite des tâches, il traitera les données dans des unités de longueurs de mots spécifiques "Par exemple : système d'exploitation 32 bits, la longueur du mot est de 4 ; système d'exploitation 64 bits, la longueur du mot est de 8". Ensuite, lors de la lecture des données, l'unité est également basée sur la longueur des mots. Par exemple : pour les systèmes d'exploitation 64 bits, le nombre d'octets lus par le programme en même temps est un multiple de 8. Voici la disposition de demo1 sous alignement non-mémoire et alignement mémoire :
Alignement non-mémoire :
La variable c sera placée dans des longueurs de mots différentes Lors de la lecture, le CPU doit lire deux fois en même temps, et lisez les deux. Ce n'est qu'en traitant les résultats des temps que nous pouvons obtenir la valeur de c. Bien que cette méthode économise de l’espace mémoire, elle augmentera le temps de traitement.
Alignement de la mémoire :
L'alignement de la mémoire adopte un schéma qui peut éviter la situation du même alignement de non-mémoire, mais il prendra de l'espace supplémentaire "espace pour le temps". Vous pouvez rechercher sur Google des règles d'alignement de mémoire spécifiques.
Pointeur non sécurisé
En go, vous pouvez déclarer un type de pointeur ici. Le type ici est un pointeur sûr, ce qui signifie que vous devez indiquer clairement le type vers lequel pointe le pointeur. Si les types ne correspondent pas, une erreur se produira lors de la compilation. Comme dans l'exemple suivant, le compilateur pensera que MyString et string sont de types différents et ne peuvent pas être attribués.
func main() {
type MyString string
s := "test"
var ms MyString = s // Cannot use 's' (type string) as the type MyString
fmt.Println(ms)
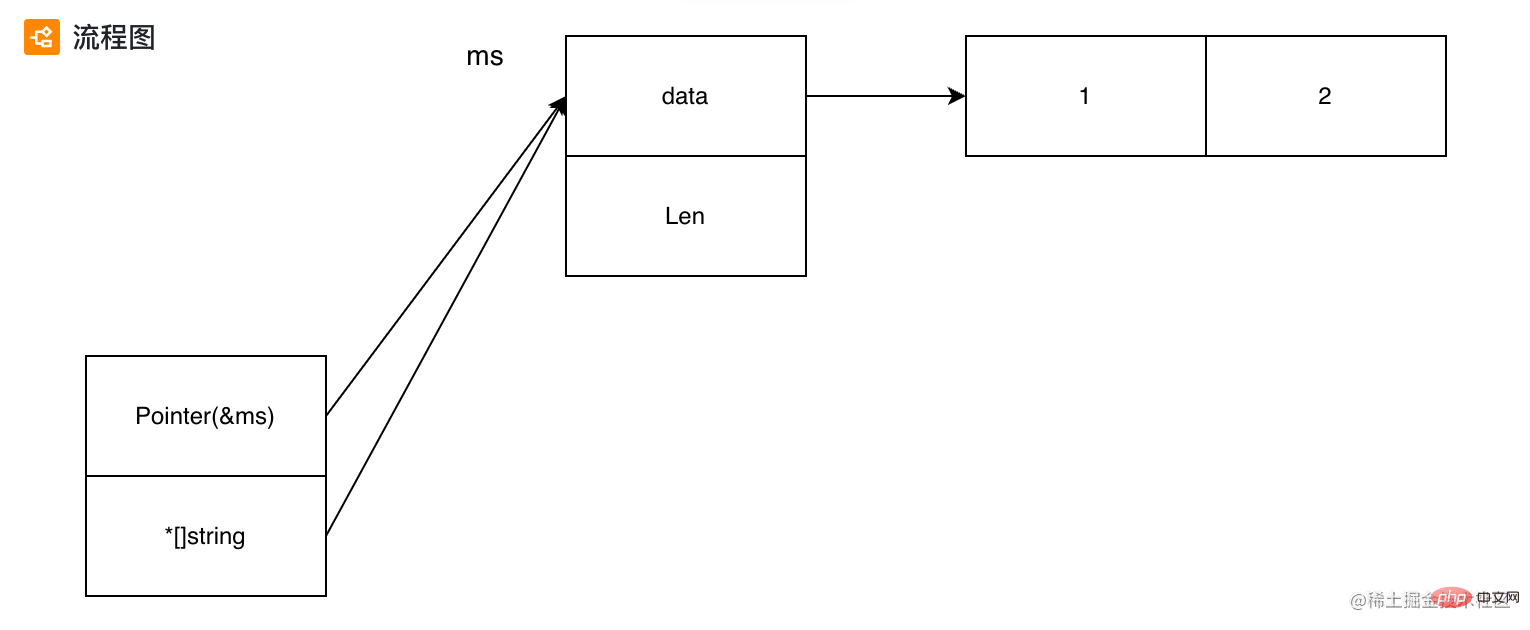
}Existe-t-il un type qui peut pointer vers des variables de n'importe quel type ? Vous pouvez utiliser unsfe.Pointer, qui peut pointer vers n'importe quel type de variable. Grâce à la déclaration de Pointer, on peut savoir qu'il s'agit d'un type pointeur, pointant vers l'adresse de la variable. La valeur correspondant à l'adresse spécifique peut être convertie via uinptr. Le pointeur a les quatre opérations spéciales suivantes :
- Tout type de pointeur peut être converti en type de pointeur
- Les variables de type pointeur peuvent être converties en n'importe quel type de pointeur
- Les variables de type uintptr peuvent être converties en type de pointeur
- Type de pointeur. la variable peut être convertie en type uintprt
type Pointer *ArbitraryType
// uintptr is an integer type that is large enough to hold the bit pattern of
// any pointer.
type uintptr uintptr
func main() {
d := demo1{true, 1, 2}
p := unsafe.Pointer(&d) // 任意类型的指针可以转换为 Pointer 类型
pa := (*demo1)(p) // Pointer 类型变量可以转换成 demo1 类型的指针
up := uintptr(p) // Pointer 类型的变量可以转换成 uintprt 类型
pu := unsafe.Pointer(up) // uintptr 类型的变量可以转换成 Pointer 类型; 当 GC 时, d 的地址可能会发生变更, 因此, 这里的 up 可能会失效
fmt.Println(d.a, pa.a, (*demo1)(pu).a) // true true true
}Six façons d'utiliser Pointer
Le document officiel donne six façons d'utiliser Pointer.
Convertir *T1 en *T2 via Pointer
Pointer pointe directement vers un morceau de mémoire, cette adresse mémoire peut donc être convertie en n'importe quel type. Il convient de noter ici que T1 et T2 doivent avoir la même disposition de mémoire et qu'il y aura des données anormales.
func main() {
type myStr string
ms := []myStr{"1", "2"}
//ss := ([]string)(ms) Cannot convert an expression of the type '[]myStr' to the type '[]string'
ss := *(*[]string)(unsafe.Pointer(&ms)) // 将 pointer 指向的内存地址直接转换成 *[]string
fmt.Println(ms, ss)
}
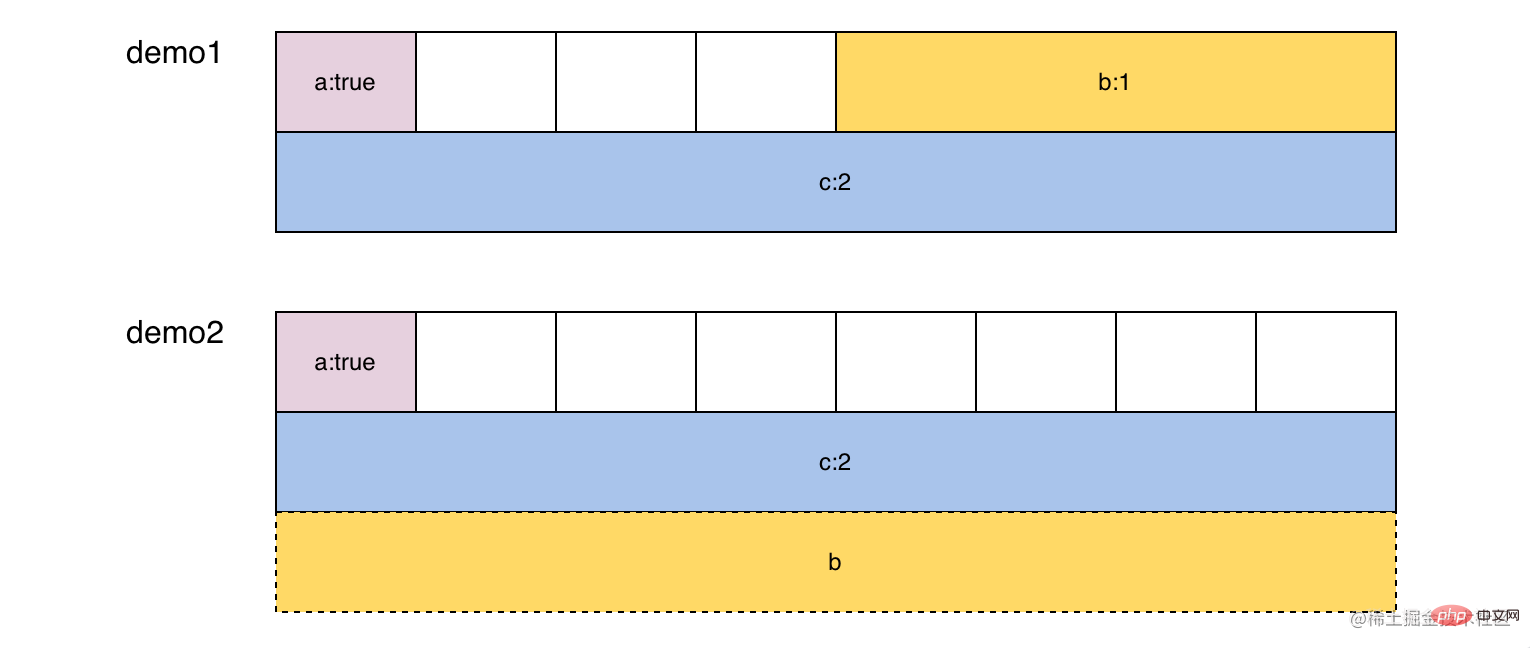
Que se passera-t-il si la disposition de la mémoire de T1 et T2 est différente ? Dans l'exemple ci-dessous, bien que demo1 et demo2 contiennent la même structure, en raison de l'alignement de la mémoire, ils ont des configurations de mémoire différentes. Lors de la conversion du pointeur, 24 octets "sizeof" seront lus à partir de l'adresse de demo1, et la conversion sera effectuée selon les règles d'alignement de la mémoire de demo2. Le premier octet sera converti en a:true et 8 à 16 octets. sera converti en c. :2, 16-24 octets dépassent la plage de demo1, mais peuvent toujours être lus directement, et la valeur inattendue b:17368000 est obtenue.
type demo1 struct {
a bool // 1
b int32 // 4
c int64 // 8
}
type demo2 struct {
a bool // 1
c int64 // 8
b int32 // 4
}
func main() {
d := demo1{true, 1, 2}
pa := (*demo2)(unsafe.Pointer(&d)) // Pointer 类型变量可以转换成 demo2 类型的指针
fmt.Println(pa.a, pa.b, pa.c) // true, 17368000, 2,
}
Convertir le type de pointeur en type uintptr "Vous ne devez pas convertir uinptr en pointeur"
Pointer est un type de pointeur qui peut pointer vers n'importe quelle variable et peut être imprimé en convertissant le pointeur en pointeur uintptr pointe vers l'adresse de la variable. De plus : uintptr ne doit pas être converti en pointeur. Prenons l'exemple suivant : lorsque GC se produit, l'adresse de d peut changer, puis pointe vers la mauvaise mémoire en raison de mises à jour non synchronisées.
func main() {
d := demo1{true, 1, 2}
p := unsafe.Pointer(&d)
up := uintptr(p)
fmt.Printf("uintptr: %x, ptr: %p \n", up, &d) // uintptr: c00010c010, ptr: 0xc00010c010
fmt.Println(*(*demo1)(unsafe.Pointer(up))) // 不允许
}通过算数计算将 Pointer 转换为 uinptr 再转换回 Pointer
当 Piointer 指向一个结构体时, 可以通过此方式获取到结构体内部特定属性的 Pointer。
func main() {
d := demo1{true, 1, 2}
// 等同于 unsafe.Pointer(&d.b); unsafe.Add(unsafe.Pointer(&d), unsafe.Offsetof(d.b))
pb := unsafe.Pointer(uintptr(unsafe.Pointer(&d)) + unsafe.Offsetof(d.b))
fmt.Println(pb)
}当调用 syscall.Syscall 的时候, 可以讲 Pointer 转换为 uintptr
前面说过, 由于 GC 会导致变量的地址发生变更, 因此不可以直接处理 uintptr。但是, 在调用 syscall.Syscall 时候可以允许传递一个 uintptr, 这里可以简单理解为是编译器做了特殊处理, 来保证 uintptr 是安全的。
- 调用方式:
- syscall.Syscall(SYS_READ, uintptr( fd ), uintptr(unsafe.Pointer(p)), uintptr(n))
下面这种方式是不允许的:
u := uintptr(unsafe.Pointer(p)) // 不应该保存到一个变量上 syscall.Syscall(SYS_READ, uintptr( fd ), u, uintptr(n))
可以将 reflect.Value.Pointer 或 reflect.Value.UnsafeAddr 的结果「uintptr」转换为 Pointer
在 reflect 包中的 Value.Pointer 和 Value.UnsafeAddr 直接返回了地址对应的值「uintptr」, 可以直接将其结果转为 Pointer
func main() {
d := demo1{true, 1, 2}
// 等同于 unsafe.Pointer(&d.b); unsafe.Add(unsafe.Pointer(&d), unsafe.Offsetof(d.b))
pb := unsafe.Pointer(uintptr(unsafe.Pointer(&d)) + unsafe.Offsetof(d.b))
// up := reflect.ValueOf(&d.b).Pointer(), pc := unsafe.Pointer(up); 不安全, 不应存储到变量中
pc := unsafe.Pointer(reflect.ValueOf(&d.b).Pointer())
fmt.Println(pb, pc)
}可以将 reflect.SliceHeader 或者 reflect.StringHeader 的 Data 字段与 Pointer 相互转换
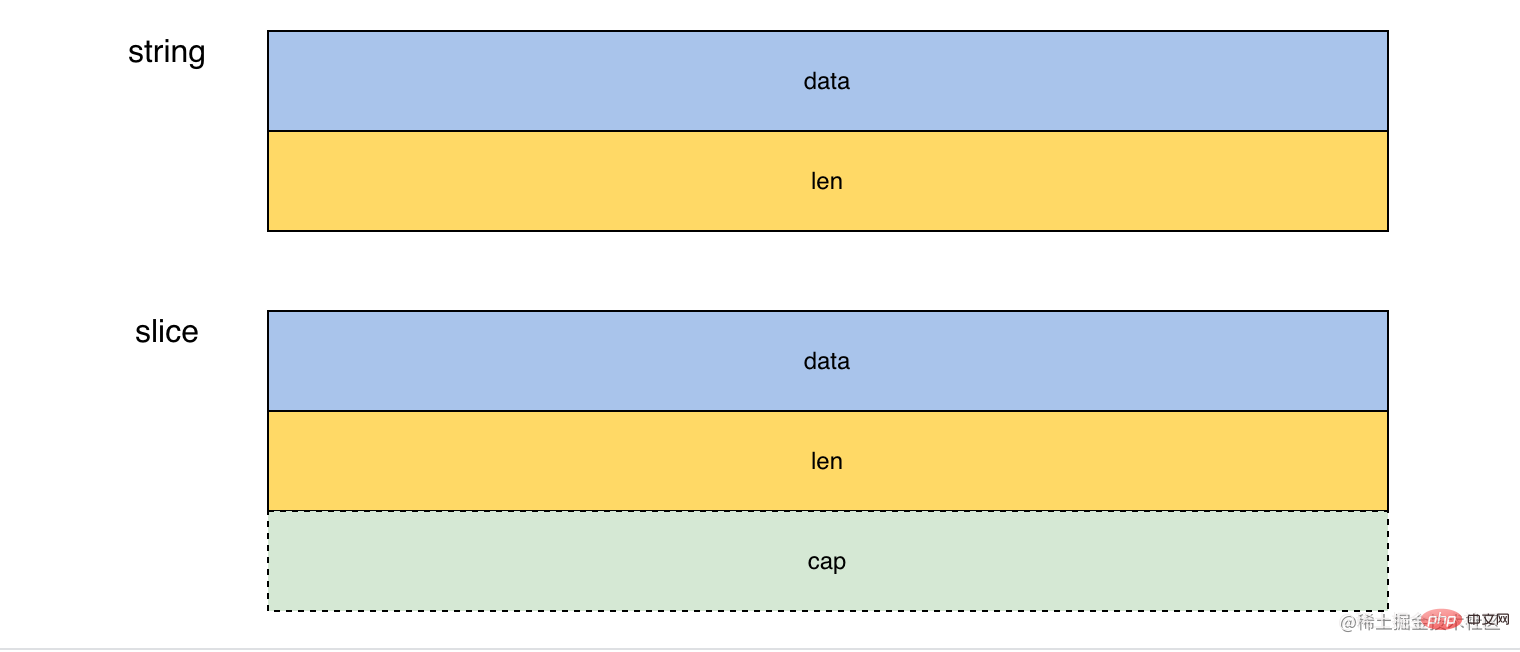
SliceHeader 和 StringHeader 其实是 slice 和 string 的内部实现, 里面都包含了一个字段 Data「uintptr」, 存储的是指向 []T 的地址, 这里之所以使用 uinptr 是为了不依赖 unsafe 包。
func main() {
s := "a"
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // *string to *StringHeader
fmt.Println(*(*[1]byte)(unsafe.Pointer(hdr.Data))) // 底层存储的是 utf 编码后的 byte 数组
arr := [1]byte{65}
hdr.Data = uintptr(unsafe.Pointer(&arr))
hdr.Len = len(arr)
ss := *(*string)(unsafe.Pointer(hdr))
fmt.Println(ss) // A
arr[0] = 66
fmt.Println(ss) //B
}应用
string、byte 转换
在业务上, 经常遇到 string 和 []byte 的相互转换。我们知道, string 底层其实也是存储的一个 byte 数组, 可以通过 reflect 直接获取 string 指向的 byte 数组, 赋值给 byte 切片, 避免内存拷贝。
func StrToByte(str string) []byte {
return []byte(str)
}
func StrToByteV2(str string) (b []byte) {
bh := (*reflect.SliceHeader)(unsafe.Pointer(&b))
sh := (*reflect.StringHeader)(unsafe.Pointer(&str))
bh.Data = sh.Data
bh.Cap = sh.Len
bh.Len = sh.Len
return b
}
// go test -bench .
func BenchmarkStrToArr(b *testing.B) {
for i := 0; i < b.N; i++ {
StrToByte(`{"f": "v"}`)
}
}
func BenchmarkStrToArrV2(b *testing.B) {
for i := 0; i < b.N; i++ {
StrToByteV2(`{"f": "v"}`)
}
}
//goos: darwin
//goarch: amd64
//pkg: github.com/demo/lsafe
//cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
//BenchmarkStrToArr-12 264733503 4.311 ns/op
//BenchmarkStrToArrV2-12 1000000000 0.2528 ns/op通过观察 string 和 byte 的内存布局我们可以知道, 无法直接将 string 转为 []byte 「确实 cap 字段」, 但是可以直接将 []byte 转为 string
func ByteToStr(b []byte) string {
return string(b)
}
func ByteToStrV2(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
// go test -bench .
func BenchmarkArrToStr(b *testing.B) {
for i := 0; i < b.N; i++ {
ByteToStr([]byte{65})
}
}
func BenchmarkArrToStrV2(b *testing.B) {
for i := 0; i < b.N; i++ {
ByteToStrV2([]byte{65})
}
}
//goos: darwin
//goarch: amd64
//pkg: github.com/demo/lsafe
//cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
//BenchmarkArrToStr-12 536188455 2.180 ns/op
//BenchmarkArrToStrV2-12 1000000000 0.2526 ns/op总结
本文介绍了如何使用 unsafe 包绕过类型检查, 直接操作内存。正如 go 作者对包的命名一样, 它是 unsafe 的, 随着 go 版本的迭代, 有些机制可能会发生变更。如无必要, 不应使用这个包。如果要使用 unsafe 包, 一定要理解清楚Pointer、uinptr、对齐系数等概念。
推荐学习:Golang教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Compréhension approfondie du cycle de vie des fonctions Golang et de la portée variable
Apr 19, 2024 am 11:42 AM
Compréhension approfondie du cycle de vie des fonctions Golang et de la portée variable
Apr 19, 2024 am 11:42 AM
Dans Go, le cycle de vie de la fonction comprend la définition, le chargement, la liaison, l'initialisation, l'appel et le retour ; la portée des variables est divisée en niveau de fonction et au niveau du bloc. Les variables d'une fonction sont visibles en interne, tandis que les variables d'un bloc ne sont visibles que dans le bloc. .
 Comment faire correspondre les horodatages à l'aide d'expressions régulières dans Go ?
Jun 02, 2024 am 09:00 AM
Comment faire correspondre les horodatages à l'aide d'expressions régulières dans Go ?
Jun 02, 2024 am 09:00 AM
Dans Go, vous pouvez utiliser des expressions régulières pour faire correspondre les horodatages : compilez une chaîne d'expression régulière, telle que celle utilisée pour faire correspondre les horodatages ISO8601 : ^\d{4}-\d{2}-\d{2}T \d{ 2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$ . Utilisez la fonction regexp.MatchString pour vérifier si une chaîne correspond à une expression régulière.
 Comment envoyer des messages Go WebSocket ?
Jun 03, 2024 pm 04:53 PM
Comment envoyer des messages Go WebSocket ?
Jun 03, 2024 pm 04:53 PM
Dans Go, les messages WebSocket peuvent être envoyés à l'aide du package gorilla/websocket. Étapes spécifiques : Établissez une connexion WebSocket. Envoyer un message texte : appelez WriteMessage(websocket.TextMessage,[]byte("message")). Envoyez un message binaire : appelez WriteMessage(websocket.BinaryMessage,[]byte{1,2,3}).
 La différence entre la langue Golang et Go
May 31, 2024 pm 08:10 PM
La différence entre la langue Golang et Go
May 31, 2024 pm 08:10 PM
Go et le langage Go sont des entités différentes avec des caractéristiques différentes. Go (également connu sous le nom de Golang) est connu pour sa concurrence, sa vitesse de compilation rapide, sa gestion de la mémoire et ses avantages multiplateformes. Les inconvénients du langage Go incluent un écosystème moins riche que les autres langages, une syntaxe plus stricte et un manque de typage dynamique.
 Comment éviter les fuites de mémoire dans l'optimisation des performances techniques de Golang ?
Jun 04, 2024 pm 12:27 PM
Comment éviter les fuites de mémoire dans l'optimisation des performances techniques de Golang ?
Jun 04, 2024 pm 12:27 PM
Les fuites de mémoire peuvent entraîner une augmentation continue de la mémoire du programme Go en : fermant les ressources qui ne sont plus utilisées, telles que les fichiers, les connexions réseau et les connexions à la base de données. Utilisez des références faibles pour éviter les fuites de mémoire et ciblez les objets pour le garbage collection lorsqu'ils ne sont plus fortement référencés. En utilisant go coroutine, la mémoire de la pile de coroutines sera automatiquement libérée à la sortie pour éviter les fuites de mémoire.
 Comment afficher la documentation des fonctions Golang dans l'EDI ?
Apr 18, 2024 pm 03:06 PM
Comment afficher la documentation des fonctions Golang dans l'EDI ?
Apr 18, 2024 pm 03:06 PM
Consultez la documentation de la fonction Go à l'aide de l'EDI : passez le curseur sur le nom de la fonction. Appuyez sur la touche de raccourci (GoLand : Ctrl+Q ; VSCode : Après avoir installé GoExtensionPack, F1 et sélectionnez « Go:ShowDocumentation »).
 Comment utiliser le wrapper d'erreur de Golang ?
Jun 03, 2024 pm 04:08 PM
Comment utiliser le wrapper d'erreur de Golang ?
Jun 03, 2024 pm 04:08 PM
Dans Golang, les wrappers d'erreurs vous permettent de créer de nouvelles erreurs en ajoutant des informations contextuelles à l'erreur d'origine. Cela peut être utilisé pour unifier les types d'erreurs générées par différentes bibliothèques ou composants, simplifiant ainsi le débogage et la gestion des erreurs. Les étapes sont les suivantes : Utilisez la fonction error.Wrap pour envelopper les erreurs d'origine dans de nouvelles erreurs. La nouvelle erreur contient des informations contextuelles de l'erreur d'origine. Utilisez fmt.Printf pour générer des erreurs encapsulées, offrant ainsi plus de contexte et de possibilités d'action. Lors de la gestion de différents types d’erreurs, utilisez la fonction erreurs.Wrap pour unifier les types d’erreurs.
 Un guide pour les tests unitaires des fonctions simultanées Go
May 03, 2024 am 10:54 AM
Un guide pour les tests unitaires des fonctions simultanées Go
May 03, 2024 am 10:54 AM
Les tests unitaires des fonctions simultanées sont essentiels car cela permet de garantir leur comportement correct dans un environnement simultané. Des principes fondamentaux tels que l'exclusion mutuelle, la synchronisation et l'isolement doivent être pris en compte lors du test de fonctions concurrentes. Les fonctions simultanées peuvent être testées unitairement en simulant, en testant les conditions de concurrence et en vérifiant les résultats.
